Gokart+MLflowで実験のパイプライン処理をシンプルに構築して、研究を効率的に進める
こんにちは、@makiart13です。
普段は筑波大学で情報検索に関する研究を行っています。
この記事では、機械学習パイプライン処理のライブラリであるGokartと実験のパラメタや結果を管理してくれるMLflow(Tracking)を利用して、シンプルに研究の実験を効率化する方法について提案しています!
対象読者
- 機械学習をはじめとする情報系の研究を行う学部生、院生
- パイプライン処理に興味のある方
- Kaggleなどを行う方?
この記事では、情報系の研究での実験の構築と結果の管理を効率よく行うことにフォーカスしています!
逆にプロダクト向けのMLOpsの話ではないので注意!
以下のような課題を理解できる人にはぜひ読んで欲しい
- 重複した処理を何度も行う実験が多い
- 実験の中間ファイルの管理がごちゃごちゃ(最悪コンフリクト;;)
- 実験結果の全体を見るのに一手間コードを書かなくてはいけない
- パラメータの管理が大変
- 実験コードの全容が複雑で修正しにくい
このような問題をGokart+MLflowで改善することができると思いますので、ぜひ今後の参考にしていただければ幸いです!
背景
研究では、多くの実験を効率的に管理し、実行する必要があります。
特に、情報系の研究ではテーマによっては大量の実験を行うことが予測され、それらの管理が大きな課題になると思います。(私はそうでした。)
そのため、研究にもいわゆるMLOps的な側面が重要になってきます。
しかし、世のMLOpsはAWS・GCP・Azureなどをはじめとするクラウドサービスや大規模なシステムを利用した手法が主流で、学生が行うような研究ではオーバースペックかつコスト(学習・お金)が大きいです。
そこで私は、よりシンプルで、より小さく始められ、よりコストを抑えられるやり方はないかと考え、最終的にGokartとMLflowを利用して改善する方法に辿り着きました!
これら2つのツールを統合することで、以下のような利点が得られることを期待しています!
- 実験の構造化:Gokartによって実験のパイプラインを明確に定義し、再現性を向上。
- 効率的な実行:Gokartのキャッシュシステムにより、重複した処理の回避。
- 包括的な実験管理:MLflowを通じて、実験のパラメータ、結果などを一元管理。
- 低い学習コスト:シンプルな仕組みなので比較的簡単に始められる(はず)
この記事で達成されること
- GokartとMLflowの統合
- 実験パイプラインの構築
- キャッシュによる効率的なタスク実行
- パラメタ、実験結果の簡単な管理
Gokart+MLflowでうまく処理を分割しつつ、結果をリッチなUIで管理することが可能になります!
パイプライン処理とは?
パイプライン処理とは、一連のデータ処理タスクを効率的かつ自動化された方法で実行するためのシステムです。研究におけるパイプラインは、データの取り込み、変換、分析、モデルトレーニング、評価といったタスクによって構成されると思います。
これらのタスクをモジュールと考えてパイプラインを構築することで、例えば、推論モデルの種類を変更して同じ問題を解かせるといったことをしようとした時にモデルのモジュールだけ付け変えるだけで同じ条件の実験を行うことができます。
仮に上記のような形で分割しモジュールを作成すると、そのタスク単位でコードを入れ替えすることが可能になると思います!
パイプライン処理の主な目的は以下の通りです:
- 再現性の向上: パイプラインは実験の各ステップを明確に定義し、パラメータや依存関係を追跡することで、実験の再現性を高めます。
- 自動化: 手動のデータ処理や実験の実行は時間がかかり、エラーが発生しやすくなります。パイプラインは繰り返しのタスクを自動化し、効率を高めます。
- モジュール化: パイプラインはワークフローを独立したタスクに分割することで、コードの管理や保守を容易にします。各タスクは個別にテストや最適化が可能です。
要は、実験をある程度の粒度で分割し、タスクとして定義してあげることで、コードの管理が容易になり、より効率的に研究を進めることができるということです!
私はこのパイプライン処理を研究で取り入れるためにGokartというパイプライン処理のライブラリを利用することにしました!
パイプライン処理ライブラリ自体はたくさんあります!少し昔ですが、ライブラリの比較記事を置いておきます。
なぜGokart?
Gokartはエムスリーさんが開発したライブラリで、luigiというパイプライン処理ライブラリをラッパーしたものです。
Gokartを選んだ理由としては以下のとおりです。
- ちょうどいい制約
- 基本構成がわかりやすく、他人が見ても理解しやすい
- 出力ファイルを設定しなくてもpklでいい感じにやってくれる
- キャッシュシステムがいい感じ
- 小さく始めやすい
- (一部の先輩が使用していた)
といっても、私自身色々なパイプラインライブラリを利用してきたわけではないので、一概にGokartを推すことはできませんが、研究の実験コードに取り入れるにはちょうどいいなと感じました。
Gokartでは、各タスクで入力パラメータに対する出力を保持しているので、同じタスク同じパラメータによる実行はキャッシュを返すようになっており、再度同じ処理が行われることを回避できます!これによって効率よく計算サーバーを利用できますね!
しかし、Gokartではうまくパラメータや結果をまとめて、実験ごとに比較するなどが容易ではなかったので、MLflowによってうまく管理できないかと考えました。
MLflowには様々な機能があるのですが、パラメータや結果を管理するために、ここではTrackingの機能を使用しました。
GokartでMLflowを使う
私はMLflowにパラメータ、中間ファイルを管理できるようにGokartにMLflowを組み合わせた基底クラスを作成しました。
これを利用してパイプラインを作成することで自動的に各パイプラインのタスクのパラメータ、中間ファイルが自動的にmlflowに記録されることに加えてタスク内でMLflowのロギング機能を使うことでより細かな結果やログをとることが可能です!そしてそれらの記録をMLflowのGUIから確認することができるのです!
Gokart+MLflowの基底クラス
作成にあたり以下の記事を参考にさせていただきました。
実際に動かしてみる
実際にパイプライン処理でNTCIR18のSUSHIという検索タスクを実行するものをざっくり作成しました。処理の内容は公開されているサンプルコードから作成しています。
だいぶ大雑把にパイプラインを構築していますが、大体こんな感じにパイプライン処理を構築できるんだという感じに思っていただけたら幸いです🙇
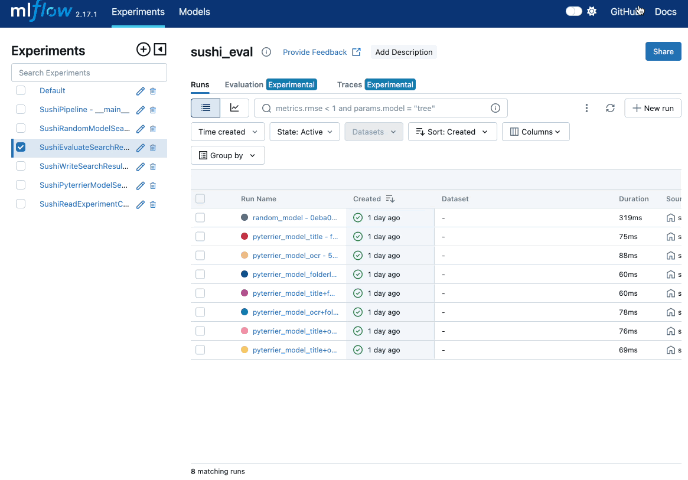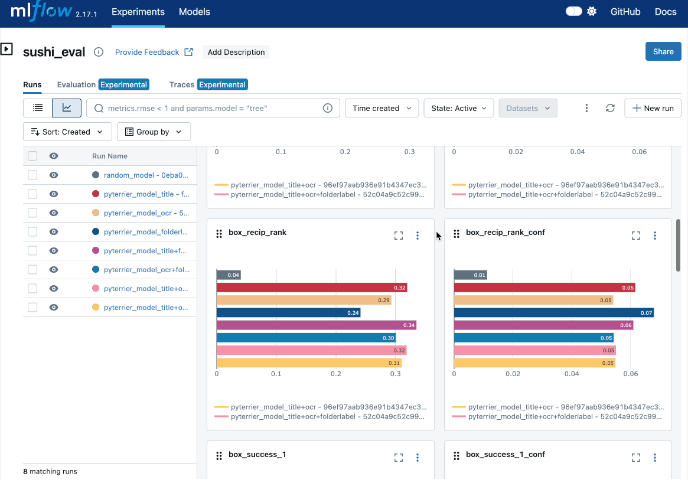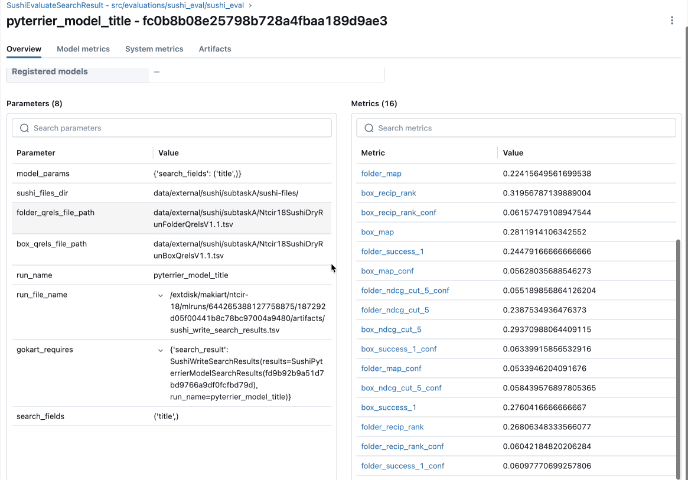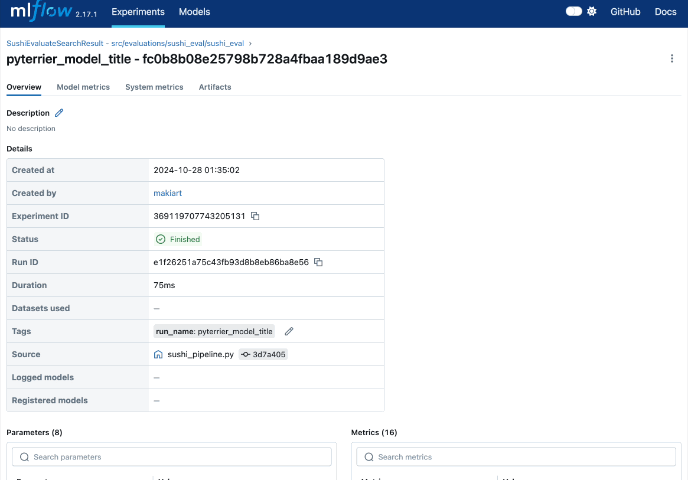
パイプラインを実行した後はMLflowを使ってブラウザから実験結果を閲覧してみます。
mlflow ui
上記のコマンドを実行するとパイプラインのタスク別に結果、パラメタなどを閲覧したり、結果を比較したりすることができます!
今後行なっていきたいこと
この記事ではGokartで実験のコードをわかりやすい形でタスクごとに分割し、コード管理のしやすさを向上しつつ、MLflowによって、行なった実験の内容と結果をわかりやすく管理できる方法について提案しました。
大抵の学生はB4(高専では5年生)から研究室に配属されて研究を行うと思うのですが、配属時点からゴリゴリにコードを書いてきたという人はそこまで多くないかと思います。
それに加えて、そもそも研究というのは不確実性が多く、論文を書き始める頃にはたくさんの実験コードと実験のログでごちゃごちゃになりやすいです。そして、非本質的な部分で苦しむみたいなことが多々起きがちです。
GokartとMLflowを使うことによってその状況を少しでも軽減できたらと願いつつ、他にも軽減するための方法はいくつかあると考えられます。
例えば、
- Lint、Formatterを導入する
- テストを導入する
- CIの導入
- ある程度決められたディレクトリ構造でコードを管理する
などが挙げられます。
今後は上記のようことを簡単に最初から使える状態にセットアップできる研究テンプレリポジトリなどを作成していきたいと考えています。
Cookiecutter Data Scienceなどが有名だと思いますが、これよりも少し制限を強くし、より簡単に使えるテンプレを目指して作成していきます!
ぜひ研究のコード管理、実験管理を簡単に管理できるツールや方法についてご存知の方いればコメントなどで教えてください!
Discussion