PDFの情報を元にAIがラジオを作成する仕組みを作ってみた👀
こんにちは!makiartです!
私は少し前に与えられたPDFデータをもとに、AI(LLM)がラジオ番組を作成してくれるサービスを公開しました!!
⬆️このポストのツリーにクーポン貼っているので興味のある方はチェックしてみてください!
そして今回はそのサービスのコア部分である生成AIを利用して、ラジオを作成する部分の実装について紹介したいと思っております!
公開したサービスはこちら!10円でラジオを作成できますー!
興味のある方はぜひお試しください!
今回作成したAIラジオ生成の仕組みや基礎
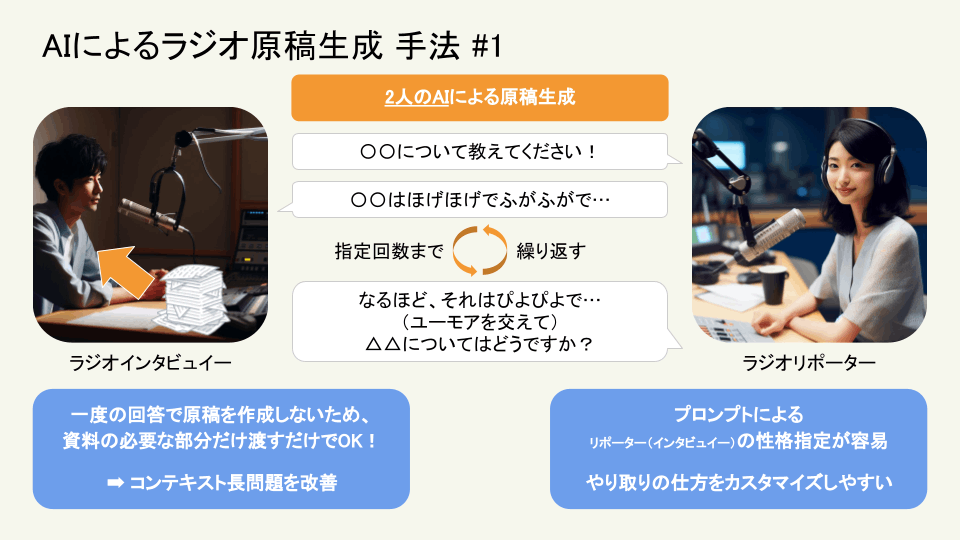
この記事で生成したいラジオ番組は、以下のようなものです。
- 2人によって構成される
- リポーターとインタビュイーを1人ずつ
- 提供した情報をもとにラジオを生成
- 指定した回数分会話を行う
この条件をもとにAIラジオ生成の仕組みは以下のようになると考えました。
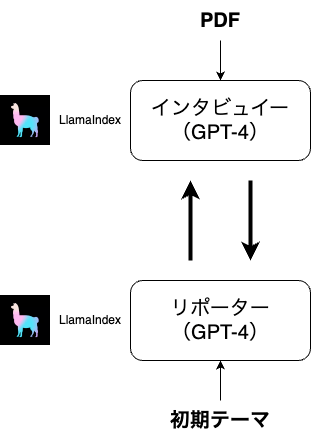
AIラジオ生成の仕組み図。LlamaIndexとGPT-4を利用して、リポーターとインタビューイーどうしが指定した回数質問や回答を行う。
ラジオ生成(原稿の生成)として最初に考えられるのは、1人のAIでFunction Callingなどを用いて、リポータとインタビュイーの相互のやりとりを配列的に生成する方法が考えられます。

ですが、この方法だといくつかの問題点が発生します。
- アップロードしたPDFの内容が多いとGPT-4のコンテキスト長を超えてしまう可能性がある
- 指定回数分の会話をするという指示が難しい、正しく動作しない可能性がある
- 会話に自由度を持たせようとした時にコストが高い
一方、リポータとインタビュイーの二つのチャットボットを作成して、相互にやり取りを行うことで、
- インタビュイーはリポータの質問内容からPDFの一部の情報を抽出し、それをもとに回答させる
- それぞれのチャットボットに対して、独立した(システム)プロンプトを与えることが可能であるため、会話のカスタマイズが容易である
- リポーターはユーモアを交えて会話させるなど
- 指定した回数分、お互いにやり取りを行わせれば良いので、会話の長さの調整が容易
以上のことから、チャットボットを二つ用意してお互いに会話させる方式でAIラジオ生成を開発しました!
チャットボット部分
チャットボットの生成に関しては、リポータ、インタビュイーどちらもLlamaIndexを使用して作成することにしました。以下にそれぞれのチャットボットを作成する関数を貼り付けておきます。
リポーターBot
リポーターのチャットボットはPDFの内容を参照することはなく、あくまでもインタビュイーからの応答をもとに、反応や質問などを行うボットですので、シンプルに実装しました。
custom_prefix_messagesの引数には、今までの会話情報や細かな情報や指示を加えられるように付け加えました。
from langchain.chat_models import ChatOpenAI
from llama_index import ServiceContext
from llama_index.chat_engine import SimpleChatEngine
from llama_index.llms.base import ChatMessage, MessageRole
service_context_gpt4 = ServiceContext.from_defaults(
llm=ChatOpenAI(temperature=1, model="gpt-4")
)
def make_reporter(custom_prefix_messages=None):
# リポーター
system_prompt = """あなたは優秀なラジオリポーターになりきってください。あなたはこれから現場取材を行います。相手は解説役ですので、質問をしながら話を深掘りしてください。また、生放送ですので、質問は短い文章になるようにしてください。会話には少しユーモアを加えるようにしてください。自然なはなし口調でお願いします。"""
prefix_messages = [
ChatMessage(content=system_prompt, role=MessageRole.SYSTEM),
]
if custom_prefix_messages:
prefix_messages.extend(custom_prefix_messages)
reporter = SimpleChatEngine.from_defaults(
prefix_messages=prefix_messages, service_context=service_context_gpt4
)
return reporter
インタビュイーBot
インタビュイーはリポータがする質問に対して、与えられたPDFの情報をもとに回答をしなくてはいけません。
今回はLlamaIndexとLlamaHubを利用して、PDFの情報をもとに応答するBotの実装を行いました。
やってることを簡単に説明すると(わかる人にはおせっかいな文章ではあるとは思いますが;)、PDFからテキスト情報を抽出し、一定のサイズのチャンクごとにベクトルに変換し、インデックスを作成し、それをもとに応答するようなチャットボットを作成しています。
このチャットボットはリポーターから質問を受けるごとに、質問内容をベクトルに変換し、PDFのベクトルインデックスと近い距離のチャンク(意味合いの似ているチャンク)をチャットボットの回答の参考として与えるような仕組みです。
from pathlib import Path
from langchain.chat_models import ChatOpenAI
from llama_index import GPTVectorStoreIndex, ServiceContext, download_loader
from llama_index.chat_engine.types import ChatMode
from llama_index.llms.base import ChatMessage, MessageRole
service_context_gpt4 = ServiceContext.from_defaults(
llm=ChatOpenAI(temperature=1, model="gpt-4")
)
def make_interviwee(file):
# 読み込んだドキュメントを使用してインデックスを作成する
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file=Path(file.name))
index = GPTVectorStoreIndex.from_documents(documents)
# インタビュイー
system_prompt = """あなたはラジオゲストになりきってください。あなたはこれからインタビューを受けます。これは生放送ですので、回答は短い文章にしてください。また、音声のみのコミュニケーションになりますので、相手に伝わるように長文は避けてください。自然なはなし口調でお願いします。"""
prefix_messages = [
ChatMessage(content=system_prompt, role=MessageRole.SYSTEM),
ChatMessage(
content="私はこれからあなたの質問に回答したいと思います。何から話せば良いでしょうか?", role=MessageRole.ASSISTANT
),
]
interviwee = index.as_chat_engine(
chat_mode=ChatMode.CONTEXT,
prefix_messages=prefix_messages,
service_context=service_context_gpt4,
)
return interviwee
ラジオ原稿生成部分
結構雑な実装ですみません;;
ポイントとしては毎回会話のレスポンスをさせる際にシステムプロンプトで残りの回数を提示して回答させるようにしている点ですね。
# 適当に最初のプロンプト
reporter_message = (
f"私はこれからあなたにインタビューをしていきたいと思います!まずは今日お話ししていただく{first_theme}教えてください!"
)
interviwee = make_interviwee(pdf_file)
# リポーターには質問をしたという記憶を植え付ける^-^
reporter_prefix_messages = [
ChatMessage(
content=reporter_message,
role=MessageRole.ASSISTANT,
),
]
reporter = make_reporter(custom_prefix_messages=reporter_prefix_messages)
for i in range(iteration):
interviwee_chat_history = interviwee.chat_history
interviwee_chat_history.append(
ChatMessage(
content=f"このやりとりはあと{iteration - i + 1}回です。残りの会話のやり取り回数を考慮して会話を続けてください。この回数が0になる前に話は絶対に終わらせないでください。",
role=MessageRole.SYSTEM,
)
)
interviwee_response = interviwee.chat(reporter_message + "簡潔に答えてください!")
interviwee_message = interviwee_response.response
radio_manuscripts.append({"speaker": "man01", "message": interviwee_message})
reporter_chat_history = reporter.chat_history
reporter_chat_history.append(
ChatMessage(
content=f"このやりとりはあと{iteration - i}回です。残りの会話のやり取り回数を考慮して会話を続けてください。この回数が0になる前に話は絶対に終わらせないでください。",
role=MessageRole.SYSTEM,
)
)
# ラジオを終わらせる
reporter_response = reporter.chat(interviwee_message)
reporter_message = reporter_response.response
radio_manuscripts.append({"speaker": "women01", "message": reporter_message})
interviwee_response = interviwee.chat(reporter_message + "簡潔に答えてください!")
interviwee_message = interviwee_response.response
radio_manuscripts.append({"speaker": "man01", "message": interviwee_message})
radio_manuscripts.append(
{
"speaker": "women01",
"message": f"ありがとうございます。そろそろお時間です!それでは、今日は{first_theme}お話を伺いました。ありがとうございました。",
}
)
radio_manuscripts.append({"speaker": "man01", "message": "ありがとうございました。"})
ラジオ音声生成部分
まずは一つの文章から音声を生成する関数を作成します。
今回は2人の話者がいるので、二つの違う人の声で生成できるようにする必要があります。
下記の関数ではGoogleのText2SpeechのAPIを利用して音声合成を行い、音声データを返すという内容になっています。
from google.cloud import texttospeech
def make_audio_from_message(message, speaker="women01"):
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=message)
name = "ja-JP-Neural2-C" # 男性の声
if speaker == "women01":
name = "ja-JP-Neural2-B" # 女性の声
voice = texttospeech.VoiceSelectionParams(language_code="ja-JP", name=name)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
mp3_content = io.BytesIO(response.audio_content)
return mp3_content
次に上記の音声を一つの音声データに結合させるコードを書きます。
というのも、1人の話者だけであれば上記の関数のみでよいのですが、今回は2人の話者が交互に会話する形式ですので、個々に音声を生成させて、それらを結合しなければならないのです。
今回はPydubというライブラリを利用して音声を一つに結合させるようにしました。
from pydub import AudioSegment
combined = AudioSegment.empty()
for manuscript in radio_manuscripts:
mp3_binary = make_audio_from_message(
manuscript["message"], speaker=manuscript["speaker"]
)
combined += AudioSegment.from_mp3(mp3_binary)
combined.export("radio.mp3", format="mp3")
# APIとして使う際に音声はサーバーに保存したくないのでBytesIOを使用する
# response_content = io.BytesIO()
# combined.export(response_content, format="mp3")
まとめ
(終始雑なコードですみません。。。)
今回は、AIを利用して、PDFを元にラジオを生成させてみました。応用として、WebページなどのPDF以外のソースからラジオを生成させたり、3人以上の登場人物による音声コンテンツの生成などがありそうです👀
ぜひ、色々改造しておもしろコンテンツをAIに生成させてみてください笑
今後も生成AIを使ったミニアプリなどを開発していきますので、良かったらX(Twitter)のフォローお願いします!
おまけ
生成AI高専人会という生成AIに興味がある(元)高専生のコミュニティのイベントでLTした時のスライドを載せておきます!(開発する上で発生した問題などにも触れています)
Discussion