「PromQL を駆使して Grafana で可視化したい!」SLO駆動なSRE活動に向けた取り組み パート3
Agenda
- 登場人物
- 想定読者
- 前回の内容
- SLI/SLO 定義・PromQL 苦労話
登場人物
- 藤崎:@kyohei_fujisaki
- 増田:@hiro8ma
想定読者
- SRE に取り組んでいる、または取り組もうとしている方
前回の内容
増田)前回は、SLI/SLO を定義するために取り組んだこと を紹介しました。今回は、実際に定義した SLI/SLO と、その時の苦労話について振り返りながら紹介していきましょう。
藤崎) そうですね!振り返っていきましょかーー!
SLI/SLO 定義・PromQL 苦労話
増田) SLI/SLO の定義をするにあたり、最初にやったのは一般的な SLI/SLO や、他社での事例の調査からでした。
藤崎) パート1 で SLI/SLO とはなにかを深堀りした際に、一般的なものは調査済みだったので、特に他社事例を重点的に調べましたね。
増田) ですね。他社事例を調査しつつ、Magic Moment Playbook に当てはめるとどうなるか、ということを考えまずは SLI を立てていきました。
藤崎) 最初はサービス稼働率や、リクエストレイテンシー、エラーレートなど、一般的なものを中心にしましたね。
増田) SLO を決めるにあたり、そもそも現状の数字がわからないことには目標を決められないということで、まずは現状を把握することに着手していきました。
藤崎) パート2 で紹介したように、サービスメッシュを構築して SLO をたてるために必要なメトリクスを取得できるようにし、 Grafana で可視化をしたんですよね。
増田) Grafana での可視化はひたすら PromQL を書いていったわけですが、ここがすごく苦労しましたね。
藤崎) そうですね。そもそも PromQL の前提知識がなくキャッチアップするところから始めていきました。
増田) よく使われる rate 関数なども irate 関数との違いは何かなど1つ1つドキュメントを逆引きして理解していきましたね。
藤崎) istio で取得できるメトリクス のそれぞれが何を表し、どのラベルが何を対象にしているのかを把握しどれを可視化に使うべきなのかなど PromQL を書く前段の作業も多かったですよね。
増田) 実際に PromQL を書き出してからも、リクエストレイテンシは外れ値を除外するためにパーセンタイルでのモニタリングが必要で、 histogram_quantile 関数を使用し99パーセンタイルの場合は下記のように PromQL を定義しました。
histogram_quantile(0.99, sum(rate(istio_request_duration_milliseconds_bucket{destination_service_namespace="my-namespace"}[5m])) by (le, destination_service_namespace))
藤崎) rate や sum の組み合わせで算出する PromQL には特に苦労しました。ステータスコード別にエラーレートを出すために以下のような PromQL を書いていたのですが、これだと正確に取得できていませんでした。
sum by(source_workload,destination_workload,response_code,request_protocol) (rate(istio_requests_total{kubernetes_namespace="my-namespace",response_code=~"5..",request_protocol="http"}[5m]))
/
sum by(source_workload,destination_workload,response_code,request_protocol) (rate(istio_requests_total{kubernetes_namespace="my-namespace",request_protocol="http"}[5m]))
分母は総リクエスト数のはずが、そもそも sum by に response_code を入れていたという単純なミスもあったのですが、 response_code を sum by から抜くだけではだめでした。
この PromQL の結果は N:N になりますが、分母と分子の sum by のグルーピングの仕方が異なります。この場合、分母に ignoring(response_code) group_left を付けて上げないと、同じグループ同士での計算をしてくれないんですよね。
sum by(source_workload,destination_workload,response_code,request_protocol) (rate(istio_requests_total{kubernetes_namespace="my-namespace",response_code=~"5..",request_protocol="http"}[5m]))
/
ignoring(response_code) group_left sum by(source_workload,destination_workload,request_protocol) (rate(istio_requests_total{kubernetes_namespace="my-namespace",request_protocol="http"}[5m]))
増田) これはなかなか気づけず、解決にも試行錯誤が必要でした。でも、ちゃんと解決できてよかったですね!
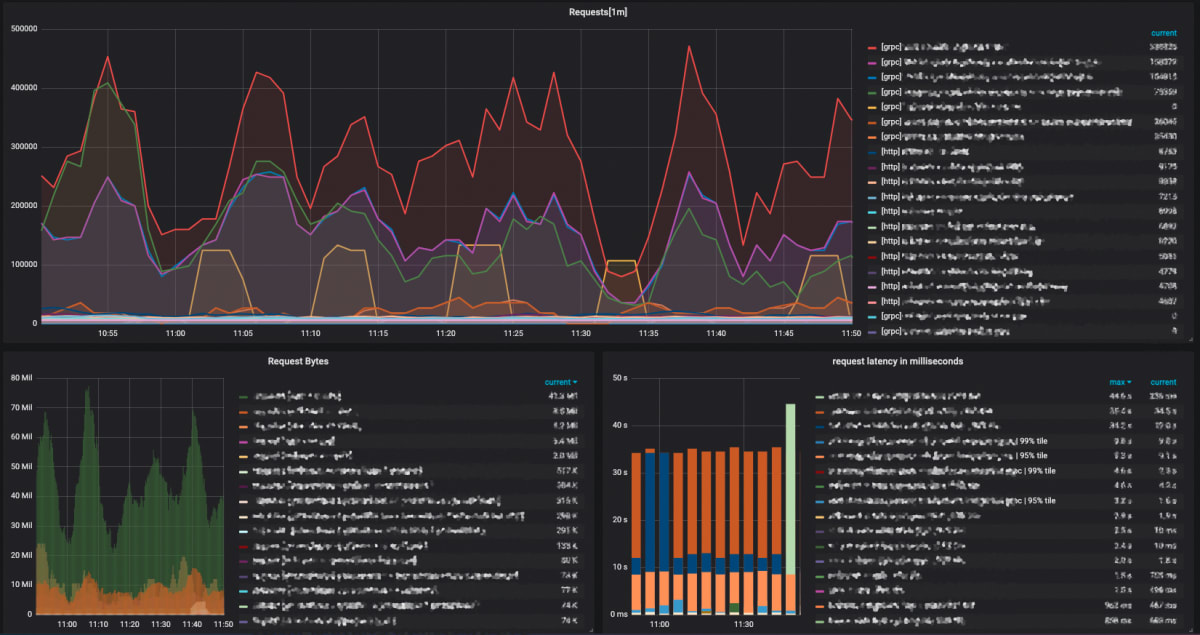
Grafanaで可視化したダッシュボードの一例
藤崎) 解決できてよかったのですが、同時に新たな問題が出てきましたよね。エラーレートに対するアラート設定によって、アラート通知の頻度が上がり、アラートに対する意識が希薄になっていってしまったんですよね。
増田) 次の記事ではアラート通知をバーンレートに基づいたエラーバジェットでの運用に切り替えてアラートの質を向上させた経緯をご紹介できればと思います。
藤崎) あ、最後に! Magic Moment では、サービスの根本から一緒に考えて開発してくださる方を募集しています!
Discussion