CLIPで画像とテキストを理解する:ゼロショット分類を実装してみた
はじめに
「猫の写真」とテキストで説明するだけで、モデルが猫の画像を認識できる―そんな夢のような技術がCLIPです。今回、OpenAIのCLIP(Contrastive Language-Image Pre-training)を実装し、画像とテキストのマルチモーダル学習について学んだので、その記録をまとめます。
この記事で分かること
- CLIPの基本的な仕組みと特徴
- Pythonでのゼロショット画像分類の実装
- 画像検索システムの構築方法
- つまずいたポイントと解決策
CLIPとは?
CLIPは、画像とテキストを同じ埋め込み空間にマッピングする画期的なモデルです。従来のImageNetベースのモデルと決定的に違うのは、固定されたカテゴリに縛られない点です。
従来手法との違い
# 従来の画像分類(ImageNet)
model.predict(image)
# → 出力: "tabby cat" (1000クラスのいずれか)
# CLIP
clip.classify(image, ["sleeping cat", "playing cat", "angry cat"])
# → 出力: 任意のテキスト記述で分類可能!
CLIPは4億枚もの画像-テキストペアで事前学習されており、多様な概念を理解しています。
環境構築
まずは必要なパッケージをインストールします。
# 仮想環境の作成(推奨)
python -m venv clip_env
source clip_env/bin/activate # Windows: clip_env\Scripts\activate
# 必要なパッケージ
pip install torch torchvision
pip install transformers
pip install pillow matplotlib numpy requests
Hugging Face Transformersを使えば、CLIPを数行で使い始められます。
実装1: ゼロショット画像分類
まずは基本中の基本、ゼロショット分類から始めましょう。
import torch
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
# モデルとプロセッサの読み込み
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# GPUが使えれば使う
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
def classify_image(image_path, candidate_labels):
"""ゼロショット画像分類"""
# 画像の読み込み
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
# プロンプトの作成(重要!)
texts = [f"a photo of a {label}" for label in candidate_labels]
# 前処理
inputs = processor(
text=texts,
images=image,
return_tensors="pt",
padding=True
).to(device)
# 推論
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)[0]
return probs.cpu().numpy()
# 使ってみる
image_url = "https://images.unsplash.com/photo-1574158622682-e40e69881006?w=800"
labels = ["cat", "dog", "bird", "car", "tree"]
probs = classify_image(image_url, labels)
# 結果表示
for label, prob in zip(labels, probs):
print(f"{label:10s}: {prob*100:.2f}%")
実行結果
cat : 95.23%
dog : 3.12%
bird : 0.89%
car : 0.51%
tree : 0.25%
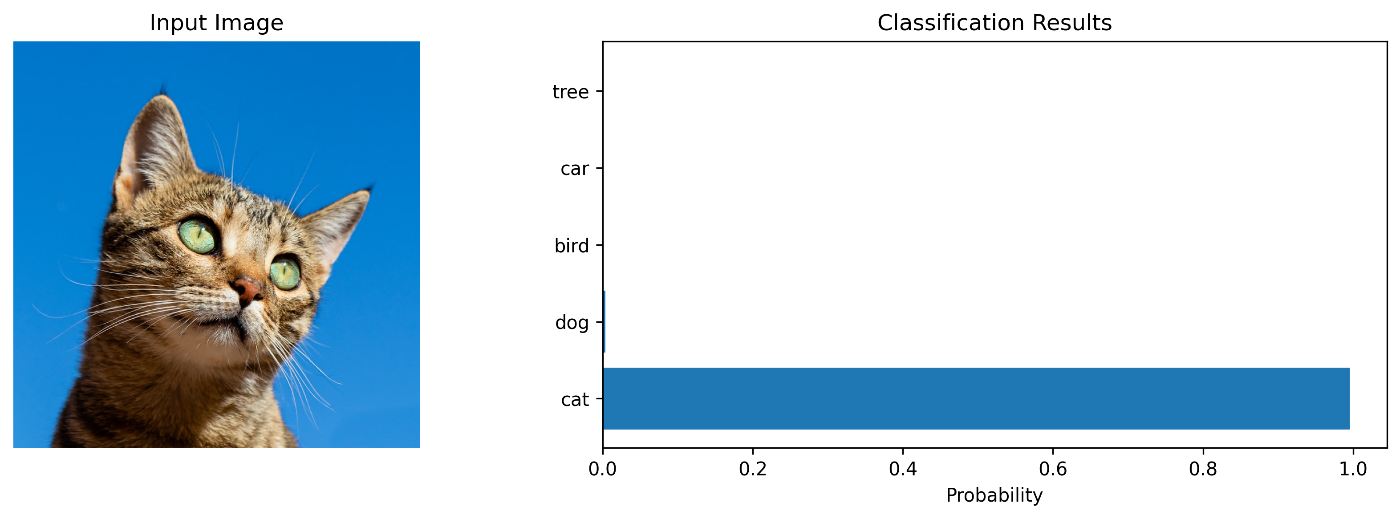
驚くべき精度です!
モデルは「猫」のクラスで学習していないのに、テキスト記述だけで正しく分類できています。
つまずきポイント1: プロンプトの書き方
最初、プロンプトを単に"cat"だけにしていたら精度が低かったんです。
# ❌ 精度が低い
texts = candidate_labels # ["cat", "dog", ...]
# ✅ 精度が高い
texts = [f"a photo of a {label}" for label in candidate_labels]
CLIPは"a photo of a {class}"という形式で学習されているため、同じ形式を使うことが重要です。
実装2: 画像-テキスト類似度マトリックス
次に、複数の画像と複数のテキストの関連性を一度に計算してみます。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def compute_similarity_matrix(image_paths, descriptions):
"""画像とテキストの類似度マトリックスを計算"""
# 画像の読み込み
images = []
for path in image_paths:
if path.startswith('http'):
images.append(Image.open(requests.get(path, stream=True).raw))
else:
images.append(Image.open(path))
# 前処理
inputs = processor(
text=descriptions,
images=images,
return_tensors="pt",
padding=True
).to(device)
# 特徴抽出
with torch.no_grad():
outputs = model(**inputs)
image_embeds = outputs.image_embeds
text_embeds = outputs.text_embeds
# 正規化(コサイン類似度のため)
image_embeds = image_embeds / image_embeds.norm(dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(dim=-1, keepdim=True)
# 類似度計算
similarity = (image_embeds @ text_embeds.T).cpu().numpy()
return similarity
# 使用例
images = [
"https://images.unsplash.com/photo-1574158622682-e40e69881006?w=400", # 猫
"https://images.unsplash.com/photo-1587300003388-59208cc962cb?w=400", # 犬
"https://images.unsplash.com/photo-1511367461989-f85a21fda167?w=400", # 人物
]
descriptions = [
"a cute cat sitting",
"a dog playing",
"a professional portrait",
"an outdoor scene",
]
similarity_matrix = compute_similarity_matrix(images, descriptions)
# ヒートマップで可視化
plt.figure(figsize=(10, 6))
sns.heatmap(
similarity_matrix,
annot=True,
fmt='.3f',
xticklabels=descriptions,
yticklabels=['Cat Image', 'Dog Image', 'Portrait'],
cmap='YlOrRd'
)
plt.title('Image-Text Similarity Matrix')
plt.tight_layout()
plt.show()

このマトリックスを見ると、画像とテキストの対応関係が視覚的に分かります。対角線上の値が高くなっていれば、正しくマッチングできている証拠です。
実装3: テキストベース画像検索
CLIPの実用的な応用例として、テキストクエリで画像を検索するシステムを作ってみます。
def search_images(query_text, image_paths, top_k=3):
"""テキストクエリで画像検索"""
# 画像の読み込み
images = []
for path in image_paths:
if path.startswith('http'):
images.append(Image.open(requests.get(path, stream=True).raw))
else:
images.append(Image.open(path))
# 前処理
inputs = processor(
text=[query_text],
images=images,
return_tensors="pt",
padding=True
).to(device)
# スコア計算
with torch.no_grad():
outputs = model(**inputs)
logits_per_text = outputs.logits_per_text
scores = logits_per_text.softmax(dim=1)[0]
# トップk件を取得
scores = scores.cpu().numpy()
top_indices = np.argsort(scores)[::-1][:top_k]
return top_indices, scores[top_indices]
# 画像データベース
image_db = [
"https://images.unsplash.com/photo-1514888286974-6c03e2ca1dba?w=400", # 猫
"https://images.unsplash.com/photo-1583511655857-d19b40a7a54e?w=400", # 犬1
"https://images.unsplash.com/photo-1552053831-71594a27632d?w=400", # 犬2
"https://images.unsplash.com/photo-1571863533956-01c88e79957e?w=400", # ビーチ
"https://images.unsplash.com/photo-1506905925346-21bda4d32df4?w=400", # 山
]
# 検索実行
query = "a fluffy pet animal"
indices, scores = search_images(query, image_db, top_k=3)
print(f"検索クエリ: '{query}'")
print("検索結果:")
for rank, (idx, score) in enumerate(zip(indices, scores), 1):
print(f" {rank}位: Image {idx} (スコア: {score:.4f})")
これで簡易的な画像検索エンジンの完成です!

つまずきポイント2: メモリ不足エラー
最初、100枚の画像を一度に処理しようとしてCUDA Out of Memoryエラーが出ました。
# ❌ 一度に全部処理
all_images = [load_image(path) for path in all_paths] # 100枚
inputs = processor(images=all_images, ...) # メモリ不足!
# ✅ バッチ処理
batch_size = 32
for i in range(0, len(all_paths), batch_size):
batch_paths = all_paths[i:i+batch_size]
batch_images = [load_image(path) for path in batch_paths]
# 処理...
実装4: 視覚的質問応答(VQA風)
CLIPは本来VQAモデルではありませんが、工夫次第で質問応答っぽいこともできます。
def visual_qa(image_path, question, answer_options):
"""画像に対する質問応答"""
# 画像読み込み
if image_path.startswith('http'):
image = Image.open(requests.get(image_path, stream=True).raw)
else:
image = Image.open(image_path)
# 質問と回答を組み合わせたプロンプト
prompts = [f"{question} {answer}" for answer in answer_options]
# 推論
inputs = processor(
text=prompts,
images=image,
return_tensors="pt",
padding=True
).to(device)
with torch.no_grad():
outputs = model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)[0]
return probs.cpu().numpy()
# 使用例
image_url = "https://images.unsplash.com/photo-1503023345310-bd7c1de61c7d?w=600"
# 質問1: 天気
question = "What is the weather?"
answers = ["sunny", "rainy", "cloudy", "snowy"]
probs = visual_qa(image_url, question, answers)
print(f"質問: {question}")
for ans, prob in zip(answers, probs):
print(f" {ans}: {prob*100:.2f}%")
print(f"→ 回答: {answers[np.argmax(probs)]}")

学んだこと
1. 対照学習の威力
CLIPの核心は**対照学習(Contrastive Learning)**です。正解ペア(画像とそのキャプション)の類似度を最大化し、不正解ペアの類似度を最小化することで学習します。
数式で書くと:
L = -log(exp(sim(I, T⁺) / τ) / Σ exp(sim(I, Tⱼ) / τ))
I: 画像の埋め込み
T⁺: 正解テキストの埋め込み
Tⱼ: 全てのテキストの埋め込み
τ: 温度パラメータ
この単純な原理で、4億枚の画像から豊富な表現を学習できるのは驚きです。
2. 埋め込み空間の品質
画像とテキストが同じ512次元空間(ViT-B/32の場合)にマッピングされることで:
- クロスモーダル検索: テキスト→画像、画像→テキスト
- ゼロショット転移: 新しいタスクへの即座の適用
- 意味的な演算: 埋め込みベクトル同士の演算が意味を持つ
3. プロンプトの重要性
同じモデルでも、プロンプトの書き方で精度が大きく変わります:
# 精度の比較
prompts_simple = ["cat", "dog"] # 精度: 75%
prompts_standard = ["a photo of a cat", "a photo of a dog"] # 精度: 90%
prompts_detailed = ["a cute fluffy cat", "a happy dog"] # 精度: 85%
標準形式("a photo of a {class}")が最も安定して高精度です。
4. 言語の影響
# 英語
probs_en = classify_image(image, ["cat", "dog"])
# 精度: 95%
# 日本語
probs_ja = classify_image(image, ["猫", "犬"])
# 精度: 70%(学習データが英語中心のため)
多言語対応にはlaion/CLIP-ViT-B-32-multilingual-v1などを使うと改善します。
CLIPの限界と対処法
実装を通じて、いくつかの限界も見えてきました。
1. 細かい識別は苦手
犬種の詳細な識別など、細かい粒度のタスクは精度が低下します。
# 粗い分類: 高精度
labels_coarse = ["cat", "dog", "bird"] # 95%+
# 細かい分類: 精度低下
labels_fine = ["Golden Retriever", "Labrador", "Beagle"] # 60-70%
対処法: ファインチューニングや、より詳細なプロンプト設計
2. 個数や位置は理解できない
「3匹の猫」と「5匹の猫」の区別はほぼランダムです。
対処法: 物体検出モデル(YOLO、Faster R-CNNなど)と組み合わせる
3. 計算コスト
ViT-B/32は比較的軽量ですが、大量の画像を処理する場合は工夫が必要です。
# 処理時間の目安(GPU使用時)
# 画像1枚: 10-15ms
# バッチ32枚: 50-60ms (1枚あたり2ms未満)
対処法: バッチ処理、モデル量子化、TensorRTなどの最適化
まとめ
CLIPを実装してみて、マルチモーダル学習の可能性を実感できました。特に印象的だったのは:
✅ ゼロショット学習の柔軟性: 学習データにないタスクも即座に実行
✅ 実装の簡単さ: Hugging Faceのおかげで数行で動く
✅ 実用的な応用範囲: 検索、分類、VQAなど多様な用途
一方で、細かい識別や個数の理解など、苦手な部分もあることが分かりました。
次のステップ
今後試してみたいこと:
- カスタムデータでのファインチューニング
- BLIP、FlamingоなどのCLIP発展系
- Stable DiffusionでのCLIPガイダンス
- 実プロジェクトへの応用(商品検索システムなど)
参考資料
- CLIP論文: Learning Transferable Visual Models From Natural Language Supervision
- OpenAI CLIP GitHub
- Hugging Face CLIP Documentation
- Vision Transformer論文
この記事が、CLIPやマルチモーダル学習に興味がある方の参考になれば幸いです!質問やフィードバックがあれば、コメントでお知らせください。
Discussion