はじめに
普段、業務で開発・運用をしている中で、CloudWatch Logs上のログを確認することがあります。
AWSリソースのログは分析しやすい形になっているのですが、CloudWatch Agentから転送されるアプリケーション固有のログについては、@messageでしかフィルタリングすることができず、必要な情報を参照しづらいという問題を抱えています。
@messageのログは以下のタブ区切り形式になっています。
key1:value1 key2:value2 ... keyN:valueN
現状の課題
上記のログを分析する際に問題と感じている点は以下の通りです。
-
クエリ作成に時間がかかる
@messageをフィルタする場合、like句で検索するしかなく、正規表現で条件を記述する必要があります。別の観点で分析したい場合、都度正規表現で条件を書かなければならず、分析のハードルとなっています。また、範囲指定などもできません。 -
CloudWatch Logs Insight上で抽出したデータの視認性が低い
@messageが1つの文字列として表示されるため、コンソールの表示幅に収まらず、ログ内容の確認には横スクロールもしくはエクスポートが必要です。欲しい情報がどこにあるのか、自分が想定したデータなのかを確認することに時間がかかっています。 -
ログデータの再利用しづらい
こちらも前述と関連しますが、@messageが1つの文字列になっており、抽出結果をスプレッドシートなどに転記して、自分で列を分割しなければ扱いづらいデータとなっています。
上記の課題を解消するため、CloudWatch Logs Insightのparseを利用して見やすい形式に整形し、@message内のそれぞれの項目で検索できるようにしたいと思います。
CloudWatch Logs Insightsとは
簡単にいうと、Amazon CloudWatch Logsのログデータを検索・分析するためのサービスです。
クエリを実行することでテキストで保存されているログデータを簡単に確認することができます。
parseコマンド
parseを利用すると、@messageから一時的なフィールドを生成することができます。
公式ドキュメントには以下の記載があります。
parseを使用して、ログフィールドからデータを抽出し、クエリで処理できるエフェメラルフィールドを作成します。parseは、ワイルドカードを使用するグロブモードと正規表現の両方をサポートします。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/CWL_QuerySyntax.html
一時的なフィールドにしたい箇所をワールドカード(*)で指定すれば分割できるようです。
やってみる
今回のログデータの場合、以下のような指定で実現できそうです。
parse @message 'key1:* key2:* ... keyN:*' as フィールド名1, フィールド名2, ... , フィールド名N
エフェメラルフィールドに分割してみる
parseでエフェメラルフィールドに分割し、displayで必要なデータだけを取り出してみます。
sort @timestamp desc
| parse @message 'time:* level:* (中略) method:* code:* response_sec:*' as time, level, (中略), method, code, response_sec
| display time, level, method, code, response_sec
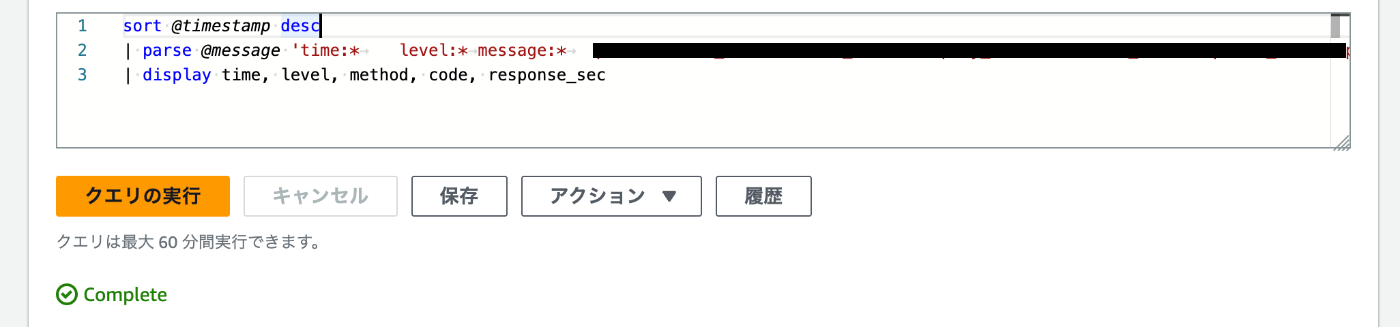

ちゃんとパースした通りのデータが取れました!
エフェメラルフィールドで検索してみる
sort @timestamp desc
| parse @message 'time:* level:* (中略) method:* code:* response_sec:*' as time, level, (中略), method, code, response_sec
| display time, level, method, code, response_sec
| filter code = 401

filterでエフェメラルフィールドの検索もできるようになりました!
結果
課題として挙げていた点を解消することができました。
-
クエリ作成に時間がかかる
フィールドの指定だけになり検索の柔軟性がUP。 - CloudWatch Logs Insight上で抽出したデータの視認性が低い
-
ログデータの再利用しづらい
1つの文字列が各フィールドに分かれたことで表示列が分かれたこと、key:valueのkey部分が除去できたことで視認性、再利用性がUP。
また、「結果をエクスポート」でエクスポートされるデータがスプレッドシートなどで扱いやすくなった。
終わりに
parseを活用することで、今までスプレッドシートなどを駆使する必要のあったログデータの分析が早くできるようになりました。
出来てしまえば簡単だなと思えるのですが、初見では理解できなかったので、私と同じように悩んでいる何方かの参考になれば幸いです。

Discussion