DataTroveによるデータの処理
はじめに
言語モデルの開発において、学習データの前処理は非常に重要です。この記事では、Hugginfaceが開発している Datatrove というライブラリを使用したデータ処理の方法についてまとめます。 具体例を通して DataTrove の基本的な使い方を知る事が目標です。
Datatroveについて
DataTroveのGitHubに
DataTrove is a library to process, filter and deduplicate text data at a very large scale. It provides a set of prebuilt commonly used processing blocks with a framework to easily add custom functionality.
DataTrove processing pipelines are platform-agnostic, running out of the box locally or on a slurm cluster. Its (relatively) low memory usage and multiple step design makes it ideal for large workloads, such as to process an LLM's training data.
Local, remote and other file systems are supported through fsspec.
とあるように、DataTrove はデータのフィルタリングや重複排除を行うことができます。テキスト前処理で一般的に用いられる処理は予め用意されています。それらを簡単かつ直感的に処理を行えるようになっている点が、DataTroveの特徴です。
インストール
pip を用いてインストールすることができます。
pip install datatrove[FLAVOUR]
[FLAVOUR] の部分にオプションを入れるとより多くの機能を使えるようになります。詳細は公式ドキュメントを参照してください。
今回扱う例に関しては [FLAVOUR] には processing を指定します。
使用例
具体的な処理を行いながら DataTrove の使用方法についてみていきます。
使用するデータ, 目標
今回はWikipediaのダンプデータを処理してみます。こちらのページ から手に入れられるWikipediaのダンプデータのうち、jawiki-20240401-pages-articles-multistream1.xml-p1p114794.bz2 を用います。
ここにはWikipediaの記事のデータが入っているので、今回はこの中から
- 見出しに「情報」という文言を含む
- 記事のbyte数が5000byte 以上
であるものの抽出を目標とします。
データの前処理
ダウンロードしたデータをDataTroveが直接扱えるjson形式へと前処理をします。
前処理コード
import xmltodict
import bz2
import json
DUMP_FILE="testdata.bz2"
with bz2.open(DUMP_FILE,'rb') as file,open('inputdata.json','w') as wile:
xml_data = file.read()
json_data = xmltodict.parse(xml_data)["mediawiki"]["page"]
for line in json_data:
wile.write(json.dumps(line,indent=None,ensure_ascii=False).replace('\n','')+'\n')
ここでの注意点として、一行に一データとなるように前処理をしてください。一つのデータが複数行にまたがっていると DataTrove の実行時に warning が出て正しく処理されません。
実行方法
from datatrove.executor.local import LocalPipelineExecutor
from datatrove.pipeline.filters import (
LambdaFilter,
RegexFilter,
)
from datatrove.pipeline.readers import JsonlReader
from datatrove.pipeline.writers import JsonlWriter
MAIN_OUTPUT_PATH = "output_folder"
pipeline = [
JsonlReader(data_folder="inputdata.json", text_key="title"),
RegexFilter(
regex_exp=r"^(?!.*情報).*$",
exclusion_writer=JsonlWriter(f"{MAIN_OUTPUT_PATH}/removed/regex"),
),
LambdaFilter(
filter_function=lambda doc: int(doc.metadata["revision"]["text"]["@bytes"])
>= 5000,
exclusion_writer=JsonlWriter(
f"{MAIN_OUTPUT_PATH}/removoed/lambda/",
output_filename="" + "/${rank}.jsonl.gz",
),
),
JsonlWriter(f"{MAIN_OUTPUT_PATH}/output"),
]
executor = LocalPipelineExecutor(pipeline)
executor.run()
プログラムの大まかな構成としては、pipelineに処理させる内容を書き、それをexecutorで実行するという流れです。
今回の場合、
- JsonReaderでデータを読み込む
- データのフォルダーを指定
- データの見出しに相当するキーとして 'title' を指定
- RegexFilterで正規表現を用いたフィルタリングをする
- 正規表現として '情報' を含まない表現を指定
- exclusion_writerで、フィルターではじかれたものを別途出力
- LambdaFilterでラムダ式を用いたフィルタリングをする
- filter_functionにデータの@byteの項目が5000以上ならTrueを返す関数を書く
- exclusion_writerで、フィルターではじかれたものを別途出力
- JsonWriterで出力する
- データのフォルダーを指定
という流れとなっています。
他の処理を行いたい場合はそれに応じてpipelineの中身を書き換えることになります。既に用意されている処理を行う場合は、Datatroveのgithub上のソースコード中に挙動やオプションの付け方がコメントアウトされています。
実行結果
上述のpythonファイルを実行すると、ターミナルに以下のような画面が順次出ます。
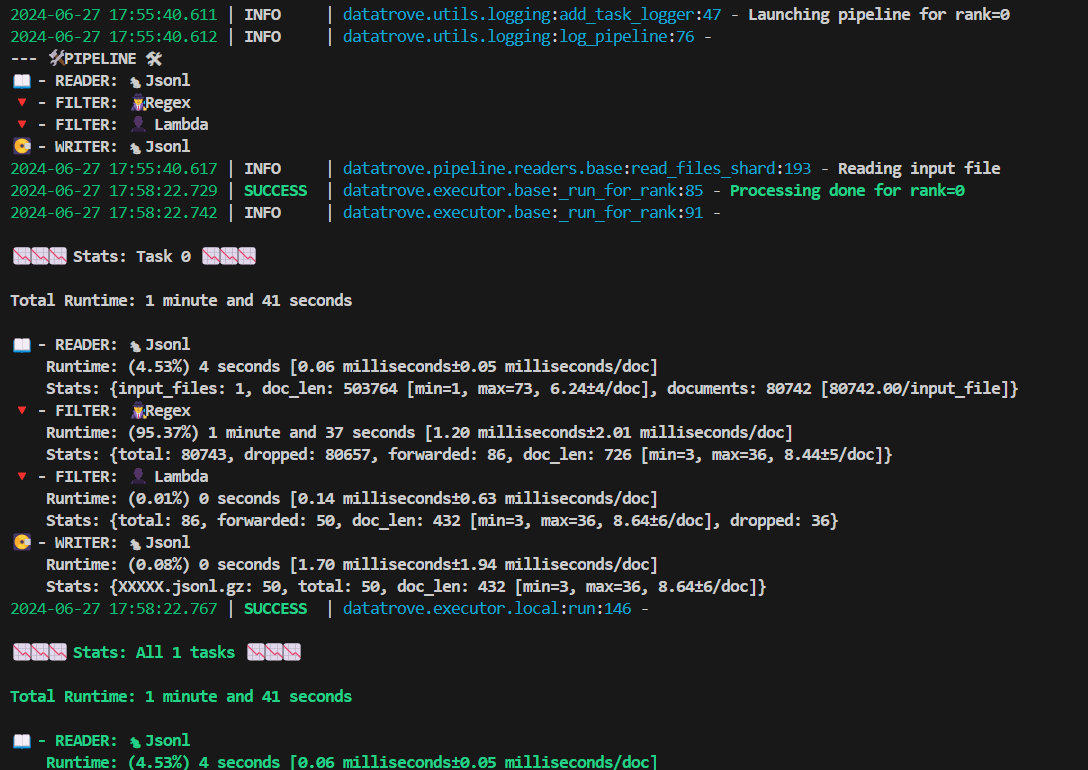
実行時のターミナルの様子
実行が終わると、出力先に指定したフォルダーに実行結果がでます。
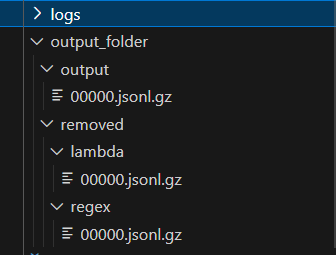
実行後のフォルダー構成
それぞれの実行結果はbzip形式に圧縮されています。
今回のコードでは output_folder/output に出力するようにしていました。この中の 00000.jsonl.gz の中を見ると、以下のようになっており、タイトルに「情報」が含まれている記事が抽出できているのが分かります。
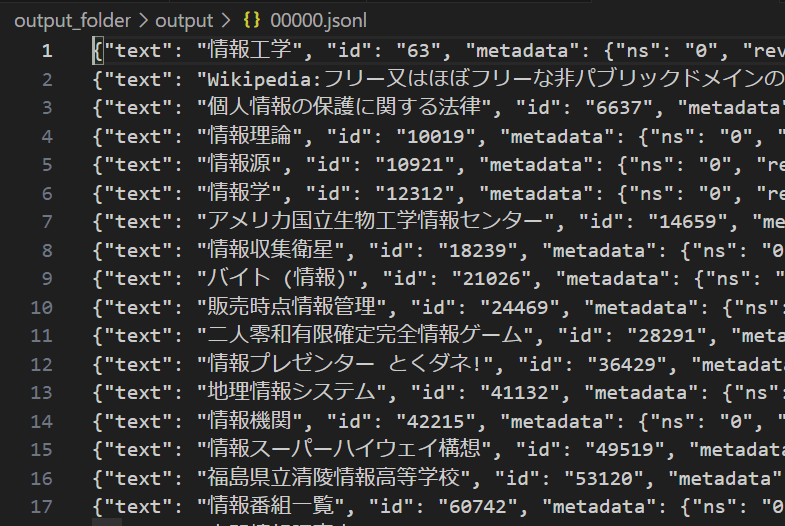
出力結果
00000.jsonl.gz(各行最初の30文字を表示)
{"text": "情報工学", "id": "63", "
{"text": "Wikipedia:フリー又はほぼフリー
{"text": "個人情報の保護に関する法律", "id"
{"text": "情報理論", "id": "10019"
{"text": "情報源", "id": "10921",
{"text": "情報学", "id": "12312",
{"text": "アメリカ国立生物工学情報センター", "
{"text": "情報収集衛星", "id": "1823
{"text": "バイト (情報)", "id": "21
{"text": "販売時点情報管理", "id": "24
{"text": "二人零和有限確定完全情報ゲーム", "i
{"text": "情報プレゼンター とくダネ!", "id
{"text": "地理情報システム", "id": "41
{"text": "情報機関", "id": "42215"
{"text": "情報スーパーハイウェイ構想", "id"
{"text": "福島県立清陵情報高等学校", "id":
{"text": "情報番組一覧", "id": "6074
{"text": "内閣情報調査室", "id": "618
{"text": "秘密情報部", "id": "61895
{"text": "個人情報", "id": "62635"
{"text": "ミロク情報サービス", "id": "6
{"text": "情報革命", "id": "68518"
{"text": "情報技術", "id": "68519"
{"text": "情報格差", "id": "68521"
{"text": "情報リテラシー", "id": "685
{"text": "独占!!スポーツ情報", "id": "
{"text": "行政機関の保有する情報の公開に関する法律
{"text": "情報通信政策局", "id": "791
{"text": "携帯情報端末", "id": "7933
{"text": "電子情報技術産業協会", "id": "
{"text": "情報デスクToday", "id": "
{"text": "情報学部", "id": "84644"
{"text": "情報学研究科", "id": "8481
{"text": "個人情報保護法関連五法", "id":
{"text": "情報公開・個人情報保護審査会設置法",
{"text": "京都情報大学院大学", "id": "8
{"text": "ザ!情報ツウ", "id": "9069
{"text": "Template:基礎情報 国", "i
{"text": "情報 (教科)", "id": "969
{"text": "個人情報漏洩", "id": "9873
{"text": "新車情報", "id": "99354"
{"text": "情報セキュリティ大学院大学", "id"
{"text": "情報倫理", "id": "101774
{"text": "図書館情報学", "id": "1028
{"text": "図書館情報大学", "id": "102
{"text": "情報教育", "id": "103716
{"text": "テレビ情報誌", "id": "1107
{"text": "歌謡曲ヒット情報", "id": "11
{"text": "600 こちら情報部", "id": "
{"text": "追跡 (情報番組)", "id": "1
その他、removed/lambda/00000.jsonl.gz には LambdaFilter で除外された項目が、removed/regex/00000.jsonl.gz には RegexFilter で除外された項目が入っているはずです。また、logsファイルからは実行ログの他、各出力ファイルの簡単な統計をみることもできます。
統計情報の例
統計情報の一部を抜粋
{
"name": "\ud83d\udd3b - FILTER: \ud83d\udd75 Regex",
"time_stats": {
"total": 104.81023360894233,
"n": 80736,
"mean": 0.0012981846215931049,
"variance": 4.435611947746242e-06,
"std_dev": 0.002106089254458662,
"min": 4.5589995352202095e-06,
"max": 0.06606043000010686,
"total_human": "1 minute and 44 seconds",
"mean_human": "1.30 milliseconds",
"std_dev_human": "2.11 milliseconds",
"min_human": "0.01 milliseconds",
"max_human": "66.06 milliseconds"
},
"stats": {
"total": 80736,
"dropped": 80650,
"forwarded": 86,
"doc_len": {
"total": 726,
"n": 86,
"mean": 8.44186046511628,
"variance": 26.20246238030095,
"std_dev": 5.11883408407627,
"min": 3,
"max": 36
}
}
},
各処理の所要時間や、処理項目数、処理がフィルターの場合フィルタリングされた項目数等の情報が残ります。
カスタムブロックについて
前節の例では, 既存の機能を用いて処理を行いました。DataTroveではこれに加えて、処理のブロックを簡単に自作することができます。
例
前節の例にカスタムブロックを追加します。
以下のカスタムブロックは記事タイトルをナンバリングに置き換え、ナンバリングと元の記事名の対応を別ファイルに出力するものです。
from datatrove.pipeline.base import PipelineStep
from datatrove.data import DocumentsPipeline
from datatrove.io import DataFolderLike, get_datafolder
class Numbering_title(PipelineStep):
def __init__(self, some_folder: DataFolderLike):
super().__init__()
self.some_folder = get_datafolder(some_folder)
def run(self, data: DocumentsPipeline, rank: int = 0, world_size: int = 1) -> DocumentsPipeline:
article_name=[]
article_counter=0
for doc in data:
with self.track_time():
article_name.append(f"article {article_counter:05}: "+doc.text)
doc.text = f"article {article_counter:05}"
article_counter+=1
yield doc
with self.some_folder.open("article_name", "wt") as f:
f.write('\n'.join(article_name))
カスタムブロックを作った場合も pipeline で呼び出すことで処理に追加させることができます。フィルタリング処理を終えた後の部分に今回追加する Numbering_title を呼びます。
pipeline = [
JsonlReader(data_folder="inputdata.json", text_key="title"),
RegexFilter(
regex_exp=r"^(?!.*情報).*$",
exclusion_writer=JsonlWriter(f"{MAIN_OUTPUT_PATH}/removed/regex"),
),
LambdaFilter(
filter_function=lambda doc: int(doc.metadata["revision"]["text"]["@bytes"])
>= 5000,
exclusion_writer=JsonlWriter(
f"{MAIN_OUTPUT_PATH}/removed/lambda/",
output_filename="" + "/${rank}.jsonl.gz",
),
),
Numbering_title(f"{MAIN_OUTPUT_PATH}/additional_output"),
JsonlWriter(f"{MAIN_OUTPUT_PATH}/output"),
]
すると、先ほどの出力結果の記事名がナンバリングされたものに変わり、 additional_output フォルダーには追加でナンバリングと記事名の対応が出力されました。
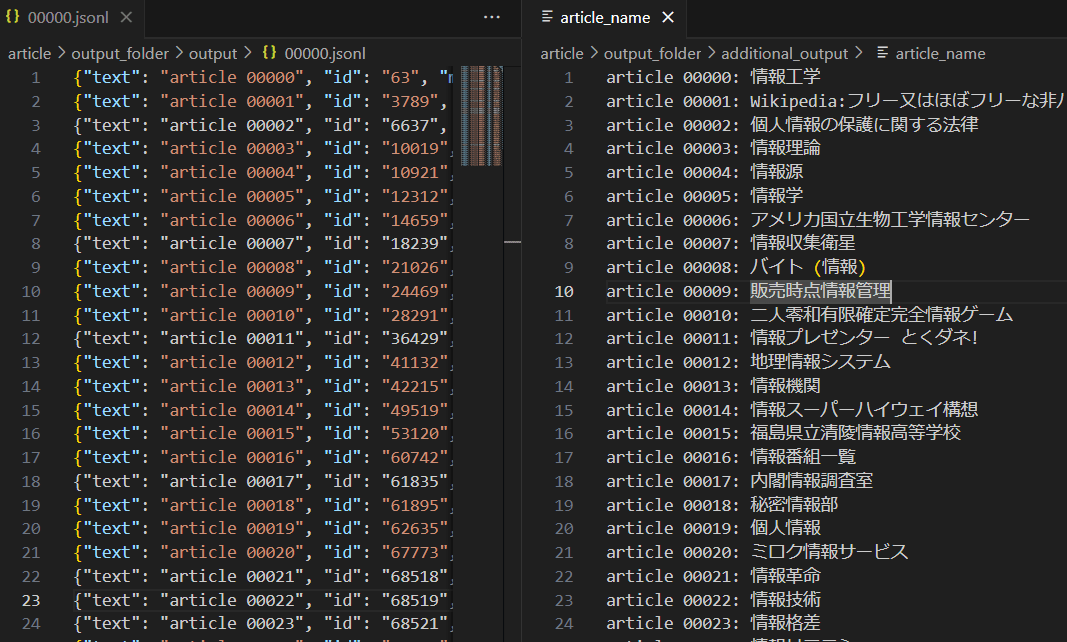
実行結果
終わりに
本記事ではDataTroveの使い方を具体例を通して見てきました。今回扱ったのはDataTroveのごく基本的な部分です。既に用意された処理blockも数多くある他、 customblock を作ることでより柔軟にな処理にも対応できます。これらを組み合わせることで目的に応じて様々な使い方が出来そうです。
参考文献
- Hugging Face. DataTrove.
- Wikimedia Foundation. jawiki dump progress on 20240401.
- GeeksforGeeks. Python – XML to JSON.

Discussion