OOP・デザインパターン
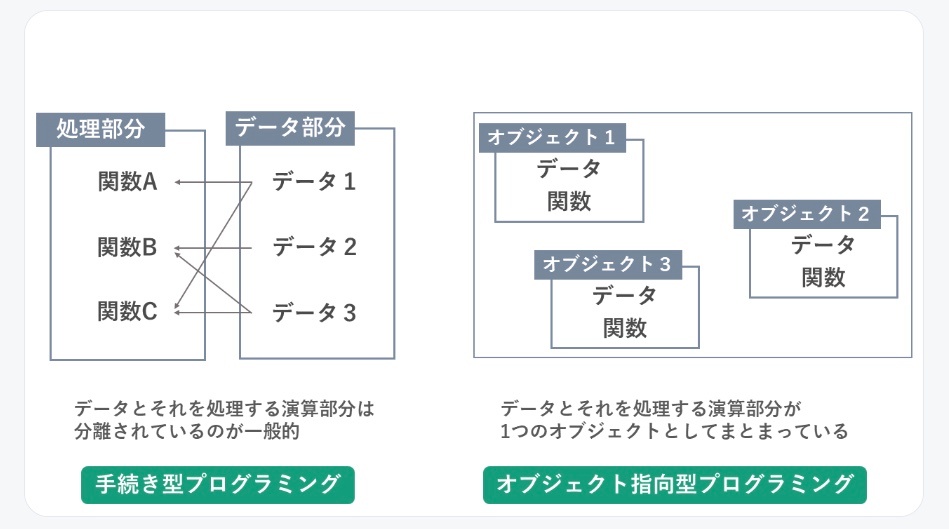
オブジェクト指向プログラミング(OOP)
OOP
プログラム全体をオブジェクト(状態と振る舞いを持つ要素)として設計する手法。
オブジェクトの相互作用によってプログラム全体が動く。
具体的な「もの」をプログラムの中に作り出し、それらが相互作用することで全体としてのプログラムを構築するというイメージ。
OOP では、オブジェクトが持つ状態と挙動のセットを定義し、オブジェクト間の相互作用によってプログラムを構築する。これにより、プログラムの理解や再利用性を高めることが目指されている。
手続き型
手続き型プログラミングは、一連の手順(手続き)に従ってデータを操作するプログラミングの形式。
一つ一つの手続きがデータ(材料)を変換していく。
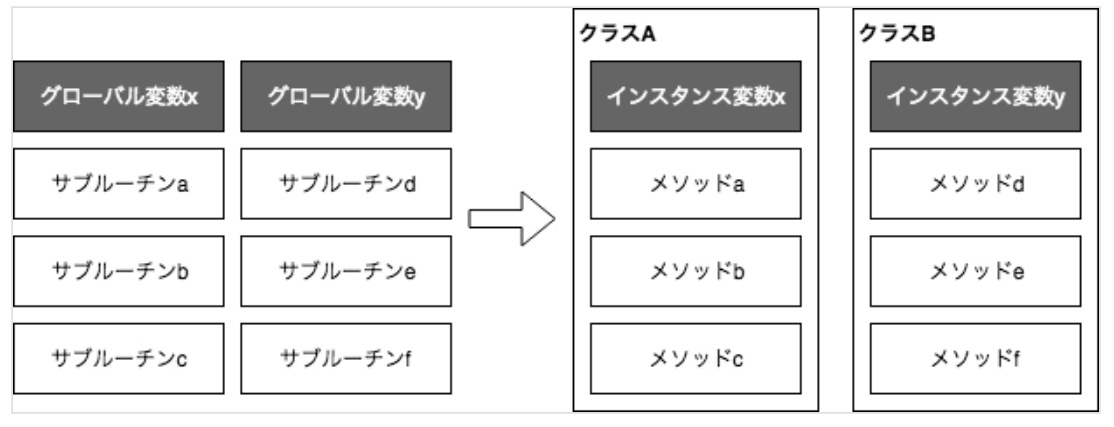
クラスとインスタンス
※https://xtech.nikkei.com/it/article/COLUMN/20070820/279950/ より画像引用
クラス(class)
クラスは、データがどのような形を持つべきかを指定する設計図のようなもの。
クラスはデータ構造の設計図のようなもの。
設計図は、オブジェクトがどのようなメンバ変数(状態)とメソッド(振る舞い)を持つべきかを明確に指定する。
サブルーチン
よく使う処理をまとめたプログラムの部品。関数(function)やメソッド(method)と同じ意味。
※https://qiita.com/tamago3keran/items/bbe92baebf72c89d11a5 より画像引用
インスタンス(instance)
クラスに基づいて作られる具体的なデータをオブジェクト、またはクラスのインスタンス(instance)と言う。オブジェクトを作るという行為を、一般的には「インスタンス化」と呼ばれる。
オブジェクトは他のオブジェクトやプリミティブなデータ型から成り立ち、そのため複合データ構造とも呼ばれる。
整数は 2 進数で表現され、文字列は文字の連続として表現される。
オブジェクトの場合も同様で、その構成要素や構造を理解するためには、そのオブジェクトがどのクラスに属しているかを知る必要がある。
メンバ変数とメソッド
メンバ変数(member variable)
オブジェクトが持つデータを表し、オブジェクトの現在の状態を示す。
メンバ変数にアクセスすることで、オブジェクトの状態を読み取ったり変更したりできる。
クラスのメンバ変数は、そのクラスから作られるオブジェクトが持つデータを定義する部分。
メソッド(method)
オブジェクトが持つ機能、つまりオブジェクトがどのように振る舞うかを定義する。
メソッドを使うことで、オブジェクトの振る舞いを操作できる。
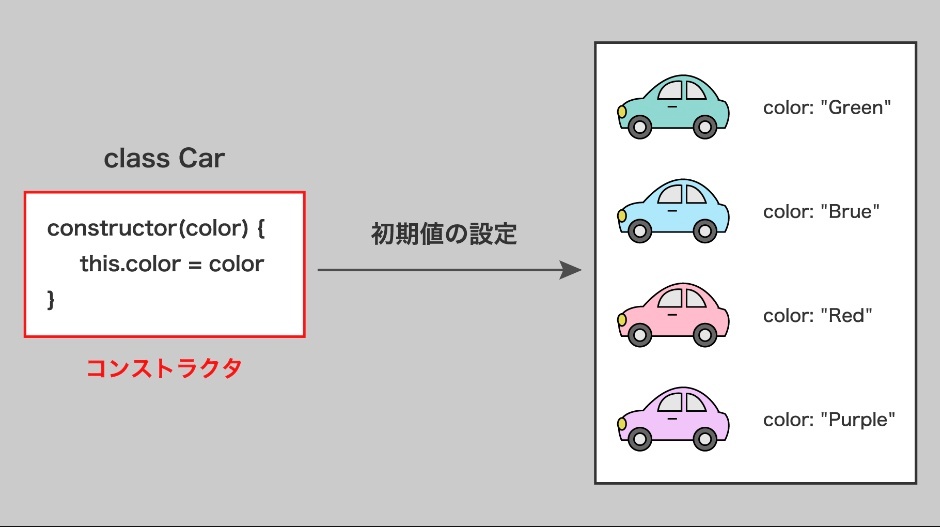
コンストラクタ(constructor)
※https://recursionist.io/dashboard/course/4/lesson/568 より画像引用
オブジェクトを作成する際に自動的に実行される特殊なメソッド
コンストラクタ関数は、新しいオブジェクトの初期化と設定を行なうために使用される。
オブジェクトが作成されるときに実行されるため、クラスのインスタンス化と同時に特定の処理を実行するのに適している。
例えば、オブジェクトのプロパティの初期値を設定したり、必要なリソースを準備したり、他のオブジェクトとの関連性を確立したりするために使用される。
メモリ割り当て
プログラムが実行されると、コンピュータのメモリ(RAM) にデータが格納される。
オブジェクトもメモリ上に確保され、変数はその場所を指し示す。
オブジェクトが作成されるとき、つまり新しいインスタンスが生成されるときには、そのオブジェクトに必要なメモリがヒープから割り当てられる。この割り当てられたメモリは、オブジェクトのデータとメソッドを格納するスペースとして機能する。
オブジェクトが作成された後は、コンストラクタと呼ばれる特殊なメソッドを使ってオブジェクトの初期設定を行ない、それによりオブジェクトの情報を保持する変数にそのオブジェクトを紐付ける。
このオブジェクト変数はオブジェクト自体のデータが直接保存されるのではなく、ヒープ上のオブジェクトの場所への参照(メモリアドレス)を保持する。
コンストラクタは、メモリ割り当て(new)後に初期化処理を実行
オブジェクトが不要になったとき、つまりそのオブジェクトへの全ての参照が失われたとき、そのオブジェクトに割り当てられたメモリはガベージコレクションというプロセスによって自動的に解放される。
これにより、不要なメモリ使用を避け、ヒープメモリの効率的な使用を実現する。
ただし、ガベージコレクションの動作はプログラミング言語や環境によって異なる。
オブジェクト生成からメモリ割り当てまでの流れ
以下、DeepSeek解説から引用
※Java/Pythonの場合
User user = new User("山田太郎", 25);
- ヒープメモリにオブジェクトを確保
・new演算子がヒープ領域にメモリを割り当て
・例:アドレス0x1000にUserオブジェクトのデータ(名前、年齢)を格納 - コンストラクタの実行
・User("山田太郎", 25)が呼び出され、オブジェクトを初期化
・メンバ変数に値を設定(this.name = "山田太郎") - スタックメモリに参照を格納
・変数userにはヒープのアドレス(例:0x1000)が保存される
・スタックフレーム内に4バイト(32bit)or 8バイト(64bit)の参照が記録
メモリ状態のイメージ
[ヒープ] 0x1000: User{name="山田太郎", age=25}
[スタック] user → 0x1000
UML(Unified Modeling Language)
特にクラスを表現する際は、UML クラス図と呼ばれるものを使います。
UML は大きく分けて、スケッチ・設計図・プログラミング言語という 3 つの観点から見ることができる。
例
※https://online.visual-paradigm.com/ja/diagrams/features/uml-tool/ より画像引用
・UMLスケッチはシンプルでわかりやすく、コードの骨組みを示すために使われる。
・UML 設計図では、全ての設計とそれらの具体的な実装が詳述される。
・プログラミング言語の観点からの UMLは、詳細に記述されており、実際の実行可能なプログラムに変換可能。
参考URL
クラス設計
クラスの設計をする際には、自分自身や他の開発者が後でそのクラスを利用することを考えなければならない。つまり、クラスが後に新機能を追加できるような「拡張性」を持つこと、そしてクラスのユーザーに影響を与えずにコードを修正・変更できる「リファクタリング」能力を考慮することが必要になる。
プログラミングにおけるクラス設計では、そのクラスの目的と用途を明確に定義することが非常に重要
クラスの設計段階で、
・どの部分を公開するか(つまり、クラスのユーザーが直接使用する部分)と、
・どの部分を隠蔽するか(つまり、クラスの内部コード)
を決めることが可能(カプセル化)。
その結果、クラスの利用者は、公開されたメソッドや変数を通じてクラスとやりとりし、その内部実装やコードの詳細を気にする必要がなくなる。
これは、クラスの安全性を高め、保守性を向上させ、誤った使用を防ぐ助けとなる。これを達成するための一つの方法として、契約を用いてクラスをブラックボックスとして扱うことがある。
オーバーライド

※https://medium-company.com/オーバーライドとオーバーロードの違い/ より画像引用
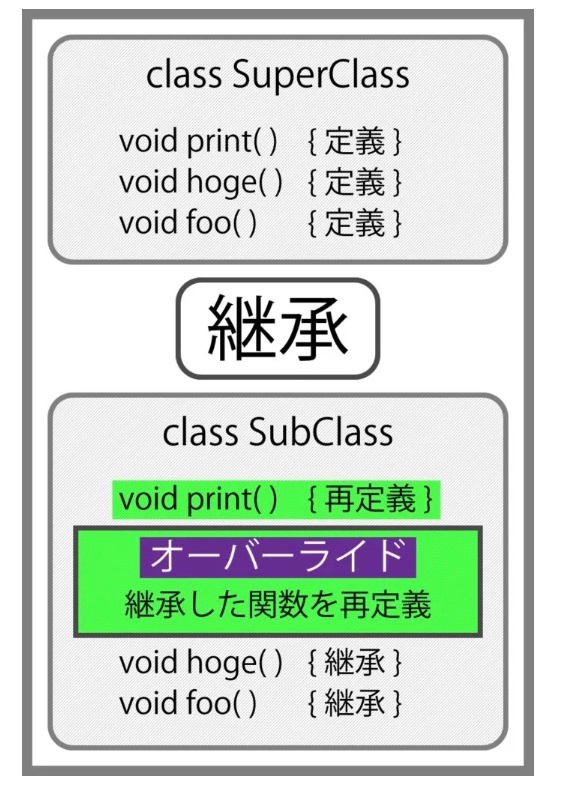
※https://webpia.jp/override-overload/ より画像引用
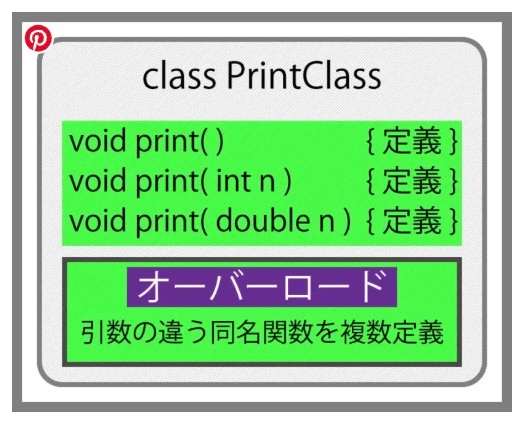
オーバーロード
パッケージ化
イメージ
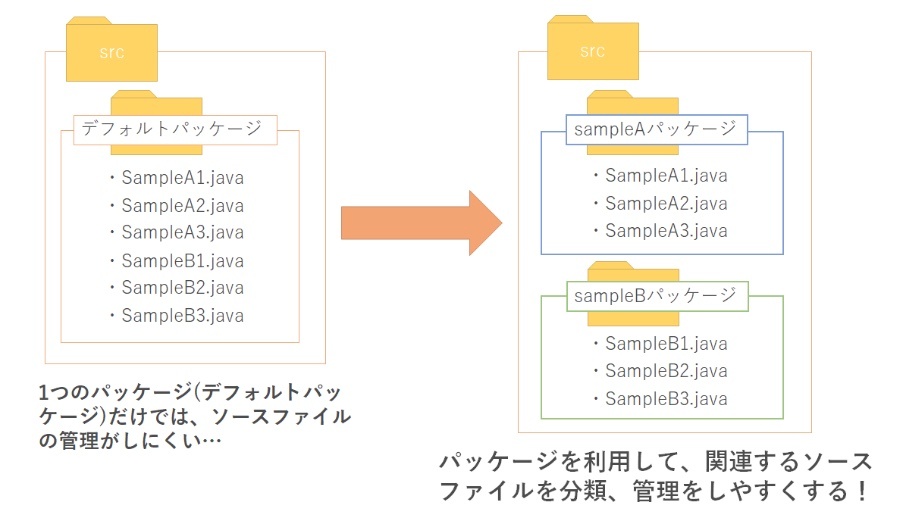
※https://tech.pjin.jp/blog/2021/07/29/java_09_01_use_package/ より画像引用
ファイルをフォルダに分けるイメージ。
toString()
Javaは、System.out.println(data)関数のように、オブジェクトを文字列に変換する必要がある場合、文字列変換メソッド toString() を自動的に呼び出す。
※独自の処理を実行したい場合は、オーバーライドする。
メンバ変数とメソッド
メンバ変数(member variable)
オブジェクトが持つデータを表し、オブジェクトの現在の状態を示す。
メンバ変数にアクセスすることで、オブジェクトの状態を読み取ったり変更したりできる。
クラスのメンバ変数は、そのクラスから作られるオブジェクトが持つデータを定義する部分。
これらのオブジェクトはメモリ上に保存される。
具体的には、オブジェクト全体がメモリ内の特定の領域(通常はヒープと呼ばれる領域)に確保され、その確保された領域の開始アドレスがオブジェクトの参照となる。
各メンバ変数へのアクセスは、このオブジェクトの参照(ベースアドレス)と各メンバ変数の相対的な位置(オフセット)を用いて行われる。
例えば、Person クラスに name、age、height といったメンバ変数があるとする。
ここで John というオブジェクトを生成したとき、そのオブジェクトの参照(ベースアドレス)が例えばメモリ上の 1000 とすると、name、age、height の各メンバ変数へのアクセスは、それぞれのオフセット(name, age, height がメモリ上でどのように配置されているか)を基にした相対的なアドレス指定を行なうことになる。
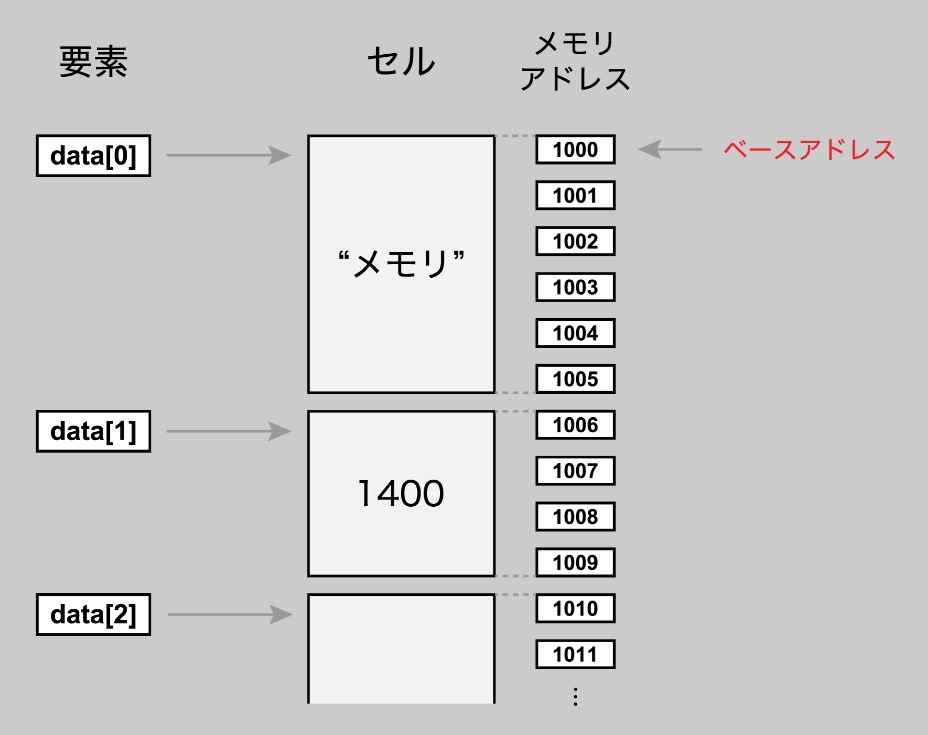
※https://recursionist.io/dashboard/course/4/lesson/572 より画像引用
オブジェクトの参照が利用可能になれば、メンバアクセス演算子を使って、そのオブジェクトのメンバ変数にアクセスできる。
オブジェクトのメンバ変数に対するアクセスは、そのメンバ変数の可視性(アクセス修飾子やアクセスレベルとも呼ばれる)によって制限される場合がある。たとえば、Java や C++ のような言語では、private と宣言されたメンバ変数は、そのクラスの外から直接アクセスすることはできない。これらの変数へのアクセスは、公開されたメソッド(たとえば、getter や setter)を通じて行なう必要がある。
デフォルト値の手動設定
メンバ変数がプリミティブ型の場合、その定義時にデフォルト値を設定することができる。
これらの値は、コンストラクタが実行される前に割り当てられることを覚えておこう。
しかし一般的には、これらの値は特別な事情がない限り、コンストラクタ内で初期化するのが理想的と言われている。
メソッド(method)
オブジェクトが持つ機能、つまりオブジェクトがどのように振る舞うかを定義する。
メソッドを使うことで、オブジェクトの振る舞いを操作できる。
コンストラクタ(constructor)
※https://recursionist.io/dashboard/course/4/lesson/568 より画像引用
オブジェクトを作成する際に自動的に実行される特殊なメソッド
コンストラクタ関数は、新しいオブジェクトの初期化と設定を行なうために使用される。
オブジェクトが作成されるときに実行されるため、クラスのインスタンス化と同時に特定の処理を実行するのに適している。
例えば、オブジェクトのプロパティの初期値を設定したり、必要なリソースを準備したり、他のオブジェクトとの関連性を確立したりするために使用される。
コンストラクタ関数は、オブジェクトの生成時に引数を受け取ることもある。
これにより、オブジェクトを初期化するために必要な情報を渡すことができる。
クラスのインスタンスを作成したときに必ず実行される
オブジェクトの比較
どのようにオブジェクトを比較するかは、プログラミング言語により異なる。
例えば、等号演算子(==)を使ってオブジェクトを比較するとき、Java では、それらが同じオブジェクト(つまり、同じメモリ上の場所を参照している)であるかどうかを確認する。これは参照比較と呼ばれる。
一方、動的言語では、オブジェクトの比較は通常、それらが等価(つまり、同じ値または状態を持つ)であるかどうかを調べるために行われる。これは値比較や内容比較と呼ばれる。
このような違いは、それぞれの言語が設計上どのようにオブジェクトの等価性を定義しているかによるもの。したがって、使用しているプログラミング言語の特性を理解し、それに適した方法でオブジェクトの比較を行なうことが重要になる。
クラスのインスタンスを比較する方法は、それぞれのプログラミング言語やそのクラスを設計する開発者により異なる。その比較は、オブジェクトの状態、つまり、そのオブジェクトの各メンバ変数の値を比較することで行われる。
オブジェクトのスコープ

※https://beginners-hp.com/javascript/object-class-create.html より画像引用
クラスは、オブジェクトの属性(メンバ変数)と振る舞い(メソッド)を定義する。
オブジェクトが生成される際、最初に行われるのは、そのメンバ変数へのデフォルト値の代入。
これはメモリ上で行われる。
データ型によっては、あらかじめ決まったデフォルト値を持っているものがある。
プリミティブデータ型の場合
数字は '0'
文字や文字列は空の文字列("")
がそれぞれのデフォルト値となる。
オブジェクトデータ型の場合、デフォルトは 'null' が設定されていたり、
C++ のような言語では開発者が自分でデフォルトのオブジェクトを定義することが可能。
そして開発者自身がメンバ変数にデフォルト値を設定することも可能。
クラスは新たなオブジェクトスコープを創出し、その中にあるメソッドや変数の利用を許可する。
オブジェクトに関連するメソッドが呼び出されるときには、該当オブジェクトのメンバ変数へのアクセス優先度が決まる。
スコープの優先順位
- メソッド内のローカルスコープ
- オブジェクトを定義するクラススコープ
- ソフトウェア全体で共有されるグローバルスコープ
ブロック → メソッド → クラス → パッケージ → public
(「内側から外側」の原則)
プログラミング言語によっては、オブジェクト自身を参照するための特別なキーワード「this」が提供されているが、メソッド内で必ず使わなければならないわけではない。
この「this」キーワードを利用するか否かは、上述のスコープルールを参照して、どの変数を使用するかが決定される。
※thisの有無による参照の優先順位
(1) thisあり(明示的インスタンス変数アクセス)
this.age = x;
常にインスタンス変数を直接参照
→ 引数やローカル変数と同名でも必ずフィールドを指す
(2) thisなし(暗黙的参照)
age = x;
Javaのスコープ解決ルールに従い、以下の順で探索する。
- 現在のブロック内のローカル変数/引数
- 外側のメソッド/コンストラクタの引数
- インスタンス変数
- スーパークラスの変数
言語のスコープルールが許す場合、メソッド内からメンバ変数にアクセスするときに、「this」キーワードの使用を選択したり、省略したりすることができる。
「this」キーワードを使用するとコードが長くなり、冗長性が増すというデメリットがある一方で、「this」キーワードを使用することで、メンバ変数のアクセスが保証され、開発者はそのメンバ変数が活用されていることを理解しやすくなる。
したがって、「this」キーワードの使用は個人の嗜好やチームのポリシーによる。
例として、Javaの開発者の間では、コンストラクタやゲッター、セッターを除いて、「this」キーワードを省略する傾向が見受けられる。
しかし、一部の開発者はインスタンス変数へのアクセスを明示的に示し、テキストエディタのチェック機能で警告が出ることを避けるために、「this」キーワードを利用する。
どちらのアプローチを採用するにせよ、その選択を一貫して適用し、スタイルの統一性を保つことが重要である。
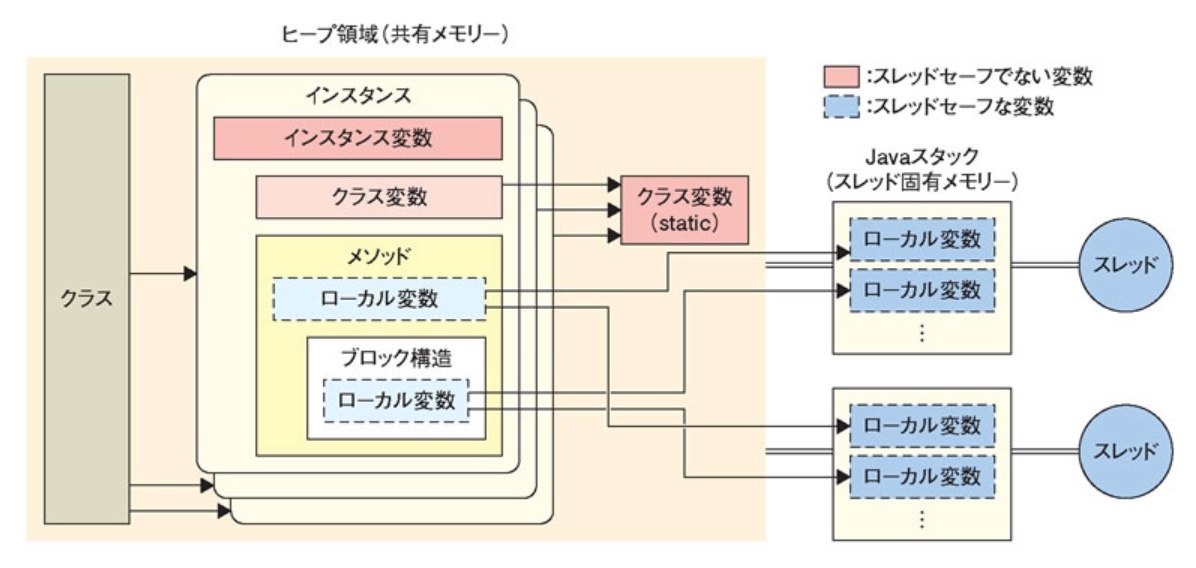
メンバ変数
クラスのすべてのオブジェクトが同じメンバ変数を共有する必要がある場合、そのメンバ変数は通常、静的メンバ変数 または クラス変数として宣言される。
クラス変数
クラス変数は、クラスの全てのインスタンスで共有される。
つまり、あるインスタンスでその変数を変更すると、そのクラスの他の全てのインスタンスもその変更を見ることができる。
これは、静的メンバ変数がメモリ内の固定された場所(静的メモリ)に存在していることに起因する。
この特性は、全てのインスタンスが同じ値を参照したり、その値を共通に保持したりする必要がある場合に特に有用。
例えば、全てのインスタンスが同じ設定情報を参照する必要がある場合や、特定のクラスが生成した全インスタンスの数を追跡したい場合などが考えられる。
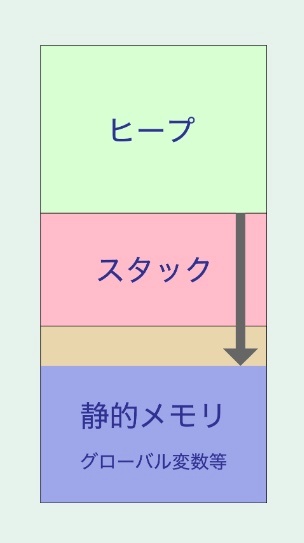
※メモリ
コンピュータのメモリは、大まかにはスタック領域とヒープ領域に分けられるが、静的メモリはこれらのいずれにも含まれず、特別に確保された領域に存在する。
静的メモリは、プログラムが開始されるときにすぐに割り当てられ、プログラムが終了するまでそのメモリは解放されない。
静的メモリ割り当ては、プログラムのコンパイル時に行われるメモリの割り当ての形式。
このメモリ割り当ての特性として、割り当てられるメモリのサイズが固定されており、プログラムが開始するときから終了するまでの期間、そのメモリは維持される。
静的メモリは通常、グローバル変数や静的変数、そして定数に用いられる。
※https://recursionist.io/dashboard/course/4/lesson/576 より画像引用
クラス変数は、特定のクラスのすべてのインスタンス(=そのクラスのオブジェクト)によって共有される変数。
「静的」であるため、プログラムが実行されている間は常に存在し続け、その値は全てのオブジェクト間で共有される。個々のオブジェクトではなく、クラス自体に関連付けられている。
メンバ変数
クラス内で定義され、そのクラスのメソッドやコンストラクタからアクセス可能な変数。
メンバ変数はさらに、インスタンス変数とクラス変数に分けられる。
クラス変数
クラス全体にわたって共有される変数。
これは一つのクラスに属しており、そのクラスのすべてのインスタンス(オブジェクト)間で共有される。
したがって、あるオブジェクトがクラス変数を変更すると、その変更はそのクラスの他のすべてのオブジェクトに影響を及ぼすことになる。
クラス変数は静的(static)キーワードを使用して定義され、プログラムの実行全体の間、存在する。
※Java の場合は final キーワードを使って、クラス変数を定数にすることができ、このキーワードによって、クラス変数の状態はロックされ、上書きすることができなくなる。つまり、他のオブジェクトに影響を与えなくなる。
インスタンス変数
クラスの個々のインスタンス(オブジェクト)に固有の変数。
そのオブジェクトが持つ特定の状態や属性を表現する。
各オブジェクトが自身のインスタンス変数のコピーを持ち、それらは他のオブジェクトとは独立している。
したがって、あるオブジェクトがインスタンス変数を変更しても、それはそのオブジェクトにのみ影響し、他のオブジェクトは影響を受けない。
クラスメソッド
静的メソッドとも呼ばれ、クラスの具体的なインスタンスを生成しなくても利用できる。
オブジェクトの状態に依存しない。
クラスメソッドは、基本的にはそのクラスの名前空間内で定義された関数として働く。
つまり、myContainer.myFunction() のように特定の名前を使用することで、同名の他の関数との衝突を避けることができる。
名前空間のイメージ
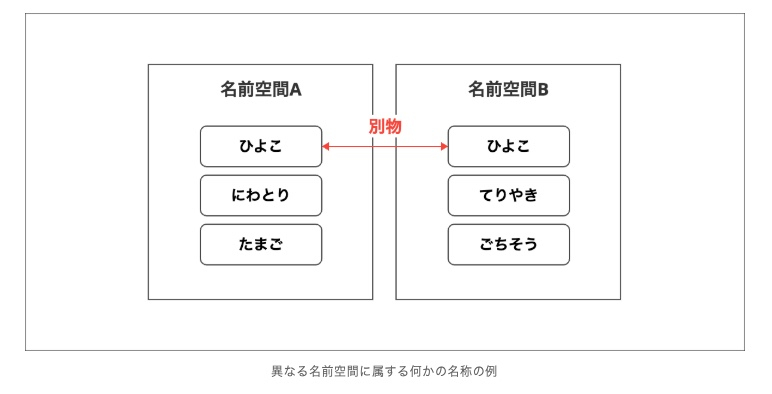
※https://business.ntt-east.co.jp/content/cloudsolution/ihcm_column-09.html より画像引用
通常のインスタンスメソッドとは異なり、静的メソッドは特定のインスタンスの状態には依存しないため、それぞれのインスタンスが独自の this 参照を持つことはない。
その代わり、静的メソッドはクラスレベルで操作を行ない、インスタンス固有の情報にアクセスすることはない。
インスタンスを生成しなくても直接使用できるメソッド。オブジェクトに共通の操作などを記述することで全てのオブジェクトで使用できる。
ステートレスオブジェクト(stateless object)
オブジェクト指向プログラミング言語、例えば Java では、静的メンバ変数と静的メソッドのみを持つクラスを作成する手法は、基本的に名前空間の作成を伴う。このようなクラスは、特定のインスタンスや状態を要求せず、幅広い適用性を持つライブラリの開発などにおいて利用される。
全てのメンバ変数が final(変更不能)であるとき、つまり状態を持たないとき、そのオブジェクトはステートレスオブジェクトと呼ばれる。
静的クラスや静的メソッドは、特定のオブジェクトのインスタンスに紐づけられるのではなく、クラス自体に紐づけられる。静的メンバ(メソッドや変数)はクラスがロードされたとき(通常は初めて参照されたとき)にメモリに一度だけ確保される。
これは、その後生成されるそのクラスの全てのインスタンスから参照可能で、それぞれのインスタンスで個別にメモリに格納されるわけではない。
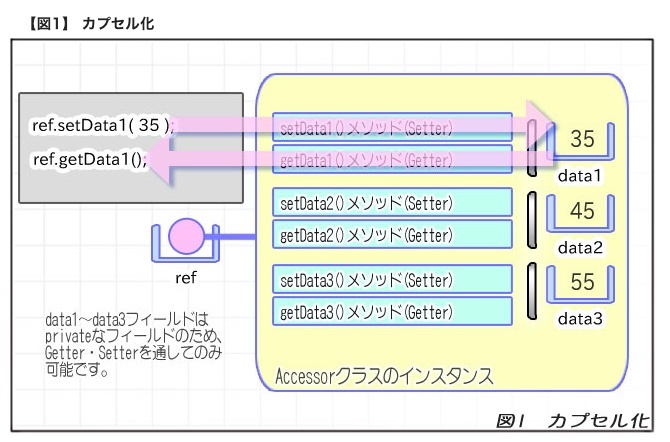
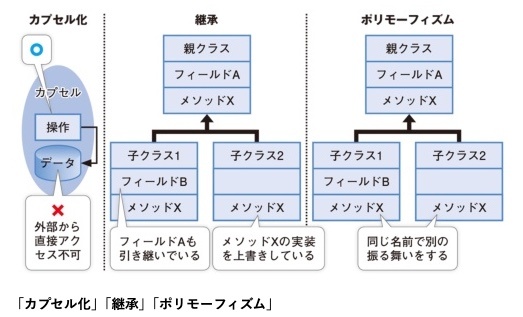
カプセル化(encapsulation)
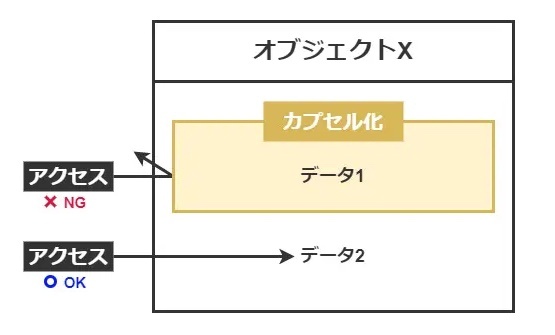
※https://webpia.jp/encapsulation/ より画像引用
オブジェクト指向プログラミングでは、クラスの設計において、その成分や機能を他のチームメンバーや企業、外部の開発者にどの程度公開するか非公開にするかを決める際には注意深く考える必要がある。
この適切な情報の管理は、プログラムの安全性と安定性を保証する重要な要素となる。
カプセル化は、クラスの状態と挙動をあたかもカプセル内に封じ込めるかのように隠蔽し、何を公開し、何を非公開にするかをクラス設計段階で決定する手法のこと。
カプセル化を通じて、実装の詳細を隠蔽し、外部からアクセスできる範囲を明確にすることができる。
これにより、クラスの使用方法を定義し、それを強制することが可能になる。外部利用者が隠蔽された状態や挙動にアクセスしようとした場合、プログラムは実行前にエラーを出す。
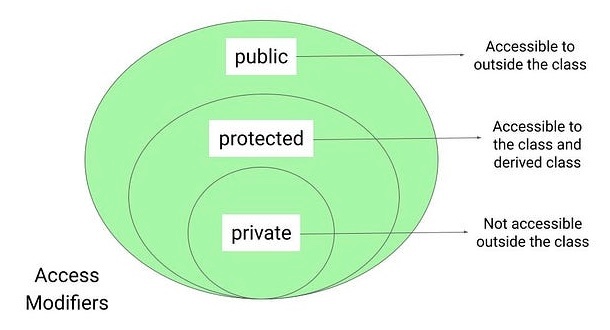
アクセス修飾子(Access Modifiers)
アクセス修飾子は「クラス単位のスコープ」を制御する
※https://www.enjoyalgorithms.com/blog/encapsulation-in-oops より画像引用
クラス、メソッド、フィールドなどの 可視性(スコープ)を制御 するための重要な仕組み
public キーワード(広いスコープ)
任意のユーザがアクセスできるようにメンバ変数やメソッドを公開するための可視性修飾子
・どこからでもアクセス可能(異なるパッケージ、異なるモジュールからも参照可能)
・クラス、メソッド、フィールドに適用可能
(使用する場面)外部に公開するAPI(ライブラリの主要クラス、ユーティリティメソッドなど)
private キーワード(最も狭いスコープ)
メンバ変数やメソッドを外部から見えないように隠蔽するための可視性修飾子。
これを使うことで、クラス外部からの不適切なアクセスを防止し、必要に応じてエラーを発生させることができる。
※privateメソッドのアクセス可否は「クラス内に書かれたコードかどうか」だけで決まり、インスタンスの有無は一切関係ない。
・同じクラス内からのみアクセス可能
・主にフィールドや内部メソッドに使用(クラスには適用不可)
・カプセル化(Encapsulation)を実現するために重要
(使用する場面)クラス内部の隠蔽データや処理(カプセル化が必要なフィールド)
protected キーワード
・同じパッケージ内のクラスからアクセス可能
・サブクラス(継承したクラス)からもアクセス可能(異なるパッケージでもOK)
・主にメソッドやフィールドに使用(クラスには適用不可)
(使用する場面)サブクラスでのみ利用可能にしたい処理(テンプレートメソッドパターンなど)
protectedとパッケージ
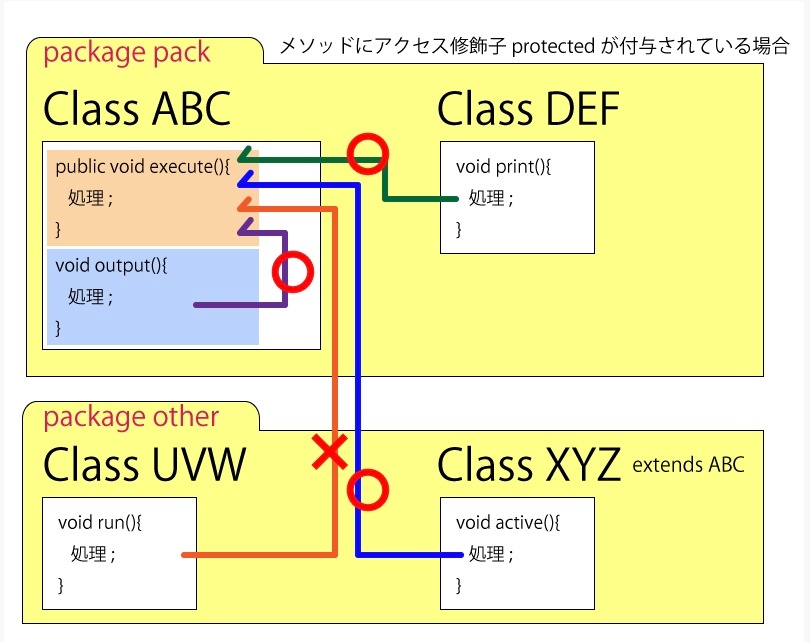
※https://it-level-up.club/java/java-section4/post-1432/ より画像引用
※Java
デフォルト(package-private)
・修飾子を省略した場合のデフォルトのアクセスレベル
・同じパッケージ内からのみアクセス可能(サブクラスでも異なるパッケージなら不可)
・クラス、メソッド、フィールドに適用可能
(使用する場面)パッケージ内でのみ利用する内部実装(非公開のヘルパークラスなど)
※https://www.scaler.com/topics/getter-and-setter-in-java/ より画像引用
UML クラス図では、メンバ変数とメソッドの前に "-" または "+" を付けて表現する。
"-" は private を、"+" は public を、"#" は protectedを意味する。
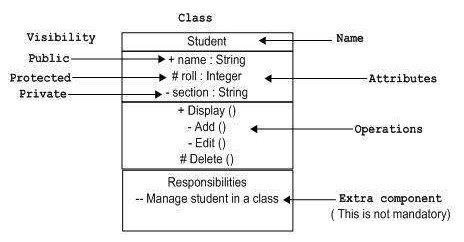
※https://www.tutorialspoint.com/uml/uml_basic_notations.htm より画像引用
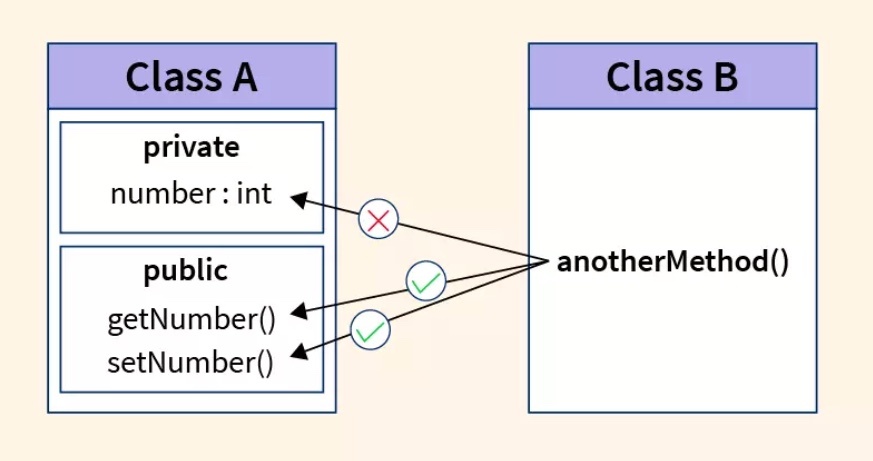
オブジェクト指向プログラミングの中核的な概念であるカプセル化は、データとその操作を単一の単位、つまり「クラス」に包含する技術。このカプセル化を適切に行なうためには、定数以外のメンバ変数を一般的に private として保持する。これにより、オブジェクトの内部データを直接操作することが防がれ、データの整合性と安全性が保たれるようになる。
アクセサメソッド(accessor method)
ゲッターメソッドのこと。
private キーワードで設定されたフィールドには通常クラスの外部から内部へアクセスできないため、メンバ変数のデータを取得して返す役割を果たす。
慣習的に、これらのメソッドの名前は "get" で始まり、その後に対象となるメンバ変数の名前が続く。
※http://www.kab-studio.biz/Programing/OOPinJava/11/03.html より画像引用
ミューテータメソッド(mutator method)
セッターメソッドのこと。
メンバ変数の値を変更するために使用する。
セッターメソッドは引数を取り、これを基にメンバ変数の値を更新する。
これらのメソッド名は、慣習的に "set" で始まり、その後に対象となるメンバ変数の名前が続く。
セッターはその属性を更新するメソッドであり、バリデーション(検証)ロジックを追加することも可能。これにより特定の条件が満たされていない場合に属性の更新をブロックすることができる。
ゲッターとセッターの導入は、しばしばコード量の増加を伴うが、現代のテキストエディタの多くはこれらのメソッドを自動生成する機能を提供している。
これにより、コードの品質を維持しつつ、開発時間を節約することが可能となる。
使用と実装の分離
ゲッターやセッターを使用すると、クラスの内部データ(実装)とそのデータの使用方法を分けることができるようになる。これにより、クラスのユーザーはクラスの内部構造を知る必要がなく、代わりに提供されたメソッドを使用するだけでよくなる。これはコードの整理と保守性の向上に寄与する。
追加の処理
セッターメソッドでは、データをクラスに設定する前に、追加の操作(例えば、入力データの検証、デバッグ情報のログ出力、入力データの変換など)を行なうことができる。これにより、データの一貫性と安全性が確保される。
ゲッターメソッドでも同様のことが可能で、データを取得する際に必要な処理を行なうことができる。
内部実装の隠蔽と更新
ゲッターとセッターは、内部データの詳細を隠蔽しながら、データの取得と更新を行なう手段を提供する。これにより、データの詳細が変更されたとしても、それがクラスの使用に影響を与えないようにします。
例えば、あるデータが内部的にどのように格納されているか(配列、リスト、マップなど)が変更されたとしても、それに対応するゲッターとセッターが提供するインターフェースは変わらないため、クラスを使用している他のコードを変更する必要はない。
クラスの抽象化
クラスの利用者は、クラスの説明、利用可能な public コンストラクタ、メソッド、変数、そしてそれら public メンバがどのように動作するのかだけを理解していればよいとされている。
クラスの利用者には、クラスの契約を除いて、その他の全ての情報が非表示となっているのが理想的とされている。
抽象化 Abstractionとは「必要なことだけを取り出して、余計な情報を隠すこと」
オブジェクト指向では、「クラス」という仕組みを使って現実世界のものをプログラム上に表現する。
そのとき、すべてを詳細に表現するのではなく、本質的な部分だけを切り出してモデル化する。
そのクラスの具体的な実装とその使用方法を分離することが可能となる。
クラスの契約は、そのクラスがどのように使用されるべきかを示すものであり、カプセル化はその内部実装と契約によって利用可能となるインタフェースを隔離する。
契約(Contract)とは「このクラスは、こういう使い方ができると約束する」という考え方のこと。
クラスやインターフェースは、使う側に対して使い方のルールや約束を提示する。
これはプログラムにおける「インターフェース設計」や「APIの使い方」などにも関係する。
関数の抽象化
関数をブラックボックスとして扱う場合、その使用者は以下の 3 つの観点を理解する必要がある。
① 何を行なうのか
② 何を入力するのか
③ 何を出力するのか
※その関数がどのように具体的に実装されているかについては理解する必要はない。
クラスの契約(contract)
クラス契約は、オブジェクト同士の約束事。「こういう条件で呼んでくれたら、こういう結果を保証するよ」というルールを明確にすることで、システム全体の信頼性が高まる。
そのクラスがどのように動作すべきか、または具体的にはどのようにやりとりすることができるかを定義する一連のルールやプロトコルを指す。
この契約はクラスの公開メソッド、プロパティ、そしてイベント(公開インターフェース)を通じて定義され、これらのメソッドが呼び出されたとき、プロパティがアクセスされたとき、またはイベントがトリガーされたときに、クラスが特定の方法で動作することを保証するもの。これらの契約は多くの場合、記述形式で表現され、コード内のコメントや API ドキュメンテーションとして提供される。
契約の概念は、OOP のカプセル化と抽象化の原則と密接に関連しており、明確な契約を定義することで、クラスは内部の実装詳細を隠すことができ、プログラムの他の部分が契約に基づいてだけそれとやりとりすることができる。
クラスの利用者は、契約に記載されている事項のみを使用する。
これは、クラスの利用者が契約を遵守する限り、他のプログラムに影響を与えることなく、また壊すことなく、クラスの内部を自由にリファクタリングや拡張できるということを意味する。
これは、パフォーマンスを向上させるなど、より効率的なプログラムを作成するための可能性を提供している。
防御的プログラミングの4大原則
1. 入力検証
メソッドの最初で不正値を排除
public void setAge(int age) {
if (age < 0 || age > 150) throw...
}
2. 不変条件の維持
オブジェクトが常に満たすべきルール
// 残高がマイナスにならない
assert balance >= 0;
3. nullチェック
Objects.requireNonNull()
4. ドキュメント化
@throws で契約条件を明記
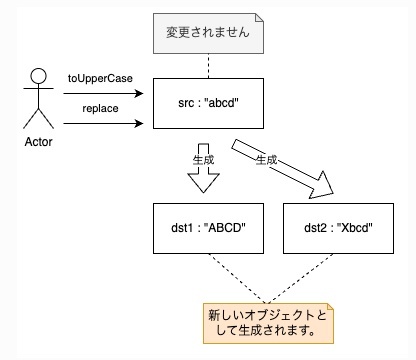
不変オブジェクト(immutable object)
※ https://programming-tips.jp/archives/j/2/index.html より画像引用
オブジェクト指向プログラミングにおけるオブジェクトは、基本的に以下のいずれかに分類される。
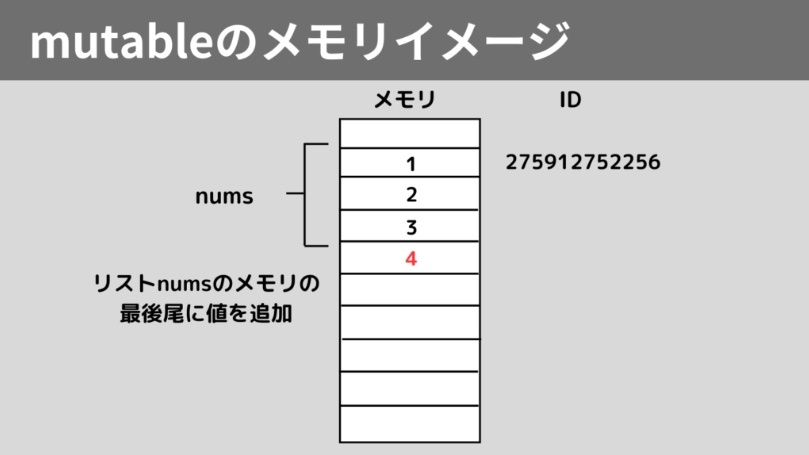
可変オブジェクト mutable ※ミュータブル
そのコンストラクタが呼び出された後でも、その状態(つまりそのデータ)を変更することが可能。
不変オブジェクト immutable ※イミュータブル
一度コンストラクタが呼び出されると、そのオブジェクトの状態は変更できないままロックされる。
データを安全かつ保護された状態に保つことを目指す。
不変オブジェクトを使用すると、一度設定されたデータは、オブジェクトがメモリから削除されるまで、その状態が変更されることはない。
一度作られたら状態が変わらない(=再代入や変更ができない)ように設計されたオブジェクト
プリミティブデータ型を不変(つまり定数)にする際に、定数キーワードを使って宣言すると、割り当てられたデータはロックされ、他のユーザーが上書きすることはできなくなる。
これと同じ原理が不変オブジェクトにも適用される。
コンストラクタがメンバ変数へのデータの代入を終えると、その状態はロックされ、ユーザがその状態を上書きすることはできない。
不変オブジェクトを実現するには、すべてのメンバ変数を private に設定し、コンストラクタ以外には public なミューテータメソッドを持たせないことが必要になる。
不変オブジェクトを使用する理由は主に安全性にある。
これにより、データが突然変化したり、意図しない副作用を生じたりするのを防ぐ。
また、他の部分のコードやスレッドにオブジェクトを安心して渡すことができる。
さらに、データが読み取り専用であることを保証するため、複数のスレッドやコンピュータがそのデータを同時にアクセスする場合にも有用である。
不変オブジェクトは、共有メモリリソースに多くのコンポーネントやプロセスがアクセスしている状況で特に効果を発揮する。
これは、データの状態が変化することがないため、デバッグが容易になることによる。
このため、不変オブジェクトは、安全性が重要視されるプロジェクトや並行プログラミングでよく使用される。
いくつかのプログラミング言語では、デフォルトのデータ構造が不変であることもある。
例えば、多くの言語では文字列が不変に設定されており、文字列操作の安全性を向上させるが、文字列が不変であることによる影響を理解していなければならない。
たとえば、2 つの文字列を結合する場合、不変性のために両方の文字列を新しい文字列にコピーする必要がある。この操作は、文字列のサイズに比例する時間がかかるため、大きな文字列を扱う場合には注意が必要となる。
例えば、片方の文字列が 10,000 文字で、それに "hi" を連結する場合、新しいコピーを作るためには実際に 10,002 ステップが必要となる。
この時間の影響は、小さな文字列ではほとんど問題にならないが、数十万文字にも及ぶ大きなテキストを扱う場合には重要となる。そのような場合、連結操作を文字列ではなく文字配列で行ない、最後に全体を文字列に変換することで、処理速度を向上させることができる。
さらに、不変性はメモリ効率にも寄与する。
例えば、"hello" という文字列がコード中に何千回と現れる場合、これらは全て一つのメモリアドレスに格納できる。
これは不変であるため、それぞれの "hello" が同一のメモリアドレスを共有することで、メモリの使用を効率化できる。
メモリ割り当ての最小化
・char[]は1回だけ確保:最初に使用するメモリ領域を確保する
・String連結は毎回新しいメモリ領域を要求:連結の都度、新たなメモリ領域を確保する必要がある
データコピーの削減
・配列操作は既存のメモリを直接更新
・文字列連結は毎回全データをコピー
※文字列連結の問題点
・毎回 新しいStringオブジェクト が生成される
・毎回 全データのコピー が発生(前の文字列を新しい配列に複製)
・ガベージコレクション が頻発
繰り返しメモリを確保することによる累積コストが巨大なパフォーマンス劣化の原因になる。
ミュータブルのメモリイメージ
※https://pokoroblog.com/python-mutable-immutable/ より画像引用
イミュータブルのメモリイメージ
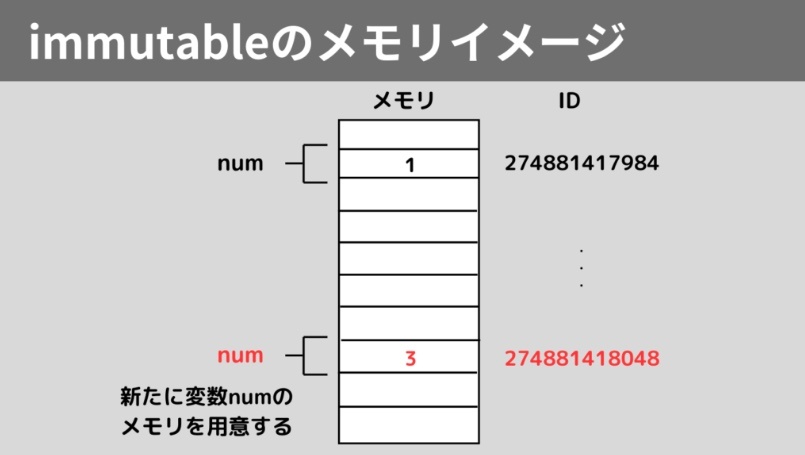
※https://pokoroblog.com/python-mutable-immutable/ より画像引用
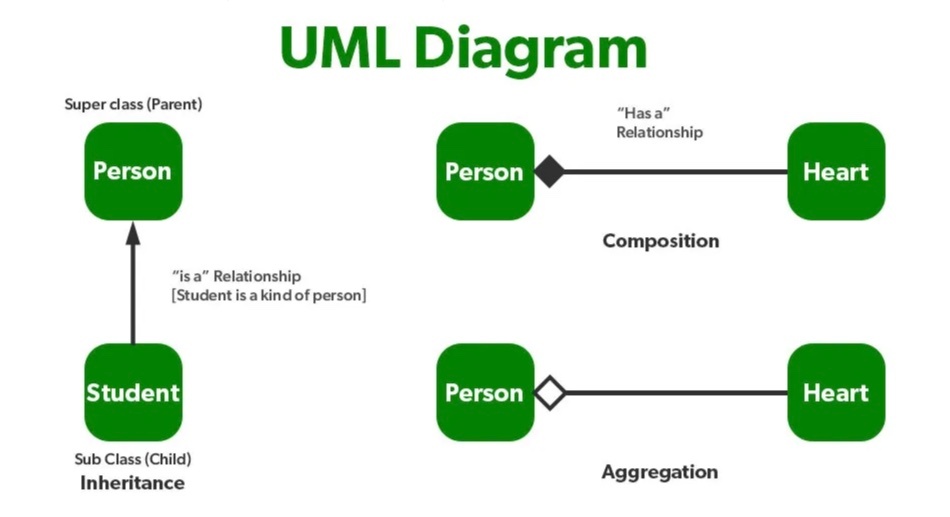
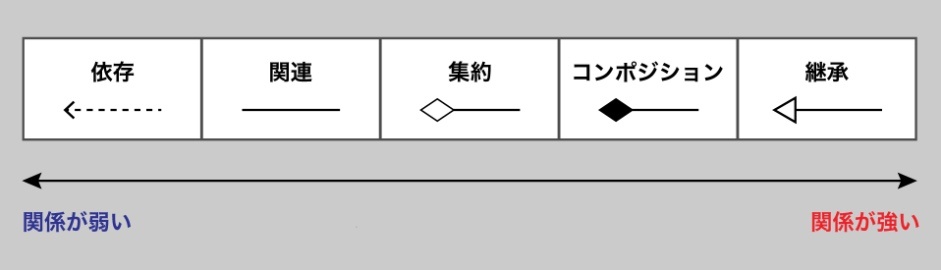
関連と継承
クラス設計における重要な要素である「関係(relationship)」について
特に重要な種類
・関連(association)
・集約(aggregation)
・コンポジション(composition)
・継承(inheritance)
継承の概念を理解することで、ソフトウェアの再利用性がどのように向上するかについて理解できるようになる。
関連(association)
二つの異なるクラス間の二項関係を指す。
UML 図では、関連は二つの項目をつなぐ線で表現される。
※https://medium.com/@bindubc/association-aggregation-and-composition-in-oops-ec2d197dc04d より画像引用
関連とは、二つのクラス間の線であり、クラスが自身に対して関連を持つ場合は、再帰的関連と呼ばれる。
多くの場合、関連が双方向か単方向かを指定する。
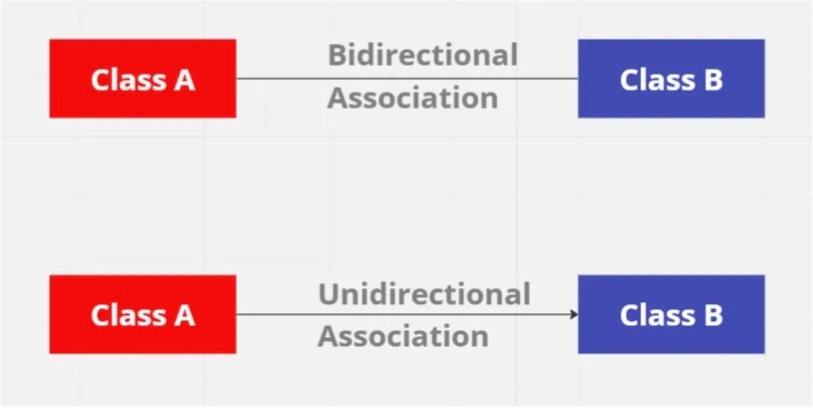
※https://medium.com/@akshatsharma0610/beginners-guide-to-class-diagrams-660d068c1802 より画像引用
双方向性 - bidirectional association
二つのクラスが互いにアクセス権を持つことを指す。
(例)従業員が勤務先の会社の全ての public 変数とメソッドにアクセスでき、同様に会社も従業員の全ての public 変数とメソッドにアクセスできる状況
※https://www.researchgate.net/figure/Joining-Unidirectional-Associations_fig1_3919815 より画像引用
単方向性 - unidirectional association
一方のクラスのみが他方のクラスへアクセス権を有している関係を指す。
例えば、「人(Person)が、財布(wallet)を所有する」というコードでは、Person クラスのみが wallet の public 変数やメソッドにアクセス可能であり、逆に wallet から Person へのアクセスは存在しないというものが挙げられる。
UML 図上では、単方向性は一方の端に一本の矢印だけを持つ線で表現され、この矢印の向きからどのクラスがどの方向を向いているのか、すなわちどのオブジェクトがどのデータにアクセス可能なのかが理解できる。
※クラス間の関係を表現する方法
オブジェクト指向プログラミングでは、クラス間の関係はメンバ変数を介して表現されることが多い。このメンバ変数は、他のクラスのオブジェクトへの参照を保持する。
しかし、このオブジェクト間の関連性は、テーブルやポインタのような他のデータ構造を使用しても実装はできる。たとえば、関連するオブジェクト間のマッピングを保持するテーブルを作成したり、メモリ内の特定の場所を指すポインタを使用してオブジェクト間の関係を管理することができる。
しかし、そのような方法は一般的には少なく、多くの場合、他のクラスのオブジェクトへの参照を保持するメンバ変数を使って、オブジェクト間の関係が実装される。
多重度(multiplicity)
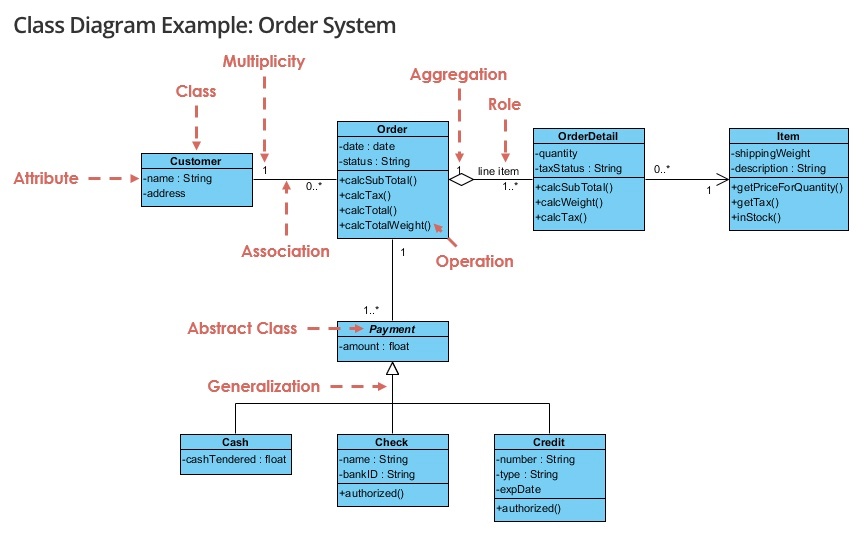
※https://stackoverflow.com/questions/76675708/how-to-read-multiplicity-in-uml より画像引用
あるオブジェクトが関わる他のオブジェクトの数を示すもの。
UML 図では、この数値または変数は、関連先のオブジェクトに向けて示される。* 記号は、関連するオブジェクトが無数に存在する可能性を示す。
また、m..n と表記することで、関連先のオブジェクトが最小 m 個から最大 n 個存在することを示す。

※https://blog.visual-paradigm.com/what-is-multiplicity/ より画像引用
集約とコンポジッションは、「部分オブジェクトの独立性」と「生存期間の依存性」で区別する。
集約(aggregation)
UML 図では、集約は空のダイヤモンドで示される。

※https://medium.com/@varungusain1997/relationship-in-oop-69fc21589b36 より画像引用
※https://www.momoyama-usagi.com/entry/info-software06 より画像引用
あるクラス A がその状態の一部としてクラス B を含む形の関連を示す。
→ クラス A はクラス B の所有者となる。この文脈において、クラス A は集約する側となり、クラス B は集約される側となる。
「弱い」全体-部分関係
・部分オブジェクトは全体オブジェクトとは独立して存在できる。
・全体オブジェクトが消滅しても、部分オブジェクトは残る。
・「has-a」関係(〜は…を持っている)と表現される。
◎「部品を集めただけ」→ 部品は別の場所でも使える
ただし、集約によって得られる情報は、インスタンスの寿命についての詳細を提供するまでには至らない。具体的には、クラス A がクラス B の所有者であるという関係性において、オブジェクト A がメモリから削除された場合に、オブジェクト B もそれに伴って削除されるのか、それとも独立してメモリ内に存続するのかという区別を確定することができないということ。
(例)人は財布を持っている。財布を無くしても人は存在する。逆に人がいなくなっても財布は存在できる。
コンポジション(composition)
UML 図では、コンポジションは塗りつぶされたダイヤモンドで示される。
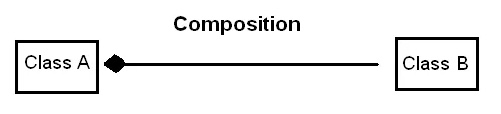
※http://medium.com/@varungusain1997/relationship-in-oop-69fc21589b36 より画像引用
「運命共同体」のような関係
集約の特殊な形態で、ここでは集約されるオブジェクトが集約するオブジェクトに対して依存性を持つ。
コンポジションでは、所有者が完全な支配権を持つため、集約先のオブジェクトはそれ自体で存在することはできない。
これは、クラス A とクラス B の間にコンポジションが適用されている場合、クラス A は B の所有者であり、オブジェクト A が消滅すれば、オブジェクト B も同様に消滅することを意味する。
※https://recursionist.io/dashboard/course/4/lesson/593 より画像引用
「強い」全体-部分関係
・部分オブジェクトは全体オブジェクトに強く依存する。
・全体オブジェクトが消滅すると、部分オブジェクトも消滅する。
・「part-of」関係(〜は…の一部である)と表現される。
※「has-a」関係(〜は…を持っている)とも表現できる。
◎「部品は全体の一部」→ 部品は全体なしでは存在できない
親→子の一方向的な所有関係
クラス A がクラス B を持つ形の関係性を持つ集約は、「持つ」または「一部である」関係と呼ばれる。
独立したエンティティとして存在可能とは、他に依存せず、単体で意味や機能を完結できる存在のこと。
依存関係(dependency)
あるクラス A が何らかの形でクラス B に依存していて、クラス B の状態や振る舞いの変更がクラス A に影響を及ぼす可能性がある状況を指す。
関連は依存関係の一種で、より強い形の依存関係とも言える。
クラス A がクラス B を所有するとき、すなわちクラス A がクラス B のインスタンスをメンバ変数として持っているとき、クラス A はクラス B に対する依存関係を持つことになる。
依存関係はソフトウェアの一部が他の部分にどの程度依存しているかを表している。
そのため、この依存関係がどのように構築されているかを理解していると、ソフトウェアの変更やアップデートが他の部分にどのように影響を及ぼすかを予見することができる。クラスが他のクラスに依存している場合、その依存関係を明示的に示すことで、コードをリファクタリングしたり、依存関係があるクラスを更新したりする際に、その影響を適切に管理することが可能となる。
※https://recursionist.io/dashboard/course/4/lesson/596 より画像引用
参考URL:https://blog.rcard.in/programming/oop/software-engineering/2017/04/10/dependency-dot.html
依存関係は UML 上で破線と矢印で表現される。
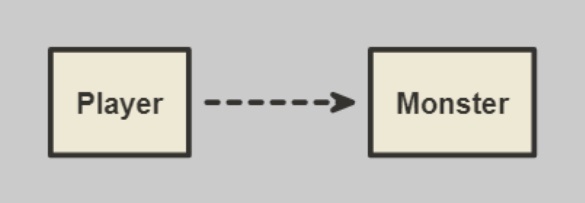
※https://recursionist.io/dashboard/course/4/lesson/596 より画像引用
矢印は依存の方向を指し示すため、依存元のクラスから依存先のクラスへ向かう。
例えば、下記の図では、Player クラスは Monster クラスに依存している。つまり、Player クラスの一部の機能(例えば"攻撃")は、Monster クラスの設計や機能に依存しているということを示している。この依存関係があるために、Monster クラスが変更されると、それが Player クラスに影響を及ぼす可能性がある。
依存性注入(dependency injection, DI)
関数が必要とするクラスのオブジェクトを直接生成するのではなく、そのオブジェクトを外部から渡すことにより、依存関係を明示的にする方法。
必要なもの(依存)を、自分で作るのではなく、外から渡してもらう設計思想
クラス内でnewせず、外から必要なものを受け取る
→ こうすることで、生成責任を追わず、使うことに専念できる
この方法を使用すると、外部のユーザーはクラスが何に依存しているかを明確に理解することはできないが、開発者はそのメソッドがどのオブジェクトに依存しているかを明確に知ることができる。
これは関数型プログラミングの考え方に似ており、メソッドがその入力に明示的に依存する形となる。
これにより、コードの理解性とメンテナンス性が向上する。
「コンセント(インターフェース)に差すだけで使える」 がDIの本質
依存関係を入力として明示することのもう一つの大きな利点は、依存するオブジェクトを自由に切り替える柔軟性を持つこと。
例えば、メソッドのオーバーロードやインターフェースを用いて、ある特定の動作を持つ異なるオブジェクトを同じメソッドに渡すことが可能。
制御の反転(inversion of control, IoC)
通常、プログラムの流れは「開発者が書いたコード」が直接制御するが、IoCでは「フレームワークやライブラリ」がプログラムの流れを管理し、開発者はその流れに「従う」形になる。「制御の主体」が反転(Inversion)する概念。
オブジェクト指向プログラミングにおいて、依存性の注入(Dependency Injection、DI)と密接に関連しており、IoC はプログラムの制御フローが従来の方法とは逆の方向に制御されるという概念。
従来の手法では、アプリケーションの制御フローは主にアプリケーション自体が担っていた。
つまり、アプリケーションが他のコンポーネントやクラスを直接制御し、その実行順序や依存関係を管理していた。
制御の反転では、アプリケーションは自らの制御フローをフレームワークのような他の外部エンティティに委任する。具体的には、アプリケーションは外部の制御コンテキストやフレームワークによって制御され、必要なタスクや処理の実行順序が外部から与えられる。これにより、アプリケーションは個々のコンポーネントやクラスに焦点を当てて開発することができる。
IoC の原則を使用すると、開発者は処理の具体的な詳細から手を引き、自分の目的に合わせたビジネスロジックの構築に専念できる。
これにより、開発の生産性を向上させ、コードの再利用性と可読性を向上させることができる。
依存性の注入(DI)は、制御の反転を実現するための手法の 1 つ。
DI では、依存関係を持つオブジェクト(依存先)を別のオブジェクト(依存注入コンテナ)が管理し、必要なタイミングで依存先オブジェクトを注入する。つまり、アプリケーションは自ら依存関係を解決するのではなく、外部のコンテナに依存性の解決を委任することで、制御の反転を実現する。これにより、テスト時の依存オブジェクトの差し替えやコードの再利用が容易になる。
DIコンテナ
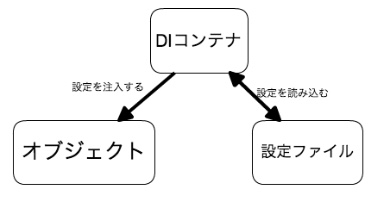
※https://pgpg-sou.hatenablog.com/entry/2013/12/09/140619 より画像引用
DIコンテナはオブジェクト間の依存関係を外部ファイルに書き出し、その外部ファイルを読み込んでそれをクラスに注入する
依存関係を持つオブジェクトを「自動で作って、注入してくれる」便利な道具
手作業で依存オブジェクトを渡す代わりに、DIコンテナがオブジェクトを管理して、必要なときに適切なものを提供してくれるという役割を果たす
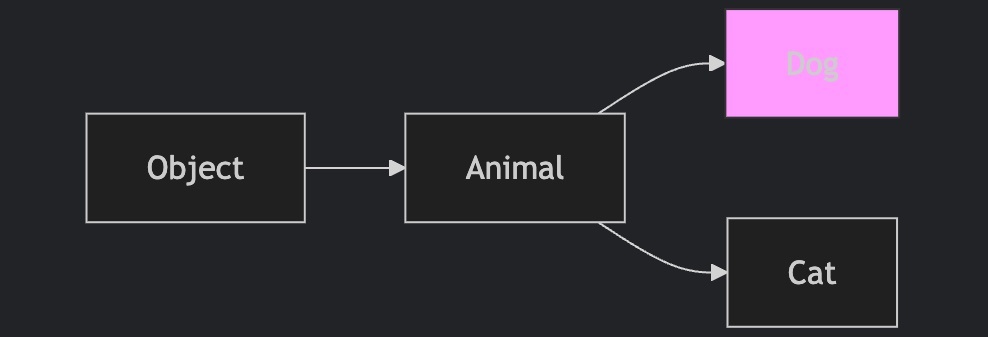
継承
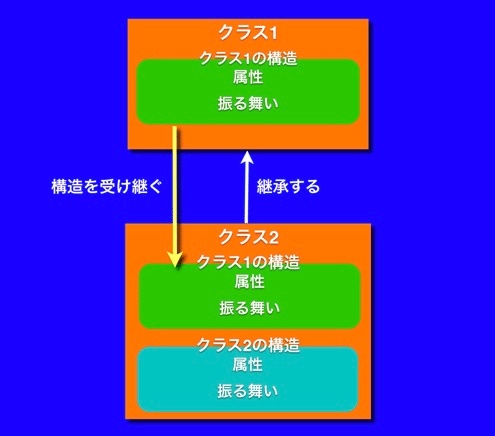
※https://codezine.jp/article/detail/3708 より画像・以下テキスト引用
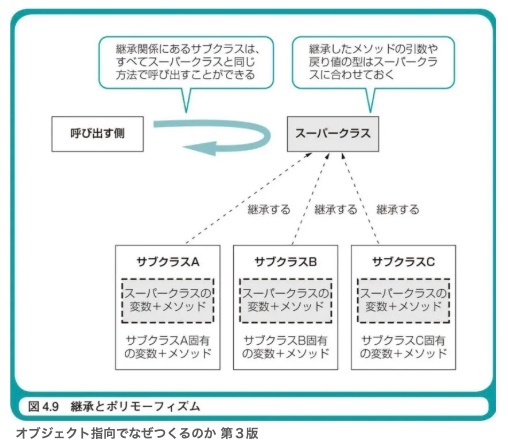
既存のクラスの構造をベースに新しいクラスを定義する、クラスの再利用の仕組みです。1つのクラスだけをベースにできる仕組みを「単一継承」、複数のクラスをベースにできる仕組みを「多重継承」と呼びます。また、元になるクラスを親クラス(もしくはスーパークラス)、新しく定義されるクラスを派生クラス(もしくはサブクラス)と呼びます。継承を利用することで、派生クラスはメッセージ/メソッド/属性といった親クラスの構造を受け継ぐことができます。派生クラスは親クラスと同一の性質を受け継ぐため、派生クラスのインスタンスは親クラスのインスタンスでもあると考えることができます。
あるクラスが別のクラスの既存の定義を引用し、それを基に自己の定義を行う、クラス間の関係性を指す。
継承を利用することで、既存のクラスの定義を再利用し、新たなクラスを作成することが可能になる。
継承を用いるとデータ構造の一般化が可能となり、主に is-a 関係を満たす際に用いられる。
UML においては、継承は一般化という概念で表現され、継承は主に is-a 関係を持つ場合に適用される。
その名が示す通り、継承は階層構造に従い、親から子へ属性や振る舞いが伝えられる。
継承を実装するには、まずスーパークラスと呼ばれる一般的なクラスを定義し、そのクラスをベースにサブクラスと呼ばれる、より特化したクラスを作成する。
super()は親クラスのコンストラクタを参照する。これにより、スーパークラスのメンバ変数の初期状態を適切に設定する。
同じパッケージ内の全クラス + サブクラス(子クラス)に限定して公開するアクセス修飾詞。
そのクラスのサブクラス以外からは、全てのメンバ変数を隠蔽する。すなわち、全てのサブクラスは親クラスの protected メンバ変数にアクセスすることが可能。
※super キーワードを使わずに、継承したクラスの状態を、新たなルールに従って設定することも可能。
※https://kazulog.fun/dev/why-use-object-oriented-programming/ より画像引用
継承の正体は「暗黙的に自分にコピーされている」というよりも、「必要なときに親を探しに行く(委譲/探索)」という仕組みになっていること
(スーパークラスのコードがサブクラスに暗黙的にコピーされているわけではない)
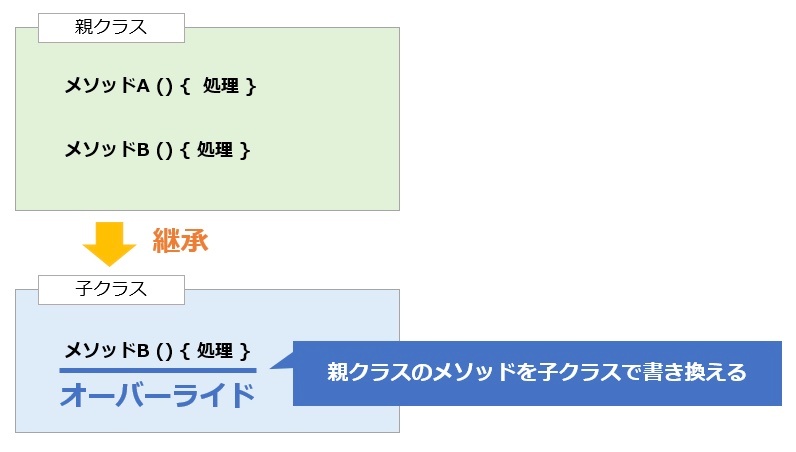
オーバーライド:継承したメソッドの振る舞いを再定義
※https://medium-company.com/オーバーライド/ より画像引用
親クラスのフィールドを子クラスで変更したい場合
親クラスのフィールドを変更する際は、親クラスの変数を そのまま使用して、this.name などでアクセスして変更する方法が一般的
abstract class Animal {
String name = "動物"; // 親クラスのインスタンス変数
public abstract void speak();
}
class Dog extends Animal {
// 親クラスのフィールドにアクセスして変更する
public void changeName(String newName) {
this.name = newName; // 親クラスのnameフィールドを上書き
}
@Override
public void speak() {
System.out.println("ワンワン");
}
}
public class Main {
public static void main(String[] args) {
Dog dog = new Dog();
System.out.println(dog.name); // => 動物
dog.changeName("犬");
System.out.println(dog.name); // => 犬
}
}
親クラスのフィールドを子クラスで再利用したい場合は、子クラスから 親クラスのフィールドを参照し、その値を変更するのが一般的
オーバーライド時の戻り値のルール
サブクラスでメソッドをオーバーライドする際は、親クラスで定義されたメソッドと
・メソッド名
・引数の数・型・順番
・戻り値の型
がすべて一致している必要がある。
abstract class PetCreator {
public abstract PlayfulPet createPlayfulPet(); // 戻り値:PlayfulPet(親)
}
class Dog implements PlayfulPet {}
class DogCreator extends PetCreator {
@Override
public Dog createPlayfulPet() { // Dog は PlayfulPet のサブタイプ → OK!
return new Dog();
}
}
※サブタイプとは、親の戻り値型を継承・実装しているクラスの型のこと
上記の例で言うと、DogクラスはPlayfulPetクラスを継承しているため、抽象メソッドをオーバーライドするときの戻り値をDogクラスに変更することができる
→ Dog は PlayfulPet を実装している
→ Dog は PlayfulPet の一種(=サブタイプ)
戻り値をサブタイプ(子クラス)にできるのは、子クラスは親クラス(インターフェース)を内包しているから=親の型を満たしているから
is-a 関係
「〇〇は△△の一種である」という関係のこと。
オブジェクト指向プログラミング(OOP)における継承(inheritance)の基本的な考え方を示すもの
OOPの世界では、この「is-a 関係」をクラスとオブジェクトの関係に当てはめる。
あるクラスが別のクラスを継承するとき、継承元のクラス(親クラスまたはスーパークラス)との間に「is-a 関係」が成立する。
◎ サブクラス is a スーパー(親)クラス
(例)Dog クラスは Animal クラスを継承しているとする
Dog is-a Animal (犬は動物の一種である) と表現できる。
この is-a 関係によって、Dog クラスのオブジェクトは、Animal クラスの持つ属性やメソッドを受け継ぎ、自身の持つ属性やメソッドとともに利用できる。
さらに重要なのは、親クラス型の変数で子クラスのオブジェクトを参照できるということ。
上記の例では、Animal animal = myDog; というコードが成立する。
これは、「犬は動物の一種である」という関係が成り立っているから。
ただし、親クラス型の変数で子クラスのオブジェクトを参照した場合、その変数を通して呼び出せるのは親クラスで定義されたメソッドのみ。子クラス固有のメソッドは、親クラス型としては認識されないため、直接呼び出すことはできません。
is-a 関係のメリット
・コードの再利用性:親クラスで定義された共通の属性やメソッドを、子クラスで実装する必要がなくなる。
・階層的な構造:クラス間に明確な階層構造を作り出すことができ、コードの整理や理解が容易になる。
・ポリモーフィズムの実現:is-a 関係は、ポリモーフィズム(多態性)を実現するための基盤となる。親クラス型の変数で異なる子クラスのオブジェクトを扱えることで、柔軟なプログラミングが可能になる。
is-a 関係は継承によるクラス間の「種類」の関係を表す
Animal pome = new Dog(); // 例:Dogはポメラニアン
class Animal {
void speak() {
System.out.println("Animal speaks");
}
}
class Dog extends Animal {
void speak() {
System.out.println("Dog barks");
}
void wagTail() {
System.out.println("Dog wags tail");
}
}
public class Main {
public static void main(String[] args) {
Animal a = new Dog(); // 実体は Dog(例えばポメラニアン)
a.speak(); // → "Dog barks" ← オーバーライドされたメソッドが実行される
a.wagTail(); // ❌ コンパイルエラー(Animal型には wagTail が存在しない)
}
}
変数 pome の型が Animal なので、使えるメソッドは Animal クラスに定義されているものに限定される。
ただし、それらのメソッドが Dog クラスでオーバーライドされていれば、実行時には Dog 側の処理が呼ばれる。
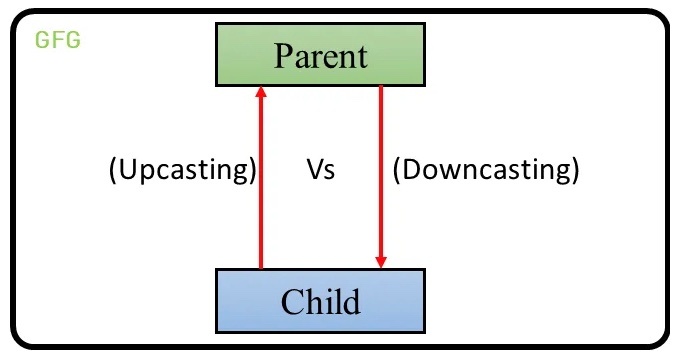
アップキャスト(upcasting)
子クラスの型を親クラスの型に暗黙的に変換すること
アップキャストは、より特化した型からより一般的な型への変換であり、子クラスは親クラスのすべての特性を備えているため、安全に行なうことができる。
ダウンキャスト(downcasting)
※https://www.geeksforgeeks.org/class-type-casting-in-java/ より画像引用
has-a 関係
has-a 関係とは、「〇〇は△△を持っている」という関係のこと。
→ あるクラスが別のクラスをメンバーとして持つこと
オブジェクト指向プログラミング(OOP)におけるオブジェクト間の関連性を示すもので、あるクラスのオブジェクトが、別のクラスのオブジェクトをメンバ変数(フィールド)として持つ場合に成立する。
これは、集約(aggregation) や コンポジション(composition) といった概念と深く関連している。
OOPの世界では、あるクラスが別のクラスのオブジェクトをその属性(フィールド)として持つときに、「has-a 関係」が成立する。
集約(Aggregation)・コンポジション(Composition)
has-a 関係は、その関連性の強さによってさらに「集約」と「コンポジション」に分けられることがある。
・集約(Aggregation): 緩やかな所有関係(例: Car が Engine を持つが、Engine は独立して存在可能)
・コンポジション(Composition): 強い所有関係(例: House が Room を持つが、Room は House なしでは存在しない)
集約(Aggregation)
「has-a」の関係が比較的弱い場合に使われる。
関連するオブジェクトは、互いに独立して存在できる。
一方のオブジェクトが破棄されても、他方のオブジェクトは存在し続ける可能性がある。
(例)「大学」は「学部」を持っている(学部がなくなっても大学は存続できる)
コンポジション(Composition)
「has-a」の関係が非常に強い場合に使われる。
関連するオブジェクトは互いに依存しており、一方のオブジェクトが破棄されると、他方のオブジェクトも通常は存在しなくなる。
(例)「自動車」は「エンジン」を持っている(自動車がなくなれば、通常エンジンも意味をなさなくなる)。
has-a 関係:オブジェクトが他のオブジェクトをメンバとして持つ「所有」または「構成」の関係
(例)「自動車はエンジンを持っている」
has-a 関係のメリット
・コードの再利用性:既存のクラスの機能を、新しいクラスの構成要素として取り込むことで、コードの再利用を促進できる。
・モジュール化:各クラスが特定の役割に集中し、それらを組み合わせてより複雑な機能を実現できるため、コードがモジュール化され、管理しやすくなる。
・柔軟性:異なるクラスのオブジェクトを組み合わせることで、様々な機能を持つオブジェクトを柔軟に構築できる。
※依存性の注入(DI)も has-a 関係になる。
ポリモーフィズム(polymorphism)
同じインターフェース(メソッド)で異なる振る舞いを実現するオブジェクト指向の重要な概念。
継承とオーバーライドを組み合わせることで実現され、プログラムの柔軟性、拡張性、再利用性を高める上で非常に重要な役割を果たす。
Javaでは 継承(Inheritance) と インターフェース(Interface) を利用して実現される。

※https://medium.com/@shanikae/polymorphism-explained-simply-7294c8deeef7 より画像引用
※https://medium-company.com/ポリモーフィズム/ より画像引用
「同じ名前の操作が、オブジェクトの種類に応じて異なる振る舞いをする」というオブジェクト指向の強力な機能。
ポリモーフィズムとは、あるオブジェクトがスーパークラスと同じ形を取る一方で、別のオブジェクトとしての特性も持つ能力を指す。
→ 異なるサブクラスのオブジェクトを同じインタフェース(メソッド)で扱える
親クラス型の変数で子クラスのインスタンスを扱うことで、多様なオブジェクトを統一的な方法で操作できるようになるのが、ポリモーフィズムの大きな利点。
ポリモーフィズムの実現方法
① 継承 + オーバーライド extends @Override
② インターフェース実装 implements interface
③ 抽象クラス abstract class abstract method`
「サブクラスは特殊な形のスーパークラスである」
親クラスの参照変数が子クラスのオブジェクトを参照することができるという性質を示している。
言い換えると、一つの型(親クラス)に対して、多くの形(子クラス)を持つことができる。
ポリモーフィズムは、サブクラスがスーパークラスのすべてのメソッドと変数を受け継ぐことを保証し、これがプログラムのコンパイラによってチェックされるため、プログラムが実行される前にサブクラスがどのような機能を持つかを事前に確認することができる。
スーパークラス型のオブジェクトが必要で、その要求をサブクラス型のオブジェクトが満たす場合も、これはポリモーフィズムの一例となる
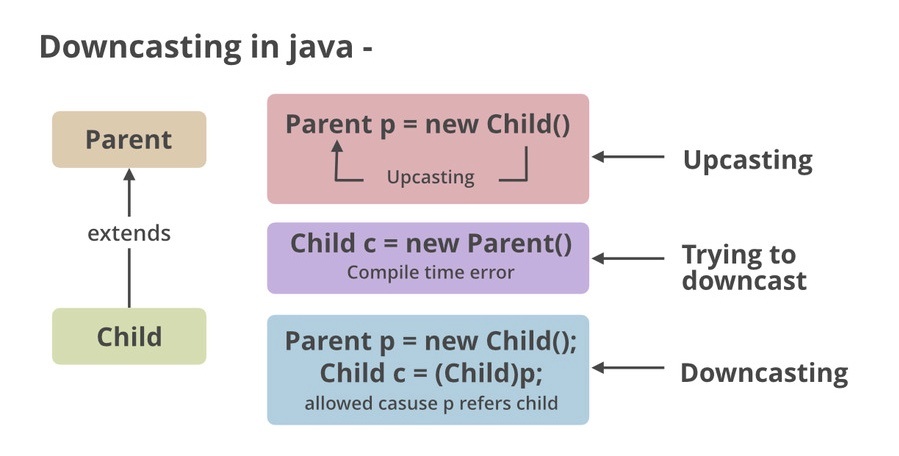
キャスティング(casting)
・スーパークラス(親)→ サブクラス(子)への変換(ダウンキャスト)
→ 明示的な変換が必要で、実行時チェックが必要。instanceof チェック必須
・サブクラス → スーパークラスへの変換(アップキャスト)
→ 常に安全で型変換不要。コンパイラが自動処理、サブクラスの独自メソッドは呼び出せない。
・インタフェースを介した型変換
オブジェクトが特定のクラスのインスタンスであるかを確認するために、instance ofというキーワードを使用することもある。
instanceof が有効なケース(使ってもOKな場合)
(1) 外部ライブラリやフレームワークの型チェック
実行時に型を判定する必要がある場合
if (obj instanceof String) {
String str = (String) obj;
System.out.println(str.toUpperCase());
}
(2) equals() メソッドの実装
equals() では、対象オブジェクトの型が一致するか確認する必要がある
@Override
public boolean equals(Object obj) {
if (!(obj instanceof MyClass)) return false;
MyClass other = (MyClass) obj;
return this.id == other.id;
}
(3) デバッグ・ログ出力
ログにオブジェクトの実際の型を出力する場合など。
System.out.println("Object type: " + (obj instanceof Dog ? "Dog" : "Cat"));
原則
・「instanceof を使いたくなったら、ポリモーフィズムで解決できないか考える」
・デザインパターン(Visitor, Strategyなど)で代替できないか検討する
オブジェクトのキャスティング(型変換)を「レンズ(視点)の切り替え」と捉える考え方は、Javaのポリモーフィズムを理解する上で非常に重要
理想:できるだけ抽象度の高いレンズで処理する
オブジェクトのキャスティング(型変換)は 「同じオブジェクトを別の型として扱う」 技術であり、「別のオブジェクトに変換する」 わけではない。
「キャスト = オブジェクト変換」ではない
→ あくまで 「同じオブジェクトを別の型の参照で見る」 だけ。オブジェクト自体は変化しない。
class Animal {
void eat() { System.out.println("動物が食べる"); }
}
class Dog extends Animal {
void bark() { System.out.println("ワンワン!"); }
}
// ケース1: Dog型のレンズ
Dog dog = new Dog();
dog.eat(); // Animalのメソッドが見える
dog.bark(); // Dog固有のメソッドが見える
// ケース2: Animal型のレンズ
Animal animal = dog; // アップキャスト(暗黙的)
animal.eat(); // OK
animal.bark(); // コンパイルエラー!Animalレンズではbark()が見えない
・Dogレンズ:Animalの全機能 + Dog固有機能が見える
・Animalレンズ:Animalの機能のみ見える(Dogの拡張部分は「隠れる」)
※ダウンキャスト時の注意点
Animal animal = new Dog();
// ダウンキャスト(明示的変換が必要)
if (animal instanceof Dog) {
Dog dog = (Dog) animal; // Animalレンズ→Dogレンズに変更
dog.bark(); // これで見えるようになる
}
・ClassCastExceptionのリスクあり
・instanceofチェックが必須
・レンズの視野を「無理やり広げる」操作
キャストが成功するのは以下のとき
・アップキャスト(子→親): 常に安全
・ダウンキャスト(親→子): 元のオブジェクトが実際にその型である場合のみ可能
キャストは「フィルター」:オブジェクトに被せる型の「レンズ」で見える範囲が変わる
メソッド呼び出しの2段階チェック
・コンパイル時:参照型で使えるメソッドを制限
・実行時:実際のオブジェクトのメソッドを呼び出し
設計におけるベストプラクティス
① レンズは必要最小限
② キャストが必要な設計は再考
・キャストが頻繁に必要=設計の不備の可能性
・ポリモーフィズムやVisitorパターンで代替できないか検討
③ レンズの切り替えコスト
・階層が深いほどキャストのリスク増大
フィールドのメモリ配置
・スーパークラスのフィールド(age)→ 先頭に配置
・サブクラスのフィールド(breed)→ その後に追加
・これが「連続したアドレス」の正体
メソッドの扱い
・メソッド本体はメソッドエリアに1回だけ格納
・各オブジェクトはvtable(仮想メソッドテーブル)へのポインタを持つ
・継承関係はvtableのチェーンで表現
オブジェクトヘッダー
全てのオブジェクトの先頭にはクラス情報へのポインタが存在
同一メモリ内にそのオブジェクトのスーパークラスの情報が同じヒープ領域の中に格納されているため、同じオブジェクトに対して型変換をして別の型で当該オブジェクトを見ることができる
→ サブクラスオブジェクトは、スーパークラス部分を含む「1つの連続メモリ領域」に格納される
→ キャストは「同じメモリ領域を別の型として解釈」するだけ
→ 実際のオブジェクトは不変で、ヘッダーに元のクラス情報を保持
[0x123: Dogオブジェクト]
├─ **ヘッダー** (クラス情報/GCHistoryなど)
├─ **Animal部分** (スーパークラス)
│ └─ age = 0 (デフォルト値)
└─ **Dog部分** (サブクラス)
└─ name = null (デフォルト値)
コンパイル時には、オブジェクトが特定のクラスを継承しているかどうかだけを検証し、その結果に基づいて全てのメソッドが実行可能かを判断する。
しかし、継承のチェーン内でどのメソッドを実行するかは、動的バインディングルールによって決まる。
変数を定義する際には、その変数に型を割り当て、その型に対応する任意のクラス、あるいはそのクラスを継承したクラスのオブジェクトをその変数に格納することができる。
メソッドを実行時に呼び出す場合には、動的バインディングが適用される。
動的バインディング Dynamic Binding
プログラムの実行時(ランタイム)に、呼び出すべきメソッドや関数を決定する仕組みのこと。
「遅延バインディング(Late Binding)」とも呼ばれる。
動的バインディングのイメージ
例えば、親クラスとそれを継承した複数の子クラスがあり、それぞれ同じ名前のメソッドを持っているとする。どのオブジェクトのメソッドを呼び出すかは、プログラムの実行時に、実際にその変数がどのクラスのインスタンスを指しているかによって決まる。
継承とポリモーフィズム(プチまとめ)
※https://xtech.nikkei.com/atcl/nxt/column/18/00208/031300003/ より画像引用
継承
あるクラスがスーパークラスから全てのコードを受け継ぐという原則。
これにより、サブクラスはスーパークラスで定義された状態とメソッドをそのまま引き継ぎ、必要に応じて上書きすることができる。
したがって、ある関数がクラス C のオブジェクト O を引数として受け取る場合、O は C で定義された全てのメソッドを保持することが確定される。
ポリモーフィズム
ポリモーフィズムでは、オブジェクト O はクラス C またはそのサブクラスのインスタンスとなる。
継承の性質により、O は C で定義された全てのメソッドを持つと保証されている。
具体例として、Van と Truck が Vehicle を拡張する場合、Van も Truck も Vehicle で定義されている全てのメソッドを継承する。実行時に、O の特定のメソッドが呼び出されると、コンピュータは動的にバインディングし、適切なメソッドを選択する。
※動的バインディングとは、プログラムの実行時に「どのメソッドを呼び出すか」を決める仕組み
プログラムは「この子は“動物”ですよ」って言っておいて、実際の鳴き方(= 実際の動作)は、そのときの正体(= 本当のクラス)に合わせて決まる
※静的バインディング:最初から決まってる動作しかできないということ。
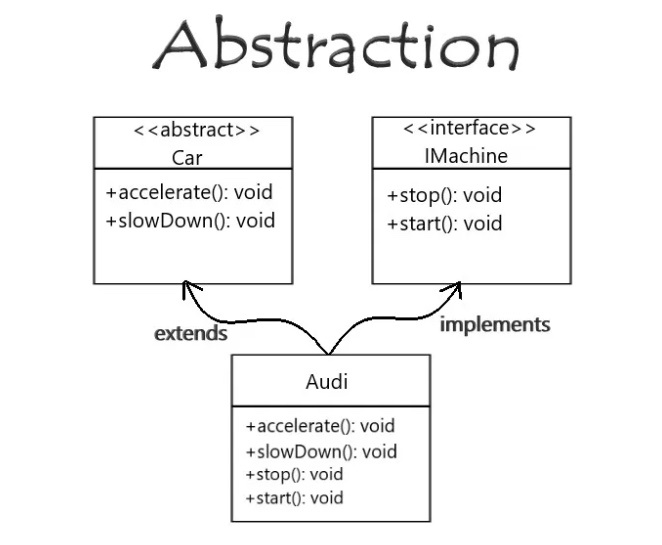
抽象クラスとインターフェース
・抽象クラスは「共通の処理(中身)を持つ」
→ 「どう動くか」をある程度決めている。
・インターフェースは「共通の機能(名前や契約)だけを持つ」
→ 「何ができるか」だけを定義して、どう動くかは任せる。
目指すべきは、抽象化の設計と、クラスが保持すべきメソッドのセットの定義。
これは UML 図を描くようなもので、直接コードに反映する必要はなく、むしろ設計の柔軟性を向上させ、抽象型を作り出すことができる。
抽象化の一例としてリストがある。
これは、要素の追加、削除、取得といった操作が可能な順序付きシーケンスの抽象化である。
具体的な実装例としては、固定配列、動的配列、片方向リスト、双方向リスト、特定の走査を持つ二分木などがある。
その次には、ジェネリクスを通じて、更なる抽象化の方法について学ぶ。
これにより、プログラムの実行前に構文チェックを行ないつつ、データのプレースホルダを作成し、より汎用的な抽象化を達成することが可能となる。
インターフェースと抽象クラスの違い
| 項目 | インターフェース | 抽象クラス |
|---|---|---|
| 継承キーワード | implements | extends |
| 継承元の数 | 複数可 | 1つだけ |
| メソッドの中身 | 書けない(定義だけ) | 書ける(具体的な処理もOK) |
| 実装義務 | すべてのメソッドを実装 | 抽象メソッドのみ実装すればOK |
| 共通処理の定義 | 不可 | 可能 |
| 目的 | 「共通の契約(インターフェース)」 | 「共通の機能の再利用 + 一部強制実装」 |
インターフェースと抽象クラスの使い分け判断ポイント

※ChatGPTより引用
・インターフェース
→ 契約書だけ渡して“何をすべきか”だけ決める
→ 「複数の役割」を持たせたいとき
・抽象クラス
→ テンプレを渡して“こう動かす”も共有する
→ 「ベースとして動きを持たせたい」とき
抽象クラス(abstract class)
UML において、抽象クラスはイタリック体でクラス名を表示することで表現される。
※https://stackoverflow.com/questions/62252353/uml-to-java-code-abstract-class-simple-association-methods より画像引用
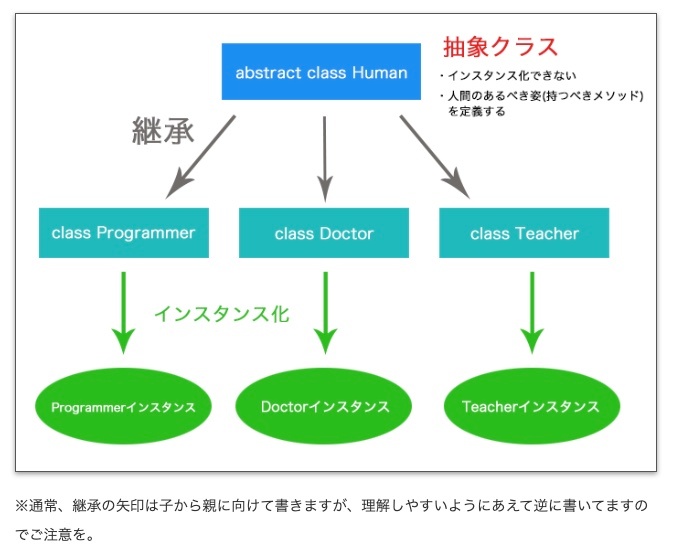
※https://nobuo-create.net/java-beginner-29/ より画像引用
クラス間の継承関係は、枝分かれした木構造を形成する。
木の根となるのは、大抵の場合、汎用的な抽象クラス(abstract class)となる。この抽象クラスから派生する具象サブクラスは、基本的な機能を拡張し、特化した形を持つことになる。
これにより、根ノードから葉ノードに向かうほど具体性が増し、逆に葉ノードから根ノードに向かうほど抽象性が高まる構造が出来上がる。
抽象クラスとは、一部または全てのメソッドが未実装のクラスのことを指し、具象クラスと対比させる形で理解するとより明確になる。
具象クラス concrete classはその名の通り、具体的な実装を持つクラスで、全てのメソッドが具体的な振る舞いを定義している。
例えば、Animals という抽象クラスは move() や die() というメソッドを定義しているが、具体的な動作の内容は、それを継承する具象クラスにより定義される。
重要なのは、抽象クラスが具体的な実装を持たず、一部または全てのメソッドが未実装であるという事実。これにより、抽象クラスはインスタンス化することができませんが、具体的な振る舞いを持たない一方で、共通の振る舞いや属性の概念を提供する。
抽象クラスは、具体的な実装を持たない一部の抽象メソッドを含むクラスで、これらはサブクラスで実装を行なう必要がある。
抽象クラスを定義するには、abstract というキーワードを使用する。
このキーワードは、クラスが全てのメソッドを実装していないこと、そしてそのクラスのインスタンスを直接作成できないことを示している。
この抽象クラスを用いることで、複数の異なるクラスが共通のインターフェースや動作を共有でき、それぞれが異なる具体的な動作を提供できる。これにより、コードの再利用性と柔軟性が大幅に向上する。
抽象クラスのルール
オブジェクト指向プログラミングにおける抽象クラスの使用には、一連の基本原則が存在する。
これらの原則を把握することで、抽象クラスの利用法をより深く理解し、より効果的なプログラミングが可能になる。
Rule 1
抽象クラスは、Java のようなプログラミング言語における特別なタイプのクラス。この不完全なメソッドは抽象メソッドと呼ばれ、クラスの中で abstract キーワードが使用される必要がある。
Rule 2
抽象クラスから直接オブジェクトを作成することはできない。
抽象クラスのメソッドを使うには、抽象クラスを継承した別のクラスを作る必要がある。この新しいクラスはしばしば具象クラスと呼ばれる。具象クラスには、抽象クラスの抽象メソッドに足りないコードを含める必要がある。
Rule 3
抽象クラスでは、状態を定義しデフォルト値を割り当てることができる。
さらに、状態を初期化するコンストラクタも定義できる。このコンストラクタは、サブクラスから呼び出されることが一般的。サブクラスがこれらの状態にアクセスできるように、状態を protected として設定することが推奨される。
Rule 4
特定の言語では、抽象メソッドを持たない抽象クラスを定義することが許可されていることがある。
これによって、他のプログラマに、このクラスは親クラスであることを示すことができる。
言い換えれば、サブクラス化することを強制する抽象メソッドがなくても、抽象クラスとして宣言されているという事実は、使用する前にサブクラス化されるべきであるというシグナルである。
こうすることで、コード内の特定のクラスが常に基底クラスとして使用され、オブジェクトを直接作成するために使用されないようにすることができる。これは良いコーディング設計の一部であり、コードの構造と構成を維持するのに役立つ。
Rule 5
抽象クラスを継承した具象クラスで、すべての抽象メソッドのコードを実装しなかった場合、そのクラスも抽象クラスとなり、オブジェクトを直接作成するために使用することはできない。
Rule 6
具象クラスを継承したサブクラスを作成し、その内部で抽象メソッドを定義するか、親クラスのメソッドを抽象メソッドとして上書きすることで、サブクラスを抽象クラスにすることができる。
継承のルールは「is-a」の関係を保持する必要があり、これは抽象クラスにも同じく適用される。
共通処理は抽象クラスに任せ、変化する部分だけ子クラスに作らせることで、無駄なコード重複を防ぐことができる
抽象クラスが推奨されるケース
・共通の実装を提供したいが、一部の処理は子クラスに任せたい場合
・インスタンス化を禁止したい場合(new AbstractClass() を防ぐ)
抽象構造体
ソフトウェア設計の初期段階では、具体的なコードの実装に先立ち、アイデアを抽象化することに注力する。同じデータ構造でも、その利用目的や時間計算量、空間計算量によって、異なる実装方法が適用される。このような理由から、アイデアを抽象化し、状況に応じて適用することが推奨されている。
このコンテクストにおいて、抽象クラスは大変役立つ。
これは、具体的な実装の詳細や必要なパターンを全て把握することなく、データ構造の一般的な状態や動作を先に定義できるため。各具体的な実装は全く異なる可能性があるが、それらは常に抽象クラスによって定義された型として扱われる。
インターフェース(interface)
クラスが実装すべきメソッドの契約(約束事)を定義する仕組み
「何をできるか(What)」を定義し、「どう実装するか(How)」は委ねる抽象的な型。
具体的な実装を持たず、メソッドのシグネチャ(名前、引数、戻り値の型)のみを宣言する。
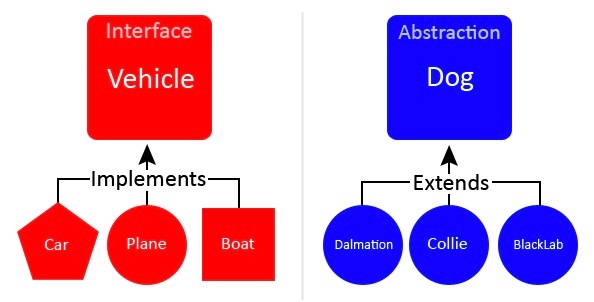
※https://wimsonevel.blogspot.com/2016/03/konsep-oop-interface.html より画像引用
オブジェクトが実装しなければならない一連の振る舞いを定義したもの。
インターフェースには抽象メソッドのみが含まれ、それらのメソッドはインターフェースを実装するクラスで使用される。
implements(インプリメンツ)は、クラスが「インターフェースを実装する」こと。
インターフェースを使用する理由は、データ型をデータ構造ではなく、オブジェクトが有する振る舞いによって宣言するため。
ここではポリモーフィズムのルールが適用され、オブジェクトは指定されたインターフェースの形状になる。オブジェクトがインターフェース I のものであれば、そのオブジェクトは I によって指定されたすべての振る舞いを実装していることが保証される。
「Can-Do」(〜できる)関係に適する。
インターフェースは継承や構成とは異なり、密接な関係性なしに振る舞いを指定するために使用される。
つまり、インターフェースはクラスが共有すべき共通の振る舞いを定義するが、クラスが何かを共有する必要性はない。クラスが持つべきものはインターフェースで定義された振る舞いだけ。
コンポジションは通常、has-a の関係(人は BMI と名前を持つ)を持ち、
継承は is-a の関係(キツネは哺乳類で、哺乳類は動物である)を持つが、
インターフェースは契約ベースの関係(ヘリコプターと鷲は Fly を実装するため、飛ばなければならない)を持つ。
契約とは、オブジェクトが特定のインターフェースとみなされるために何をしなければならないかを意味する。
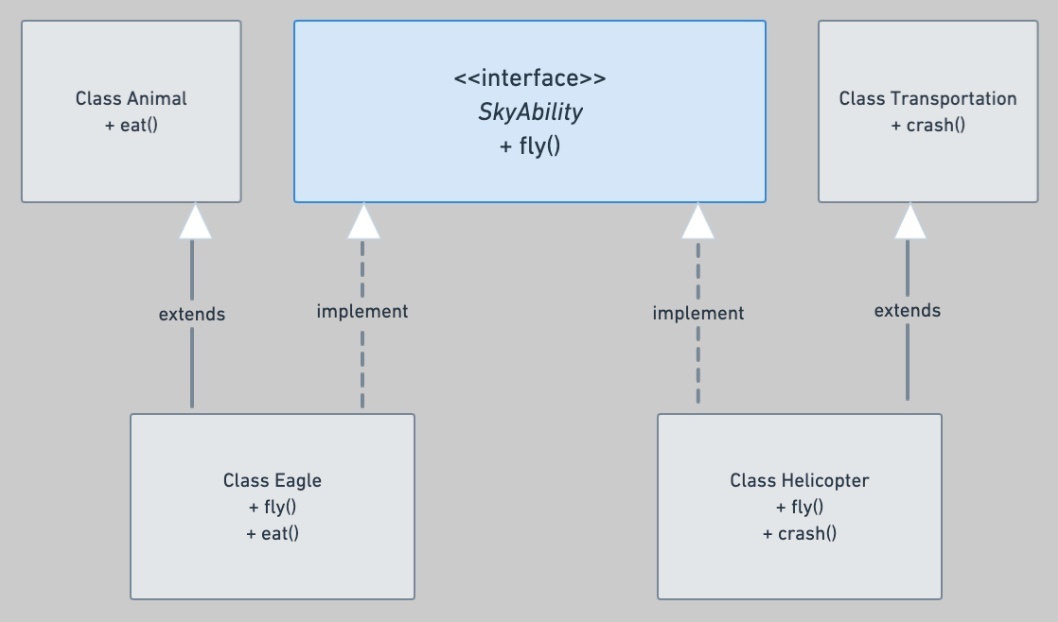
※https://recursionist.io/dashboard/course/4/lesson/610 より画像引用
インターフェースの核心的なメリット
(1) ポリモーフィズム(多態性)の実現
インターフェースを介して、異なるクラスを同じ型として扱えます。
Animal[] pets = { new Dog(), new Cat() };
for (Animal pet : pets) {
pet.speak(); // それぞれの実装が呼ばれる
}
→ 「犬も猫もAnimalとして扱える」という柔軟性。
(2) クラス間の疎結合(Decoupling)
インターフェースは「依存関係を抽象化」する。
(例)データベース接続のインターフェースを定義すれば、MySQL実装とPostgreSQL実装を切り替え可能。
テスト時にはモック(偽装実装)に差し替えることも容易。
(3) 契約プログラミング
「このインターフェースを実装するなら、必ずこれらのメソッドを用意せよ」というルールを強制。
(例)Comparableインターフェースを実装すれば、オブジェクトの並び順を定義できる。
| 項目 | 抽象クラス | インターフェース |
|---|---|---|
| 継承/実装 | 単一継承のみ | 多重実装可能 |
| メソッド | 抽象+具象メソッドOK | 原則的に抽象メソッドのみ |
| フィールド | 普通の変数を持てる | 定数(public static final)のみ |
| 用途 | 「共通機能の再利用」が目的 | 「クラスの振る舞いの契約」が目的 |
| 例 | Animal → Dog(「動物」の基本機能あり) | Runnable(「実行可能」という約束) |
抽象クラスが向くケース:複数の子クラスで共通の処理や状態を持たせたいとき
インターフェースが向くケース:全く異なるクラス群に同じ振る舞いを強制したいとき
◎共通の土台作りには抽象クラス、柔軟な機能追加にはインターフェース
インターフェースを使用することで、異なるクラス間で共通のメソッド(この場合は音を出す振る舞い)を保証することができる。
また、インターフェースを型として使用することで、異なるクラスのオブジェクトを一貫した方法で扱うことができる。これは、ポリモーフィズムというオブジェクト指向プログラミングの重要な原則を示している。
インターフェース設計のベストプラクティス
単一責任の原則(SRP): 1つのインターフェースは1つの役割だけ持つ。
悪い例: UserService(認証+ログイン+プロファイル管理)
良い例: AuthService, ProfileService に分離。
クライアントに必要なものだけ公開: インターフェースを小さく保つ。
名前は「〜able」や「〜Handler」など役割を明確にする(例: Runnable, Comparable)。
インターフェースは「振る舞いの契約」を定義し、以下の力を発揮する
・ポリモーフィズムによる柔軟な設計
・疎結合で変更に強いシステム構築
・テスト容易性の向上(モック活用)
「抽象クラス」との使い分けや、defaultメソッドなどの進化した機能も押さえておくこと
インターフェースについての重要な点
インターフェースは振る舞いだけを指定し、状態を指定することはできない。
インターフェースによって指定された振る舞いは抽象メソッド。
これらはインターフェースを実装するクラスが定義して実装しなければならない関数名として扱う。
インターフェースは抽象メソッドだけから構成される。
インターフェースには抽象メソッドのみが許可されているため、抽象クラスとは大きく異なる。
抽象クラスでは、状態を指定したり、一部のメソッドを実装したり、一部のメソッドを抽象化したりすることができる。
クラスが実装できるインターフェースの数に制限はない。
つまり、Car は Audible, Drivable, Vehicle, Product などのインターフェースを実装することができる。
特定のインターフェースを実装するオブジェクトは、インターフェースで指定されたメソッドを実装しなければならないという契約を結ぶこと以外、何も共通点を持つ必要がないことを覚えておいておこう。
※インターフェースは「契約」であり、強制ではない
オブジェクト指向プログラミング(OOP)は、概念の抽象化とコードの再利用性も重視する。
コードの再利用性を持つために、リスト構造をあらゆる種類のオブジェクトのコンテナとして使いたいところ。
Javaにおいて、抽象クラスを継承しつつインターフェースを実装する場合の記述方法
extends(継承)と implements(実装)を同時に使用するが、構文の順序に注意が必要
// 抽象クラスとインターフェースの定義
abstract class 抽象クラス名 { /* ... */ }
interface インターフェース名 { /* ... */ }
// 継承と実装を同時に行うクラス
class 具象クラス名 extends 抽象クラス名 implements インターフェース名 {
// 抽象クラスのメソッドとインターフェースのメソッドを実装
}
ルール
・extends が先、implements が後(順序を逆にするとコンパイルエラー)
・抽象クラスの抽象メソッドとインターフェースの全メソッドを実装する必要あり
・複数のインターフェースを実装する場合はカンマ区切りで列挙可能
抽象クラスとインターフェースでメソッド名が衝突した場合、抽象クラスの実装が優先される(defaultメソッドを含む)。
インターフェースのdefaultメソッドは、オーバーライドしなくても利用可能。
ただし、複数のインターフェースでdefaultメソッドが衝突する場合は、明示的なオーバーライドが必要。
抽象クラスのコンストラクタはsuper()で呼び出し必須(インターフェースはコンストラクタを持たない)。
設計上のアドバイス
抽象クラス
・共通の状態(フィールド)や処理(メソッド)を提供したい場合に使用。
・is-a関係(例: Penguin is an Animal)を表現。
インターフェース
・複数の振る舞い(Swimmable, Flyable)を横断的に追加したい場合に使用。
・has-a関係(例: Penguin has a Swimmable ability)を表現。
使い分け基準
・「何であるか(本質)」 → 抽象クラスで表現
・「何ができるか(振る舞い)」 → インターフェースで表現
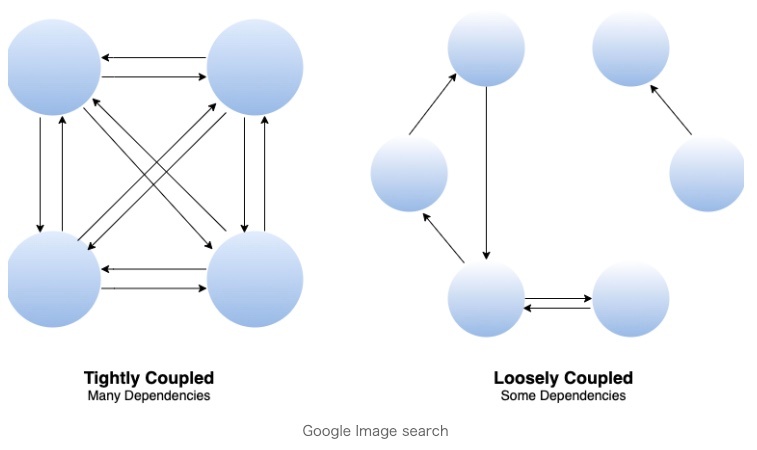
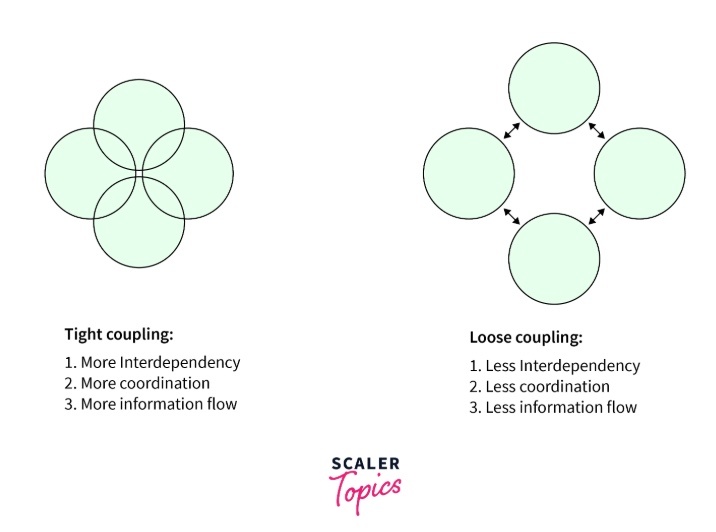
クラスの疎結合(Loosely Coupled)
クラス同士の依存関係を最小限に抑え、「変更に強く、再利用しやすい設計」を指す重要な概念。
※https://www.linkedin.com/pulse/loosely-coupled-strongly-cohesive-microservices-kumar-srinivasan より画像引用
疎結合(Loosely Coupled)の定義
「クラスAがクラスBに依存する際、Bの内部実装の変更がAに影響を与えない状態」を意味する。
逆に密結合(Tightly Coupled)な設計では、クラス同士が直接依存し合い、一部の変更が全体に波及する。
実現にはインターフェース、DI、ファクトリパターンなどの手法が有効。
「依存方向を抽象に向ける」という原則が鍵
疎結合が重要な理由
・変更に強い: 依存先クラスの実装変更やバグ修正が、依存元に影響しにくい。
・テスト容易性: モック(偽装オブジェクト)を使った単体テストが容易。
・再利用性: 部品(クラスやモジュール)を他のプロジェクトで流用しやすい。
Loose Coupling vs. Tight Coupling in Java
※https://www.scaler.com/topics/coupling-in-java/ より画像引用
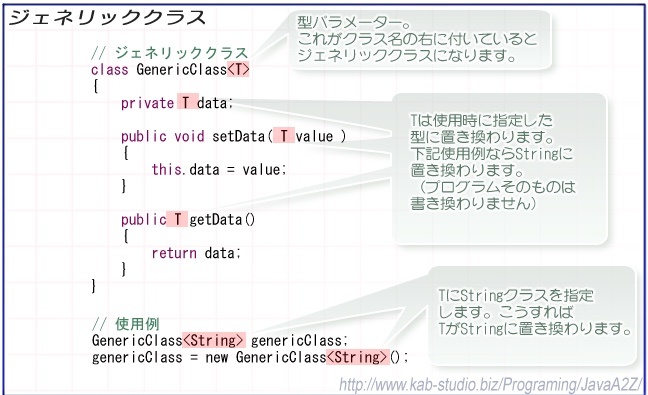
ジェネリクス(generics)
※http://www.kab-studio.biz/Programing/JavaA2Z/Word/00001111.html より画像引用
ジェネリクスは、クラスが変数や入力として一般的なデータ型を宣言することを可能にする。
「型」をパラメータ化することで、安全性・再利用性・柔軟性を同時に実現する。
そして、特定のクラスの下でオブジェクトがインスタンス化されるとき、コンパイル時の構文チェックがエラーを検出するために実行される。
これが意味することは、コンテナとして機能するような構造(例えば、スタック)を作成する場合、まずデータ入力と状態をジェネリクスとして定義できるということ。
スタックがインスタンス化されるとき、特定のクラスが宣言され、コンパイル時の構文チェックが行われます。これにより、単一の汎用なスタック構造を定義するだけで、Integer 用の Stack<Integer>、Character 用の Stack<Character>、Double 用の Stack<Double>、または Animal 用の Stack<Animal> を持つことができる。
ジェネリクスはインターフェースにも使用することが可能。インターフェースは抽象メソッドのみから構成されるため、そのメソッドが取り扱うデータ型をジェネリクスにすることで、一般化することが可能。
インターフェースをより抽象化することができる。
主なメリット
① タイプセーフティの向上(型安全性)
●コンパイル時の型チェック
ジェネリクスを使用すると、コンパイル時に型の不一致を検出できるため、実行時のクラスキャスト例外などを防ぐことができる。
(例)List<String> と宣言すれば、文字列以外の要素を追加しようとした時点でエラーがわかります。
●キャストの削減
明示的な型キャストが不要になり、コードが簡潔になる。
・非ジェネリックコード: String s = (String) list.get(0);
・ジェネリックコード: String s = genericList.get(0);
② コードの再利用性向上
●汎用的なクラス/メソッドの作成
異なる型で同じロジックを再利用できる。
(例)List<T> は T が String でも Integer でも動作する
●アルゴリズムの抽象化
型に依存しないアルゴリズムを記述できる(例: ソートや検索)
③ 抽象化と設計の柔軟性
●インタフェースや抽象クラスとの組み合わせ
ジェネリクスを活用することで、より汎用的な設計が可能になる。
(例)Comparable<T> インタフェースは、比較可能な任意の型を表現できる
●依存性注入(DI)など
フレームワークでジェネリクスを利用すると、型安全な依存関係を注入できる。
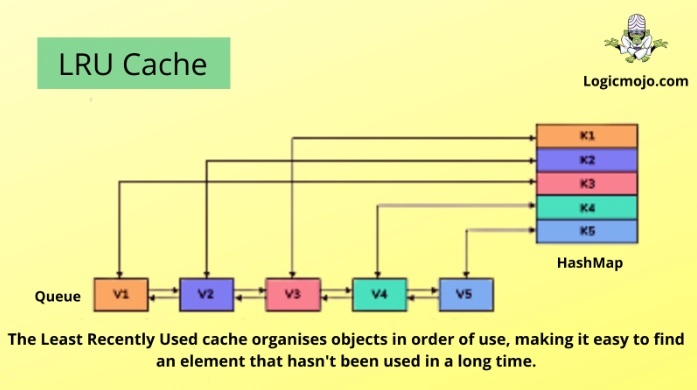
LRU キャッシュ
参考URL:https://www.enjoyalgorithms.com/blog/implement-least-recently-used-cache
高度なシステム設計、特にサーバやオペレーティングシステムの構築においては、メモリとディスクストレージとの間で一連の問題が頻発する。
この問題を理解するためには、まず二つの技術の基本的な特性を理解する必要がある。
メモリとストレージ
メモリの性質
・素早いデータアクセスを可能にする
・容量は限定的
・コストが高い
・電源を断つとデータが消失する(揮発性の特性)を持っている
ディスクストレージの性質
・大容量でコスト効率が良い
・電源を切ってもデータが保持される(永続性を備えている)
・データの読み書きに時間がかかる
一秒間に多くのデータにアクセスする必要がある場合、帯域幅の観点から見ると、メインメモリのアクセス速度は最新の SSD ストレージデバイスと比較しても 10 倍以上の速さがある。
さらにレイテンシ、すなわち単一のデータアクセスに必要な時間を考えると、この差は更に大きくなる。
例えば、メモリ上のデータへのアクセスには 50 ナノ秒かかるのに対し、SSD では 50 マイクロ秒、つまり 1000 倍の時間が必要となる。
それは RAM はバイト単位でアクセスできるのに対し、ストレージはデータをブロック単位でアクセスしなければならないため、このような時間の差が生じる。
SSD とメモリとの比較だけでなく、プロセッサの内部にあるキャッシュメモリについても視野に入れると、データアクセスの速度差はさらに顕著となる。
CPU に組み込まれている L1 キャッシュや L2 キャッシュは、本体から僅かな距離しか離れていないため、これらのキャッシュからのデータ取得は、メモリからのそれよりも遥かに速い。
具体的には、L1 キャッシュからはメモリアクセスの数百倍、L2 キャッシュからはメモリアクセスの数十倍の速度でデータにアクセスできる。
※ https://elite-lane.com/cache-memory/ より画像引用
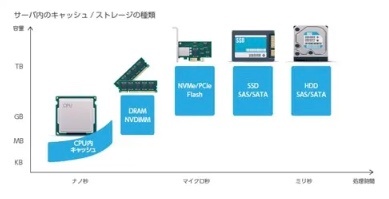
※ https://tintri.co.jp/news/flash-storage_tintri-2/ より画像引用
多くのアプリケーションのパフォーマンス向上には、メモリキャッシュが極めて重要であると言える。
しかし、メモリが物理的に保有できるデータ量には限界があるため、すべてのデータをメモリにキャッシュすることは現実的ではない。
そこで、この問題を効率的なアルゴリズムを利用して、ソフトウェアのレベルで解決する方法が求められる。
データをメモリにキャッシュすることにより、CPU がストレージからメモリにデータを移動させるよりも先に、メモリ上のデータにアクセスできる。
初めに、キャッシュに割り当てるメモリ容量を設定する。
キャッシュが満杯になった場合、新たなデータを追加するスペースを確保するために、既存のキャッシュデータの中から何を削除するかを決定する必要がある。
LRU キャッシュ
※https://qiita.com/grouse324/items/8c7c48b17c4fbf246f44 より画像引用
※https://andrelucas.io/how-to-implement-the-lru-cache-algorithm-32ccb00da4f9 より画像引用
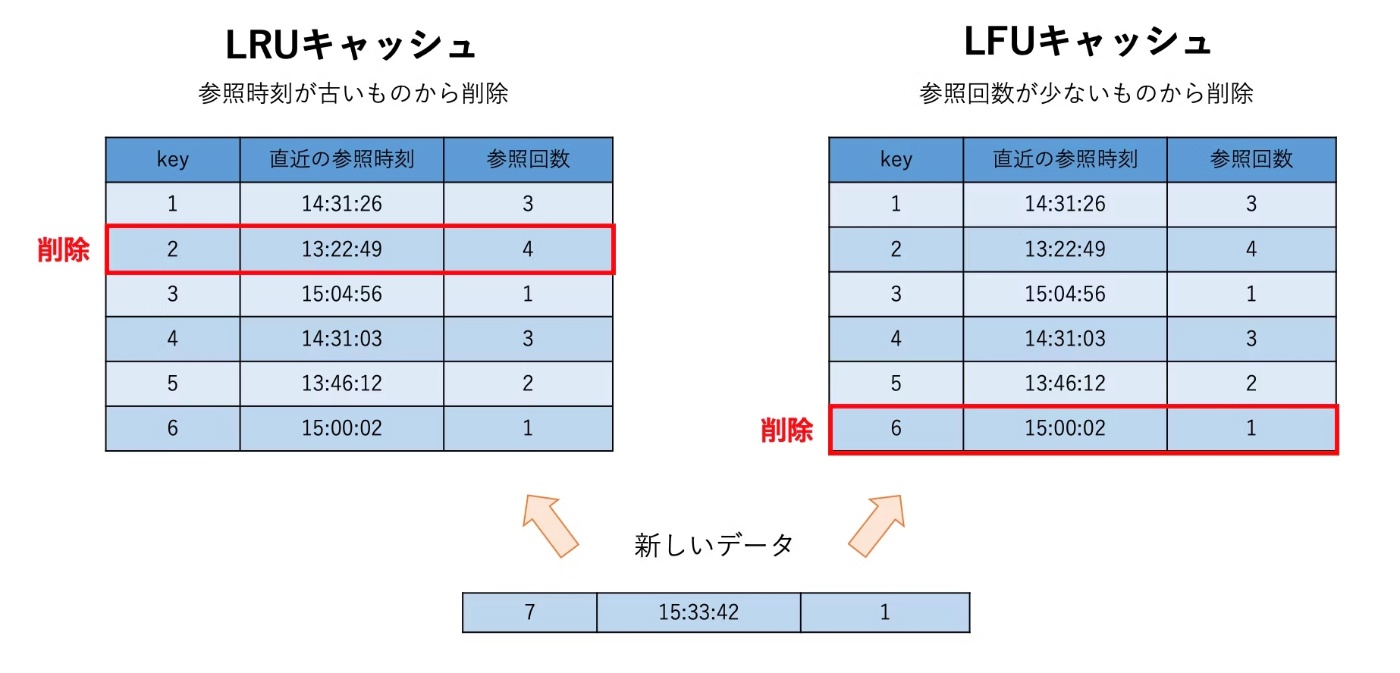
この問題に対する解決策として、いくつかのキャッシュアルゴリズムが開発されており、中でも特に広く利用されているアルゴリズムの一つが、Least Recently Used (LRU) キャッシュ。
LRU(Least Recently Used)キャッシュは、キーをインデックスや文字列で表現し、データは get(key) や put(key, data) のような操作を介して取得できる。
なお、このキャッシュ内のキーはすべてが一意となる。
LRUCache(int capacity)
このコンストラクタは、新しい LRU キャッシュのインスタンスを生成する。
ここでの capacity は、キャッシュが保持できる最大のエントリ数(キーとデータのペアの数)を指定する。
get(key)
指定されたキーのデータを返す。もしキャッシュに該当するデータが存在しなければ null を返し、データを取得した場合は、そのキーが最近使用されたことを示すためにキャッシュの状態を更新する。
put(key, data)
キーとデータの組を受け取り、その組をキャッシュに追加する。
既に同じキーが存在する場合は、そのキーのデータ部分を新しいデータで上書きする。
また、キーが存在せずキャッシュが既に最大容量に達している場合、新たにデータを追加するためにキャッシュ内の既存のキーとデータの組を削除する。この際、キーとデータがキャッシュに追加されると、そのキーは最新の使用状況を反映するように更新される。
このキャッシュは読み取りと挿入を O(1)、空間計算量を O(n) で実行できる必要がある。
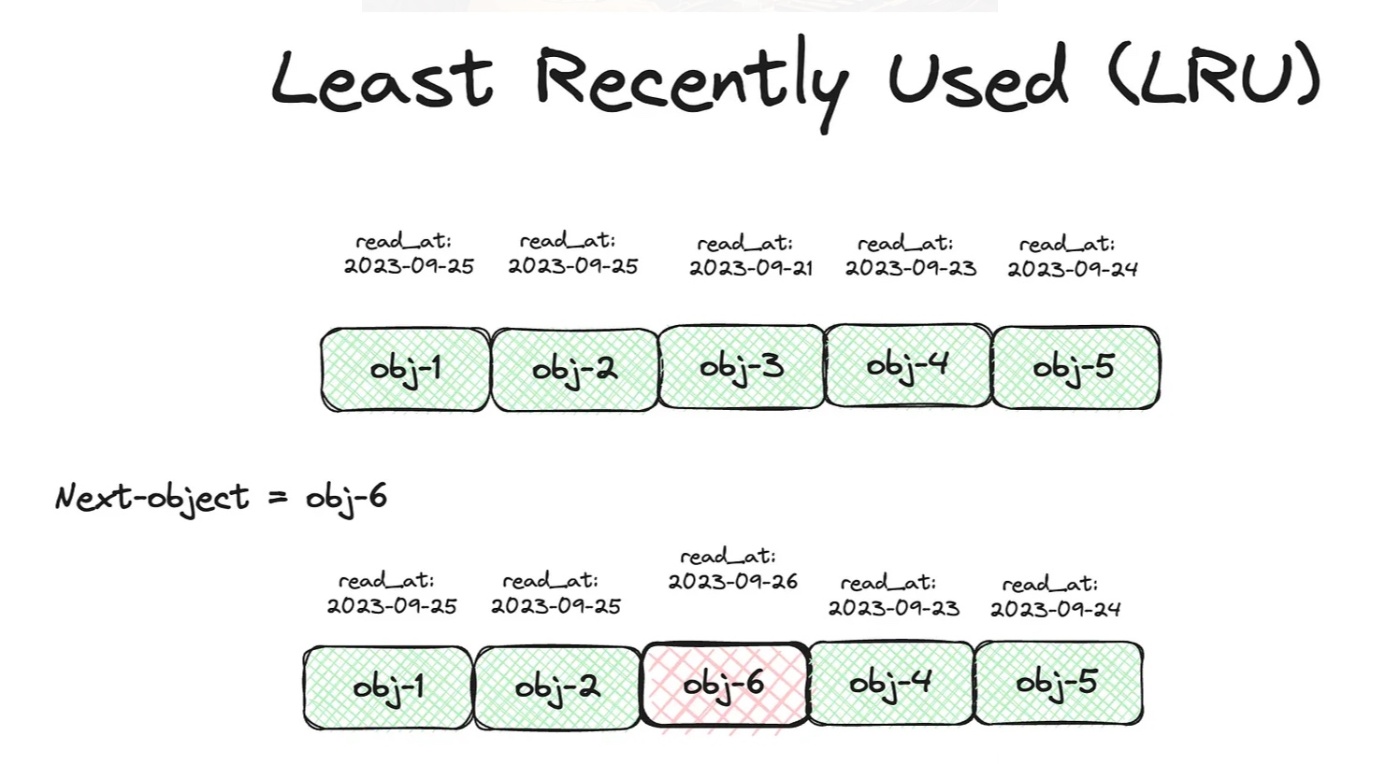
LRU キャッシュでは、最も古くに使用されたデータ(最初に使用されたキー)を最初に削除するため、キーの使用順序を保持する必要がある。
そのためには、使用された順序にキーを並べたリスト(ノードリスト)を作成し、そのリストの先頭に最初に使用されたキーを、末尾に最後に使用されたキーを置くように管理する。
キーがアクセスされるたびに、そのキーをリストの末尾(最新の使用位置)に移動させる必要がある。
これにより、リストの先頭側には常に最も古くにアクセスされたキーが、末尾側には最も新しくアクセスされたキーが配置される状態が保たれ、LRU の原則が実現される。
双方向リスト
ここで、双方向リストが最適なデータ構造となる。
これにより任意のノードを O(1) で削除することが可能になる。
ただし、双方向リストでは任意のノード X にアクセスするためにはリスト全体を走査しなければならず、これは O(n) の計算量を要する。
しかし、配列を用いることで任意のノードに O(1) でアクセス可能になる。
配列のインデックスはキーとなり、その配列のスロットには該当キーの双方向リストのノードが格納される。このノードはキーとデータを含み、配列内の位置を O(1) で確認可能。配列のインデックスが null の場合、それはそのキーが存在しないことを示す。
最も新しく使われたノード、つまり双方向リストの先頭を削除する場合、そのキーを持つ配列スロットは null に設定する。
このように、インデックスへのアクセスや挿入・削除が O(1) で可能となり、get(key) や put(key, data) もそれぞれ O(1) の計算量で実行できるようになる。
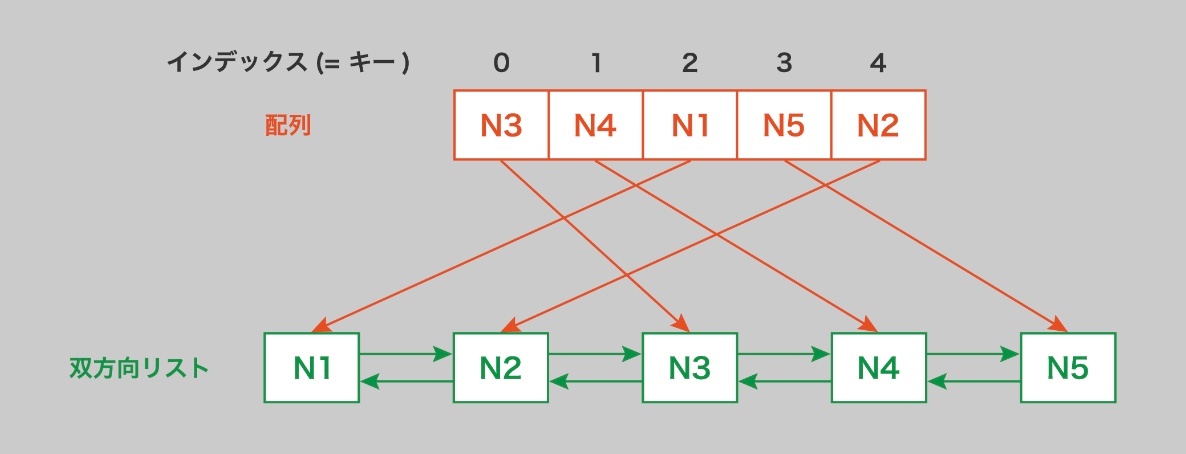
※ https://recursionist.io/dashboard/course/4/lesson/644 より画像引用
今回採用したデータ構造は、いくつかの明確な限界が存在する。
その中で、特に重要な3つの制約
1 つ目の制約:データ保存領域としての配列の大きさが固定となっている点
これは、配列が事前に定められた大きさを超えて拡張することができないということを意味する。
つまり、配列の大きさは設定時に固定され、それ以上のデータを保存する余地は存在しない。
2 つ目の制約:このデータ構造が配列と双方向リストの 2 つを同時に保持するために、それぞれのデータ構造を維持するためのメモリが必要となる点
これにより、このデータ構造を利用するためには、それぞれのデータ構造に対応したメモリスペースが常に必要となる。
3 つ目の制約:データ構造が一度構築された後にはその容量が変更不可能である点
特に、容量を変更する際には、すべてのデータを再配置し直すために、データ量(n)に比例する時間が必要となる。
配列の大きさは固定である一方で、双方向リストのサイズ(つまり双方向リストに保存されているデータの数)は、その時点でキャッシュされているアイテムの数により変動する点に注意すること。
帯域幅(Bandwidth)
帯域幅(Bandwidth)の概念は、ネットワーク通信だけでなく、メインメモリ(DRAM)へのデータアクセスにも適用できる重要な考え方。
「データの通り道の能力」とイメージできる。
ただし、その文脈での具体的な意味合いや影響は異なる。
メインメモリアクセスにおける「帯域幅」の定義
メモリ帯域幅(Memory Bandwidth)とは、CPUがメインメモリ(DRAM)から単位時間当たりに読み書きできるデータ転送量の最大値を指す。メモリ帯域幅 = CPUとDRAMを結ぶ「データの道路」
単位: GB/s(ギガバイト毎秒)
(例: DDR4メモリの帯域幅は約25~50GB/s)
「帯域幅がボトルネック」とは、CPUがメモリからデータを必要とする速度に対して、メモリの供給が追いつかない状態を指す。
データ転送能力に違いがある
・高帯域幅: 一度に大量のデータを転送可能(例: DDR5メモリ → 高速な多車線道路)。
・低帯域幅: データ渋滞が発生し、CPUが待機状態(例: 古いDDR3メモリ → 渋滞しやすい狭い道路)。
※帯域幅(Bandwidth)の元々の意味は、信号が通れる周波数の「幅」
※メモリコントローラ(信号機の役割)
データの流れを調整する交通整理役として存在する(IntelならIMC、AMDならIOD)
広い道路(高帯域幅)ほど性能向上に寄与するが、「車の運転方法」(アクセスパターン)も重要。
最適化には「車線増設(メモリチャネル)」「駐車場活用(キャッシュ)」「交通整理(プリフェッチ)」が有効。
メモリ帯域幅が性能に与える影響
(1) データ読み込み/書き込みの速度
連続アクセス(Sequential Access)
メモリ帯域幅が高いほど、連続したデータ(例: 配列)の読み書きが高速化します。
(例)動画編集や科学計算のような連続データ処理では帯域幅が重要。
ランダムアクセス(Random Access)
帯域幅よりもレイテンシ(遅延時間)が影響するが、帯域幅が不足すると全体のスループットが低下する。
(2) マルチコアCPUでの競合
複数のCPUコアが同時にメモリにアクセスする場合、帯域幅が共有されるため、コア数増加に伴う性能向上が頭打ちになることがある。
(例)8コアCPUでメモリ帯域幅が50GB/sの場合、1コアあたり約6GB/sしか利用できない。
帯域幅を意識する具体的なケース
(例1)大規模データ処理
// 連続メモリアクセスの例(帯域幅を最大活用)
float sum_array(float* array, int size) {
float sum = 0;
for (int i = 0; i < size; i++) {
sum += array[i]; // 連続アクセス → 帯域幅が効率化
}
return sum;
}
最適化: キャッシュライン(64バイト)を意識したデータ配置が重要
(例2)GPUとメモリ帯域幅
GPUは超並列処理を行なうため、CPUよりも高いメモリ帯域幅(例: NVIDIA H100で3TB/s)が必要。
帯域幅不足がGPUの計算性能を制限する「メモリバウンド」状態に陥る。
帯域幅のボトルネックを緩和する方法
(1) キャッシュの活用
CPUキャッシュ(L1/L2/L3):メモリ帯域幅への依存を減らすため、頻繁に使うデータをキャッシュに保持する。
(例)小さな配列を繰り返し処理する場合、キャッシュヒット率を高める。
(2) メモリ効率の良いデータ構造
配列 vs リンクリスト:連続アクセス可能な配列の方が帯域幅を効率的に利用できます。
リンクリスト(連結リスト)はランダムアクセスが多く、キャッシュ効率が悪化する。
(3) プリフェッチング
CPUやコンパイラが事前にデータを読み込むことで、帯域幅を有効活用する。
(4) メモリチャネルの増加
デュアルチャネル/クアッドチャネルメモリ構成で帯域幅を倍増させる。
帯域幅の「分割」の仕組み
(1) 完全な均等分割ではない
現実の動作:ある瞬間には1つのコアが帯域幅の大部分を使い、別のコアはアイドル状態になることがある。
(例)コア1が30GB/sを使っている間、他のコアは帯域幅をほとんど使わない場合もある。
(2) 競合が発生する条件
全コアが同時にメモリにアクセスする場合
コア1: 8GB/s要求 \
コア2: 7GB/s要求 │ → 合計50GB/sを超えるとボトルネック発生
... │
コア8: 6GB/s要求 /
この場合、OSやメモリコントローラが優先順位を付け、帯域幅を動的に割り振る。
帯域幅不足は「メモリバウンド」を引き起こし、CPUの計算資源を無駄にする。
最適化にはキャッシュの活用、連続メモリアクセス、メモリチャネル増設が有効。
ネットワーク帯域幅と同様に、「データの流れの効率」を考える上で不可欠な概念。
配列とリンクリストのアクセスの性能差
連続アクセス(配列)とランダムアクセス(リンクリスト)の性能差は、まさにメモリ帯域幅の活用効率とアクセスパターンの違いによって生まれる。
連続アクセス(配列)が高速な理由
(1) キャッシュの効率的な利用
キャッシュライン(64バイト)の一括読み込み
CPUはメモリからデータを取得する際、単一の値ではなく周辺の連続データもまとめてキャッシュに読み込む。
(例)array[0]にアクセスすると、array[0]~array[15](int型の場合)がキャッシュに載る。
次のアクセスはキャッシュから即座に取得可能(帯域幅を使わない)。
(2) プリフェッチの有効化
CPUは「連続的なメモリアクセスパターン」を検出すると、必要になる前に次のデータを先読みする。
(例)for (int i=0; i<N; i++) sum += array[i];
→ ループ中のi+1, i+2のデータを事前に読み込む
(3) 帯域幅のフル活用
メモリコントローラは連続アドレスへのアクセスをバースト転送で効率化する。
「往復」が不要: データが連続しているため、メモリからCPUへのデータ転送が途切れない。
ランダムアクセス(リンクリスト)が低速な理由
(1) キャッシュミスの多発
各ノードがメモリ上で散在しているため、キャッシュラインの再利用率が低い。
struct Node { int data; Node* next; /* 他フィールド */ };
// nextポインタを追うたびに異なるキャッシュラインにアクセス
(2) プリフェッチの失敗
ポインタをたどる動作はCPUから予測不能なため、先読みが機能しない。
(例)node = node->next; の次にどこにアクセスするか事前にわからない。
(3) 帯域幅の無駄遣い
「往復」が発生
各ノードアクセスごとにメモリコントローラが新しいアドレスを解決する必要があり、帯域幅が未使用のまま待機時間が生じる。
1ノード取得ごとのオーバーヘッド
[CPU] 「ノードAのデータください」 → [メモリ] 「はい、Aのデータ」
[CPU] 「次はノードBのデータください」 → [メモリ] 「はい、Bのデータ」
(毎回アドレス解決と往復が発生)
数値で見る性能差
実験例(Intel Core i7, DDR4メモリ)
| データ構造 | アクセス速度 | 帯域幅利用率 |
|---|---|---|
| 配列(連続) | 約40 GB/s | 80%以上 |
| リンクリスト | 約1.2 GB/s | 10%未満 |
リンクリストは理論帯域幅のごく一部しか活用できていないことがわかる。
具体例で比較
配列のアクセス(連続)
int array[1000000];
for (int i = 0; i < 1000000; i++) {
sum += array[i]; // 連続アクセス
}
メモリアクセスパターン: [0x1000]→[0x1004]→[0x1008]→... (予測可能)
リンクリストのアクセス(ランダム)
struct Node { int data; Node* next; };
Node* head = /* 初期化 */;
while (head != nullptr) {
sum += head->data; // ランダムアクセス
head = head->next;
}
メモリアクセスパターン: [0x1000]→[0x3040]→[0x5000]→... (不規則)
オブジェクト思考によるソフトウェア開発
オブジェクト指向でソフトウェアを開発する際、
コードのリファクタリングを最小化し、将来の仕様変更を見越しながら再利用可能なソフトウェアを設計することが望ましいとされる。
低結合・高凝集を持つシステムの実現を目指すこと。
また、設計の複雑さはコードに反映されるが、シンプルさを保ちつつ、将来の変更への対応も考慮した設計が重要になる。
再利用性
再利用性とは、同一のコードを異なる状況で再利用する際の汎用性を指し、どれだけ容易に、そして多くのシナリオに対応できるかで評価される。再利用性が高い設計は優れた設計と見なされる。
リファクタリング
リファクタリングは、外部からの契約を変更せずにコードを内部的に改善するプロセスを指す。
理想的には、リファクタリングされたコードは他のソフトウェアに影響を与えない。
リファクタリングが容易な設計は良質なコードと評価される。
結合度

※https://qiita.com/ryoq/items/c5a556dc29694b072f50 より画像引用
結合度は、あるモジュールが他のモジュールとどれほど関連しているかを表す。
高結合は、2 つのモジュールが密接に関連し、互いに依存している状態を指す。
低結合は、2 つのモジュールがあまり関連せず、依存していない状態を指す。
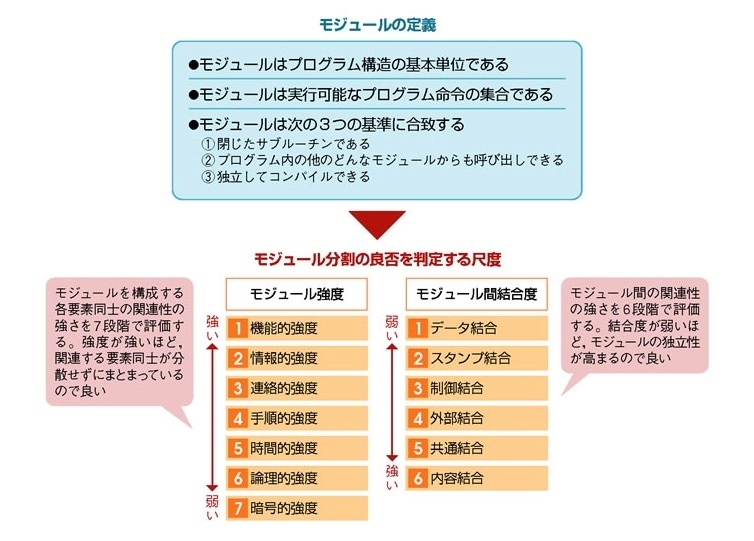
※https://xtech.nikkei.com/it/article/lecture/20070702/276410/?P=2 より画像引用
凝集度
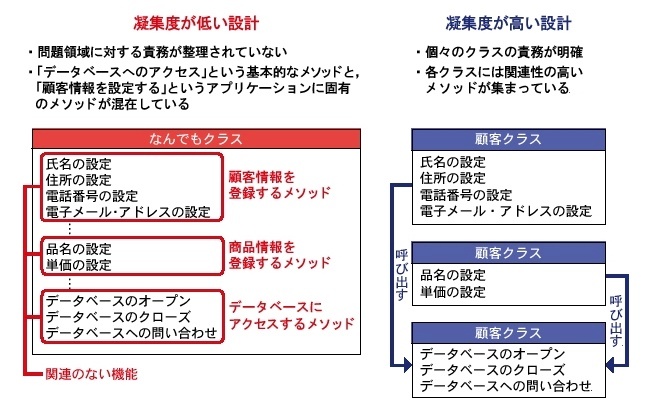
※https://xtech.nikkei.com/it/article/COLUMN/20060607/240196/ より画像引用
凝集度は、構成要素が特定のタスクを達成するためにどれほど効果的に協力しているかを示す。
高凝集は、要素が効率的に連携し、一つの目標に集中している状態を意味する。
低凝集は、要素が分散し、多くの関連しないタスクや目標に関わっている状態を指す。
OKパターン・NGパターン
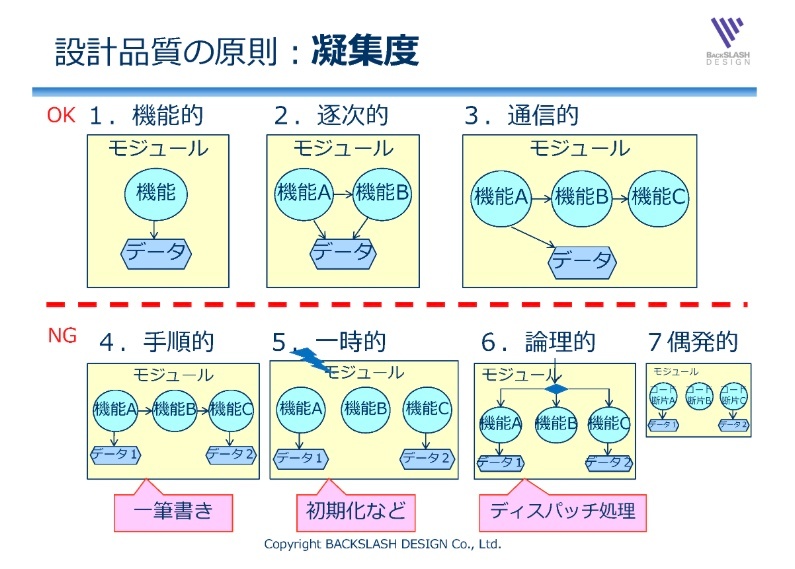
※https://www.bslash.co.jp/Seminar/report/凝集度は高いですか?/ より画像引用
複雑度
複雑度は、設計のコードベースの複雑さを指し、複雑度が高いほどソフトウェアのデバッグ、テスト、拡張、保守が難しくなる。逆に複雑度が低い設計は、よりシンプルで優れているとされる。
全ての要素をバランス良く保つことは、経験豊富な設計者にとっても容易ではない。
プロジェクトの締め切りや実装コストも加味すると、課題はさらに複雑になる。
デザインパターン(design pattern)
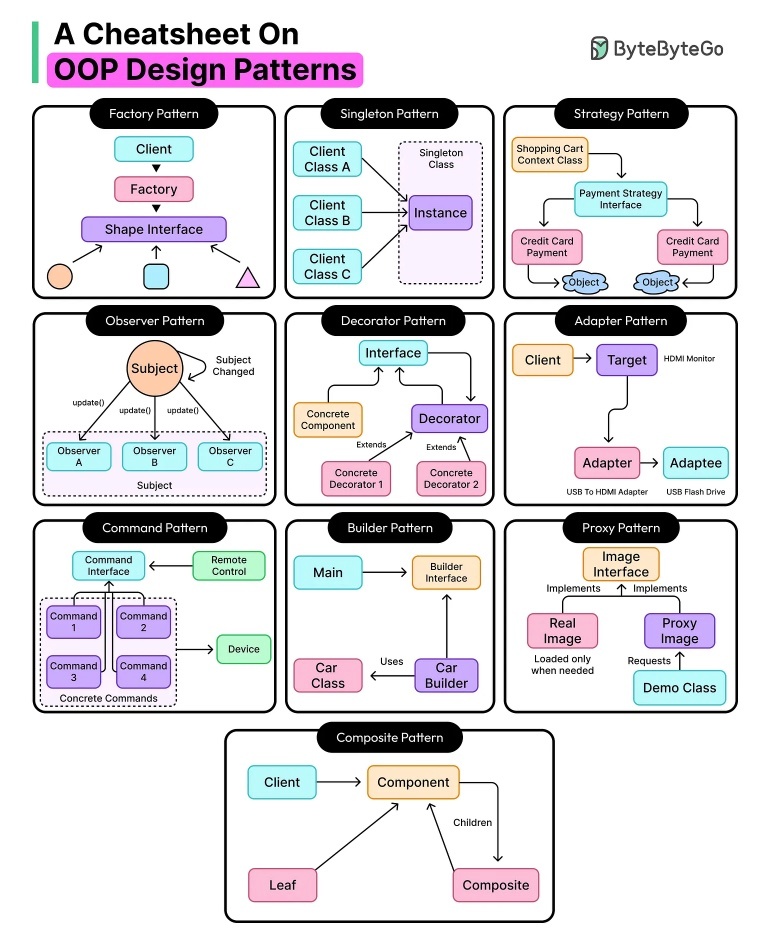
※https://blog.bytebytego.com/p/oop-design-patterns-and-anti-patterns より画像引用
「よく出会う問題とそれにうまく対処するための設計」をまとめたもの
洗練されたソフトウェアシステムでよく見られる設計の集合体。
これらは十分にテストされ、文書化され、一部は言語に統合されている。
デザインパターンは OOP フレームワークで一般的に使用されている。
※https://recursionist.io/dashboard/course/8/lesson/645 より画像引用
※https://astikanand.github.io/techblogs/software-design-patterns/creational-design-pattterns より
シンプルで再利用可能、リファクタリングしやすく、低結合かつ高凝集の設計を持つソフトウェアは、開発速度の向上とコスト削減に貢献する。
また、ソフトウェアをスケールアップし、より多くの機能を追加し、バグを減らすことが可能になる。
十分にテストされたデザインパターンを使用することで、高品質なソフトウェアの構築と維持が可能になる。
ソフトウェアの規模によっては、デザインパターンを全く使用しないこともある。
設計の一般性は、問題の範囲、ソフトウェアの規模、開発コストによって異なる。また、使用言語の特性によってデザインパターンが不要になることもある。多くの場合、パターンにはトレードオフがあるが、スコープに応じて多様な選択肢が存在する。
これは異なるデータ構造が存在する理由と似ており、プログラムの実装時には、固定配列、動的配列、連結リストなど、どのデータ構造を使用するかを検討する。この場合、プログラムがどれだけのアクセス、削除または追加の操作を行なうか、またはそれらを組み合わせるかが決定要因となる。
リストが常にソートされる必要がある場合や、特定のプロパティを維持する必要がある場合、ハッシュマップ、二分木、ヒープ、キューなどのデータ構造を検討する必要がある。
設計時には、使用可能な選択肢だけでなく、設計および開発コストも考慮に入れることが大切。
設計の目標は、開発能力と予算を最大限に活用しながら、再利用性が高くリファクタリングが容易で、低結合かつ高凝集、複雑度の低いオブジェクト指向ソフトウェアを作成すること。
これを達成するには、大規模なオブジェクト指向開発チームや拡張性の高いソフトウェア(例えば人気のあるフレームワーク)で見られるパターンを理解するための知識が必要になる。
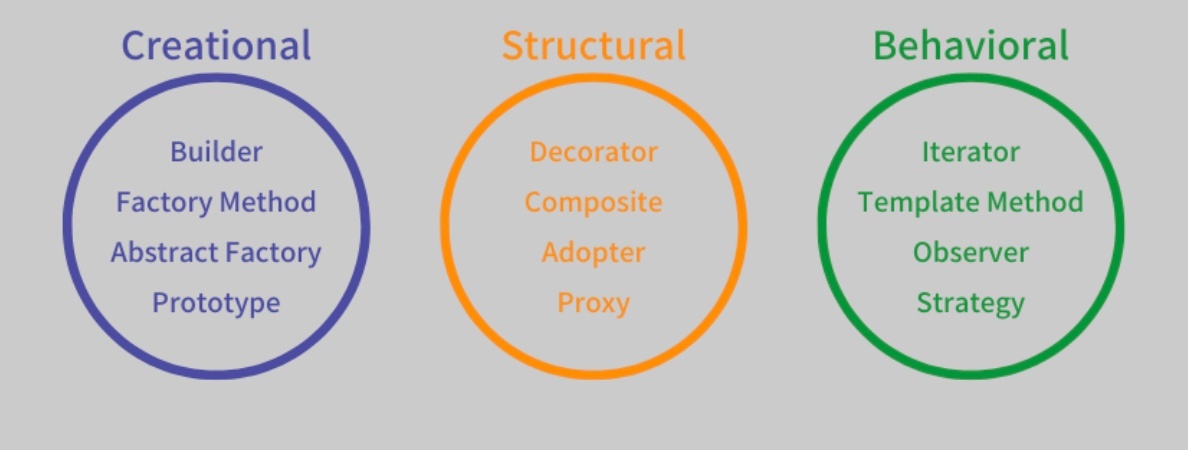
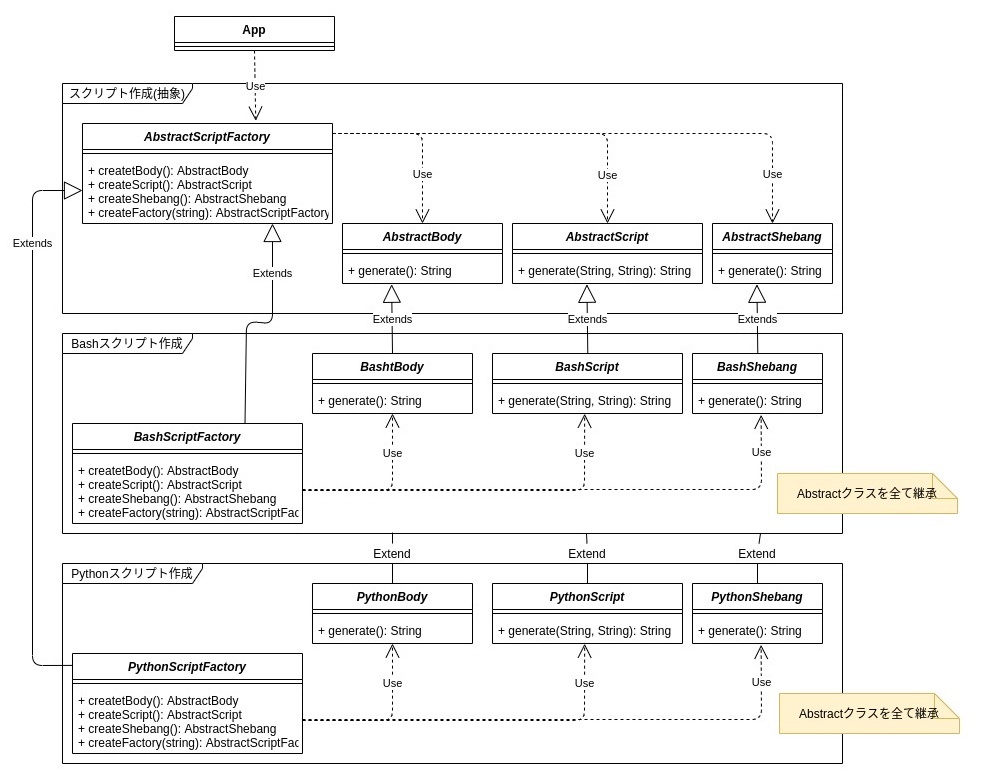
生成パターン(creational pattern)
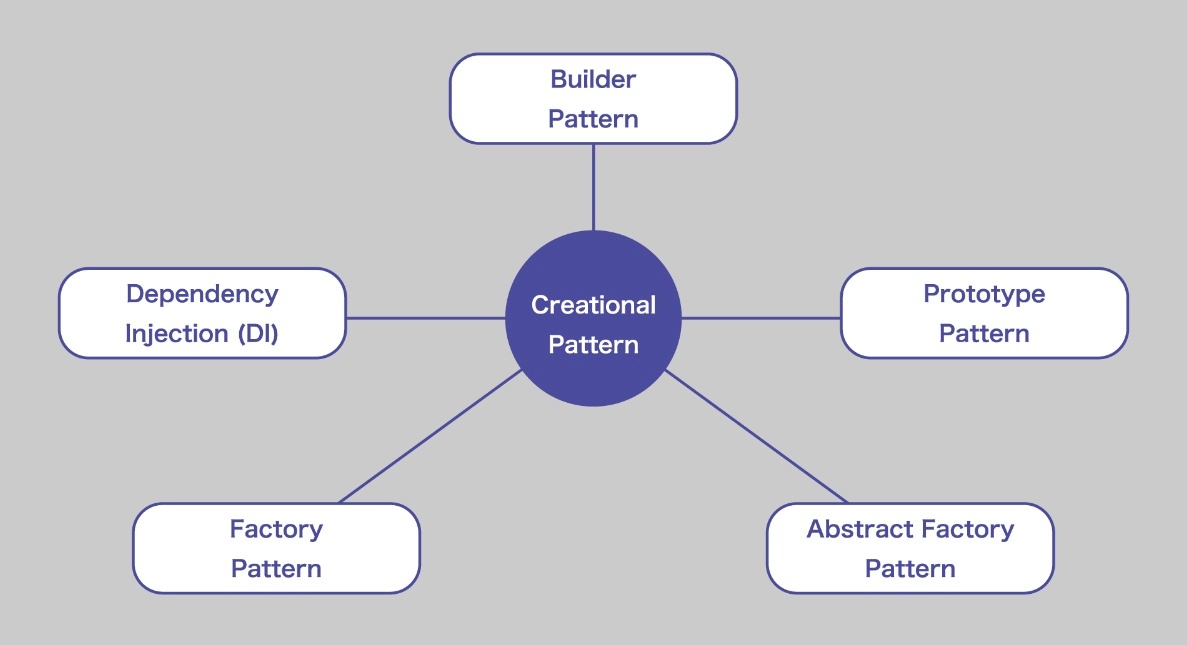
※https://recursionist.io/dashboard/course/8/lesson/645 より画像引用
参考:https://www.scaler.com/topics/design-patterns/creational-design-pattern/
関心の分離(separation of concerns)
OOP の生成パターンは、関心の分離(separation of concerns)の原則に基づいている。
オブジェクトの構築や取得は手間がかかり、複雑なタスクになることがある。オブジェクトの作成が「New」キーワードの使用以上に複雑な場合、それを他のタスクから分離することを考慮する。
これにより凝集性を高め、コードの複雑化を避けることができる。
(例)商品 → 注文品・予約品・在庫品・発送品(関心ごとに分離)
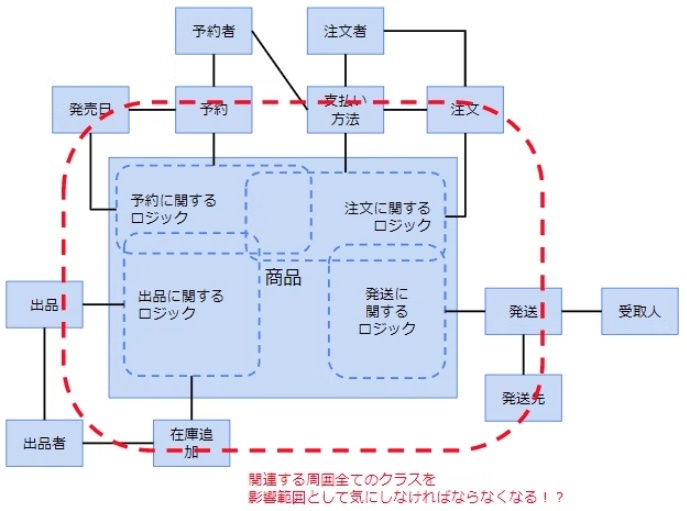
※https://qiita.com/MinoDriven/items/37599172b2cd27c38a33 より画像引用
↓
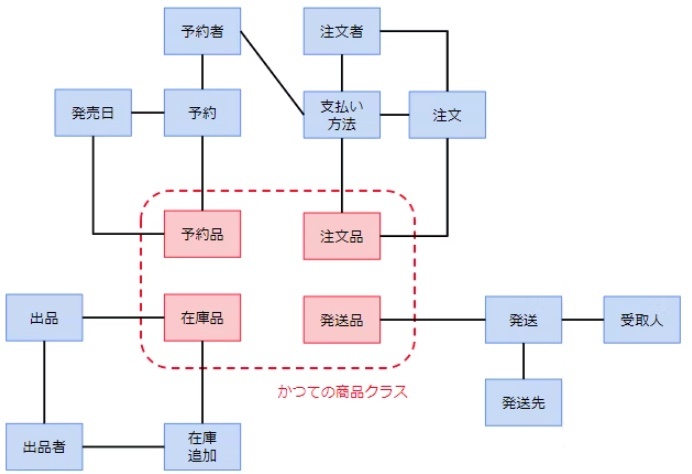
※https://qiita.com/MinoDriven/items/37599172b2cd27c38a33 より画像引用
関心の分離は、ソフトウェア工学において、プログラムを異なる関心ごと(何をしたいか)に分ける考え方。これは複雑なシステムの設計を容易にするために頻繁に用いられる。
依存性の注入(dependency injection)
通常、関数やメソッド内でオブジェクトを直接作成(インスタンス化)することがあるが、この方法だと関数がそのオブジェクトに強く依存することになり、再利用やテストが難しくなってしまう。
代わりに、オブジェクトを関数の外部から引数として渡すことで、関数は特定のオブジェクトの作成方法や詳細に依存しなくなる。これを依存性の注入 dependency injectionといい、関数の柔軟性が高まり、再利用やテストが容易になる。
依存オブジェクトを外部から注入することで、実行時に異なる実装を動的に切り替えられるようになる。
クラスは自身の責務(ビジネスロジック) に集中し、依存オブジェクトの生成・管理は呼び出し側(またはDIコンテナ)に任せる。
これにより、コードの見通しが良くなり、保守性が向上する。
関数型プログラミングでは、オブジェクトのような「状態」を持つものを作らず、すべての操作を関数の入力と出力で処理する。これは、オブジェクト指向とは異なるアプローチであり、オブジェクトの生成や状態管理が必要ないため、一部の問題に対してはよりシンプルな解決策を提供する。
OOP では、式以外にもステートメントや状態を持つことができ、これにより、オブジェクトをインスタンス化し、途中でローカルスコープの変数に代入したり、関数のスコープ外からオブジェクトやデータを取得したりすることが可能になる。
OOP では、特にオブジェクトやクラスが他のオブジェクトやクラスに依存している場合、コードはその外部のコードに強く影響される。つまり、依存しているオブジェクトやクラスに変更があると、意図しない副作用が発生したり、コードが複雑化したり、可読性が低下したり、コードが密結合な状態になるリスクがある。
コードへ変更があるとコード全体に影響を与える可能性があるため、安定した状態を維持することを望むしかない。また、依存関係は直接的に可視化することが難しくなる。これは、依存している部分が別の場所(例えば別のクラスやメソッド)に定義されているため、その関係を把握するのが複雑になるためである。
関数をブラックボックスとして捉えた場合、メソッドの入力と出力のみに注目し、関数の内部状態を外部から把握することはできない。
例えば、オブジェクトが関数内部で作成された場合、外部からの依存関係は一切見えない。
しかし、依存関係が入力パラメータとして渡される場合は、外部から把握可能。
ハードコードされたデータ Hard-coded dataとは、プログラムのソースコード内に直接埋め込まれた固定値や設定を指す。このデータは外部からの変更が難しく、コードの修正なしには更新できないことを意味する。
・コード内に直接記述:変数や設定ファイルではなく、ソースコード中に値がベタ書きされる
・変更に再コンパイルが必要:値の修正にはプログラムの再ビルドが必要(例: 定数の更新)
・柔軟性が低い:環境やユーザーごとのカスタマイズが難しい
「メソッドの呼び出し側でオブジェクトを作成する」 ことで、得られるメリット
・結合度が下がり、コードの柔軟性が向上する
・単体テストが容易になる(モックを使える)
・責務が分離され、保守性が高まる
・実行時に依存先を動的に変更可能
呼び出し元が必要な依存関係をメソッドに注入することで、ソフトウェアのリファクタリングや再利用性を向上させることができる。コードの変更なしに依存関係だけを変える。
依存関係をさらに柔軟にするために、ポリモーフィズムを用いて、あるインターフェースを実装した任意のオブジェクトを受け取ることができる。
依存性の注入は、親子関係に基づく概念
この関係において、親(呼び出し側)はオブジェクトを作成して設定し、子(呼び出される側)は親から渡された依存関係を使って処理を行なう。この依存関係によって処理の内容は異なる。
依存性の注入の利点は、ユニットテストが容易になること。テスト時に異なるデータを通過させ、特定の側面に重点を置いてテストを行なうことができる。
依存関係を入力として指定しない場合、異なるオブジェクトを使用してメソッドのさまざまなシナリオをテストすることは難しくなる。
依存性の注入には欠点もある。オブジェクトの作成を呼び出し元に委ねる必要があるため、複雑なオブジェクトの作成は呼び出し元に負担をかけることになる。特に、複雑なオブジェクトの作成に特化したシステムがない場合、または何を渡すかを明確に記載した API 契約書がない場合、依存性の注入は逆効果になる可能性がある。これは呼び出し元の複雑度を増加させることにつながる。
DIが適さない(または過剰になる)具体的なケース
① シンプルで変更可能性の低いクラス
・依存オブジェクトが絶対に変わらない(例: Math ユーティリティクラス)
・クラスが単一の責務しか持たず、テストの必要性が低い
② パフォーマンスが極めて重要な場合
・マイクロ秒単位の最適化が必要な超低レイテンシシステム
・DIコンテナ(Springなど)のリフレクション処理がボトルネックになる場合
対処法
→ 手動で依存オブジェクトをnewするか、ファクトリパターンを利用
→ Dagger 2のようなコンパイル時DIツールを検討
③ 依存オブジェクトの生成が複雑すぎる場合
・依存オブジェクトの構築に多数のパラメータが必要(例: ビルダーパターンが必要なケース)
・依存関係が循環している(A → B → C → A)
対処法
→ セッターインジェクションで遅延注入するか、デザインパターンの見直し
④ フレームワークやライブラリの制約
・AndroidのActivityなど、フレームワークがインスタンス生成を強制するクラス
・JavaFXコントローラなど、コンストラクタ引数を渡せない場合
対処法
→ セッターインジェクションや Daggerの@Injectフィールドを利用
⑤ シングルトンや静的メソッドで十分な場合
・真にグローバルな状態(例: ログガー、設定ファイルリーダー)
・静的ユーティリティクラスで十分な機能(Collections.sort()など)
制御の反転(inversion of control, IoC)
依存性の注入に関連した課題を解決するために、多くのフレームワークやシステムで実装されているアプローチ。
このアプローチでは、フレームワークがユーザーに従うべき特定のガイドラインを提供している。
「誰が処理の流れを決めるか」の主導権が“逆になる”ことを指す。
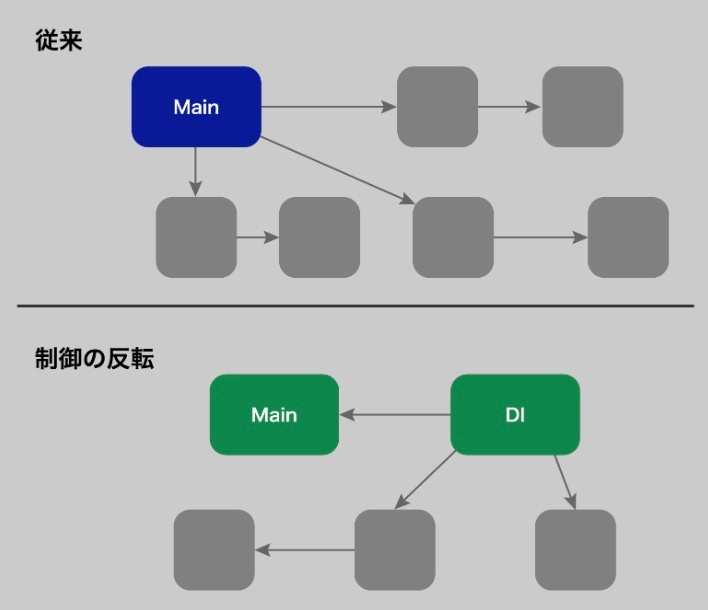
※https://recursionist.io/dashboard/course/8/lesson/648 より画像引用
制御の反転とは、自分が主導していた処理の流れを“外側の仕組み”に委ねること。
DIコンテナはその実現手段の1つ
従来の流れ:Main(自分のコード)が全部newして処理の流れを制御
制御の反転による流れ:処理の主導権が“外側(コンテナ側)”にある
→ 自分でインスタンスを作らない
→ フレームワークやDIコンテナが勝手に作って渡してくれる(依存注入)
→ 処理の主導権が“外側(コンテナ側)”にある!=制御の反転
※制御の反転 ≠ 依存注入
制御の反転(IoC)は「設計原則(広い概念)」
依存注入(DI)は「IoCを実現する具体的な手段」の一つ
|項目|従来のやり方|IoC / DI|
|主導権|自分が持ってる(全部new)|フレームワークやコンテナが持ってる|
|組み立て|自分でパーツを組み立てる|外から完成品を渡してもらう|
DI コンテナ(dependency injection container)
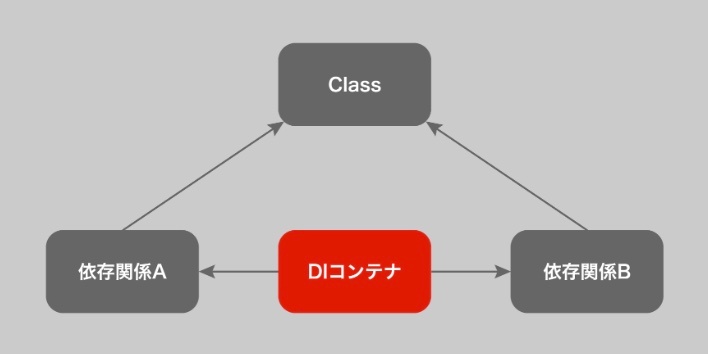
※https://recursionist.io/dashboard/course/8/lesson/648 より画像引用
プログラム内で必要とされるオブジェクトや関数を格納しておく容器
フレームワークやシステムによく含まれている機能。
プログラムが実行される際、DI コンテナは必要なオブジェクトや関数を自動的に提供し、プログラムの各部分がスムーズに機能するのを助ける。
サービスロケーター(Service Locator)
サービスロケーターは、依存性を取得するためのデザインパターンで、アプリケーションが必要とするサービス(オブジェクト)を中央集権的に管理・提供する仕組み。
プログラムが必要とする依存関係を見つけ出し、適切な場所に配置する役割を持つレジストリ(登録簿)。
依存性注入(DI)と似ているが、オブジェクトの取得方法に根本的な違いがある。
主な役割
・サービスの登録: あらかじめ利用可能なサービスを登録
・サービスの検索: 実行時に必要なサービスを名前や型で取得
これらの機能により、プログラムの構造がより明確になり、開発者は複雑な依存関係を容易に管理できるようになる。
IoC や DI コンテナを使ったシステムでは、開発者はフレームワークが提供する方法に従ってオブジェクトを追加したり、依存関係を配置したりすることができる。特に大きなプロジェクトや複雑なフレームワークを使用する際には、これらの概念が重要となる。
依存関係の定義は開発者の判断によるが、すべての場合に明確な依存関係を設定する必要はない。
以下のような状況では、依存関係を異なる方法で扱うことがある。
1. メインシステムの役割
メインシステムが中心となり、他の部分で使われるオブジェクトを作成する。
この場合、メインシステムが他の部分の依存関係を管理するため、個々のメソッドがそれぞれ依存関係を定義する必要はない。
2. 同じクラスのオブジェクト
もしクラス A とクラス B が同じであれば、互いを依存関係として特別に扱う必要はない。
3. 同じエコシステム内のクラス
クラス A と B が同じモジュールやエコシステムに属している場合、これらのクラスはすでに密接に関連しているため、明確な依存関係として定義する必要はないことがある。
これらのクラスは自然に相互依存しているため、個別に依存関係を設定する必要はない。
これらのケースを理解することで、依存性の注入が常に適切な解決策であるわけではなく、場合によっては開発者がオブジェクトの作成を自らの責任として行なう必要があることがわかる。
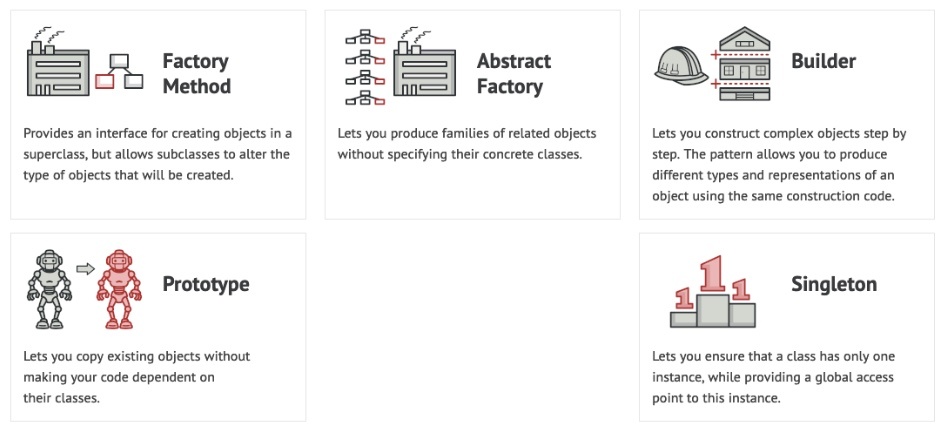
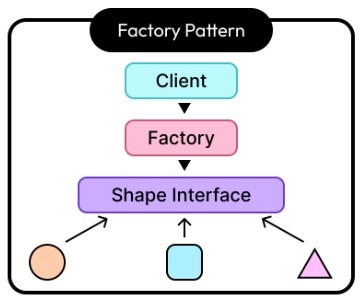
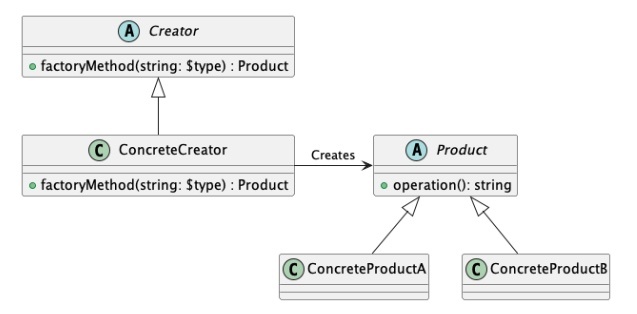
ファクトリーメソッド(Factory Method)
オブジェクト指向プログラミングにおける「生成に関する」デザインパターンの1つで、オブジェクトの生成をサブクラスに委ねることで、柔軟性と拡張性を高める設計手法
ユーザーがクラスのメソッドをサブクラス化し、そのメソッドをオーバーライドして異なるオブジェクトを生成するためのデザインパターン
=あるクラスを継承(=サブクラス化)して、その中のメソッドを上書き(=オーバーライド)し、自分なりの処理に変えることで、異なるオブジェクト(または振る舞い)を実現する。
オブジェクト生成を継承によって切り替えるパターン
ファクトリーメソッドは「継承による実装の差し替え」が前提なので、単なる型の定義(=インターフェース)では足りないケースが多いため、抽象クラスがよく使われる。
ファクトリーメソッド(Factory Method)は、スーパークラス(親クラス)で抽象化されていて、実際のオブジェクト生成はサブクラス(子クラス)で実装する。
new を直接書かずに、オブジェクトの生成を“サブクラスに任せるデザインパターン
オブジェクトの生成(インスタンス化)を担当するメソッドのこと。new キーワードを使わずに、メソッド経由でオブジェクトを作る。
※https://blog.bytebytego.com/p/oop-design-patterns-and-anti-patterns より画像引用
より具体化すると
※https://recursionist.io/dashboard/course/8/lesson/650 より画像引用
一般的なファクトリーメソッドの構造
※https://recursionist.io/dashboard/course/8/lesson/652 より画像引用
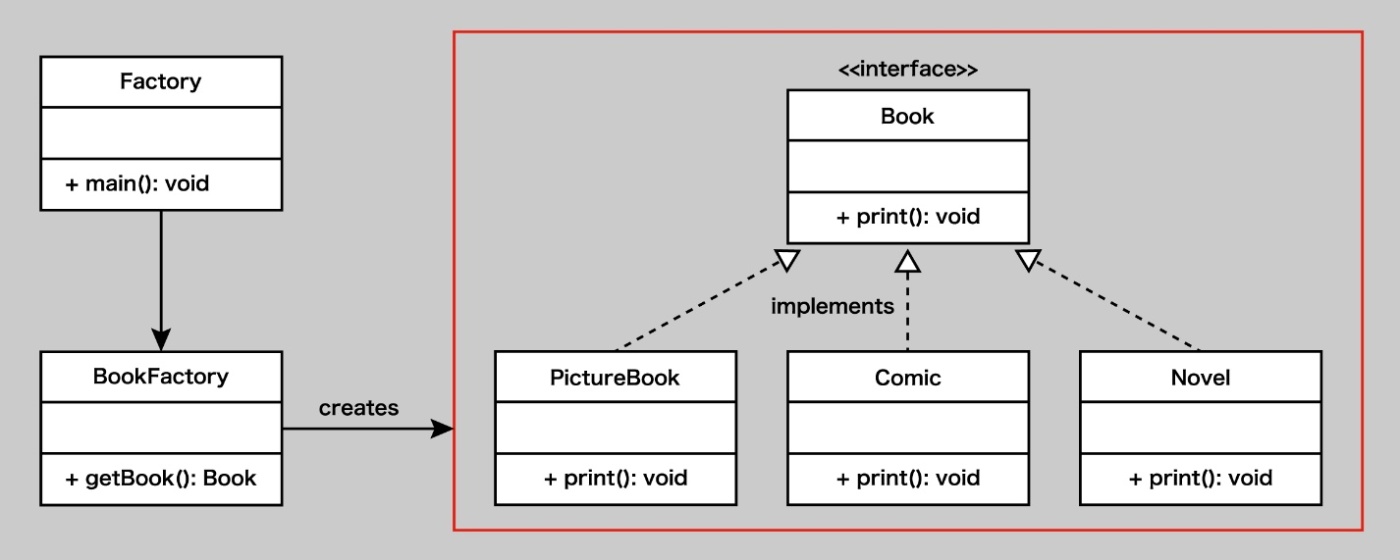
クリエーター(creator)
オブジェクトを作成するクラスのこと。
抽象メソッドであるファクトリーメソッドを定義したクラスのこと。
ファクトリーメソッド(=オブジェクト生成用メソッド)」を定義しているクラスのこと。
クリエーターは「どんな処理でプロダクトを生成するか」は知らずに、「どう使うか」だけを知っているという構造になる。
クリエーターは「プロダクト」と呼ばれるオブジェクトを作成する。
クリエーターは、クリエーター A、クリエーター B、クリエーター C などに拡張し、それぞれプロダクト A、プロダクト B、プロダクト C などを作成することができる。
※https://supersoftware.jp/tech/20230509/18753/ より画像引用
まとめると
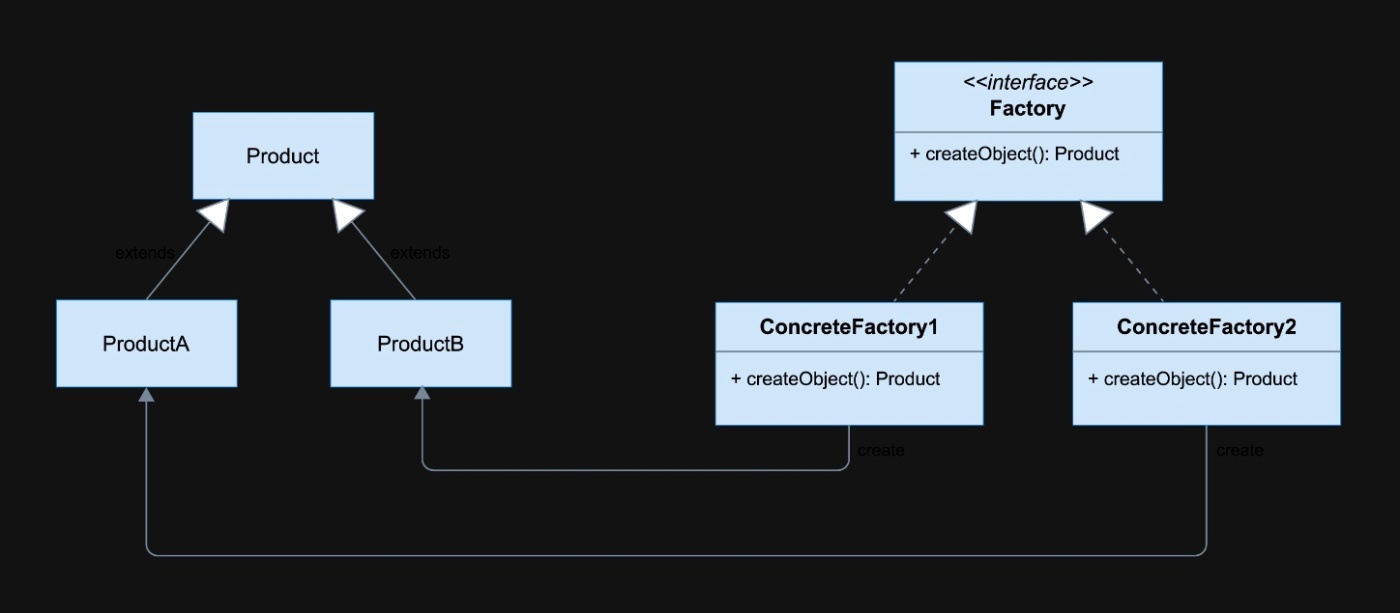
クリエーター(Creator)
プロダクトを生成するためのインターフェースや抽象クラス
これがファクトリーメソッドを定義する。ファクトリーメソッドは、具体的なプロダクトを生成する責任を持つ。
※Creator(クリエーター)クラス
・共通のインターフェース(例:createProduct())を定義
・サブクラスでこのメソッドをオーバーライドして、具体的なプロダクトを返すようにする
プロダクト(Product)
生成されるオブジェクトの共通インターフェースや抽象クラス
※Product(プロダクト)クラス
・作成されるオブジェクトの共通インターフェースや基底クラス
・これを継承して ConcreteProductA, ConcreteProductB などが定義される
具体的なクリエーター(ConcreteCreator)
クリエーターを継承した具体的なクラスで、ファクトリーメソッドをオーバーライドして、具体的なプロダクトを生成する。
具体的なプロダクト(ConcreteProduct)
実際に生成される具体的なオブジェクト。
抽象クラスに定義するファクトリーメソッドの戻り値の型は、作りたいオブジェクトの型(抽象型)になる(抽象クラスの型をしようすることで、サブクラスで具体的なプロダクトを返しても、抽象型として統一的に扱えるようになる)
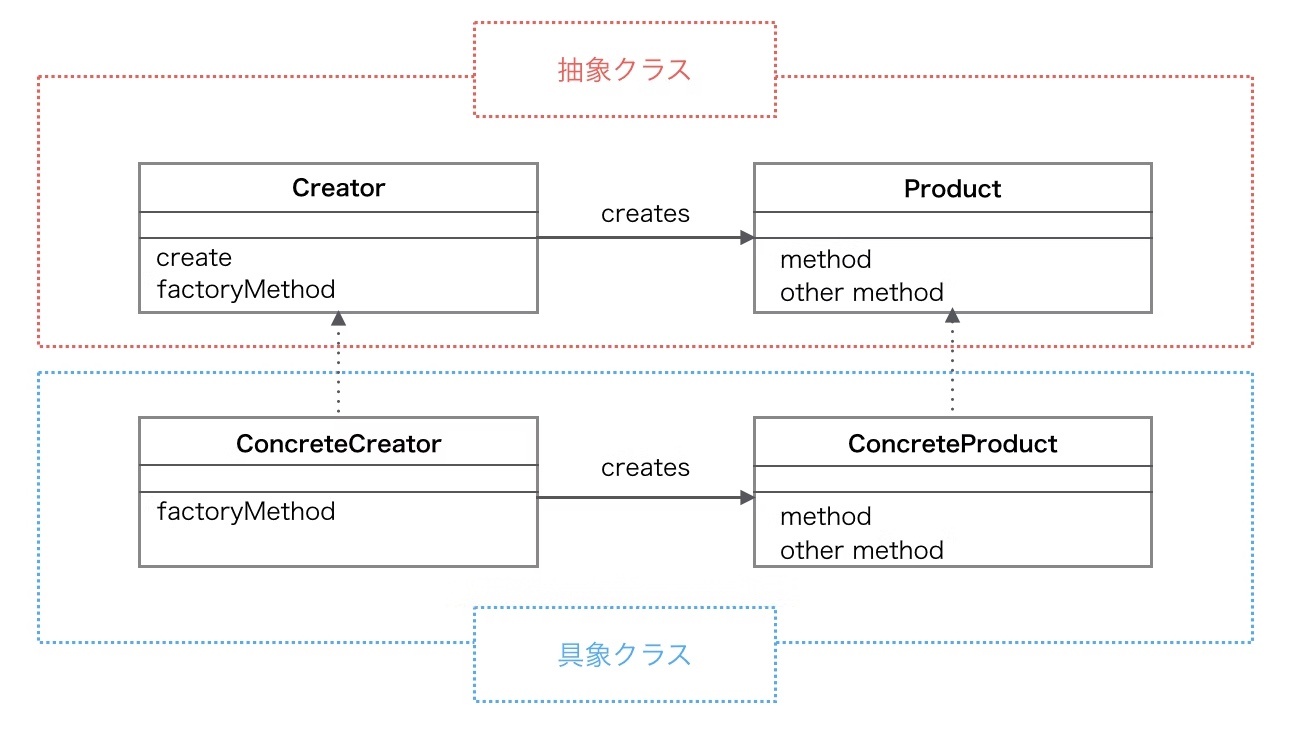
※https://qiita.com/shoheiyokoyama/items/d752834a6a2e208b90ca より画像引用
具体
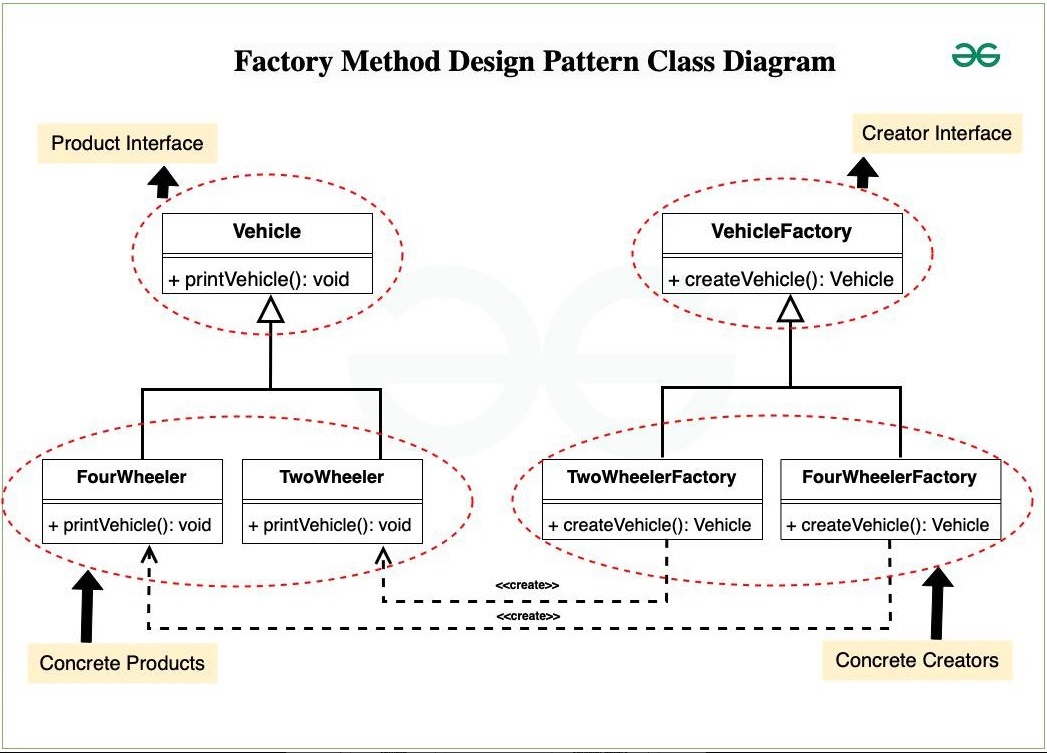
※https://www.geeksforgeeks.org/factory-method-for-designing-pattern/ よち画像引用
ファクトリーメソッドは再利用可能であり、単一責任原則に従うが、クリエーターに多くのサブクラスが必要である点に注意すること。
これはまた、クリエーターインターフェースが新しい抽象メソッドを追加するたびに、全てのサブクラスが独自の実装を定義する必要があることを意味する。しかし、多くの場合、抽象メソッドを持たずに、デフォルトのファクトリーメソッドの実装を最初から提供することが一般的。
Create 関数は、オブジェクトの構築に使われるデータに必要な引数を受け取り、それらを処理して最終的にコンストラクタに渡される値を計算することができる。
また、引数を直接コンストラクタに渡すことも可能。
ファクトリーメソッドは作成プロセスをカプセル化しているため、最終的な値を取得する前に、データの準備やデータベースからのデータ取得など、さまざまな処理を実行することができる。また、メソッドは引数を使用して、どのクラスのどのコンストラクタを呼び出すかを決定する。
引数は、クリエーターが使用するあらゆるオブジェクトインターフェースを生成するのに十分汎用的である必要がある。入力として配列やハッシュマップを使用し、各サブクラスにデータを解析させることも可能。
オブジェクトの生成は、ファクトリーメソッドによって行われるので、データベースからのデータアクセスや他の関数からデータを生成するなど、複雑な処理を介してオブジェクトを作成することが可能。
また、Least Recently Used、スタック/キュー、ラウンドロビン、優先度付きキューなど、複数のオブジェクトをプールして、最適なものを選択して返す実装も行なうことができる。
ファクトリーメソッドパターンでは、オブジェクトを生成する際に直接コンストラクタを呼び出すのではなく、専用のメソッド(ファクトリーメソッド)を通じて生成する。
このようにすることで
① オブジェクト生成の詳細を隠蔽できる
クライアントコードは生成ロジックを知る必要がなく、インターフェースだけ知っていればよい
② 拡張性が高まる
新しい種類のオブジェクトを追加する際に、既存コードを変更せずに拡張できる
③ 生成ロジックの一元管理
オブジェクト生成に関する複雑なロジックを1箇所に集約できる
といったメリットがある。
ファクトリーメソッドを使う理由
・new による生成を分離したい
・親クラスは「どんなものを作るか」知らずに動きたい
・「作る処理だけを任せられる仕組み(メソッド)」がほしい
→ これを実現するために「ファクトリーメソッド」が使われる
ファクトリーメソッドパターンの核となるのは、オブジェクトを生成するための特定のメソッドを提供するインターフェース。
このメソッドを使って、クライアント(オブジェクトを必要とするコード)は必要なオブジェクトを作成する。インターフェースの各サブクラスは、このメソッドをオーバーライドして、異なるタイプのオブジェクトやそのサブクラスを生成することが可能。
特に将来どのような派生クラスが追加されるか予測できない場合や生成ロジックが複雑になる可能性がある場合に有効
ファクトリーメソッドとコンストラクタ
ファクトリーメソッドがある抽象クラスでも、コンストラクタは普通にあるにはある。
ただし、「直接インスタンス化できない」ため、使う機会が少ない。
抽象クラスは new で直接インスタンスを作れない
→ そのため、コンストラクタがあっても直接呼ばれることは少ない。
→ 結果的に「コンストラクタがないように感じる」ことがある。
しかし、実際はサブクラスが親クラスのコンストラクタを super(...) で呼び出すために、抽象クラスにはちゃんとコンストラクタがあることがほとんど
抽象クラスにコンストラクタが「ある意味」
→ 抽象クラス自体はインスタンス化できない
→ でも、その抽象クラスを継承したサブクラスはインスタンス化される
→ そのとき、サブクラスのコンストラクタ内で super(...) を使って親のコンストラクタを呼び出す必要がある
→ だから、抽象クラスにもちゃんとコンストラクタが実装されてる
※あくまで「サブクラスで使うため」 のコンストラクタ
サブクラスでsuper()を使うかどうかの判断基準
親クラスのコンストラクタで引数があるかないかで決まる。
・デフォルトあり(引数なし):super()を書かなくてもOK(自動で呼ばれる)
・デフォルトなし(引数ありのみ):必ず書かないとエラーになる
つまり、親クラスの初期化に何か情報が必要なら、それはサブクラスが責任持って渡すというルール。
ファクトリーメソッドを使用する主な利点
→ オブジェクトの生成の責任をサブクラスに委ねることができる点
この方法を採用することで、元のクラスが提供する他の機能はそのまま利用でき、各サブクラスはファクトリーメソッドを異なる方法で実装することで、異なる種類のオブジェクトを使用することが可能になる。
ファクトリーメソッドパターンを使用する理由
一つは、単一責任の原則に基づいて、関数が一つのタスクだけに集中するようにすること。
オブジェクトの生成はしばしば複雑であり、このプロセスを独立したタスクとして切り分けることが推奨される。
これはまた、関心の分離の原則にもつながる。たとえオブジェクトを作成するのに 50 行のコードが必要な場合でも、クライアント(オブジェクトを使用する側)はその複雑さを意識する必要はありません。クライアントはオブジェクトの生成以外の実装に集中するべきで、必要なオブジェクトを簡単に生成できる手段が必要。
クライアントが生成しない場合(依存性注入やファクトリパターンなど)
設計をきれいにしたいときや、柔軟性をもたせたいときは、クライアントが自分で new しないようにする。
具体例
public abstract class Animal {
public abstract void speak();
}
public class Dog extends Animal {
@Override
public void speak() {
System.out.println("ワンワン");
}
}
public abstract class AnimalFactory {
// ← これがファクトリーメソッド!
public abstract Animal createAnimal();
// 動物にしゃべらせる処理(newは使わずに createAnimal を呼ぶ)
public void speakAnimal() {
Animal animal = createAnimal(); // ← newしない!
animal.speak();
}
}
public class DogFactory extends AnimalFactory {
@Override
public Animal createAnimal() {
return new Dog();
}
}
public class Main {
public static void main(String[] args) {
AnimalFactory factory = new DogFactory(); // ← サブクラスを差し替えるだけ!
factory.speakAnimal(); // => ワンワン
}
}
AnimalFactory: 抽象的な「生成メソッド」を定義する親クラス
createAnimal(): ファクトリーメソッド, newの代わりになる
DogFactory: 実際にどのオブジェクトを生成するかを決める
Main: 生成処理を意識せずに speakAnimal() を使う
サブクラスで作ったもの(DogFactory)を親クラスの型(AnimalFactory)に格納するのは、ポリモーフィズム(多態性)を使うため
「何を作るか」や「どう動くか」はサブクラスに任せて、呼び出す側は 親クラスの共通インターフェースだけで操作することができればいい。
→ 親クラスの型でオブジェクトを扱うということは、「親クラスで定義されているメンバー(メソッド・フィールド)」しか使えないということ
→ 呼び出し側は「共通の仕様」だけに依存している
→ DogFactory でも CatFactory でも BirdFactory でも問題なく動く
→ 柔軟に差し替え可能、テストもしやすい、拡張しやすい
「親クラスの型で変数を宣言する」=「親クラスで定義された共通インターフェースだけを使う」
これはまさに、オブジェクト指向の「ポリモーフィズム」の基本であり、設計の強み
逆に、「どうしてもサブクラス独自の機能を使いたい」という場合は、キャストを使うこともできるが、密結合になることから、設計としてあまりおすすめされない。
親クラスは new しない代わりに抽象メソッドで“作るだけ”を頼む
→ 「何を作るかはサブクラスが決める」という設計
オブジェクトの生成を担う抽象的なメソッド(ファクトリーメソッド)を親クラスに用意し、
実際に何を生成するかはサブクラスで決めさせる
・親クラスは「いつ作るか」は知ってるけど、「何を作るか」は知らない
・子クラスが「何を作るか」を決める=生成の責任を持つ
「抽象に依存して具体を隠す」=「ポリモーフィズムを使う」考え方
長期的に保守・拡張されるようなアプリや、チーム開発ではポリモーフィズムを積極的に活用するのがベスト
オブジェクト指向における「クライアント」
あるオブジェクト(やクラス)の機能やサービスを利用する側のことを指す。
class Printer {
void print(String message) {
System.out.println(message);
}
}
class Report {
void output() {
Printer printer = new Printer(); // ← Printerのクライアント
printer.print("月次レポートを出力します。");
}
}
Printer はサービスを提供するオブジェクト(「提供者」)
Report は Printer の機能(printメソッド)を使っているので、「クライアント(利用者)」
クライアント:他のクラス・オブジェクトの機能を利用する側
サーバ or サービス提供者:クライアントに機能を提供する側
「クライアントコード」:他のクラスやオブジェクトの機能を使って処理を行なうコードのこと
つまり、「使う側のコード」=クライアントコード
クライアントを意識する理由
・依存関係を明確にする:どのクラスがどのクラスに依存しているかが分かる。
・設計の責任を分ける:何が何を使うのか、役割を整理しやすい。
・インターフェース設計:利用側(クライアント)から見て、どう使いやすくするか考えられる。
多くのフレームワークではファクトリーメソッドパターンが採用されており、これによりフレームワークアプリケーションはユーザーが作成したオブジェクトと相互作用できるようになる。フレームワークは、サブクラス化を通じてコードを拡張することができ、作成されるオブジェクトが準拠すべきインターフェースを指定できる。ユーザーがそのインターフェースに従ってオブジェクトを生成すれば、クライアントはそのオブジェクトを利用することができる。
ファクトリーメソッドパターンと生成メソッド、シンプルファクトリーは異なる概念なので、混同しないように注意
| 名称 | 正体 | 主な目的 | 実装の特徴 |
|---|---|---|---|
| 生成メソッド | 単なるnewをラップしたメソッド | より分かりやすい or 柔軟なインスタンス生成 | static User.of() など |
| シンプルファクトリー | 別クラスに生成処理を切り出す | 条件分岐で異なるサブクラスを返す | Factory.create(String type) など |
| ファクトリーメソッドパターン | 継承によって生成処理を切り替えるデザインパターン | サブクラスごとに異なる生成処理を可能にする | 抽象クラスの中で create() を定義し、サブクラスが実装 |
生成メソッド(creation method)
特定の引数を受け取り、それに基づいて特定のオブジェクトを生成する任意のメソッドを指す。
オブジェクトを生成するためのメソッドのこと。
この方法では、オブジェクトの生成とロジックの処理が一つのメソッドに集約される。
全てのファクトリーメソッドは生成メソッドだが、ファクトリーメソッドはユーザーに生成メソッドをサブクラス化し、オーバーライドすることを要求または許可する。
ファクトリーメソッドは継承とサブクラス化を利用することで、柔軟性と拡張性を提供する。
主に「new を使ってインスタンスを作る処理」を、コンストラクタの代わりや補助として別メソッドに分けたもの
目的
・インスタンス生成の処理をカプセル化して、呼び出し側(クライアント)をシンプルにする
・生成の中身を柔軟に切り替えられるようにする
・サブクラスで生成処理をカスタマイズできるようにする
class User {
private String name;
// コンストラクタは private にして外から new できないようにする
private User(String name) {
this.name = name;
}
// これが生成メソッド(factory method)
public static User createWithDefaultName() {
return new User("Guest");
}
public static User createWithName(String name) {
return new User(name);
}
}
User user1 = User.createWithDefaultName();
User user2 = User.createWithName("Taro");
よく使われる文脈
・デザインパターン(ファクトリメソッド、抽象ファクトリなど)
・ライブラリやフレームワークでの インスタンス制御
・生成ロジックを柔軟に変えたいとき(例:キャッシュ、条件付き生成など)
コンストラクタとの違い
| コンストラクタ | 生成メソッド |
|---|---|
| new で直接呼び出す | メソッドとして呼び出す(User.create()など) |
| 名前がクラス名に固定される | 好きなメソッド名をつけられる(意味が明確に) |
| 戻り値はそのクラスだけ | 戻り値をサブクラスなどに柔軟にできる |
ファクトリーメソッドパターンと生成メソッド、シンプルファクトリーは異なる概念なので、混同しないように注意
| 名称 | 正体 | 主な目的 | 実装の特徴 |
|---|---|---|---|
| 生成メソッド | 単なるnewをラップしたメソッド | より分かりやすい or 柔軟なインスタンス生成 | static User.of() など |
| シンプルファクトリー | 別クラスに生成処理を切り出す | 条件分岐で異なるサブクラスを返す | Factory.create(String type) など |
| ファクトリーメソッドパターン | 継承によって生成処理を切り替えるデザインパターン | サブクラスごとに異なる生成処理を可能にする | 抽象クラスの中で create() を定義し、サブクラスが実装 |
シンプルファクトリー(simple factory)
具体
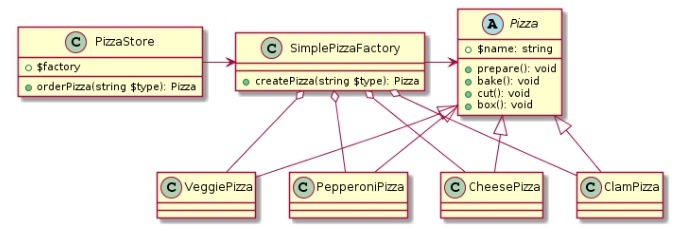
※https://kin29.info/factoryパターン〜simple-factory〜/ より画像引用
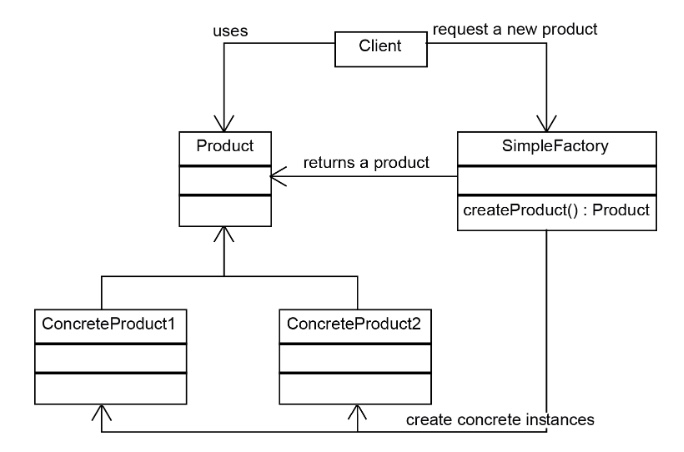
キーや他の引数を受け取り、それに応じて異なるオブジェクトを生成する関数やメソッドを指す。
しかし、多くのオブジェクト(例えば 40 個の if 文で 40 のオブジェクトを生成する場合)を扱うと、シンプルファクトリーの内部は複雑化するため、最終的にはサブクラス化が必要になり、ファクトリーメソッドパターンに移行することが一般的。
「new を直接使いたくない」「条件で生成するものを切り替えたい」
→ 専用のクラスでまとめて生成する方法
class AnimalFactory {
public static Animal create(String type) {
if (type.equals("dog")) return new Dog();
if (type.equals("cat")) return new Cat();
throw new IllegalArgumentException("Unknown type");
}
}
条件に応じて違うインスタンスを返す
クライアントは new を知らずに済む
デザインパターンではないが、よく使われる設計
簡単に使えるが、if 文が増えると保守がつらくなる
ファクトリーメソッドパターンと生成メソッド、シンプルファクトリーは異なる概念なので、混同しないように注意
| 名称 | 正体 | 主な目的 | 実装の特徴 |
|---|---|---|---|
| 生成メソッド | 単なるnewをラップしたメソッド | より分かりやすい or 柔軟なインスタンス生成 | static User.of() など |
| シンプルファクトリー | 別クラスに生成処理を切り出す | 条件分岐で異なるサブクラスを返す | Factory.create(String type) など |
| ファクトリーメソッドパターン | 継承によって生成処理を切り替えるデザインパターン | サブクラスごとに異なる生成処理を可能にする | 抽象クラスの中で create() を定義し、サブクラスが実装 |
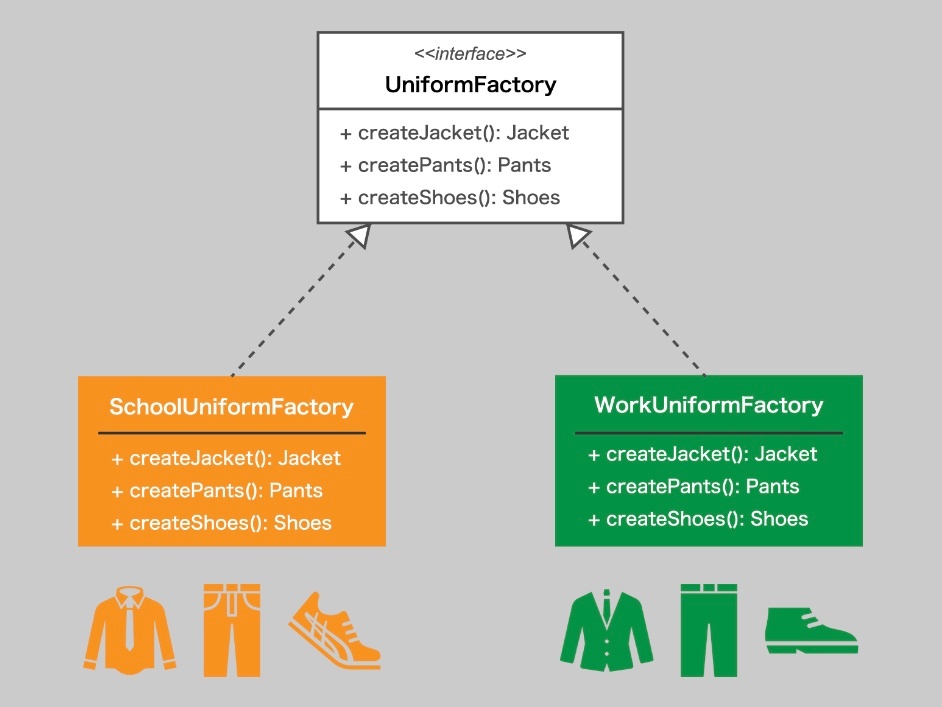
抽象ファクトリー(abstract factory)
※https://debimate.jp/2021/05/15/【abstract-factoryパターン】コンポジットの部品変更を容易/ より画像引用
関連するオブジェクトの「グループ」をまとめて作る工場(Factory)を作る設計パターン
関連するオブジェクトのセットを作成するインターフェース
抽象ファクトリー(Abstract Factory)は、 「こういう種類のオブジェクトを作るよ」というルールだけを定義し、実際にどう作るか(中身)は書かない。
=インターフェースか抽象クラスで表現する
ファクトリーメソッド(Factory Method)は「単体のオブジェクト」を作るのに対して、
抽象ファクトリーは「セットで揃ったオブジェクト」を作るイメージ
関連するオブジェクト群をシステム内で作成する際、その作成方法や構成を他のプログラムの部分から分離するのに役立つ。
※https://recursionist.io/dashboard/course/8/lesson/656 より画像引用
このパターンはまた、オブジェクトの異なる抽象ファミリー(関連するグループ)を定義する際にも有効。開発者は、このパターンのインターフェースを用いて、自分たちのニーズに合わせた具体的なオブジェクト群を作成できる。
抽象ファクトリーパターンは通常、ファクトリーメソッドを使用してオブジェクトの作成を行なうが、プロトタイプパターンを使用するなど、他のオプションも可能。
抽象ファクトリーパターンでは、作成するオブジェクトの種類がインターフェースによって定義される。
これにより、他の開発者はこのインターフェースを API のように扱い、独自のオブジェクトを含むファクトリーを実装することが可能。
クライアントはこのファクトリーを使用してオブジェクトを生成する。
ファクトリーは特定のオブジェクト群(ファミリー)の作成に特化しているため、そのファミリーに含まれるオブジェクトの種類を事前に理解しておくことが重要です。
この点が抽象ファクトリーパターンの一つの大きな欠点になるため気をつけよう。
抽象ファクトリーに新しい機能(メソッド)を追加する必要が生じた場合、そのファクトリーが対応する全てのファミリーを更新する必要がある。この問題は、プロトタイプパターンを利用することで緩和することが可能だが、プロトタイプパターン自体が持つ特定のデメリットにも注意が必要になる。
使うタイミング
・複数の製品が、互いに組み合わせて使われる必要があるとき
・製品の種類(テーマ、スタイル、ブランドなど)をまとめて切り替えたいとき
Abstract Factory(抽象ファクトリー)
→ 製品群を作るための「インターフェース・抽象クラス」
Concrete Factory(具体ファクトリー)
→ 抽象ファクトリーを継承して、実際に製品を作るクラス
Abstract Product(抽象製品)
→ 各製品(ボタン・ウィンドウなど)の共通インターフェース・抽象クラス
Concrete Product(具体製品)
→ 抽象製品を実装した「本物の製品」
抽象ファクトリーの構造
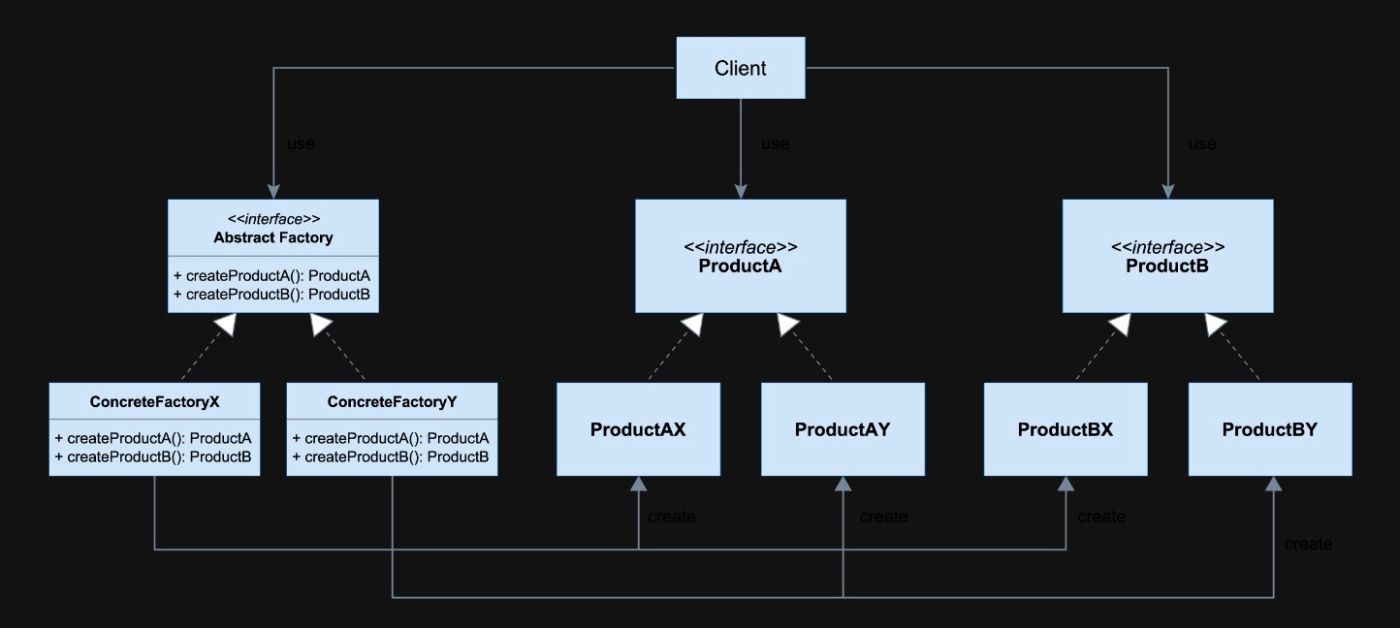
※https://recursionist.io/dashboard/course/8/lesson/657 より画像引用
「呼び出し側が具体的なクラスを知らなくてもいい」とは?
LowTierMonster monster = factory.createLowTierMonster();
monster.attack(); // ← これで動作する
monster という変数は AntarcticaLowTierMonster なのか DesertLowTierMonster なのか、呼び出す側(上記のコード)は一切知りません。
つまり、「LowTierMonster」という“共通の型(インターフェース)」だけを使えばよい
「どの地域のモンスターを生成するか」は、ファクトリーの中身を変えるだけで済む
→ 呼び出す側はコードを一切変更せず、モンスターのバリエーションを切り替えられる。
「具体的なクラスを知らなくてもいい」
依存を減らして、変更に強い設計にできる
依存:プログラムのある部分が、別の具体的なものに強く結びついている状態
AntarcticaLowTierMonster monster = new AntarcticaLowTierMonster(10);
「南極モンスターしか使えない」状態:特定のクラスに直接依存している
「別の地域のモンスターにしたい」と思っても、この行を書き換える必要がある
複数箇所で書いていたら、全部書き換えないといけないため、メンテナンスが大変
→ 「ファクトリーパターン」+「インターフェース型の戻り値」にすると
LaserTagMonsterFactory factory = new AntarcticaLaserTagMonsterFactory();
LowTierMonster monster = factory.createLowTierMonster();
monster は「南極モンスター」かもしれないし、「砂漠モンスター」かもしれない
呼び出し側は「LowTierMonsterという共通の性質をもつもの」として扱うだけでよい
生成するクラスを切り替えたいときは factory のインスタンスを変えるだけ
ポリモーフィズム(多態性)の強み
使う側は共通の型(インターフェース)しか見ない
実際にどのクラスのインスタンスかは、後から自由に切り替えられる
つまり、柔軟に差し替えられる=コードの再利用性・保守性が高くなるのがポリモーフィズムのメリット
ポリモーフィズムの本質は「共通の型で異なる振る舞いを扱えること」。
※ポリモーフィズムを実現できる2つの型
インターフェース
メソッドのシグネチャ(中身なし)だけを定義する。実装は各クラスに任せる。
例:interface Monster { void attack(); }
抽象クラス
共通の実装を含むことができる。部分的にメソッドを実装可能。
例:abstract class Monster { void roar() { ... } abstract void attack(); }
テレスコーピングコンストラクターパターン(Telescoping Constructor Pattern)
オプションの引数を持つインスタンスを作成するために、複数のコンストラクターを「重ねがけ(telescoping)」のように定義するパターン。
オブジェクトの構築に必要なパラメータが多い場合に、そのパラメータの組み合わせごとに複数のコンストラクタを作成するデザインパターンのことを指す。この方法では、必要なパラメータの組み合わせに応じて、異なるコンストラクタを多数用意する。
しかし、これによりコンストラクタの数が急激に増加し、コードの可読性や管理が困難になるという欠点がある。
たとえば、サンドイッチを作る場合、パンの種類、トッピングの数、野菜の種類など、多くのパラメータがある。テレスコーピングコンストラクターパターンを使用すると、これらの異なるパラメータの組み合わせごとに、別々のコンストラクタを用意することになる。
こうしたアプローチでは、全ての可能なケースをカバーすることはできません。
さらに、このコードは再利用性が低く、クラスのインスタンス化が非常に困難な元々の問題も未解決のままになる。
特徴と構造
このパターンでは、少ない引数のコンストラクタが、より多くの引数を持つコンストラクタを呼び出すという形で、引数が増えていくように構成する。
public class Pizza {
private int size;
private boolean cheese;
private boolean pepperoni;
private boolean bacon;
// 最小限のコンストラクタ
public Pizza(int size) {
this(size, false);
}
public Pizza(int size, boolean cheese) {
this(size, cheese, false);
}
public Pizza(int size, boolean cheese, boolean pepperoni) {
this(size, cheese, pepperoni, false);
}
public Pizza(int size, boolean cheese, boolean pepperoni, boolean bacon) {
this.size = size;
this.cheese = cheese;
this.pepperoni = pepperoni;
this.bacon = bacon;
}
}
※引数の数が異なる複数のコンストラクターを順番に定義しているため、「望遠鏡(telescope)」のように見えるというのが名前の由来。
利点
簡単で理解しやすい(小さなクラスでは有効)
欠点
・引数の順番が同じ型だと混乱しやすい
・引数の数が増えるとメンテナンス性が下がる
・オプションが多いと爆発的にコンストラクタが増える
解決策:Builder パターンへ
オプションが多い場合は、テレスコーピングよりも ビルダーパターン(Builder Pattern) の方が読みやすく、拡張性も高いため、そちらが推奨される。
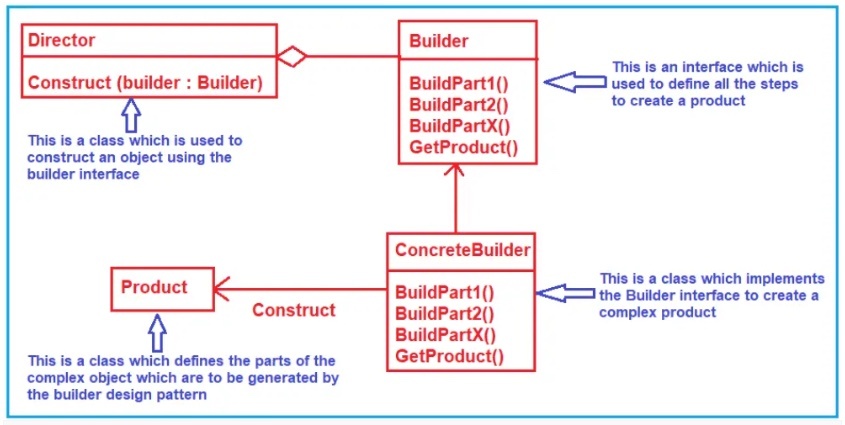
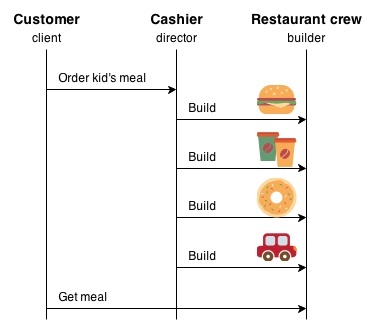
ビルダーパターン(builder pattern)
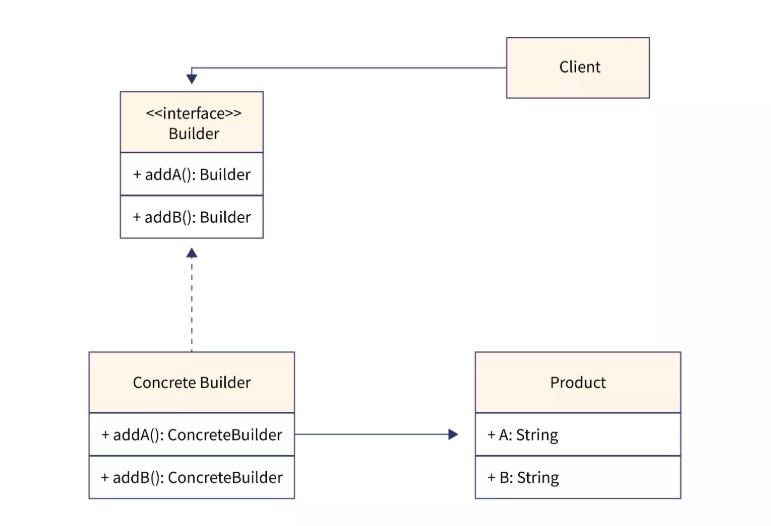
※https://www.scaler.com/topics/design-patterns/builder-design-pattern/ より画像引用
説明付き
※https://dotnettutorials.net/lesson/builder-design-pattern-in-java/ より画像引用
具体例
※https://sourcemaking.com/design_patterns/builder より画像引用
複雑なオブジェクトの構築を段階的に行なうために役立つ。
複雑なオブジェクトを分かりやすく段階的に作る方法を提供するデザインパターン。
主に「コンストラクターの引数が多くてわかりにくい」問題を解決するために使われる。
ビルダークラスには、オブジェクトを一つずつ構築するためのメソッドが含まれており、オブジェクトの準備が整ったら、特定のメソッドを実行して最終的にオブジェクトを生成する。
ビルダーパターンは、オプションが多い状態や将来的にオブジェクトが大きくなることが予想される場合に特に有用。
ステップごとに値を設定し、最後に build() メソッドで完成させるようにする。
プロパティを一つひとつ設定して、最後に build() で完成形にする流れが「段階的な生成」
オブジェクトを作成する準備ができたら、Creation Method が実行され、Builder は多くの場合ではリセットされる。Builder Pattern は複雑なオブジェクトを作成する場合や、多くのオプションを状態として持つ場合、将来オブジェクトが大きくなることがあらかじめわかっている場合に非常に便利になる。
「コンストラクタでリセット」は、「ビルダーは常にまっさらな状態からスタートできるようにするための初期化処理」
◎「再利用性」と「状態の独立性」がビルダーパターンの設計のカギ
build() メソッド
→ ビルダークラスのプロパティ(具材や調味料など)を使ってオブジェクトを作成・返却する
→ buildメソッドの中にあるthis.reset() の目的
→ ビルダークラス自身のプロパティを初期状態に戻すため
→ 次のオブジェクト作成のためにビルダー内部を初期化しておく
この状態を都度リセットするという設計により、ビルダーは使いまわしができるようになる。
・Sandwichクラス:完成品(データを持つだけ)
・SandwichBuilderクラス:部品を1つずつセットして Sandwich を作る技術者
・SandwichDirectorクラス:レシピ通りにビルダーに命令して、決まった商品を作る指揮者
ビルダーパターンの利点は、オブジェクトの作成プロセスを明確に分離し、このプロセスを段階的に行えることにある。これにより、処理の順序を自由に設定でき、より柔軟なプログラミングが可能になる。
ビルダーパターンで「処理の順序が重要」なケース
・特定の部品が前提になる(順番を守らないとロジック的におかしい)
・後に設定する部品が、前の部品に依存する
・構築手順が業務ルール(ビジネスロジック)に影響される
例として、データベースから取得した請求書 ID のリストを操作するビルダーがある。このビルダーは ID リストをフィルタリングし、特定の順序でソートする機能を持っている。このシナリオでは、各処理の実行順序が非常に重要。なぜなら、処理の順序によって最終結果や処理速度が変わってくるため。
不変オブジェクトの作成にはビルダーパターンが適している。ビルダーパターンでは、オブジェクトの作成プロセスを分割し、段階的に構築することができるが、作成後に状態を変更することはできない。
また、多くのフレームワークやライブラリでは、ビルダークラスにメソッドチェーンを適用することがある。これは、各ビルダーメソッドがvoidではなくビルダー自身を返すことによって、一連のメソッド呼び出しを連続して行なえるようにするもの。これにより、コードの可読性が向上し、より流暢なインターフェースを提供することができる。
プライベート変数とは、「そのクラスの外からはアクセスできない変数」のことで、privateフィールドのことを指す。
ディレクター(director)
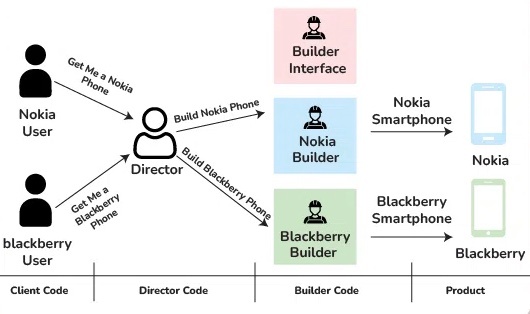
※https://www.geeksforgeeks.org/builder-design-pattern/ より画像引用
ビルダーパターンは、複雑なオブジェクトの構築に特化し、オプションや構築の順序に対して高い柔軟性を提供する。ビルダーパターンにはディレクター(director)という概念を組み込むことも可能。
ディレクターは、特定のビルダーを用いてオブジェクトを構築するための手順と引数が事前に定義されたメソッドを持つクラス。
ディレクターのメソッドは、ビルダーを取得し、所定の手順(stepA、stepB、stepC など)を実行してビルダーを返す。この後、最終的なオブジェクトを生成するための build() メソッドを呼び出すか、追加のビルダーメソッドを用いてオブジェクトをさらにカスタマイズできる。
ディレクターはオブジェクトを直接返さず、ビルダーを返すため、呼び出し元はチェーン化されたカスタマイズ(調味料の追加や野菜の変更など)を行なうことができる。
ビルダー自体も拡張可能。ビルダーの最大の利点の一つは、下位互換性が完全に保たれていること。将来の変更があっても、ビルダーを使用している他のクライアントコードを変更する必要がないため、特に多くのユーザーに使用されているソフトウェアにおいて、新機能の拡張や提供において重要な要素となる。
・ビルダー:部品を一つずつ指定して組み立てる職人
・ディレクター:その職人に「こうやって作って」と手順を指示するマネージャー
複雑なオブジェクトを定型的に、再現性高く作るときに便利
| 役割 | 説明 |
|---|---|
| Builder(ビルダー) | 部品や手順(ステップ)を定義する。 例:パンを選ぶ、具材を入れる、サイズを決めるなどの細かい構築方法を知っている人 |
| Director(ディレクター) | 決まった順序でビルダーのメソッドを呼び出して、 目的の完成品(例:特定のサンドイッチ)を作る。 レシピを知っている人。 |
| Product(製品) | 最終的に出来上がるオブジェクト。 例:サンドイッチ、パソコン、ロボットなど |
ビルダーパターンは、作成するオブジェクトの種類を決定するキーを取り込むことで、サブクラス化やシンプルファクトリ、ファクトリメソッドなどの他のデザインパターンと組み合わせることができる。このパターンは、オブジェクト作成の複雑さをカプセル化し、開発者が使いやすいようにカスタマイズできるようにする。
オブジェクト指向プログラミング(OOP)のデザインパターンは、共通のパターンを定義するが、具体的な問題に対するニーズに合わせてパターンを調整する必要がある。多くの場合、単一のパターンだけでなく、複数のパターンを組み合わせて使用し、独自のアーキテクチャを構築する。
ビルダーパターンの一般的な構造
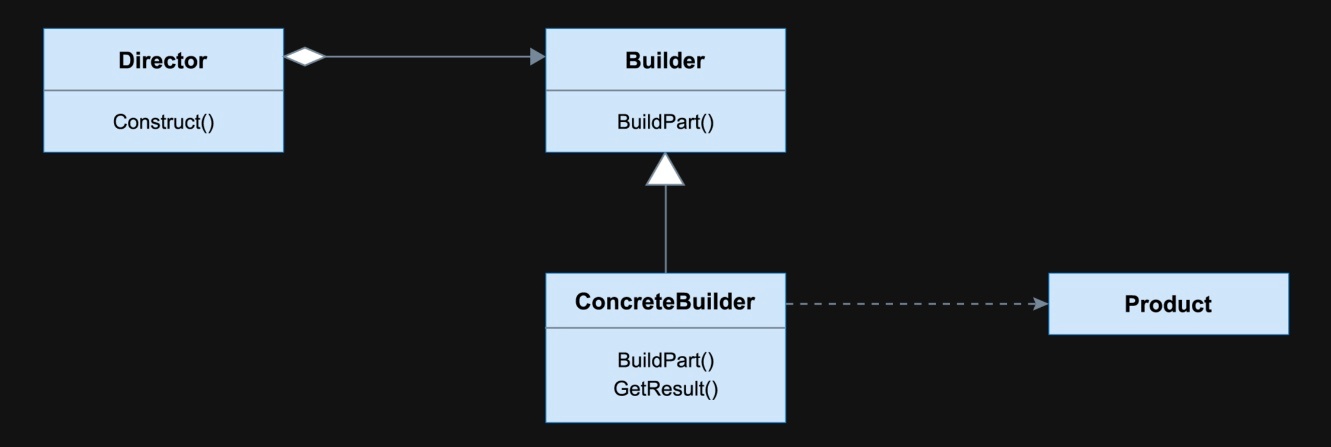
※https://recursionist.io/dashboard/course/8/lesson/664 より画像引用
ビルダーパターンは複雑なオブジェクトの作成をクラスから切り離し、単一の場所に集約し、単一責任原則を守ることを目的としている。ただし、サポートに対して余分な作業を多く必要とし、コードベースが複雑化してしまう恐れがあることがため、使用する際には慎重に検討する必要がある。
ビルダーの下位互換性(Builder's Backward Compatibility)
ビルダーパターンを使用してオブジェクトを作成する際に、新しいバージョンのビルダーやオブジェクト構造が古いバージョンとも互換性を保つことを指す。ビルダーパターン自体はオブジェクトの生成を効率化し、設定可能なパラメータを明示的に管理するために使用されるが、この「下位互換性」という概念は、システムやコードが進化しても、古いバージョンのコードや設定方法を破壊することなく、新しい機能を追加できることを意味する。
ビルダーパターンを使用する場合に考えられるシナリオ
新しいフィールドやオプションの追加
古いバージョンのビルダーでは、たとえばcolorフィールドしか設定できなかったとする。
新しいバージョンでは、sizeやshapeなどの新しいオプションが追加されることがある。しかし、古いコードが新しいビルダーを使ったとしても、古いフィールド設定(例えば、colorだけ)で問題なく動作するようにしなければならない。
柔軟なデフォルト値
新しいバージョンで追加されたフィールドにはデフォルト値を設定し、既存のコードがそのフィールドを設定しない場合でも動作するようにする。
たとえば、古いコードでcolorだけを設定して新しいコードでsizeが追加された場合、sizeにデフォルト値を与えておくと、古いコードでもエラーなく動作する。
インターフェースの変更
新しいビルダーに変更を加えた場合でも、古いインターフェースを保ち、古いコードが新しいビルダーを問題なく利用できるようにする。
たとえば、メソッド名や引数の数が変わっても、古いメソッドと新しいメソッドを併用できるようにすることが求められる。
ビルダーにおける下位互換性を確保する方法
オプション引数やデフォルト値を使用
新しい引数やパラメータを追加する際、既存の引数にデフォルト値を設定することで、既存コードを壊すことなく新しい機能を追加できる。
Builderクラスの継承
新しいビルダーを作成する際に、古いビルダーを継承して拡張する方法。これにより、古いビルダーがサポートする構造を保ちながら、新しいビルダーを作成できる。
ファクトリーメソッドの使用
古いバージョンのオブジェクト作成方法をファクトリーメソッドとして維持し、必要に応じて新しいビルダーメソッドに切り替えることで、下位互換性を保ちながら新しい機能を利用できるようにする。
継続的なテスト
新しいビルダーで古いコードの動作確認をすることで、互換性が保たれていることを検証する。
レジストリ
ある種類のオブジェクトやデータを、動的に登録・管理・取得する仕組みのこと
データやオブジェクトを動的配列として保存し、インデックスを使ってそれらを効率的に取得することを可能にする。
シナリオ
訪問者が写真を撮影し、デコレーションするためのフォトブースを設置している遊園地
このブースでは、ユーザーが様々なスタンプを選んで写真に適用することができる。これらのスタンプは「マイツールボックス」と呼ばれるツールボックスに収められ、ユーザーはここから好きなスタンプを写真に何度でも貼り付けることができる。
ただし、どのスタンプが使われるかを予測することは難しく、ユーザーは虹のスタンプや四角いスタンプ、文字のスタンプ、ロゴのスタンプなど、何千もの中から選ぶことができる。たとえば、ユーザーが虹のスタンプと文字のスタンプを選んで、写真に何回もこれらを使用する場合、システムはどのようにこれらのスタンプを効率的に管理すればよいでしょう?
この問題を解決するために、レジストリを利用することができる。
レジストリは、スタンプを動的配列として保存し、インデックスを使ってスタンプを効率的に取得することを可能にする。例えば、ユーザーが虹のスタンプを選択した場合、それをスタンプの配列に追加し、必要に応じて取得する。
さらに、防御的コピーを用いることで、スタンプのオブジェクトを何度も作成することなく、元の状態を保持することができる。これは、スタンプのサイズや形状などの属性を変更しても、元のスタンプの状態を維持し、意図しない副作用を避けるために重要。オブジェクトのコピーを作成して元の状態を保存することにより、ユーザーが自由にスタンプをカスタマイズしても、常に元のスタンプを再利用できるようになる。
プロトタイプパターン(Prototype Pattern)
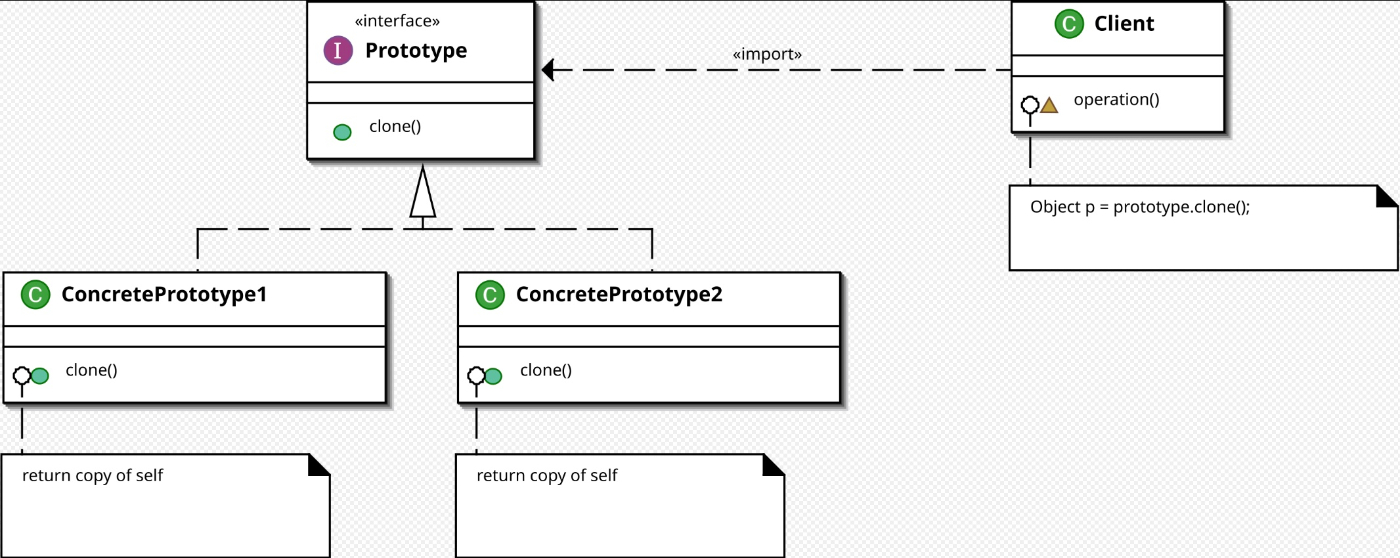
※https://ja.wikipedia.org/wiki/Prototype_パターン より画像引用
オブジェクトを複製するためのデザインパターンの一つ。
このパターンでは、既存のオブジェクトをコピーして、新しいインスタンスを作成する。特に、オブジェクトを生成する際にコストが高かったり、オブジェクトの初期化が複雑である場合に効果的。
プロトタイプパターンの目的
オブジェクトの生成コスト削減
新しいオブジェクトを一から作るのではなく、既存のオブジェクトをコピー(クローン)して新しいインスタンスを生成する。これにより、オブジェクト生成にかかる時間やリソースを削減できる。
複雑なオブジェクトの簡単な複製
初期化が複雑なオブジェクトを一度作成し、その後はコピーするだけで新しいオブジェクトを生成できる。
プロトタイプパターンの構成要素
プロトタイプ(Prototype)
クローン可能なオブジェクトのインターフェースを定義。通常は、clone() メソッドを持っている。このメソッドがオブジェクトをコピーするための重要な部分。
具体的なプロトタイプ(Concrete Prototype)
Prototype インターフェースを実装したクラス。このクラスは、実際に複製されるオブジェクト。
クラスは、オブジェクトの状態を保存し、clone() メソッドをオーバーライドして複製する。
クライアント(Client)
clone() メソッドを呼び出して、プロトタイプを複製する。クライアントは、複製したオブジェクトを利用する。
プロトタイプパターンの基本的な流れ
① 初期オブジェクト(プロトタイプ)を作成
② プロトタイプをクローンして、新しいオブジェクトを作成
③ クライアントがその新しいオブジェクトを使用する
このパターンでは、システム実行時にオブジェクトを一度作成し、その後は同じ種類のオブジェクトを必要なだけ作成する際に、この初期オブジェクトを複製(クローン)して使用する。
たとえば、データベースからダウンロードするスタンプの生成に 5 秒かかると仮定した場合、同じスタンプを何度も作成する際に毎回 5 秒待つのは非効率的となる。プロトタイプパターンを使うことで、最初に 1 回スタンプをダウンロードし、それ以降はこのダウンロードしたスタンプのクローンを作成することで、待ち時間を削減できる。
プロトタイプパターンには、キーとオブジェクトのペアで構成されるレジストリが含まれる。このレジストリは、動的配列やハッシュマップの形で実装されることがある。
各プロトタイプオブジェクトは、自身を複製する clone() メソッドを実装している必要がある。
オブジェクトを正確にクローンする方法、オブジェクトをディープコピーする方法の詳細はカプセル化されており、その処理を定義するのはクラス次第になる。
受け取ったキーを使って、プロトタイプファクトリーから対応するクローンオブジェクトを生成する方法などがある。
プロトタイプパターンは、オブジェクトのクローン(複製)を作成する方法に重点を置いている。
この方法では、同じクラスの既存オブジェクトを元に新しいオブジェクトを構築するためにオーバーロードされたコンストラクタを使用するのが効果的なケースもある。このプロセスは、特に両方のオブジェクトが同じクラスに属している場合、プライベートな状態へのアクセスを容易にする。
しかし、複雑なオブジェクトの場合、ディープコピー(完全な複製)を行なうのは簡単ではない。
こうした状況では、オブジェクトを文字列やバイト列に変換し、その後再びオブジェクトに戻すシリアライズアルゴリズムが必要になることがある。
また、プロトタイプパターンはレジストリを活用する。このレジストリは、与えられた入力に基づいてオブジェクトを動的に生成するファクトリの役割を果たす。これは、特定のメソッドを呼び出すのではなく、与えられたキーに応じて同じメソッドを呼び出す点で、抽象ファクトリーと似ている。さらに、このアプローチには実行時にファクトリーにオブジェクトを動的に追加する機能も含まれる。
プロトタイプパターンは便利ですが、いくつかの欠点がある。抽象ファクトリーやビルダーと同様に、プロトタイプのためのレジストリを作成することは複雑になることがある。抽象ファクトリーがファクトリーメソッドを使用してサブクラスによる拡張性を提供するのとは異なり、プロトタイプパターンではクライアントが利用するオブジェクトの作成手順をほとんど制御できない。
また、プログラム実行時に要素を動的に作成するため、コンパイル時のチェック(例えば、特定のメソッドが存在するかどうかの確認)の恩恵を完全に受けることができない場合がある。
さらに、ファクトリーメソッドとは異なり、プロトタイプパターンでは、ファクトリーのレジストリに配置されたオブジェクトを新たにインスタンス化する必要がある。
これに対して、ファクトリーメソッドでは、既に作成されたオブジェクトやオブジェクトプール内のオブジェクトを再利用することが可能。
プロトタイプパターンのメリット
複雑なオブジェクトの生成を簡単にする
オブジェクトの初期化に時間がかかる場合でも、一度作成したオブジェクトを複製して使うことで効率的に新しいオブジェクトを作成できる。
柔軟性
オブジェクトをクローンすることで、変更が必要な部分だけを新しいオブジェクトに適用できる。元のオブジェクトに影響を与えることなく、新しいバリエーションを作成できる。
プロトタイプパターンのデメリット
オブジェクトのクローンが複雑な場合
オブジェクトが非常に複雑で、深いコピーが必要な場合、clone() メソッドが複雑になり、管理が難しくなることがある。
シャローコピーとディープコピー
デフォルトでは、clone() メソッドは浅いコピーを作成する。深いコピーが必要な場合は、clone() メソッドをオーバーライドして実装する必要がある。
プロトタイプパターンの使いどころ
オブジェクトの生成に高コストがかかる場合
例えば、大きなデータ構造や複雑な設定が必要なオブジェクトを頻繁に生成する場面
似たようなオブジェクトを複製して使う場面
ユーザーインターフェースのコンポーネントやゲームキャラクターなどで、基本的なプロトタイプをクローンして似たようなオブジェクトを生成したい場合