データベース
データベースシステム
※https://anken-hyouban.com/blog/2021/02/09/dbms/ より画像引用
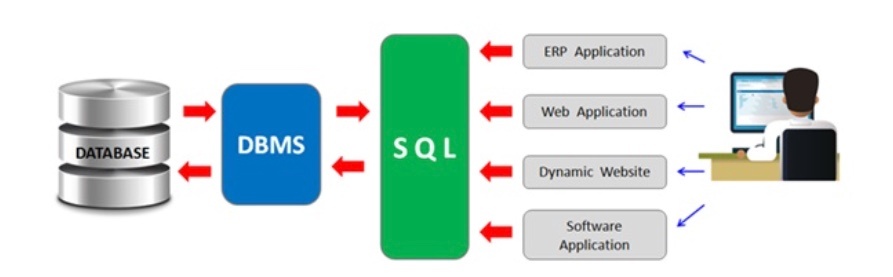
データベース(情報の集まり)を効率的に作成・管理・操作するためのソフトウェア。
ユーザーやアプリケーションがデータを安全に保存・検索・更新・削除できるようにする役割を持っている。
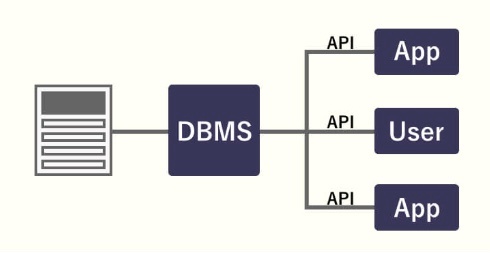
データにアクセスする流れ(全体像)
アプリケーション → API(インターフェース) → DBMS → データベース(実際のデータ)
※https://www.learncomputerscienceonline.com/database-management-system/ より画像引用
データの永久保存
| 項目 | メモリ(RAM) | データベース(DB) |
|---|---|---|
| 目的 | 一時保存 | 永久保存 |
| データの保持 | 電源OFFで消える | 電源OFFでも残る |
| 処理速度 | 非常に速い | 遅い(が、十分実用的) |
| 用途の例 | セッション、キャッシュ等 | ユーザー情報、ログ等 |
メモリ or データベース
ソフトウェアを扱う際、ほとんどのプログラムはデータの永久保存が必要となる。
通常、コンピュータの CPU はメモリを介して直接動作するが、メモリはハードウェア的な理由から揮発性(volatile)を持つ。つまり、メモリ内のデータを保持するために電力を必要とし、メモリの電源を切ると、メモリ内のデータはすぐに失われてしまう。
そのため、恒久的に保存されているデータを取り出したり、保存したりする方法が必要になるが、これにも課題がある。単にメモリの電源を常にオンにしたり、データをファイルとしてオペレーティングシステムに保存するという手段も考えられるが、データベースシステムを活用する方法もある。
データベースは非常に複雑で、膨大な量の作業負荷を処理している。
低・中規模のソフトウェアでは、数十テラバイトのメモリを使用し、1 秒間に何万回もデータにアクセスして更新する。ソフトウェアエンジニアは、臨機応変に対応できる汎用性の高いストレージシステムを必要とする複雑な構造を扱い、データサイエンティストはソフトウェアが収集したさまざまなデータセットにアクセスして分析を行なう。
一方、大規模なソフトウェアでは数百万人のユーザーを扱うことが多いため、データの保存と取得に対して拡張性を持つ方法が必要となる。その結果、保存されるデータの量と 1 秒間にアクセスされるデータの量は驚異的なものとなり、通常のソフトウェアとは異なる問題や課題が発生する。
機能、物理的特性、論理、プロトコルを 1 つのソフトウェアツールに抽象化し、データの保存や読み書きを可能にするシステムのことをデータベース管理システム(DBMS : Database Management System)と呼ぶ。データベース管理システムは、組織化されたデータの集合体を持ち、データへのアクセス、操作、管理を行うプログラムの集合を提供する。
データベースの種類
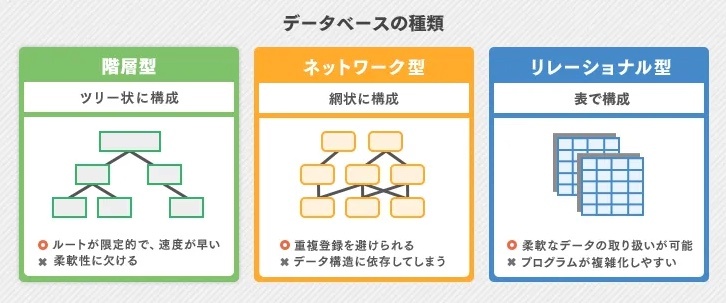
※https://it-trend.jp/database/article/89-0066 より画像引用
RDBMS:SQLを利用するデータベース管理システム
NoSQL:SQLを利用しないデータベース管理システム(データが構造化されていない)
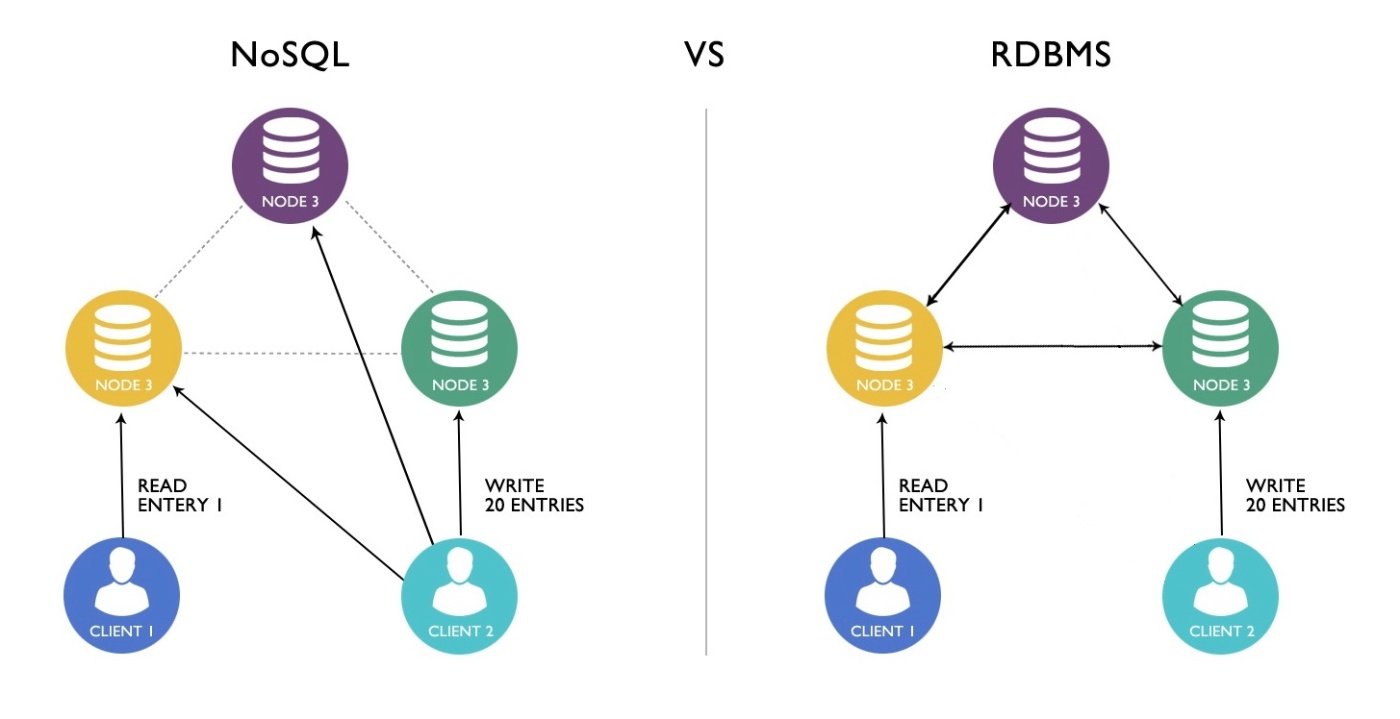
※https://www.flexsin.com/blog/nosql-and-rdbms-advantages-and-challenges/ より画像引用
比較
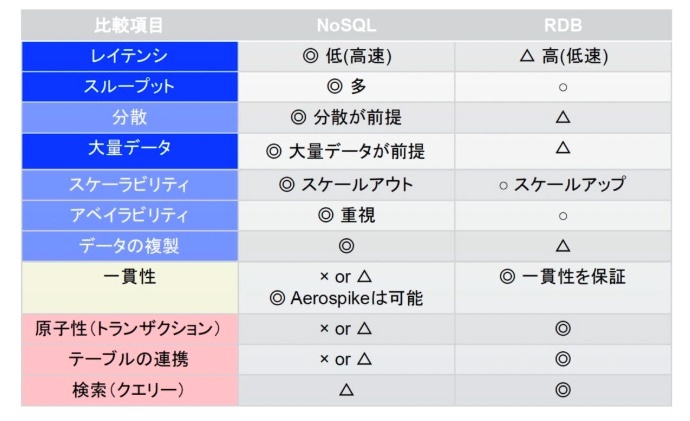
※https://aerospike.co.jp/blog/what-is-nosql/ より画像引用
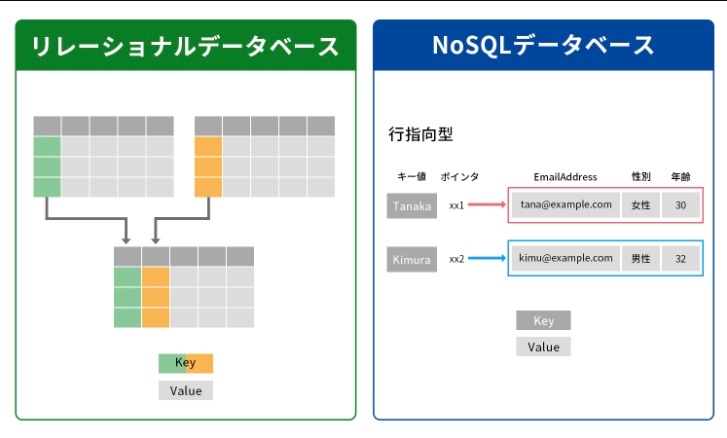
※https://x-tech.pasona.co.jp/media/detail.html?p=9063 より画像引用
OSによるデータの取り扱い
オペレーティングシステムには、データをファイルとしてストレージに保存する方法が備わっており、プログラミング言語には、ファイルを読み書きするためのライブラリが用意されている。
このファイル処理システムによって、あらゆる種類のデータをローカルストレージに保存し、後から読み出すことができる。シリアル化や逆シリアル化を行なうこともある。
シリアル化(serialize):データ構造をファイルに格納できるように文字列やビット等の形式に変換すること。データ(オブジェクト)を、保存・送信可能な形式に変換すること。
→ オブジェクト(箱の中の複雑なデータ)を、一列に並べて文字列やバイト列に変換するイメージ
逆シリアル化(deserialize):ファイルを読み込んでメモリ内のオブジェクトに戻すこと。シリアル化されたデータを、元のオブジェクトに戻すこと。
よく使う形式:JSON, XML, YAML, バイナリ, Pickle など
シリアル化のイメージ
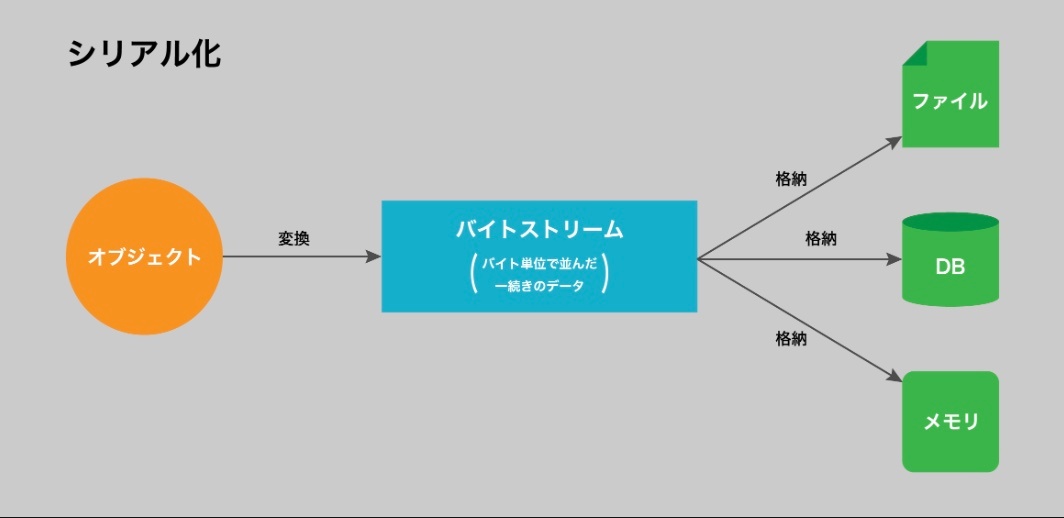
※https://recursionist.io/dashboard/course/6/lesson/670 より画像引用
複雑なソフトウェアにおける問題点とDBMS
ファイルへの簡単な保存だけなら、シンプルなソフトウェアであれば問題ないかもしれないが、複雑なソフトウェアでは以下のような問題が発生し、すぐに手に負えなくなってしまう。
・データ構造の変更や、バックアップはどうするのか?
・データの重複、繰り返し構造をどのように回避するのか?
・データの制約をどのようにチェックするのか?
・複数のクライアントがファイルにアクセスする際のセキュリティや並行性はどうするのか?
・データへのアクセスや分析は簡単で再利用可能なのか?
・ファイルは破損しないのか? 読み書きをどうやって拡張するか?
これらは、ファイルの作成や管理等、手動でデータを保存する際に、効率性という点で問題になってしまう。
このように、多くの機能が必要であり、それらの機能を全て抽象化して、アプリのクライアント、開発者、データサイエンティスト、データベース管理者など、さまざまなタイプの利用者が簡単かつ効率的に使用できるシステムにすることが重要になる。
これは単なるファイルではなく、データベースであり、このシステムがデータベース管理システム(DBMS)となる。
本来データベースは、大量のユーザーが少量のデータを読み書きするトランザクション処理と、データサイエンティストのような少数のユーザーが大量のデータを分析する、データ分析の両方に使用される。
例えば、Twitter では、ユーザー 1 人がタイムラインを読んだり、ツイートするのに必要なデータは 10MB 程度だが、少数で構成されるデータサイエンティストが扱うデータは何十万テラバイトにもなる。
トランザクション(transaction)とは、データエントリの更新など、状態の変化を表すデータベースシステム内の作業単位のことを指す。
トランザクション

※https://recursionist.io/dashboard/course/6/lesson/670 より画像引用
より具体的なトランザクション
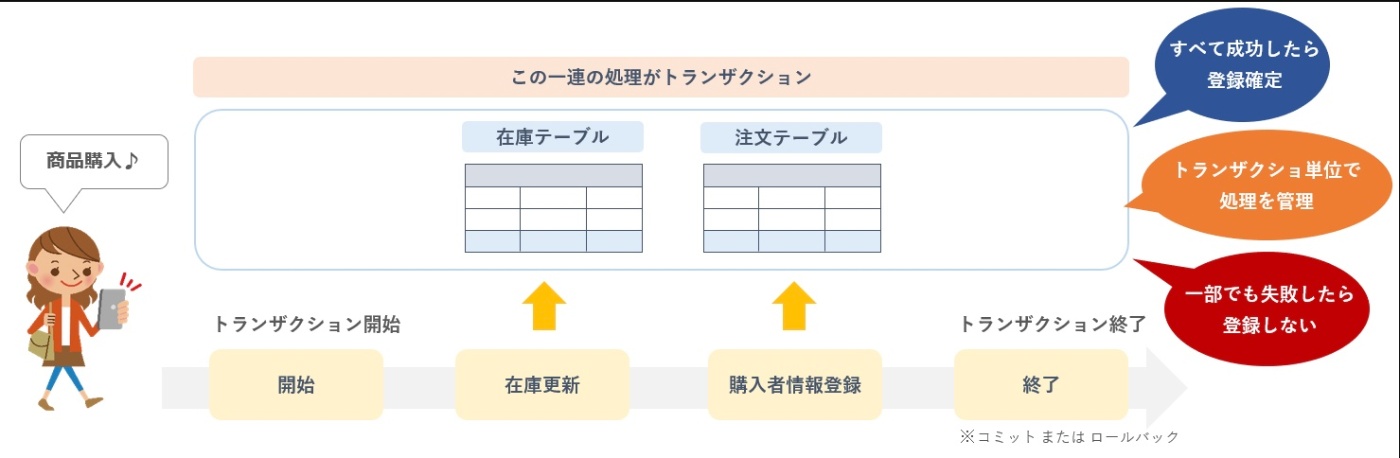
※https://medium-company.com/トランザクション/ より画像引用
トランザクションを終了するときは、一連の処理を「確定させるのか(コミット)」「破棄するのか(ロールバック)」の命令を実行しトランザクションを終了する。
DBMS は、優れた技術を使って利便性と効率性を実現しなければなりません。つまり、保存されているデータの複雑な構造等に対して、開発者がデータを簡単に読み書きできるようにしながら、カプセル化を行なう必要がある。抽象化を行なうことで、内部の複雑度を隠すことができるため、ブラックボックスとして入出力を用いてデータベースを管理することができる。
また、データはソフトウェアに不可欠な要素。データが重要な役割を果たすということは、言い換えると、それを管理するシステムも同様に重要な存在になるということ。
データベースの特性
データベースシステムは、次のような特性を全て抽象化して、利便性の高いツールになっている。
① 利便性 (ease of use)
データベースシステムを使うと、あらゆるユーザーがデータに簡単にアクセスし更新することができる。
データベースは、開発者がデータを照会(クエリ)できるように、一連の言語ツールを提供している。
クエリ(query)とは、データを取得したり操作したりするために、データにアクセスするリクエストのことを指す。
開発者がアプリケーションを作成した場合、クエリを使うとユーザーが一定量のデータや特定の種類のデータにしかアクセスできないように制限することができる。プログラミング言語やフレームワークの中には、データにネイティブに接続したりアクセスするための多くのツールがあらかじめ組み込まれているものもある。
例えば、過去 1 ヶ月間に発生した全ての銀行取引を表示するクエリがあると仮定する。
このとき、開発者は、アプリのユーザーがアクセスできるビューやデータの量に対して自由に制限をかけることができる。つまり、銀行口座の所有者のみが自分の口座の詳細を閲覧することができ、銀行員は限られた量のデータにしかアクセスできないように設定することができる。
データサイエンティストは、データベース内のデータを効率的に分析することができる。クエリは全ての階層において微調整可能で、複数のデータセットを相互に参照し、演算、述語、集約関数を適用することによって、さまざまなデータを得ることができる。データ分析ソフトウェアやカスタマイズされたソフトウェアを使うことによって、データを探索したり、データを視覚的に確認したりすることもできる。統計学と各専門分野の知識を組み合わせることで、ビジネスにおいて優位な意思決定を行なうことができる。
データベース管理者は、さまざまなツールやコマンドによってデータベースを管理する。一般的な機能として、サーバ管理、バックアップ、インポート/エクスポート、レプリケーション、インデックス、物理的なストレージアルゴリズム、ユーザー認証等がある。
② 永続性(durability)
永続性とは、一度コミットされたトランザクションが、システム障害(コンピュータのシャットダウンなど)が発生しても、コミットされた状態を維持することを意味する。これは、コンピュータディスクのハードドライブに直接保存するなど、不揮発性を持つストレージによって実現される。
データベースシステムがメインメモリを使用して全てのデータを保存している場合でさえも、システムは常にディスクストレージ内にバックアップを保持している。
DBMS(データベース管理システム)がソフトウェアでありながらデータを永続的に保存できるのは、データベースの実体(データそのもの)がハードディスクドライブ(HDD)やソリッドステートドライブ(SSD)といったストレージデバイスに保存されているためである。
DBMSの役割
DBMSは、データベースを効率的かつ安全に管理・操作するためのソフトウェア。ユーザーやアプリケーションからの「データを追加したい」「特定のデータを検索したい」「データを更新したい」といった要求を受け付け、それを解釈して実行する。
データの保存場所
DBMS自体はコンピュータのメモリ上で動作するプログラムだが、管理対象であるデータそのものは、ストレージ上のファイル(データベースファイル)に書き込まれる。ストレージは電源を切っても内容が消えない不揮発性メモリなので、データは永続的に保持される。
DBMSとストレージの関係
DBMSは、メモリとストレージの間でデータのやり取りを管理する仲介役と言える。
・データを書き込む際、DBMSはメモリ上のデータをストレージ上のデータベースファイルに書き込む指示を出す。
・データを読み出す際、DBMSはストレージ上のデータベースファイルから必要なデータをメモリに読み込み、ユーザーやアプリケーションに渡す。
③ 一貫性と統合性(consistency and integrity)
システム内のデータは、特定の情報を参照する異なるセクションが、全て同じデータを参照するように、一貫性を保つ必要がある。
例えば、オンラインショップのユーザーのメールアドレスが記録された場合、そのユーザーの請求書、連絡先、領収書、購入品には、同じユーザーの電子メールを含み、仮にユーザーが電子メールを更新した場合においても、システム全体で一貫性が保たれ、コピーや参照が全て一致する必要がある。
データエントリは、一貫性を保証するために、制約と呼ばれる指定されたルールに従う必要がある。
例えば、ユーザーの給与を数字で入力する必要があるにもかかわらず、文字列が入力された場合、システムが整合性エラーを直ちに認識するべきで、制約条件に従わない場合は、直ちにエラーとなり、トランザクションは実行されるべきではない。
統合性に関するルールは、参照チェック等、データベース内の一貫性を維持するために使用される。
例えば、エントリが他のエントリを識別子(id 等)で参照する場合、チェックを行い id が存在することを保証する必要がある。仮に参照しているデータエントリが削除された場合、他の参照を削除または修正するカスケードやロールバックなど、一貫性を保つためのルールが設けられている場合がある。
データエントリが入力または更新されると、データベースは以前の状態から新しい状態、つまり古いデータから新しいデータへと移行する。新しい状態に移行する前に、この新しい状態が有効であることを保証しなければ、以前の有効な状態に戻ってしまう。これがデータベースシステムの一貫性を保証するものになる。
※データエントリ:データを入力・登録する「作業」そのもの、または、入力された「データ項目」や「レコード」そのもののこと。
データベース内の個々のデータ値や、データの一行(レコード)を指したりする。
④ 冗長性の低減(reduce redundancy)
データベースシステムは、データが効率的に整理されているという物理的な特性を持っている。つまり、データベースを慎重に設計することで、相互参照が可能になり、不必要な重複を減らし、データベースのストレージ使用量を低く抑えることができる。冗長性が減ることで、インデックスアルゴリズム等がより強力になり、データへのアクセスをより速く実行することができるようになる。
データベースの特性
⑤ 独立性と並行性 (isolation and concurrency)
データベースシステムでは、データを分離・独立させることができる。エントリが入力されると、そのエントリは所定の位置にロックされるか、または「コミット」される。エントリを読み込む際には、データ形式が保証されているので、linux、macOS、windows、その他のプラットフォームから読んでも、システムは同じデータを読み込むことができる。
1 秒間に多くのデータベースの呼び出しが実行されているため、異なるプログラムやクライアントが同じデータや構造に同時にアクセスし、全てのエントリーを同時に更新しようと試みることもある。エントリの更新など、データベースのエントリに対するトランザクションが行われると、それは分離され、完全にコミットされるまで独立して処理される。エントリに対して複数の更新が行われた場合、分離が適用されていれば、更新は全て同時に行われるのではなく、順次処理されているかのように 1 つずつ行われることになる。
※コミット:トランザクション内で行なわれた一連の変更をデータベースに永続的に反映させる操作。コミットが実行されると、それまでのデータの変更は確定され、他のトランザクションからも参照できるようになる。
※ロールバック:トランザクション内で行われた一連の変更をすべて取り消し、トランザクション開始前の状態に戻す操作。ロールバックは、トランザクションの途中でエラーが発生した場合や、意図しない変更が行なわれた場合に実行される。
例えば、イベントのチケットを販売するアプリケーションを想像してみる。
チケット販売が開始されると同時に、何千人ものユーザがイベント A のチケットを購入しようとする。チケットの現在の在庫が 3430 枚で、ユーザー K が 5 枚のチケットを、ユーザー L が 2 枚のチケットを同時に購入する状況を考えてみよう。トランザクションが分離されていない、同時進行のデータベーストランザクションでは、システム内で何が起こるか把握することはできない。
例えば、仮に K が先に 5 枚のチケットを購入したとしても、L の 2 枚のチケットのトランザクションが邪魔をしているせいで、チケットの合計が 3428 枚と表示されてしまう可能性がある。その逆に、L がチケットを先に購入しているにもかかわらず、K のトランザクションが邪魔をしてトータルが 3425 枚になってしまう可能性もある。本来ならば、最終チケットは 3423 枚になるはずだが、上記のケースではチケットの在庫数の計算の整合性が合わない。
独立したトランザクションでは、K と L のどちらが先に処理されても問題ない。2 つの処理は分離されるので、トランザクションは 1 つずつ進み、他のトランザクションが終わってから次のトランザクションに移ることになる。つまり、一連の操作が 1 つずつ適用され、全て合格して状態が更新されるか、全て失敗して状態が更新されないかのどちらかになる。
K, L の順 -> 3,430 - 5 = 3,425, 3,425 - 2 = 3,423
L, K の順 -> 3,430 - 2 = 3,428, 3,428 - 5 = 3,423
⑥ 原子性(Atomicity)
原子性とは、「原子」という言葉に由来しており、分割できないものという意味を指す。データベースのトランザクションにおいて、システムの状態を変化させる一連の操作が、全体的に起こるか、あるいは全く起こらないことを意味する。これは、障害やエラーの発生からデータを守るために非常に重要になる。
例として、ユーザーがある大学へ授業料を支払う場合を考えてみよう。
クレジットで 1 万ドルを支払った際に、システム障害が発生したとする。クレジットが削除されたにも関わらず、システム上で学生が授業料を支払っていないと表示されてしまう可能性がある。
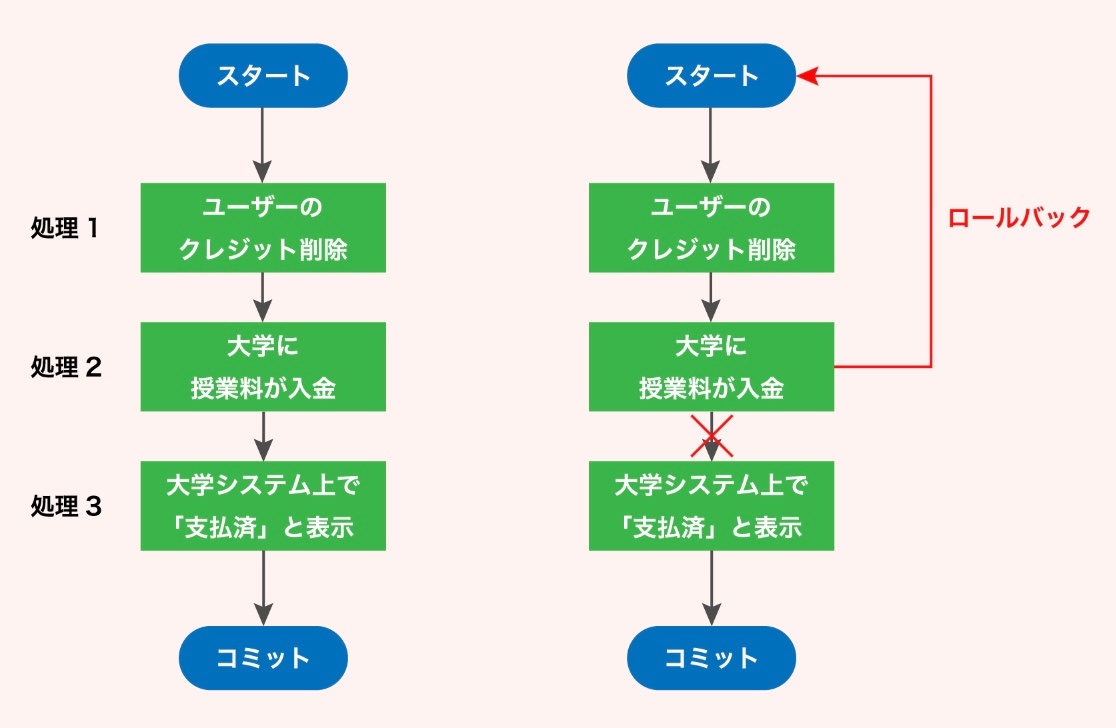
※https://recursionist.io/dashboard/course/6/lesson/672 より画像引用
この場合、データベースが原子性を持つことは非常に重要になる。つまり、1 万ドルのクレジットが削除され学生の授業料が支払われるか、あるいは完全に何も起こらないという 2 つの選択肢のみを持つことになる。仮に、途中でエラーが発生しても、クレジットは削除されない。
実際の開発では、トランザクションの処理が途中で終わった場合は、前の状態にロールバックすることが通例となる。
トランザクションが完全に行われ、状態がコミットされて新しい状態になるか、何も起こらずに以前の正しい状態に戻る、「all-or-nothing」 が適用される。
ACID
原子性(Atomicity)
一貫性(Consistency)
独立性(Isolation)
永続性(Durability)
は、データベースシステムの基本であり、主要な要素になる。
⑦ セキュリティ(security)
データが非常に貴重なものである以上、データベースシステムにはセキュリティが不可欠。セキュリティは、意図的かどうかを問わず、データのアクセスや更新に対して行われる安全対策のことを指す。システムは認証メカニズムを提供し、データがしっかりと管理されるようにする。
例えば、ソーシャルメディア上での個人情報について考えてみよう。
アプリ上で何らかのトラブルが発生したため、ユーザーがサポートチケットを消費して、サポートデスクへ連絡したとする。サポートデスクの人間は、ユーザーの設定、登録日等の特定のデータにはアクセスすることができるが、個人的なプライベートメッセージを閲覧することはできない。
認証メカニズムのおかげで、データベースシステム内で異なるアカウントが提供されるため、各データベースユーザーがアクセスできるものをフィルタリングすることができる。これにより、任意のセキュリティルールを適用することができる。サポートチケットのケースでは、サポートのみに関する限られた量のデータにのみアクセス可能なデータベースユーザ「support_tickets」を設定することができる。つまり、サポート管理のダッシュボードを扱う開発者は、「support_tickets」 ユーザを通してのみバックエンドコードに接続することになる。
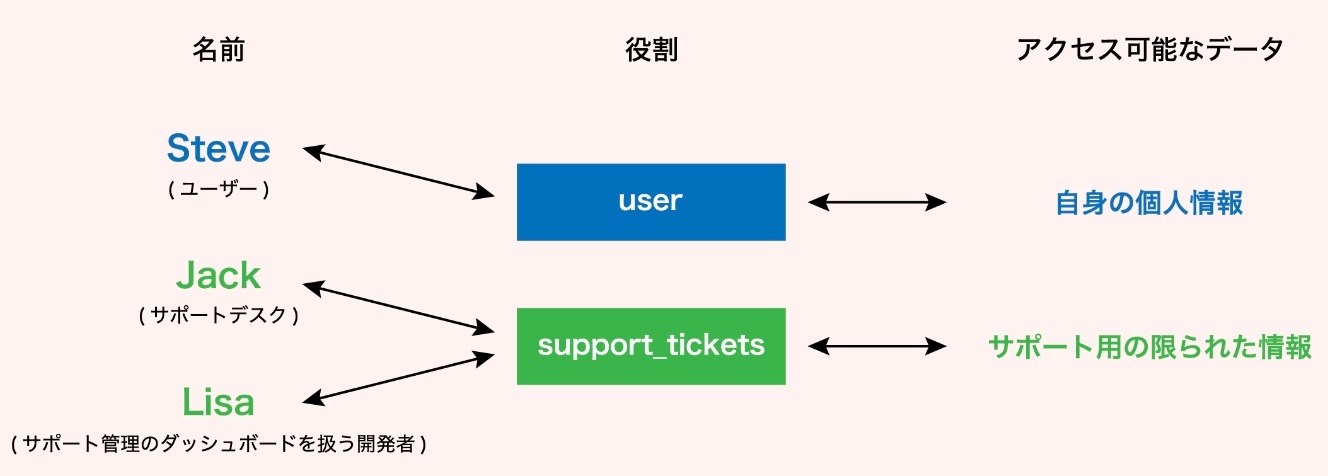
※https://recursionist.io/dashboard/course/6/lesson/672 より画像引用
全てのデータベースは、パスワードで安全に管理されており、承認されたハッシュキーを使ったアクセスなど、追加のセキュリティレイヤーも用意されている。他にも、読み取り専用オプションや、特定のデータベースユーザーに対する書き込み制限など、多くのセキュリティルールを細かく設定することができる。
DBMSがアクセスするストレージ
多くの場合、データベース管理システム(DBMS)がアクセスするデータは、そのDBMSが動作しているサーバー自身に内蔵されているストレージ(HDDやSSD)、またはそのサーバーに直接・間接的に接続された専用のストレージシステムに保存されている。
ただし、システムの規模や構成によって、データの保存場所はいくつかのパターンがある。
サーバー内蔵ストレージ
最もシンプルで一般的な構成。
特に小〜中規模のシステムでよく見られる。
DBMSソフトウェアがインストールされているサーバーマシンの中に、物理的にHDDやSSDが搭載されており、そこにデータベースファイルが保存される。まさに「サーバー内のストレージ」。
直接接続ストレージ (DAS: Direct Attached Storage)
サーバーにケーブル(SAS、SCSI、USBなど)で直接接続された外付けのストレージ装置にデータを保存する構成。
サーバーから見ると内蔵ストレージとほぼ同様に扱えるが、物理的にはサーバー筐体の外にある場合もある。これも広義には「サーバーに紐づいたストレージ」と言える。
ネットワーク接続ストレージ (NAS/SAN)
大規模なシステムや、高い可用性・拡張性が求められる場合に利用される。
NAS(Network Attached Storage)
ファイル共有のプロトコル(NFS, SMB/CIFSなど)を使ってネットワーク経由でアクセスするストレージ。
SAN(Storage Area Network)
ブロックレベルでアクセスするための専用ネットワーク(通常ファイバーチャネルやiSCSI)でサーバーと接続される高性能なストレージ。
これらは物理的にはデータベースサーバーとは別の独立した装置だが、ネットワークを通じてサーバーからアクセスされ、データが保存される。
クラウドデータベース
AWS RDS, Google Cloud SQL, Azure SQL Databaseなどのクラウドサービスを利用する場合、DBMSの実行環境(仮想サーバー/インスタンス)とデータのストレージは、クラウドプロバイダーのデータセンター内で管理される。
物理的な配置はユーザーから見えないが、通常、DBMSインスタンスとは分離された、高可用性・高耐久性を持つ専用のストレージサービス上にデータが保存され、内部の高速ネットワークで接続されている。
SQL Server Architecture
※https://www.tpointtech.com/sql-server-tutorial より画像引用
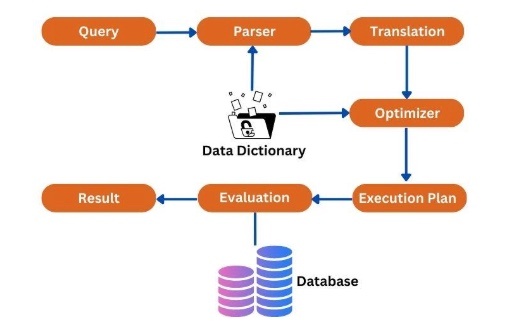
クエリが実行されるプロセス
主にリレーショナルデータベース(例:MySQLやPostgreSQL)でのSQLクエリ(たとえばSELECT文)の実行プロセスをベースにまとめる。
[クエリ入力]
↓
[構文解析]──→(文法ミスがあればエラー)
↓
[意味解析]
↓
[オプティマイザ]
↓
[実行プラン]
↓
[実行エンジン]
↓
[結果返却]
クエリ実行の全体の流れ
① クエリの送信(クライアント → サーバへSQLクエリ送信)
クライアント(アプリケーションなど)がSQLクエリをデータベースに送信する。
② パーサー(構文解析)
・クエリの文法チェック
・トークン分割、構文ツリー作成
(例)クエリを「SELECT部分」「FROM部分」「WHERE条件」などに分解し、「文法に誤りがないか」確認する。
③ 意味解析・バインディング
・テーブルやカラムが実際に存在するかを確認
・カラムの型や制約もチェック
(例)
・usersというテーブルがあるか?
・ageというカラムは存在するか?
・age > 30という条件は論理的に正しいか?
④ オプティマイザ(最適化)(Optimizer)
「一番速い方法」でデータを取得する実行計画を立てる
処理内容
・テーブル結合の順序やインデックスの利用を判断
・統計情報(各テーブルの行数・値のばらつき)などを使う
(例)
・インデックスがあればそれを使う
・フルスキャン(全件読み込み)を避けるよう工夫
⑤ 実行プラン作成(Execution Plan)
実際にどうやってデータを取得するか、処理の流れを決定する
例:(MySQLでのEXPLAIN)
| id | select_type | table | type | key | rows |
|---|---|---|---|---|---|
| 1 | SIMPLE | users | range | age_idx | 1000 |
これは、「age_idxというインデックスを使って、1000件の行を調べる計画です」と示している
⑥ 実行エンジンがプランに従って処理・クエリ実行(Execution)
・実行プランに従ってデータを読み込む
・条件に合う行を選ぶ
・結果を整形して返す(たとえば名前だけ取り出す)
⑦ 結果をクライアントに返す
クエリの実行速度は インデックスの有無 で大きく変わる
・インデックスがない場合:全ての行を1行ずつ確認する
→「フルスキャン(全件走査)」に相当する
・インデックスがある場合:インデックス(木構造)をたどることで、該当する行の位置を高速に特定
→ 「インデックススキャン」に相当し、該当のデータにすぐにアクセスできる。
※https://www.naukri.com/code360/library/query-processing-in-dbms より画像引用
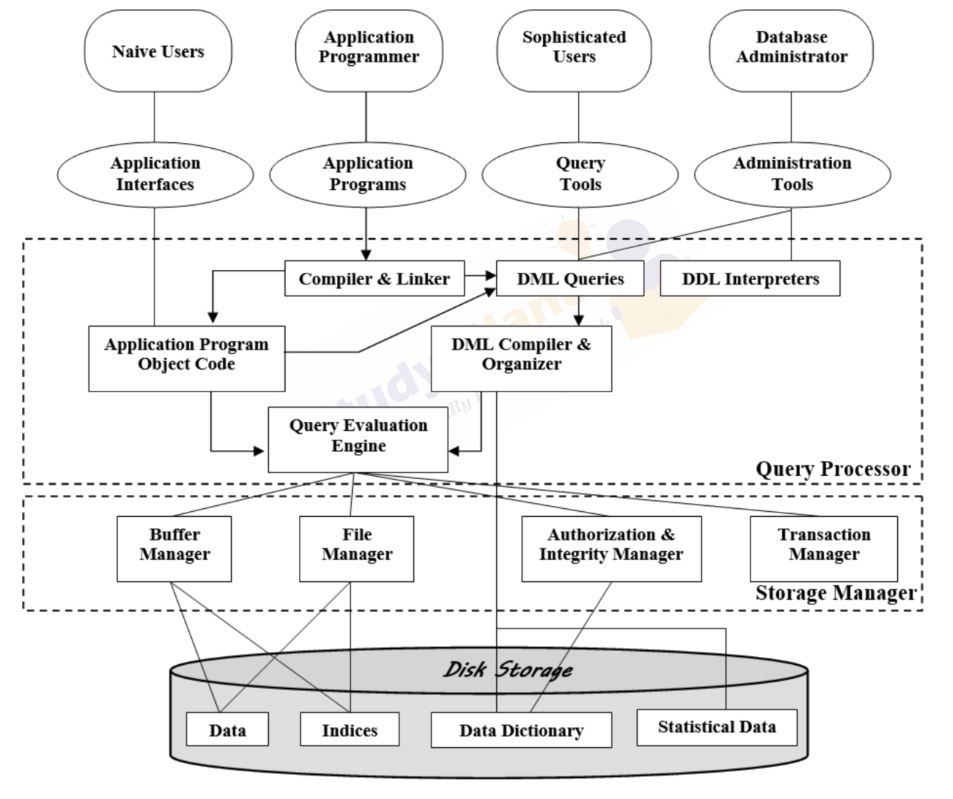
データベースの内部
他のシステムと同様に、データベースシステムも異なるモジュールとみなすこともできる。
※参考:https://www.naukri.com/code360/library/query-processing-in-dbms
※クエリプロセス:https://www.scaler.com/topics/dbms/query-processing-in-dbms/
リレーショナルエンジンの構成
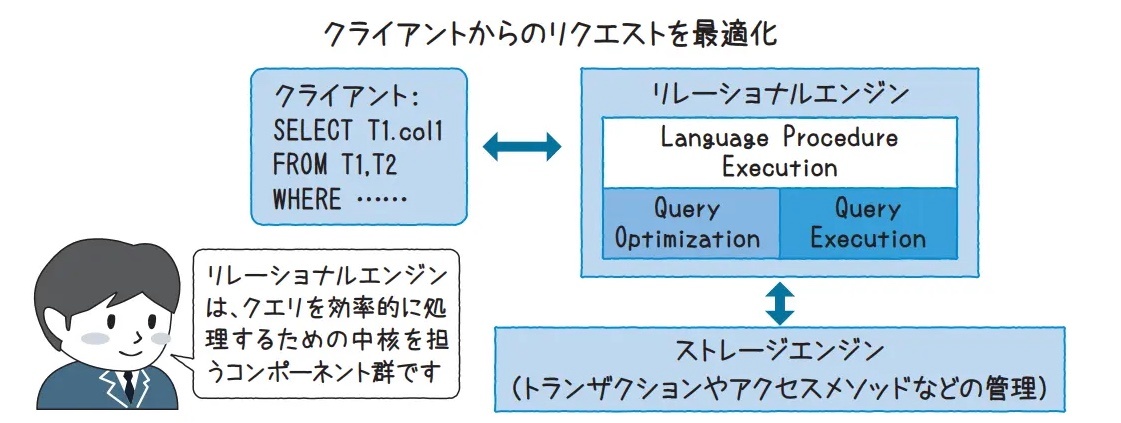
※https://enterprisezine.jp/article/detail/14146 より画像引用
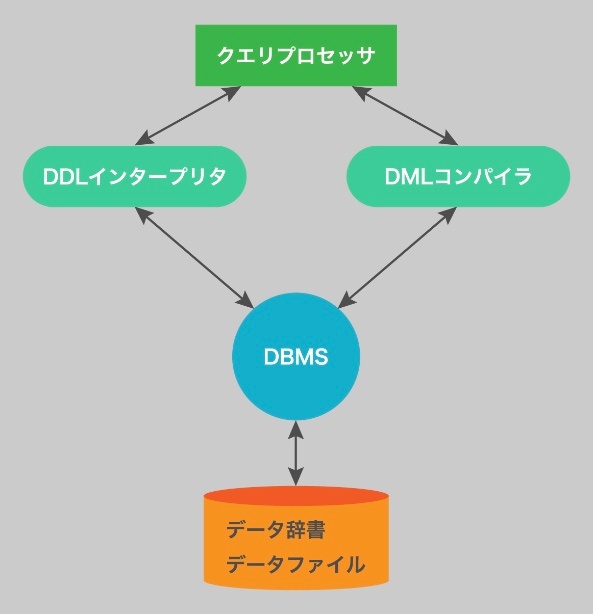
クエリプロセッサ(query processor)
クエリ評価エンジン
SQL文を受け取り、意味を解釈し、実行準備を行うモジュール
この中に、SQL文の種類(DDL / DML)ごとに担当する処理ユニットが存在する。
┌────────────────────────────┐
│ クエリプロセッサ Query Processor │
├────────────────────────────┤
│ ① パーサ(Parser) │ ← 全SQL共通:構文解析
│ ② 意味解析器(Semantic Analyzer) │ ← 全SQL共通:意味チェック
│ ③ DDLインタープリタ(DDL Interpreter) │ ← DDL文用:構造の即時変更
│ ④ DMLコンパイラ(DML Compiler) │ ← DML文用:実行プラン作成
│ ⑤ クエリオプティマイザ(Optimizer) │ ← DML文用:高速化
│ ⑥ 実行プラン生成器(Plan Generator) │ ← 実行エンジン用命令作成
└────────────────────────────┘
※https://www.researchgate.net/figure/Query-Processing-Architecture_fig4_267386340 より画像引用
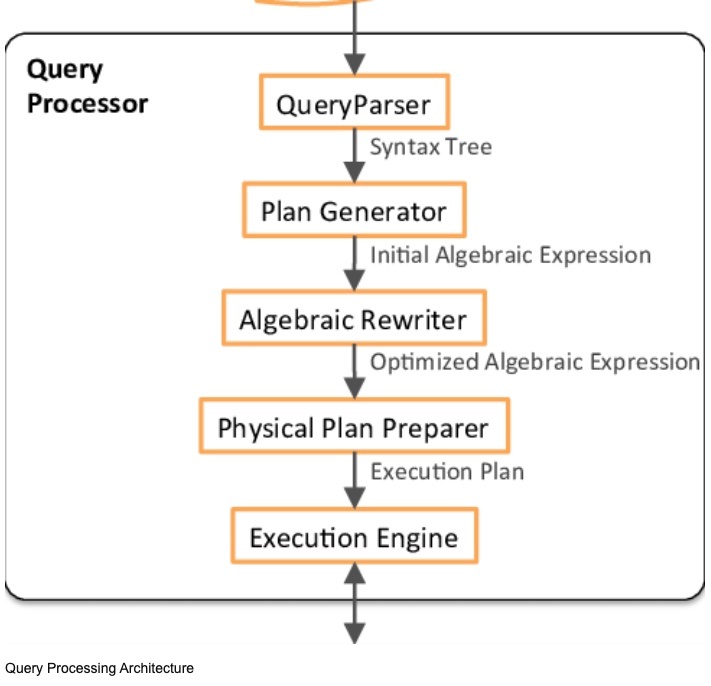
クエリプロセッサ(query processor)モジュールは、データベース言語を解釈し、低階層の命令にコンパイルする役割を担っている。データベース言語とは、データベースシステム内で使用可能な、データベースを操作するための言語を指す。ほとんどのリレーショナルデータベースでは、SQL 言語(structured query language)が採用されている。
クエリプロセッサはデータベースにおいて SQLクエリを受け取り、理解し、最適な方法で実行するための司令塔
= 「SQL文を解釈し、効率的に処理する手順を決めて実行エンジンに渡す」頭脳的存在
クエリプロセッサの役割・構成
クエリプロセッサは主に以下の4つの処理を行なう
① 構文解析(Parser)
クエリ文が文法的に正しいかチェック(例:カンマやWHEREの書き方など)
正しい場合、構文木(Parse Tree) を生成
② 意味解析(Semantic Analyzer)
存在しないテーブル名・カラム名が使われていないかチェック
データ型の整合性なども確認
③ 最適化(Optimizer)
どうすれば速くデータを取れるかを検討
→ インデックスは使えるか?
→ 結合の順序はどうすべきか?
実行計画(Execution Plan) を作成
④ 実行計画生成・命令送信
最適化された手順を「実行エンジン」に渡して、実行を開始させる
アプリケーション層
※https://qxf2.com/blog/mysql-architecture-and-layers/ より画像引用
ロジック層
※https://qxf2.com/blog/mysql-architecture-and-layers/ より画像引用
データベース言語
データベース言語は、データ定義言語 DDL(data-definition language)、データ操作言語 DML(data-manipulation language)の 2 つの独立したサブ言語から構成されている。
SQL のように 1 つの言語で DDL と DML の両方を扱う場合がほとんど。
DDL は、データベースのスキーマを定義する役割を担っている。
データベースのスキーマ(schema)とは、保存されているデータの集合体に紐付けられる全ての規則のことを指す。
スキーマには、格納するデータ型、使用する物理的データ構造(上級ユーザー向け)、データエントリの整合性と制約、および承認ルールの宣言が含まれる。
つまり、スキーマは
・どのようなデータをデータベースに入れることができるか
・どのようにデータベースに保存するか
・誰がデータベースにデータを保存したり読み出したりできるか
を決定する。
これらのルールや設定は全て、データベース自身だけがアクセスできるメタデータを持つデータ辞書(data dictionary)に含まれる。
SQL のような言語では、DDL コマンドには CREATE args コマンドと DELETE args コマンドがあり、テーブル、ユーザー、ビュー、インデックス、その他多くのアイテムを作成/削除することができる。
一方、DML を使うとデータベースのユーザーが保存されているデータを追加、アクセス、操作することができる。これは、データの読み取りにつながるクエリ、つまりトランザクションを通じて行われる。
・Create new data(新しいデータの作成)
・Read available data(利用可能なデータの読み取り)
・Update available data(利用可能なデータの更新)
・Delete available data(利用可能なデータの削除)
SQL のような言語では、INSERT(作成)、SELECT(読み込み)、UPDATE、DELETE の各コマンドが使われる。
データベースの設計をスキーマと呼ぶのに対し、ある特定の時点でのシステム内に存在する実際のデータをインスタンス(instance)という。
プログラミング、特に OOP の観点からは、スキーマは「クラスの設計図」、データベースのインスタンスは「ある時点で特定の状態にあるオブジェクト(クラスのインスタンス)」と考えることができる。
例えば、バックアップを作成する際には、その時点でのスキーマ(構造)とデータベースのインスタンスがエクスポートされる。
クエリプロセッサモジュールの中には、DDL 文を実行し、それに応じてデータ辞書を更新する DDL インタープリタ(DDL interpreter)と、クエリを最適化し、さらに低階層の命令に変換して、クエリ評価エンジンで処理する DML コンパイラ(DML compiler)がある。
※https://recursionist.io/dashboard/course/6/lesson/674 より画像引用
用語の整理
DDL
データベースの構造(テーブル・カラム・インデックスなど)を作ったり変更したり削除するための言語
・主なDDLコマンド
| コマンド | 説明 |
|---|---|
CREATE |
テーブルやデータベースなどを作成する |
ALTER |
既存のテーブルを変更(カラム追加・変更など) |
DROP |
テーブルやデータベースを削除する |
TRUNCATE |
テーブル内のデータを全削除(構造は残す) |
DML
テーブル内のデータ(中身)を操作するための言語(登録・更新・削除・取得)
・主なDMLコマンド
| コマンド | 説明 |
|---|---|
SELECT |
データの取得(読み取り) |
INSERT |
データの追加(登録) |
UPDATE |
データの更新(書き換え) |
DELETE |
データの削除 |
スキーマ
「データベースの設計図」や「構造の定義」 のこと
データベース内の構造やルール を定義する
・テーブルの名前
・各テーブルのカラム(列)名・データ型・制約(NOT NULL, UNIQUEなど)
・テーブル間の関係(外部キーなど)
・インデックスの定義
・ビュー(仮想テーブル)
・トリガー、ストアドプロシージャ、関数 など
※「スキーマ=データベース」とは限らない:多くのRDBMS(PostgreSQLやOracleなど)では、
1つのデータベース内に複数のスキーマを持てることがある。
データ辞書(data dictionary)
データベースに関する情報そのものを記録・管理するための辞書のようなもの(データについてのデータ)
= データベースの中にある、データベースについての情報(メタ情報)をまとめた表
= データベース内の「テーブル構造・カラム情報・制約・型」などを記録したメタデータの集まり
直接的なデータ検索には使用されない。
データベースシステム自身が、テーブルやカラムの存在確認、データ型のチェック、アクセス権限の検証など、データベースの運用管理に必要な情報を得るために参照する。
データベース管理者がデータベースの構造を理解したり、変更したりする際に役立つ。
ストレージマネージャーなどが、データベースの構造を把握し、整合性や権限のチェックを行なうために利用する。
※メタ情報とは「データを説明するための情報」のこと
たとえば「ユーザー情報を管理する users テーブル」があるとするが、データ辞書にはこんな情報が記録されている
| 項目 | 内容 |
|---|---|
| テーブル名 | users |
| カラム名 |
id, name, email, age など |
| データ型 | INT, VARCHAR, DATE など |
| 制約 | NOT NULL, UNIQUE, PRIMARY KEY など |
| デフォルト値 | 例: CURRENT_TIMESTAMP
|
| 所属スキーマ |
public など |
| インデックス情報 | どのカラムにインデックスがあるか |
・スキーマ:データベース構造そのもの
・データ辞書:DB構造に関する情報
DDLインタープリタ(DDL Interpreter)
CREATE や ALTER などの DDL文(データ定義言語)を解析して、データベースの構造情報(スキーマ)を更新するコンポーネント。構造(テーブル定義)を読み取って、メタ情報を更新する。
「このSQL文に書かれた新しいテーブルの設計図を、データベースに追加して反映しよう!」という処理を行うエンジン。
SQL文を解釈(=構文解析+意味解析)して、DBのスキーマ情報を反映させる
・SQLの構文を解析
・データ辞書(=メタデータ)を更新
→ テーブル名
→ カラム名・型
→ 制約(PRIMARY KEY、NOT NULLなど)
・テーブル構造の作成・変更・削除の実行
※DDLインタープリタもDMLコンパイラも、クエリプロセッサの中に含まれる
DMLコンパイラ(DML Compiler)
SELECT や INSERT, UPDATE, DELETE などの DML文(データ操作言語)を解析して、効率的に実行するための内部命令に変換するコンポーネント。データ操作文を読み取って、最適な実行方法を考える。
「このクエリ文をどうやって最速で実行できるか計画を立て、内部命令にして実行準備する頭脳」
=DML文を解釈して、効率的に実行するための内部命令(実行プラン)に変換することが主な役割
DMLコンパイラは「実行プラン」という中間命令列(内部表現)を生成し、それを DBの実行エンジンに渡して実行させる。
DML文 → DMLコンパイラ → 実行プラン → 実行エンジン → データ取得
※DDLインタープリタもDMLコンパイラも、クエリプロセッサの中に含まれる
・SQL文の構文解析
・テーブル構造・インデックスを参照
・実行プラン(クエリプラン)を生成
→ どの順番でデータを取り出すか?
→ インデックスを使うか?
→ 結合の順番は?
・実行エンジンに命令を送る
| 項目 | DDLインタープリタ | DMLコンパイラ |
|---|---|---|
| 対象 | DDL文(構造) | DML文(データ操作) |
| 処理内容 | テーブル定義を解析・反映 | クエリを解析し実行プランを生成 |
| 更新対象 | データ辞書(メタ情報) | 実行プランとデータ本体 |
| 実行例 |
CREATE TABLE, ALTER TABLE
|
SELECT, INSERT, UPDATE
|
データベースの内部
コンピュータに保存されているあらゆるファイル(バイナリファイルを含む)の管理は、オペレーティングシステム(OS)が行なっている。
「オペレーティングシステム階層でコンピュータに保存されている」というのは、OSが管理するファイルシステムという仕組みの中でファイルが保存されているという意味合い。アプリケーションは、OSが提供する機能(システムコール)を通じてファイルへのアクセスをOSに依頼し、OSが実際にストレージデバイスとのやり取りを行なう。アプリケーションが直接ハードウェアを制御してファイルを保存したり読み込んだりすることはない。
バイナリファイルもテキストファイルも、コンピュータに保存されているすべてのファイルは、OSの管理下にあるファイルシステムによって組織的に管理されている。
ストレージマネージャ(storage manager)
OSの内部的なストレージ管理機能全体を指す。
OSには、コンピュータに接続されたストレージデバイス(ハードディスク、SSD、USBドライブなど)を管理し、ファイルシステムを構成・維持する機能が組み込まれている。
具体的には、新しいストレージデバイスの認識、パーティションの作成・管理、ファイルシステムの作成・マウント、ディスク容量の監視、ディスクのエラーチェックなど、ストレージに関する様々なタスクを行なう。
GUI(グラフィカルユーザーインターフェース)を提供するOSの場合、これらの操作を行うためのツール(Windowsの「ディスクの管理」、macOSの「ディスクユーティリティ」など)が用意されており、これらを指して「ストレージマネージャー」と呼ぶこともある。
ストレージマネージャは、オペレーティングシステムの低階層 I/O API(Input/Output API)と通信することで、データをコンピュータ内のファイルとして保存する役割を果たす。ストレージマネージャは、データ辞書にアクセスしてデータベース管理者が微調整したデータベースの構造を把握し、整合性と権限のチェックを行なうことができる。
ストレージマネージャは、データに素早くアクセスできるルックアップテーブルのように、インデックスのセットを管理することができる。
インデックスは通常、平衡二分探索木として実装される。特に B 木や R 木は、ディスクメモリ効率が良いだけでなく、ルックアップが O(log n)と非常に高速で、O(n)の順序付き走査のような利点を備えている。
=ストレージマネージャーは、単にデータを保存する場所を提供するだけでなく、インデックスという仕組みを用いることで、アプリケーションやユーザーが求めるデータに迅速にアクセスできるよう、様々な最適化を行なっている。
ストレージに保存されたデータを論理的に管理する仕組みであるファイルシステムが、一般的に木構造(階層構造)を採用している。OSは、物理的なストレージを抽象化し、ファイルとディレクトリ(フォルダ)という概念でデータを管理する。このファイルとディレクトリの関係性が、木構造を形成する。
※インデックスは、ファイルシステム内の特定のファイルやデータの場所を高速に見つけるための索引であり、ファイルシステム全体の構造そのものではないことに注意
※https://studyglance.in/dbms/display.php?tno=5&topic=Structure-of-DBMS より画像引用
データを保存し、CRUD クエリを処理する場合、ストレージマネージャは多くのことを処理しなければなりません。これらの責任は、さらにマネージャ内の他のコンポーネントに委ねられる。
Authorization manager
ユーザーがデータにアクセスする権限を持っているかどうかを、データベースのデータ辞書を参照してチェックする。
Integrity manager
状態の変更がスキーマで指定された制約と参照の整合性に従うかどうかをチェックする。
File manager
ディスクストレージ内のデータの構造を決定し、ディスクストレージ内のデータの割り当てを行います。
Buffer manager
メインメモリに何をキャッシュするかを決定し、ディスクからメインメモリへのデータの取り込みを行なう。
Transaction manager
データベースのトランザクション内で必要な手続きを行なう。これには、同時実行時の一貫性の維持、ロールバックの仕組み、原子性のルールの適用等が含まれる。リレーショナルデータベースでは、ACID (原子性、一貫性、独立性、永続性) ルールが適用される。
データの抽象化
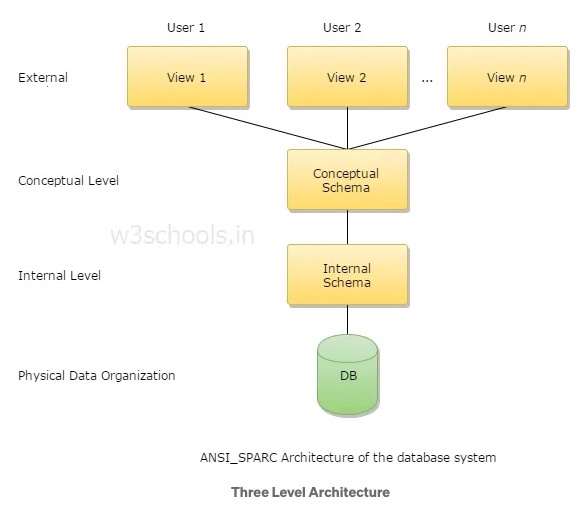
※https://medium.com/nixis-institute/three-level-architecture-of-database-92ce5a7977a7 より画像引用
データベースシステム内では、データは 3 つの異なる階層で抽象化される。抽象化によって、各階層がそれぞれ独立して存在することができる。つまり、物理層内部の複雑度を理解しなくても、論理層で作業を実行することができる。ほとんどの場合、私たちは論理層で作業を行なう。
外部層(view level)
データベースの一部分のみを表す。
外部層はデータベース管理者が設定するもので、セキュリティ上の目的や複雑度を軽減するためのもの。アプリケーションの一部や開発者は、大規模なアプリケーションのデータベース設計全体のうち、ごく一部だけを知っていれば問題ない。
論理層(logical level)
スキーマ設計のように、データベースが高階層でどのように構成されているかを表す。
データの意味や関係性、そして制約といった、データベースの抽象的な構造を定義する段階。
データベース設計者は、この論理層の設計を行なう際には以下の質問を自問自答し、明確に定義していく必要がある。
これらの質問は設計の指針であり、それに基づいて定義されたスキーマが、その後のデータベース運用における整合性チェックなどの基礎となる。
テーブル(データ集)にはどのようなデータ型を束ねるべきか?
テーブル定義: 各テーブルに含めるカラム(属性)とそのデータ型を決定する。
(例)「顧客テーブルには、顧客ID(整数型)、氏名(文字列型)、住所(文字列型)などのカラムを持つ」)
制約や整合性のルールは何か?
制約と整合性ルール定義: データの入力や更新に関するルールを定義する。
(例)「顧客IDは主キーであり、NULL値は許容しない」「年齢は0以上の整数でなければならない」
他のテーブルのキーなど、参照すべきものはあるか(外部キー等)?
参照整合性制約定義: テーブル間の関連を定義し、データの矛盾を防ぐためのルール(外部キー制約など)を設定する。
(例)「注文テーブルの顧客IDは、顧客テーブルの顧客IDを参照する」
データベース全体のデータ関係はどうなっているか?
データ関係の定義: ER図(Entity-Relationship Diagram)などを用いて、データベース全体のテーブル間の関係性を視覚的に表現する。
(例)「一人の顧客は複数の注文を持つことができる(1対多の関係)」
論理層の設計における主要な焦点は、
「何をどのような意味を持つデータとして管理したいのか」
「データ間にどのような関係を持たせたいのか」
「どのようなルールでデータを管理したいのか」
という、データの抽象的な表現と構造にある。
物理層(physical level)
データが物理的にどのように保存されるかを決定する。
物理層は、その論理構造を実際にどのようにストレージに格納するかという、具体的な実装方法を扱う段階。
データベース設計者は、この物理層の設計を行なう際には以下の質問を自問自答し、明確に定義していく必要がある。
データ型は何バイトか?
ストレージ効率やデータ処理効率に関わる物理的なサイズ
ファイル内の記号を解析する際、区切り文字は必要か?
データの物理的なフォーマットや解析方法
使用すべきデータ構造は何か?
B木、ハッシュテーブルなど、効率的なデータアクセスを実現するための物理的な構造
何をどのような方法でインデックス化するか?
検索効率を高めるための物理的なインデックスの実装方法
物理層の設計における主要な焦点は、その論理設計を「どのように効率的にコンピュータのストレージに実装するか」という、具体的な格納方法やアクセス方法に関わるもの
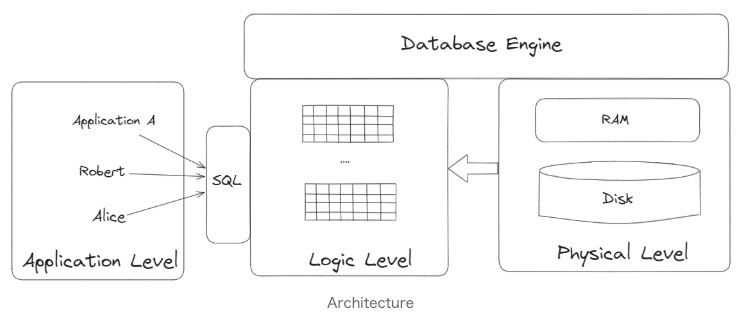
データベースシステムのコアアーキテクチャ
※https://www.linkedin.com/pulse/core-database-system-ke-an-nguyen-ldgme より画像引用
データベースアーキテクチャ
全体像
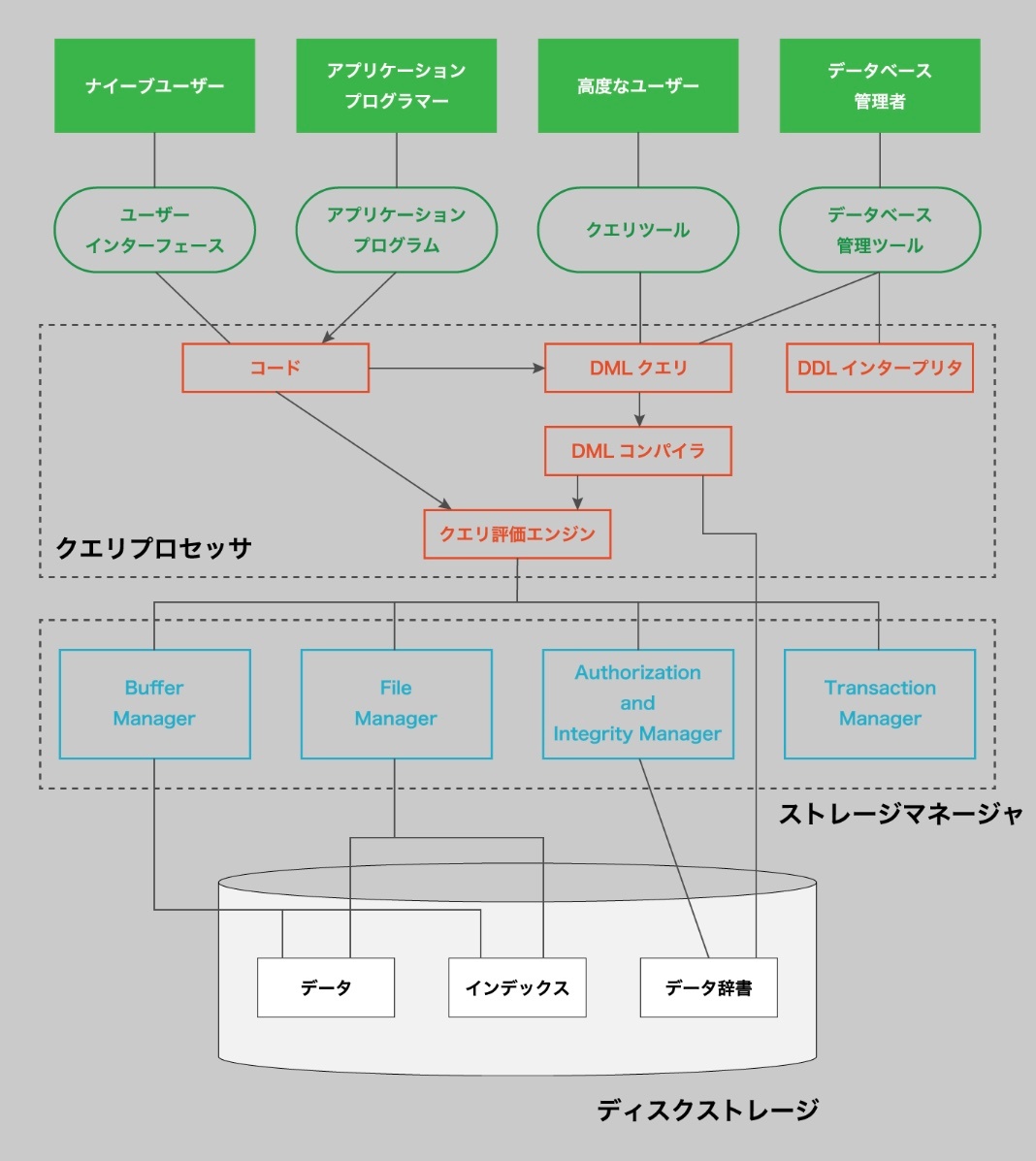
※https://recursionist.io/dashboard/course/6/lesson/677 より画像引用
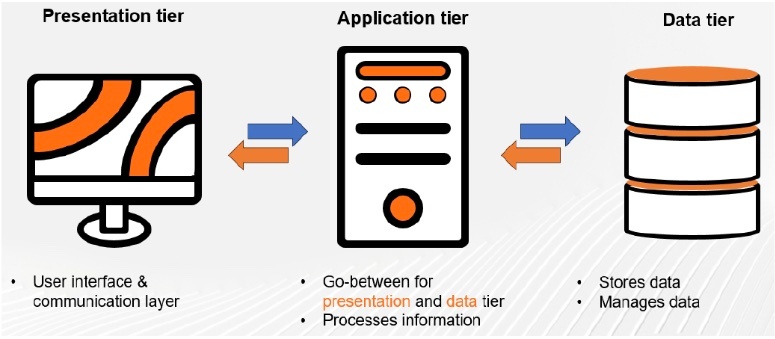
Web三層構造の全体像
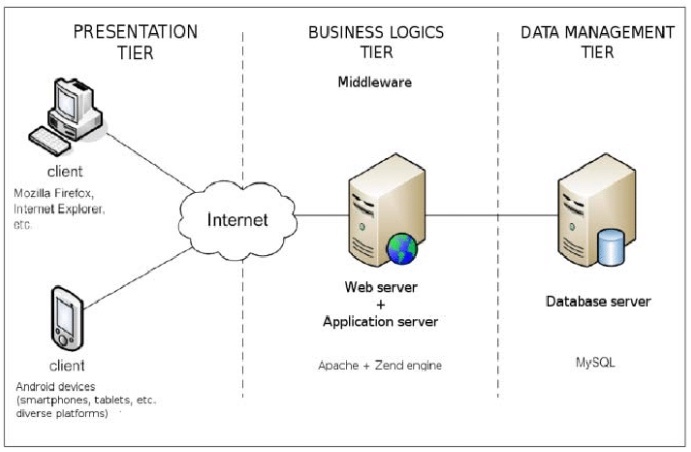
※https://www.researchgate.net/figure/tier-architecture_fig1_277187696 より画像引用
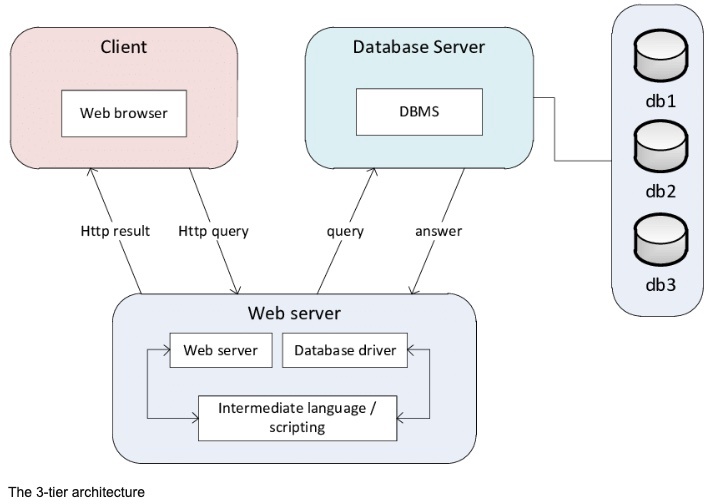
※https://www.researchgate.net/figure/The-3-tier-architecture_fig22_260389483 より画像引用
Web三層構造
① プレゼンテーション層 (Presentation Tier / UI層)
ユーザーが直接操作するインターフェースを提供し、ユーザーからの入力を受け付け、ビジネスロジック層から受け取った結果をユーザーに表示する役割。
ユーザーエクスペリエンス (UX) やユーザーインターフェース (UI) が重視され、ビジネスロジックの詳細は持たず、表示と入力の制御に特化している。
また、プラットフォーム(Web、モバイル、デスクトップなど)によって技術が異なる。
(例)Webブラウザで表示されるウェブページ (HTML, CSS, JavaScript)、スマートフォンアプリの画面、デスクトップアプリケーションのGUIなど。
② ビジネスロジック層 (Business Logic Tier / アプリケーション層)
アプリケーションの主要な機能や業務ルールを実装する。プレゼンテーション層からの要求に基づいて、データの検証、計算、ワークフローの制御、外部システムとの連携などを行なう。
アプリケーションの根幹となる処理を行なうため、堅牢性、信頼性、保守性が重要になる。
プレゼンテーション層やデータ層の技術に依存しないように設計されることが理想的。
様々なプログラミング言語やフレームワーク (Java/Spring, Python/Django, Ruby/Rails, Node.jsなど) で実装される。
(例)
・ECサイトでの商品の検索、カートへの追加、注文処理、在庫管理
・銀行システムでの口座残高の照会、振込処理
・SNSでの投稿、フォロー、メッセージ送信
③ データアクセス層 (Data Access Tier / データ層)
データの永続化と管理を行なう。ビジネスロジック層からの要求に基づき、データベースとの間でデータの読み書き(CRUD操作: Create, Read, Update, Delete)を行なう。
データの整合性、可用性、セキュリティが重要で、ビジネスロジック層がデータベースの種類や構造を意識せずにデータ操作を行なえるように、抽象化されたインターフェースを提供することが望ましい (ORM: Object-Relational Mapper など)。
(例)
・リレーショナルデータベース (MySQL, PostgreSQL, Oracle, SQL Serverなど)
・NoSQLデータベース (MongoDB, Cassandra, Redisなど)
・ファイルシステム
クライアントはアプリケーションサーバに接続し、アプリケーションサーバはユーザーのリクエストを処理し、必要に応じてデータベースシステムにアクセスしてデータを取得する。
クライアントとは、異なるプラットフォームに表示されるユーザーインターフェース(ユーザーが直接操作する画面やアプリケーション)のことを指す。これらのブラウザ、モバイルアプリ、デスクトップアプリのインターフェースは、HTTP リクエスト等の要求を行なうことで、アプリケーションサーバに接続する。
ナイーブユーザー(naive user)
ナイーブユーザーとは、(G)UIを使って間接的にデータベースシステムとやりとりをするソフトウェアのエンドユーザーのことを指す。これらのユーザーインターフェースは、ナイーブユーザーを常に意識しており、ドラッグ&ドロップ、フォーム、ボタン、音声コマンド等、非常に便利で使いやすいものとなっている。
ほとんどの場合、ユーザーインターフェースは、バックグラウンドで発生する詳細のほとんど全てを隠し、結果のみを表示する。つまり、ナイーブユーザーがアプリを開いたとき、どのようなデータを表示するかはすでに定義されており、アプリケーションサーバによって取得されている。
例えば、ナイーブユーザーが株式を購入したい場合、ボタンをいくつかクリックするだけで、トランザクションやクエリは全てアプリケーションサーバに書かれたコードによって処理される。
アプリケーションプログラマー(application programmer)
アプリケーションの開発者は、アプリケーションプログラマー(application programmer)と呼ばれる。データベースの開発者は、アプリケーションサーバにコード化されている全てのビジネスロジックの開発を行ない、要件とデータフローに基づいてプログラム内で DML クエリに変換するコードを記述する。
上記の例では、これらのプログラマーが、ナイーブユーザーがアプリケーションを開いた際に起こる事象、つまり、株式取引の手順や条件、アプリケーション内でのオプション等の詳細やビジネスロジックを決定する。
データベース管理者(database administrator)
データベーススキーマの設定や更新、物理的なストレージ構造の変更、インデックスの定義、データベースユーザーの権限管理、ビューの管理などを行なう。
これらの管理者は、バックアップの作成、健康状態のチェック、負荷の管理、古いストレージの交換など、日常的なメンテナンスも行なうので、多くのユースケースと高度な技術を持っている傾向にある。
データベース管理者は、dbeaver、HeidiSQL、MySQL Workbench などの専門的なデータベース管理ツールを使用してデータベースの管理を行なう。DDL を扱う唯一の人間であるため、小規模なチームや専門的なチームでは、アプリケーションプログラマーがスキーマや環境をセットアップするデータベース管理者を兼ねることになる。
データベース設計
ソフトウェアを作成する際、要求事項をよく吟味して、高い階層を持つデータモデルを作成することが推奨される。これは、機能要件と非機能要件を整理し、システムのデータ要件が適切に作成されることを意味します。つまり、どのようなデータが保存され、どのように処理されるのかを大まかに把握しておけば、ソフトウェアのニーズに合わせてデータベースを作り始めることができます。
※ソフトウェア開発におけるデータモデルで「高い階層を持つ」が意味するもの
「高い階層を持つデータモデル」とは、ソフトウェア開発の初期段階において、抽象度が高く、複雑な関連性を持ち、粒度の粗いレベルでビジネス上の要求事項を捉えたデータモデルを作成することを指し、これによって、より柔軟で保守性の高いソフトウェア開発を目指すことが推奨される。
① 抽象度の高さ
データモデルが、具体的な実装の詳細に依存せず、より概念的で抽象的なレベルで表現されていることを指す。
例えば、「顧客」というエンティティを、具体的なデータベースのテーブル構造やデータ型といった詳細ではなく、その属性(名前、住所、連絡先など)と他のエンティティとの関係性(注文を持つ、請求先を持つなど)といった、より上位の視点で捉えることを意味する。
高い階層のデータモデルは、ビジネス上の概念や要件を直接的に反映しやすく、開発初期の段階や、ビジネスサイドとのコミュニケーションに適している。
② 複雑な関連性
データモデル内のエンティティ(データのかたまり)間に、多岐にわたる複雑な関係性が存在することを指す。
例えば、顧客、注文、商品、配送、請求といった複数のエンティティが、一対多、多対多など、様々な種類の関連性を持つようなモデル。
高い階層のデータモデルは、現実世界の複雑な業務プロセスやデータ構造をより忠実に表現できる可能性がある。
③ 粒度の粗さ
データモデルの初期段階において、詳細な属性レベルではなく、より大きなまとまりのエンティティとしてデータを捉えていることを指す。
例えば、最初は「製品」という大きなエンティティとして捉え、後により詳細な属性(製品名、型番、価格、在庫数など)に分解していくようなアプローチ。
高い階層から始めることで、全体の構造を把握しやすく、段階的に詳細化していくことができる。
データベース設計者は、ソフトウェア設計チームや専門家と直接連携して、ソフトウェアの範囲を事前に十分に把握し、そのニーズに基づいてスキーマを設計する必要がある。しっかりとした基盤を持つことは重要だが、DBMS には DDL コマンドでスキーマを更新できる柔軟性があり、データを自由に操作することができるので、アジャイルチームには欠かせないものとなっている。
データベーススキーマを設計した後は、データモデルを選択することになる。データモデルは、どのような概念を適用すべきか、また要件をデータベースモデルに適合する設計にどのように変換するかを決定する。設計段階では、特定の低階層や物理層のプロパティではなく、まず論理層に焦点を当てることが重要。
データベースモデル(database model)
データベースに共通して適用されるデータモデルで、データの論理構造や、データの整理・保存・操作の方法を決定するもの。データベースモデルでは、保存されたデータについて特殊な方法で考える必要がある。
DBMSのデータモデル
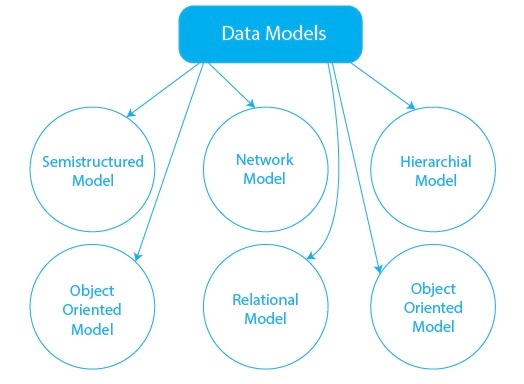
※https://www.prepbytes.com/blog/dbms/what-are-data-models-in-dbms-and-types/ より画像引用
データタイプ
※https://www.featureform.com/post/feature-engineering-guide より画像引用
関係モデル(relational model)
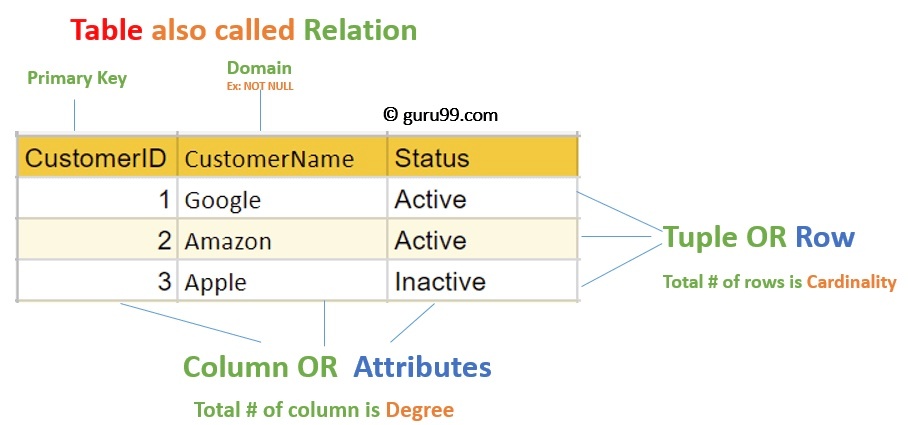
※https://www.guru99.com/relational-data-model-dbms.html より画像引用
データと関係をテーブルで表現する。テーブルはリレーションと呼ばれ、データエントリを表すタプルと呼ばれる行と、タプルの要素がどのようなデータタイプであるかを指定する属性と呼ばれる列を含んでいる。行のエントリ形式は、テーブル内では常に固定されている。
リレーショナルデータベース(relational database)

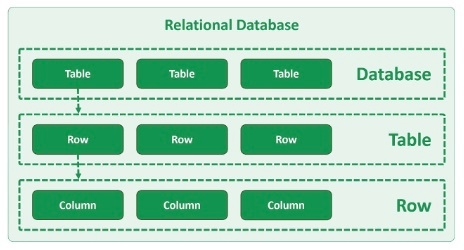
※https://www.pragimtech.com/blog/mongodb-tutorial/relational-and-non-relational-databases/ より画像引用
関係モデルを用いてデータを構造化するデータベースに与えられる名称。
リレーショナルデータベースは、最も広く使用されている種類のデータベースで、構造と豊富な機能を備えており、ACID の特徴を保証していることが最大の売りとなっている。
実体関連データモデル(entity-relationship data model)
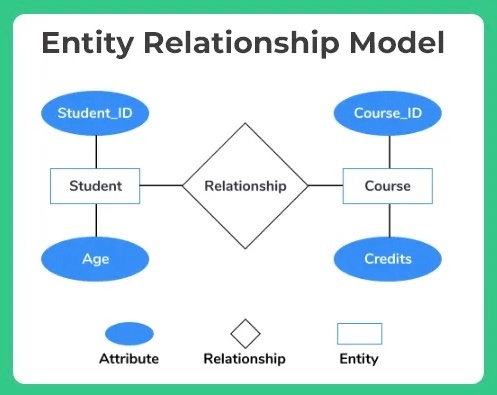
※https://prepinsta.com/dbms/entity-relationship-model-er-model/ より画像引用
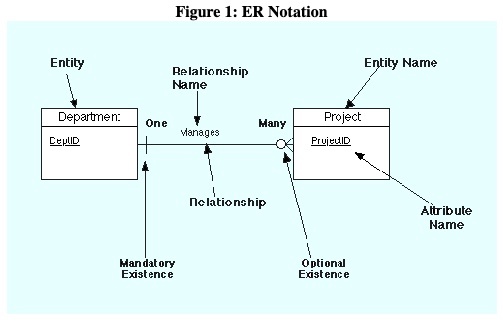
※https://www.jalowiec.org/phillip/cgc/cis154/datamodeling/dm/erintro.html より画像引用
エンティティと呼ばれる基本的なオブジェクトの集合体を使用し、エンティティ間の関係を記述する。
ER 図は、現実世界やビジネスの観点からデータを見てオブジェクトを互いに区別し、関係を指定するために使用される。ER 図を使うと、データベースの設計がしやすくなったり、設計をスキーマへ変換やすくなる。
主にデータベースの設計初期段階で用いられ、システムが扱うべき「実体(エンティティ)」と、それらの間の「関連(リレーションシップ)」、そして実体が持つ「属性(アトリビュート)」を明確に図示することで、データの構造を分かりやすく表現する。
半構造化データモデル(semi-structured data model)
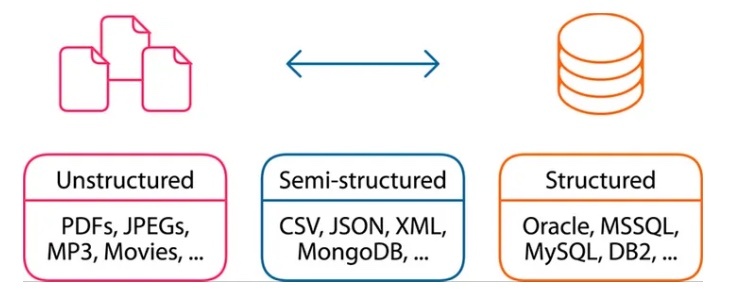
同じデータ型のエントリが異なる属性のセットを持つことができるデータモデルのことを指す。
これは、スキーマで指定された固定のカラム(属性)を強制する関係モデルとは異なる。
データはさまざまな方法で表現できるが、XML と JSON による表現が最も一般的。
半構造化データモデルを採用したデータベースでは、key value ペアが重要な役割を果たす。
リレーショナルデータベースではないデータベースは半構造化データモデルに該当し、NoSQL データベースと呼ばれることもある。これらのデータベースは構造を持たないため、ACID の特徴は保証されません。
リレーショナルデータベースと NoSQL データベースの読み取り速度は同じだが、NoSQL データベースの方が書き込み効率が高いため、ACID の特徴を犠牲にしてでも、拡張性の高いソフトウェアに頻繁に使用される傾向にある。
このようなデータベースシステムには、redis、mongodb、cassandra などがあります。
ドキュメント指向データベース
ドキュメント指向データベースでは、JSONやXMLのような柔軟な形式でデータを格納する
// ドキュメント1 (顧客情報)
{
"type": "customer",
"name": "山田太郎",
"age": 30,
"email": "taro.yamada@example.com"
}
// ドキュメント2 (商品情報)
{
"type": "product",
"name": "高機能マウス",
"price": 5000,
"color": "black"
}
// ドキュメント3 (注文情報)
{
"type": "order",
"order_id": "ORDER001",
"customer_id": 123,
"order_date": "2025-05-03",
"items": [
{"product_id": "P001", "quantity": 2},
{"product_id": "P002", "quantity": 1}
]
}
すべてのエントリ(ドキュメント)は、データ構造としてはJSONという同じ「データ型」で表現されているが、それぞれのドキュメントが持つ属性(キーと値のペア)は大きく異なる。
これが「同じJSONというデータ型でありながら、格納するデータの種類に応じて異なる属性のセットを持つ」ということ。
※リレーショナルデータベースとの違い
リレーショナルデータベースの場合、テーブルのスキーマを事前に定義するため、同じテーブル内のすべての行は原則として同じ属性(カラム)のセットを持つ。もし異なる属性を持たせたい場合は、NULL値を許容したり、別のテーブルを作成して関連付けたりする必要がある。
オブジェクトモデル(object model)
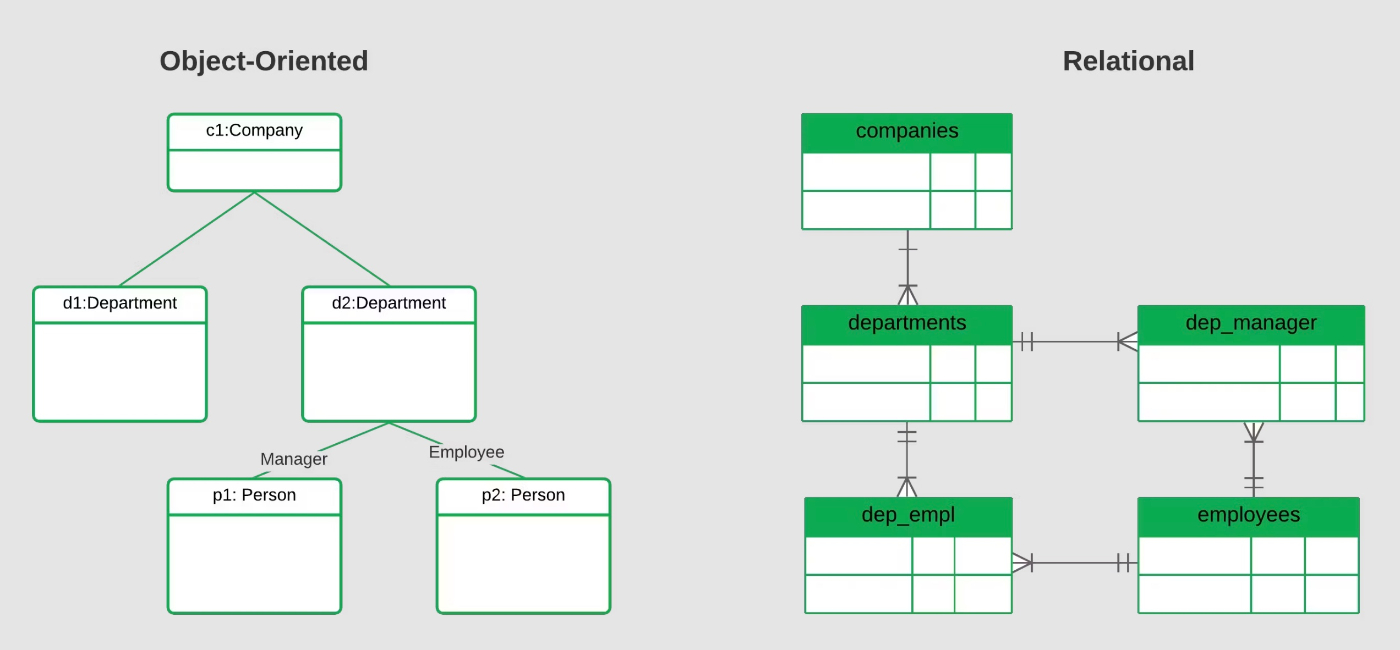
※https://www.sprinkledata.com/blogs/10-best-data-modelling-techniques より画像引用
オブジェクト指向プログラミングにおいて、データをオブジェクトになぞらえてモデル化したデータモデルのことを指す。要するに、スキーマがクラスの設計図に近い役割を果たし、データエントリはある時点でのオブジェクトの状態であることを意味する。データエントリを読み込んでプログラミング言語にロードすることで、オブジェクトを再作成することができる。
オブジェクトモデルのデータには、リレーショナルデータベースが最も一般的に使用されるが、オブジェクトモデルのニーズを満たす特定のデータベースもある。
また、ORM(Object Relational Mapping)のように、データベースのエントリをマッピングし、実行時のオブジェクトに変換するツールもある。
ORM(Object Relational Mapping)
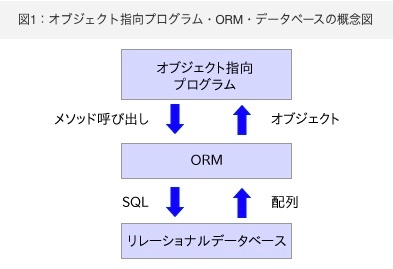
※https://codezine.jp/article/detail/5858 より画像引用
オブジェクト指向の概念とリレーショナルデータベースの概念を橋渡しする役割がORMです。オブジェクト指向とリレーショナルデータベースの相性はそれぞれの概念が異なるため、相性が良くありません。なぜなら、オブジェクト指向では、データをオブジェクトとして扱うのですが、リレーショナルデータベースではデータを2次元の表として扱うためギャップが生じてしまいます。ORMを利用することによって、オブジェクトとデータベース問い合わせの相互変換を行います。
関係モデル(relational model)
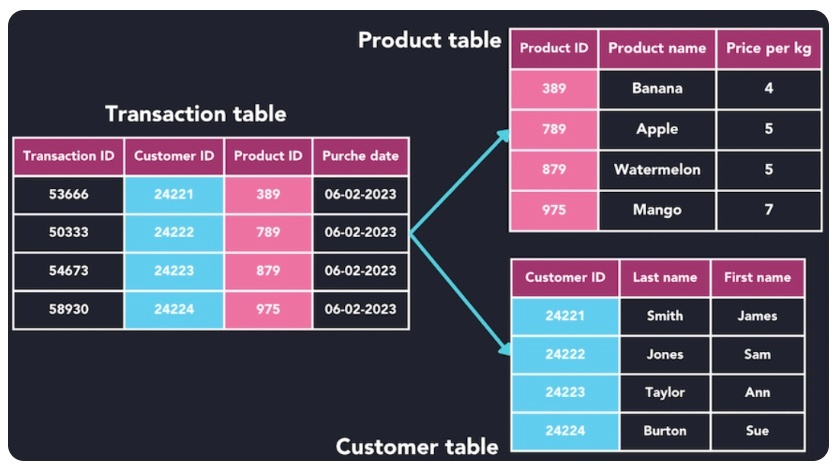
※https://airbyte.com/data-engineering-resources/hierarchical-vs-relational-database より画像引用
リレーショナルデータベース(relational database)は、商用ソフトウェアの中で最もよく使われるデータベースシステム。
リレーショナルデータベースには多くの機能や効率性が組み込まれているため、プログラマーやデータアナリストの間で長年にわたって人気を博している。
データベースが関係モデル(relational model)を採用している場合、システムの内部は、論理層や外部層のような高い階層とは完全に独立することになる。
なぜなら、関係モデルはデータインスタンスをモデルで定義された関数の入力/出力とする特性を持つからである。この特性によって、データベースシステムがブラックボックスを作ることができ、DBMS ユーザーは高い階層で作業を行なうことができる。これらのシステムは整理されたデータモデルに従っているので、ACID 特性も保証される。
上記をわかりやすくまとめると
関係モデル(Relational Model)の基本的な考え方
関係モデルは、データを「リレーション」(テーブル)という形式で表現する。
各テーブルは、行(レコード)と列(属性)を持ち、データ間の関連は主キーと外部キーによって表現される。
データ独立性(Data Independence)とは
データ独立性とは、上位の層(アプリケーションやユーザー)が、下位の層(データの物理的な格納方法や論理的な構造の詳細)の変更に影響を受けにくいという性質のこと。関係モデルは、このデータ独立性を高く実現するように設計されている。
関係モデルにおけるデータ独立性は、主に以下の2つの側面から成り立つ。
物理的データ独立性(Physical Data Independence)
データの物理的な格納方法(ファイルの構成、アクセス方法、記憶装置など)が変更されても、論理的なデータ構造(テーブル定義、データ型など)やアプリケーションの動作に影響を与えない性質。
例えば、データベースのパフォーマンス向上のために、データの格納形式を変更したり、新しいインデックスを追加したりしても、SQLクエリやアプリケーションのコードを変更する必要がない、ということ。
論理的データ独立性(Logical Data Independence)
データの論理的な構造(テーブルの追加や分割、属性の変更など)が変更されても、外部のアプリケーションプログラムに影響を与えない性質。
例えば、アプリケーションの新しい要件に対応するために、テーブルに新しいカラムを追加したり、複数のテーブルを結合して新しいビューを作成したりしても、既存のアプリケーションのSQLクエリやコードを大幅に変更する必要がない、ということ。
「データベースが関係モデル(relational model)を採用している場合、システムの内部は、論理層や外部層のような高い階層とは完全に独立することになる。」
この部分は、関係モデルがデータ独立性を備えているため、物理層(データの物理的な格納方法)が、論理層(テーブル定義などの論理的な構造)や 外部層(ユーザーやアプリケーションからのデータの見え方) から独立している、ということ。
「なぜなら、関係モデルはデータインスタンスをモデルで定義された関数の入力/出力とする特性を持つからである。」
・データインスタンス: テーブルに格納されている個々のデータ(行)
・モデルで定義された関数: 関係モデルにおける操作、つまり SQLクエリ を指している(SELECT、INSERT、UPDATE、DELETEなど)
つまり、関係モデルでは、アプリケーションやユーザーは、具体的なデータの格納方法や物理的な構造を意識する必要はなく、論理的に定義されたテーブルとSQLという「関数」 を通してデータにアクセスする。
SQLクエリは、論理的なテーブル構造に基づいてデータを操作するものであり、物理的な格納方法に依存しない。データベース管理システム(DBMS)が、そのSQLクエリを効率的な物理的な操作に変換して実行する。
同様に、論理層での変更(例えば、ビューの作成)は、物理層に直接的な影響を与えず、外部層(アプリケーション)は、そのビューを通してデータを操作するため、元のテーブル構造の変更を意識する必要がない場合がある。
関係
関係モデルの語源は、関係代数(relational algebra)という用語に由来している。
関係と呼ばれるデータの集合を定義し、関係を入出力とする関数を定義する数学理論のことを関係代数という。これらの関数を使うと、関係を入力として取り込み、述語と一定の操作を行なうことによって、関係を変換することができる。
リレーショナルデータベースは、関係モデルを用いてデータを論理的に整理しており、DML のクエリコマンドは関係代数で定義された関数から派生したものになります。
関係代数(relational algebra)とは、リレーショナルデータベースにおけるデータの操作方法を「数学的に定義」した理論体系。
=「SQLの元になっている、集合演算ベースのデータ操作ルール」
「関係と呼ばれるデータの集合を定義する」
関係代数における「関係」とは、テーブル(表)のこと。
このテーブルは、同じ種類のエンティティに関する属性(列)と、それらの属性に対する値の組(行、レコード)で構成される。
例えば、「顧客」という関係(テーブル)は、「顧客ID」「氏名」「住所」などの属性を持ち、それぞれの顧客の情報が1つの行として格納される。
「関係を入出力とする関数を定義する」
関係代数では、この「関係」(テーブル)を入力として受け取り、何らかの操作を施して、別の「関係」(テーブル)を出力する演算子(関数)を定義する。
これらの演算子は、データを操作するための基本的な「道具」となる。
「これらの関数を使うと、関係を入力として取り込み、述語と一定の操作を行なうことによって、関係を変換することができる」
ここが関係代数の核心部分で、定義された演算子を使って、既存の関係(テーブル)から、必要な情報だけを取り出したり、複数の関係を組み合わせたり、特定の条件を満たすデータだけを選び出したりすることができる。
述語 (Predicate)
これは、データを抽出する際の条件のこと。
例えば、「年齢が30歳より大きい顧客」という条件は述語となる。
関係代数には、以下のような基本的な演算子(関数)が定義されている。
・選択 (Selection)
ある関係から、指定された述語(条件)を満たす行だけを取り出して、新しい関係を作成する。
(例)「顧客」テーブルから「住所が東京」の行だけを選ぶ
・射影 (Projection)
ある関係から、指定された属性(列)だけを取り出して、新しい関係を作成する
(例)「顧客」テーブルから「氏名」と「電話番号」の列だけを取り出す
・直積 (Cartesian Product)
2つの関係のすべての可能な行の組み合わせからなる新しい関係を作成する。
・結合 (Join)
2つの関係の間に関連する行を組み合わせて、新しい関係を作成する(自然結合、内部結合、外部結合など、様々な種類がある)。
・除算 (Division)
ある関係に含まれるすべての値と関連を持つ別の関係の行を取り出す操作(やや複雑な演算子)
・和集合 (Union)
2つの関係のすべての行を重複を取り除いてまとめた新しい関係を作成する(両方の関係で属性の集合が同じである必要がある)。
・差集合 (Set Difference)
ある関係に含まれる行のうち、別の関係には含まれない行だけを取り出して、新しい関係を作成する(両方の関係で属性の集合が同じである必要がある)
・共通部分 (Intersection)
2つの関係の両方に含まれる行だけを取り出して、新しい関係を作成する(両方の関係で属性の集合が同じである必要がある)。
・関係の変換
これらの演算子を組み合わせることで、複雑なデータ操作や問い合わせを表現し、元の関係を必要な形に変換した新しい関係を得ることができる。

※https://www.upgrad.com/blog/tuple-in-dbms/ より画像引用
関係とは、同じサイズのタプルの集合であり、タプル内の各位置は属性によって定義される。関係は一般的にテーブル(table)とも呼ばれている。
タプル(tuple)とは、固定サイズのデータのリストを指す。
タプルは通常、n-タプルと呼ばれ、n はリストの長さを表す。つまり、タプルの固定サイズが 3 であれば 3 タプル、固定長が 8 であれば 8 タプルという。同じデータ型のエントリが要求される固定サイズの配列とは異なり、タプルの要素は必ずしも同じデータ型である必要はない。
関係には x 個のタプルが含まれており、データエントリやテーブルの行(row)と呼ばれる。
属性(attribute)とは、タプル内の位置を特定するもので、データ型や定義域などのプロパティを定義する。定義域(domain)とは、許容される値の集合を指し、例えば、unsigned intsの定義域は、全ての正の整数になる。属性はタプルのインデックスやテーブルの列(column)と呼ばれる。
※定義域:ある列(属性)が取りうる値の「型」や「範囲」のこと
n タプルの行を格納する関係は、n 個の属性を含み、関係は可能な限り多くのタプルエントリを持つことができる。関係はタプルの集合と定義されているため、関係内に同じ属性値のタプルを持つことができない。この点が、関係代数とリレーショナルデータベースの大きな違い
つまり、リレーショナルデータベースでは、開発者が実用上の理由からテーブル内の行を重複させることができる。
※関係代数の原則
・「関係」は集合(set)として定義される。
・集合は重複を許さない → 同じタプル(行)が2つ以上存在できない
関係スキーマ(relation schema):関係の設計と構造を定義する
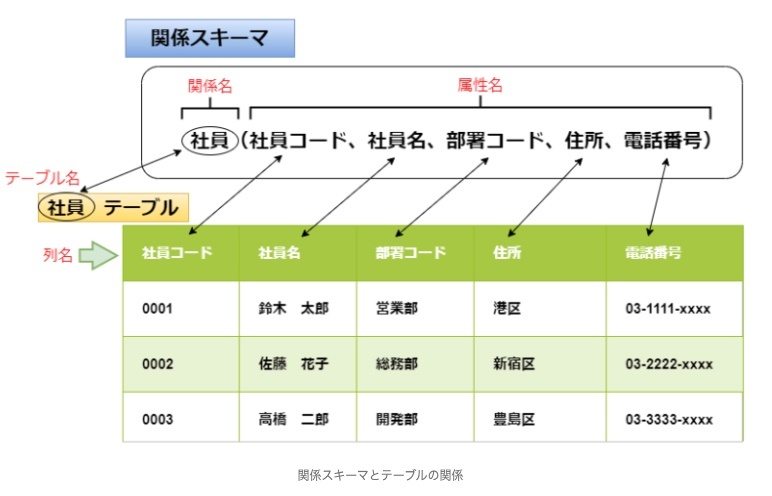
※https://itmanabi.com/relational-schema/ より画像引用
データベースにおける、ある関係を関係名とそれを構成する属性名を並べたもので構成するもの
関係名(属性1、属性2、属性3、・・・、属性名n)
関係インスタンス(relation instance):任意の時点での関係の全てのタプルのことを指す
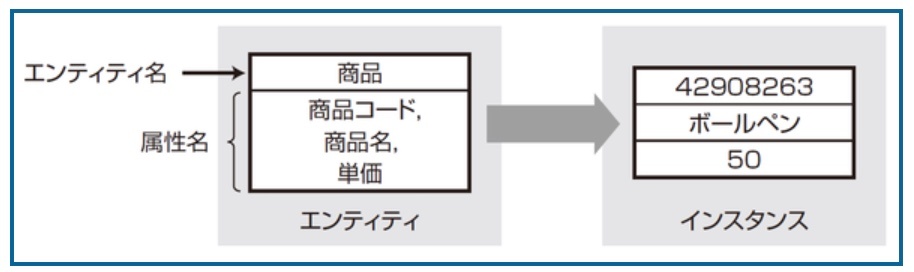
※https://atmarkit.itmedia.co.jp/ait/articles/1703/01/news178.html より画像引用
リレーショナルデータベースシステムでは、属性に対してデータ型の集合が提供され、これらの属性の定義域は、制約(constraint)と呼ばれるものによって、さらに絞ることができる。
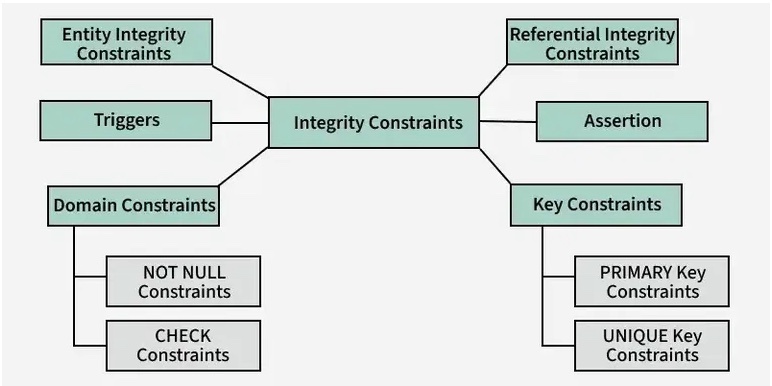
※https://www.geeksforgeeks.org/dbms-integrity-constraints/ より画像引用
関係 = 関係スキーマ + 関係インスタンス
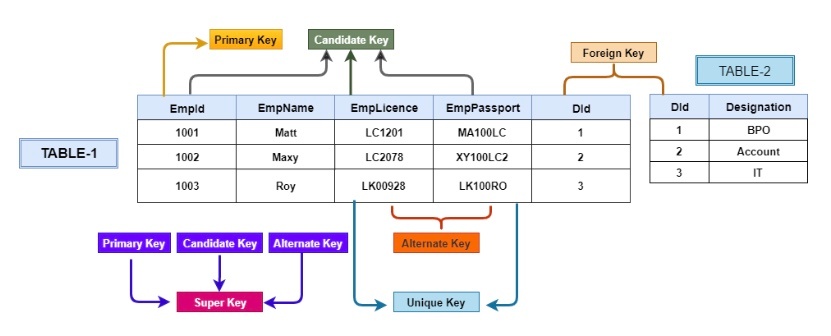
キー(key)
リレーショナルデータベースにおける 「キー」 というのは、簡単に言うと、「この行はどのデータなのか?」を特定するための“目印”や“ラベル”のこと。
テーブルは「たくさんの行(レコード)」が入っている表で、その中から「この人のデータを見たい」「この注文を更新したい」など、特定の1行を確実に見つけるためには、何か「ユニークな情報(目印)」が必要になる。
・スーパーキー:一意に見分けられる「目印」の組み合わせ(ちょっと大きめでもOK)
・候補キー:その中でも「ムダのない最小限の目印」
・主キー:候補キーの中から選ばれた“代表の目印”
関係内のタプルを一意に識別するために使用される、属性または属性の集合のことを指す。キーを使うことで、関係内のデータにアクセスしたり、他の関係のデータを参照することができる。キーはタプルを識別するための識別子であり、ルックアップテーブルで使用されるキーと同様に扱うことができます。
関係は結局のところテーブルであるため、キーに適切なインデックスが付けられ、関係が上手く設計されていれば、コンピュータはキーを使って O(log n)や O(1)の速度でデータを見つけることができる。
関係の数学的な定義: 関係 = タプルの集合
全く同じ属性値を持つタプルは存在しない。
これはタプルの全ての属性をスーパーキーとして使い、タプルを識別することができることを意味する。
スーパーキー(super key)
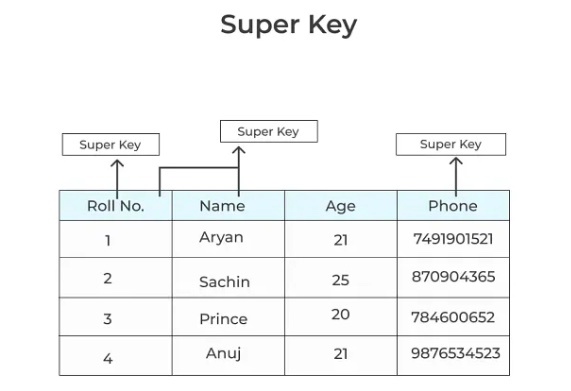
※https://medium.com/@udayangakasun696/key-types-of-dbms-5f695bb6f3f8 より画像引用
関係内でタプルを一意に識別することができる任意のキー。タプルの全ての属性は、タプルを識別することができるので、定義上はスーパーキーになる。
リレーショナルデータベースにおいて、ある表(テーブル)の中で行(レコード)を一意に識別できる属性(列)の組み合わせ
「行を一意に識別できる列(または列の組み合わせ)」
重複がなければ複数の組み合わせがスーパーキーになる可能性がある。
候補キー(candidate key)
※https://powerbidocs.com/2019/12/25/sql-keys/ より画像引用
属性が一つでも欠けると一意に識別できなくなる属性の集合
1 つの関係は複数の候補キーを持つことができる。
テーブルの中でレコード(行)を一意に識別できる最小限の列(属性)または列の組み合わせのこと
・一意性(ユニーク性)→ 他のレコードと重複しない値である必要がある
・最小性(ミニマリティ)→ 不要な列を含まない、最小限の組み合わせである必要がある
主キー(primary key)
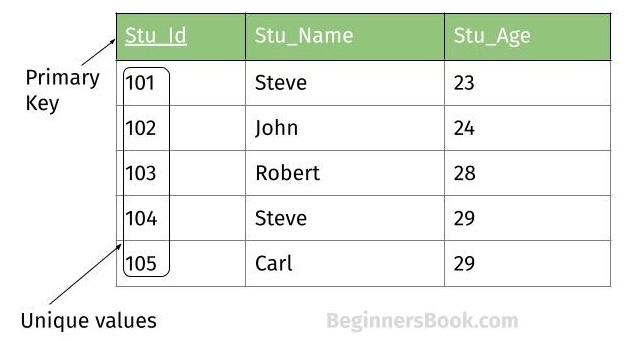
※https://beginnersbook.com/2015/04/primary-key-in-dbms/ より画像引用
タプルの識別に最も好ましいものとして、設計者や開発者にとって選択される候補キーのこと。
関係に存在する候補キーが 1 つしかない場合、その候補キーは主キーとなる。
前述の通り、キーはタプルを一意に識別するものでなければならない。
これは、2つのタプルが同一属性内で同じ値を持つことができないことを意味する。実際のリレーショナルデータベース内では、テーブルスキーマの定義で指定することで、同一の値が保存されないよう一意制約を強制する整合性のチェックが実装されることもある。
良い主キーは、値が変更されることがないと予想される属性であるべき
◎主キーは単一の属性である必要はない
=あるテーブルで、
「1つの列(属性)だけでは一意にデータを区別できないが、2つ以上の列を組み合わせれば区別できる」
という場合には、複数の列をあわせて「主キー」にできるということ
一意制約は、属性の集合に対して機能することに注意すること。
つまり、一意でなければならない単一の属性の場合もあれば、連結によって一意の値になる複数の属性もある。
候補キーに含まれない全ての属性は、非キー属性(non-key attribute)と呼ばれる。
非キー属性(non-key attribute)
テーブルの中で「キー(主キーや候補キーなど)」には使われない属性(列)のこと。
・行(レコード)を一意に識別するためには使われない列。
・ただし、その行に付随する情報(値)としては重要なデータ。
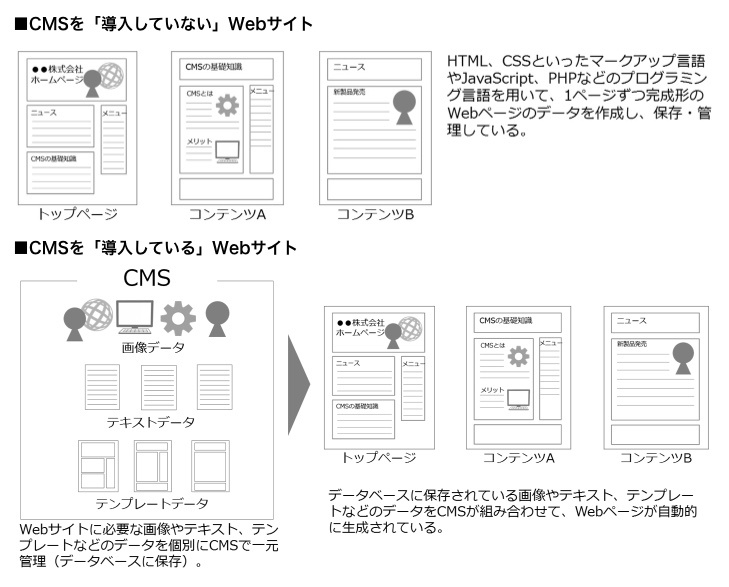
CMS(Content Management System、コンテンツ管理システム)
※https://www.hitachi-solutions.co.jp/digitalmarketing/sp/column/cms_vol01/ より画像引用
専門的なプログラミングの知識がなくても、Webサイトの「記事の作成・編集・管理」ができる仕組みのこと
通常、Webサイトを作るには HTML や CSS、サーバー操作が必要だが、CMSを使えば次のような流れになる。
① 管理画面にログイン
②「新規記事作成」ボタンを押す
③ タイトルと本文を入力
④「公開」ボタンを押す → すぐにWebサイトに反映する
Web CMS(WCM)
技術者ではないユーザーが Web サイトや Web ページを動的に作成し、コーディングなしで Web コンテンツを管理できるシステム(WordPress 等がこれに該当する)のこと。このシステムでは、テーマテンプレートとプラグインを使用して機能を拡張する。また、全てのウェブページのデータをデータベースを通じて保存、取得する。
参照(referencing)
メモリアドレスがメモリブロックに物理的に格納されている値への参照であるのと同様に、キー値は特定の関係からのタプルへの参照として使用することができる。
キー値(例:主キー)は、そのテーブル(関係)の中の特定の1行(タプル)を探し出す“参照先”になる」ということ。
※メモリアドレスとは、プログラムがメモリの中の値を読むときに「ここを見て!」と指定する“場所の目印”のこと。
外部キー(foreign key)
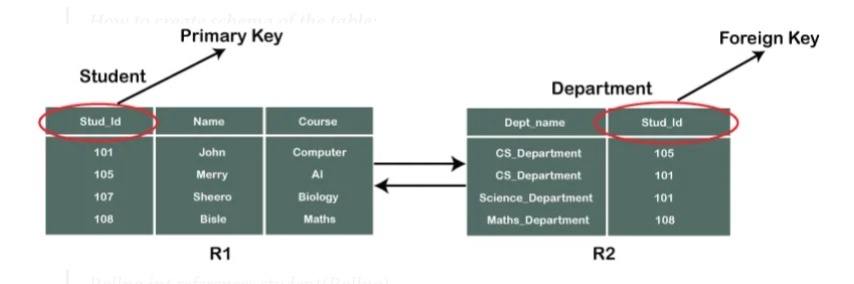
あるテーブルの列が、別のテーブルの主キー(または候補キー)を参照しているときの「参照元のキー」のこと
=外部キーとは、「他のテーブルの主キーを参照するための目印」
これは、テーブル同士の関連づけ(リレーション)を行ない、データの整合性(正しい関係を保つこと)を保つために必要とされる。
上記の図で、R2 は参照関係(referencing relation)、R1 は被参照関係(referenced relation)と呼ばれる。
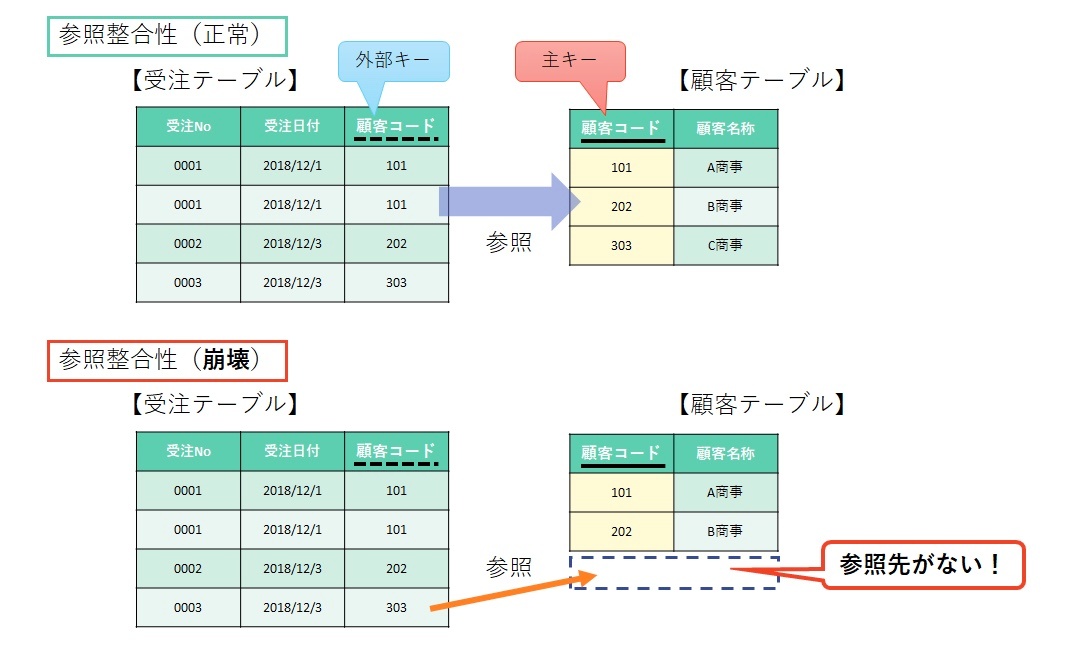
外部キー制約
※https://itmanabi.com/foreign-key-referential-integrity/ より画像引用
あるテーブル(R2)に外部キーとして指定された列(F)がある場合、
その列に入れられる値は、必ず他のテーブル(R1)の主キーに存在している値でなければならないというルール(=外部キー制約)
データベースシステムは、外部キーが正しいことを確認するために整合性チェックを行なう。外部キー制約が主キーに結びついている。
参照整合性制約(referential integrity constraint)
データの矛盾や孤立を防ぐことを目的とした、テーブル同士の関連づけが“正しく”保たれていることを保証するルールのこと。
定義された参照整合性をチェックし,整合性を逸脱するような値がテーブル内に存在しないようにする機能のこと。この機能を使用する場合は,テーブル定義の際にConstraint句を用いることが一般的。
タクソノミー(taxonomy)
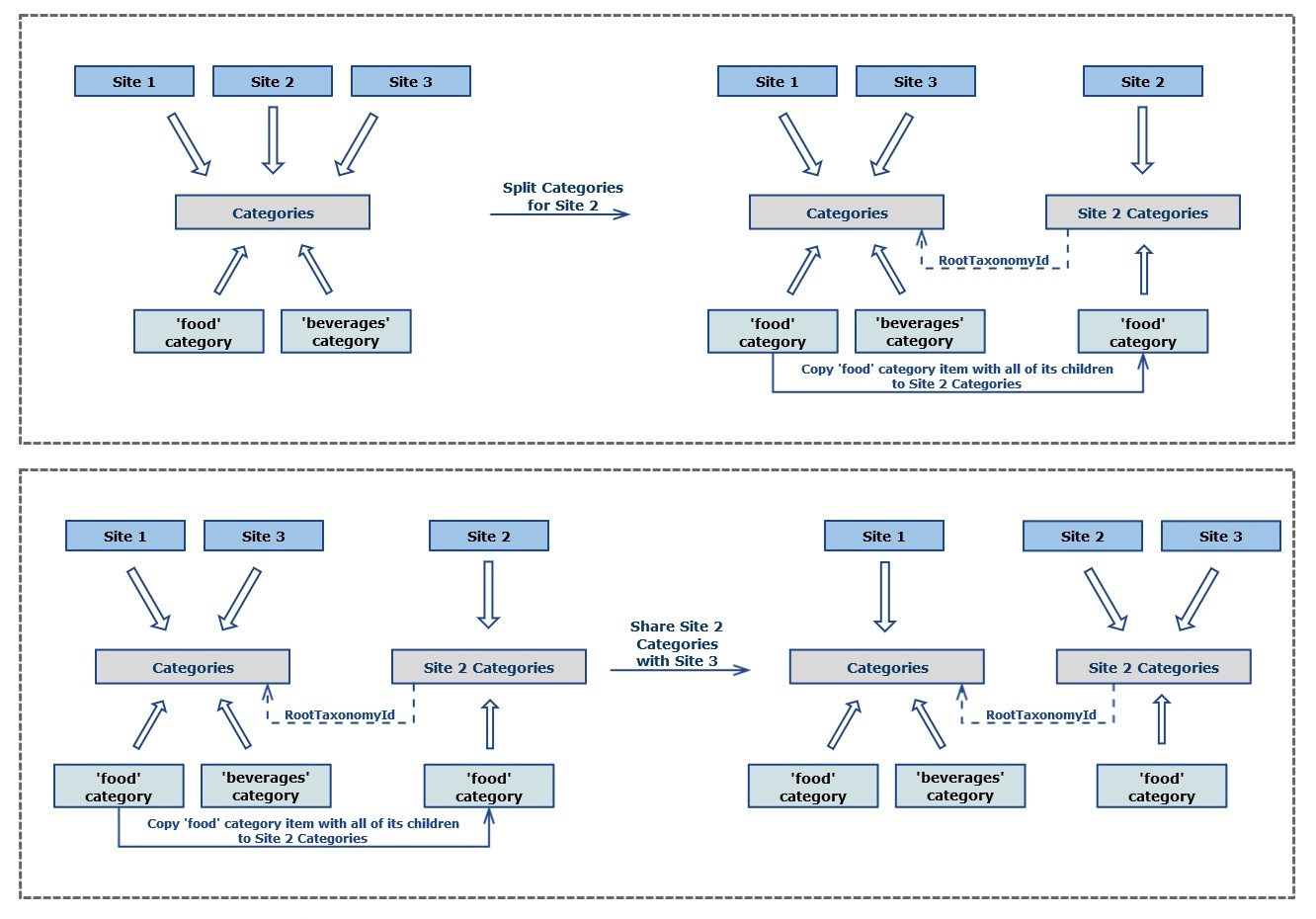
※https://www.progress.com/documentation/sitefinity-cms/for-developers-site-specific-taxonomies より画像引用
※https://www.immediait.com/en/why-do-we-need-taxonomy より画像引用
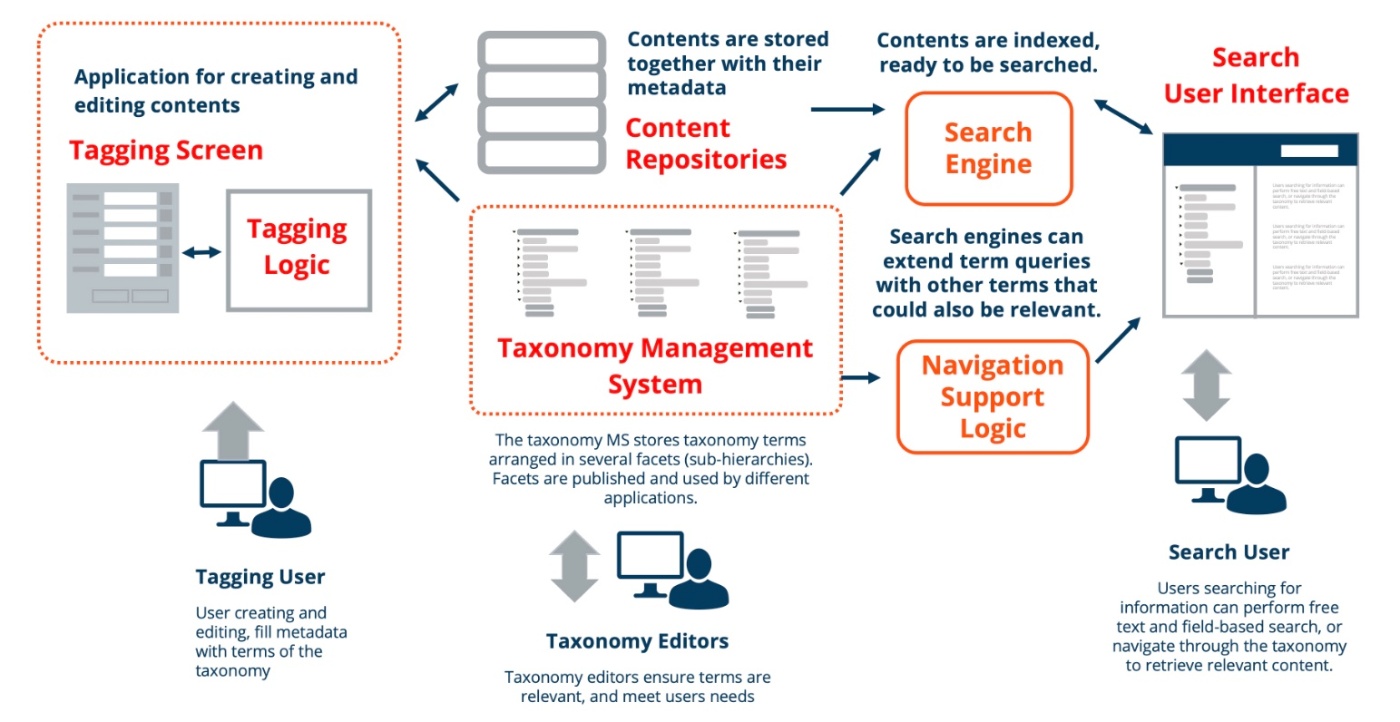
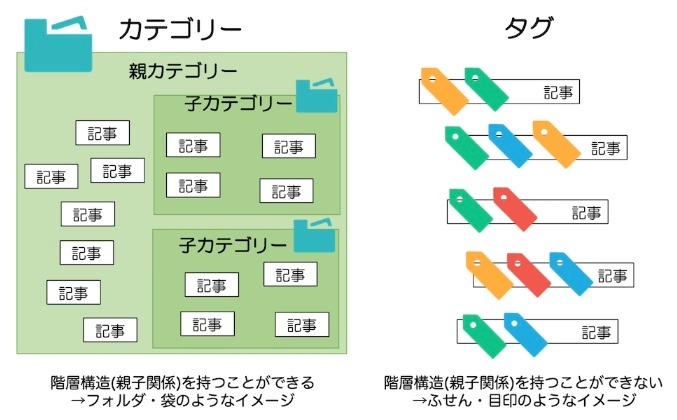
CMS では、ページが特定のカテゴリーに分類されていたり、複数のタグが含まれていたりすることがよくある。ここでは、カテゴリやタグなどをタクソノミー(taxonomy)という。
また、カテゴリーやタグを表す文字列を用語(term)と呼ぶ。
カテゴリーは階層化されており、サブカテゴリーが存在する場合もあるが、
タグは個々の単位であり、階層化されることはない。
※https://webst8.com/blog/wordpress-category-tag/ より画像引用
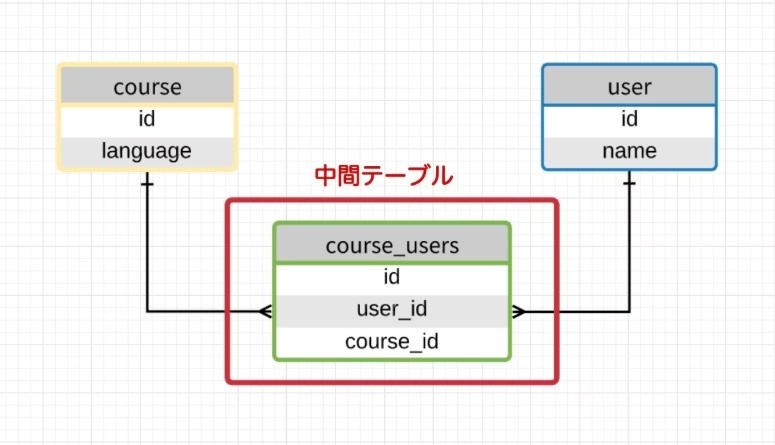
中間テーブル(intermediate table)
※https://qiita.com/ramuneru/items/db43589551dd0c00fef9 より画像引用
2 つのテーブルの間に存在する、それぞれに接続するテーブル
中間テーブルの主な目的は、関係の集合を参照するタプルを作成することによって特定の情報を取得することであり、関係どうしを紐付けることができる。
データベースで多対多(N対M)の関係を表現するために使われる補助的なテーブルのこと
「多対多」の関係は、そのままではデータベースに表現できないため、「AとBが多対多の関係にある」ときには、中間テーブルが必要になる。
主に「外部キー2つ + 必要に応じて追加情報」で構成される
演算子
select 演算子(σ、発音は「シグマ」)
select は、ある述語に基づいて関係のタプルをフィルタリングする演算子
ある条件を満たすタプル(行)だけを取り出す操作
σ_条件(関係)
・σ(シグマ):選択(select)の記号
・条件:取り出したいデータの条件(列に対する条件)
・関係:対象となる表(リレーション)
構文は σp(r) = y で、p は述語、r は入力関係、y は出力関係を表している。
r と y の両方は同じ属性とスキーマを持つ。
タプルの属性は、述語式の中でアクセスすることができ、ブール演算子(AND、OR、NOT)と比較演算子(=、<、<=、>、>=)を使って、より複雑な述語を組み立てることができる。
select 演算子は非常に強力で、あらゆるものにフィルターをかけることができ、データの検索や取得を目的としたクエリの定番となっている。述語式の一部として出力される関数に属性値を渡すこともできる。
project 演算子(Π、パイ)
関係 r を受け取り、r 内の属性 A の集合を使用して、r の全てのタプルのうち属性 A のみを含む新しい関係を生成する。project 演算子は不要な属性データを切り出すために使われる。
関係代数の演算子は関係を評価するので、評価された関係を使うことによって合成を作ることができる。
これは、数学やプログラミングで使われる関数の合成と全く同じように扱うことができる。
select 演算子は、入力された関係と全く同じ属性を持つ関係を評価するという定義。
これは、select 演算子の出力を project 演算子の入力として使うことができることを意味する。
つまり、入れ子になった演算子を使うことによって、処理を複雑にすることができる。
SQL
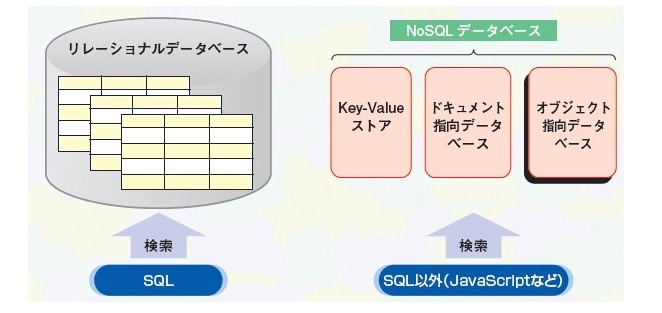
SQL とは、DBMS(データベース管理システム)上でデータやデータベースを制御するための言語であり、ユーザーやシステムからの命令を受けて DMBS にクエリ(問い合わせ)を行ない、結果を返す。
現在、世界に存在するデータベースは SQL を使用するものとしないものがある。
※https://xtech.nikkei.com/it/article/COLUMN/20120306/384810/ より画像引用
SQL を使用する DB を RDB(リレーショナルデータベース)と呼ぶ。
RDB とはデータベースの種類のことで、他にも NoSQL と呼ばれる SQL を使わないデータベースも存在する。
リレーショナルデータベースには、基本的原則としてACID特性というものがありますが、あまりにもデータ量やアクセス頻度が増大すると、性能低下の原因になることが分かってきました。データ量やアクセス頻度に増大に伴って、ACID特性を維持するためのコストが無視できなくなるためです。
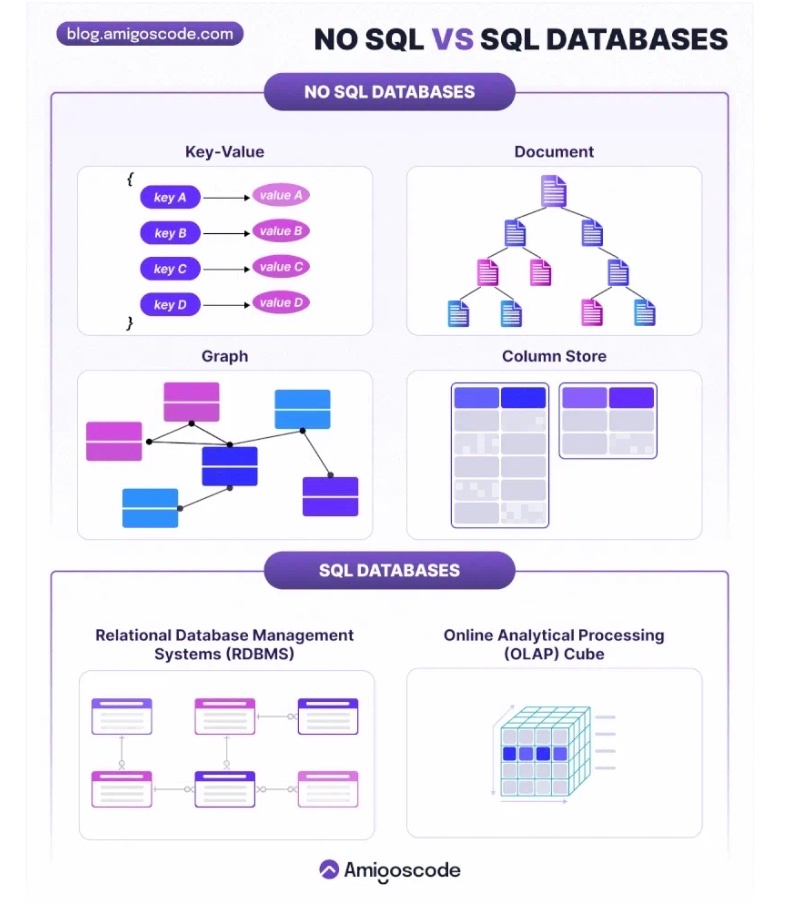
※https://blog.amigoscode.com/p/sql-vs-nosql-explained より画像引用
SQL は、大文字・小文字を区別しない。
SQLステートメントを大文字で記述するのが一般的。
SQLステートメントとは、これから学習していく CREATE hogehoge や SELECT fugafuga FROM piyopiyo などの SQL 文法のこと。また、SQL 文の終わりには必ず ;(セミコロン)を挿入しなければならない点に注意。
クエリとは DBMS に 送る命令のこと。これ自体を SQL と呼ぶこともあるが、SQL が概念的な単語であるのに比べて、クエリは実行される具体的な SQL や命令のことを指す。
SQL は、大きく 2 種類に分けることができる
・DDL(Data Definition Language | データ定義言語)
・DML(Data Manipulation Language | データ操作言語)
DDL(Data Definition Language | データ定義言語)
データベースは、エンティティと呼ばれる抽象的な概念ごとにデータを取り扱う。また、データベースはこのエンティティをテーブルという単位で管理する。
例えば、企業の給与管理システムのデータベースであれば、以下のようなテーブルが存在するでしょう。
・従業員テーブル
・役職テーブル
・給与テーブル
上記のようなテーブルを作成・更新・削除したり、テーブルごとのルールや制約を決めたりすることのできる言語を DDL(Data Definition Language | データ定義言語)と呼ぶ。
DDL には以下のような種類が存在する
・CREATE : 新しいテーブルやビューなどのデータベースオブジェクトを作成する
・DROP : 既存のデータベースオブジェクトを削除する
・ALTER : 既存のテーブルベースオブジェクトを変更する
・TRUNCATE : テーブルを再作成する(テーブル内のデータを全削除する)
エンティティ
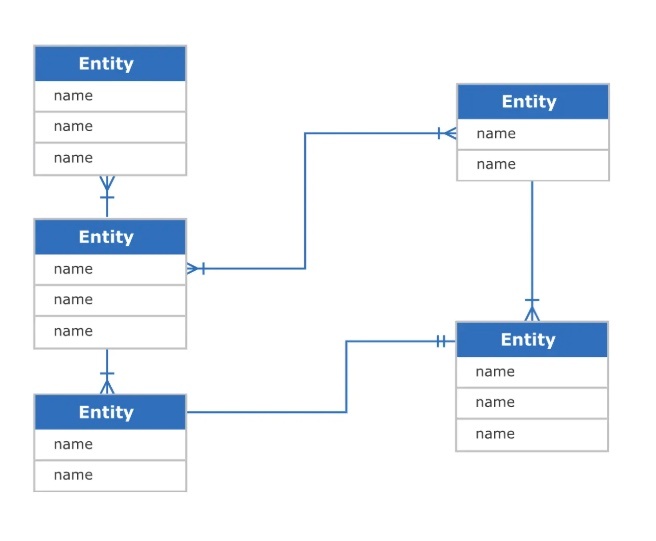
※https://botpenguin.com/glossary/entity より画像引用
DML(Data Manipulation Language)
テーブルにデータを作成したり、既にテーブルに存在するデータを更新・削除したりすることのできる言語
DML には以下のような種類が存在する
・SELECT : テーブルからレコードを抽出する
・INSERT : テーブルにレコードを新規登録する
・UPDATE : テーブルのレコードを更新する
・DELETE : テーブルのレコードを削除する
※レコードとは、データベース内のテーブルを構成する単位のひとつで、一行分のデータを指す。
RDB を使ってデータを操作する際は、必ず DML が使用される。
例えば、世の中に存在するサービス上で、以下のような操作をしたことがあるでしょう。
・自分のアカウントを作成する
・文章や画像を投稿する
・EC サイトで商品を注文する
サービスで使われているテータベースが RDB の場合、これらの操作が行われた際に、アカウントデータ、投稿データ、注文データなどの新しいデータが、見えないところでテーブルに作成されている。この時に使われている言語が SQL。
DML は SQL のうちの一つであり、単に SQL と呼ばれることもある。
Homebrew
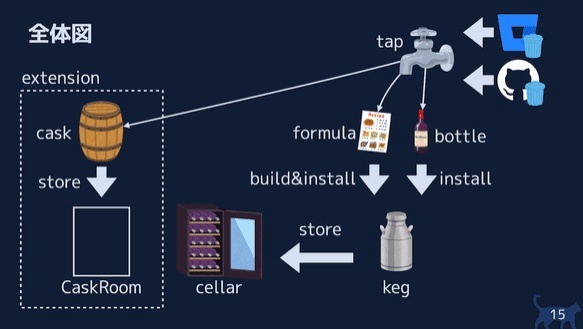
※https://blog.ottijp.com/2020/05/23/homebrew/ より画像引用
macOSやLinuxでソフトウェアのインストール、管理、アンインストールを簡単に行うための、非常に便利なツール
開発環境を効率的に構築・維持するために必須のツール
パッケージマネージャー
Homebrewは「パッケージマネージャー」と呼ばれる種類のソフトウェア。
パッケージとは、ソフトウェアやツール、ライブラリなどのこと。
ソフトウェアのインストールを簡単に
通常、macOSに標準で入っていない便利なツール(例えば、プログラミング言語のPythonやNode.js、データベースのMySQL、画像処理ツールのImageMagickなど)をインストールしようとすると、Webサイトからダウンロードしたり、コマンドラインで複雑な操作が必要だったりする。Homebrewを使うと、これらのソフトウェアをコマンド一つで簡単にインストールできる。
依存関係の管理
多くのソフトウェアは、動作するために他のソフトウェアやライブラリが必要。Homebrewは、これらの依存関係を自動的に管理し、必要なものを一緒にインストールしてくれるため、ユーザーが個別に用意する必要がない。
アンインストールやアップデートも簡単
インストールしたソフトウェアのアンインストールや、最新バージョンへのアップデートも、Homebrewの簡単なコマンドで行える。
「レシピ」と「ボトル」
Homebrewは、各ソフトウェアのインストール方法や依存関係などを記述した「Formula(フォーミュラ)」と呼ばれるファイル(レシピのようなもの)を持っている。また、多くのソフトウェアは「Bottle(ボトル)」と呼ばれるビルド済みのバイナリパッケージとして提供されており、高速にインストールできる。
GUIアプリケーションも管理可能 (Homebrew Cask)
Homebrewには「Cask(カスク)」と呼ばれる拡張機能があり、Google ChromeやSlack、Visual Studio CodeのようなGUI(Graphical User Interface)アプリケーションもコマンドラインからインストールや管理できる。
参考URL:
SQL クライアント
データベースサーバにネットワークを通じて接続するためのソフトウエアのこと。
SQL クライアントツールを使用することで、SQL の実行や SQL の記述を簡単に行なうことができる。
SQLデータベースとの通信
SQLクライアントは、自分が書いたSQLクエリ(データベースからデータを取得したり、データを更新したりするための命令文)をSQLデータベースサーバーに送信し、その結果を受け取る役割を担う。
ユーザーインターフェースの提供
多くのSQLクライアントは、SQLクエリの作成、実行、結果の表示などを簡単に行えるように、グラフィカルなユーザーインターフェース(GUI)を提供している。これにより、コマンドラインに慣れていないユーザーでも直感的にデータベースを操作できる。
データベース管理機能
単にクエリを実行するだけでなく、テーブルの作成や編集、インデックスの管理、ユーザーアカウントの管理など、データベースの管理作業をSQLクライアント上で行えるものもある。
JDBCドライバ
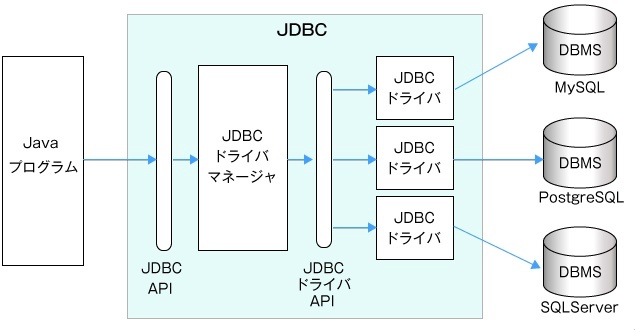
※https://ts0818.hatenablog.com/entry/2017/07/16/205829 より画像引用
ローカル
ローカル接続とは、まさに使用中のPC上で完結する接続のことを指す。
クライアント (Client)
データベースに接続して操作を行うソフトウェア(例:DBeaver、MySQLのコマンドラインツール mysql など)。
サーバー (Server)
データベースのデータ本体を管理し、クライアントからの要求に応じて処理を行うソフトウェア(例:MySQLサーバー mysqld)。
データベースサーバー は、DBMSソフトウェアが稼働しているコンピュータと、そのDBMSソフトウェア全体を指し、クライアントからの接続を受け付けてデータベースへのアクセスを提供する。
データベースはデータそのものであり、それを管理するソフトウェア(DBMS)がサーバーとして機能する。
localhost と 127.0.0.1 は、あらかじめ用意されている特別なホスト名、IP アドレス。
ホスト名とは、ネットワーク上でのコンピュータの名前のこと。コンピュータに名前を付けることで、特定のコンピュータを指定することができる。
localhost と 127.0.0.1 は、それぞれローカルホスト、ローカル・ループバック・アドレスと呼ばれ、自分自身のコンピュータを表す。
ローカル通信
自分内のクライアント(ブラウザ)とTCP/IPを使ってローカルにダウンロードされたデータベースサーバー(例えばMySQL)がお互いに通信する場合の流れ
① クライアント(ブラウザ内のJavaScriptなど)がデータベースサーバーに接続を試みる。
この際、接続先として localhost (または 127.0.0.1) と、データベースサーバーが待ち受けているポート番号(例えばMySQLなら 3306)を指定する。
② OSのネットワークプロトコルスタック(TCP/IP)が、この接続要求を受け付け。 localhost または 127.0.0.1 という宛先IPアドレスは、OSによって特別に扱われる。これは「自分自身」を意味するため、物理的なネットワークインターフェース(例えば、Wi-FiアダプターやLANポート)を通じて外部にデータが送信されることはない。
③ データは、OS内部のループバックインターフェースという仮想的なネットワークインターフェースを経由する。 これは、ソフトウェア的に作られた仮想的なネットワーク接続であり、外部の物理的なネットワークとは隔離されている。データは、この仮想的なインターフェースを通って、送信元のプロセス(ブラウザの一部)から宛先のプロセス(データベースサーバー)へとルーティングされる。
④ データベースサーバーは、指定されたポート番号 (3306 など) で接続要求を待ち受けており、ループバックインターフェースを通じて送られてきた接続を受け入れる。
⑤ 以降のデータのやり取り(SQLクエリの送信、結果の受信など)も、同様にループバックインターフェースを通じて行われる。
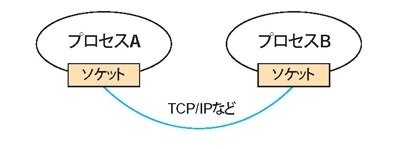
ソケット
※https://xtech.nikkei.com/it/article/Keyword/20100205/344262/ より画像引用
ソケットは一般的に、異なる端末(外部の端末と自分の端末)間でネットワークを介して通信を行なうための「パイプ」のような役割を果たす
※https://til.toshimaru.net/2020-11-06 より画像引用
ネットワーク通信の終点
ソケットは、ネットワーク通信における一方の端点となる。通信を行なう二つのアプリケーションそれぞれがソケットを持ち、そのソケットを通じてデータの送受信を行なう。
アドレスとポートの組み合わせ
各ソケットは、IPアドレス(端末を特定する住所)とポート番号(端末内の特定のアプリケーションやサービスを特定する番号)の組み合わせによって一意に識別される。これにより、ネットワーク上のどの端末のどのアプリケーションと通信しているのかが特定できる。
データの流れのパイプ
ソケットを通じて、データはバイトストリームとして順序正しく相手に届けられる。まさにパイプの中を情報が流れるイメージ。
ただし、ソケットの用途は外部の端末との通信だけではない。
実は、同じコンピュータ内の異なるプロセス間で通信を行なうためにもソケットが使われることがある。
これが「ソケットファイル」を使ったローカル接続。
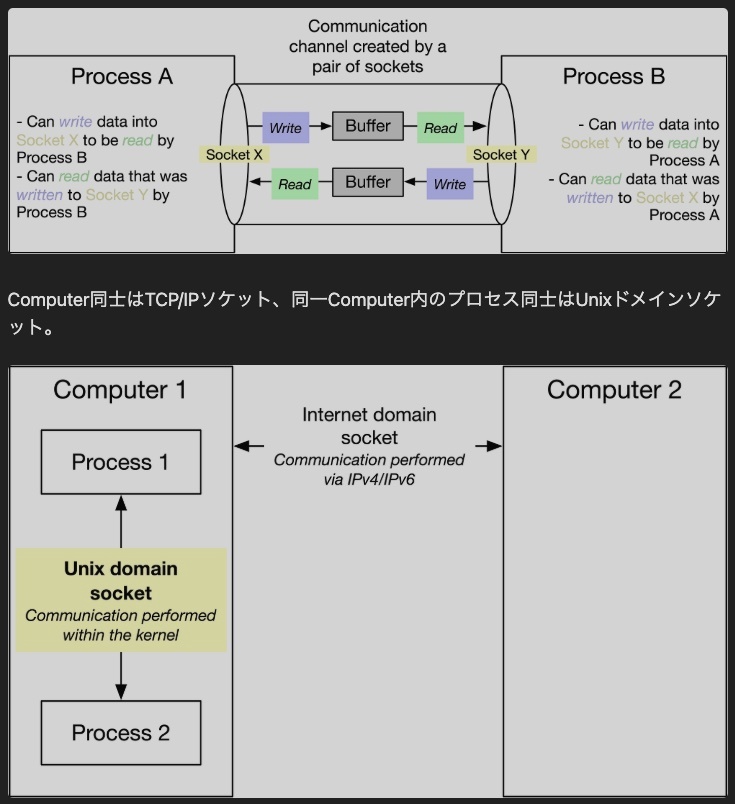
ローカルソケット (Unixドメインソケット)
同じコンピュータ内で動作する複数のプロセスが、ファイルシステム上の特別なファイル(ソケットファイル)を介して通信を行なう仕組み。ネットワークインターフェースを通らず、OSの内部的な仕組みで効率的にデータを受け渡すことができる。MySQLのローカル接続で /tmp/mysql.sock が使われるのはこの方式。
↓
主な役割として、ソケットは異なる端末間のネットワーク通信のためのパイプ。 これは、インターネットやローカルネットワークを通じて、自分のコンピュータと外部のサーバーや他のコンピュータが通信する際に利用される。
加えて、ソケットは同じコンピュータ内の異なるプロセス間の通信(ローカル通信)にも使われる。 この場合は、ネットワークではなく、ファイルシステムなどを介して通信が行われる。
データベース(database)
データベース > テーブル > 個別のデータ と、階層構造になっている。
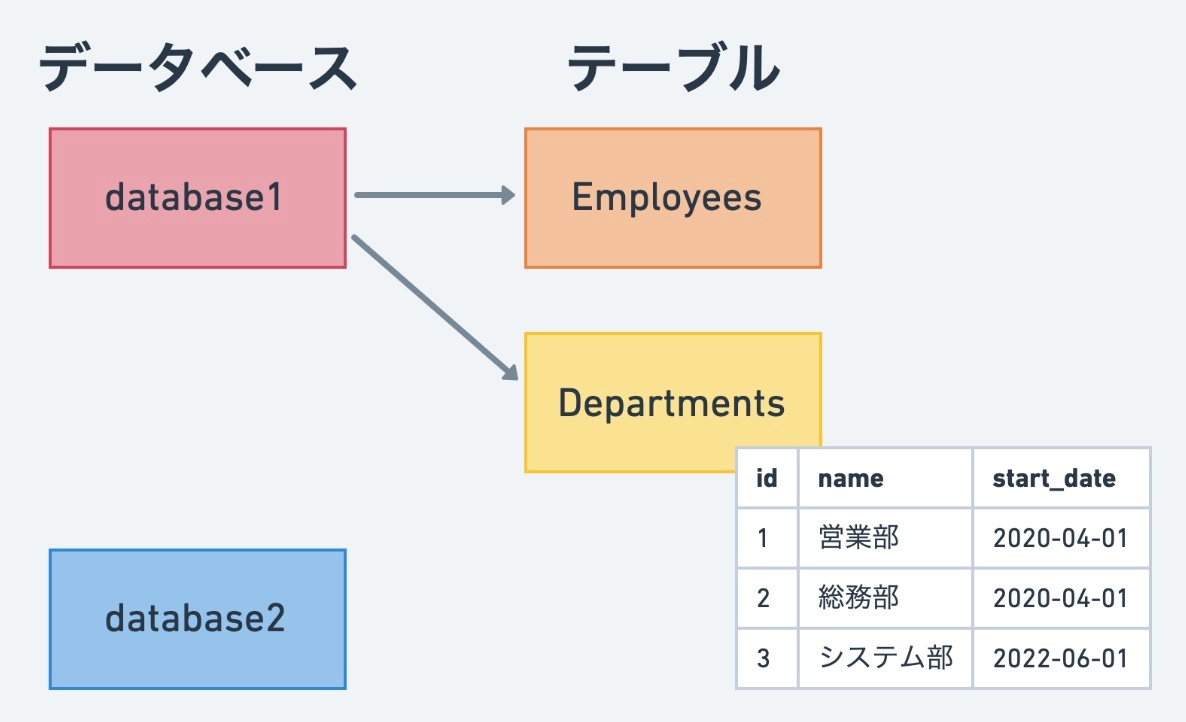
※https://recursionist.io/dashboard/course/6/lesson/992 より画像引用
データベースには複数のテーブルが存在し、テーブルの中には複数のデータが存在する。図を見ると、データベースが複数存在し、database1 の中には Employees テーブル、Departments テーブルが存在する。
Deptartments テーブルには、営業部、総務部、システム部データが入っている。それぞれの部署には、id, name, start_date という項目がある。
◎データベースは階層構造でデータを管理する
テーブル(table)
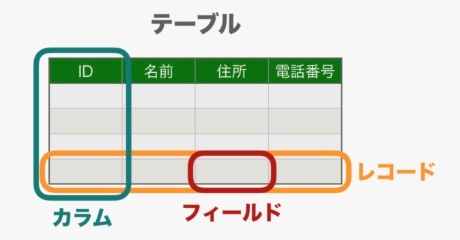
※https://26gram.com/database-terms より画像引用
データベースの一つ下の階層に存在するもので、ここにデータを保存し、管理する。 テーブルは、エンティティと呼ばれる抽象的な概念ごとに作成されることが多く、このようなテーブルを複数作成して、システムで使用する様々なデータを管理していく。
テーブルの列のことをカラム(column)と呼び、行のことをロウ(row)と呼ぶ。
また、一行ごとのデータのことをレコード(record)と呼ぶ。
コマンド
mysql -u root -p : MySQLにログイン(ルートユーザー)
exit; : MySQL からログアウト
mysql > : 待機状態
オプション
-h:--host オプション
接続先のMySQLサーバーが動作しているホスト名を指定
-u:--user オプション
MySQLサーバーへの接続に使用するユーザー名を指定
データベースの作成
① 「SQL」または「localhost:3306」からスクリプトを開く
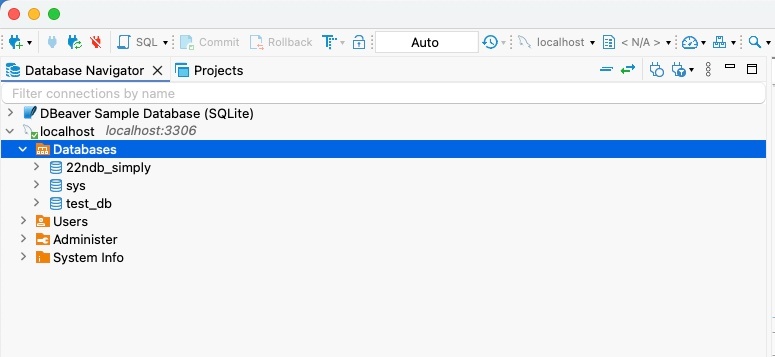
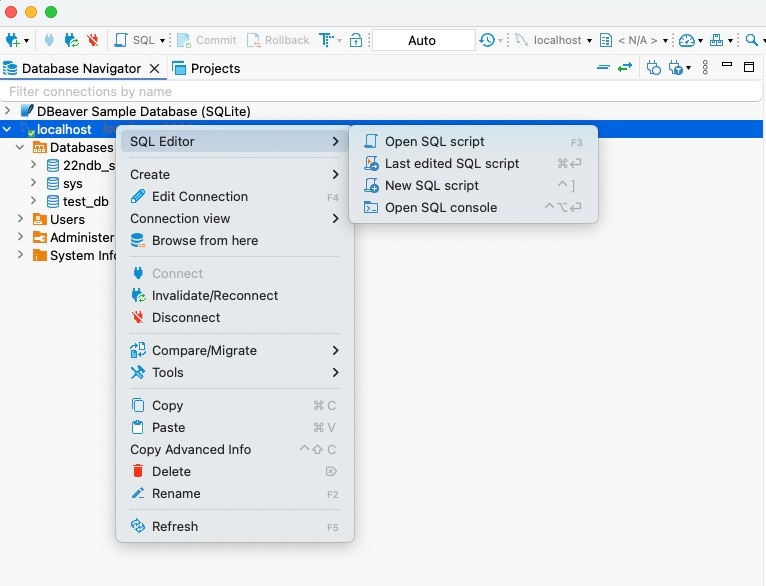
② 「CREATE DATABASE データベース名」を入力
③ クエリの上にカーソルを置いて「Ctrl + Enter」でクエリを実行
※この段階では、データベースナビゲータの localhost:3306 からデータベースの一覧を見ても、新しいデータベースは追加されていない
④ 「localhost:3306 の上で右クリック → 更新」
※DBeaver には即座に変更が反映されないので、更新する必要がある。
CREATE USER user_name@host_name IDENTIFIED BY 'password';
SET PASSWORD FOR test_user@localhost = 'passpass';
※test_user@localhostについて
「localhost から接続する test_user」という特定のユーザーアカウントを指す。
@前後で役割が異なる。
test_user: ユーザー名
このユーザー名を使って、システムやサービスにログインしたり、特定のリソースへのアクセス権限が確認されたりする。
localhost: ホスト名
そのユーザーアカウントが存在するコンピュータまたはネットワーク上の場所
※ MySQLやPostgreSQLなどのデータベースシステムでは、ユーザーアカウントは ユーザー名@ホスト名 の形式で管理される。
CREATE DATABASE db_name;
CREATE DATABASE [IF NOT EXISTS] データベース名;
データベースオブジェクト(テーブル、データベース、インデックスなど)を作成する際に、同じ名前のオブジェクトが存在しない場合にのみ作成する ように指示するもの
SELECT user, host FROM mysql.user;
RENAME USER 'user_name'@'host_name' TO 'new_user_name'@'new_host_name';
DROP USER user_name@host_name;
CREATE TABLE table_name (id INT, parent_table_name_id INT, FOREIGN KEY parent_table_name_fk(parent_table_name_id) REFERENCES parent_table_name(id));
FOREIGN KEY
テーブル間に外部キー制約を定義する。
外部キーは、あるテーブルのカラムが、別のテーブルの特定のカラムを参照し、テーブル間の参照整合性を保つための制約
FOREIGN KEY 外部キー制約名(外部キー制約を適用する現在のテーブルのカラム)
REFERENCES
外部キーが参照する先のテーブルとカラムを指定するために使用
※FOREIGN KEY キーワードの直後の括弧内には、現在のテーブルのどのカラムに外部キー制約を適用するかを記述する。FOREIGN KEY の直後の括弧は、制約をかける側のテーブルのカラムを指定する役割を持っている。
※REFERENCES キーワードの後の括弧は、参照される側のテーブルのカラムを指定する。
データベースの確認
SHOW DATABASES;
※Sが最後についているので見落とし注意
※コメントの記述: SQLファイル内にコメント (-- または /* ... */) を記述して、クエリの意図や背景を記録しておくことができる。
データベースの選択
USE db_name;
データベースの削除
DROP DATABASE db_name;
インデックスの設定
ALTER TABLE table_name ADD INDEX index_name (column_name);
CREATE INDEX index_name ON table_name(column_name);
SHOW INDEX FROM table_name;
テーブルの作成(CREATE)
テーブルを作る際は、カラムのデータ型を決める必要がある
| データ型 | 内容 |
|---|---|
| INT | 4バイトの数値 |
| BIGINT | 8バイトの数値 |
| FLOAT | 浮動小数点ありの数値 |
| DATE | 日付 |
| DATETIME | 日時 |
| CHAR(n) | 固定長文字列(足りない分は空白で埋められる) |
| VARCHAR(n) | 変長文字列 |
| TEXT | 変長文字列 |
※ n には文字数が入る。
VARCHAR 型と TEXT 型はどちらも文字列を格納することのできるデータ型。
TEXT 型は 65535 文字まで格納可能なため、データ量の大きな文字列を格納したい場合は TEXT 型を使用する。
しかし、TEXT 型はデータベースにデータが直接格納される訳ではなく、ポインタのみが格納され、データ自体は別領域に格納される。そのため、データをCRUD(Create, Read, Update, Delete)する際の効率を考えると、別領域にアクセスする必要のない VARCHAR 型の方が良いと言える。ここは、ユースケースに合わせてより適切な方を選択していきましょう。
ポインタとは、データが保存されているメモリアドレスを指す変数、またはメモリアドレスそのものを指します。
CREATE TABLE db_name.table_name (column_name data_type, column_name data_type, ...);
テーブルを作成する際に指定のデータ型からカラムの型をそれぞれ指定する。
テーブル名の後の部分は、カラム名とデータ型の組み合わせが入る。
CREATE TABLE table_name (column_name data_type, column_name data_type, ...);
使用するデータベースを選択している場合、db_name は不要。
テーブルを作成する際に指定のデータ型からカラムの型をそれぞれ指定する
テーブル名の後の部分は、カラム名とデータ型の組み合わせが入る。
入出力バッファ
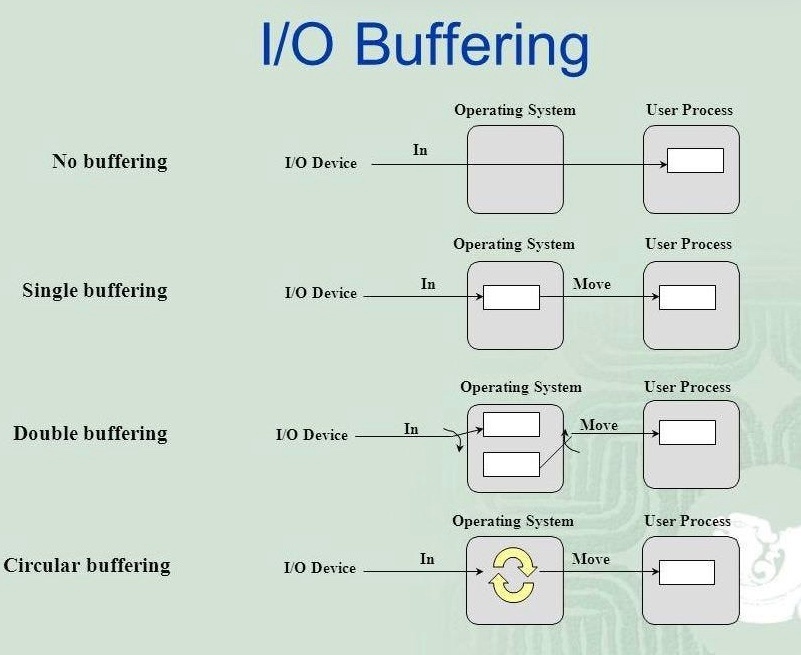
※https://wisemonkeys.info/blogs/IO-Buffering より画像引用
プログラムが外部のデバイス(ファイル、ネットワーク、キーボード、ディスプレイなど)とデータをやり取りする際に、一時的にデータを蓄えておくためのメモリ領域のこと
入出力バッファが必要な理由
コンピュータの内部処理速度と、外部デバイスのデータ転送速度には大きな差がある場合がよくある。もしデータをやり取りするたびに直接読み書きを行なっていたら、プログラムの効率が非常に悪くなってしまう。
そこで、入出力バッファが仲介役として働くことで、この速度差を吸収し、効率的なデータ転送を実現する。
具体例
ファイルへの書き込み
プログラムがファイルにデータを書き込む際、少しずつデータをバッファに溜め込む。
バッファがいっぱいになるか、プログラムが明示的に書き込みを指示したタイミングで、バッファの内容がまとめてファイルに書き込まれる。
これにより、頻繁な低速なディスクへの書き込みを減らし、プログラムの処理を高速化できる。
ファイルからの読み込み
プログラムがファイルからデータを読み込む際、ファイルの内容がまとめてバッファに読み込まれる。
プログラムは、必要に応じてバッファからデータを順次読み取る。
これにより、データの要求があるたびに低速なディスクアクセスを行なう必要がなくなり、効率的にデータを取得できる。
※プログラムがアクセスするファイルは、通常、オペレーティングシステム (OS) のファイルシステムによって管理されているファイルのこと
ネットワーク通信
ネットワークを通じてデータを送受信する際にも、バッファが利用される。
送信するデータはバッファに溜められ、ある程度のまとまりになってからネットワークへ送信される。
受信したデータも一旦バッファに格納され、プログラムが必要なタイミングで読み取られる。
これにより、ネットワークの遅延やパケットの断片化などの影響を緩和し、安定したデータ転送を可能にする。
キーボード入力
キーボードから入力された文字は、プログラムに直接渡されるのではなく、一旦キーボードバッファに蓄えられる。
プログラムは、必要に応じてバッファから入力文字を読み取る。これにより、高速なキー入力に対応できる。
CHAR型とVARCHAR型
CHAR の場合
CHAR(n) のように、格納できる固定の長さ n を指定する。
・例えば CHAR(10) と定義されたカラムには、常に10文字分の領域が確保される。
・格納する文字列が10文字より短くても、残りの部分はスペースで埋められて保存される。
・取り出すときは、末尾のスペースは通常自動的に削除される。
(例)'hello' (5文字) を CHAR(10) カラムに保存すると、内部的には 'hello ' (スペース5つで10文字) として保存される。
VARCHAR の場合
VARCHAR(n) のように、格納できる最大長 n を指定する。
・例えば VARCHAR(10) と定義されたカラムには、最大で10文字までの文字列を格納できる。
・CHAR とは異なり、実際に格納する文字列の長さに合わせて必要なだけの領域が確保される。
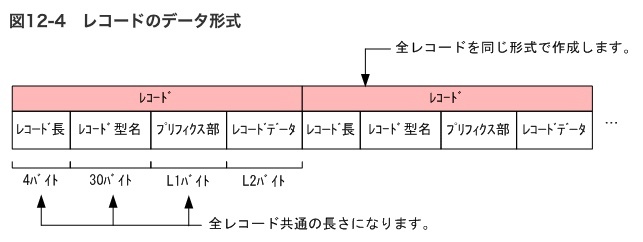
・ただし、格納する文字列の長さをMySQLが認識するために、接頭辞(プレフィクス) という情報が付加されて保存される。
「1 バイトまたは 2 バイト長のプリフィクスの付いたデータ」とは?
VARCHAR 型のデータが実際にどのようにディスクに保存されるかの内部的な仕組み。
長さプリフィクス: 格納される文字列の実際のバイト数を示す情報
?なぜプリフィクスが必要なのか?
VARCHAR は可変長のデータなので、MySQLは各行のデータが何バイトあるのかを知る必要がある。この長さプリフィクスが、その役割を果たす。
1 バイト長のプリフィクス
格納する文字列の長さ(バイト数)が 255 バイト以下の場合に使われる。
1バイトで表現できる最大の数値は255なので、これ以下の長さであれば1バイトで十分情報を格納できる。
例えば、5バイトの文字列 'hello' を VARCHAR カラムに保存する場合、内部的には [0x05]hello のようなイメージで保存される([0x05] が長さを示す1バイトのプリフィクス)。
2 バイト長のプリフィクス
格納する文字列の長さ(バイト数)が 256 バイトよりも大きい場合に使われる。
1バイトでは表現しきれない長さになるため、より大きな数値を格納できる2バイトのプリフィクスが使用される。
例えば、300バイトの文字列を VARCHAR カラムに保存する場合、内部的には [0x01][0x2c]... (300バイトのデータ) のようなイメージで保存される ([0x01][0x2c] が300を示す2バイトのプリフィクス)。
256 文字以上を格納できるようにすると、より多くのデータ容量を消費するということ
↓
VARCHAR 型のデータは、実際に格納する文字列に加えて、その文字列の長さを記録するための小さな「おまけの情報」(長さプリフィクス)と一緒に保存される。このおまけの情報のサイズは、格納する文字列の長さによって1バイトか2バイトのどちらかになる。
※https://itpfdoc.hitachi.co.jp/manuals/3020/3020657860/W5780486.HTM より画像引用
この仕組みの利点
・ディスク容量の節約: 実際に必要なバイト数だけを保存するため、CHAR のように無駄なスペースを確保する必要がなく、ディスク容量を効率的に利用できる。
・柔軟性: 最大長を超えない範囲であれば、様々な長さの文字列を格納できる。
スキーマ(schema)
データベースのデータ構造やデータの持ち方
データベースを作成する前には、必ずデータベース設計というものを行なう。
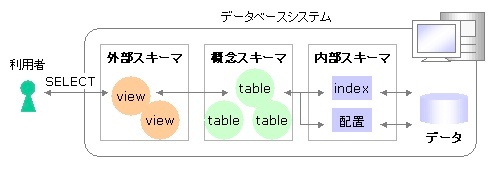
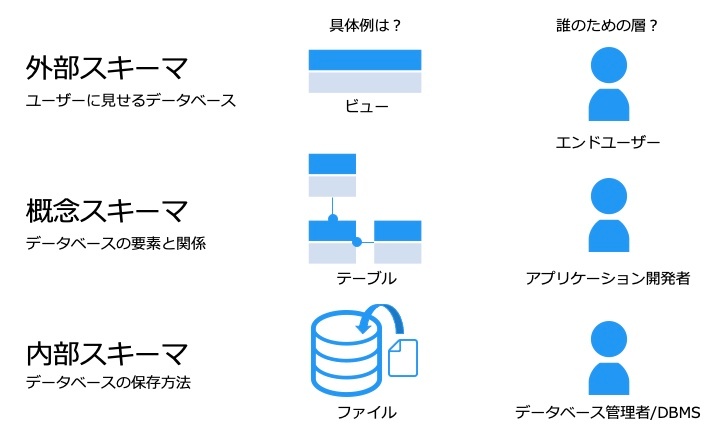
※https://www.it-shikaku.jp/top30.php?hidari=09-01-01.php&migi=km09-01.php より画像引用
外部スキーマ : データベースのビューや、アプリケーションのユーザーインターフェースなど
概念スキーマ : 開発者から見たデータベースで、データ構造や関係について
内部スキーマ : DBMS から見たデータベースで、データを格納しているファイルなど具体的な格納方法など
※https://hogetech.info/database/design/three-schema より画像引用
※ビューは、データベースのデータを組み合わせて作った仮想的なテーブルを指す。
カラムやデータ型、インデックスや制約など、テーブルについての様々な定義は、概念スキーマに分類される。これら 3 つのスキーマをレイヤーごとに分割してデータベースを管理することで、データベースの拡張や修正を簡単に行えるようにしている。
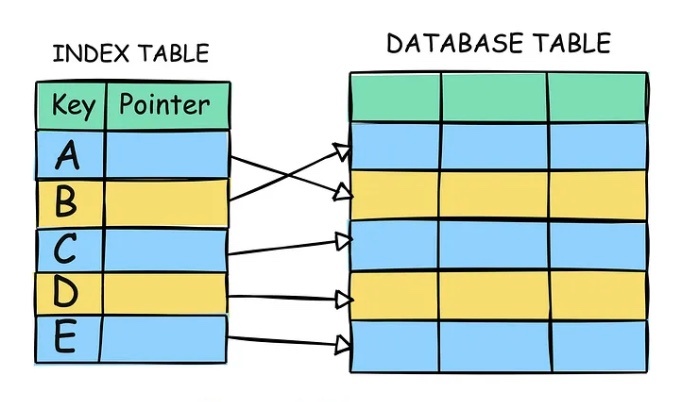
インデックス(index)
※https://blog.algomaster.io/p/a-detailed-guide-on-database-indexes より画像引用
インデックスは特定のカラム値のある行をすばやく見つけるために使用される。
インデックスがないと、MySQL は該当する行を見つけるために、先頭行から始めてテーブル全体を走査する必要がある。テーブルが大きいほど、このコストが大きくなってしまう。
テーブルの特定のカラムにインデックスが設定されており、そのカラムでレコードを走査する場合、MySQL は全てのレコードを調べる必要なく、素早く特定できる。これは全ての行を順次読み取るよりはるかに高速。
これは内部的に B ツリーと呼ばれる、データ走査に強い木構造を用いることで、データの特定を素早く実行している。特定のカラムに対してインデックスを設定すると、そのカラムでレコードを特定する場合のコストを非常に小さくできる。
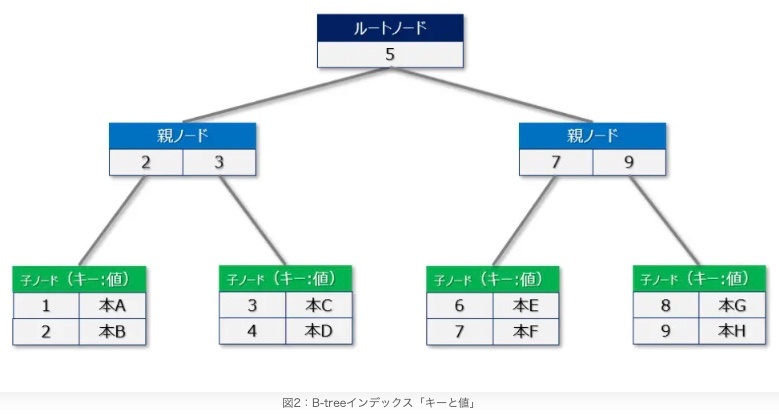
Bツリー
※https://it-biz.online/it-skills/b-tree/ より画像引用
BツリーとBST
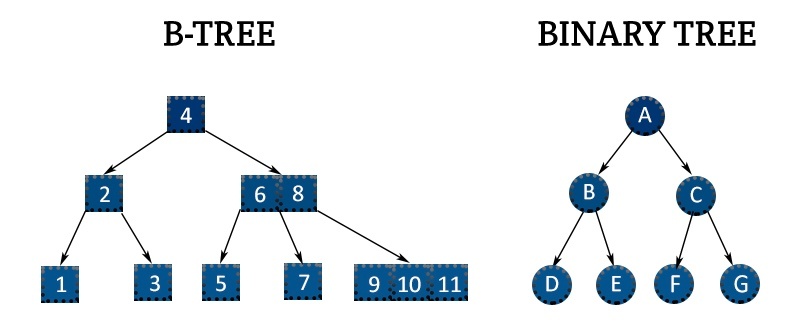
※https://open4tech.com/b-tree-vs-binary-tree/ より画像引用
各ノードは複数の子ノードを持つことができる多分木。
この子ノードの最大数は、B-tree の「次数 (order)」と呼ばれるパラメータによって決まる。
各内部ノードは、子ノードの数より 1 つ少ない複数のキーを持つ。これらのキーはソートされた順に格納され、子ノードへの分岐点を定義する。
すべての葉ノードは同じ深さにある。これは、B-tree が平衡木であることを意味する。
B-tree は、ディスクなどのブロック単位でアクセスされる記憶装置(例えば、データベースのインデックスやファイルシステム)での利用に適している。1つのノードを1つのディスクブロックに対応させることで、ディスクI/Oの回数を減らし、効率的なアクセスを実現する。
B-tree は、挿入や削除操作後も木のバランスを保つための複雑なアルゴリズムを持っている。
インデックスの設定クエリ
ALTER TABLE table_name ADD INDEX index_name (column_name);
CREATE INDEX index_name ON table_name(column_name);
制約(constraint)
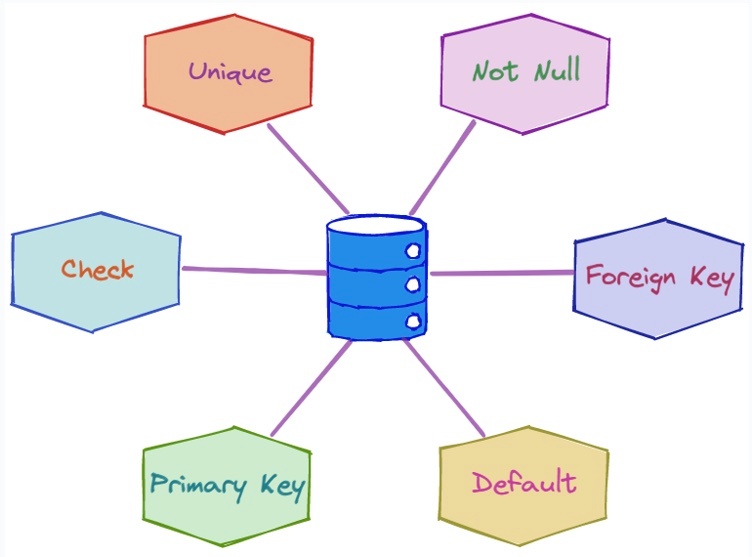
※https://algodaily.com/lessons/sql-constraints より画像引用
① 主キー(PRIMARY KEY)制約
② 外部キー(FOREIGN KEY)制約
③ NOT NULL 制約
④ 一意(UNIQUENESS)制約
⑤ CHECK 制約
CONSTRAINT は、テーブルに定義する制約に名前をつけるためのキーワード
① 主キー(PRIMARY KEY)制約
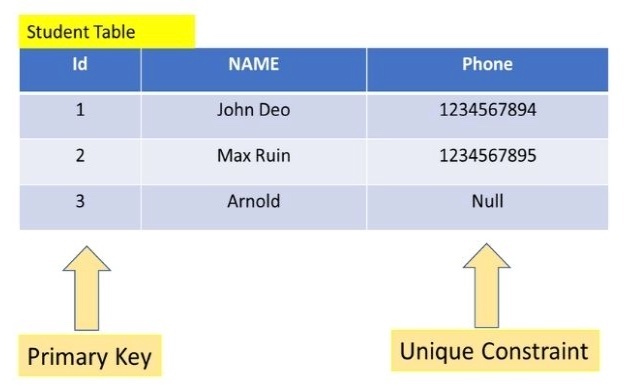
※https://www.plus2net.com/sql_tutorial/constraints-primary-key.php より画像引用
・一意を保証する
・NULL を禁止する
・1 つのテーブルにおいて 1 つのカラムにだけ主キー制約を設定できる
・主キー制約を設定するカラムにはインデックスが必要。手動でも設定できるが、自動で設定される
↓
・ID は、一意でなければならない
・ID は、NULL を禁止しする
・このテーブルには、ID 以外のカラムに主キー制約を設定できない
・ID は、自動でインデックスが設定され、ID によるデータ走査は素早く行なうことができる
テーブルの id カラムに主キー制約を設定する : CREATE TABLE members (id INT PRIMARY KEY);
② 外部キー(FOREIGN KEY)制約
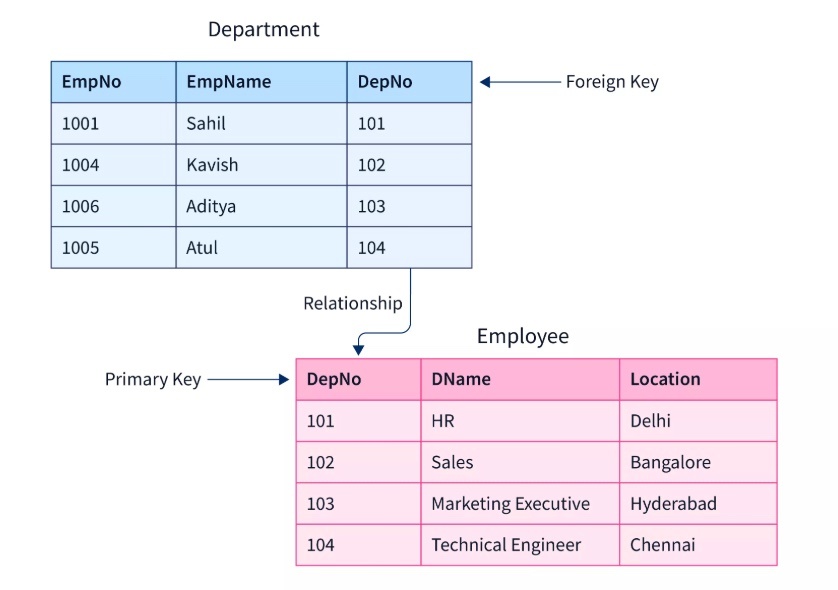
※https://www.scaler.com/topics/sql/foreign-key-in-sql/ より画像引用
・他のテーブルの主キーを参照する。
・この制約を設定したカラム(外部キー)の値は、必ず主キーに設定したカラムに存在する値でなければならない。
・この制約を設定したカラムの値を先に削除しなければ、参照先の主キーのデータを削除することはできない。
・外部キー制約を設定するカラム、参照先の主キーカラムにはインデックスが必要。手動でも設定できるが、自動で設定される。
↓
・外部キーは、主キーを参照し、同じ値が入る。
・主キーに存在しない値は、外部キーに入れることはできない。
・外部キーを先に削除しなければ、主キーを削除することはできない。
例えば、主キー = 2 を削除するためには、先にそれを参照しているテーブルの 該当ID のデータを削除する必要がある。
・主キー、外部キー両方は、自動でインデックスが設定され、ID によるデータ走査は素早く行なうことができる。
外部キー制約のついたテーブルの作成
CREATE TABLE <子テーブル名> (<カラム名1> <データ型> <制約>, <外部キーとなるカラム名> <データ型> <制約>,
CONSTRAINT <外部キー制約名>
FOREIGN KEY (<外部キーとなるカラム名>)
REFERENCES <親テーブル名>(<親テーブルの主キーとなるカラム名>)
);
※FOREIGN KEY キーワードの直後の括弧内には、現在のテーブルのどのカラムに外部キー制約を適用するかを記述する。FOREIGN KEY の直後の括弧は、制約をかける側のテーブルのカラムを指定する役割を持っている。
※FOREIGN KEY キーワードの直後に外部キー制約の名前をつける。これは、 データベース内で、この外部キー制約を一意に識別するための名前となる。もしテーブルに複数の外部キー制約がある場合、それぞれの制約に異なる名前を付けることで、どの制約がどのカラム間の参照関係を定義しているのかを明確に区別できる。
MUL は Multiple の略で、そのカラムがインデックスの一部であり、かつそのインデックスがUNIQUEではないことを意味する
制約(constraint)
※https://algodaily.com/lessons/sql-constraints より画像引用
③ NOT NULL 制約
NULL 値を禁止する

※https://www.scaler.com/topics/not-null-in-sql/ より画像引用
テーブルの name カラムに NULL 値が入ることを禁止する : CREATE TABLE products (id INT, name VARCHAR(255) NOT NULL);のように記述する
④ 一意(UNIQUENESS)制約
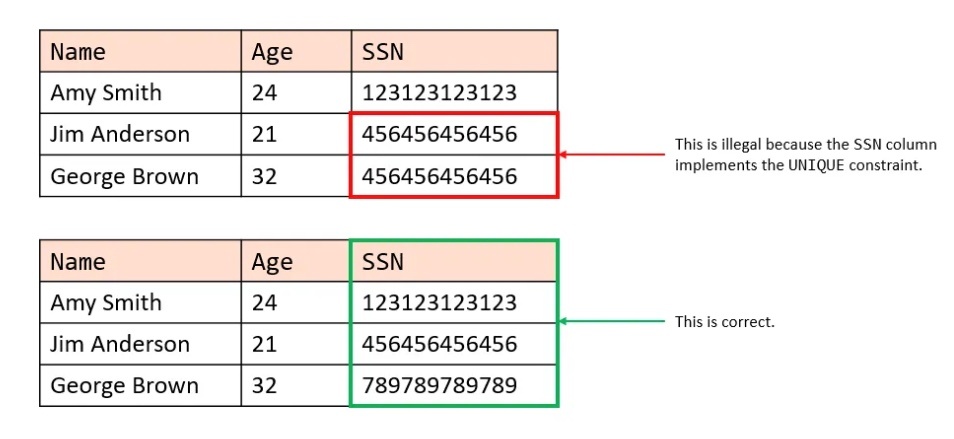
※https://learnsql.com/blog/unique-constraint-in-sql/ より画像引用
・一つのカラムでデータが重複することを禁止する
・複数のカラムに設定可能
・NULL を禁止するわけではない(NULL の重複は許される)
・自動でインデックスが設定される
テーブルの カラムに同一の値が入ることを禁止する : CREATE TABLE employees (id INT, name VARCHAR(255), email VARCHAR(255) UNIQUE); のように記述する
一意制約でもインデックスが自動で設定される。
⑤ CHECK 制約
条件を指定して、その条件を満たさないデータが入るのを禁止する。
テーブルのカラムに指定データが入ることを禁止する : CREATE TABLE users (id INT PRIMARY KEY, age INT, CONSTRAINT age_check CHECK(age >= 18));のように記述する。
CHECK 制約に名前を付け(age_check)、条件を設定することで、age カラムに入る値はその制約を守るよう強制できる。
※CHECK 制約の内容は、今までのように SHOW TABLE FROM users; では確認できない。CHECK 制約の内容は、SHOW CREATE TABLE users; で確認することができる。このクエリは、CHECK 制約の内容だけでなく、テーブルの様々な設定を確認することができるクエリ。従って、これまで SHOW INDEX を使って確認していたインデックス情報も SHOW CREATE TABLE table_name; で確認できる。
※SHOW TABLE FROM users;
users データベース内のテーブル名の一覧を表示する。
テーブルの構造や定義といった詳細な情報ではなく、どのテーブルが存在するかを知りたい場合に用いる。
※SHOW CREATE TABLE users;
テーブルの構造定義の詳細を確認したい場合やスキーマをコピー・バックアップしたい場合などに用いる。
users テーブルを作成するための完全な CREATE TABLE 文。
テーブルの更新(ALTER)
テーブルの更新は、ALTER を使って、ALTER TABLE table_name change_command; のように記述する。
change_command の部分は、table_name にどんな変更を加えようとしているかによって異なる。
変更内容には
・テーブル名、カラム名、インデックス名を変更する
・カラムの定義を変更する
・カラムを追加する
・カラムを削除する
といったものがある。
テーブル名の変更
ALTER TABLE table_name RENAME [TO|AS] new_table_name;
カラム名の変更
ALTER TABLE new_departments RENAME COLUMN start_date TO start_on;
インデックス名の変更
ALTER TABLE new_departments RENAME INDEX id_index TO new_id_index;
カラムの定義の変更
ALTER TABLE table_name MODIFY column_name new_definition;
MODIFY の代わりに CHANGE を使えば、カラム名の変更も同時に行なうことができる。
ALTER TABLE new_departments MODIFY id BIGINT UNIQUE;
MySQLでは、「UNIQUE KEY」(ユニークキー)を設定したカラムには、その値が一意(重複しない)であることを保証するための仕組みとして、自動的にインデックスというものが作られる。このインデックスのおかげで、データの検索などが速くなる。
そのため、「UNIQUE KEY」を設定した「id」カラムには、すでに検索を速くするためのインデックスが自動的に付くため、すでにKEYが存在する場合はそのKEYは重複するため削除すること。
カラムの追加
ALTER TABLE table_name ADD column_name definition [FIRST | AFTER column_name];
最後の部分を特に指定しなければ、新規カラムは最後の列に追加される。
FIRST を指定した場合は最初に、AFTER column_name を指定した場合は指定したカラムの後に追加される。
ALTER TABLE table_name ADD column_name definition FIRST column_name;
ALTER TABLE table_name ADD column_name definition AFTER column_name;
カラムの削除
ALTER TABLE table_name DROP column_name;
MySQLにおけるKEY, INDEX, UNIQUE KEY, PRIMARY KEY
KEY, INDEX
ほとんど意味を持つ。従って、その違いを意識する必要はそこまでない。両方インデックスツリーが作成され、データ走査が速くなるという特徴がある。
※https://www.geeksforgeeks.org/binary-indexed-tree-or-fenwick-tree-2/ より画像引用
UNIQUE KEY
値を重複させたくないカラムに対して設定するキー。
これを設定すると、そのカラムに対して自動的にインデックスが付与される。理由は簡単で、データを追加するごとにその新規データが既存データと重複していないかをチェックするわけだが、そのチェックを極力速めるため。
PRIMARY KEY
UNIQUE KEY と同様重複を許さない。
このように UNIQUE キーと近い側面があるが、さらに特別なキーになっている。
例えば、
・NULL 値を許さない
・一つのテーブルに一つしか設定できない
といった特徴がある。
また、外部キーの参照元になるという特徴もある。
単に重複を許したくない場合は、UNIQUE KEY で十分だが、それ以上に主キーとしての特徴を持たせたい場合は PRIMARY KEY を使用するといった使い分けになる。
テーブルの削除(DROP/TRUNCATE)
テーブルの削除
テーブルの削除は、DROP TABLE table_name; のように記述する。
テーブルを削除すると、テーブルそのものとテーブルに格納されているデータも削除される。
※CHECK 制約やインデックスなど、カラムに付与する設定を削除したい場合
ALTER TABLE table_name DROP [INDEX CHECK ...];
のようにするため、DROP とは文法が異なることに注意
データの全削除
データの全削除は、TRUNCATE を使って行なうことができる。これにより、指定したテーブルに存在するデータを全て削除することができる。これはテーブルの定義ではなく、テーブル内のデータを削除するという操作であるため、TRUNCATE は DDL(Data Definition Language | データ定義言語)に分類される。DML(Data Manipulation Language | データ操作言語)であると思われがちだが、実際はそうではない。
TRUNCATE は単にデータ行を削除するだけでなく、テーブル自体を初期化に近い状態に戻す。
理由は、データ削除をする際、一度テーブルを削除、つまり DROP するため。
テーブルを一度削除してから元のテーブル定義の通りにテーブルを再作成する。
そのため、TRUNCATE は DDL に分類されている。
同じく、テーブル内のデータを全て削除する方法として、DML の一つである DELETE 文があるが、これらの間には以下のような違いがあります。
・DELETE は一行ずつデータを削除していくため、データ数が増えると TRUNCATE よりも削除に時間がかかる
・TRUNCATE でデータを削除した場合、AUTO_INCREMENT 値はその開始値にリセットされるが、DELETE で削除した場合は削除前の状態から続けて採番される。
TRUNCATE TABLE テーブル名;
※AUTO_INCREMENT は、カラムに対して設定できる。AUTO_INCREMENT を設定すると、データを作成するごとにそのカラムの値が自動で採番されていく。最初の値は手動で決めることができるが、基本的には 1 から始まることが多い。
DML (Data Manipulation Language | データ操作言語)
データベースにおいての CRUD(Create・Read・Update・Delete)処理を行なうために使用される。テーブルに保存されているデータを操作したい場合は DML を使用する。
具体的には、以下が該当する。
・SELECT 文(データの検索・抽出)
・INSERT 文(データの追加)
・UPDATE 文(データの更新)
・DELETE 文(データの削除)
一行でクエリを書いていくと、見辛くなるので、改行やインデントをつかっていこう。
インデントは、Tab キーで行なう。DBeaver の場合、Ctrl + Shift + F を押せば、自動フォーマットがかかり、適切な形のクエリにしてくれる。
SELECT
SELECT 句は、出力する項目を指定することができる文法。
例えば、SELECT 1, 2; のように固定値を出力することができる。
SELECT の後には、取得したいデータの種類(特定のカラム、計算結果、集計関数など)を指定する。
データベースは数学の「関係」という考え方に由来しており、それはテーブル形式で出力される。
出力はテーブル形式で出力される。
※SELECT 文では、テーブルに実際に存在するカラムだけでなく、仮想的なカラムを作成して結果セットに含めることができる。
SELECT '固定値' AS 仮想カラム FROM users;
仮想的なカラムを使う方法
・リテラル値の使用
・計算結果の使用
・関数の適用結果の使用
・CASE式の使用
・連結演算子の使用
AS
エイリアス。SELECT句で指定したカラムに別名を指定することができる。
SELECT 句で計算された値や関数適用の結果に別名(エイリアス)を付ける際に、AS キーワードは省略可能。
SELECT 句で定義したエイリアスは、主に ORDER BY 句で使用できる。他の句でエイリアスを使用したい場合は、式を繰り返すか、サブクエリや CTE を活用するのが一般的。
※それ以外の句、例えば WHERE 句や GROUP BY 句、HAVING 句などでは、一般的にエイリアスを直接使用することはできない。
これは、SQLの論理的な処理順序に関係している。多くのデータベースシステムでは、クエリは以下のような順序で処理される。
クエリの実行順序
① FROM
② WHERE
③ GROUP BY
④ HAVING
⑤ SELECT
⑥ ORDER BY
⑦ LIMIT / OFFSET
SELECT 句でエイリアスが定義されるのは、WHERE 句や GROUP BY 句などが処理された後。
そのため、これらの句が処理される時点では、まだエイリアスは「存在しない」か、少なくとも認識されていないため、直接参照することができない。
FROM
FROM 句は、入力になるテーブルを指定することができる文法。
SELECT と組み合わせれば、入力と出力をコントロールすることができる。
例えば、「FROM で指定した入力テーブルに存在するカラムの内、表示したいカラムを SELECT で指定する」といった使い方ができる。
WHERE
WHERE 句は、入力テーブルから条件に合うレコードのみを抽出することができる文法。
SELECT, FROM と組み合わせれば、入力テーブルから条件に合うレコードのみを出力することができる。
SELECT products.* FROM products WHERE products.id = 1;
この時の内部での処理は、以下のように行われている。
・一行目のレコードを見て、WHERE 句を評価する。つまり、products.id = 1 を評価する。
・WHERE 句の評価が true であればその行は出力され、false であればその行は出力されない。
・一行目のレコードの評価が完了したので、二行目のレコードへと移る。
・上記を繰り返す。
全てのレコードを評価していき、最終的に出力対象になっているレコードをテーブル形式で表示する。
評価するレコード数が多くなれば内部の処理にかかるコストが大きくなっていくことが予測される。このコスト増加を抑えるためにインデックスが使用される
SELECT や WHERE 内でカラムを指定する場合は、table_name.column_name という形で記述してきたが、実はテーブル名を省略することができる。
→ SELECT * FROM products WHERE id = 1; のように記述することも可能ということ
一つのクエリで入力テーブルを一つしか取らない場合は、 SELECT や WHERE 内でテーブル名を省略することができる
※一つのクエリで複数の入力テーブルを取る必要が場合、SELECT や WHERE 内で指定されているカラムがどの入力テーブルのカラムなのかがわからなくなるため、table_name.column_name という形でテーブル名を明示する必要がある。明示しなかった場合は構文エラーが出力される。
SQL演算子(比較/論理)
WHERE 句で指定できる条件(比較演算子)
二つの式や値の比較を行ない、結果を真偽値(true または false)で返す演算子
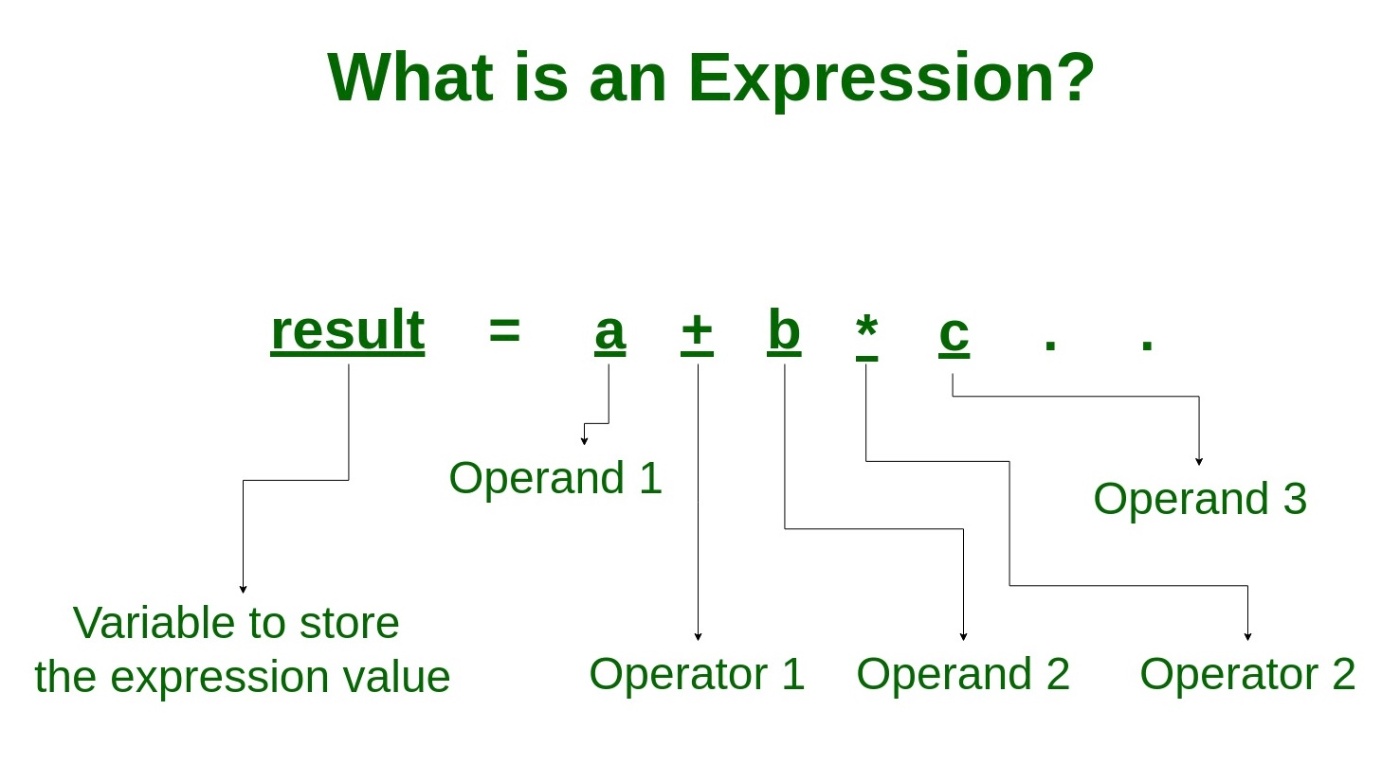
式(expression)とは評価され、値を出力するものを指す。
例えば、1 + 1 は、2 という値を返すため式にあたる。
対なるものとして説明されることが多い文(statement)は、プログラムの制御文。文のわかりやすい例として、if 文や for 文がこれにあたる。文はプログラムの制御を行なうものであり、プログラムの分岐や流れを決めるもの。この文の中で流れや分岐を決める時に利用されるのが式。プログラムでは、文の中の至る所で式を評価することで連続する分岐を制御し、一つの大きな処理が完結する。
※https://www.geeksforgeeks.org/what-is-an-expression-and-what-are-the-types-of-expressions/ より画像引用
式や値を評価する比較演算子には以下が存在し、これらは出力として、真偽値を返す。
| 比較演算子 | 意味 |
|---|---|
= |
等しい |
<> |
等しくない |
> |
より大きい |
>= |
以上 |
< |
より小さい |
<= |
以下 |
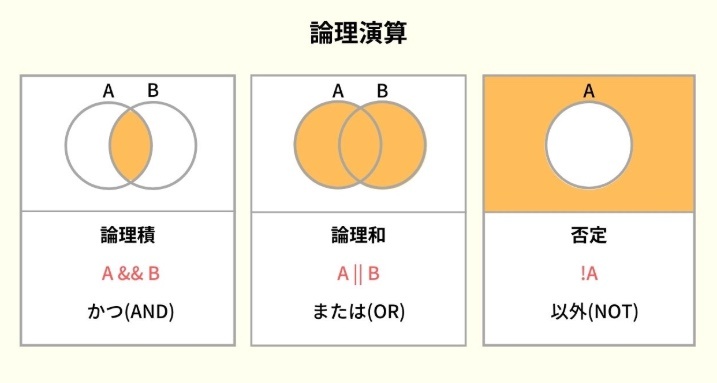
WHERE 句で指定できる条件(論理演算子)
真偽値に対して演算を行ない、結果として真偽値を返す演算子
比較演算子などを使用して出力された真偽値を用いて、演算を行なう
※https://webukatu.com/wordpress/blog/39742/ より画像引用
NOT(否定)
オペランドの出力が真の場合、false を返し、偽の場合、true を返す。
AND(論理積)
右オペランドと左オペランドが共に真の場合、true を返し、それ以外は false を返す。
OR(論理和)
右オペランド、または左オペランドが真の場合、true を返し、両方偽の場合 false を返し。
WHERE 句で指定できる特別な条件
| 条件 | 意味 |
|---|---|
| IN | 列挙してる値のいずれかを含む |
| BETWEEN | 数値が~以上~以下である |
| LIKE | 指定された文字列を含む |
| IS NULL | NULL 値である |
| IS NOT NULL | NULL 値でない |
◎SQL において注意しなければならないのが、NULL の扱い
NULL と一緒に比較演算子を使用することはできず、IS NULL や IS NOT NULL を使って比較する。
SQL では、NULL 値は他の値(NULL を含む)との比較で true になることはない。NULL を含めた比較演算は全て NULL を返す。そして、MySQL では 0 や NULL は false を意味するため、最終的な出力は Empty Set になり、意味のある出力を得られることはない。
WHERE 句で指定できる特別な条件
IN : 列挙してる値のいずれかを含む
IN 句は、列挙している値のいずれかを含む場合、true を返し、それ以外の場合、false を返す。
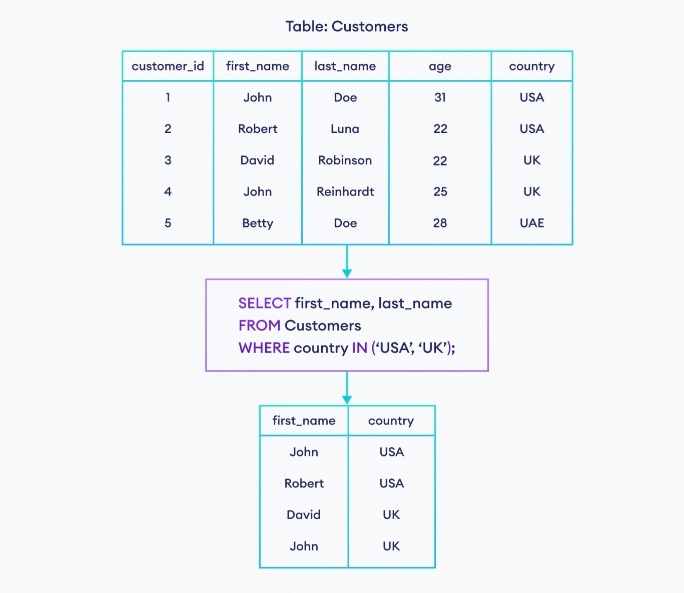
※https://www.programiz.com/sql/in-operator より画像引用
SELECT * FROM products WHERE price IN (100000, 200000);
IN 句は内部的に比較演算子を用いた演算に展開して評価している。
処理の流れ
- 1 行目のレコードについて、WHERE price IN (10000,20000) を評価していく
- 内部にて、WHERE price = 10000 OR price = 20000 に展開される
- それぞれの比較演算が評価され、WHERE 真偽値 OR 真偽値 になる
- この WHERE 句の結果が true であれば、1 行目のレコードを出力する
- 次のレコードへ
IN 句を使用する際の注意点
NULL を IN の候補値に入れることはできない。
SELECT * FROM products WHERE price IN (100000, 200000, NULL);
// 内部的に以下のような不正な演算がおこなわれるため、意味のある出力が得られなくなる
SELECT * FROM products WHERE (price = 100000 OR price = 200000 OR price = NULL);
NOT IN : 「〜の中にない」という条件
指定されたカラムの値が、指定されたリストやサブクエリの結果に含まれていない行を抽出する
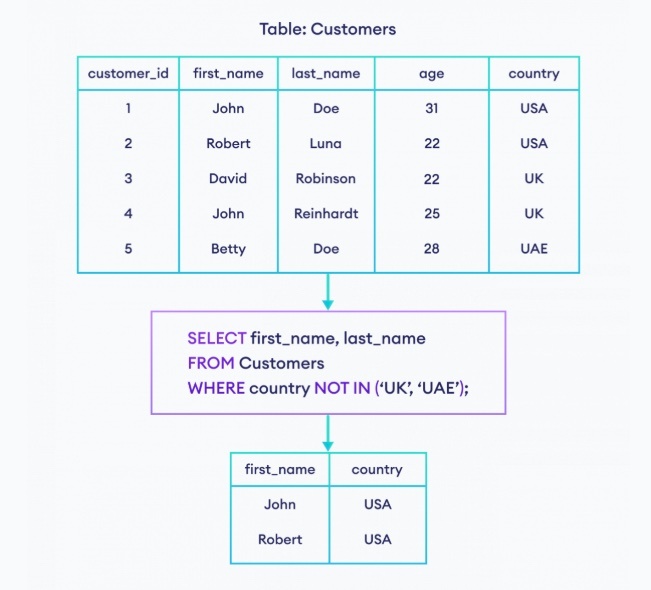
※https://www.programiz.com/sql/in-operator より画像引用
処理の順番としては、まず IN 句が処理される。
その後、IN 句の出力で得られた真偽値と NOT を組み合わせて評価する。
NOT IN においても、候補値に NULL を入れることは推奨されていない。
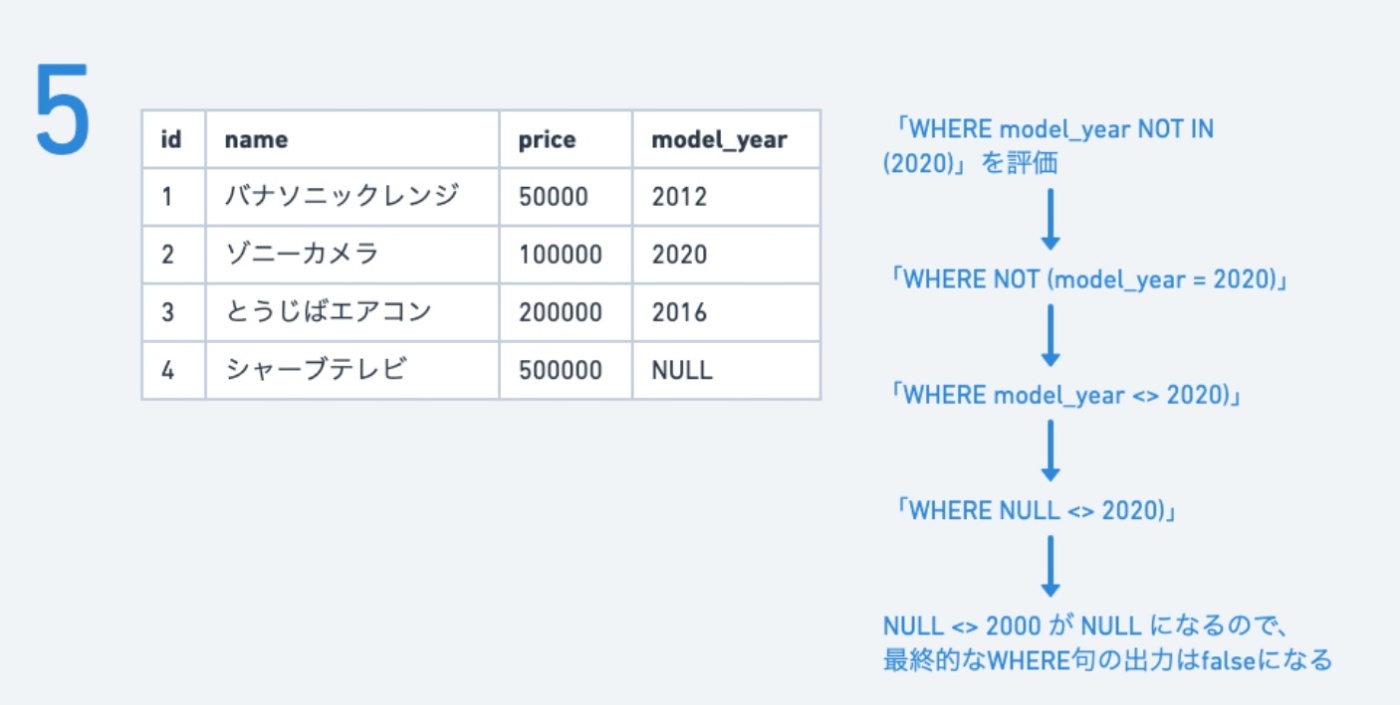
※https://recursionist.io/dashboard/course/6/lesson/1021 より画像引用
・最初に、IN 句を展開していく
・その後、NOT =の形を <> へ変換していく(ド・モルガンの法則)
※NOT(model_year = 2020) → model_year <> 2020 の変換
・一行目から順に処理していき、NULL の行が来た時に、NULL は演算ができないため false になる
論理演算の出力を考える時は、「結果がわからないもの」は NULL になる
NULL = 0
-- NULL
NULL = 123
-- NULL
NULL <> 123
-- NULL
NULL + 123
-- NULL
NULL = NULL
-- NULL
NULL <> NULL
-- NULL
// 論理演算(AND / OR)における「短絡評価(short-circuit evaluation)」 と、NULL の扱い(不確定) が関係している
NULL AND true
-- NULL
-- 左オペランドの NULL が true かどうかがわからないため
NULL AND false
-- false
-- 右オペランドの false で false が確定しているため
NULL OR false
-- NULL
-- 左オペランドの NULL が true かどうかがわからないため
NULL OR true
-- true
-- 右オペランドの true で true が確定しているため
NOT (NULL)
-- NULL
-- 演算できないものの出力は NULL になるため
参照: NULL の扱いについて https://dev.mysql.com/doc/refman/5.6/ja/working-with-null.html)
SQL において、NULL は他の値との比較で true になることはない
SQLでは論理値(Boolean)はTRUE・FALSE・NULL(「不明」や「未定義」)の3種類がある
※NULL AND false
AND 演算は、どちらかが FALSE なら結果は FALSE になる。
→ AND は「両方が TRUE でないと TRUE にならない」ので、右が FALSE の時点で結果は絶対に FALSE
→ つまり、左の NULL はもはや評価する必要がない(短絡評価)
※NULL OR true
OR 演算は、どちらかが TRUE なら結果は TRUE になる。
→ OR は「どちらかが TRUE なら TRUE」なので、右が TRUE の時点で結果は 絶対に TRUE
→ 左の NULL は評価不要(短絡評価)
※短絡評価:最初に答えが確定した時点で、残りを評価しないこと
WHERE 句で指定できる特別な条件
BETWEEN
BETWEEN 句は、指定された二つの値の間に入っている場合、true を返し、それ以外の場合、false を返す。
SELECT * FROM table WHERE カラム名 BETWEEN 値1 AND 値2
// 否定
SELECT * FROM table WHERE カラム名 NOT BETWEEN 値1 AND 値2
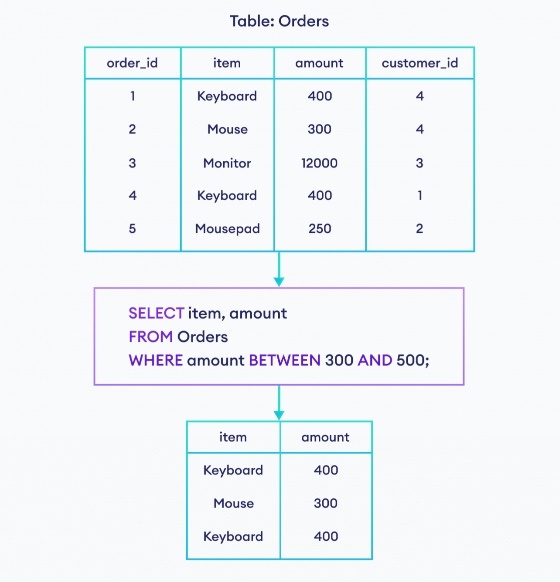
※https://www.programiz.com/sql/between-operator より画像引用
BETWEEN 句の場合、A AND B の A, B を含む点に注意
(例)BETWEEN 100000 AND 200000 は、100000 と 200000 自体を含む
※WHERE 句の中を、100000 <= price <= 200000 と書くことはできない
LIKE
LIKE 句は、指定された文字列が含まれている場合、true を返し、それ以外の場合、false を返す。
LIKE を使用するとき、ワイルドカード(%)と呼ばれるものを一緒に使用する。
ワイルドカードとは、任意の文字列を指定するための特殊な文字記号のこと。
SQL のワイルドカード(%)は、0 文字以上の任意の文字列を指定することができる。これを LIKE と組み合わせることで、部分一致を表現することができる。
例えば、LIKE "pro%" のように記述すれば、「最初は pro で始まり、それ以降はどのような文字列を含んでも良い」という検索の仕方が可能。この時、文字列検索なので、ダブルクオテーション("")で囲む必要がある。
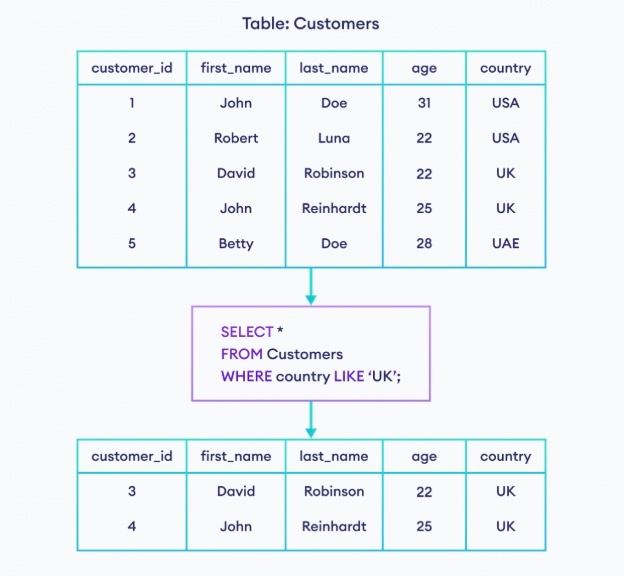
※https://www.programiz.com/sql/like-operator より画像引用
LIKE 句を使った文字列の部分一致検索には全部で 4 種類存在する
① 前方一致
指定された文字列で始まる文字列に一致する場合、true を返し、それ以外の場合、false を返す。
SELECT * FROM products WHERE name LIKE "アル%";
② 後方一致
指定された文字列で終わる文字列に一致する場合、true を返し、それ以外の場合、false を返す。
SELECT * FROM products WHERE name LIKE "%テレビ";
③ 部分一致
指定された文字列が、全体の文字列のどこかに一致する場合、true を返し、それ以外の場合、false を返す。この時、指定された文字列は、全体の文字列の中のどこに含まれていても構わない。
全体の文字列のどこに含まれていても構わないため、先頭、後尾でも検索にヒットする。
SELECT * FROM products WHERE name LIKE "%じば%";
④ 中間一致
指定された文字列が、全体の文字列の内側のどこかに一致する場合、true を返し、それ以外の場合、false を返す。部分一致と似ているが、全体の文字列の内側で一致していなければいけないところが異なりる。つまり、先頭や後尾で一致しているものは検索にヒットしない。
SELECT * FROM products WHERE name LIKE "_%じば%_";
SELECT * FROM products WHERE name LIKE "_%ゾニー%_";
_
任意の一文字を表す特殊記号
_%hoge%_ とすることで、先頭と後尾には任意の一文字が入っていることを意味し、中間一致を検索することができる。
連続して使用すると、その文字数分文字が入っていることを意味する
SELECT * FROM products WHERE name LIKE "ゾニー___";
IS NULL
カラムの値が NULL のレコードを検索する場合は、IS NULL を使用する。
NULL は比較演算子で比較することができません。
SELECT * FROM products WHERE price IS NULL;
IS NOT NULL
カラムの値が NULL でないレコードを検索する場合は、IS NOT NULL を使用する。
SELECT * FROM products WHERE price IS NOT NULL;
データの表示(ORDER/LIMIT)
ORDER
ORDER 句は、データの表示順を指定することができる。
SELECT column_names FROM table WHERE clause ORDER BY column_name ASC LIMIT count;
SELECT column_names FROM table WHERE clause ORDER BY column_name DESC LIMIT count;
SELECT * FROM table_name ORDER BY column_name ASC
// ASC省略可
SELECT * FROM products ORDER BY price;
SELECT * FROM table_name ORDER BY column_name DESC
SELECT * FROM products ORDER BY price ASC;
昇順の場合、NULL は一番最初に表示される。降順の場合は最後に表示される。
また、ORDER 句はデフォルトで昇順となるため、SELECT * FROM products ORDER BY price; のように書くこともできる。
※降順の場合は、DESC を省略することができない
ORDER 句を指定しなかった場合は、実質並び順は不明になる。データベースは極力効率よくデータを取得しようとするので、その時に並んでいる順番をそのまま表示する。
ソートカラムとして、複数のカラムを同時に指定することができる。その場合、先に書いてあるカラムで優先的にソートされ、それが同じだった場合に、後ろのカラムでソートされていく。
ORDER BY 句では、SELECT 句で指定したエイリアス(別名) を使って、並び替えの基準となるカラムや式を参照することができる
GROUP BY 句では、カラム名を直接指定するだけでなく、式 を記述することも可能なため、カラムを限定した上で文字列連結を行なうことも可能
(例)year ||'-'|| month
LIMIT
LIMIT 句は、表示するレコード数を指定することができる。
LIMIT offset, count
・offset: 結果セットの先頭からスキップする行数を指定する
・count: 取得する行数を指定する
※offset は省略可能。省略した場合、取得する行数を指定する
※DBMSによる書き方の違い例
・MySQL: LIMIT スキップする行数, 取得する行数
・PostgreSQL: LIMIT 取得する行数 OFFSET スキップする行数
例えば、3 つのレコードだけを表示したい場合は、LIMIT 3 と指定できる。この時取り出されるデータは、ORDER 句によって決められた順番の上から順になっている。
SELECT * FROM users ORDER BY age ASC LIMIT 3;
「データの抽出(SELECT, FROM, WHERE)→ データの表示(ORDER, LIMIT)」のプロセスがあることを意識しよう。
SELECT, FROM, WHERE でレコードを絞り込んだ後、ORDER BY で並び替えを行い、LIMIT で指定したレコード数を表示するという順番。
データの作成(INSERT)
INSERT INTO table_name (column_name1, column_name2, ...) VALUES (value1, value2, ...);
// 複数行のレコードの追加
INSERT INTO table_name (column_name1, column_name2, ...) VALUES (value1, value2, ...), (value3, value4, ...);
// カラム名を省略: テーブルに存在する全カラムに対して値を入れる場合
INSERT INTO table_name VALUES (value1, value2, ...);
// テーブルに存在する一部のカラムに、デフォルト値を入れたい場合
INSERT INTO table_name VALUES (value1, default, value2, ...);
データの更新(UPDATE)
UPDATE table_name SET column_name=value WHERE clause;
もし WHERE を記述しなければ、テーブルに存在するすべてのレコードを指定された値で更新することになる。特定のレコードだけを更新したい場合は、WHERE でレコードを絞り込むようにしよう。
データの削除(DELETE)
DELETE FROM table_name WHERE clause;
もし WHERE を記述しなければ、テーブルに存在するすべてのレコードを削除することになる。
特定のレコードだけを削除したい場合は、WHERE でレコードを絞り込むようにしよう。
また、テーブルの全データを削除する場合、DELETE FROM table_name; 以外に、DDL である TRUNCATE TABLE table_name; を使用することもできる。
DELETEとTRUNCATEの違い
・DELETE は一行ずつデータを削除していくため、データ数が増えると TRUNCATE よりも削除に時間がかかる。
・TRUNCATE でデータを削除した場合、AUTO_INCREMENT 値はその開始値にリセットされるが、DELETE で削除した場合は削除前の状態から続けて採番される。
SQL 標準では、日付や時刻のリテラルはシングルクォート ' で囲むことが推奨されている
トランザクション対応データベースの重要な特性(ACID特性)
トランザクションを正しく処理するために、トランザクション対応データベースは一般的にACID特性と呼ばれる性質を持つ。
Atomicity(原子性)
トランザクション内のすべての操作は、不可分な1つの単位として扱われる。
すべて成功するか、すべて失敗するかのどちらかであり、中途半端な状態にはなりません。
Consistency(一貫性)
トランザクションの開始時と終了時で、データベースは定義された整合性制約(例えば、NOT NULL制約、UNIQUE制約、参照整合性制約など)を満たした正しい状態を保つ。
Isolation(独立性、隔離性)
複数のトランザクションが同時に実行されても、それぞれのトランザクションは互いに干渉せず、あたかも単独で実行されているかのように振る舞う。これにより、データの矛盾を防ぐ。
Durability(永続性)
一度コミットされたトランザクションの結果は、その後のシステム障害などが発生しても失われることなく、永続的にデータベースに保存される。
代表的なトランザクション対応データベース:
・MySQL
・PostgreSQL
・Oracle Database
・SQL Server
・DB2
集計関数(aggregate function)
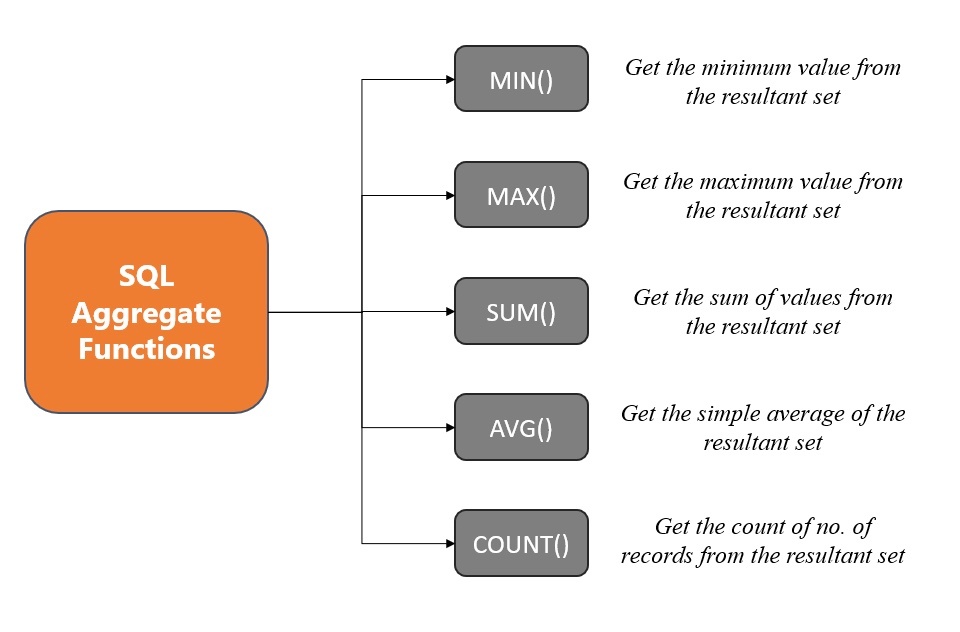
※https://www.geeksforgeeks.org/sqlalchemy-aggregate-functions/ より画像引用
値の集まりに対して計算を実行し、1 つの値を返す DBMS 組み込みの関数のこと
集計関数を用いると、column_name に指定したカラムの集計結果を取得することができる。下図の表の「値の集まり」とは、特定の列(カラム)の値の集まりのことを指す。
MySQLの集計関数
| 集計関数 | 戻り値 |
|---|---|
| MAX(column_name) | 値の集まりの中で最大値を返す |
| MIN(column_name) | 値の集まりの中で最小値を返す |
| AVG(column_name) | 値の集まりの平均値を返す |
| SUM(column_name) | 値の集まりの合計値を返す |
| COUNT(column_name or *) | 値の集まりの個数を返す |
※Count(*) を除いて NULL 値は無視される
// age カラムの最大値の取得
SELECT MAX(age) FROM users;
// age カラムの最小値の取得
SELECT MIN(age) FROM users;
// age カラムから平均値を取得
SELECT AVG(age) FROM users;
※NULL値はカウントされない。
// age カラムの合計値を取得
SELECT SUM(age) FROM users;
// 全行数を取得
SELECT COUNT(*) FROM users;
// column_name の値が NULL ではない行数を取得
SELECT COUNT(column_name) FROM users;
// users テーブルの nickname カラムが NULL ではない行数を取得
SELECT COUNT(nickname) FROM users;
COUNT は、値の集まりの行数を返す集計関数。
SUM との違いは、SUM は特定のカラムの合計値を返すのに対して、COUNT は単に行数を返す。
また、COUNT には二種類の使い方がある。
特定の条件下で集計したい場合は、集計関数と WHERE 句と組み合わせて使用する
// 東京都に住んでいる方の平均年齢を取得
SELECT prefecture, AVG(age) FROM users WHERE prefecture = '東京都';
表示カラム名も指定することができる。これは表示カラムを指定する SELECT 句で行なう。
集計関数のように関数名がそのまま表示カラム名として表示される場合は特に使用する。
SELECT column_name AS display_name FROM table_name;
カラム名を指定することで、それぞれの可読性が向上し、正しい名称でバックエンドサーバへデータを受け渡すことができるようになる。
※バックエンドサーバとは、一般的には、データベースと通信してデータの処理を行うサーバを指す。データベースと通信する際に、正しい名前でバックエンドサーバへデータを受け渡すことは重要。
mysqld はプログラム(実行ファイル)
実行ファイル
mysqld は、コンピューター上で実行できる形式のファイル。
このファイルを実行することで、MySQL サーバーの機能が起動する。
デーモンプロセス
起動すると、通常はバックグラウンドで動作する「デーモンプロセス」となる。これは、ユーザーが直接操作するのではなく、システムが裏で動かし続けるプログラムのこと。
関連ファイル
mysqld 以外にも、MySQL は設定ファイル(my.cnf など)や、データベースの実体ファイルなど、多くのファイルを利用する。しかし、mysqld 自体はこれらのファイルを管理・操作する側のプログラム。
GROUP BY
各レコードをグループ化し、各グループごとに集計関数を実行する
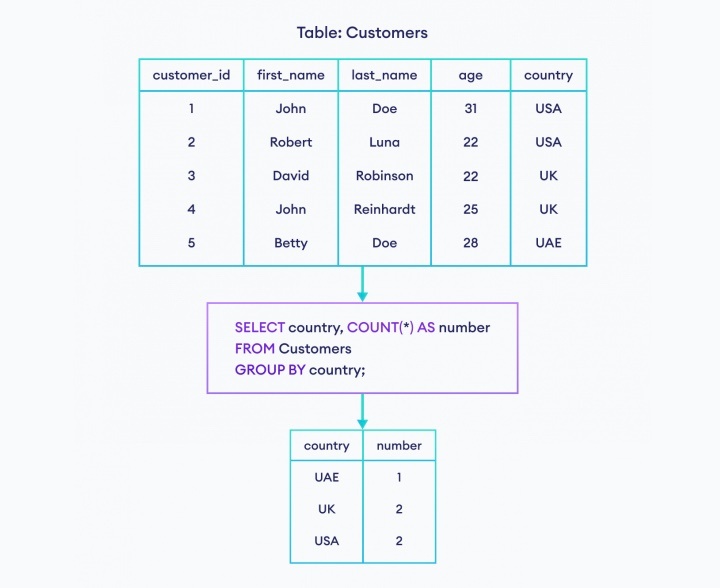
※https://www.programiz.com/sql/group-by より画像引用
SELECT prefecture AS 都道府県, AVG(age) AS 平均年齢 FROM users GROUP BY prefecture;
// WHERE 句と組み合わせ
SELECT prefecture AS 都道府県, AVG(age) AS 平均年齢 FROM users WHERE prefecture IN ('大阪府', '東京都') GROUP BY prefecture;
可読性を意識した記述
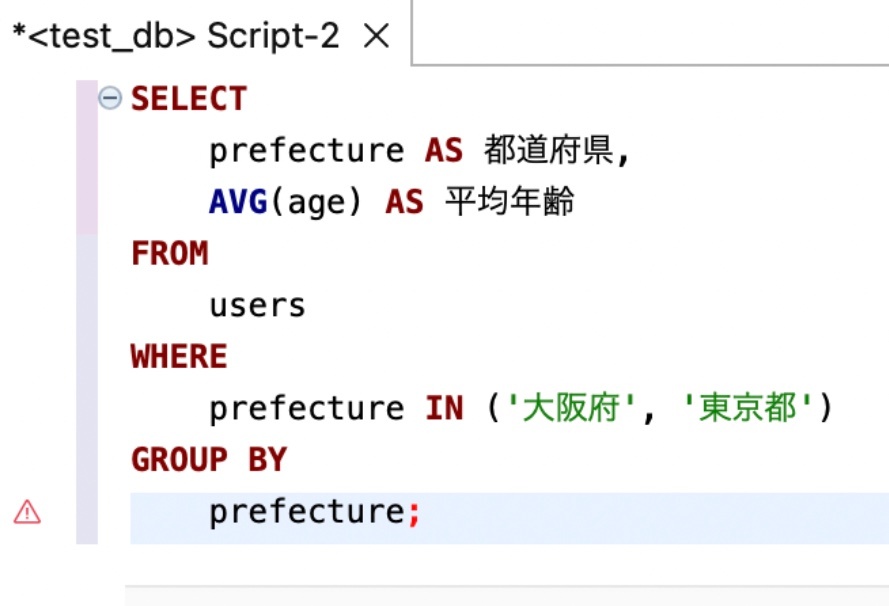
処理順 例
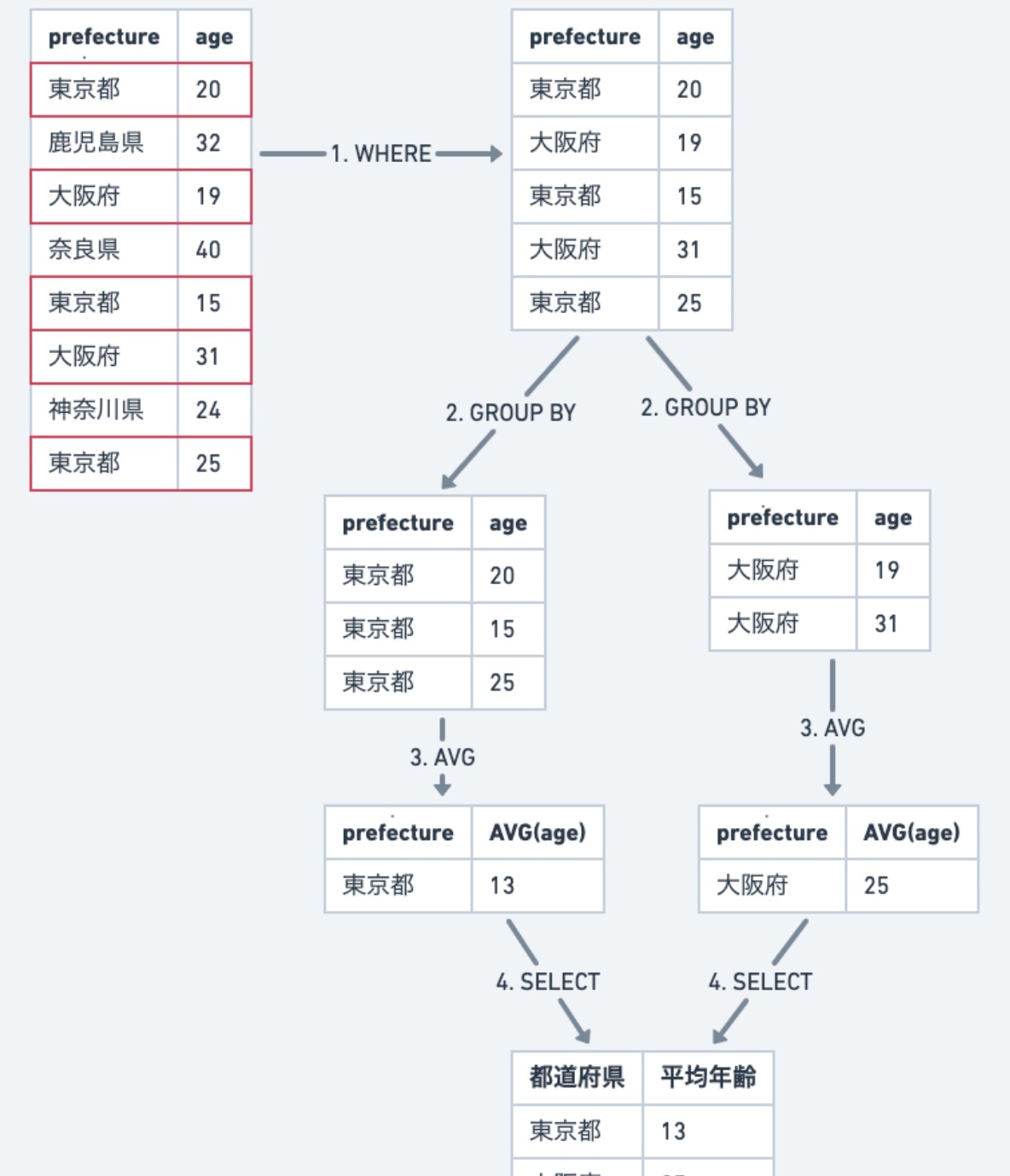
※https://recursionist.io/dashboard/course/6/lesson/1046 より画像引用
① WHERE 句で、大阪府、東京都のレコードだけに絞り込む。
② 残ったレコードを、都道府県ごとにグループ化する。
③ 各グループで、年齢の平均値を取得する。
④ SELECT 句で各グループのレコードをまとめて表示する。
SQLでは、GROUP BY でまとめた単位ごとに集計されるため、SELECTに書かれている全ての「集計関数でない列」は GROUP BY に含めないと、その列の値をグループの中でどう扱うか決められない(例:どれ選ぶの?)。その結果、結果が曖昧になりエラーになってしまうというルールがある。
→ カラム内で重複するデータが出てくる
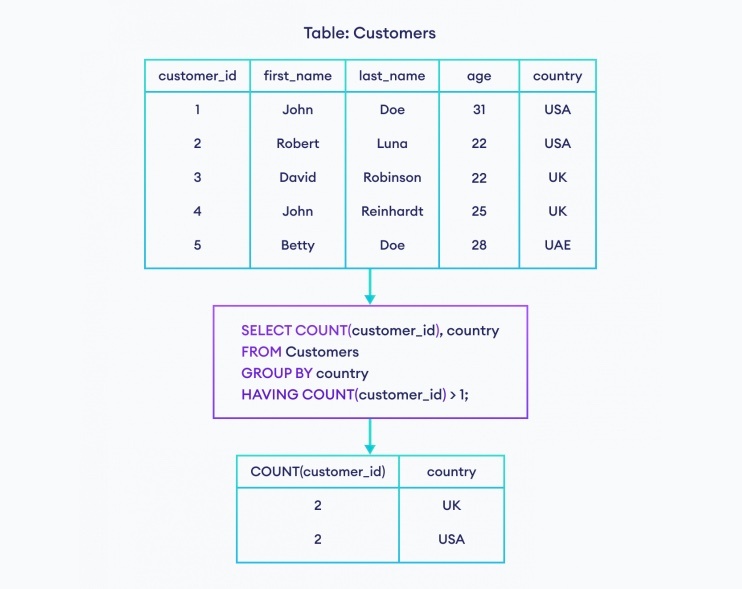
HAVING
HAVING は、GROUP BY でグループ化した後のそれぞれの仮想テーブルに対して、絞り込みを実行する。
グループ化された後の各仮想テーブルに対して絞り込みを行ないたい場合に使用する。
※https://www.programiz.com/sql/having より画像引用
絞り込みであれば、WHERE 句でも同じことをできそうな気がするが、実行順序によってはHAVING 句でしか得ることができない。
SELECT prefecture AS 都道府県, AVG(age) AS 平均年齢 FROM users WHERE prefecture IN ('大阪府', '東京都') GROUP BY prefecture HAVING AVG(age) <= 20;
※HAVING 句を使えば、AVG の処理を実施した後に、絞り込みを実施することができる。
CASE
SELECT
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
...
ELSE else_result
END
FROM テーブル名;
CASE 式は、SELECT ステートメントの列リスト、WHERE 句の条件、ORDER BY 句のソートキー、GROUP BY 句のグループ化キーなど、SQLの様々な場所で使用できる。
SELECT
product_name,
category,
CASE category
WHEN 'Electronics' THEN '電化製品'
WHEN 'Books' THEN '書籍'
WHEN 'Clothing' THEN '衣類'
ELSE 'その他'
END AS category_jp
FROM products;
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE else_result
END
SELECT
product_name,
price,
CASE
WHEN price < 100 THEN '低価格'
WHEN price >= 100 AND price < 500 THEN '中価格'
WHEN price >= 500 THEN '高価格'
ELSE '不明'
END AS price_range
FROM products;
SQLiteでは、|| は主に文字列の連結演算子として機能する
→ SELECT 句のカラムの値を操作する際や、CASE 式の THEN 句や ELSE 句で値を生成する際には、|| は 文字列連結 の意味を持つ
SELECT column1 || ' - ' || column2 AS combined_value FROM table;
SELECT
..., -- 他の必要なカラム
stock_year || '-' ||
CASE
WHEN stock_month < 10 THEN '0' || stock_month
ELSE CAST(stock_month AS TEXT)
END AS stock_year_month,
... -- 他の必要なカラム
FROM your_table;
UNION
複数の SELECT ステートメントからの結果を 1 つの結果セットに結合するために使用される。
UNION はテーブルの対象カラムを指定して、行 を他のテーブルの行とまとめて一つの結果セットにするためのもの。
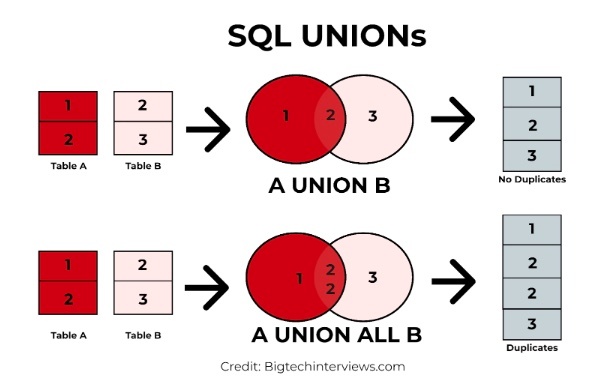
※https://bigtechinterviews.com/sql-union-vs-union-all/ より画像引用
SELECT column_name FROM table_name UNION SELECT column_name FROM table_name (UNION ...);
UNION は、3 つ以上の SELECT ステートメントをつなぐこともできる。最初の SELECT ステートメントからのカラム名が、返される結果のカラム名として使用される。
各 SELECT ステートメントの対応する列は、必ずしも同じ名前のカラムを使用する必要はないが、これらのデータ型は同じになるようにすること。出力カラムにエイリアスを付ける場合は、同じエイリアス名にすること。
UNION を使用する主なルール
結合する複数の SELECT ステートメントが、
・同じ数のカラム を持っている
・対応するカラムが 互換性のあるデータ型 である
・(UNION ALL の場合は必須ではないが)通常は 同じ順序 でカラムが定義されている
カラムを指定して「横に」結合する のであれば、JOIN 句(INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN など)を使用する。
JOIN は、指定された結合条件に基づいて、複数のテーブルの関連する行を組み合わせて新しいカラムを持つ単一の行を作成する。
UNION ALL
複数の SELECT ステートメントからの結果を 1 つの結果セットに結合するために使用される。
UNION ALL は出力結果に重複があってもそのまま出力する
※UNION は出力結果に重複があった場合に重複を削ぎ落として出力する
UNION と UNION ALLの違い
重複を残すか残さないかという違い
加えて重要なのは、UNION の重複排除が内部でどのように行われているのかということ。
重複排除の大まかな流れ
① レコードをソートする。昇順または降順に並び替える。
② 隣り合うレコードで値が重複するレコードが存在した場合、それを排除する。
レコードのソートがクエリ実行時のコストになり、処理速度に大きく影響することがある。
そのため、UNION や UNION ALL は、重複排除を行なう重要性と処理速度を天秤にかけて、どちらを優先するかを考えた上で使用すること。
テーブルの結合
SQL は、リレーショナルデータベースと呼ばれるデータベースシステムを使って、データを集合として取り扱い、その集合やその要素に対して様々な処理をする言語。
※https://stackoverflow.com/questions/46040256/combine-two-tables-in-one-table-with-sql より画像引用
結合は、複数の集合(テーブル)に関係を持たせ、新しい要素の集合を作るために使用する。
異なるテーブルに存在するカラムを一つのテーブルとして出力したい場合に、結合を行なう。
つまり、結合とは、複数のテーブルに関係を持たせて一つのテーブルとして出力することを意味する。
※CONCAT() は、MySQL で使用できる関数、引数に文字列をとり、それらを連結する。
結合は、主テーブル(駆動表(外部表)とも呼ばれる)と、結合先テーブル(内部表とも呼ばれる)で行われる。
駆動表(driving table)
先に読み込まれ、ループの外側で使われる表。ループの「基準」になる表。
内部表(inner table)
駆動表の1行に対して参照される、ループの内側で参照される表。
SQLでは普通、FROMの左側の表が駆動表になることが多い。
ただし、RDBMSによってはオプティマイザ(最適化エンジン)がテーブルのサイズやインデックスの有無を見て、最適な順序に自動的に変えることもある。
・小さいテーブルを駆動表にした方が速いことが多い
・インデックスの有無により、内部表の検索速度が大きく左右される
SELECT column_name FROM table1 JOIN table2 ON table1.id = table2.table1_id;
この SQL で言えば、駆動表は table1 で、内部表は table2 になる。
ON 句には結合条件を記述する。この SQL で言えば、table1 の id カラムの値と、table2 の table1_id カラムの値が等しいレコードを結合する。
MySQL で結合時に採用されているアルゴリズムに、nested loop join というアルゴリズムがある。
nested loop join では以下の手順で結合が行われます。
- 駆動表のレコードを 1 行取り出す
- 取り出したレコードと結合可能なレコードを内部表から検索する
結合の処理速度のボトルネックになるのが、2 の処理。もし内部表の結合条件に使用しているカラムにインデックスが貼られていない場合、内部表をフルスキャンする必要がある。これは、内部表のデータ量が多くなると致命的になる。結合カラムにはインデックスを貼るようにすること。
※フルスキャン:テーブルの全レコードを検索すること
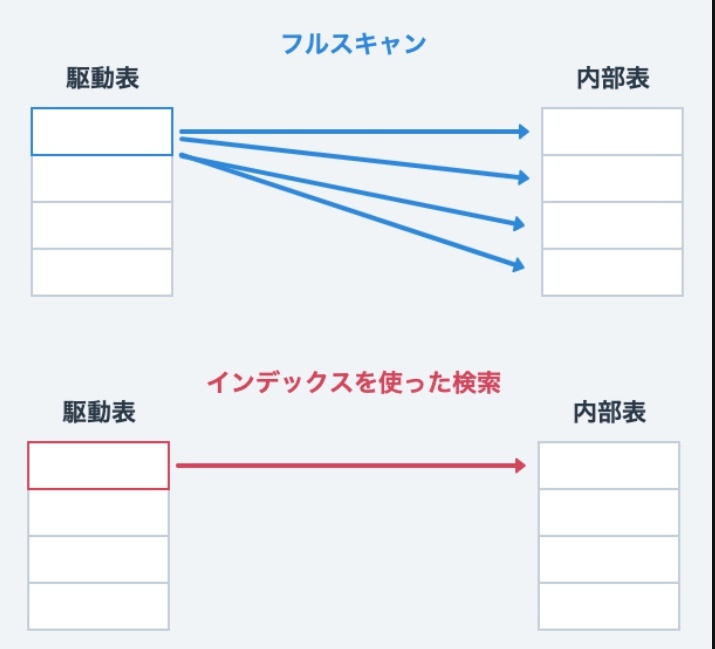
※https://recursionist.io/dashboard/course/6/lesson/1055 より画像引用
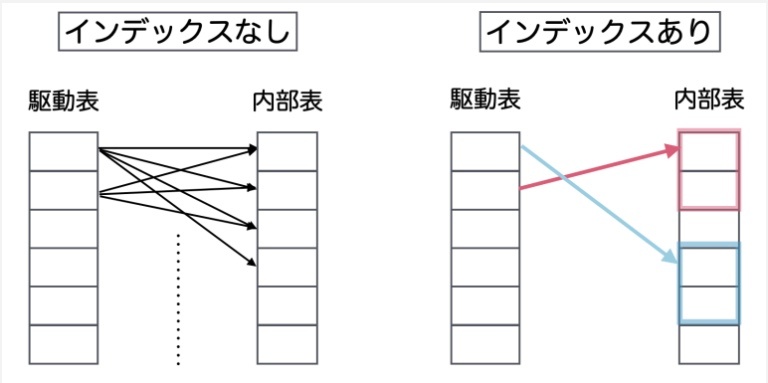
※https://nishinatoshiharu.com/overview-nested-loopjoin/ より画像引用
// 1.
SELECT books.id AS 本ID, books.name AS 本タイトル, CONCAT(authors.family_name, ' ', authors.first_name) AS 著者名 FROM books INNER JOIN authors ON authors.id = books.author_id;
// 2.
SELECT books.id AS 本ID, books.name AS 本タイトル, CONCAT(authors.family_name, ' ', authors.first_name) AS 著者名 FROM books JOIN authors ON authors.id = books.author_id;
// 3. テーブル名にもカラム名と同様に AS を使ってエイリアスを付けることができる(結果は同じ)
SELECT b.id AS 本ID, b.name AS 本タイトル, CONCAT(a.family_name, ' ', a.first_name) AS 著者名 FROM books AS b JOIN authors AS a ON a.id = b.author_id;
// 4. AS は省略することができる
SELECT b.id 本ID, b.name 本タイトル, CONCAT(a.family_name, ' ', a.first_name) 著者名 FROM books b JOIN authors a ON a.id = b.author_id;
テーブル名のエイリアスは、最初の一文字で表すことが多いが、複数のテーブルで同じ文字になる場合や一文字だけでは明らかではない場合は、もう少し明確な名前を付けることが推奨される
結合の種類
・内部結合
・外部結合
→ 左外部結合
→ 右外部結合
→ 完全外部結合
・クロス結合
内部結合(inner join)
※https://amg-solution.jp/blog/26287 より画像引用
結合の中でも、内部表から結合先のレコードが見つかった駆動表のレコードのみを出力テーブルに表示する結合方法
・内部結合では結合先がない駆動表のレコードは、出力テーブルから消える
・内部結合を含む全ての結合は、結合先が複数存在する場合、駆動表のレコードは分裂して、内部表のレコードを結合する
結合先が見つからなかった駆動表のレコードは消えてしまうというのは内部結合独特の動きなので注意
INNER JOINイメージ
INNER JOIN:結合するテーブルデータの中で、結合条件に示したデータ項目(カラム)の値が一致するデータのみを結合する方法
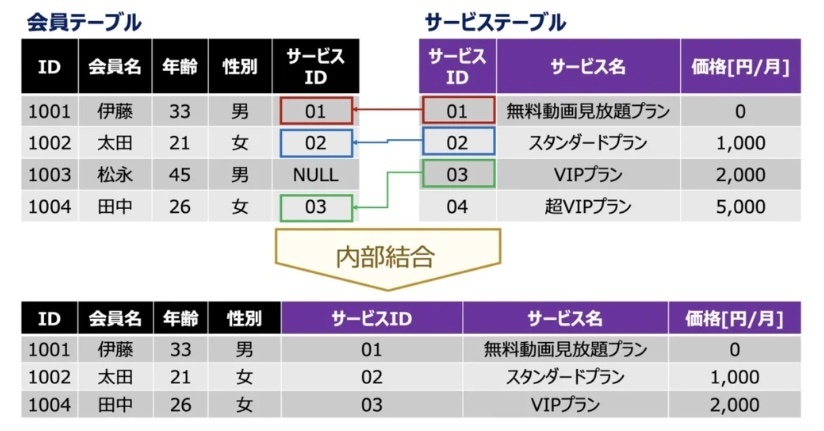
※https://di-acc2.com/system/database/14325/ より画像引用
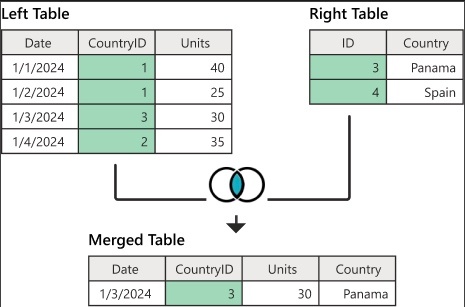
※https://learn.microsoft.com/ja-jp/power-query/merge-queries-inner より画像引用
外部結合(outer join)
結合の中でも、結合先のレコードが見つからない場合も結合元のレコードを残す結合のこと。
外部結合では、駆動表と内部表の交わる領域以外も抽出する。
左外部結合(left outer join)
駆動表のデータを全て残す外部結合方法
駆動表のレコードは全て残る。
なお、結合先のレコードがない場合、内部表の部分のデータは全て NULL 値として結合される。
https://communities.gainsight.com/ルールエンジンとデータ管理-273/rule-engineのjoin-typeについて-15431 より画像引用
右外部結合(right outer join)
左外部結合と同様、駆動表のデータを全て残す外部結合方法
左外部結合との違いは、駆動表が JOIN 句で指定するテーブル(図でいうと右側の集合)になるという点
※https://recursionist.io/dashboard/course/6/lesson/1057 より画像引用
RIGHT OUTER JOIN の挙動は、LEFT OUTER JOIN と非常に似ており、異なる点は、駆動表がどちらになるのかという点のみになる。
全てのレコードを残したいテーブルの方を駆動表として指定しよう
完全外部結合(full outer join)
結合する両テーブルについて、その結合先が見つからなかったレコードも残す、LEFT OUTER JOIN と RIGHT OUTER JOIN を組み合わせたような結合
※https://recursionist.io/dashboard/course/6/lesson/1058 より画像引用
※MySQL には、FULL OUTER JOIN という文法は用意されていない。そのため、UNION を使用することで FULL OUTER JOIN と同じ挙動を実現する
結合する両テーブルのレコードを全て残したい場合は、FULL OUTER JOIN を使用する
駆動表としてテーブルを「確実に」使いたい場合の方法
① FROM 句の先頭に書く
通常、最初に指定されたテーブルが駆動表になる(特に INNER JOIN の場合)
② RIGHT OUTER JOIN を使う
JOIN の右側にあるテーブルが駆動表になる(特に LEFT / RIGHT JOIN の場合)
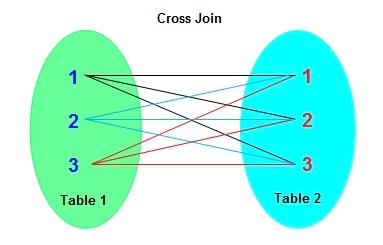
【1. テーブルの結合はどう動く?】
テーブルの結合は「駆動表」と「内部表」を使って行の組み合わせを作る処理。
JOINの種類(INNER, LEFT, RIGHT, FULL)によって少しずつ異なるが、基本は以下の3つのアルゴリズムのどれかが使われる
① ネストループ結合(Nested Loop Join)
最も単純な方法。2つのテーブルのすべての組み合わせを1つずつチェック。
駆動表(外側)の各行について、内部表(内側)を全探索して一致するか調べる。
※https://cs186berkeley.net/notes/note9/ より画像引用
イメージ:Aの各行 → B全体をループ
遅いが、小規模データには有効。
② マージ結合(Merge Join)
両方のテーブルをソート済みである前提で、一致を高速に探す。
イメージは「2本の並んだ電車の窓から同じ駅を探す」ような処理。
※https://bertwagner.com/posts/visualizing-merge-join-internals-and-understanding-their-implications/ より画像引用
大量データに強い。
インデックスやORDER BYがあると効果的。
マージ結合(Merge Join)の分かりやすい例え(2つの名簿を使ったペア探し)
・名簿A(たとえば社員番号の昇順に並んだリスト)
・名簿B(同じく社員番号の昇順に並んだリスト)
この2つの名簿を見比べて、「同じ社員番号があるかどうか」を探したい。
マージ結合ではこんな処理をする
・両方のリストの先頭を見る。
・小さい方を進める。
・値が一致したらペアとして取り出す。
・最後までこれを繰り返す。
(例)
名簿A:101, 103, 105, 110
名簿B:102, 103, 104, 105, 120
(操作イメージ)
| 名簿A | 名簿B | 比較結果 |
|---|---|---|
| 101 | 102 | 101 < 102 → A進める |
| 103 | 102 | 103 > 102 → B進める |
| 103 | 103 | 一致!保存! |
| 105 | 104 | 105 > 104 → B進める |
| 105 | 105 | 一致!保存! |
| 110 | 120 | 110 < 120 → A進める |
| — | — | A終了、終了! |
両方がソートされていれば非常に効率的に結合できる
③ ハッシュ結合(Hash Join)
内部表をメモリ上のハッシュテーブルに変換。
駆動表から取り出したキーで、ハッシュテーブルを高速に検索。
ソートしなくても速く結合できる
小さいテーブルをハッシュテーブルに変換して、大きいテーブルと照合することで高速に結合
※https://www.ashisuto.co.jp/db_blog/article/exadata-tuning-with-hash-join.html より画像引用
大規模な結合にとても強い
一時的にメモリ(またはディスク)を使ってハッシュ表を作るので、メモリが重要
全体の流れ(ハッシュ結合)
- 小さい方のテーブルでハッシュテーブルを構築
- 大きいテーブルをスキャン
ハッシュ関数は同じでなければならない(でないと同じ値が異なるハッシュになって一致しない)
ハッシュ値が一致しても、中身のキーの値(A.key = B.key)が本当に一致しているか確認(これが「ハッシュ衝突」の場合の対策)
・小さい方をハッシュテーブルにすると メモリ効率が良い(RAMに乗りやすい)
・大きい方は全件スキャンする必要があるが、高速なハッシュアクセスで結合先を絞れる
ハッシュ結合(Hash Join)では、ハッシュ関数で使用されるアルゴリズムは結合の両側(小さいテーブルと大きいテーブル)で同じものがDBMSによって自動的に使われる。
※結合条件の データ型に応じた最適なハッシュ関数が内部的に自動選択される
※衝突したデータを順番に格納できるように、値を格納する側は「配列」「連結リスト」などの形になっている。
【2. インデックスの仕組み】
テーブルの特定のカラムに対して作る「検索の高速化用の目次(索引)」。
指定したカラムに対してインデックスが自動で作られる
→ データベースは裏側で自動的にインデックスを作成する
| カラム名 | 制約 | 自動で作られるインデックス名 | 対象カラム |
|---|---|---|---|
| id | PRIMARY KEY |
sqlite_autoindex_users_1(例) |
id |
| UNIQUE |
sqlite_autoindex_users_2(例) |
email |
B-tree構造(二分木)で作られるのが一般的
テーブルに比べて軽量かつソート済み
検索や結合条件のWHERE句やON句に使われると効果を発揮する
付与方法(SQL)
CREATE INDEX idx_players_team_id ON players(team_id);
自動的に作られる場合(例:PRIMARY KEY や UNIQUE)もある。
【3. メモリとの関係】
インデックスと結合処理がどれだけメモリを使うかは重要
| 処理 | メモリとの関係 |
|---|---|
| ハッシュ結合(Hash Join) | ハッシュテーブルをメモリ上に作成 |
| ソート処理(Merge Join等) | 両テーブルをソート済みにするため一時領域を使用 |
| インデックスアクセス | インデックス自体はメモリにキャッシュされることが多い |
| ディスクI/O | メモリ不足時はスワップやテンポラリ領域が使われる |
インデックスは「テーブルとは別の構造」として管理されている
RDBMSが内部的に別のデータ構造として保持
テーブルの各行とは別に、インデックス専用のデータ構造(例:Bツリー)が作られる。
インデックスは通常、ディスク上の専用の領域に保存される
データベースファイル内で管理されるが、テーブルとは別管理
| RDBMS | インデックスの保存場所・方法 |
|---|---|
| PostgreSQL | インデックスはテーブルとは別のファイルに保存される(例:base/ディレクトリ以下にOIDで管理) |
| MySQL (InnoDB) | テーブルと同じ.ibdファイルに共存(または共有テーブルスペース) |
| SQLite | 単一の.dbファイルの中にテーブル・インデックスの両方が詰まっている |
| Oracle | テーブルスペースに分けて保存(表領域の管理) |
メモリとの関係
インデックスはディスクに保存されるが、検索時に使う部分だけがメモリにキャッシュされるようになっている(バッファプールなど)。
サブクエリ(subquery)
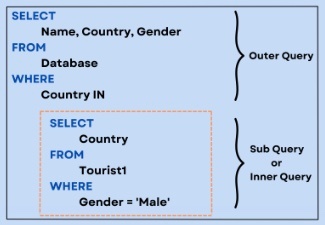
※https://www.boardinfinity.com/blog/subquery-in-sql/ より画像引用
SQL ではクエリ結果(仮想テーブル)を次の入力テーブルとすることができる。この時、クエリ結果を入力クエリとして使う外側のクエリをメインクエリ、クエリ結果を得るための内側のクエリをサブクエリ(subquery)と呼ぶ。
サブクエリは、括弧を使って記述でき、メインクエリとサブクエリを入れ子(ネスト)にできる。
また、サブクエリは JOIN 句と一緒に使用されることが多い。
サブクエリを含むクエリは、サブクエリ→メインクエリの順序で処理される。
「クエリを二階構造にする」という手段を提供する文法がサブクエリ。
しかし、サブクエリはパフォーマンスを下げる要因になることが多いため、積極的に使用することは避けること。実際サブクエリを使用しなくても、結合など他の文法を使っても同じ結果が得られ、さらにパフォーマンスも良いことも少なくない。
サブクエリでないと出力できない形式であったり、パフォーマンスチューニングを施しながら作成したサブクエリであれば、使用しても良い。特定の文法だけを使用せず、それぞれの文法の得意なことや不得意なことを理解し、適材適所の使用を心がけよう。
WITH
MySQL8.0 から導入された新しい文法。
他の DBMS には既に実装されている機能だったが、MySQL にも WITH 句が導入された。
WITH を使用すると、サブクエリにエイリアスをつけることができる。サブクエリはクエリが入れ子になるため、クエリ全体が長くなってしまい、可読性が落ちてしまうことが懸念される。
そこで、WITH でサブクエリにエイリアスを付けることで、そのエイリアス名を使用してメインクエリを簡潔に書くことができるようになる。
共通テーブル式:Common Table Expression / CTE
サブクエリに書いていたものを、先に名前付きで定義しておき、あとで使い回すための構文
WITH alias AS (Query);
ステートメントを本体のクエリの直前に書くことで、本体のクエリでエイリアスを使用することができる。
カラム名やテーブル名のエイリアスを付ける際は、AS を省略できたが、WITH 句では AS は省略できない点が注意。
長いサブクエリを使用する際は積極的に WITH 句を使用するようにしよう
→ メインクエリを簡潔に記述することができ、可読性が上がる
正確なデータ操作
正確なデータ操作を脅かすもの
安全で確実なデータ操作・データ管理は超重要
DBMSが正しく処理を完了しなかったり、テーブル内のデータがおかしな値になってしまったりする可能性はある。
トランザクション(transaction)
DBMSが管理するデータに不具合が発生することは許されない。
DBMSには、問題が起きないようにするための仕組みが備わっている。
データベースにおいて一連の処理をまとめて1つの単位として扱う仕組みのこと。
DBMSに対して複数のSQLを送る場合に、1つ以上のSQL文をひとかたまりとして扱うよう指示することができる(トランザクション制御 transaction control)。
これにより、処理全体が成功するか、あるいは失敗して元に戻るかのどちらかになり、データの整合性が保たれます。
※ https://well-field.co.jp/services/education/web-text/sql-mysql/sql-v28 より画像引用

◎DBMSによるトランザクション制御(1)
- トランザクションの途中で、処理が中断されないようにする
- トランザクションの途中に、他の人の処理が割り込めないようにする
コミットとロールバック
トランザクションの中断
振り込み処理の例
振り込み処理を実現するために必要なこと
① 振込元の口座残高を減らす
② 振込先の口座残高を増やす
ここで、①が完了したあと、異常停止によって処理が中断してしまうと、振込元の口座残高が減るだけで、振込先のお金が増えない事態になってしまう。
2つのUPDATE文を1つのトランザクションとして扱うようにDBMSに指示することで、この問題を解決することができる。
DBMSは、どんな非常時であっても、トランザクションを「一部だけが実行されることはあってはならない、途中で分割不可能なもの」として取り扱う
◎DBMSによるトランザクション制御(2)
DBMSは、トランザクションに含まれるすべてのSQL文について、必ず
「すべての実行が完了している」または「1つも実行されていない」のどちらかの状態になるように制御する
原始性(atomicity)
トランザクションに含まれる複数のSQL文が、DBMSによって不可分なものとして扱われる性質のこと。
トランザクションは、複数のSQL文(例:UPDATEやINSERT)をひとまとめにした論理的な処理単位です。この単位を不可分(分割できない、すべて実行されるか、あるいは何も実行されないかのどちらか)として扱う性質が原子性です。
原始性確保の仕組み
コミット(commit)
トランザクション中のSQL文によってテーブルのデータが書き換えられると、それは確定ではなく仮のものとして管理される。
そして、トランザクションが終了する際に、これらの「仮の書き換え」をすべて確定したことにする。
※ https://well-field.co.jp/services/education/web-text/sql-mysql/sql-v28 より画像引用

ロールバック(rollback)
トランザクション中に異常が発生して中断した場合、DBMSはそれまで行なったすべての仮の書き換えをキャンセルして、「なかったこと」にする動作。
トランザクション内のそれまでの変更をすべて取り消し、トランザクションが開始される前の状態にデータベースを戻す処理のことを指します。
※ https://well-field.co.jp/services/education/web-text/sql-mysql/sql-v28 より画像引用

SQL文のエラーで失敗したり、明示的にキャンセルが指示された場合などに行われる。
電源が落ちて突然処理が中断した場合も、再びデータベースを起動した際に自動的にロールバックが行われる。
トランザクションの指定方法
DBMSにどの範囲が1つのトランザクションであるかを伝えることで制御される。
トランザクションを使うための指示
-
BEGIN:開始の指示
この指示以降のSQL文を1つのトランザクションとする。 -
COMMIT:終了の指示
この指示までを1つのトランザクションとし、変更を確定する。 -
ROLLBACK:終了の指示
この指示までを1つのトランザクションとし、変更の取り消しをする。
BEGIN;
-- 処理1: アーカイブテーブルへコピー
INSERT INTO 家計簿アーカイブ
SELECT *
FROM 家計簿
WHERE 日付 <= '2024-01-31';
-- 処理2: 家計簿テーブルから削除
DELETE FROM 家計簿
WHERE 日付 <= '2024-01-31';
COMMIT;
これにより、処理1と処理2を不可分なものとして扱う
仮に、処理1の後に障害が発生した場合、自動的にロールバックが行われ、処理1の実行が取り消される。
自動コミットモードの解除
自動コミットモード(auto commit mode)
通常、トランザクションはBEGIN TRANSACTIONで開始し、COMMITまたはROLLBACKで明示的に終了させる必要があります。しかし、自動コミットモードが有効な場合、このプロセスは自動化されます。
(例)トランザクション = INSERT文 + UPDATE文
- INSERT文を実行: このSQL文が成功すると、その時点で自動的にコミットされる
- UPDATE文を実行: このSQL文が成功すると、その時点で自動的にコミットされる
これにより、ユーザーは明示的なコミットを意識することなく、個々のSQL文の変更を確定させることができます。
自動コミットモードで動作しているとき、DBMSは1つのSQL文が実行されるたびに、自動的に裏でコミットを実行している。
DBMSによっては、デフォルト状態では自動コミットモードで動作している。
また、DBMSによって、自動コミットモード中であっても BEGIN を実行することで、コミットかロールバックまでの間、一時的に自動コミットを解除することができる。
自動コミットモードは、トランザクションが明示的に開始されていない場合のデフォルトの動作であり、トランザクションを開始することでこの動作は一時的に上書きされます。
多くのデータベースでは、BEGIN TRANSACTION(または同等のコマンド)を実行して明示的にトランザクションを開始すると、自動コミットモードは一時的に無効になります。
-
通常時(自動コミットモードが有効)
INSERT文やUPDATE文を1つ実行するたびに、その変更が自動的にコミットされます。 -
トランザクション開始後
BEGIN TRANSACTIONを実行すると、この状態が解除されます。その後、複数のSQL文(例:UPDATEやINSERT)を実行しても、それらは単一のトランザクションとして扱われ、自動的にコミットされることはありません。 -
トランザクション終了
すべての処理が成功したらCOMMITを実行して変更を永続化し、失敗したらROLLBACKを実行して変更を破棄します。この時点で、再び自動コミットモードに戻るのが一般的です。
トランザクションの分離
同時実行の副作用
世の中で利用されているサービスは、多くの利用者から1つのDBMSに対してたくさんのSQL文が送られます。
DBMSはそれらのリクエストを同時に処理しようとするため、同じ行を複数の利用者が同時に読み書きする可能性がある。このような状態が発生すると、副作用が発生し、正しい処理が行われない可能性があります。
3つの代表的な副作用
副作用1 ダーティーリード(dirty read)
あるトランザクションが更新されている最中に、他のトランザクションからデータを読み出すことができてしまう状況です。これは、READ UNCOMMITTEDの分離レベルでのみ発生します。以下の例では、トランザクションBの内容をCOMMITされる前に途中で読みこんでしまっています。結果的に、ロールバックされたにもかかわらずトランザクションA、誤ったデータを取得しています。
※ https://qiita.com/WebEngrChild/items/e85d0762c1383e353349 より引用

まだコミットされていない未確定の変更を他の人が読めてしまう副作用のこと
その後キャンセルされてしまう可能性のある未確定の情報を元にして別の処理を行なうため、非常に危険な副作用
副作用2 反復不能読み取り(non-repeatable read)
同一トランザクション内で同じデータを2回以上読み取ると、その間に他のトランザクションがデータを更新しコミットした結果、異なる値が返される現象を指します。これは、READ COMMITTEDの分離レベルで可能性があります。以下の例では、トランザクションAの中で2回に分けて商品Aの在庫数を取得していますが、結果が異なっています。
※ https://qiita.com/WebEngrChild/items/e85d0762c1383e353349 より引用

あるテーブルに対してSELECT文を実行した後、他の人がUPDATE文でデータを書き換えると、次回SELECTした際に検索結果が異なってしまうという副作用のこと
テーブルの内容を複数回読み取る際、その間にデータの内容が変化してしまっては困るケースがある。
副作用3 ファントムリード(phantom read)
同一トランザクション内で同じデータ範囲を二回以上クエリすると、その間に他のトランザクションが新たなデータを追加・コミットした結果、クエリ結果が異なる現象を指します。これは、一般的にREPEATABLE READの分離レベルで発生する可能性があります。ただし、MySQLのInnoDBでは、この分離レベルでも後述するネクストキーロックという機能を使うことで防止することができます。
※ https://qiita.com/WebEngrChild/items/e85d0762c1383e353349 より引用

2回のSELECT文の間に、他の人がINSERT文で行を追加すると、2回のSELECT文で結果行数が変わってしまう副作用のこと
1回目の検索結果の行数に依存するような処理を行なう場合に問題となることがある。
トランザクションの分離
分離性(isolation)
複数のトランザクションが同時に実行された場合でも、お互いに影響を与えず、あたかも1つずつ順番に実行されたかのように見えるという性質です。これにより、データの整合性が保たれます。
分離性とは、まさに一つのトランザクションを独立したブロックとして扱い、他のトランザクションからの干渉を防ぐ性質のこと。
分離性がないと起こる問題
更新の消失(Lost Update)
2つのトランザクションが同じデータを同時に読み込み、それぞれ異なる変更を加えてコミットした場合、先にコミットした変更が後からコミットした変更によって上書きされ、失われてしまう。
ダーティリード(Dirty Read)
あるトランザクションが、まだコミットされていない別のトランザクションの変更を読み込んでしまう。
その後、変更元のトランザクションがロールバックされると、読み込んだデータは存在しない変更となり、不整合が発生する。
ノンリピータブルリード(Non-repeatable Read)
あるトランザクションが同じデータを複数回読み込んだ際、その間に別のトランザクションがデータを変更・コミットしたため、読み込むたびに異なる値を取得してしまう。
◎DBMSによるトランザクション制御(3)
DBMSは、あるトランザクションを実行する際、他のトランザクションから影響を受けないよう、分離して実行する。
→ 仮に他のトランザクションと同時に実行していたとしても、あたかも単独で実行しているのと同じ結果になるように制御する。
ロック(lock)
複数のユーザーやプロセスが同じデータベースのデータに同時にアクセスする際に、データの整合性を保つために、一時的にそのデータへのアクセスを制限する仕組みです。
あるトランザクションが現在読み書きしている行に鍵をかけ、他の人のトランザクションからは読み書きできないようにします。
「ロックを取る」「ロックを取得する」
あるトランザクションが特定の行などをロックすること表す表現
自分のトランザクションがコミットまたはロールバックで終了すると、かけた鍵は解除され、他の人のトランザクションがその行を読み書きできるようになります。
→ 自分が読み書きしたい行を他の人がロックしている場合、その人のトランザクションが完了するまで自分は待ち続けることになります。
※このロックの1つ1つの待ち時間は短いが、ロックがたくさん発生すると、データベースの動作は非常に遅くなってしまう点には注意が必要
ロックが多発する主な理由(パフォーマンス低下の理由)
ロックの競合(Lock Contention)
複数のトランザクションが、同じデータに対する排他ロックを要求すると、先にロックを取得したトランザクションが完了するまで、他のトランザクションは待ち状態に入ります。この待ち時間が増えると、全体の処理効率が落ちます。
デッドロック(Deadlock)

複数のトランザクションが互いに相手がロックしているリソースを待つ状態になり、永遠に処理が進まなくなる状況です。DBMSはデッドロックを検知すると、どちらか一方のトランザクションを強制的に終了(ロールバック)させますが、これによりトランザクションが無駄になり、リソースの再取得が必要になります。
データベースの世界においては、一つのトランザクションで複数のデータにロックをかける際に、そのロックをかける順番によっては、二つのトランザクションでお互いのロックの解放(アンロック)を待つ状態になってしまう、いわゆるお見合い状態になり、後続の処理が動かないことになってしまうことがあります。
※ https://itmanabi.com/exclusive-lock/ より引用

並列性の低下
ロックは基本的に、複数の処理を直列化させる効果があります。これにより、本来同時に実行できたはずの処理が、ロックのせいで順番待ちになり、システムの並列性が失われます。
これらの問題を避けるためには、トランザクションの範囲をできるだけ小さくしたり、適切な分離レベルを選択したりすることが重要です。
ロックの一般的な種類
共有ロック(Shared Lock)
データの読み取りを目的としたロックです。複数のトランザクションが同時に共有ロックをかけることができます。
しかし、共有ロックがかかっている間は、他のトランザクションがそのデータを変更するための排他ロックをかけることはできません。
排他ロック(Exclusive Lock)
データの変更(挿入、更新、削除)を目的としたロックです。一度に1つのトランザクションしか排他ロックをかけることができません。排他ロックがかかっている間は、他のトランザクションは読み取りも変更もできません。
分離レベル
トランザクションを使うメリット
- ロックの仕組みが有効になり、副作用は発生しないようになる
トランザクションを使うデメリット
- DBMSのパフォーマンスが損なわれる
正確なデータ操作とパフォーマンスは二律背反の関係にあるが、ある程度の両立は可能
トランザクション分離レベル(transaction isolation level)
多くのDBMSで、どの程度厳密にトランザクションを分離するかを指定することができる。
※ https://qiita.com/dodonki1223/items/69350c46602f51ca56fd より引用

デフォルトの分離レベル以外の任意の分離レベルを SET TRANSACTION ISOLATION LEVEL 命令を使用して選択できる。
SET TRANSACTION ISOLATION LEVEL 分離レベル名
SET CURRENT ISOLATION 分離レベル名
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
分離レベルで性能と安全性のバランスを選択できる
並列実行制御( MVCC: multi-version concurrency control )
複数のトランザクションが同時に同じデータにアクセスしても、互いに干渉せず、ロックを使わずにデータの整合性を保つための仕組み
MVCCの主な考え方は、データの変更履歴を複数世代(バージョン)として保持すること
つまり、あるデータについて「未確定の書き換え済み」と「書き換え前」の2つのバージョンを併存させる
-
読み取りの隔離
読み取り専用のトランザクションは、データが変更される前の古いバージョンを参照します。これにより、書き込み中のトランザクションがロックをかけていても、読み取りはブロックされません。 -
書き込みの非ブロッキング
書き込みを行なうトランザクションは、データの新しいバージョンを作成します。これにより、他のトランザクションが古いバージョンを読み取っている間も、書き込みを待つ必要がなくなります。
参考URL
ロックの活用
明示的なロック
DBMSはトランザクションの分離性を確保するために自動的に行にロックをかける
そのため、具体的に「いつ」「どの行に対して」ロックするかという指示をする必要はない。
SQL文を使って明示的に指定した対象をロックすることもできる
また、テーブル全体やデータベース全体をロックすることもできる。
明示的に取得できるロックの種類
-
行ロック : ある特定の1行だけをロックする
-
表ロック : ある特定のテーブル全体をロックする
-
データベースロック : データベース全体をロックする
※DBMSによっては「ページ」や「表スペース」などもロック対象となる
ロックの厳しさ
排他ロック(exclusive lock)
他からのロックを一切許可しないため、主にデータの更新時に利用される
共有ロック(shared lock)
他からの共有ロックを許す特性あり
データの読み取り時に多く利用される
1. 行ロックの取得
SELECT ~ FOR UPDATE (NOWAIT)
通常、SELECT文で選択した行には自動的に共有ロックがかかる。
このSELECT文の末尾に "FOR UPDATE" を追加すると、排他ロックがかかり、他のトランザクションからは該当行のデータを書き換えることができなくなる。
明示的なロックを取得しようとしたとき、すでに他のトランザクションによって同じ行がロックされている場合、通常はロックが解除されるまで自分のトランザクションは待機状態になる。
しかし、NOWAITオプションを指定した場合、DBMSはロックの解除を待機せずにすぐさまロック失敗のエラーを返すため、トランザクションは即時終了する。
※処理を待たせたくないアプリケーションなどに有効
かけたロックは、コミットまたはロールバックによってトランザクションが終了すると解除される。
2. 表ロックの取得
LOCK TABLE テーブル名 IN モード名 MODE (NOWAIT)
モード名
-
EXCLUSIVE: 排他ロック -
SHARE: 共有ロック
ある特定の表全体をロックするには、LOCK TABLE 命令を利用する。
取得した表ロックは、トランザクション終了によって解除される。