仮想化
仮想化
※https://clouddirect.jp.fujitsu.com/service/navi-beginner-virtualization より画像引用
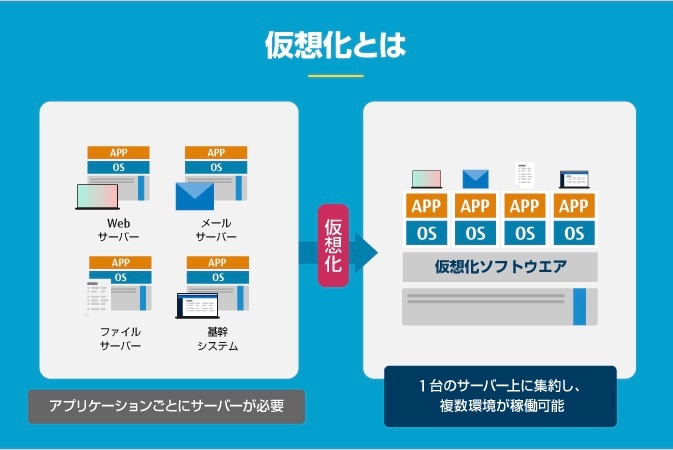
仮想化とは、サーバーなどのハードウエアリソース(CPU、メモリ、ディスクなど)を抽象化し、物理的な制限にとらわれず、ソフトウエア的に統合・分割できるようにする技術
物理サーバーはあくまで1台しかないため、 CPU やメモリなどは1つしか存在しない。しかし、仮想化の技術を活用することで、仮想サーバーごとに CPU 処理量やメモリ容量を振り分けることができ、それぞれの仮想サーバーを独立したサーバーのように動作させることが可能になる。
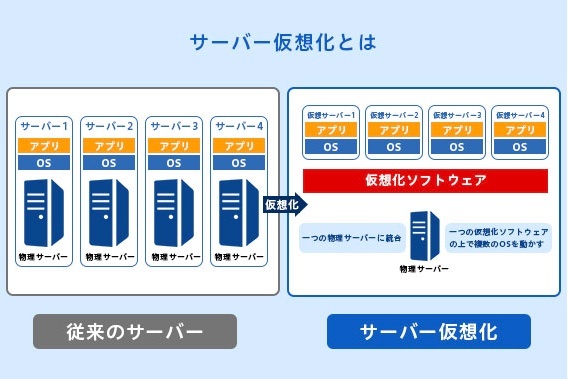
サーバ仮想化とは、1台の物理サーバ上に複数のOSを動作させる技術
本物の(物理的な)サーバーではないが、ソフトウエアによって実質的に本物と同じように扱えるサーバー
現代のように仮想化技術が普及していなかった頃は、サーバーは用途ごとに専用のハードウエアを用意して構築するのが一般的でした。つまり、Webサーバー、メールサーバー、ファイルサーバーなど、サーバーの種類や数が増えるごとに保有するハードウエアの台数も増えていたわけです。しかし、サーバーを仮想化することで、1台の物理サーバーの上に複数の仮想サーバーをソフトウエア的に作成し、同時に動かすことができるようになりました。
サーバーの仮想化を行うには、専用の仮想化ソフトウエアが必要になります。仮想化ソフトウエアとしては、主にPCで利用されているオラクルの「Virtualbox」、FJcloud-V(旧ニフクラ)で採用しているVMwareの「VMware vSphere®」、Microsoftの「Hyper-V」などが有名です。また、サーバーだけでなく、ストレージやネットワーク、デスクトップ環境やアプリケーションといったリソースの仮想化も利用されています。
※※https://clouddirect.jp.fujitsu.com/service/navi-beginner-virtualization より引用
仮想化ソフトウェア
※https://it-ichiba.jp/info/0630/ より画像引用
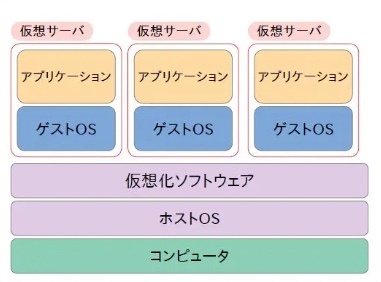
1台のコンピュータ(物理マシン)の上で、複数の仮想的なコンピュータ(仮想マシン)を動作させるためのソフトウェア。
仮想マシンは独立した環境を持ち、それぞれが独自のオペレーティングシステムやアプリケーションを実行できる。
1台の物理マシンで複数の環境を構築し、学習、開発、テスト、サーバー統合などに活用できる強力なツール
基本的な仕組み
※https://www.designet.co.jp/ossinfo/selection/virtual-infrastructure.html より画像引用
コンピュータのリソース(CPU、メモリ、ストレージ、ネットワーク)を抽象化して、複数の仮想マシンに分配する。これにより、仮想マシンは実際のハードウェアにアクセスしているように振る舞うようになる。
ホストマシン:仮想化ソフトウェアがインストールされている実際の物理コンピュータ。
ゲストマシン:仮想化ソフトウェアによって作成された仮想マシン。各ゲストマシンは独自のOSを持つ。
ホストOS:仮想化ソフトウェアを動作させているOS
ゲストOS:仮想化ソフトウェアによって実行する仮想的なOS
種類
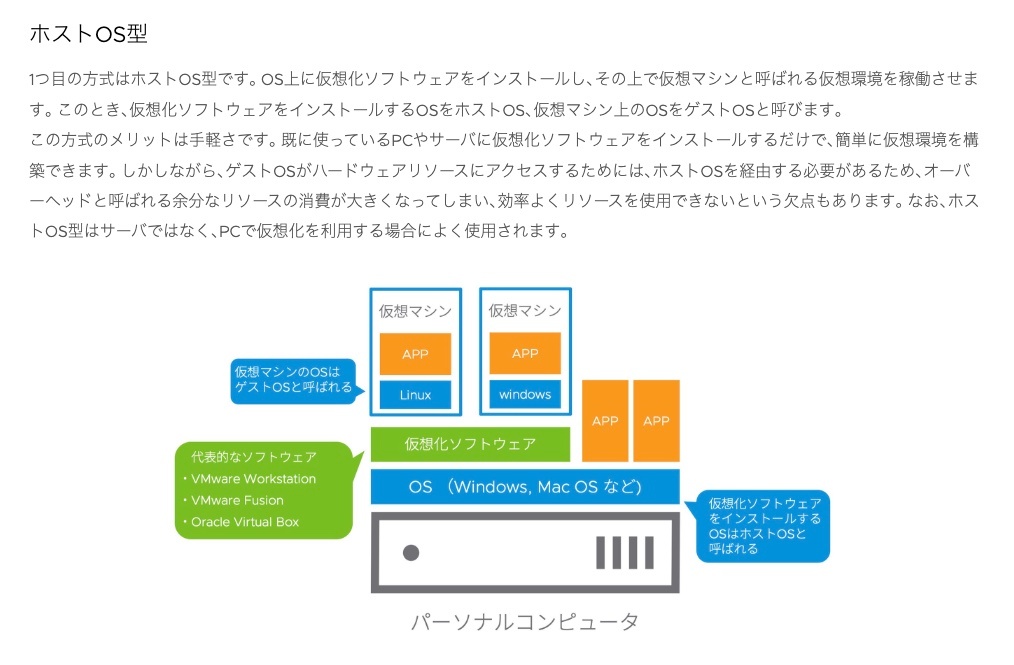
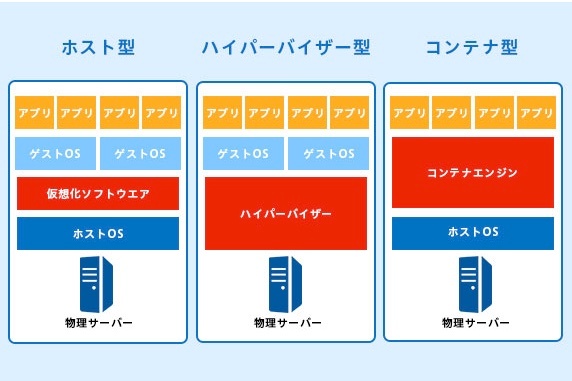
ホスト型仮想化
仮想化ソフトウェアが既存のOS上で動作し、その上に仮想マシンを作成します。
(例)VirtualBox, VMware Workstation, Parallels Desktop。
・セットアップが簡単
・パーソナル用途や開発環境に適している
※https://it-juku.jp/whatsvm/whatsvm02/ より画像・テキスト引用
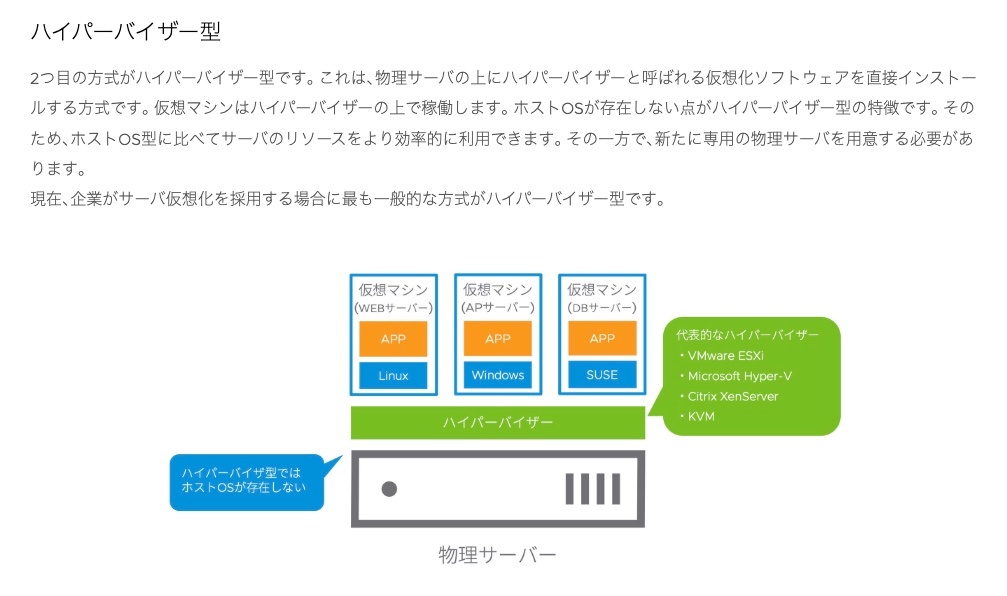
ハイパーバイザー型
ハイパーバイザー(Hypervisor) は、仮想化を直接ハードウェア上で行うソフトウェア。
(例)VMware ESXi, Microsoft Hyper-V, Xen。
・高性能
・直接ハードウェアを制御するため、効率的
・サーバー仮想化に最適
※https://it-juku.jp/whatsvm/whatsvm02/ より画像・テキスト引用
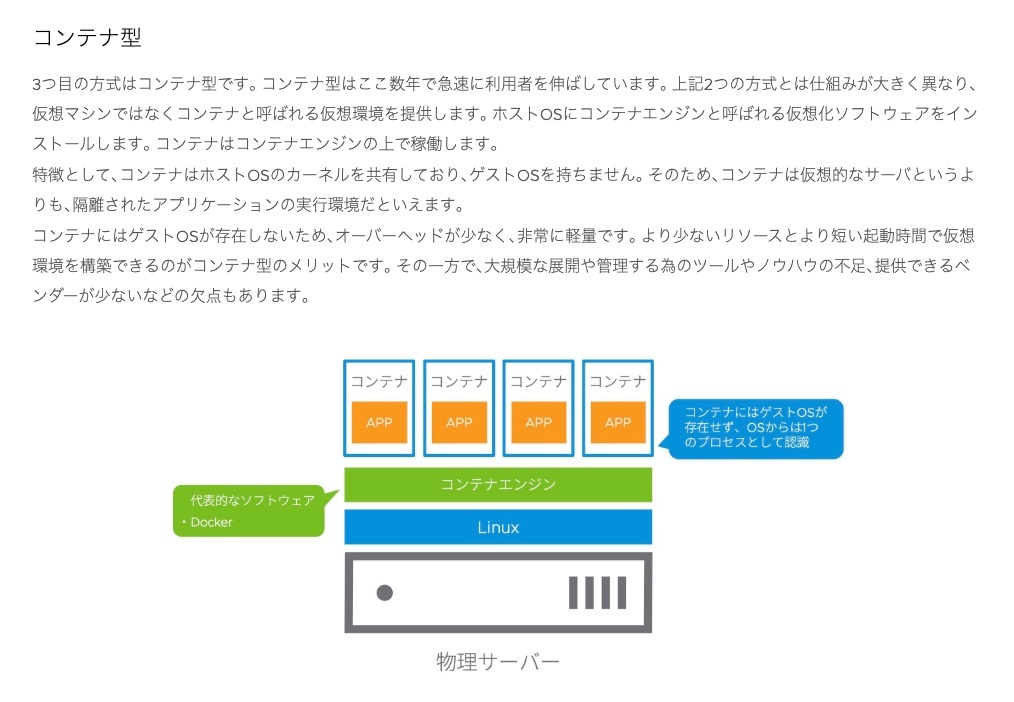
コンテナ型仮想化
※https://it-juku.jp/whatsvm/whatsvm02/ より画像・テキスト引用
まとめ
※https://it-ichiba.jp/info/0630/ より画像引用
クラウドサーバー
クラウドサーバーの種類
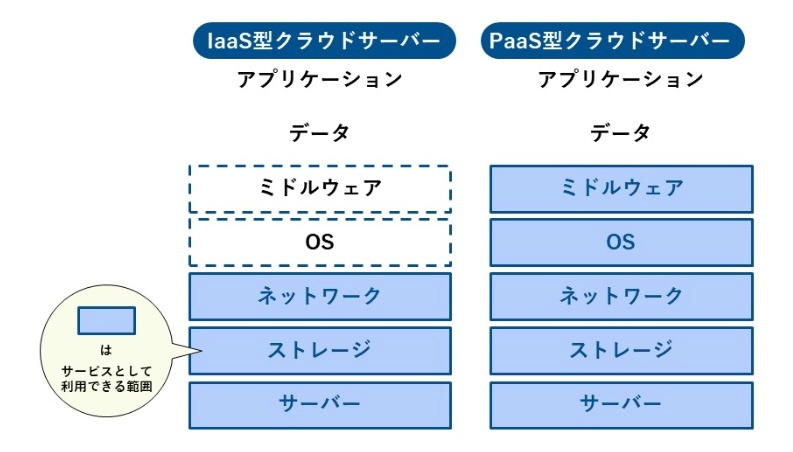
IaaS型クラウドサーバー
IaaS(Infrastructure as a Service)とは、サーバーやネットワーク、ストレージなどのITインフラをインターネット経由で提供するサービスモデルです。ユーザーは物理的なハードウェアを自分で購入・設置せずに、サービスとしてこれらのリソースを利用できます。
PaaS型クラウドサーバー
PaaS(Platform as a Service)とは、アプリケーションの開発やデプロイ、管理を行うためのプラットフォームを提供するサービスモデルです。IaaSに加えて、OSやデータベースなどの必要なプラットフォームまでサービスとして利用できます。
物理サーバーとの違い
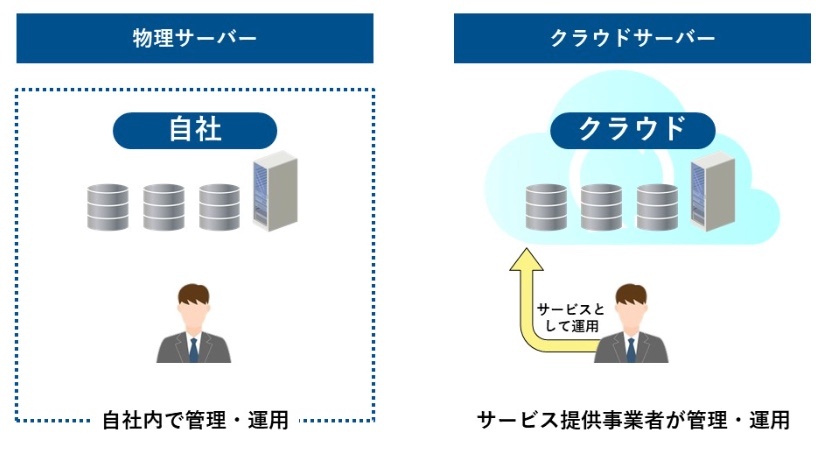
物理サーバーは企業内に物理的に存在するサーバー。
物理サーバーを自社内に設置して直接管理することをオンプレミスという。
レンタルサーバー・VPSとの違い
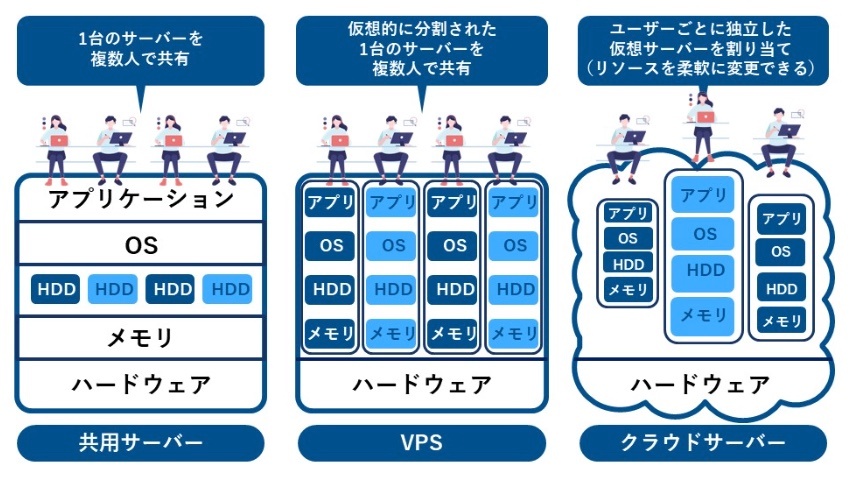
レンタルサーバー:特定のサーバーのリソースをユーザーがインターネット経由でレンタルするサービスのこと。
レンタルサーバーには複数のユーザーがサーバーを共有する共有サーバーと、仮想的に分割された専用のサーバーを提供するVPS *Virtual Private Serverがある。
クラウドサーバーとレンタルサーバーの共通点
→ 物理サーバーを持たずにインターネット経由で仮想サーバーを利用する点
しかし、共用サーバーは1台のサーバーを複数の利用者で共有するため、ユーザーごとにサーバーが割り当てられるクラウドサーバーと比較して、ほかの利用者の影響を受けやすいことが特徴。
VPSの場合は、ほかのユーザーの影響は受けにくいものの、物理的にはサーバーを共有しているため、クラウドサーバーよりもリソースの拡張性は劣る。
※https://www.nplus-net.jp/knowledge/2021/20210825132100.html より画像・テキスト一部引用
クラウドサーバーはインターネットを介して利用するため、情報漏えいリスクを完全には排除できない。とくに、クラウドサービスにおける基本的なセキュリティ対策はサービス提供事業者に依存するため、信頼性の高いサービスを選択することが重要になる。
クラウドコンピューティングの提供形態
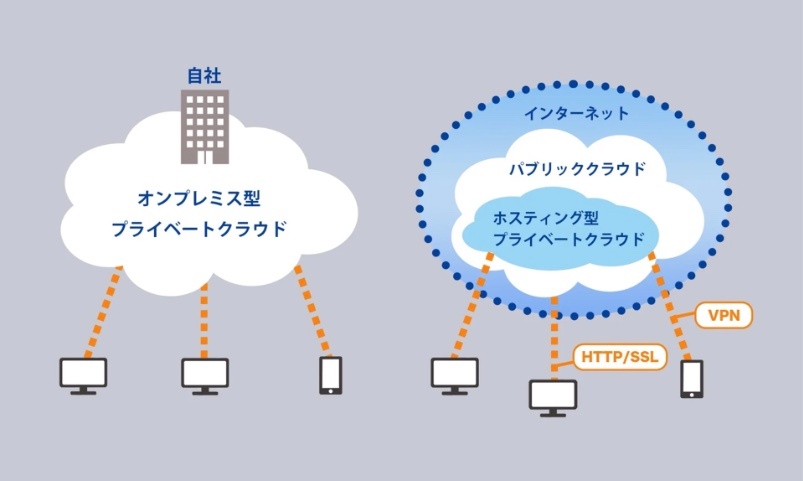
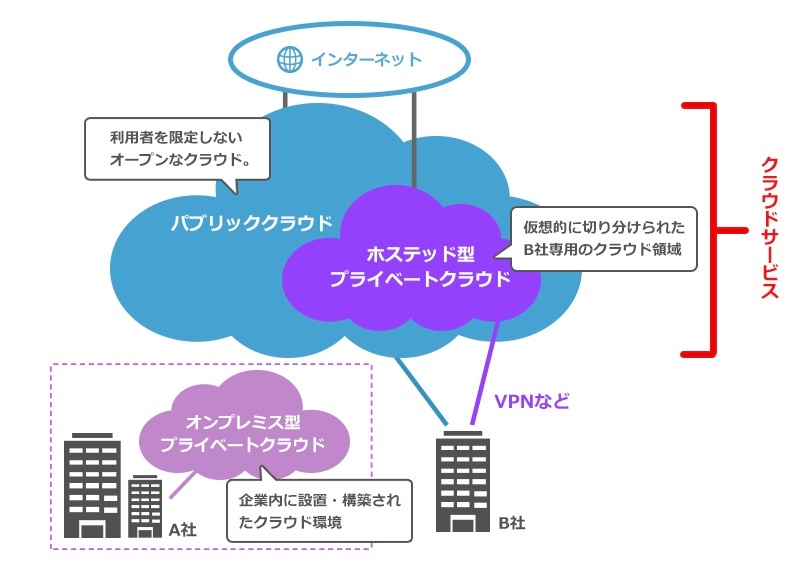
※https://www.idcf.jp/cloud/column/public_private.html より画像引用
パブリッククラウド
サービスの全てがインターネット経由で提供される、最も一般的なクラウドコンピューティングモデル。
パブリッククラウドでは、サーバーやストレージ、ソフトウェアなどのリソースやインフラは全てベンダー企業が所有・管理し、均一化されたサービスをユーザーに提供する。システムのアップデートやメンテナンスなどもベンダー企業の役割。
したがって、導入や管理運営の難易度やコストを低く抑えられるため、誰もが利用しやすいのが特徴。
(例)Webメールサービス
プライベートクラウド
ひとつの企業や組織が独占的に使用するリソースで構成されたクラウドコンピューティングモデル。
プライベートクラウドは、ユーザーが所有するデータセンターに設置されたり、ベンダー企業から他のユーザーと遮断された自社専用の環境を提供されたりする。
そしてサービスとインフラは自社のプライベートネットワーク上で維持され、自社専用のものとして利用される。そのため、プライベートクラウドでは、自社の特定のニーズに対応するためのシステムへとカスタマイズしやすいのが特徴。外部からサーバーやネットワークが遮断されている分、パブリッククラウドと比べて堅牢なセキュリティも確保しやすいが、専用の環境を構築するためにコストも高くなる。
ハイブリッドクラウド
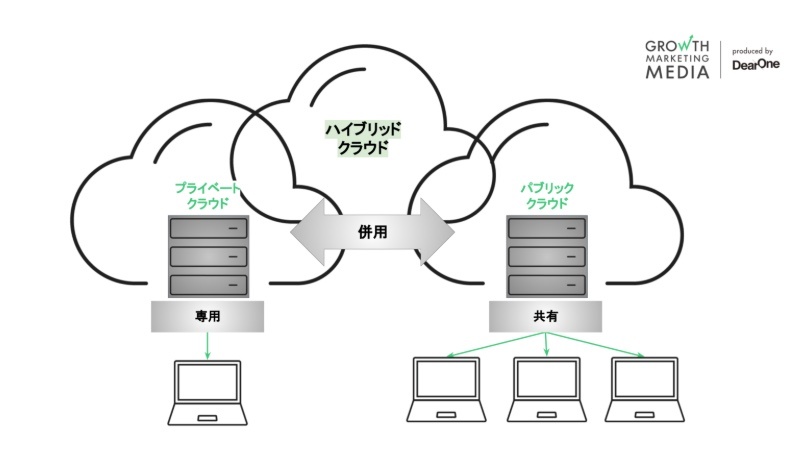
※https://growth-marketing.jp/knowledge/what-is-data-cloud/ より画像引用
ハイブリッドクラウドは、パブリッククラウドとプライベートクラウド、あるいはオンプレミスのインフラストラクチャを組み合わせたクラウドコンピューティングモデル。
ハイブリッドクラウドにおいて、ユーザーは状況や要件に応じてパブリッククラウドとプライベートクラウドの間でワークロードを自由に移動し、最適なクラウドコンピューティング環境を選択する。
たとえば、パブリッククラウドサービスを使用しつつも、重要なアプリケーションやデータなどについてはプライベートクラウド環境で安全に保持するなどがその一例。
ハイブリッドクラウドを活用することで、企業はパブリッククラウドやプライベートクラウドを単一で利用するよりも、効果やコスト効率を高めてシステムを活用できる。
ただし、適切にパブリッククラウドとプライベートクラウドを組み合わせたり使い分けたりするためには、運用上の難しさもある。
マルチクラウド
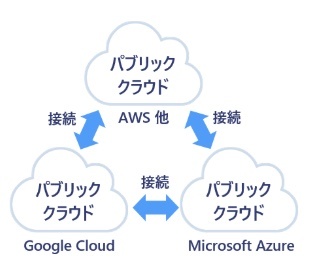
※https://atlax.nri.co.jp/blogs/20210927/ より画像引用
複数の独立したクラウドサービスを併用するクラウドコンピューティングモデル。
ユーザーは、自社の要件に応じて最適なサービスを適宜活用することで、ビジネス上の目標を効果的に達成できる。ひとつのクラウドサービスに依存しないことで、さまざまなリスクを分散する効果も見込める。
ただし、独立したクラウドサービスを併用するマルチクラウドには、複数のシステムを管理する煩雑さ、データのサイロ化、コストの増大などの課題も伴う。
※https://www.dsk-cloud.com/blog/cloud-computing より画像・テキスト一部引用し編集
クラウドの仕組み
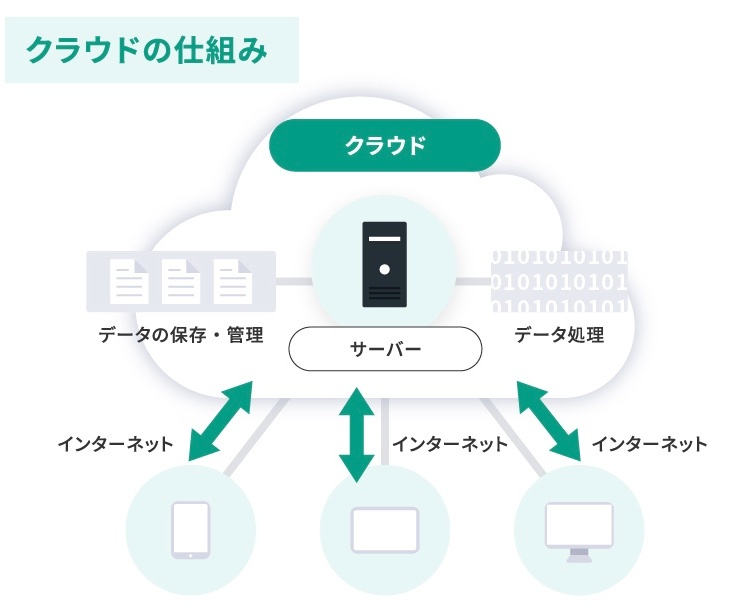
※https://2ndlabo.com/article/596/ より画像引用
クラウドサービスプロバイダー(AWS、Microsoft Azure、Google Cloud Platformなど)
世界中に大規模なデータセンターを所有している。
これらのデータセンターには、膨大な数の物理サーバー、ストレージ、ネットワーク機器が設置されている。
クラウドサービスプロバイダーは、仮想化技術を使用して、これらの物理リソースを仮想化し、ユーザーに提供している。
クラウドベンダー企業は、これらの物理サーバーを仮想化技術によって分割し、ユーザーに仮想サーバー(インスタンス)として提供している。
ユーザーは、インターネット経由でこれらの仮想化されたリソースにアクセスし、必要な時に必要なだけ利用できる。
ユーザー側の視点
ユーザーは、物理サーバーの購入や管理を行う必要はない。
クラウドサービスプロバイダーが、物理サーバーの設置、保守、セキュリティ対策などを行なう。
ユーザーは、仮想サーバーやストレージ、ネットワークなどのリソースを、オンデマンドで利用できる。
まとめ
クラウドサービスは、物理サーバーを基盤としているが、ユーザーはその物理サーバーを直接所有したり管理したりする必要はない。
クラウドサービスプロバイダーが、物理インフラを管理し、ユーザーは仮想化されたリソースを利用するという形態。
仮想化技術
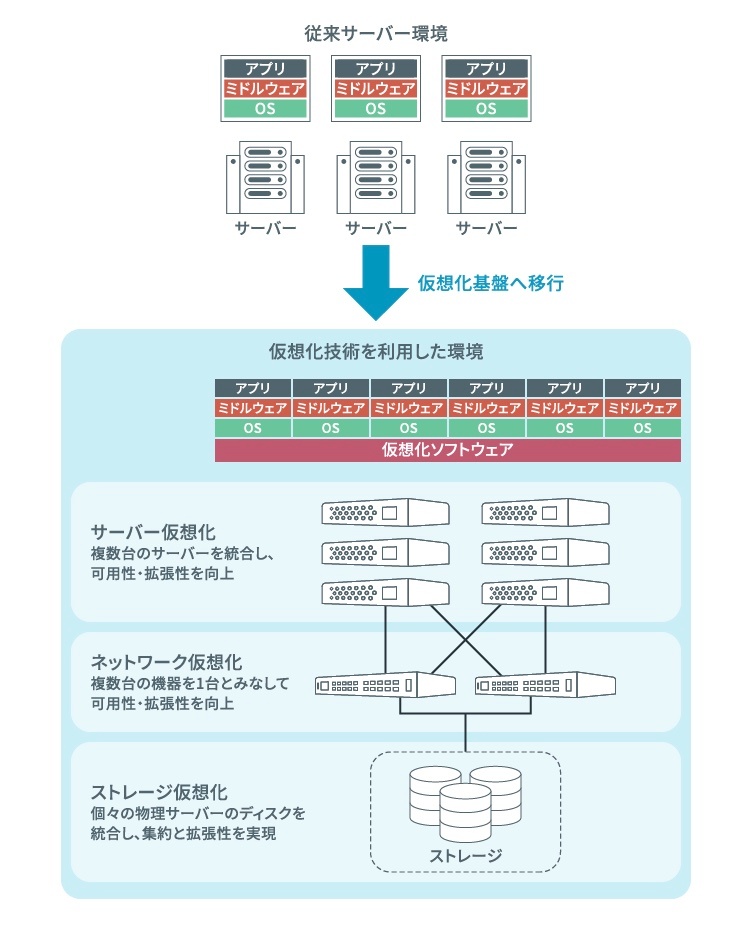
※https://www.qtpro.jp/service/integration/virtualization/ より画像引用
ネットワーク仮想化

※https://clouddirect.jp.fujitsu.com/service/navi-tech-nsx より画像引用
クラウド環境へのアクセス経路
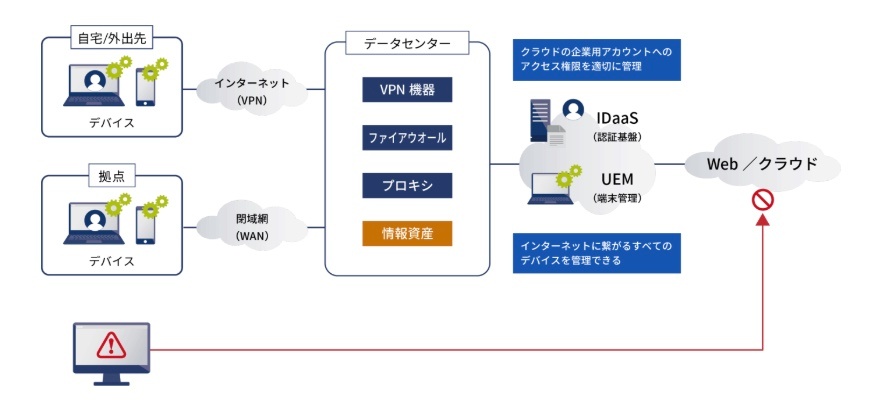
※https://www.bizxaas.com/application/office/column/article-25.html より画像引用
1. ユーザーのデバイス
ユーザーは、PC、スマートフォン、タブレットなどのデバイスからインターネットに接続します。
2. インターネット(通常のネットワーク)
ユーザーのデバイスからインターネット回線を経由して、クラウドプロバイダーのデータセンターに接続します。
この間、データは通常のインターネットネットワークを経由します。
3. クラウドプロバイダーのネットワーク
クラウドプロバイダーのデータセンターに到達したトラフィックは、まずクラウドプロバイダーの物理的なネットワークを経由します。
4. クラウド環境の仮想ネットワーク
次に、トラフィックはクラウド環境内に構築された仮想ネットワークを経由します。
仮想ネットワークは、VPC(Virtual Private Cloud)などのサービスによって提供され、セキュリティやルーティングを制御します。
5. クラウド上のサーバー(仮想マシン)
仮想ネットワークを経由して、トラフィックは目的の仮想マシンに到達します。
仮想マシン上で動作するアプリケーションがトラフィックを処理し、結果をユーザーに返します。
サーバーへのアプリケーションのアップロード
アプリケーションをサーバーにアップロードする場合、そのアプリケーションプログラムのファイルが保存される場所は、アプリケーションの種類やサーバーの構成によって異なる。
一般的には、以下の2つのケースが考えられる。
1. 静的コンテンツのみのアプリケーションの場合
・HTML、CSS、JavaScriptなどの静的ファイルで構成されるアプリケーションの場合、これらのファイルはWebサーバーに保存される。
・Webサーバーは、これらの静的ファイルをクライアント(Webブラウザ)からの要求に応じて配信する役割を担う。
(例)シンプルなWebサイトや、フロントエンドのみで構成されたアプリケーションなどが該当する。
2. 動的コンテンツを含むアプリケーションの場合
・サーバーサイドのプログラミング言語(PHP、Python、Javaなど)を使用して動的な処理を行うアプリケーションの場合、アプリケーションプログラムのファイルはアプリケーションサーバーに保存される。
・アプリケーションサーバーは、クライアントからの要求に応じて動的なコンテンツを生成し、Webサーバーを通じてクライアントに送信する。
(例)データベースと連携して動的なWebページを表示するWebアプリケーションや、APIサーバーなどが該当する。
Webサーバーとアプリケーションサーバーの連携
・多くのWebアプリケーションでは、Webサーバーとアプリケーションサーバーが連携して動作する。
・Webサーバーは、クライアントからの要求を受け付け、静的ファイルはそのまま配信し、動的な処理が必
要な要求はアプリケーションサーバーに転送する。
・アプリケーションサーバーは、転送された要求に基づいて動的なコンテンツを生成し、Webサーバーに返す。
・Webサーバーは、アプリケーションサーバーから受け取ったコンテンツをクライアントに送信する。
(具体例)
・PHPで作成されたWebアプリケーションの場合、PHPファイルはアプリケーションサーバーに保存され、ApacheやNginxなどのWebサーバーと連携して動作する。
・Javaで作成されたWebアプリケーションの場合、WARファイルやJARファイルはアプリケーションサーバー(Tomcat、Jettyなど)にデプロイされ、Webサーバーと連携して動作する。
ポイント
・静的コンテンツのみのアプリケーションはWebサーバーに保存される。
・動的コンテンツを含むアプリケーションはアプリケーションサーバーに保存される。
・多くのWebアプリケーションでは、Webサーバーとアプリケーションサーバーが連携して動作する。
ローカル環境でのWebアプリケーションの動作の流れ
1. VS Codeでの開発
VS Codeなどのテキストエディタで、PHPファイル(例:index.php)と、必要に応じてHTML、CSS、JavaScriptなどのファイルを作成する。
2. WebサーバーとPHP処理系のインストール
ローカル環境でPHPアプリケーションを動作させるためには、Webサーバー(Apache、Nginxなど)とPHP処理系(PHPインタプリタ)をインストールする必要がある。
これらのソフトウェアは、XAMPP、MAMP、Dockerなどのツールを利用して簡単にインストールできる。
3. アプリケーションサーバーとしてのPHP処理系
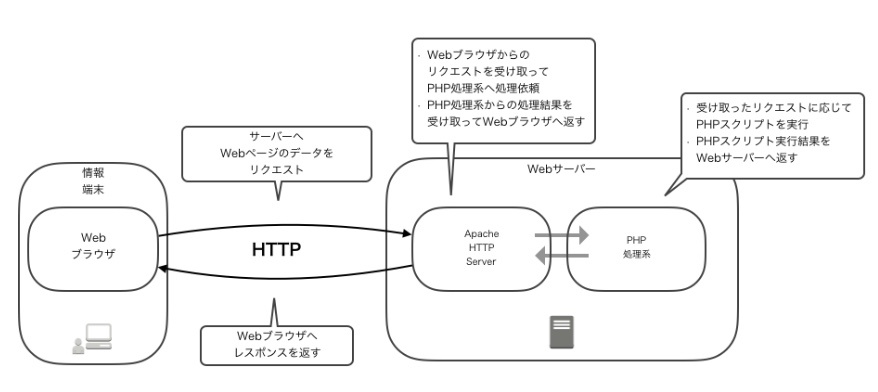
※https://tech.kurojica.com/archives/55908/ より画像引用
PHPファイルは、アプリケーションサーバーに保存されるというよりも、WebサーバーがPHP処理系を呼び出して実行する。
この場合、PHP処理系がアプリケーションサーバーの役割を果ます。
Webサーバーは、PHPファイルへのリクエストを受け取ると、PHP処理系に処理を委譲する。
PHP処理系は、PHPファイルを解析し、動的にHTMLコードを生成する。
4. Webサーバーからクライアントへのレスポンス
PHP処理系が生成したHTMLコードは、Webサーバーに返される。
Webサーバーは、このHTMLコードをクライアント(Webブラウザ)に送信する。
5. Webブラウザでの表示
Webブラウザは、Webサーバーから受け取ったHTMLコードを解析し、Webページとして表示する。
ローカル環境でアプリケーションが動作する理由
ローカル環境にWebサーバーとPHP処理系をインストールすることで、外部のVPSやコンテナを使用せずに、PC上でWebアプリケーションを動作させることができる。
Webブラウザは、ローカル環境で動作しているWebサーバーにアクセスし、Webページを表示する。
この場合、WebサーバーとPHP処理系は、PC内で連携して動作し、外部のサーバーとの通信は発生しない。
(具体例)
・XAMPPをインストールした場合、Apache WebサーバーとPHP処理系がインストールされる。
・index.php ファイルをXAMPPのhtdocsディレクトリに保存し、Webブラウザから http://localhost/index.php にアクセスすると、PHPファイルが実行され、生成されたHTMLコードがWebブラウザに表示される。
ローカル環境での開発は、外部のサーバーに依存せずに、手軽にWebアプリケーションを試すことができる
PHPのプログラム
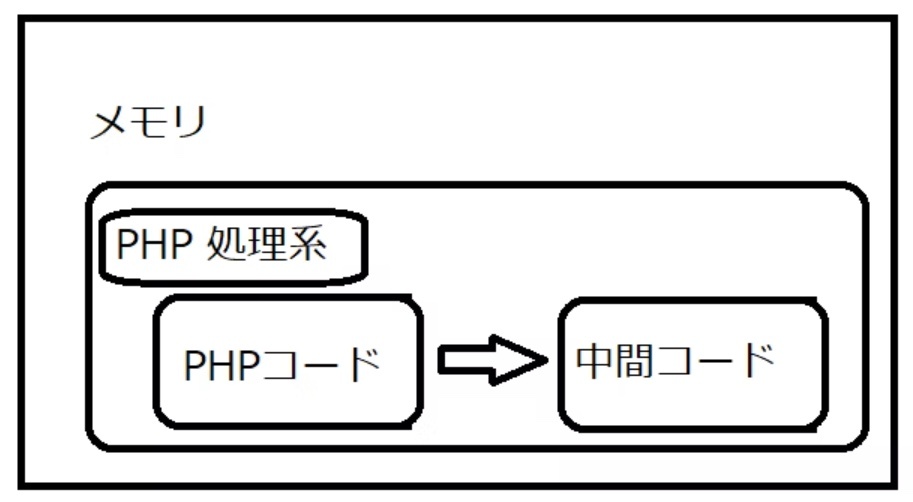
プログラムは実行時、メモリにロードされて動作する

PHP のスクリプトは、PHP 処理系という、C 言語で書かれたプログラムが解釈して実行

メモリ内にスクリプト(PHP コード)を読み込む
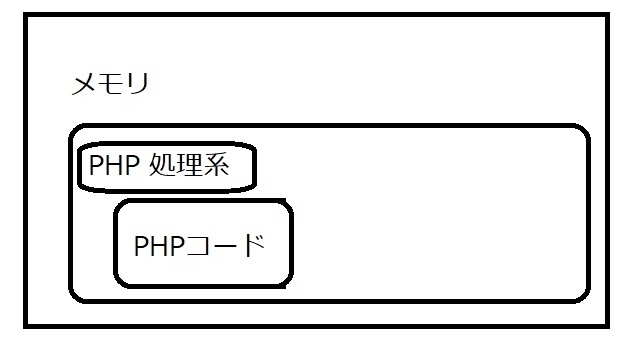
メモリ内にスクリプトと対応する中間コードを生成(コンパイル)
中間コードを解釈
中間コードに記述された通り処理を行い、ある種の仮想マシンとして処理系の内部状態(メモリ内容)を更新していく
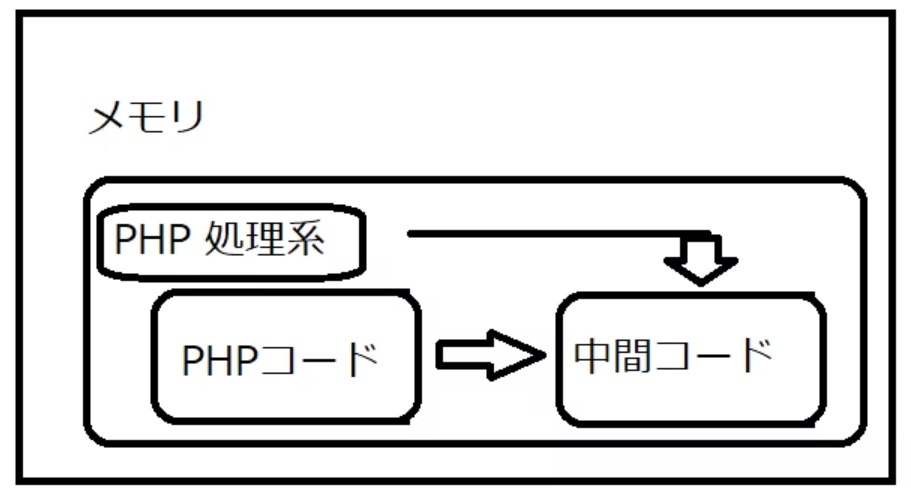
※https://qiita.com/sj-i/items/a29d54cfd83f230ddc3d より画像引用
PHP処理系
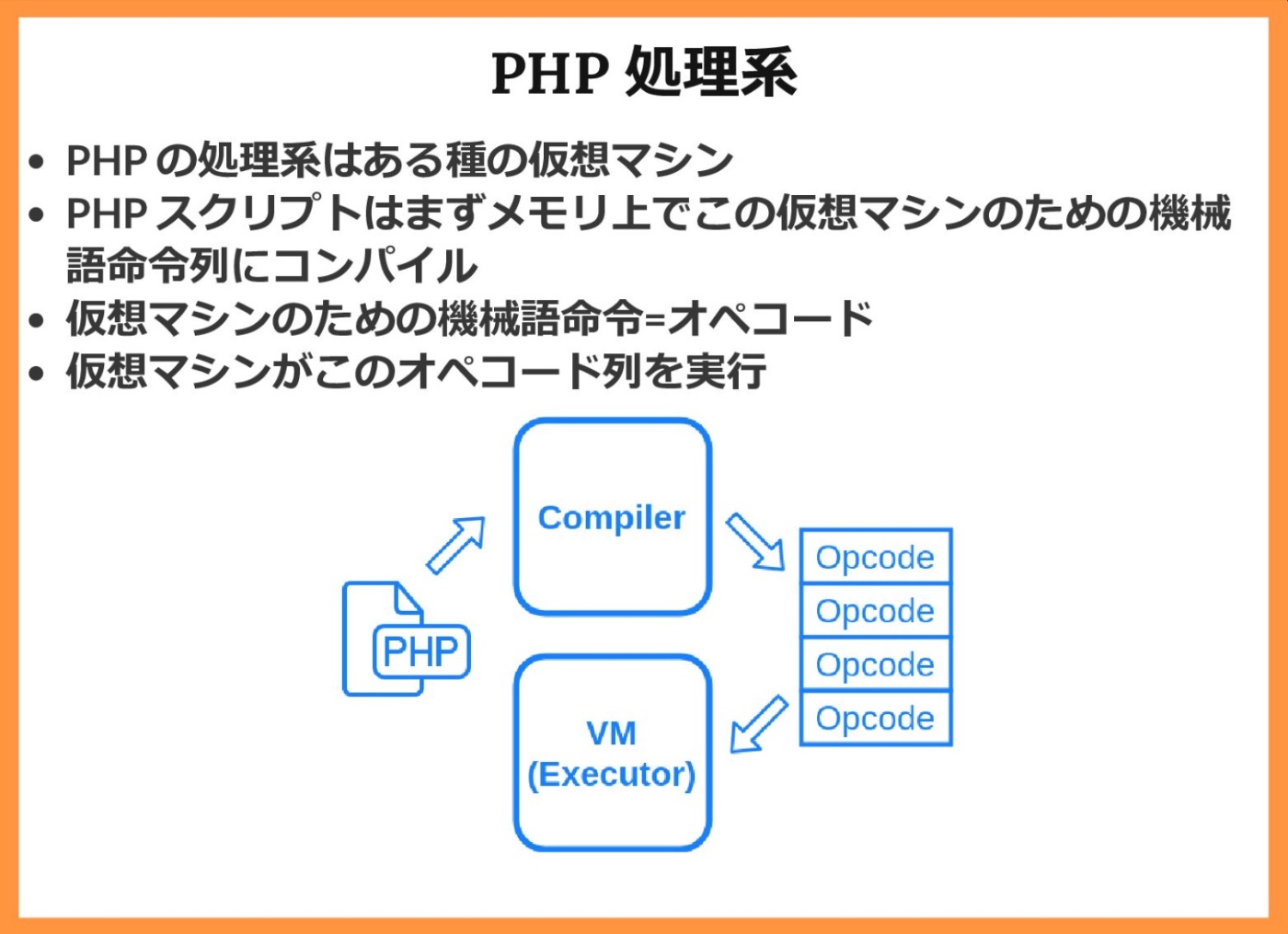
※https://speakerdeck.com/sji/php-deshi-zhong-nosukuriputonodong-zuo-woxia-karasi-ki-ru?slide=30 より画像引用
PHPプログラム処理の流れ
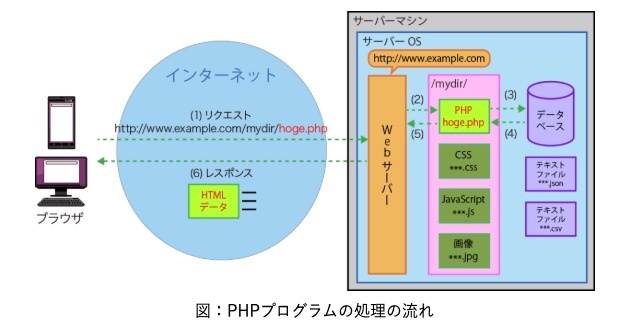
※https://iwatani.tv/programming/php-processing-of-php/ より画像引用
プログラミング言語の処理
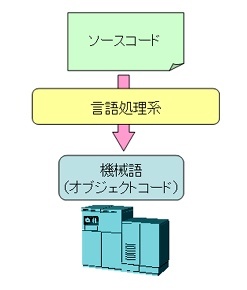
機械語命令は単純なバイト列で構成されているために、人間が直接読んでも理解するのは困難である。
そのため、ソフトウェアの作成にはプログラミング言語を用いるのが一般的となっている。
プログラマはプログラミング言語を用いて処理を記述したソースコードを作成し、言語処理系を用いて機械語命令列を生成する。この機械語命令列をオブジェクトコードやバイナリコードと呼ぶ。
またこのファイルを、オブジェクトファイル、バイナリファイル、実行可能ファイルと呼ぶ。
プログラミング言語の最も基本的なものはアセンブリ言語である。ソースコードは機械語命令と1対1に対応したニーモニックを用いたアセンブラで記述し、言語処理系でアセンブルすることによりオブジェクトコードを得る。
アセンブリ言語はきめ細かいハードウェアの操作を記述できる反面、プログラマはハードウェアに対する知識を要求される。また、処理の内容を読み取るにも、その記述方法は人間に対して直感的ではない。さらに、特定のプログラムを別のアーキテクチャを持つハードウェアに対応させるためには、ソースコードから記述しなおす必要があるなどの問題点もある。
アセンブリ言語に対してソースコードの抽象性を高め、人間にとって直感的でわかりやすい形で記述できるようにしたプログラミング言語を高級言語と呼ぶ。
ほとんどの高級言語は、順構造、分岐構造、繰り返し構造の3種類の基本的な制御構造をわかり易く記述できるようにした、構造化プログラミング言語となっている。構造化プログラミング言語には、プログラミング演習で扱うC言語とともに、FORTRAN、PASCAL、COBOLなどがある。
さらに近年では、プログラムの部品化とその独立性を高めたオブジェクト指向言語が、大規模なプログラム開発においては主流となってきている。オブジェクト指向言語にはC++、Javaなどがある。
※http://www.ced.is.utsunomiya-u.ac.jp/lecture/common/vs2010/programming_system.php より画像・テキスト引用
MAMP・XAMPP
XAMPPのhtdocsディレクトリは、Webサーバー(Apache)のドキュメントルートと呼ばれる場所であり、Webブラウザからアクセスできるファイルの置き場所。
htdocsディレクトリの役割
Webサーバーの公開ディレクトリ
htdocsディレクトリは、Webサーバー(Apache)がWebブラウザからのリクエストに応じてファイルを公開する場所。
Webブラウザからhttp://localhost/にアクセスすると、htdocsディレクトリ内のファイルが表示される。
静的ファイルの保存場所
HTML、CSS、JavaScriptなどの静的ファイルは、htdocsディレクトリに保存される。
Webサーバーは、これらのファイルをそのままWebブラウザに送信する。
PHPファイルの実行場所
PHPファイルもhtdocsディレクトリに保存される。
Webサーバーは、PHPファイルへのリクエストを受け取ると、PHP処理系を呼び出してPHPファイルを実行し、生成されたHTMLをWebブラウザに送信する。
アプリケーションサーバーとの関係
XAMPP環境では、PHP処理系がアプリケーションサーバーの役割を果たす。
PHPファイルはhtdocsディレクトリに保存されるが、WebサーバーはPHP処理系を呼び出して実行し、その結果をWebブラウザに送信する。
つまり、htdocsディレクトリは、Webサーバーとアプリケーションサーバー(PHP処理系)が連携して動作するためのファイルの置き場所と言える。
デプロイ
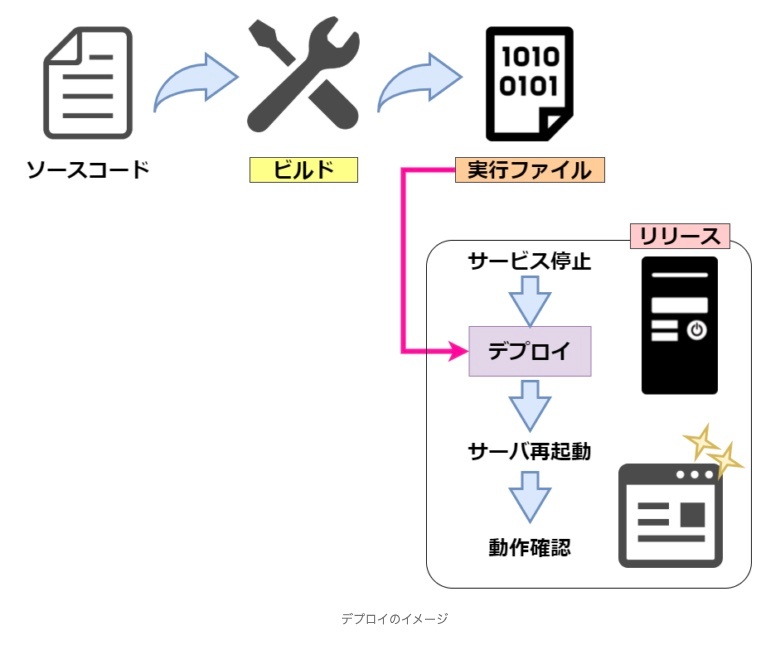
※https://itmanabi.com/deploy/ より画像引用
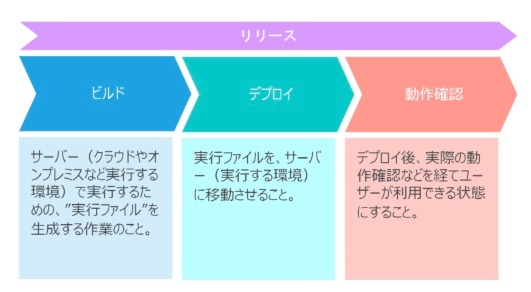
※https://assignment.co.jp/word/デプロイ/ より画像引用
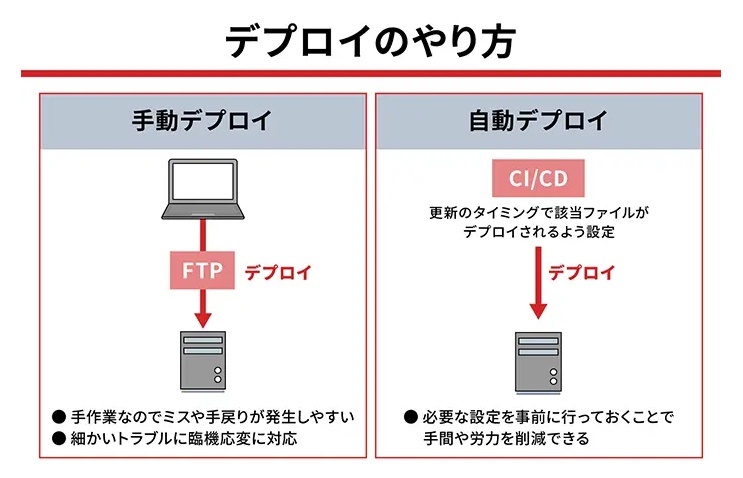
※https://www.activeimage-re.com/special/deploy.html より画像引用
一般的なケース
Webアプリケーション
WebアプリケーションをVPSやHerokuなどのクラウドサービスにデプロイした場合、ユーザーはWebブラウザからインターネット経由でアプリケーションにアクセスする。
インターネットを経由したアクセスが必須。
モバイルアプリケーションのAPIサーバー
モバイルアプリケーションのバックエンドとして動作するAPIサーバーをデプロイした場合、モバイルアプリケーションはインターネット経由でAPIサーバーにアクセスする。
インターネット経由のアクセスが必須。
例外や補足事項
プライベートネットワーク
企業内システムなど、特定のプライベートネットワーク内でのみ利用されるアプリケーションの場合、インターネットを経由せずにアクセスできる。
この場合、VPN(Virtual Private Network)などを使用してプライベートネットワークに接続する必要がある。
ローカルネットワーク
ローカルネットワーク内でのみ利用されるアプリケーションの場合、インターネットを経由せずにアクセスできる。
例えば、家庭内LANで動作するファイル共有サーバーなどが該当する。
デプロイの目的
デプロイは、必ずしもインターネット公開を意味するものではない。
例えば、ステージング環境(本番環境に近いテスト環境)にデプロイする場合、インターネットからアクセスできないように設定することもある。
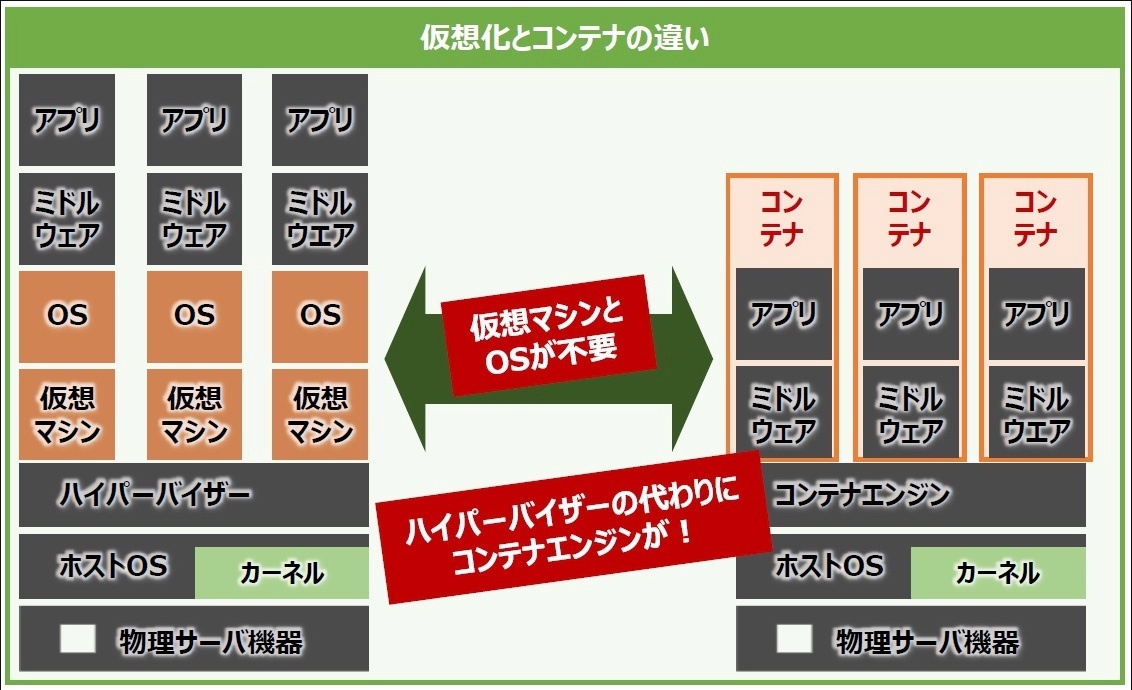
コンテナ
コンテナは、ホストOSのカーネル上で動作するプロセス
仮想マシンとは異なり、コンテナは独自のOSカーネルを持たず、ホストOSのカーネルを共有する。
→ コンテナは軽量で高速に起動できる
名前空間やコントロールグループなどのLinuxカーネルの機能を使用して、他のプロセスから隔離された環境を提供する。
→コンテナ内で動作するアプリケーションは、他のコンテナやホストOSに影響を与えずに実行できる
コンテナ内でアプリケーションが起動すると、それはコンテナのプロセスとして動作する。
構造
基本構成
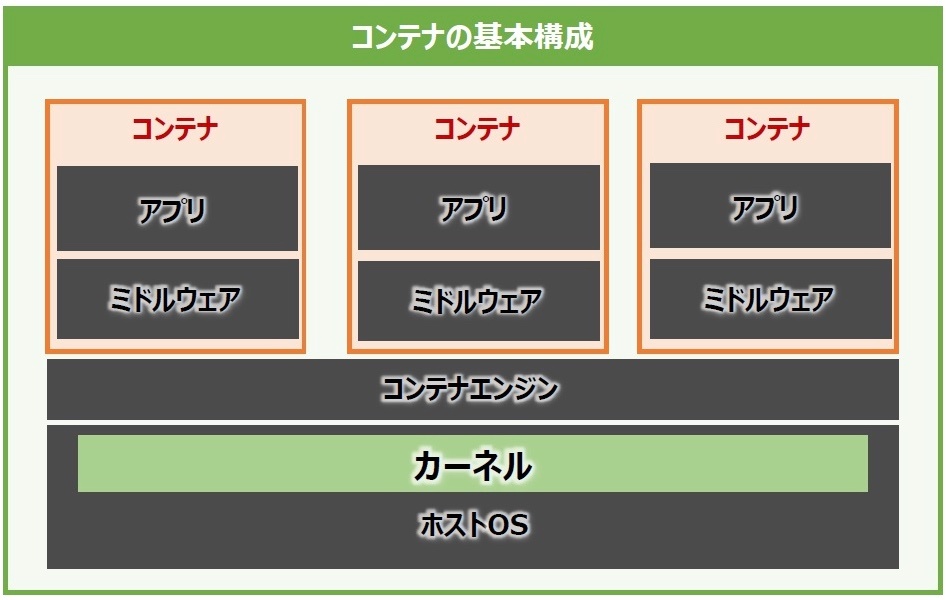
コンテナ型仮想化では、その実行基盤としてハードウェアとOSを共有する。
コンテナは単一のホストOS上で動作するコンテナエンジン上にプロセスとして存在し、そのエンジンが管理するシステムリソースの範囲内で、複数のコンテナを同時に動作させることができる。
コンテナの中には、ユーザが動作させたい「アプリケーション」と、そのアプリケーションの実行に必要な「ミドルウェア」、そして「ライブラリ」などが含まれる。このライブラリの中にはOSの基本的なコマンドセットやファイルシステムのライブラリなど、OSが提供する機能の一部が含まれている。
OSは動作させずにそれっぽい動作環境を再現している
=OS起動は不要。コンテナにおけるアプリケーションの起動方法を知ると理解できる。
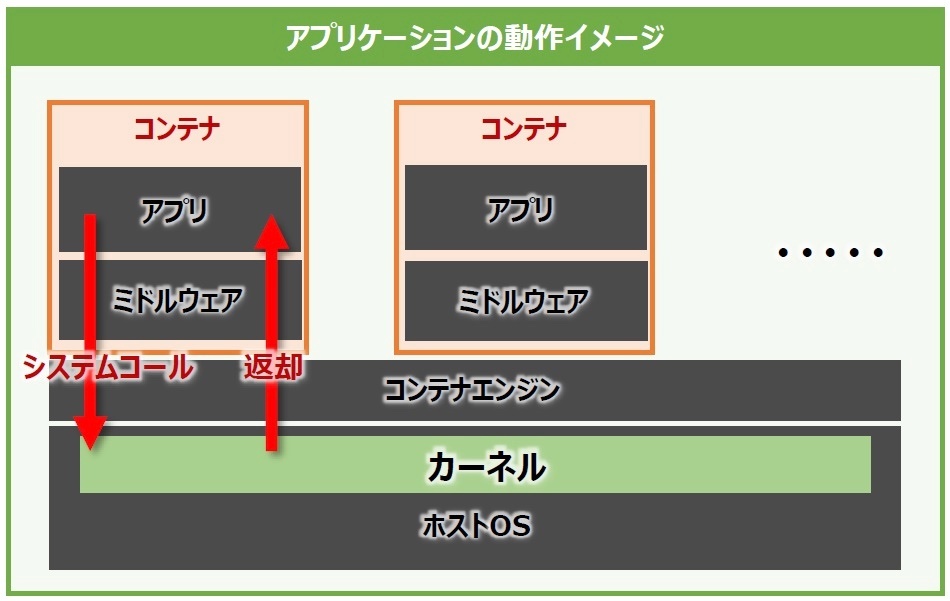
アプリケーションの起動方法
アプリケーションは、内部でOSの中核であるカーネルの機能を呼び出して動作している。
→ カーネルがシステムコールを処理することでアプリケーションを動作させている
異なるOSでも動作するコンテナ
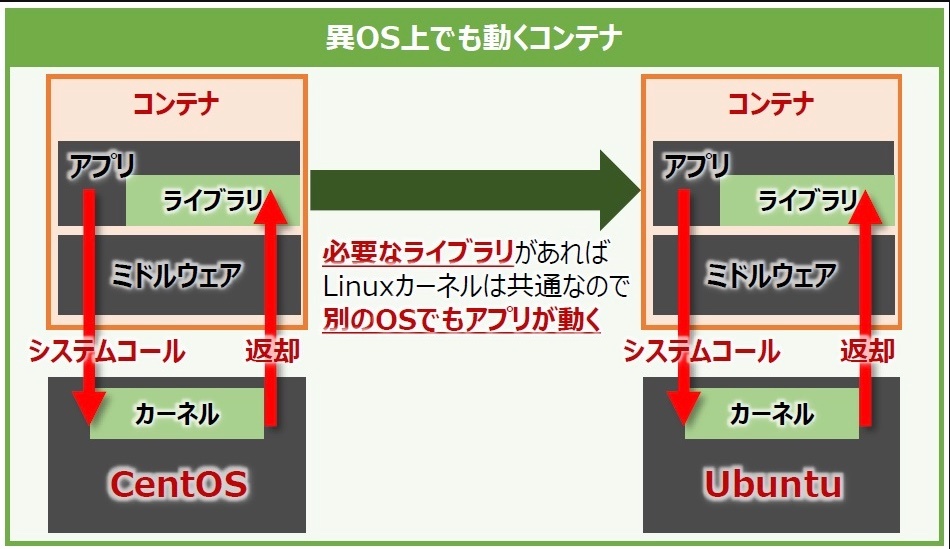
OSのコンテナイメージはあくまでもアプリケーションの動作に必要な環境を「それっぽく」再現しているに過ぎない点に注意すること。
コンテナの動作に必要なリソースはホストOSからコンテナエンジンを通して間借りしており、コンテナ内のアプリケーションが発行するシステムコールはホストOSで動作しているカーネルが処理する。ハイパーバイザー型仮想化のように個別のOSは存在しないため、コンテナ型仮想化ではLinuxカーネルの互換性に依存する。この点でコンテナ型仮想化はハイパーバイザー型仮想化と異なる。OS固有の機能を含めた動作環境を再現するには、コンテナ型仮想化よりもハイパーバイザー型仮想化を使用する方が良いと言える。
このように、Linuxにおけるアプリケーション(とその実行環境)を仮想のコンテナとして分離する方式を「Linuxコンテナ」と呼ぶ。一般にコンテナとは、このLinuxコンテナを指すことが多い。Linuxコンテナの技術を使用しているコンテナ型仮想化は、そのベースであるLinuxカーネルが持つ高い互換性によって支えられている。
◎カーネルはOSの中核。コンテナ上のアプリケーションを動かすためにはホストOSのカーネルとの互換性が重要
コンテナのプロセス
コンテナとプロセスの関係について
コンテナはNamespace、Cgroup、Capabilityなどの要素技術を駆使してプロセスやシステムリソース、権限などを分離し、管理することで1つのプロセスとして実行される。
ハイパーバイザー型仮想化における物理サーバと仮想サーバは、それぞれが1つのサーバ環境として位置付けられる。
コンテナ型仮想化におけるコンテナは、ホストOS上からは1つのプロセスとして扱われるという大きな特徴がある。
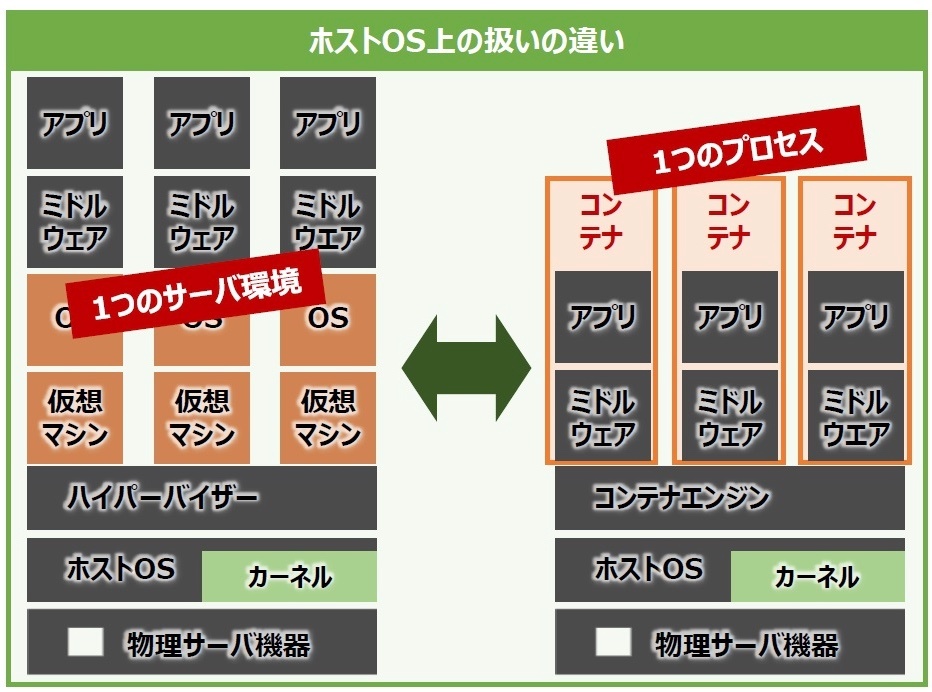
これは、例えるなら皆さんのパソコン(ホストOS)と、この記事を表示しているブラウザ(プロセス)と同じような関係性と考えることができる。
コンテナはどのようにしてこれらを実現しているのか。
コンテナはいくつかの要素技術を組み合わせることで実現している。その中でも代表格ともいえるLinuxカーネル機能のNamespace、Cgroup、Capabilityに焦点を当てて、1つずつ見ていく。
Namespace
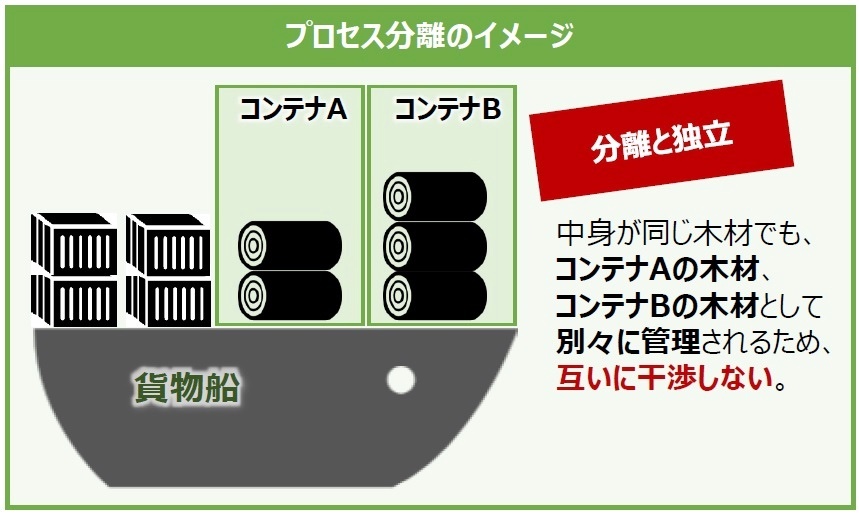
各プロセスに対してシステムリソースそれぞれをその他のプロセスと分離する役割を担っている。
例えば、ユーザIDやホスト名、ネットワークインターフェイスの分離などがある。この機能によりコンテナAのプロセスとコンテナBのプロセスは隔離されるので、互いに干渉せずにプロセスを稼働できる。
cgroup
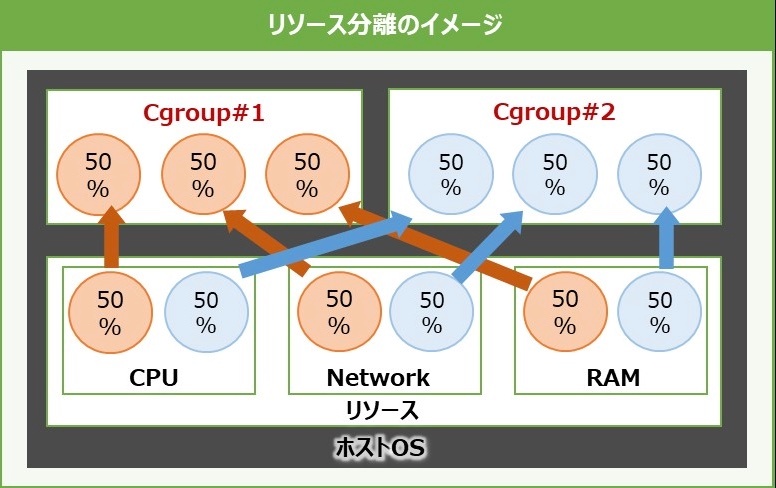
プロセスをグループ化し、CPUやメモリなどホストOSの物理的なリソースを分離する役割を担う。
例えば、プロセスが用いるCPUの使用率やメモリの割当、デバイスへのアクセスを制御する。1つの特定のプロセスがCPUやメモリリソースを大量に消費することで、ホストOSや他のプロセスに影響が出るといったリスクをコントロールする。
Capability
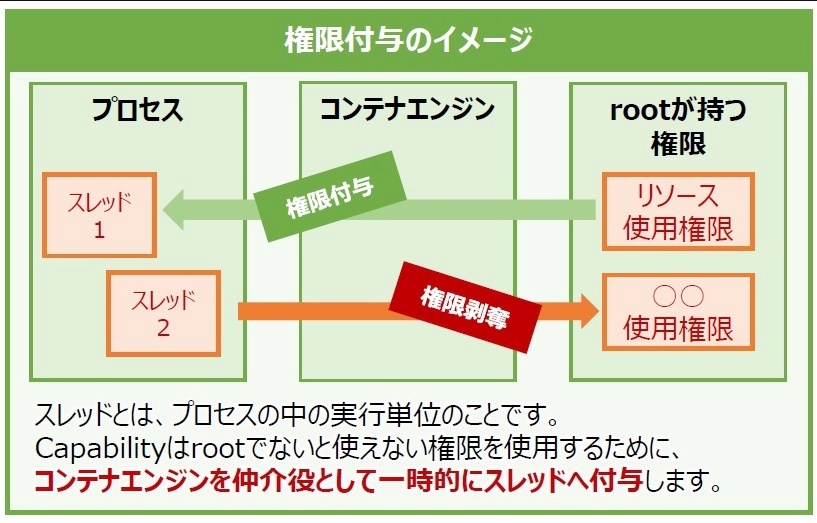
root権限を細かく分けてプロセスやファイルに付与する機能を担う。
root権限はスーパーユーザと言われるだけに、システムのほぼ全ての操作が可能となる権限なので、仮にroot権限がそのまま付与されたプロセスに脆弱性があり悪用された場合、システムそのものを他者に乗っ取られてしまう危険性がある。
そのため、Capabilityを用いてプロセスなどに与える権限を最小限に制御することで、仮に実行しているプロセスに脆弱性があったとしてもホストOSやほかのプロセスへの影響範囲をコントロールできる。
コンテナのネットワーク
コンテナとネットワークの関係について
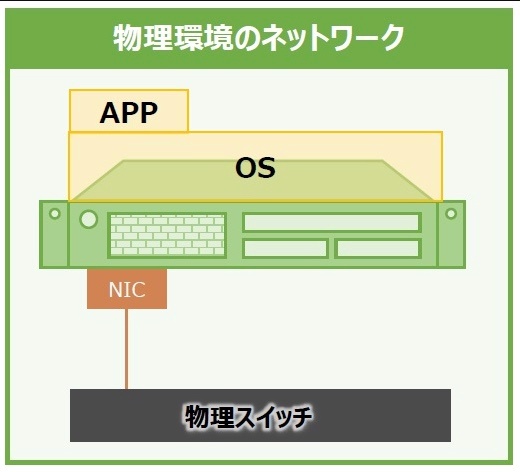
普通の物理サーバの通信方法
物理サーバには、物理的なNIC(Network Interface Card)が通信の出入り口として機能する。
例えると家の玄関のようなもの。NICに接続したLANケーブルでサーバ同士をつなげば通信自体は実現できるが、膨大な数のサーバを直接つなぐには限界がある。その限界を突破するにはケーブルを集約する集線装置、つまり「スイッチ」が必要になる。
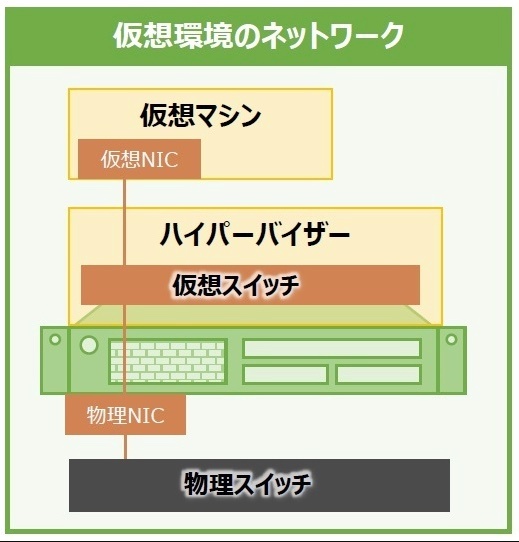
ハイパーバイザー型仮想化における仮想サーバの通信
ハイパーバイザー型仮想化では物理サーバ内に仮想サーバを作り、その上にゲストOSやアプリケーションを構築していく。
この仮想サーバには仮想NICがあり、IPアドレスやMACアドレスが割り当てられている。仮想サーバから外のネットワークと通信するときは、普通の物理サーバと同様に通信を束ねて管理する「仮想スイッチ」を経由する。
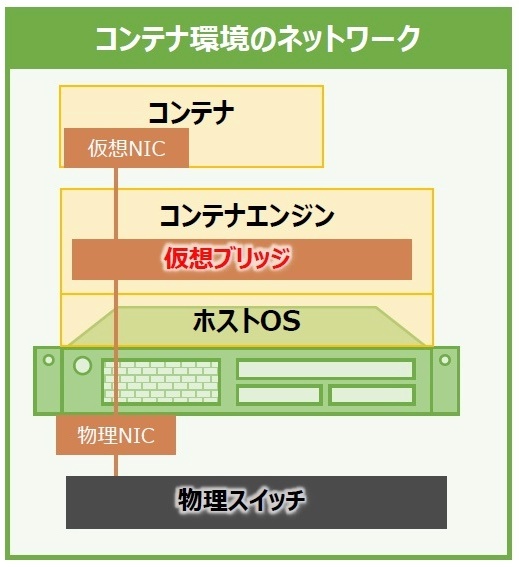
コンテナ型仮想化におけるコンテナの通信
物理サーバの物理NICとNamespaceで分離されたコンテナ内の仮想NICの間にコンテナエンジンで制御されている仮想ブリッジがあり、コンテナとホストOS間の橋渡しをしている。
ホストOSのNAT(Network Address Translation)機能により、コンテナのIPからホストOSが持つIPへ変換され、これでコンテナは外部と通信できるようになる。
https://thinkit.co.jp/article/17301 より画像・テキスト引用し、一部編集
ミドルウェア

※https://axia.co.jp/2023-08-21 より画像引用
ミドルウェアはソフトウェアの一種。「異なるシステムやアプリケーション間で仲介役を果たすソフトウェアコンポーネント」 と定義される。
ミドルウェアは「リクエスト → レスポンス」の間に実行される関数
next() で次の処理に進む(呼ばないとストップする)
ログ、認証、データ変換、エラーハンドリングなどに使われる
app.use() で登録し、複数チェーンできる
「リクエストが来たら、ミドルウェアで前処理 → ルート処理 → レスポンスを返す」
ミドルウェアが「ソフトウェア」と言える理由
(1)ソフトウェアの定義に合致する
ソフトウェア
→ コンピュータ上で動作するプログラムやデータの総称(OS、アプリ、ライブラリなど)
ミドルウェア
→ 「特定の機能を提供するプログラム」 として動作するため、ソフトウェアの一種
(2)具体的な形態で存在する
・ライブラリ形式(例: Express.js のミドルウェア)
・独立したサーバー(例: メッセージブローカー「RabbitMQ」)
・組み込み型コンポーネント(例: データベース接続用ドライバー)
代表的な機能
・データベース接続
・セッション管理
・負荷分散
・セキュリティ
・トランザクション処理
・ログ
・認証
・エラーハンドリング
サーバー用途でのLinuxの重要性
Linuxは多くのWebサーバー、アプリケーションサーバー、データベースサーバーなどで使われており、そのようなサーバーは一度に多数のクライアントからのリクエスト(HTTPリクエスト、DBアクセスなど)を処理する必要がある。
並行処理と並列処理の違い
| 処理の種類 | 説明 | 例 |
|---|---|---|
| 並行処理(Concurrency) | タスクを切り替えながら、見かけ上同時に複数のタスクを処理 | 1つのCPUで複数のリクエストを切り替えながら処理する |
| 並列処理(Parallelism) | 実際に同時に複数のタスクを同時処理 | 複数のCPUコアで別々のリクエストを同時に処理する |
重要な理由
① クライアントからの多数リクエストを処理するため
例えばWebサーバー(ApacheやNginx、Node.jsなど)は、同時に何百・何千ものリクエストを処理しなければならない。
リクエストの処理が遅れると、ユーザーの待ち時間が増え、UXが悪化する。
② ハードウェア性能を最大限に活かすため
マルチコアCPUが一般的になっている今、並列処理を活用することで、パフォーマンスを向上させることができる。
Linuxはマルチスレッドやプロセスの仕組みを使って、これをうまく制御している。
③ バックグラウンド処理やバッチ処理の効率化
サーバーはWebリクエストだけでなく、定期的なバッチ処理、ログのローテーション、ファイル圧縮などのバックグラウンド処理も行なう。
これらを非同期・並行に処理することで、サーバー全体の応答性が高まる。
共通のリソースを効率よく利用する重要性
サーバーが大量のリクエストを捌きながら自身の処理も行うためには、CPUやメモリ、I/O(ディスク・ネットワーク)などの「共通リソース」をいかに無駄なく効率よく使うかが極めて重要
共通リソースの種類
| リソース | 具体例 |
|---|---|
| CPU | リクエスト処理、暗号化処理、アプリのロジック実行 |
| メモリ | 各プロセスやスレッドの作業領域、キャッシュなど |
| ディスク | ログ書き込み、ファイル読み込み |
| ネットワーク | クライアントとの通信、外部APIとの接続 |
| DB接続 | 接続プールを使い複数リクエストで共有 |
効率よく使うことが重要な理由
① 無駄が多いとボトルネックになる
たとえば、全リクエストがディスクI/O待ちになるとCPUは暇になる。
逆に、CPUが1つの重い処理で占有されると他の処理が止まる。
② 大量リクエストに耐えられない
無駄にスレッドやプロセスを作るとメモリ不足になる。
1リクエストごとに新しいリソースを確保していたら、スケーラビリティが下がる。
③ 自身の処理と外部からのリクエストを両立するには工夫が必要
サーバー自身もログ出力やバックグラウンドジョブ、セキュリティチェックなどの自律的な処理を持っている。
それをやりつつ、リクエスト応答も落とさないためには、非同期処理、リソース共有、適切なスケジューリングが必要。
Webサーバーの効率的リソース活用
| 処理 | 効率化の仕組み |
|---|---|
| HTTPリクエスト受付 | 非同期I/O(epollなど) |
| DBアクセス | コネクションプール(再利用) |
| ログ書き込み | バッファリング、非同期書き込み |
| ファイル送信 | カーネル空間での送信(sendfile) |
| リクエスト分散 | プロセスやスレッドのロードバランス |
サーバーは「自身の処理」+「大量リクエスト」というマルチタスクをこなす必要があるため、共通リソース(CPU、メモリ、I/Oなど)を無駄なく効率的に使うことが不可欠。
これこそが、並行処理/並列処理+リソース管理(スレッドプール、非同期I/O、キャッシュ、制限付きキューなど)がLinuxサーバーで重視される理由。
Linuxにおける内部実装の特徴(プロセスとスレッドの関係)
clone() システムコール
Linuxでは、プロセスとスレッドの両方を作るのに clone() という低レベル関数を使う。
・clone() に渡すフラグによって、どこまで共有するかを細かく制御可能
・fork() は clone() を使ったラッパーで、メモリ非共有の完全な子プロセスを作る
・pthread_create() は clone() を使って メモリ共有のスレッド を作る
マルチスレッドとマルチプロセスの違いと使い分け
| 項目 | マルチプロセス | マルチスレッド |
|---|---|---|
| メモリ空間 | 独立 | 共有 |
| 安全性 | 高い(他の影響を受けにくい) | 低い(競合注意) |
| 通信コスト | 高い(IPCが必要) | 低い(変数をそのまま使える) |
| 作成/破棄コスト | 高い | 低い |
| 用途 | 安全性重視(Apacheなど) | パフォーマンス重視(Nginxなど) |
実用例
Webサーバー(Apache vs Nginx)
・Apache:マルチプロセス方式(各リクエストに対してプロセスやスレッドを割り当てる)
・Nginx:イベントループ + 少数スレッド(非同期I/Oによる高効率処理)
まとめ
| 要点 | 内容 |
|---|---|
| プロセス | 完全に独立した実行単位。安定性が高いが重い |
| スレッド | プロセス内での軽量な並行実行。効率がよいが、共有メモリの管理が難しい |
| Linux内部 |
clone() によってプロセスもスレッドも実現している |
| 使い分け | 安全性重視ならプロセス、性能重視ならスレッド(もしくは非同期) |
Linuxにおける並行処理の仕組み
1. プリエンプティブ・マルチタスク
Linuxカーネルは各プロセス/スレッドに CPU時間を短時間ずつ割り当てて切り替える。
これにより、実際は1つのCPUでも「同時に動いているように見える」並行処理が可能になる。
2. スレッドによる並行処理
pthread や std::thread(C++)などでスレッドを作成すれば、複数のタスクを並行して処理できる。
3. 非同期I/O(イベントループ)
非同期にリクエストを受け付け、I/Oを待っている間は他の処理に回る。
代表例:select, poll, epoll(高効率イベント通知)
※Nginx や Node.js がこのモデルを採用しています。
Linuxにおける並列処理の仕組み
1. マルチプロセッシング(MP)
Linuxカーネルが 複数のCPUコアにタスクを割り当てる。
例:Webサーバーがリクエストごとにワーカープロセスを生成して並列に処理
2. マルチスレッディング
スレッドが異なるCPUコアで同時実行されれば並列処理になる。
例:動画変換ソフトなどの重い処理を複数スレッドで同時進行
3. SMP(対称型マルチプロセッシング)
Linuxは複数CPU(コア)を均等に扱えるOS(SMP対応)。
タスクをどのコアに割り当てるかはスケジューラが自動的に判断。
並行処理と並列処理は両立する
実際のLinuxシステムでは、
・並行処理(多くのリクエストをスムーズに捌く)
・並列処理(重い処理を同時に走らせる)
の両方を 組み合わせて使うことがほとんど。
Webサーバーの例
| 処理 | 並行 or 並列 | 内容 |
|---|---|---|
| 複数リクエストの受信 | 並行処理 | epollでノンブロッキングに受信 |
| データベースアクセス | 並行処理 | 非同期またはコネクションプール |
| 圧縮処理 | 並列処理 | マルチスレッドで並列にGzip圧縮 |
開発時の意識ポイント
| ポイント | 説明 |
|---|---|
| 競合状態の回避 | 並行・並列どちらでも共有データへの同時アクセスは危険。排他制御(ミューテックス、セマフォ)が必要 |
| スレッドセーフ設計 | 並列実行に備えて、変数の扱いを安全に設計する必要がある |
| リソースの使いすぎに注意 | 並列処理=何でも高速化ではなく、CPUやメモリの制約を超えると逆効果 |
| スケジューラと親和性 | Linuxのスケジューラは公平性・効率を両立させるが、設計によってはうまく機能しないこともある |
※スレッドセーフとは、複数のスレッド(処理の単位)が同時にアクセスしても安全に動作すること
複数のスレッドが同じ変数やデータを同時に読み書きすると、データが壊れたり(不整合が起きる)、プログラムが予期せぬ動作をしたり、クラッシュしたり、という問題が起こる。
※スレッドセーフにする方法
・排他制御(mutexやロック)を使って、同時に一つのスレッドだけが操作できるようにする
・原子操作(atomic operation)を使って、一連の操作を中断できない形で実行する
・スレッドごとにデータを分ける(共有しない)
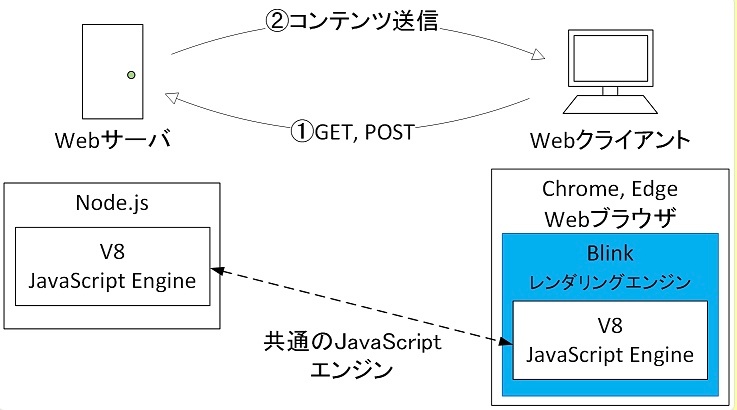
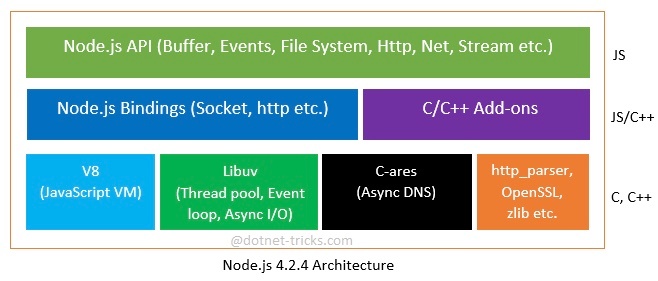
Node.js
※https://cs-tklab.na-inet.jp/nodejs/nodejs/nodejs.html より画像引用
Node.js は Linux 上で非常に高い親和性を持ち、Linuxの仕組み(特に非同期I/Oやイベントループ)を最大限活用するように設計された実行環境
JavaScriptをサーバーサイドで動かせるようにしたランタイム環境
中身
・V8エンジン(Google ChromeのJSエンジン)
・libuvライブラリ(非同期I/Oとイベントループの実装)
・C/C++で書かれた低レイヤコード(Linux APIと直接やりとり)
アーキテクチャ
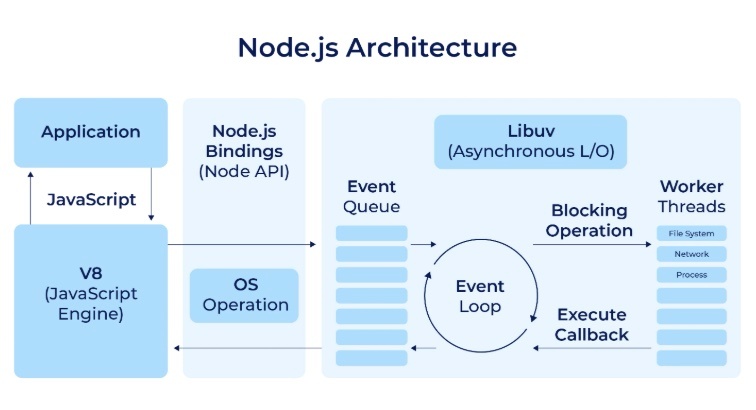
※https://litslink.com/blog/node-js-architecture-from-a-to-z より画像引用
Node.js と Linux の技術的な関係
① libuv:Linuxの非同期I/O APIを活用
Node.js の核である libuv は、Linuxの以下の仕組みを利用して非同期I/Oを実現する
| Linuxの技術 | 内容 | Node.jsでの役割 |
|---|---|---|
epoll |
非同期でファイル/ソケットのイベントを監視 | イベントループに使われる |
fork, exec, pipe
|
プロセス制御やIPC(プロセス間通信) |
child_process モジュールなど |
select, poll
|
古いI/O多重化API(epollの前身) |
fallback的に使われることも |
| POSIXスレッド(pthreads) | マルチスレッド実行 | I/Oスレッドプールに使われる |
Node.jsは、Linuxのシステムコールにかなり近い部分までアクセスしているため、性能や制御に優れている。
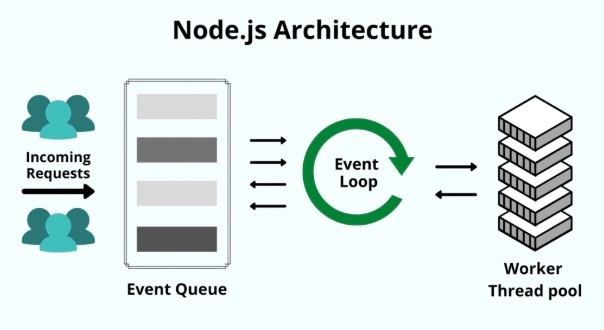
※https://kinsta.com/it/knowledgebase/node-js/ より画像引用
② UNIX哲学との親和性
Node.jsは以下のUNIX的な設計とよく合う
・小さなモジュールで処理を分ける
・標準入出力(stdin/stdout)を活用する
・非同期で効率よく処理を流す
◎LinuxはUNIX系OSなので、Node.jsとの相性は抜群
③ 実運用でも Linux が主流
Node.js は Linuxサーバー上での本番運用が非常に多い
・軽量:Node.jsもLinuxも軽量なので、小規模〜大規模まで柔軟に運用可
・スケーラブル:Node.jsのイベントループ+Linuxのマルチプロセス対応で高負荷にも耐えられる
・Dockerやクラウド対応が容易:LinuxベースのDockerイメージでNode.jsアプリを簡単にデプロイできる
Node.jsサーバー
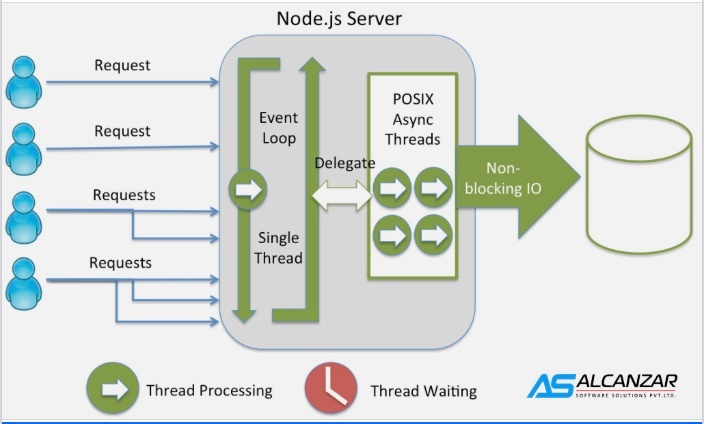
※https://www.facebook.com/alcanzarsoft/posts/nodejs-is-an-open-source-cross-platform-built-on-chromes-javascript-runtime-for-/1048360861981734/ より画像引用
Node.jsの特徴
| 特徴 | 説明 |
|---|---|
| 非同期・イベント駆動 | 多数のリクエストを効率よく処理できる |
| 軽量・高速 | GoogleのV8エンジンを使っていてとても速い |
| シングルスレッド | 1本のスレッドで動くが、I/O処理をブロックしない仕組みがある |
| npmというパッケージ管理 | 世界中の便利なモジュールがすぐ使える |
シングルプロセス・シングルスレッド
※https://cs-tklab.na-inet.jp/nodejs/nodejs/nodejs.html より画像引用Node.jsはシングルプロセスとシングルスレッドで動作します.ここでのプロセスは実行中のプログラムのことを指し,プロセスの中には1つ以上のスレッドがあります.スレッドは簡単に言うと逐次実行する処理のことを指します.
一見するとシングルプロセス・シングルスレッドでは,複数の処理に対応できないように感じます.代表的なWebサーバーのApache(prefork)のように複数のプロセスやスレッドをリクエスト毎に構成した方が確実に同時に処理を捌けます.
ではなぜ,Node.jsはシングルプロセス・シングルスレッドを採用しているのでしょう.それは大量のリクエスト時のメモリ領域を削減するためです.マルチプロセスではリクエスト毎にプロセスやスレッドを立てます.これはアクセスが増えれば増えるほどメモリ領域を圧迫してしまいます.これをC10K問題といいます.
Node.jsのシングルプロセス(シングルスレッド)を実装するために非同期 I / Oを利用しています.「I / O」とはWebアプリケーション外部との入出力処理のことです.ファイルの読み込みや,データベースとの接続がこれに当たります.
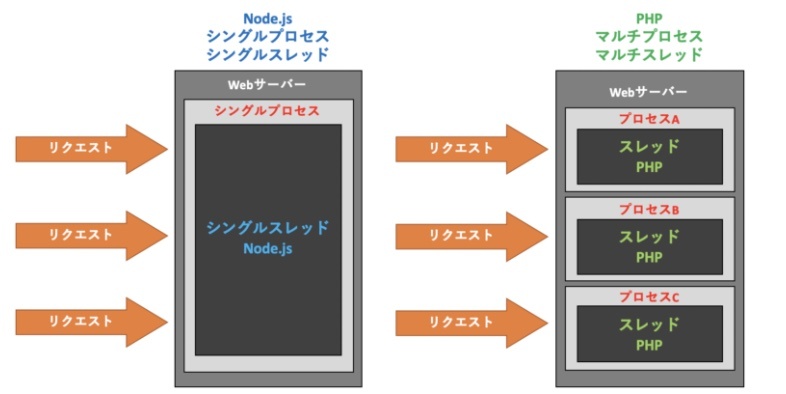
Node.jsの用途
・Webアプリのサーバー(例:チャットアプリ、ECサイト)
・REST API(モバイルアプリと通信する裏側)
・リアルタイム通信(例:Slack、ゲーム)
・CLIツール(コマンドラインで使う便利ツール)
┌────────────────────────────┐
│ Node.js(アプリ実行環境) │ ← 書いたJSがここで動く
├────────────────────────────┤
│ Linux(OS、システムコール) │ ← ファイル操作やネット通信の土台
├────────────────────────────┤
│ ハードウェア(CPU, メモリ等) │
└────────────────────────────┘
Node.jsは、「JavaScriptで作ったプログラムを動かしてくれるエンジン」
Linuxは、「Node.jsを含めたすべてのプログラムが使う共通の土台(OS)」
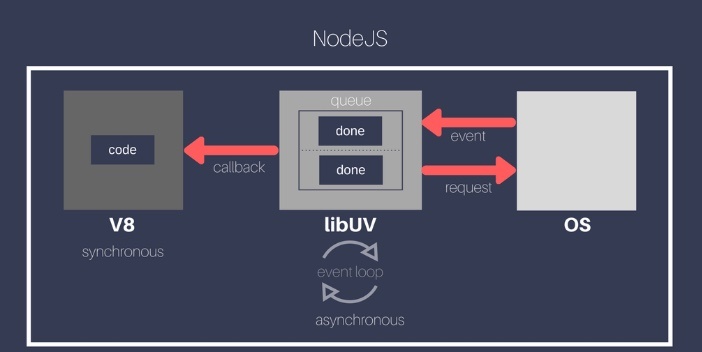
Node.jsはJavaScriptだけで完結しているわけではない
裏では、C/C++で書かれた「libuv(リブユーブ)」というライブラリがOSとやり取りしている
※https://www.scholarhat.com/tutorial/nodejs/exploring-nodejs-architecture より画像引用
※https://thewebstop.blogspot.com/2017/09/why-nodejs-is-asynchronous.html より画像引用
構造
JavaScript(記述したコード)
↓
Node.jsのAPI(fs, httpなど)
↓
libuv(C/C++製、イベントループや非同期処理を制御)
↓
Linuxのシステムコール(open, read, socket など)
↓
カーネル(Linux OSが実際に処理を行なう)