【SQL】インデックスについてまとめてみた
はじめに
以下は『スッキリわかるSQL入門 第2版』を読んでわかったことをまとめていきます。
データベースをより速くする
検索を速くする方法
最も効率が良いのは、索引を使って検索すること
インデックスの作成と削除
インデックス(index): データベースで作成できる索引情報
- 指定した列に対して作られる(列ごとに作られる)
- インデックスが存在する列に対して検索が行われた場合、DBMSは自動的にインデックスの使用を試みるため、高速になることが多い
※検索の内容によっては、インデックスの利用はできず、性能が向上しないこともある - インデックスには名前をつけなければならない
インデックスのイメージ
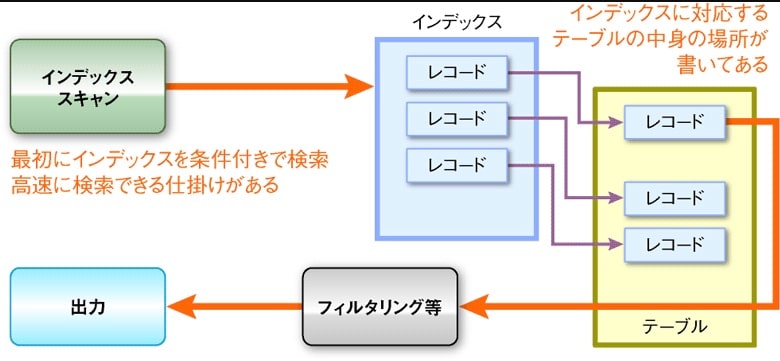
※ https://gihyo.jp/admin/serial/01/rdbms-autumn-sky/0003 より画像引用
インデックスを作成するには、DDLに属する CREATE INDEX 文を使う
CREATE INDEX インデックス名 ON テーブル名(列名)
CREATE INDEX メモインデックス ON 家計簿(メモ)
DROP INDEX インデックス名
※ MySQLやMariaDBでは「ON テーブル名」を付ける
複合インデックス: 複数の列を1つのインデックスとする
高速化のパターン
ケース1: WHERE 句による絞り込み
SELECT *
FROM 家計簿
WHERE メモ = '不明'
完全一致検索: 全く同じ値であることを条件とした検索
前方一致検索: 先頭から一致することを条件とした検索
部分一致検索: 任意の部分が一致することを条件とした検索
後方一致検索: 末尾の部分が一致することを条件とした検索
完全一致検索では、インデックスが使用され、高速に検索結果を得ることができる
DBMSの種類やインデックスの内部構造にもよるが、文字列比較の場合、完全一致ではなく前方一致検索の場合でもインデックスを利用した高速な検索が行われることがある
※ 部分一致検索や後方一致検索では、インデックスを利用できない
SELECT *
FROM 家計簿
WHERE メモ
LIKE '1月の%'
ケース2: ORDER BY による並び替え
インデックスには並び替えを高速に行えるようにする効果もあるため、ORDER BYの処理が速くなる
SELECT *
FROM 家計簿
ORDER BY 費目ID
ケース3: JOINによる結合の条件
結合処理は内部で並び替えを行なっているため、インデックスのある列を使うと高速になる
SELECT *
FROM 家計簿
JOIN 費目
ON 家計簿.費目ID = 費目.ID
一般的にインデックス設定の効果が高い例
- WHERE句に頻繁に登場する列
- ORDER BY句に頻繁に登場する列
- JOINの結合条件に頻繁に登場する列(外部キーの列)
インデックスの注意点
インデックスを作成することによるデメリット
- 索引情報を保存するために、ディスク容量を消費する
- テーブルのデータが変更されるとインデックスも書き換える必要があるため、INSERT文・UPDATE文・DELETE文のオーバーヘッドが増える
インデックスが作成されている列のデータを変更する場合、DBMSはその度にインデックス情報を更新する必要があり、更新処理に時間がかかるようになってしまう
◎インデックスは乱用しない
検索性能は向上するが、書き換え時のオーバーヘッドが増加する
参考文献
『スッキリわかるSQL入門 第2版』
Discussion