TypeScriptで 関数型プログラミング x DDD を実現する
本記事はZennの記事投稿コンテスト「TypeScriptでやってみた挑戦・学び・工夫」の参加記事となっています。
なぜこのテーマを選んだのか
私は業務でF#という言語を用いて、DDD(ドメイン駆動開発)、関数型プログラミングを実践しています。練度を上げ、 エンジニアとしてステップアップしたい! と思っています。
そこで最近話題になっていた、「Domain Modeling Made Functional」を読み、関数型プログラミング(F#)とDDDを組み合わせたアプローチを学んだので、「TypeScriptで実践してみたら、これまで書いて来たコードがどれだけ改善されるか」を検証してみたいと思いました。
業務コードが複雑になると
これまでの経験上、最初は丁寧に作られたコードでも、時間が経つにつれて、業務要件の変更や新機能の追加に伴い、コードが複雑化していくことが多いです。継ぎ足し継ぎ足しで機能が追加され、コードが複雑になってくると、以下のような問題が発生します。
- nullチェックが散らばる
- バリデーションがあちこちに書かれている
- 例外処理が不明瞭
- テストが書きにくい
- 型安全性が低下
- などなど
これらの問題は、関数型プログラミングやDDDの原則を適用することで解決できると考えています。
実装したコード
今回実装したコードは以下のリポジトリで公開しています。
ディレクトリ構成は以下のようになっています。
src/
├── db/ # データベース
├── functional-ddd/ # 関数型 + ドメイン駆動設計
| └── package-lock.json
├── es/ # Elasticsearch
| ├── articles.json # ダミーデータ
| ├── compose.yaml # Elasticsearchのコンテナ定義
| └── es_setup.sh # Elasticsearchの初期化スクリプト
├── imperative/ # 命令型
| └── package-lock.json
├── README.md
└── test.http
-
esディレクトリには、Elasticsearchのダミーデータと初期化スクリプトがあります。 -
imperativeディレクトリには、命令型プログラミングのコードがあります。 -
functional-dddディレクトリには、関数型プログラミングとDDDを適用したコードがあります。(本記事で紹介するコード)
使用ライブラリについて
本記事では、関数型プログラミングの文脈で fp-ts を使用しています。
fp-tsは、TypeScriptで関数型プログラミングを実現するためのライブラリで、Option, Either, TaskEither などの型を提供してくれます。これにより、副作用の制御やエラーハンドリング、関数合成(pipe)などを型安全に行うことができます。
import { pipe } from "fp-ts/function";
import { TaskEither, tryCatch, chain } from "fp-ts/TaskEither";
関数型パターンに不慣れな場合は、少しとっつきにくい部分もありますが、型の力でバグを減らすことができます。
実装したアーキテクチャ
今回は、クリーンアーキテクチャを採用し、以下のような構造で実装しました
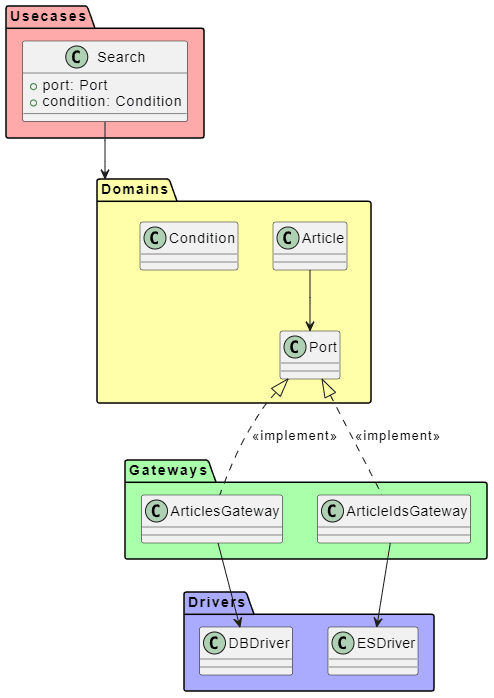
- 最も内側の
Domain層は、普遍的なビジネスルールを含みます -
Usecase層は、アプリケーション固有のビジネスルールです -
GatewayとHandler層は、外部システムとの接続を担当します -
Driver層は、フレームワークやデータベースなどの具体的な実装を提供します
この構造により、以下の利点が得られます
- 依存関係が内側に向かう(依存性逆転の原則)
- ビジネスロジックがフレームワークから独立
- テストが容易
- 外部システムの変更に強い
ドメインモデルの実装
まず、記事(Article)のドメインモデルを実装します。Value Objectパターンを使用して、型安全性を確保しました。
// Domain/Article.ts
export class ArticleIds {
constructor(private _ids: ArticleId[]) {}
get values(): string[] {
return this._ids.map((id) => id.value);
}
}
export class ArticleId {
constructor(private _value: string) {}
get value(): string {
return this._value;
}
}
export class ArticleTitle {
constructor(private _value: string) {}
get value(): string {
return this._value;
}
}
export class ArticleBody {
constructor(private _value: string) {}
get value(): string {
return this._value;
}
}
export class Article {
constructor(
private readonly _id: ArticleId,
private readonly _title: ArticleTitle
) {}
get id(): string {
return this._id.value;
}
get title(): string {
return this._title.value;
}
}
export class Articles {
constructor(private readonly _articles: Article[]) {}
get articles(): Article[] {
return this._articles;
}
}
検索条件のドメインモデル化
検索条件もドメインモデルとして実装し、ビジネスルールを型として表現します。
本実装では、検索条件を「バリデーション前(UnValidateSearchCondition)」と「バリデーション後(ValidateSearchCondition)」の2つのドメインオブジェクトとして表現しています。
-
バリデーション前の
UnValidateSearchConditionは、外部から受け取った生の値(string型や未加工の値)を保持します。 -
バリデーション後の
ValidateSearchConditionは、型や値の検証を通過した安全な状態のみを保持します。コンストラクター関数をprotectedにして、外部からの直接インスタンス化を禁止しています。
このように段階を分けてドメインモデル化することで、アプリケーションの各層で「どの段階のデータなのか」を明確に区別でき、型安全性やビジネスルールの担保がしやすくなります。
// Domain/SearchCondition.ts
export class UnValidateSearchCondition {
constructor(
public query?: string,
public limit?: string,
public offset?: string,
public sort?: string
) {}
}
export class ValidateSearchCondition {
// コンストラクター関数をprotectedに
protected constructor(
private readonly _query: string,
private readonly _limit: number,
private readonly _offset: number,
private readonly _sort: "asc" | "desc"
) {}
static apply(
c: UnValidateSearchCondition
): ValidateSearchCondition {
...省略
}
}
ユースケースの実装
検索のユースケースを実装し、ドメインロジックを適用します。
ユースケースではドメインロジックをパイプで呼ぶことで、ドメイン駆動を意識しました。
// Usecase/SearchArticles.ts
import {
Articles,
findByIds,
searchArticleIds,
SearchArticleIdsError,
} from "../Domain/Article.js";
import type { ValidateSearchCondition } from "../Domain/SearchCondition.js";
import {
SearchArticlesError,
type FindByIds,
type SearchArticleIds,
} from "../Domain/Article.js";
import { pipe } from "fp-ts/lib/function.js";
import { chain, mapLeft, type TaskEither } from "fp-ts/lib/TaskEither.js";
export interface Deps {
searchArticleIds: SearchArticleIds;
findByIds: FindByIds;
}
export const search = (
deps: Deps,
cond: ValidateSearchCondition
): TaskEither<SearchArticlesError, Articles> =>
pipe(
cond,
(c) => searchArticleIds(deps.searchArticleIds, c),
chain((ids) => findByIds(deps.findByIds, ids)),
mapLeft((e) => new SearchArticleIdsError(e.message))
);
テストの実装
ドメインロジックとユースケースのテストを実装しました。
// Domain/SearchCondition.test.ts
describe("SearchCondition", () => {
describe("ValidateSearchCondition", () => {
test("正しい検索条件ではOK", () => {
const result = ValidateSearchCondition.apply(
new UnValidateSearchCondition("query", "100", "10", "desc")
);
fold(
(error) => {
throw error;
},
(condition) => {
const expected = ConditionMock.gen("query", 100, 10, "desc");
expect(condition).toStrictEqual(expected);
}
)(result);
});
test("デフォルト値の確認", () => {
const result = ValidateSearchCondition.apply(
new UnValidateSearchCondition()
);
fold(
(error) => {
throw error;
},
(condition) => {
const expected = ConditionMock.gen("", 10, 0, "asc");
expect(condition).toStrictEqual(expected);
}
)(result);
});
describe("異常系", () => {
test("異常時にはValidationError型を返す", () => {
const result = ValidateSearchCondition.apply(
new UnValidateSearchCondition("query", "10000", "10", "desc")
);
fold(
(error: SearchConditionValidationError) => {
expect(error).toBeInstanceOf(SearchConditionValidationError);
},
(_) => {
throw new Error("バリデーションが通過してしまいました");
}
)(result);
});
describe("limit", () => {
test("limitが0以下", () => {
const result = ValidateSearchCondition.apply(
new UnValidateSearchCondition("query", "0", "10", "desc")
);
fold(
(error: SearchConditionValidationError) => {
expect(error).toBeInstanceOf(SearchConditionValidationError);
expect(error.message).toContain("limitは1以上で指定してください");
},
(_) => {
throw new Error("バリデーションが通過してしまいました");
}
)(result);
});
...
});
});
});
// Usecase/SearchArticles.test.ts
describe("Article", () => {
describe("ArticleIds", () => {
describe("search", () => {
test("検索することができる", async () => {
const s = async (_: ValidateSearchCondition) => {
return new ArticleIds([new ArticleId("1"), new ArticleId("2")]);
};
const cond = ConditionMock.gen("query", 100, 10, "desc");
const result = searchArticleIds(s, cond);
fold(
(error) => {
throw error;
},
(ids: ArticleIds) => async () => {
const expected = new ArticleIds([
new ArticleId("1"),
new ArticleId("2"),
]);
expect(ids).toStrictEqual(expected);
}
)(result)();
});
test("検索に失敗した時は特定のエラーを返す", () => {
const s = async (_: ValidateSearchCondition) => {
return new ArticleIds([new ArticleId("1"), new ArticleId("2")]);
};
const cond = ConditionMock.gen("query", 100, 10, "desc");
const result = searchArticleIds(s, cond);
fold(
(error) => {
throw error;
},
(ids) => async () => {
const expected = new ArticleIds([
new ArticleId("1"),
new ArticleId("2"),
]);
expect(ids).toStrictEqual(expected);
}
)(result)();
});
});
});
});
※ fold getOrElseの使い分け
ユースケースやドメイン層のテストでfoldを使い、エラー時に throw する構成を採用しましたが、これは好みや設計方針によって分かれる部分です。
fold(
(error) => { throw error },
(value) => { ... }
)(result);
このような明示的な throw は、テストコードに限定すれば読みやすくシンプルですが、本番コードで使う場合は副作用としての例外が混入し、関数型の文脈とは相性がよくありません。
代わりに getOrElse を使うことで、安全にデフォルト値や代替処理を実現できます。
import { getOrElse } from "fp-ts/Either";
const safeValue = result.pipe(
getOrElse(() => defaultValue)
);
目的に応じて、fold, getOrElse, match などを使い分けると、より意図が明確で、安全なコードになります。
学んだこと
1. ドメインモデルの設計
- プリミティブ型の代わりにドメインオブジェクトを使用することで、型安全性が向上し、よりドメインとして表現できました
- 例えば、
ArticleIdはstring型ではなく、ArticleId型のオブジェクトとして表現されています。
- 例えば、
// 例:ArticleIdをValue Objectとして実装
export class ArticleId {
constructor(private _value: string) {}
get value(): string {
return this._value;
}
}
2. クリーンアーキテクチャの利点
- 依存関係の方向を制御することで、ドメインロジックの純粋性を保てました
- インターフェースを介した依存性の注入により、テストが容易になりました
// 例:ポートの定義とユースケースでの利用
// Domain
export type FindByIds = (ids: ArticleIds) => Promise<Articles>;
export const findByIds = (
find: FindByIds,
ids: ArticleIds
): TaskEither<SearchArticlesError, Articles> => {
return tryCatch(
async () => find(ids),
() => new SearchArticlesError("記事の取得に失敗しました。")
);
};
// Usecase
export interface Deps {
searchArticleIds: SearchArticleIds;
findByIds: FindByIds;
}
3. テスタビリティの向上
- ドメインロジックの単体テストが容易になりました
- モックを使用したユースケースのテストが簡単になりました
- テストファーストな開発が可能になりました
// 例:SearchConditionのテスト
test("正しい検索条件ではOK", () => {
const result = ValidateSearchCondition.apply(
new UnValidateSearchCondition("query", "100", "10", "desc")
);
fold(
(error) => {
throw error;
},
(condition) => {
const expected = ConditionMock.gen("query", 100, 10, "desc");
expect(condition).toStrictEqual(expected);
}
)(result);
});
4. コードの可読性向上
- ドメインモデルがビジネスルールを表現することができました。
工夫したポイント
1. ドメインモデルの設計
- 検索条件もドメインモデルとして実装し、ビジネスルールをコードで表現
- Value Objectを活用して、ドメインの概念を型として表現
2. アーキテクチャの設計
- クリーンアーキテクチャの採用による依存関係の制御
- ユースケースではドメインロジックを組み合わせて並べるだけにし、ビジネスルールの詳細はドメイン層に委譲するよう工夫
3. テストの実装
- ドメインモデルの単体テストの実装
- ユースケースのテストでのモックの活用
- テストファーストな開発アプローチの採用
まとめ
TypeScriptでDDDとクリーンアーキテクチャを組み合わせることで以下のような利点が得られました。
- ドメインロジックの明確な表現
- 型としてビジネスルールを表現でき、意図しない使い方を防止できます。
- 外部依存からの分離
- データベースやフレームワークの影響を受けにくく、変更にも強くなります。
- テスタビリティの向上
- 各層が疎結合になるため、ユニットテストを書きやすくなります。
- コードの保守性向上
- ディレクトリ構成と責務の明確化により、プロジェクトが大きくなっても読みやすさを維持できます。
- ビジネスルールの型による表現
- モデルレイヤーでのバリデーションや制約を型で担保できるため、ロジックの重複が減ります。
これらの改善により、長期的なメンテナンス性が向上し、ビジネスルールの変更に強いコードを書くことができるようになりました。
まだまだ発展途上ですが、これからも関数型プログラミングとDDDを実践していきたいと思います。
参考資料
実装したサンプルコードは以下のリポジトリで公開しています:
Discussion