AppleのヘルスケアデータをRailsで読み込む所業 by Nokogiri
RubyでXMLファイルなんて解析するもんじゃねぇな。
ということで、貧弱メモリでiPhoneのヘルスケアデータをなんとかRailsで処理させる方法について、実装内容をベースにお伝えします。
※ HealthKitは使いません。代替方法としてご覧ください。
目的
iPhoneのヘルスケアアプリに記録した健康データの中から、睡眠記録を抽出する
前提条件
実装内容の前に、ヘルスケアに関する前提のお話をします。
ヘルスケアとは?
iPhoneユーザーにとってはお馴染み、デフォルトで入っているApple製の健康管理アプリケーションです。
iPhoneやApple Watchで運動・睡眠した記録を管理してくれます。
特に、睡眠に関しては他の睡眠スマホアプリで測定した記録と連携してくれるので、例えばポケモンスリープで記録したデータとかもここに蓄積してくれているわけですね。ポケスリはイイゾ。
👇ヘルスケアとの連携について
ヘルスケアデータを扱う手段
現状、ヘルスケアの記録を見る方法は大別して3つ。
- ヘルスケアアプリから確認する
- Swift言語でHealthKitデータを読み込む(HealthKit API)
しかしSwiftはさっぱりわからない
以下参考になった記事です。
- ヘルスケアアプリからXMLファイルをエクスポートする
2のやり方は言語的にわからないので、3のやり方が現実的かなと思いました。
また、データの加工結果をRailsに渡す必要があったので、Ruby言語に収まるならそれが理想的でした。
ヘルスケアアプリデータのエクスポート方法
AppleさんはiPhone以外のデバイスでデータを扱うことを考慮に入れてないのでしょう。データをエクスポートする方法はヘルスケアアプリにある
「すべてのヘルスケアデータを書き出す」
たったこれだけ!

数分かけて書き出すと、「書き出したデータ.zip」を保存することができます。
解凍したファイルは以下です。
- apple_health_export
- export_cda.xml
- export.xml
- workout-routes
- route_2025-08-08.4.53pm.gpxみたいなやつ
今回扱いたいファイルはexport.xmlのみ。
ちなみにこのファイルはヘルスケアを利用し始めてから今までの、運動記録や心拍数、睡眠記録がまるっと入っているので、私の2016~2025年データは脅威の総計40万行、921.2 MBでした。
export.xmlの中身どんな感じ?
運動記録など、色々入っていますが、特に今回抜粋したい睡眠レコードはこのように保存されています。
<Record type="HKCategoryTypeIdentifierSleepAnalysis" sourceName="野時計" sourceVersion="11.6" creationDate="2025-08-01 06:00:16 +0900" startDate="2025-08-01 05:29:23 +0900" endDate="2025-08-01 05:45:53 +0900" value="HKCategoryValueSleepAnalysisAsleepREM">
<MetadataEntry key="HKTimeZone" value="Asia/Tokyo"/>
</Record>
<Record type="HKCategoryTypeIdentifierSleepAnalysis" sourceName="野時計" sourceVersion="11.6" creationDate="2025-08-01 06:00:16 +0900" startDate="2025-08-01 05:45:53 +0900" endDate="2025-08-01 05:57:53 +0900" value="HKCategoryValueSleepAnalysisAsleepCore">
<MetadataEntry key="HKTimeZone" value="Asia/Tokyo"/>
</Record>
<Record type="HKCategoryTypeIdentifierSleepAnalysis" sourceName="Pokémon Sleep" sourceVersion="1440" creationDate="2025-08-01 06:22:12 +0900" startDate="2025-08-01 05:20:47 +0900" endDate="2025-08-01 06:00:47 +0900" value="HKCategoryValueSleepAnalysisAsleepREM">
<MetadataEntry key="HKTimeZone" value="GMT+0900"/>
</Record>
<Record type="HKCategoryTypeIdentifierSleepAnalysis" sourceName="Pokémon Sleep" sourceVersion="1440" creationDate="2025-08-01 06:22:12 +0900" startDate="2025-08-01 06:00:47 +0900" endDate="2025-08-01 06:17:37 +0900" value="HKCategoryValueSleepAnalysisAsleepCore">
<MetadataEntry key="HKTimeZone" value="GMT+0900"/>
</Record>
<Record type="HKCategoryTypeIdentifierSleepAnalysis" sourceName="Pokémon Sleep" sourceVersion="1440" creationDate="2025-08-01 06:22:12 +0900" startDate="2025-07-31 23:29:47 +0900" endDate="2025-08-01 06:17:37 +0900" value="HKCategoryValueSleepAnalysisInBed">
<MetadataEntry key="HKTimeZone" value="GMT+0900"/>
</Record>
- 睡眠に関する記録は全てtype="HKCategoryTypeIdentifierSleepAnalysis”
- 何の機材で記録したかはsourceName
- AppleWatchで記録したらWatchの登録名が記録される
- 他アプリで記録したらそのアプリ名
- 睡眠のステージごとでレコードが記録される
- 公式ドキュメントによれば、以下の種類のうち、いずれかになる
- HKCategoryValueSleepAnalysisInBed
- ベッドに入った時刻〜ベッドから出た時刻
- ポケスリで例えるなら、カビゴン寝かせた時刻からカビゴン起こした時刻
- AppleWatchだとベットインのタイミングが分からないので、記録されない
- 他睡眠ステージは時系列順にレコードが並んでいるが、このベッドステージだけは、一通りの睡眠が終わった最後に生成されがち
- HKCategoryValueSleepAnalysisAwake
- 途中目が覚めた時間帯
- 夜中トイレに起きてたりするとこのステージになる
- HKCategoryValueSleepAnalysisAsleepCore
- 浅い眠り。体が休まっている状態
- ポケスリで言うすやすやタイプ
- HKCategoryValueSleepAnalysisAsleepDeep
- 深い眠り。脳みそも休んでいる
- ポケスリで言うぐっすりタイプ
- HKCategoryValueSleepAnalysisAsleepREM
- レム睡眠。夢を見ているあっさい眠り状態
- ポケスリで言ううとうとタイプ
- HKCategoryValueSleepAnalysisAsleepUnspecified
- どのステージかよくわからんけど多分寝てるんじゃね?
- startDate, endDateは、その睡眠ステージの始まりから終わりまでを表す
- 1回の睡眠中睡眠ステージが変わった場合、前レコードのendDateと、次のstartDateの時刻が同じになる特徴がある
やりたいこと
元々、Railsで睡眠記録を入力できるアプリケーションを作成していました。
ヘルスケアのデータをユーザーにインポートさせて、入力なしにまるっと登録できる仕組みを作りたいと思い、どったんばったんおおさわぎしてました🦊🎒👒
実装内容
実装概要
zip解凍したXMLファイルをNokogiri::XML::SAXで読み込み、保存する
環境
フロント・バック: Ruby on Rails 7.2.2, Ruby 3.3.6
開発: Docker
インフラ: Render
最終的にインスタンスタイプはStandard 2GB(RAM) 1CPUに落ち着きました。高いよ〜
お世話になったGem様
# zipファイル処理用
gem "rubyzip"
# XMLデータをパースする
gem "nokogiri"
ヘルスケアデータをインポートしてから保存するまでの処理手順
最下部に実際のコードを貼ってるんですけど、長いので処理方法を文章化しました。
メモリ温存の参考になれば幸いです。
-
form_withでユーザーにヘルスケアのZIPファイルをアップロードしてもらう - コントローラーで受け取ったら、ZIPファイルかつexport.xmlが存在するか確認して、解凍する
- export.xmlをストリーム形式で少しずつ読み込む
- XMLの開始要素<Record>を見つける度にイベントが発動
- パースの力で、<Record>内からHashごとに要素<type>, <startDate>, <endDate>, <value>を探し、その値を同名の変数に代入
- startDateとendDateをstrptimeメソッドで読み取り、直近31日以内なら次の処理へ
- endDateが午後4時よりも前か後かで睡眠日を決める
- 睡眠日別で、Hash形式で変数・値をメモリに保存。なお、ベッドに入った時間を表す"HKCategoryValueSleepAnalysisInBed”タイプだけは他の睡眠ステージと分けておく
- もし睡眠日が異なる場合は、前日の睡眠日として登録されていたメモリ分をフォームオブジェクトに渡し、メモリを解放する
- 睡眠日とその日分のHashデータを受け取ったフォームオブジェクトで、睡眠記録の加工と保存を行っていく
- 初めに、ベッドの時間以外の睡眠レコードから、連続する睡眠レコード別でブロックに分けていく。このとき、それぞれの合計睡眠時間も分単位で計算する。
- その日の睡眠日のうち、ベッドに入ったレコードが存在するか否かで保存方法が異なる。
- ベッドに入ったレコードが存在する場合は、そのstartDateをベッドに入った時刻(go_to_bed_atという自作モデルのカラム)として、endDateをベッドから出た時刻(leave_bed_at)として代入。各睡眠ブロックのうち、ベッドに入った時間から出るまでの時間内の記録の場合、睡眠ブロック一番初めのstartDateを眠りに入った時刻(fell_asleep_at)として、一番最後のendDateを目が覚めた時刻(woke_up_at)として代入。それ以外の睡眠ブロックは、各合計睡眠時間を合算して昼寝時間として換算し、昼寝時間(napping_timeという自作モデルのカラム)を分単位で代入。夜中目が覚めたことを示す"HKCategoryValueSleepAnalysisAwake”レコードの数を数えて、中途覚醒回数(awakenings_countという自作モデルのカラム)に代入
- ベッドに入ったレコードが存在しない場合は、睡眠ブロックの中から最も長い合計睡眠時間を持つブロックを主要な睡眠とし、それ以外を昼寝として換算する。このとき、ベッドに入った時刻=眠りに入った時刻, 目が覚めた時刻=ベットから出た時刻として扱う
- 秒以下を切り捨てして、saveメソッドでデータベースに保存
- 終わったらSAXパーサーに戻り、次のレコードを読み込んでいく
実際のコード
- app/views/sleep_logs/import.html.erb
- ZIPデータをインポートする場所
<%= form_with model: @healthcare_import_form, url: import_healthcare_data_sleep_logs_path, method: :post, local: true, multipart: true, data: { turbo: false } do |form| %>
<div class="space-y-4 w-full">
<% if @healthcare_import_form.errors.any? %>
<div class="text-sm text-error">
<%= @healthcare_import_form.errors.full_messages.first %>
</div>
<% end %>
<div>
<%= form.label :zip_file, "ZIPファイル", class: "block text-sm/6 font-medium" %>
<div class="mt-2">
<%= form.file_field :zip_file, accept: ".zip", class: "file-input file-input-sm w-full bg-primary text-sm px-3 py-1.5 rounded-md outline outline-1 -outline-offset-1 outline-secondary" %>
</div>
</div>
</div>
<div class="actions mt-10 flex w-full justify-center rounded-md bg-accent px-3 py-1.5 font-semibold text-primary shadow-sm">
<%= form.submit "インポート" %>
</div>
<% end %>
- app/controllers/sleep_logs_controller.rb
- ZIPデータを受け取り、ユーザーデータと共にフォームオブジェクトに送る
class SleepLogsController < ApplicationController
before_action :authenticate_user!, only: [ :index, :new, :create, :edit, :update, :destroy, :import, :import_healthcare_data ]
before_action :set_user, only: [ :index, :new, :create, :edit, :update, :destroy, :import, :import_healthcare_data ] # user情報を取得
# ヘルスケアのzipデータを受け取るリクエストフォーム
### 中略 ###
def import
@healthcare_import_form = HealthcareImportForm.new(user: @user)
end
# ヘルスケアのzipデータを受け取った後、zip->xmlにして加工する
def import_healthcare_data
@healthcare_import_form = HealthcareImportForm.new(healthcare_import_params.merge(user: @user))
# もしインポートできてxmlファイルに加工でたら
if @healthcare_import_form.valid? && @healthcare_import_form.process_file
redirect_to sleep_logs_path, notice: "インポートできますた"
else
flash.now[:alert] = @healthcare_import_form.errors.full_messages.join(", ")
render :import, status: :unprocessable_entity
end
end
private
def set_user
@user = current_user
end
# zipファイルのみを受け付ける
def healthcare_import_params
params.require(:healthcare_import_form).permit(:zip_file)
end
end
- app/forms/healthcare_import_form.rb
- ZIPの解凍から保存まで。長いです。
# ヘルスケアデータインポート用のフォームオブジェクトさん
# Gemfileから使いたいライブラリを呼び出す
require "zip" # zipファイル解凍用
require "nokogiri" # パース用
# XMLをSAX方式で解析するためのハンドラクラス。イベントに対してどう処理するか
# 解析処理を軽くするため、XMLの要素から必要なデータだけを抽出する
class HealthcareImportSaxHandler < Nokogiri::XML::SAX::Document
# SleepAnalusisシリーズの中から、AsleepOnspecifiedだけ除外する用の定数
# さらに、freezeで定数をこれ以上変更できないようにする
EXCLUDE_FROM_EXTRACT = %w[HKCategoryValueSleepAnalysisAsleepUnspecified].freeze
# 4つの睡眠パターンを丸っと管理する定数。ただしAwake(中途覚醒)は除く
ASLEEP_VALUES = %w[
HKCategoryValueSleepAnalysisAsleep
HKCategoryValueSleepAnalysisAsleepCore
HKCategoryValueSleepAnalysisAsleepDeep
HKCategoryValueSleepAnalysisAsleepREM
HKCategoryValueSleepAnalysisAwake
].freeze
# 取り扱う日数の定数
DAYS_TO_KEEP = 31
# 日付の変わり目を決める定数(午後4時)
DAILY_CUT_OFF_HOUR= 16
# 必要なデータを抽出して入れておく配列たち
# SAXハンドラー内で一時的に日別集計を保持
def initialize(record_processor:, daily_summaries:)
@record_processor = record_processor # 日別集計が確定した際に呼び出すコールバック
@daily_summaries = daily_summaries # フォームオブジェクトに共有する日別集計ハッシュ
@cutoff_date = (Time.current - DAYS_TO_KEEP.days).beginning_of_day
@last_processed_date = nil # 最後に処理した睡眠日を追跡する
end
# XML要素の中で、開始タグを見つけたら以下を発動
def start_element(name, attrs = [])
# タグの冒頭がRecordで始まらないものは除外
return unless name == "Record"
# 調べたいキー用に、変数を初期化。Hash化して調べるよりかは早い?
type_val = nil
start_date_str = nil
end_date_str = nil
value_str = nil
# 調べたいキーの値を変数に放り込んでいく
attrs.each do |attr_name, attr_value|
case attr_name
when "type"
type_val = attr_value
when "startDate"
start_date_str = attr_value
when "endDate"
end_date_str = attr_value
when "value"
value_str = attr_value
end
# 必要なものが全て見つかったらループを抜ける (早期終了)
break if type_val && start_date_str && end_date_str && value_str
end
# typeの値が睡眠タイプHKCategoryTypeIdentifierSleepAnalysis出ない場合は除外
return unless type_val == "HKCategoryTypeIdentifierSleepAnalysis"
# Recordの中にはstartDate="2025-07-17 02:08:43 +0900"などが空白区切りで入っている
# perseよりも高速なstrptimeを使用
record_start_time = Time.strptime(start_date_str, "%Y-%m-%d %H:%M:%S %z") rescue nil
record_end_time = Time.strptime(end_date_str, "%Y-%m-%d %H:%M:%S %z") rescue nil
# 時刻が取得できないか、期間対象外か、除外対象の値の場合はスキップ
if record_start_time.nil? || record_end_time.nil? ||
record_start_time < @cutoff_date ||
EXCLUDE_FROM_EXTRACT.include?(value_str)
return
end
# 睡眠日を決める
current_sleep_date = calculate_sleep_date(record_end_time)
# 新しい日付に更新されたら、それまでメモリに覚えさせていた日別のサマリーを処理する
if @last_processed_date && @last_processed_date != current_sleep_date
# 完全に集計が終わった日付のデータをプロセッサに渡す
if @daily_summaries[@last_processed_date] && @record_processor
@record_processor.call(@last_processed_date, @daily_summaries.delete(@last_processed_date))
end
end
@last_processed_date = current_sleep_date # 現在処理中の日付を更新
# 現在の睡眠日のサマリーを初期化(存在しない場合)
@daily_summaries[current_sleep_date] ||= {
in_bed_records: [],
asleep_records: [],
sleep_blocks: [] # ここで sleep_blocks はまだ生成されない
}
# 必要な属性のみを含むハッシュを作成して追加 (メモリ削減)
record_data = {
"type" => type_val,
"startDate" => start_date_str,
"endDate" => end_date_str,
"value" => value_str
}
# InBed(ベッドに入った時間)があるかないかで仕分け
if value_str == "HKCategoryValueSleepAnalysisInBed"
@daily_summaries[current_sleep_date][:in_bed_records] << record_data
elsif ASLEEP_VALUES.include?(value_str)
@daily_summaries[current_sleep_date][:asleep_records] << record_data
end
end
# ドキュメントの終わりに到達したら、最後に残っている集計データを処理
# メモリを解放
def end_document
if @last_processed_date && @daily_summaries[@last_processed_date] && @record_processor
@record_processor.call(@last_processed_date, @daily_summaries.delete(@last_processed_date))
end
end
private
# 睡眠日の決定:今朝起きた日を決める (SAXハンドラー内で使用)
def calculate_sleep_date(end_time)
return nil unless end_time.present? && end_time.respond_to?(:hour)
# 終了時刻が日付切り替え時刻の午前4時より前かどうかで日付を決める
if end_time.hour < DAILY_CUT_OFF_HOUR
end_time.prev_day.to_date # 前日にする
else
end_time.to_date
end
end
end
# こっからフォームオブジェクト!
class HealthcareImportForm
include ActiveModel::Model
include ActiveModel::Attributes
# アップロードzipファイル受け取り属性
attribute :zip_file
# paramsのときにcurrent_userをマージしている
attr_accessor :user
# 解凍したXMLファイルを扱う
attr_accessor :xml_content
# インポートした数
attr_accessor :imported_count
# ファイルは選択されているか?
validates :zip_file, presence: true
# ZIPファイル形式のバリデーション集
validate :validate_zip_file
# 引数には、キー名がzip_fileとuserのハッシュが渡されてくる
def initialize(attributes = {}) # もし引数にattributesが渡されなかったら、空のハッシュを入れる
# zip_fileのみを加工できるように、Userモデルのインスタンスを切り出してインスタンス変数に入れておく
@user = attributes.delete(:user)
# zip_fileをattributesに渡す
super(attributes)
# 空っぽを作るシリーズ
@xml_content = nil
end
def process_file
return false unless valid?
begin
Zip::File.open(zip_file.tempfile.path) do |zip_file_obj|
export_entry = zip_file_obj.glob("**/apple_health_export/export.xml").first
unless export_entry
export_entry = zip_file_obj.find_entry("export.xml")
unless export_entry
errors.add(:base, "export.xmlファイルが見つからないです")
return false
end
end
# XMLコンテンツ全体をメモリに読み込まず、ストリームをSAXパーサーに直接渡す
export_entry.get_input_stream do |xml_stream| # ストリームを開く
daily_summaries_in_progress = {}
daily_summary_processor = Proc.new do |sleep_date, summary_data|
process_daily_sleep_data(sleep_date, summary_data)
end
sax_handler = HealthcareImportSaxHandler.new(
record_processor: daily_summary_processor,
daily_summaries: daily_summaries_in_progress
)
Nokogiri::XML::SAX::Parser.new(sax_handler).parse(xml_stream) # ストリームを直接パース
end
end
true # すべての処理が成功したらtrueを返す
rescue => e
Rails.logger.error "ファイル処理中にエラーが発生しました: #{e.message}\n#{e.backtrace.join("\n")}"
errors.add(:base, "ファイル処理中にエラーが発生しました: #{e.message}")
false
end
end
private
# ZIPファイルのみを受け付けるバリデーション
def validate_zip_file
return unless zip_file.present?
unless zip_file.content_type == "application/zip"
errors.add(:zip_file, "ZIPファイルを選択してください")
end
end
# 日別データを受け取り、睡眠ブロックのグループ化とデータベース保存を実行する
def process_daily_sleep_data(sleep_date, summary_data)
in_bed_records = summary_data[:in_bed_records]
asleep_records_raw = summary_data[:asleep_records] # 生のAsleepレコード
# ここで生データから睡眠ブロックをグループ化するロジックを再構築
sleep_blocks_for_the_day = group_asleep_records_into_blocks(asleep_records_raw)
if in_bed_records.any?
process_with_in_bed_data(sleep_date, sleep_blocks_for_the_day, in_bed_records)
else
process_without_in_bed_data(sleep_date, sleep_blocks_for_the_day)
end
@imported_count += 1 # 1日分のデータが保存されるたびにカウント
end
# Asleepレコードの生データから睡眠ブロックを生成する新しいヘルパーメソッド
def group_asleep_records_into_blocks(asleep_records_raw)
return [] if asleep_records_raw.empty?
current_block = nil
blocks = []
# 時刻順にソートする (XMLの順序が保証されない場合のため)
sorted_asleep_records = asleep_records_raw.sort_by do |record|
Time.strptime(record["startDate"], "%Y-%m-%d %H:%M:%S %z") rescue Time.at(0)
end
sorted_asleep_records.each do |record|
record_start = Time.strptime(record["startDate"], "%Y-%m-%d %H:%M:%S %z") rescue nil
record_end = Time.strptime(record["endDate"], "%Y-%m-%d %H:%M:%S %z") rescue nil
next unless record_start && record_end # 時刻を読み取れなければスキップ
if current_block.nil? # 最初のブロック
current_block = {
start_date: record_start,
end_date: record_end,
duration_minutes: (record_end - record_start) / 60,
records: [ record ]
}
elsif (record_start - current_block[:end_date]).abs < 10 * 60 # 前のレコードendと今回のレコードstartが10分未満の間に連続している場合
current_block[:end_date] = record_end
current_block[:duration_minutes] += (record_end - record_start) / 60
current_block[:records] << record
else # 連続が途切れた場合、現在のブロックを保存して新しいブロックを開始
blocks << current_block
current_block = {
start_date: record_start,
end_date: record_end,
duration_minutes: (record_end - record_start) / 60,
records: [ record ]
}
end
end
# 最後のブロックを追加
blocks << current_block if current_block
blocks
end
# InBedレコードがある場合の睡眠記録加工
def process_with_in_bed_data(sleep_date, asleep_block_details, in_bed_record_details)
main_in_bed_record = in_bed_record_details.first # 例えInBedレコードが2つあっても1つとして扱います!
go_to_bed_at = Time.strptime(main_in_bed_record["startDate"], "%Y-%m-%d %H:%M:%S %z") rescue nil
leave_bed_at = Time.strptime(main_in_bed_record["endDate"], "%Y-%m-%d %H:%M:%S %z") rescue nil
main_sleep_chunks = [] # InBed範囲内の睡眠ブロック
nap_chunks = [] # InBed範囲外の睡眠ブロック=昼寝時間
# 各睡眠レコードが、ベッドに入った時間内なら睡眠時間として、そうでないなら昼寝時間として扱わせる
asleep_block_details.each do |block|
block_start = block[:start_date]
block_end = block[:end_date]
# go_to_bed_at と leave_bed_at がnilでないことを確認
if go_to_bed_at && leave_bed_at && block_start >= go_to_bed_at && block_end <= leave_bed_at
main_sleep_chunks << block
else
nap_chunks << block
end
end
fell_asleep_at = main_sleep_chunks.map { |b| b[:start_date] }.min if main_sleep_chunks.any?
woke_up_at = main_sleep_chunks.map { |b| b[:end_date] }.max if main_sleep_chunks.any?
# Awakeningモデルの覚醒回数を計算
awakenings_count = main_sleep_chunks.sum do |block|
block[:records].count { |r| r["value"] == "HKCategoryValueSleepAnalysisAwake" }
end
# Nappingモデルの昼寝時間を計算
napping_time = calculate_total_duration_minutes(nap_chunks)
save_sleep_log(
sleep_date: sleep_date,
go_to_bed_at: go_to_bed_at,
fell_asleep_at: fell_asleep_at,
woke_up_at: woke_up_at,
leave_bed_at: leave_bed_at,
awakenings_count: awakenings_count,
napping_time: napping_time,
comment: ""
)
end
# InBedレコードがない場合の睡眠記録加工
def process_without_in_bed_data(sleep_date, asleep_block_details)
# 最も長い睡眠チャンクを主な睡眠と捉える
longest_chunk = asleep_block_details.max_by { |block| block[:duration_minutes] }
# longest_chunk が存在しない場合は処理をスキップ (Asleepレコードが全くない場合など)
return unless longest_chunk
other_chunk = asleep_block_details - [ longest_chunk ] # それ以外を昼寝と判定
# 主要な睡眠の時刻をSleepLogモデル用のカラムにセット
go_to_bed_at = longest_chunk[:start_date]
fell_asleep_at = longest_chunk[:start_date] # InBedが存在しないので、go_to_bed_atと同値になる
woke_up_at = longest_chunk[:end_date]
leave_bed_at = longest_chunk[:end_date]
# 中途覚醒のレコードがあった数をカウント
awakenings_count = longest_chunk[:records].count { |r| r["value"] == "HKCategoryValueSleepAnalysisAwake" }
# 昼寝時間
napping_time = calculate_total_duration_minutes(other_chunk)
save_sleep_log(
sleep_date: sleep_date,
go_to_bed_at: go_to_bed_at,
fell_asleep_at: fell_asleep_at,
woke_up_at: woke_up_at,
leave_bed_at: leave_bed_at,
awakenings_count: awakenings_count,
napping_time: napping_time,
comment: ""
)
end
# 一塊の合計時間を求めるだけのメソッド
def calculate_total_duration_minutes(blocks)
blocks.sum { |block| block[:duration_minutes].to_i }
end
# saveをするメソッド
def save_sleep_log(attributes)
# ユーザーと睡眠日に基づく睡眠記録を探し、なければ新規作成
sleep_log = @user.sleep_logs.find_or_initialize_by(sleep_date: attributes[:sleep_date])
# 秒切り捨て
go_to_bed_at_truncated = attributes[:go_to_bed_at]&.change(sec: 0)
fell_asleep_at_truncated = attributes[:fell_asleep_at]&.change(sec: 0)
woke_up_at_truncated = attributes[:woke_up_at]&.change(sec: 0)
leave_bed_at_truncated = attributes[:leave_bed_at]&.change(sec: 0)
# 属性をSleepLogインスタンスに設定する&秒切り捨て
sleep_log.assign_attributes(
go_to_bed_at: go_to_bed_at_truncated,
fell_asleep_at: fell_asleep_at_truncated,
woke_up_at: woke_up_at_truncated,
leave_bed_at: leave_bed_at_truncated
)
# 子モデルの関連付けと属性設定
# Awakening
awakening = sleep_log.awakening || sleep_log.build_awakening
awakening.awakenings_count = attributes[:awakenings_count] || 0
# NappingTime
napping_time_record = sleep_log.napping_time || sleep_log.build_napping_time
napping_time_record.napping_time = attributes[:napping_time] || 0
# Comment
comment_record = sleep_log.comment || sleep_log.build_comment
if comment_record.comment.blank?
comment_record.comment = attributes[:comment] || ""
end
SleepLog.transaction do
sleep_log.save!
awakening.save!
napping_time_record.save!
comment_record.save!
end
end
end
そしてできあがったものがこちらです
ここにインポートしていただいたZIPデータを処理して・・・
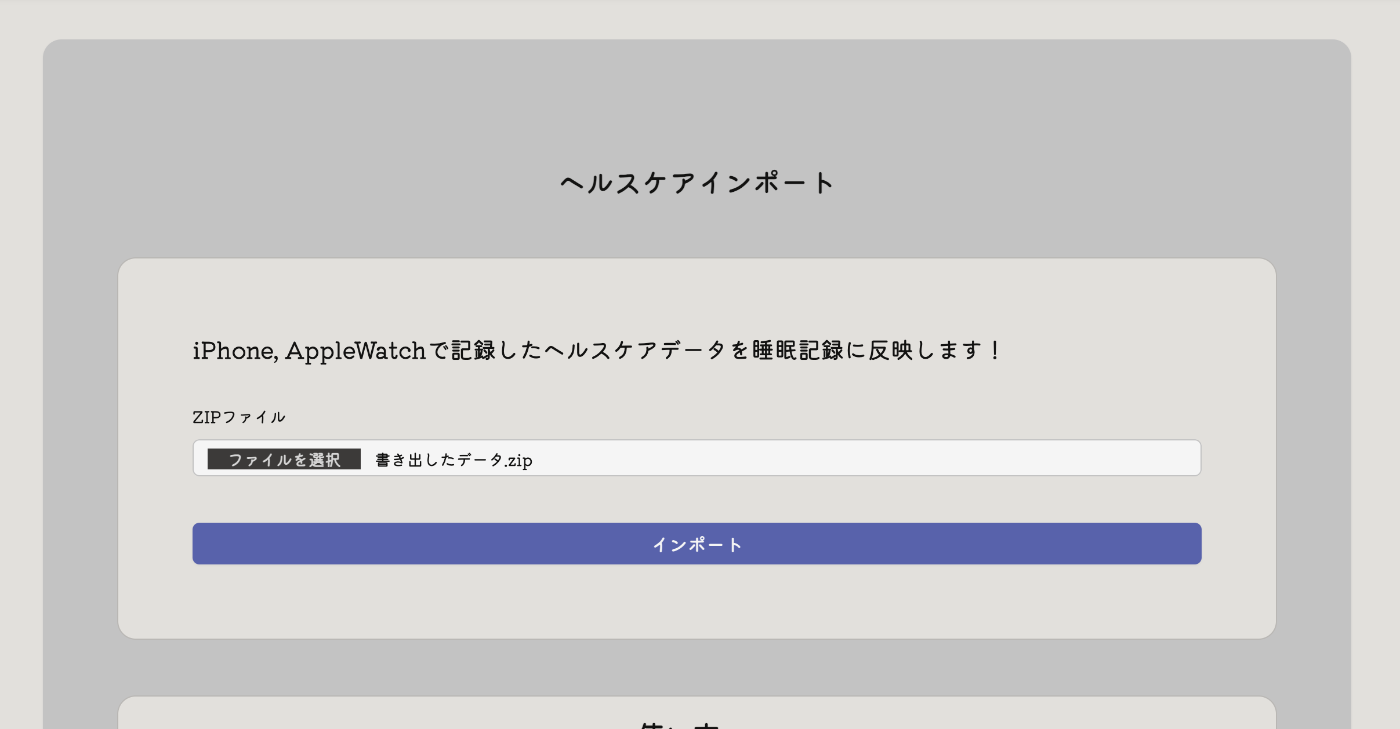
処理が完了したらリダイレクトします。

※睡眠時間だけは別のヘルパーメソッドを使っています。
やばかったところ
もう全部やばかったです。
XMLってなんですかー? から始まったのでお察しください。
- やっててよかったフォームオブジェクト
- 普通に入力して保存したデータを上書きしたかったので、入力形式の保存方法と切り分けて、インポート専用のフォームオブジェクトを作成しました。
- ロジックに人間の脳が追いつかない問題
- 処理の手順を考えるだけで1日溶けました。
- 手順をClaudeに投げて雛形を作ってもらった後、更に細かく分けてちょっとずつ実装できるかどうかを確認しながら実装していきました。
- 具体的には、ZIPファイルをインポートできるかをRailsコンソールで確認するところから始め、XMLデータをViewに出せるか確認し、Nokogiriで抽出ができるか確かめたりしながら実装しました。(以前の愚かな自分は一気にやろうとして詰んでおりました)
- ヘルスケアデータデカすぎ問題
- なんで全てのデータしか書き出せないのか。そしてなぜ一つのファイルに複数の記録が同居しているのか。せめて運動と睡眠記録は切り分けろください。
- 解凍したxmlデータをNeoVimで開けようとしたら落ちました。VSCodeだったらギリ開けましたので、そこからファイルの中身調査をなんとかできました。NeoVimさん・・・?
- JSONとかCSVとか、もっとデータ量マシなのなかったんですか・・・?
- DOMパーサーで読み込もうとしたらDockerのコンテナが落ちた
- AIさんに聞いたら「SAXパーサー使え」と言われたので、SAXパーサーを調べるところから始まりました。
- メモリとの戦い
- コンテナが落ち、ランタイムエラーになり、挙句に本番環境のRenderのメモリ量が耐えきれなくて落ちました。このときばかりは辛かったです・・・
- メモリは一度に覚えておける量に限りがあるので、小手先の工夫でどうにかしました。
- SAXハンドラーが始動する要素(タグ)は<Record>ですが、これが始まったら如何に早く該当しないレコードを読み飛ばすか、軽量に処理できるかに悩まされました。
- とにかくRecordと名のつくものはすべてメモリに入れていた
- SAXパーサーの意味ねぇ!
- なので、全てのレコードに必ず日時データが入っていることを利用して、日別で読み取りを中断してはフォームオブジェクトで保存、deleteでメモリ解放、読み取り再開を繰り返させてメモリ温存に努めました。
- ただこれだと、前日の23時に寝て翌朝に目覚めた場合、0時区切りで別々の睡眠記録判定になってしまうので、午後4時区切りで前日か当日かを判断するようにしました。多くの人は夜に睡眠をとるので。当座凌ぎかもですが・・・
- Recordの中の要素・値を毎回ハッシュ変換していた
- 指定の文字列と要素名が合致したとき、値を変数にそのまま入れることで、ハッシュ変換のタイミングを後ろの方に遅らせました。
- Time.parseとTime.strptimeなら圧倒的にstrptimeの方が早い
- パースというのはとにかく処理量が多いから時間かかるんだよ、ということを先輩にも教えていただきましたし、ベンチマーク埋め込んで処理させた時の処理時間にも教えていただきました。
- 日時は必ず"%Y-%m-%d %H:%M:%S %z”という文字列であることを利用して、日付オブジェクトに変換させてました。
- 過去31日分のみを読み込む
- 睡眠クリニックに通う頻度はだいたい月1なので、最初は余裕持たせて62日2ヶ月分にしていたのですが、処理時間の関係上31日に削りました。
- 本番環境だけ鯖落ちする
- pp埋め込んでちまちまRenderのLogを監視しまくりました。
- そこから上記のような問題に辿り着きました。
- ただこれだけだとダメだったので、無料版512MBから2段階上の2GBメモリを契約しました。金がないよ〜
今後の目標としては、AWSのS3に一旦保存させるなどして、バックグラウンドとかでゆっくり処理させたいなぁ・・・と思ってます。インポート集中したら多分地獄になる自信がありますね。
現時点だとインポートから反映までに数分かかって、その最中はなにも操作できないですし。
それでは、また。
参考文献たち
Discussion