😀
KinesisVideoStreamsの最新画像をLambdaで切り出しS3で期限付き配信する
はじめに
- 前回、KinesisVideoStreamsでリアルタイム解析の記事を書きましたが、以下のようなシチュエーションでユーザーからストリーミングの画像も見たいと言われた場合の対応策です
- ストリーミング動画を見たいが、業務用ネットワーク内で多数のストリームに対して動画閲覧をするのは帯域的に不可
実現すること
-
API Gateway経由でLambdaを呼び出し、KinesisVideoStreamsの最新のフラグメントの最後のフレームを切り出し、S3に保存しS3の期限付きURLをレスポンスする
-
Lambdaについてはコンテナイメージではなく、Lambda Layerを使います
実装手順
Lambda Layerの準備
- pipでインストールしたopencv-pythonをzipで固めます
- Amazon LinuxのコンテナかEC2で作ります
- 適当なディレクトリで、以下のようにします(環境がPython3.7の場合)
mkdir -p python/lib/python3.7/site-packages pip3 install -t python/lib/python3.7/site-packages opencv-python-headless zip -r opencv.zip python- 公式の記載にもありますが、パスの構成を合わせる必要があります
-
opencv-pythonをheadlessにすることで多少サイズは減るものの、それでも圧縮後でも50MBを超えているので、出来上がったzipはs3に格納します
- マネジメントコンソールの AWS Lambda -> その他のリソース -> レイヤーを選択し、「レイヤーの作成」
- さきほどアップロードしたs3のzipファイルを指定します
- 「互換性のあるランタイム」に
Python 3.7を指定します - 2021/9末からLambdaでもarm64が使えるようになりましたが、Python3.7は非対応だったので、今回はx86_64でいきます

Lambda関数の作成
- kvs_utils.py はクラスメソッドさんの記事 からそのまま拝借します
- lambda_function.py
import json
import boto3
import cv2
from datetime import datetime, timedelta
import kvs_utils
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
REGION_NAME = "ap-northeast-1"
# S3バケット名
S3_BUCKET = "test202109112308"
# 署名付きURLの期限 [s]
EXPIRED_TIME = 600
# KVSのストリーム名
STREAM_NAME = "sample"
def lambda_handler(event, context):
stream_name = event["stream_name"] if "stream_name" in event else STREAM_NAME
start_time = datetime.now() - timedelta(seconds=3)
end_time = datetime.now()
logger.info(f"time: {start_time} ~ {end_time}")
# get clip
response, body, filepath = kvs_utils.get_clip_from_kvam(stream_name, start_time, end_time)
# extract images
cap = cv2.VideoCapture(filepath)
frame_num = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
logger.info(f"frame_num: {frame_num}")
# set frame pos
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_num - 1)
ret, frame = cap.read()
if not ret:
return {
'statusCode': 404
}
# output image
write_path = f"/tmp/{stream_name}_{end_time}.jpg"
cv2.imwrite(write_path, frame, [int(cv2.IMWRITE_JPEG_QUALITY), 80])
s3_resource = boto3.resource('s3',
aws_access_key_id=AWS_ACCESS_KEY_ID_FOR_S3,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY_FOR_S3,
region_name=REGION_NAME
)
# upload to s3
s3_path = f"kinesis_{stream_name}_{end_time}.jpg"
s3_resource.Object(S3_BUCKET, s3_path).upload_file(write_path)
# create presigned url
s3_client = boto3.client('s3',
aws_access_key_id=AWS_ACCESS_KEY_ID_FOR_S3,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY_FOR_S3,
region_name=REGION_NAME
)
presigned_url = s3_client.generate_presigned_url(
ClientMethod='get_object',
Params={
'Bucket': S3_BUCKET,
'Key': s3_path
},
ExpiresIn=EXPIRED_TIME,
HttpMethod='GET'
)
logger.info(f"presigned_url {presigned_url}")
return {
'statusCode': 200,
'body': presigned_url
}
Lambda関数の補足
- IAMロールを設定していれば、アクセスキーの指定はいらないはずですが、使う場合は上記のように。
- kvs_utils.get_clip_from_kvam() で作成したmkvファイルをopencvで読み込み、その最後のフレームをファイルに書き出し、それをs3にアップロードしています
- フラグメントは現在時刻から3秒前までの間を指定して取得しています。私の場合はこれで2フラグメント取れることもありますが、1つも取れないとまずいので少し長めに設定します
- 取れない場合はkvs_utilsで例外を吐いてしまうので別途対応が必要です
- 署名付きS3URLの期限はとりあえず600秒(10分)にしています
- 画像のサイズが調整できるようにクオリティも指定しています
Lambda関数の設定
- タイムアウトはちょっと長めに30秒とかにしておきます
- メモリの設定については後述しますが512MBがコスト的にも速度的にもよさそう
- 「レイヤーの追加」でさきほど作成したopencv-pythonのレイヤーを指定します
API Gatewayの設定
- Lambda関数側でトリガーの追加をします
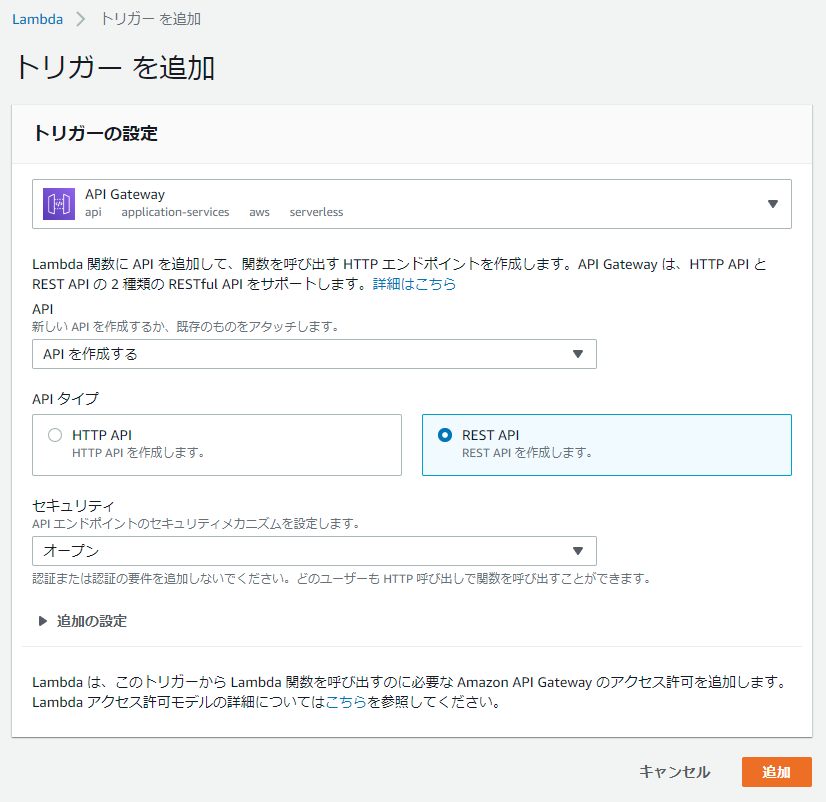
- 作成したら、今度はAPI Gateway側でリソースのアクションからデフォルトで作成された「ANY」を削除して、新たにメソッドの作成で「GET」を追加して上記で作成したLambda関数を指定します
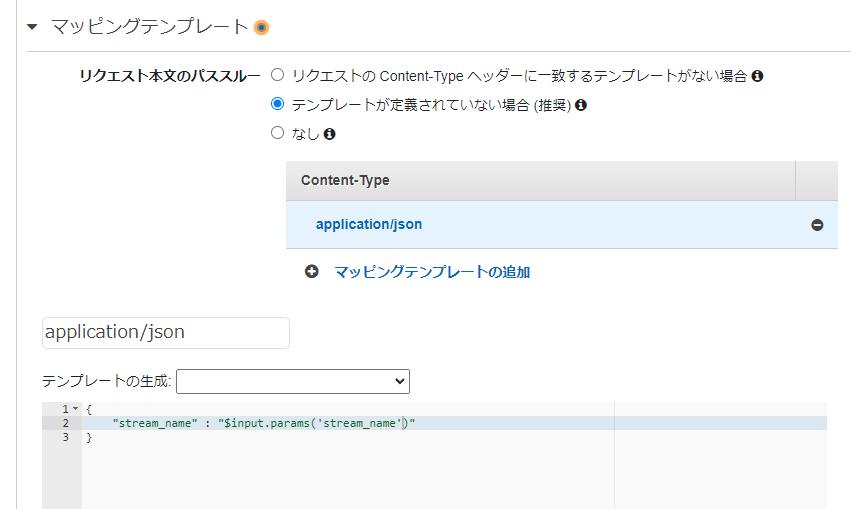
- 統合リクエストのマッピングテンプレートに以下を追加します
{ "stream_name" : "$input.params('stream_name')" }- マッピングテンプレートの場所はここ
- これでインプットパラメータとしてストリーム名を指定できます
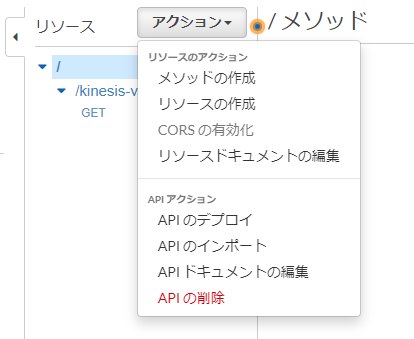
- テンプレートを保存したら、再度APIのデプロイをします
HTTP経由で実行
- APIエンドポイントからリクエストしてみて、S3のURLが返ってきたら成功です
curl "https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/default/kinesis-video-screenshot?stream_name=sample2"
{"statusCode": 200, "body": "https://test202109112308.s3.amazonaws.com/kinesis_sample2_2021-10-11%2008%3A39%3A38.662578.jpg?AWSAccessKeyId=AKIHOGEHOGEHOGEHOGE&Signature=VA233tKocGs%2FTtwWPV%2FxFXz62%2B0%3D&Expires=1633942180"}
メモリの設定について
- メモリごとの処理時間の大体の目安は以下のとおり(2,3回やった結果の雑な平均です)
| メモリ | コールドスタート | ウォームスタート |
|---|---|---|
| 128MB | 7.5秒 | 2.6秒 |
| 256MB | 4.5秒 | 1.3秒 |
| 512MB | 3.0秒 | 0.8秒 |
| 1024MB | 2.5秒 | 0.5秒 |
- ストリームの設定で解像度が低めなのと、5FPS、1Mbpsにしている軽い動画なのでこの程度で処理できますが、フルHDで30FPSとかだともっと時間がかかると思います(128MBでは厳しいかもしれません)
あとがき
- 250MB制限でLambda Layerでやるのは厳しそうだったので、コンテナイメージでいくことも考えましたが、上記の方法で比較的現実的な速度でレスポンスすることがわかって良かったです
- arm64 でやった場合の速度がどうなるかが気になるところ
- 速度が対して変わらないなら安いarm64にしたい
Discussion