【カナカラ開発ログ #2】:韓国語の歌詞を自動でカタカナ読みに変換してくれるカラオケアプリを作りたい!
こんにちは!北米のとある大学でCSを専攻している みゃおち(@MeowNotFound) です。
前回の開発ブログ #1では、カナカラの構想からMVPの実装に至るまでの初期開発プロセスをご紹介しました。
今回はその続きとして、カナルビ変換の大幅な進捗と、実運用に向けた新たな課題への挑戦についてまとめます。1つ目の記事をご覧になっていない方は上記リンクから御覧ください!
(ちなみに、一つ目の記録から大幅に期間が空いたため、内容がボリューミーになってしまいました。)
【※はじめに:大きく変更した点】
実は今回、当初取り組んでいた「英語カナルビ変換」のアプローチをいったん断念することにしました。
❌ CMUdictベースのルール変換の限界
前回までは、CMUdict(英語の発音辞書)を元にしたルールベース変換を進めていましたが、実装が非常に困難であることが分かりました。
主な理由:
1️⃣ 英語の音声連結(Linking)や例外的な発音ルールが多すぎる
→ ロジックだけでは処理しきれない複雑なパターンが多数。
2️⃣ 十分な学習データが得られなかった
→ 英単語や英文とカナ読みが対応した良質なデータセットが存在せず、Wikipediaのダンプデータやjson辞書を使った自作データも精度が出ませんでした。
とはいえ、初学者ながらに機械学習の基礎に触れたり、試行錯誤を通じて大きな学びが得られたことは、自分にとって非常に有意義な経験でした。
【韓国語→カタカナ変換ロジックの開発】
前回までに、簡易的なMVPのフロントエンド(v0)は完成していたため、今回はいよいよカナルビ変換の中核となるバックエンド部分に着手しました!
今回の課題における最終的な目標は、韓国語の歌詞を実際の発音に近いかたちでかな読みに変換することです。
たとえば:
| 原文 | カナ変換 |
|---|---|
| 감사합니다 | カムサハムニダ |
| 좋아해 | チョアへ |
変換のロジックをしては、英語カナ変換で挫折したルールベースではなく、辞書ベースを採用する方向性を取りました。
辞書ベースとは、各固有の音に対応するカナ読みを随一用意するという意味です。
はじめに: g2pkという神ライブラリについて
今回のプロジェクトの中核を担う救世主的なサードパーティのライブラリがg2pkというものです。
まず最初に取り掛かったのは、変換ロジックを自作するのではなく、こちらの外部ライブラリの調査と検証です。
g2pk は “grapheme to phoneme for Korean” の略で、
書かれたハングル(つづり)を、実際の発音に近い形のハングルへと変換してくれるライブラリです。以下にハングルが読める方向けの説明をしますと。。
たとえば:
| 原文 | g2pk変換後 |
|---|---|
| 감사합니다 | 감삼니다 |
| 좋아해 | 조아해 |
g2pkの出力結果はローマ字ではなく音声表記に近いハングルなのがポイントです。
これは英語の際に挫折したような連音化や消音に対応してくれるので、基本的にはこちらでg2pk変換後のハングルに対応するカナにするだけでかなり実際の発音に近い形になるわけです。
頻出ハングル文字の統計処理 📊
ハングルは理論上、数千〜1万以上の組み合わせが存在します。
それら1文字ずつすべてに対応するカナ読みを用意して、独自の変換ルールを作るのは非現実的。
ですが、実際の歌詞で使われるハングル、そしてルールベースでGp2kで変換されるハングル自体はごく一部に偏っているはずです。
g2pkの変換結果から「どのハングルが実際によく使われているか」を調べることにしました。ここでいうハングルとは、通常の文体ではなく、gp2k変換後のハングルです。
具体的な手順:
- バラード、ラップ、K-POPなどさまざまなジャンルの韓国語歌詞(約2000行)を.txtで用意
- g2pkを通して発音ベースのハングルに変換
- 変換結果を1文字ずつ分解し、頻出順にカウント・集計
- 最終的に残った固有文字のみ辞書に採用し、対応するカナはChatGPTで用意。
このアプローチにより、現実的な辞書サイズで高精度なカナルビ変換が実現できました!
今いろんな曲でテストしていますが、精度は90%以上あると考えられます。
こちらのロジックをさらに大きなデータで回せば、辞書の精度がどんどん上がると思われます。
変換ロジックを利用したlrcファイル対応
さあ基本的なフローを確立したところで、実際にlrcファイルと歌詞の入力に対応してこのロジックが動くようにしました。
基本的なロジックが完成している状態で、ファイルの形式に合わせるだけだったのでcursorにて一発のプロンプトで十分正常に動くsrcが完成しました。
そこから、エンドポイントの作成、検証をし、フロントエンドと接続まではcursorでサクッと終わりました。
今回の成果
- ✅ 韓国語のカナルビ変換ロジック(精度90%以上)完成!
- ✅
g2pk→ ハングル → カタカナの変換フローを確立しました。 - ✅ 実用的なハングル文字頻度辞書の生成
- ✅ 変換ロジックを利用したlrcファイル対応
【現在の課題】
カナルビ変換ロジックの完成は大きな一歩でした。が、実用的なウェブアプリとして運用するには、まだまだ乗り越えるべき課題が存在します。
課題1:.lrcファイル依存という構造的リスク
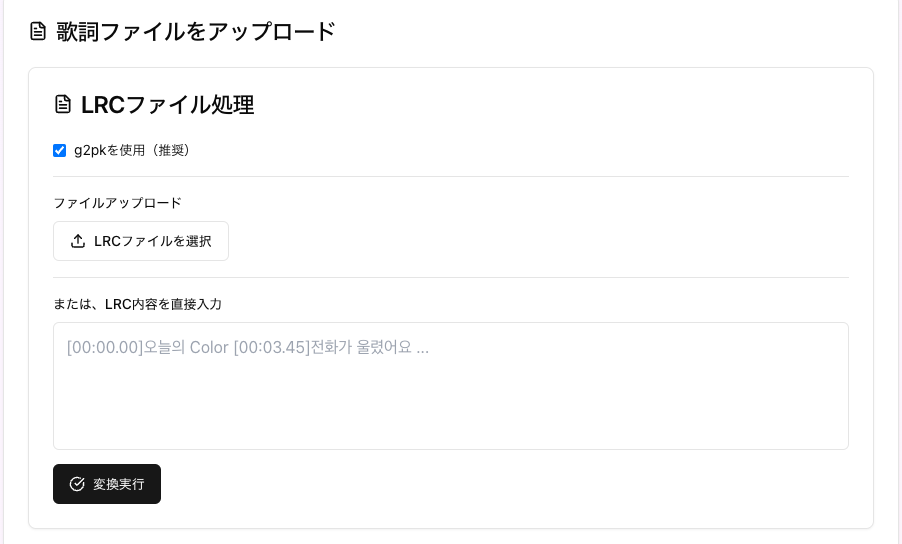
現在、著作権等の問題も加味してユーザーに .lrc ファイル(タイムスタンプ付き歌詞)を用意してもらう前提で動いていますが、これは非効率かつ非現実的だという課題に直面しています。
.lrcファイルが抱える問題点:
- そもそも .lrcファイル は一部の曲にしか存在しない
- 基本的に誰かが手作業で作成・アップロードしたもの
- ユーザー視点では.lrcファイルがなんのことかわからないし取得も大変
テスト用途としてはとても有用ですが、実運用では致命的な構造なわけです。
解決の方向性:音声処理AIによるLRC自動生成
そこで、初期から拡張案として想定していた「音声処理AIの活用」が、もはや必須レベルの機能として浮上してきました。
構想中の処理フロー:
- YouTube音声またはMP3音源の取得
- プレーンテキストでの歌詞取得
- Whisperなどの音声認識AIで音声を文字起こし
- 歌詞と文字起こしのアライメント(マッチング)
- 結果を
.lrcフォーマットで出力
この「自動LRC生成」こそが、今後のカナカラの根幹機能になりうると考えています。
以前、Whisperをローカルで試した際にも、歌声であっても非常に高い精度で文字起こしが可能であることを確認済みです。今後、本格的にPOC(検証)へと進める予定です。
課題2:歌詞取得の自動化
課題1に関連して、LRCを生成するためには歌詞そのものの取得も必要になります。
そこで現在検討しているのが、商用利用でなければ一日2000回まで無料で使える歌詞APIの活用です。
- 夜間などに自動でAPIをコールし、毎日コツコツと歌詞をデータベースに蓄積(1ヶ月で6万曲可能)
- データベース等に保存し、Whisperとの組み合わせでLRCに変換
といった仕組みを想定しています。
課題3:Youtube音源動画取得ロジックの精度の低さ
Youtubeから、アーティスト公式の音源動画を取得したいが、通常のキーワード検索ではそのような音源動画がヒットしない問題。
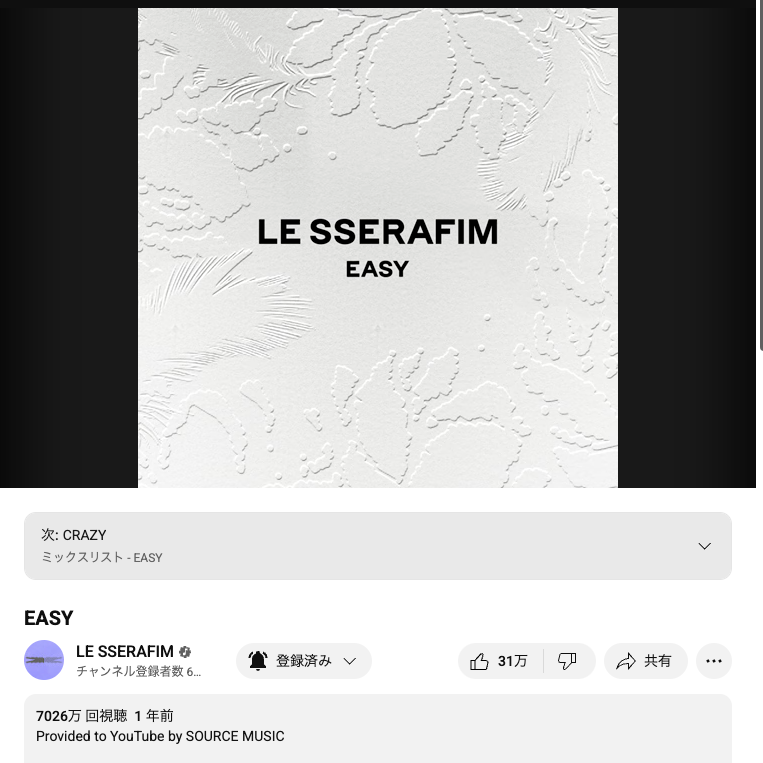
私の想定する音源動画は、Youtube Musicなどで利用されているであろう動画です。(下記参照)
上記と同じアーティスト、曲で調べた結果が以下のような感じです。
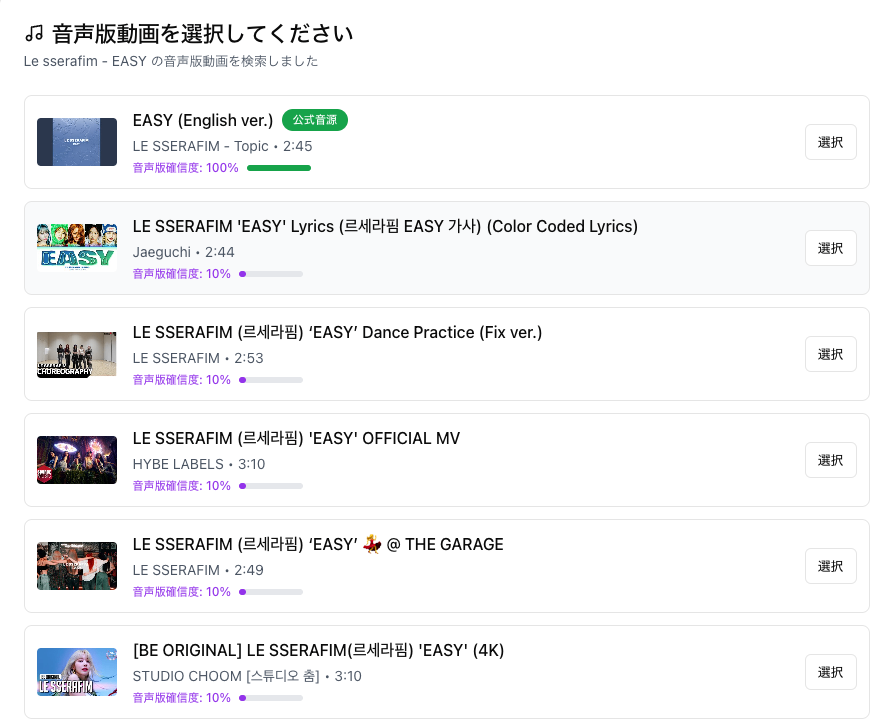
一件公式の音源がヒットしていますが、Englishバージョンなんですよね。。。
精度を上げるには、さらに調査を検証を必要としそうです。
【その他課題と解決策】
| 課題 | 対応策 |
|---|---|
| 韓国語のカナルビが不自然になる | g2pk出力の例外パターンを調査・ルールと辞書を調整 |
| 英語と韓国語が混在した場合の処理 | 文中のスクリプトを判定し、単語単位で変換関数を切り替える設計へ |
【今後の予定】
- 歌詞APIの活用
- 歌詞と.lrcファイルを保存・再利用可能にするためのデータベースの設計と実装
- Whisperを使った自動LRC生成システムの構築
- モバイル対応を含めたUI全体の大幅改善
- カナ変換辞書の拡張
- LLMや外部翻訳APIを用いたカナルビ+翻訳表示の実験
- お気に入り保存・共有URL生成などのUX向上機能
これ以外にもまだまだやること山積みです!
【最後に】
今回、何よりも肝となる韓国語のカナルビ変換ロジックが完成したことで、
カナカラというプロジェクトが現実味を帯びてきたなとワクワクしています。
今後は、AIを利用したさらなる完全自動システムの実装を目指し、
さらに技術的にも面白く、そしてユーザーにとっても役立つプロダクトへと成長させていく予定です。
Discussion
めちゃくちゃいい◎
ありがとうございます!