【LLM】PDFファイルを活用したマルチモーダルチャットアプリケーションの構築
PDFファイルを活用したマルチモーダルチャットアプリケーションの構築
はじめに
※以下は日曜大工のノリで、Cursorを利用してどこまでかけるか試したものになります。
本アプリケーションはPDFファイルをアップロードして、テキスト検索と画像認識を組み合わせた対話型アプリケーションを構築を試しました。PDFファイルからテキストと画像を抽出し、ユーザーの質問に対して回答を提供します。
主な機能
- PDFファイルのアップロードとテキスト抽出
- ベクトルデータベースを使用した効率的な検索
- テキストベースの質問応答
- 画像認識を活用したマルチモーダルな質問応答
- Streamlitベースの使いやすいUI
使用技術
- バックエンド: Python 3.11+
- フロントエンド: Streamlit
-
AI/ML:
- LangChain
- LlamaIndex
- OpenAI GPT-4
- データベース: PostgreSQL + pgvector
- インフラ: Docker, Docker Compose
システム構成
プロジェクト構造
multi-modal-sample/
├── app/ # アプリケーションのメインコード
│ ├── __init__.py # Pythonパッケージ定義
│ ├── config.py # 設定ファイル(APIキー、DB設定など)
│ ├── Dockerfile # アプリケーション用Dockerfile
│ ├── main.py # アプリケーションのエントリーポイント
│ ├── pyproject.toml # Pythonプロジェクト設定
│ ├── ui.py # Streamlit UIの実装
│ └── utils.py # ユーティリティ関数(PDF処理、画像処理など)
│ └── .env # ENV 設定
├── docker-compose.yml # Docker Compose設定
├── .gitignore # Git除外設定
└── README.md # プロジェクトドキュメント
主要コンポーネント
-
設定管理 (
config.py)- OpenAI APIキーの管理
- データベース接続設定
- アプリケーション全体の設定
-
ユーザーインターフェース (
ui.py)- Streamlitを使用した直感的なUI
- PDFファイルのアップロード機能
- 質問入力フォーム
- 回答表示エリア
-
ユーティリティ機能 (
utils.py)- PDFファイルの処理
- 画像抽出と処理
- テキスト変換
- ベクトル化処理
-
メインアプリケーション (
main.py)- アプリケーションのエントリーポイント
- 各コンポーネントの統合
- エラーハンドリング
セットアップ手順
-
環境準備
- Python 3.11以上のインストール
- DockerとDocker Composeのインストール
- OpenAI APIキーの取得
-
環境変数の設定
.envファイルを作成し、以下の環境変数を設定:OPENAI_API_KEY=your_api_key PG_HOST=localhost PG_PORT=5432 PG_DATABASE=ragdb PG_USER=raguser PG_PASSWORD=ragpass -
アプリケーションの起動
docker-compose up --build
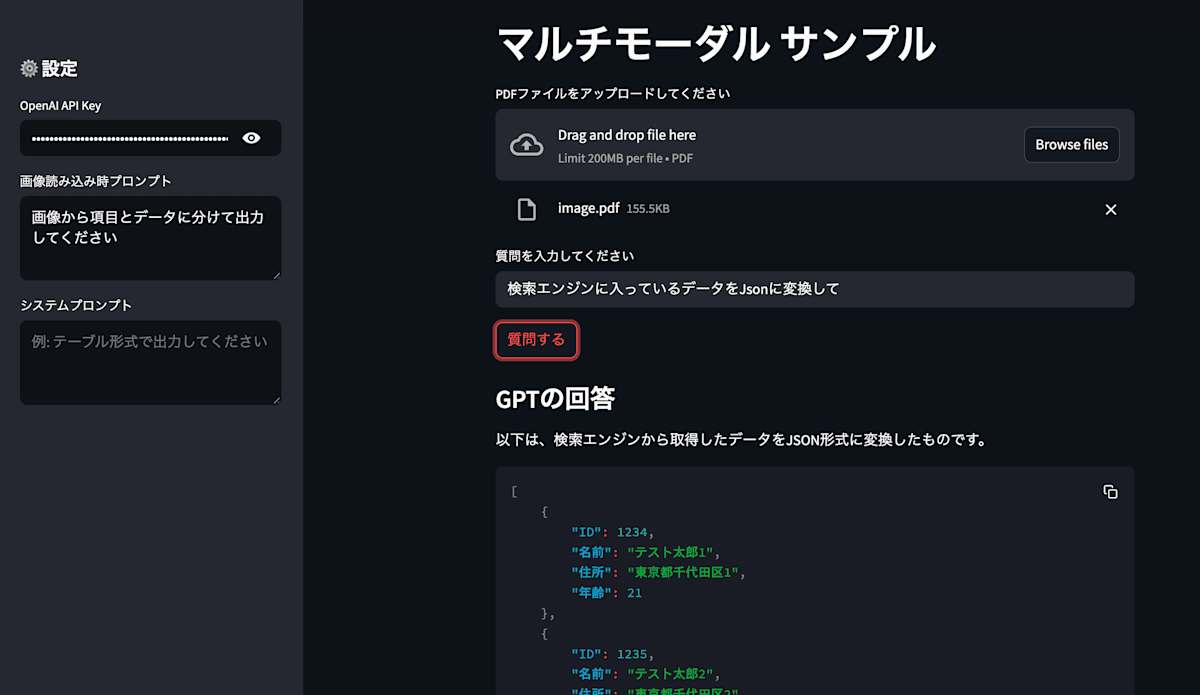
使用方法
- ブラウザで
http://localhost:8501にアクセス - PDFファイルをアップロード
- 質問を入力して「質問する」ボタンをクリック
- 設定タブで以下の設定をカスタマイズ可能:
- OpenAI API Key
- 画像読み込み時プロンプト
- システムプロンプト
コード解説
1. メインアプリケーション (main.py)
メインアプリケーションは、Streamlitを使用してUIを構築し、ユーザーとのインタラクションを管理します。
もう少しマスタ設定に分けてもよかったですが、一旦この形にしてます。
import streamlit as st
from ui import handle_file_upload, handle_question, render_settings
# タイトル
st.title("マルチモーダル サンプル")
# 設定UIの描画(APIキーやプロンプトなど)
render_settings()
# ファイルアップロードUI
uploaded_file = st.file_uploader("PDFファイルをアップロードしてください", type=["pdf"])
handle_file_upload(uploaded_file)
# 質問フォーム
query = st.text_input("質問を入力してください")
if st.button("質問する") and query:
handle_question(query)
このファイルでは、StreamlitのUIコンポーネントを使用して、PDFファイルのアップロード、質問入力、設定変更などの機能を提供しています。
2. ユーザーインターフェース (ui.py)
UIの実装は、以下の3つの主要な機能に分かれています
※設定管理は仮置きで作成
-
設定管理 (
render_settings)- OpenAI APIキーの設定
- 画像読み込み時のプロンプト設定
- システムプロンプトの設定
-
ファイルアップロード処理 (
handle_file_upload)- PDFファイルの一時保存
- テキスト抽出と画像変換
- ベクトルデータベースへのインデックス登録
-
質問処理 (
handle_question)- ユーザーの質問に対する回答生成
- システムプロンプトの適用
- 回答の表示
3. ユーティリティ機能 (utils.py)
PDFファイルの処理と画像認識のためのユーティリティ関数を提供します
model_nameなどは一旦ハードコーディングになっていますが、設定でModel切り替えなどするような形が良いかなと思います
def extract_text_from_pdf(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
return "\n".join([page.extract_text() for page in pdf.pages])
def convert_pdf_to_images(pdf_path):
with tempfile.TemporaryDirectory() as path:
images = convert_from_path(pdf_path, output_folder=path, fmt='jpeg', dpi=200)
return images
def convert_image_to_text(image):
# 画像をbase64エンコード
buf = io.BytesIO()
image.save(buf, format="JPEG")
encoded_image = base64.b64encode(buf.getvalue()).decode("utf-8")
# GPT-4 Vision APIを使用して画像からテキストを抽出
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
message = {
"role": "user",
"content": [
{"type": "text", "text": custom_prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{encoded_image}"}
}
]
}
response = llm.invoke([message])
return response.content
4. 設定管理 (config.py)
アプリケーションの設定とAIモデルの初期化を行います
今回は一つにしてますがagent, dbと分けた方が良いかなと思います。
# DB設定
db_params = {
"host": os.getenv("PG_HOST", "localhost"),
"port": int(os.getenv("PG_PORT", 5432)),
"database": os.getenv("PG_DATABASE", "ragdb"),
"user": os.getenv("PG_USER", "raguser"),
"password": os.getenv("PG_PASSWORD", "ragpass"),
}
# LLM設定
llm = OpenAI(model="gpt-4o-mini", temperature=0)
Settings.llm = llm
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# ベクトルストアとインデックス構築
vector_store = PGVectorStore.from_params(
**db_params,
table_name=table_name,
embed_dim=1536,
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
storage_context=storage_context,
)
# Agent tool として登録
tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description="PostgreSQLベースのドキュメント検索エンジン"
)
# エージェント作成
agent = OpenAIAgent.from_tools(
tools=[tool],
system_prompt=os.getenv("SYSTEM_PROMPT", "表形式で回答してください"),
verbose=True,
)
このファイルでは、以下の重要な設定を行っています
- PostgreSQLデータベースの接続設定
- OpenAIモデルの初期化
- ベクトルストアの設定
- 検索エンジンの構築
- AIエージェントの設定
5. 依存関係管理 (pyproject.toml)
プロジェクトの依存関係はpyproject.tomlで管理されています
poetryを使用していますが、通常のpipでrequirements.txtでの管理とかでも良いと思います
[tool.poetry]
name = "multi-modal-sample"
version = "0.1.0"
description = "PDFファイルをアップロードして、テキスト検索と画像認識を組み合わせた対話型アプリケーション"
authors = ["Hoge Fuga <hoge.fuga@example.com>"]
[tool.poetry.dependencies]
python = "^3.11"
streamlit = "^1.32.0"
langchain = "^0.1.12"
llama-index = "^0.10.8"
openai = "^1.14.0"
pdfplumber = "^0.10.3"
pdf2image = "^1.17.0"
python-dotenv = "^1.0.1"
psycopg2-binary = "^2.9.9"
6. Docker設定 (Dockerfile)
アプリケーションのコンテナ化には、以下のDockerfileを使用しています
FROM python:3.11-slim
WORKDIR /app
# システムの依存関係をインストール
RUN apt-get update && apt-get install -y \
poppler-utils \
&& rm -rf /var/lib/apt/lists/*
# Pythonパッケージをインストール
COPY pyproject.toml .
RUN pip install poetry && \
poetry config virtualenvs.create false && \
poetry install --no-dev
# アプリケーションコードをコピー
COPY . .
# アプリケーションを起動
CMD ["streamlit", "run", "app/main.py"]
最後に
今回、Cursorを利用してこの記事とアプリ含めてどこまで簡略化できるかの実験も兼ねて作成を行いました。
ToyProjectとしての活用や、知識のキャッチアップにかなり活用できることがわかり、非常に良い勉強となりました。
今回のコードはGithubにも載せております。もしよろしければStarもらえると励みになります。
Discussion