think ツール
Anthropic「The "think" tool: Enabling Claude to stop and think in complex tool use situations」を読んだ
Anthropicがthinkというツールを含めてあげるとエージェントの性能が良くなるよ的な記事を公開していたので読んでみました。
エージェント自身がこういったツールを自身で判断して使用するってんだから、いまだに不思議な感じがしてしょうがないですね。
As we continue to enhance Claude's complex problem-solving abilities, we've discovered a particularly effective approach: a "think" tool that creates dedicated space for structured thinking during complex tasks.
私たちは、Claudeの複雑な問題を解く能力の向上させ続けています。
その中で、特に効果的なアプローチを発見しました。
それは、複雑な作業中に構造化された思考のための
専用スペースを作る「**think**」ツールです。
This simple yet powerful technique—which, as we’ll explain below, is different from Claude’s new “extended thinking” capability—has resulted in remarkable improvements in Claude's agentic tool use ability. This includes following policies, making consistent decisions, and handling multi-step problems, all with minimal implementation overhead.
このシンプルかつ強力なテクニックは、以下で説明するように、
Claudeの新しい「extended thiking」能力とは異なるものですが、
Claudeのエージェント的なツール使用能力に著しい向上を
もたらしました。
これには、ポリシーに従うこと、一貫した意思決定を行うこと、
マルチステップの問題を処理することなどが含まれ、
これらはすべて最小限の実装オーバーヘッドで行われる。
In this post, we'll explore how to implement the “think” tool on different applications, sharing practical guidance for developers based on verified benchmark results.
この記事では、検証されたベンチマーク結果に基づき、
開発者のための実践的なガイダンスを共有しながら、
さまざまなアプリケーションに「think」ツールを
実装する方法を探ります。
"think" ツールとは何か?
With the "think" tool, we're giving Claude the ability to include an additional thinking step—complete with its own designated space—as part of getting to its final answer.
"think" ツールによって、私たちはクロードに、
最終的な答えを導き出すための追加の思考ステップ
(独自の指定スペースを含む)を提供することができます。
While it sounds similar to extended thinking, it's a different concept. Extended thinking is all about what Claude does before it starts generating a response. With extended thinking, Claude deeply considers and iterates on its plan before taking action. The "think" tool is for Claude, once it starts generating a response, to add a step to stop and think about whether it has all the information it needs to move forward. This is particularly helpful when performing long chains of tool calls or in long multi-step conversations with the user.
"extended thinking"と似ているように聞こえますが、
異なる概念です。"extended thinking"とは、Claudeが
応答を生成する前に何をするかということです。
"extended thinking"では、Claudeは行動を起こす前に
計画を深く考え、繰り返します。
"think"ツールは、Claudeが応答を生成し始めたら、
次に進するために必要なすべての情報を持っているかどうか、
立ち止まって考えるステップを追加するためのものです。
これは、連鎖する長いツールの呼び出しを実行するときや、
ユーザーとの長いマルチステップの会話で特に役立ます。
This makes the “think” tool more suitable for cases where Claude does not have all the information needed to formulate its response from the user query alone, and where it needs to process external information (e.g. information in tool call results). The reasoning Claude performs with the “think” tool is less comprehensive than what can be obtained with extended thinking, and is more focused on new information that the model discovers.
このため、"think "ツールは、Claudeがユーザーからの
問い合わせだけでは、十分な応答を返すのに必要なすべての情報を
持っていない場合や、外部情報(ツール呼び出し結果の情報など)を
処理する必要がある場合に適している。
Claudeが"think"ツールで実行する推論は、"extended thinking"で
得られるものよりも包括的ではなく、モデルが発見する新しい情報に
重点を置いている。
We recommend using extended thinking for simpler tool use scenarios like non-sequential tool calls or straightforward instruction following. Extended thinking is also useful for use cases, like coding, math, and physics, when you don’t need Claude to call tools. The “think” tool is better suited for when Claude needs to call complex tools, analyze tool outputs carefully in long chains of tool calls, navigate policy-heavy environments with detailed guidelines, or make sequential decisions where each step builds on previous ones and mistakes are costly.
extened thinking は、非連続的なツールの呼び出しや簡単な指示に
従うような、よりシンプルなツールの使用シナリオに使用することを
お勧めします。extened thinkingは、コーディング、数学、物理学の
ように、Claudeにツールを呼び出す必要がない場合にも便利です。
thinkツールは、クロードが複雑なツールを呼び出したり、
長いツール呼び出しの連鎖の中でツールの出力を注意深く分析したり、
詳細なガイドラインのあるポリシーの多い環境をナビゲートしたり、
各ステップが前のステップの上に構築され、ミスのコストが高く
なるような逐次的な決定を行う必要がある場合に適しています。
Here's a sample implementation using the standard tool specification format that comes from τ-Bench:
τ-Benchの標準的なツール仕様書式を使用した実装例です:
{
"name": "think", # ツールの名前
"description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.",
"input_schema": { # インプットスキーマ ツールに必要なパラメータを定義する
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "A thought to think about."
}
},
"required": ["thought"]
}
}
# description の内容
# このツールを使って何かを考えてみてください。
# このツールは新しい情報を得たり、データベースを変更したりはしない。
# 複雑な推論やキャッシュメモリが必要なときに使う。
Performace on T-Bench (τ-Benchでのパフォーマンス)
We evaluated the "think" tool using τ-bench (tau-bench), a comprehensive benchmark designed to test a model’s ability to use tools in realistic customer service scenarios, where the "think" tool is part of the evaluation’s standard environment.
私たちはτ-Benchを使ってthinkツールを評価しました。τ-Benchは
モデルの現実のカスタマーサービスを遂行する能力をテストするため
の包括的なベンチマークです。
「think」ツールはこの評価の標準環境の一部です。
τ-bench evaluates Claude's ability to:
- Navigate realistic conversations with simulated users
- Follow complex customer service agent policy guidelines consistently
- Use a variety of tools to access and manipulate the environment database
The primary evaluation metric used in τ-bench is pass^k, which measures the probability that all k independent task trials are successful for a given task, averaged across all tasks. Unlike the pass@k metric that is common for other LLM evaluations (which measures if at least one of k trials succeeds), pass^k evaluates consistency and reliability—critical qualities for customer service applications where consistent adherence to policies is essential.
τ-BenchはClaudeの能力を評価します:
* 想定したユーザーとの現実的な会話をナビゲートする能力
* 複雑なカスタマーサービスエージェントのポリシーガイドラインに一貫して従う能力
* さまざまなツールを使って環境データベースにアクセスし、操作する能力
Performance Analysis
Our evaluation compared several different configurations:
- Baseline (no "think" tool, no extended thinking mode)
- Extended thinking mode alone
- "Think" tool alone
- "Think" tool with optimized prompt (for airline domain)
The results showed dramatic improvements when Claude 3.7 effectively used the "think" tool in both the “airline” and “retail” customer service domains of the benchmark:
Airline domain: The "think" tool with an optimized prompt achieved 0.570 on the pass^1 metric, compared to just 0.370 for the baseline—a 54% relative improvement;
Retail domain: The "think" tool alone achieves 0.812, compared to 0.783 for the baseline.
私たちの評価では、いくつかの異なる構成で比較を行いました。:
1. ベースライン(「think」ツールなし、exteneded thinkingモードなし)
2. exteneded thinkingモードのみ
3. 「think」ツールのみ
4. プロンプトを最適化した 「Think 」ツール(航空会社ドメイン用)
その結果、「think」ツールを効果的に活用した Claude 3.7 は、ベンチマークの「航空業界」と「小売業界」のカスタマーサービス領域において、劇的な改善を示しました。
航空業界: 最適化されたプロンプトを使用した「think」ツールは、pass^1 指標で 0.570 を達成。これはベースラインの 0.370 と比較して 54% の相対的な改善 に相当します。
小売業界: 「think」ツール単体で 0.812 を記録。これはベースラインの 0.783 と比較してわずかに向上しました。
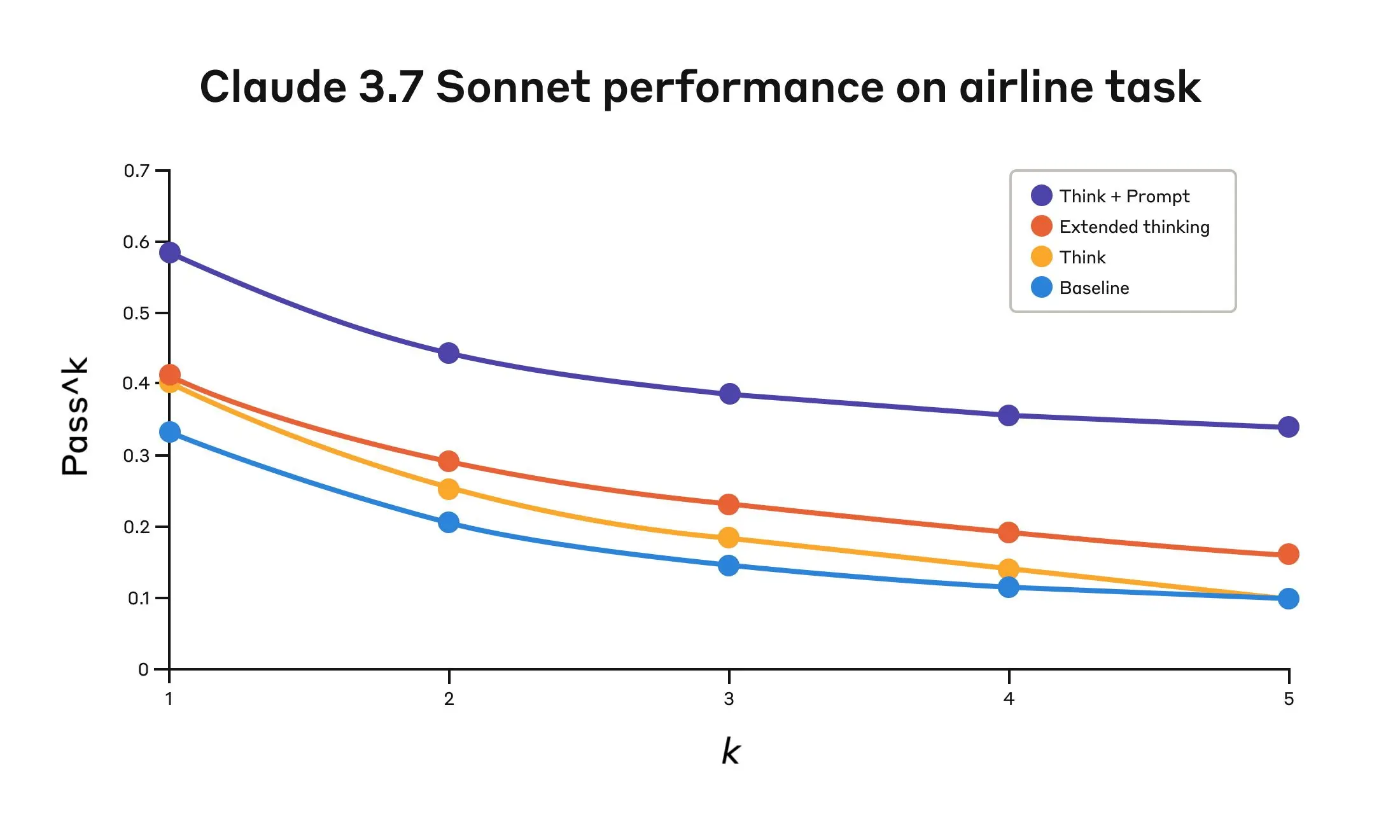
Claude 3.7 Sonnet's performance on the "Airline" domain of the Tau-Bench eval
| Configuration | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| "Think" + Prompt | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| "Think" | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| Extended thinking | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| Baseline | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
The best performance in the airline domain was achieved by pairing the “think” tool with an optimized prompt that gives examples of the type of reasoning approaches to use when analyzing customer requests. Below is an example of the optimized prompt:
航空会社のドメインで最高のパフォーマンスを達成したのは、
「think」ツールと、顧客の要望を分析する際に使用する
推論アプローチのタイプの例を示す最適化されたプロンプトを
組み合わせることであった。以下は最適化されたプロンプトの例である:
## Using the think tool
Before taking any action or responding to the user after receiving tool results, use the think tool as a scratchpad to:
- List the specific rules that apply to the current request
- Check if all required information is collected
- Verify that the planned action complies with all policies
- Iterate over tool results for correctness
Here are some examples of what to iterate over inside the think tool:
<think_tool_example_1>
User wants to cancel flight ABC123
- Need to verify: user ID, reservation ID, reason
- Check cancellation rules:
* Is it within 24h of booking?
* If not, check ticket class and insurance
- Verify no segments flown or are in the past
- Plan: collect missing info, verify rules, get confirmation
</think_tool_example_1>
<think_tool_example_2>
User wants to book 3 tickets to NYC with 2 checked bags each
- Need user ID to check:
* Membership tier for baggage allowance
* Which payments methods exist in profile
- Baggage calculation:
* Economy class × 3 passengers
* If regular member: 1 free bag each → 3 extra bags = $150
* If silver member: 2 free bags each → 0 extra bags = $0
* If gold member: 3 free bags each → 0 extra bags = $0
- Payment rules to verify:
* Max 1 travel certificate, 1 credit card, 3 gift cards
* All payment methods must be in profile
* Travel certificate remainder goes to waste
- Plan:
1. Get user ID
2. Verify membership level for bag fees
3. Check which payment methods in profile and if their combination is allowed
4. Calculate total: ticket price + any bag fees
5. Get explicit confirmation for booking
</think_tool_example_2>
What's particularly interesting is how the different approaches compared. Using the “think” tool with the optimized prompt achieved significantly better results over extended thinking mode (which showed similar performance to the unprompted “think” tool). Using the "think" tool alone (without prompting) improved performance over baseline, but still fell short of the optimized approach.
特に興味深いのは、各アプローチの比較である。
最適化されたプロンプトで「考える」ツールを使用すると、
拡張思考モード(プロンプトなしの「考える」ツールと同様のパフォーマンスを示した)
よりも有意に優れた結果が得られた。
「think」ツールを単独で使用した場合(プロンプトなし)、
ベースラインよりも成績が向上したが、それでも最適化されたアプローチには及ばなかった。
The combination of the "think" tool with optimized prompting delivered the strongest performance by a significant margin, likely due to the high complexity of the airline policy part of the benchmark, where the model benefitted the most from being given examples of how to “think.”
「think」ツールと最適化されたプロンプトの組み合わせは、かなりの差で
最も強力なパフォーマンスを示した。これは、ベンチマークの航空政策の
部分が非常に複雑で、モデルが「考える」方法の例を与えられることで
最も恩恵を受けたためと思われる。
In the retail domain, we also tested various configurations to understand the specific impact of each approach
小売業のドメインでは、各アプローチの具体的な影響を理解する
ために、さまざまな構成もテストした。
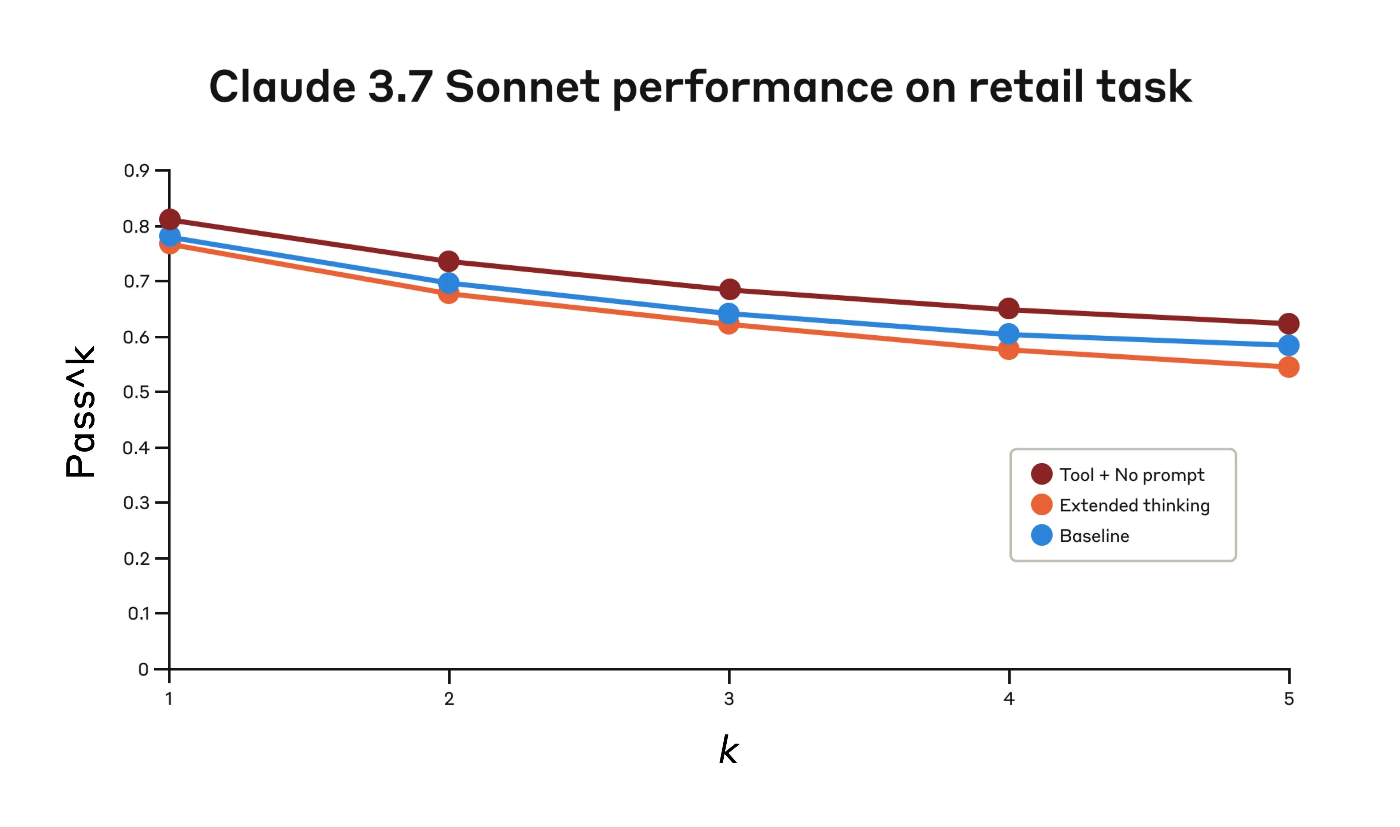
Claude 3.7 Sonnet's performance on the "Retail" domain of the Tau-Bench eval
| Configuration | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| "Think" + no prompt | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| Extended thinking | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| Baseline | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
Evaluation results across three different configurations. Scores are proportions.
The "think" tool achieved the highest pass^1 score of 0.812 even without additional prompting. The retail policy is noticeably easier to navigate compared to the airline domain, and Claude was able to improve just by having a space to think without further guidance.
"think"ツールは、追加のプロンプトなしでも0.812という最高の
合格点^1を達成した。 航空会社の領域と比べると、小売のポリシーは
明らかにナビゲートしやすく、Claudeはさらなるガイダンスがなくても、
考える間があるだけで上達することができた。
Key Insights from τ-Bench Analysis
Our detailed analysis revealed several patterns that can help you implement the "think" tool effectively:
Prompting matters significantly on difficult domains. Simply making the "think" tool available might improve performance somewhat, but pairing it with optimized prompting yielded dramatically better results for difficult domains. However, easier domains may benefit from simply having access to “think.”
Improved consistency across trials. The improvements from using “think” were maintained for pass^k up to k=5, indicating that the tool helped Claude handle edge cases and unusual scenarios more effectively.
Performance on SWE-Bench
A similar “think” tool was added to our SWE-bench setup when evaluating Claude 3.7 Sonnet, contributing to the achieved state-of-the-art score of 0.623. The adapted “think” tool definition is given below:
τ-Bench分析からの主な洞察
私たちの詳細な分析により、「think」ツールを効果的に導入するのに
役立ついくつかのパターンが明らかになった:
1.**プロンプティングは、難解なドメインで大きな意味を持つ**
単に "think "ツールを利用できるようにするだけでも、多少は成績が
向上するかもしれないが、最適化されたプロンプティングと組み合わせることで、
難しいドメインでは劇的に成績が向上した。 しかし、より簡単な領域では、
"think "を利用できるようにするだけでも効果があるかもしれない。
2. **試験間の一貫性の向上** "think"の使用による改善はk=5までの
pass^kで維持され、このツールはClaudeがエッジケースや異常な
シナリオをより効果的に処理するのに役立ったことを示している。
SWEベンチでのパフォーマンス
同様の "think "ツールは、Claude 3.7 Sonnetを評価する際のSWE-benchセットアップに追加され、0.623という達成された最先端スコアに貢献しました。 適用した "think "ツールの定義を以下に示す:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or make any changes to the repository, but just log the thought. Use it when complex reasoning or brainstorming is needed. For example, if you explore the repo and discover the source of a bug, call this tool to brainstorm several unique ways of fixing the bug, and assess which change(s) are likely to be simplest and most effective. Alternatively, if you receive some test results, call this tool to brainstorm ways to fix the failing tests.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "Your thoughts."
}
},
"required": ["thought"]
}
}
Our experiments (n=30 samples with "think" tool, n=144 samples without) showed the isolated effects of including this tool improved performance by 1.6% on average (Welch's t-test: t(38.89) = 6.71, p < .001, d = 1.47).
私たちの実験(n=30サンプルが"think"ツールあり、n=144サンプルが
"think"ツールなし)では、このツールを含めることによる単独効果で、
パフォーマンスが平均1.6%向上することが示されました。
(Welchのt検定:t(38.89) = 6.71, p < 0.001, d = 1.47)
When to use the "think" tool
Based on these evaluation results, we've identified specific scenarios where Claude benefits most from the "think" tool:
Tool output analysis. When Claude needs to carefully process the output of previous tool calls before acting and might need to backtrack in its approach;
Policy-heavy environments. When Claude needs to follow detailed guidelines and verify compliance; and
Sequential decision making. When each action builds on previous ones and mistakes are costly (often found in multi-step domains).
"think"ツールを使うべき時
これらの評価結果に基づき、Claudeが "think "ツールから最も恩恵を受ける
特定のシナリオを特定した:
1.ツールの出力分析
Claudeが行動する前に、以前のツール呼び出しの出力を
注意深く処理する必要があり、アプローチを後戻りさせる必要がある場合;
2.ポリシーの多い環境。 クロードが詳細なガイドラインに従い、
コンプライアンスを検証する必要がある場合。
3.逐次的な意思決定。 各アクションが前のアクションの上に構築され、
ミスが高くつく場合(マルチステップドメインでよく見られる)。
Implementation best practices
To get the most out of the "think" tool with Claude, we recommend the following implementation practices based on our τ-bench experiments.
実装のベストプラクティス
Claudeを使って "think "ツールを最大限に活用するには、私たちはτ-Bench実験に
基づいた以下の実装方法を推奨する。
1. Strategic prompting with domain-specific examples
The most effective approach is to provide clear instructions on when and how to use the "think" tool, such as the one used for the τ-bench airline domain. Providing examples tailored to your specific use case significantly improves how effectively the model uses the "think" tool:
-
The level of detail expected in the reasoning process;
-
How to break down complex instructions into actionable steps;
-
Decision trees for handling common scenarios; and
-
How to check if all necessary information has been collected.
1.ドメイン固有の例を用いた戦略的プロンプト
最も効果的なアプローチは、τ-Bench・航空業ドメインで使用されているような
"think "ツールをいつ、どのように使用するかについて明確な指示を与えることです。
特定のユースケースに合わせた例を提供することで、モデルが「think」ツールを
効果的に使用する方法が大幅に改善されます:- 推論プロセスで期待される詳細レベル;
- 複雑な指示を実行可能なステップに分解する方法;
- 一般的なシナリオを処理するためのデシジョンツリー、および
- 必要な情報がすべて収集されたかどうかの確認方法
2. Place complex guidance in the system prompt
We found that, when they were long and/or complex, including instructions about the "think" tool in the system prompt was more effective than placing them in the tool description itself. This approach provides broader context and helps the model better integrate the thinking process into its overall behavior.
2.複雑なガイダンスをシステムプロンプトに含める
私たちは、"think"ツールの説明が長く複雑な場合、システムプロンプトに
"think"ツールの説明を含める方が、ツールの説明そのものに含めるよりも
効果的であることを発見した。 このアプローチは、より広い文脈を提供し、
モデルが思考プロセスを全体的な動作にうまく統合するのに役立ちます。
When not to use the "think" tool
Whereas the “think” tool can offer substantial improvements, it is not applicable to all tool use use cases, and does come at the cost of increased prompt length and output tokens. Specifically, we have found the “think” tool does not offer any improvements in the following use cases:
"think"ツールは大幅な改善を提供できますが、すべてのツールのユースケースに
適用できるわけではありません、プロンプトの長さと出力トークンの増加という
代償が伴います。 具体的には、「考える」ツールは、以下のユースケースにおいて、
いかなる改善ももたらさないことがわかりました:
-
Non-sequential tool calls. If Claude only needs to make a single tool call or multiple parallel calls to complete a task, there is unlikely to be any improvements from adding in “think.”
- 非連続的なツール呼び出し。
クロードがタスクを完了するために必要なツール呼び出しが1回だけ、
あるいは複数回並行して呼び出すだけなら、"think "を追加しても
改善される可能性は低いです。
- 非連続的なツール呼び出し。
-
Simple instruction following. When there are not many constraints to which Claude needs to adhere, and its default behaviour is good enough, there are unlikely to be gains from additional “think”-ing.
- 簡単な指示に従う事。
クロードが従うべき制約がそれほど多くなく、デフォルトの挙動で十分な場合、
「考える」ことを追加することによる利点はありません。
- 簡単な指示に従う事。
Getting started
The "think" tool is a straightforward addition to your Claude implementation that can yield meaningful improvements in just a few steps:
"think"ツールは、Claudeの導入に簡単に追加でき、
わずか数ステップで有意義な改善をもたらします:
-
Test with agentic tool use scenarios. Start with challenging use cases—ones where Claude currently struggles with policy compliance or complex reasoning in long tool call chains.
-
Add the tool definition. Implement a "think" tool customized to your domain. It requires minimal code but enables more structured reasoning. Also consider including instructions on when and how to use the tool, with examples relevant to your domain to the system prompt.
-
Monitor and refine. Watch how Claude uses the tool in practice, and adjust your prompts to encourage more effective thinking patterns.
The best part is that adding this tool has minimal downside in terms of performance outcomes. It doesn't change external behavior unless Claude decides to use it, and doesn't interfere with your existing tools or workflows.-
エージェントツールの使用シナリオでテストする。 Claudeが現在、
ポリシーの遵守や長いツール・コール・チェーンでの複雑な推論で
苦労しているような、困難な使用例から始める。 -
ツールの定義を追加する。あなたのドメインにカスタマイズされた
"think"ツールを実装する。 最小限のコードしか必要としないが、
より構造化された推論が可能になります。 また、システムプロンプトに、
あなたのドメインに関連する例とともに、いつ、どのようにツールを
使うかについての説明を含めることも検討しましょう。 -
監視し、改良する。 Claudeが実際にツールをどのように使っているか
を観察し、より効果的な思考パターンを促すためにプロンプトを調整する。
-
Conclusion
Our research has demonstrated that the "think" tool can significantly enhance Claude 3.7 Sonnet's performance1 on complex tasks requiring policy adherence and reasoning in long chains of tool calls. “Think” is not a one-size-fits-all solution, but it offers substantial benefits for the correct use cases, all with minimal implementation complexity.
We look forward to seeing how you'll use the "think" tool to build more capable, reliable, and transparent AI systems with Claude.
結論
私たちの研究は、"think "ツールが、長いツール呼び出しの連鎖の中で
ポリシーの遵守と推論を必要とする複雑なタスクにおいて、Claode 3.7 Sonnet
のパフォーマンスを大幅に強化できることを実証しました。
"think"は万能のソリューションではないが、適切なユースケースに対して、
実装の複雑さを最小限に抑えながら、大きなメリットを提供します。
私たちは、皆様が "think "ツールをどのように使用し、より有能で信頼性が高く、
透明性の高いAIシステムをCladeと共に構築されるかを楽しみにしています。
参考
τ-Benchにつて
ここで使用されているτ-Benchというベンチマーク指標は、エージェントの性能を評価するためのものです。
Discussion