VisionAgentの概要
LandingAIのVisionAgentについての調査の続き
Youtubeの開発者向けの機能の紹介動画
内容をチェックしていきます。
動画の内容
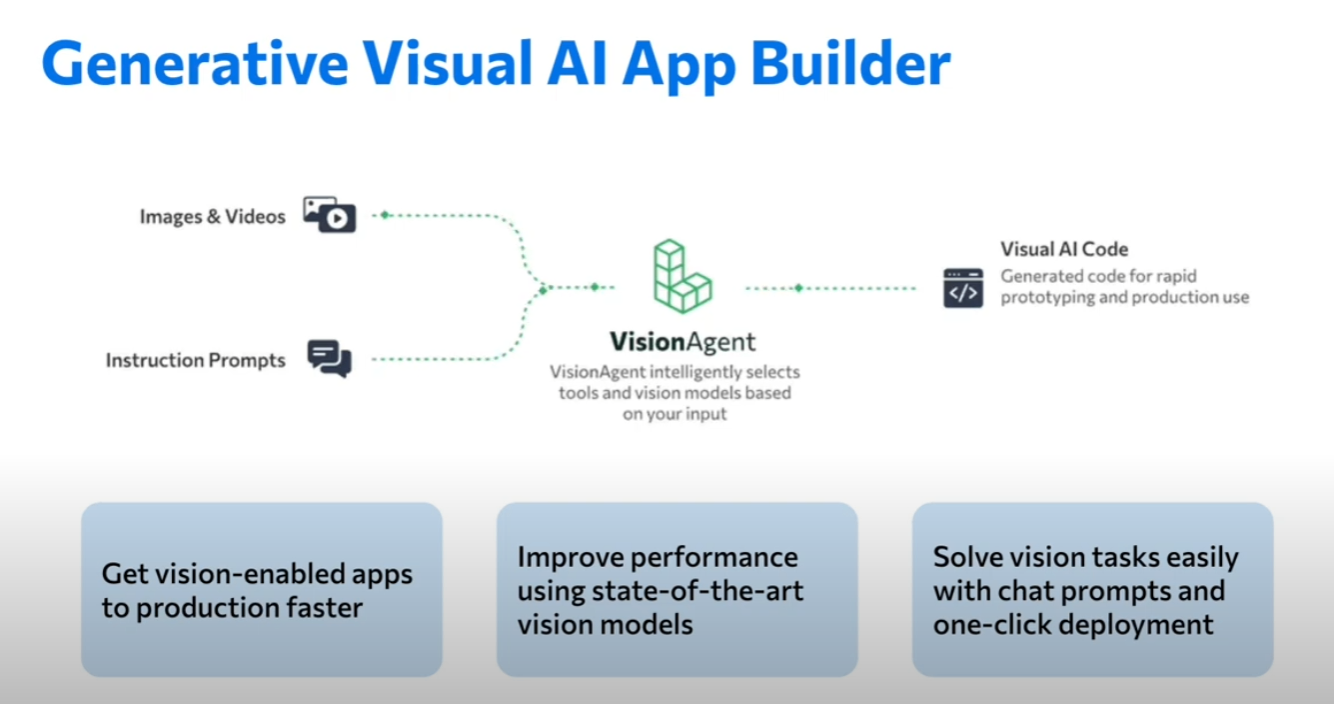
画像・動画とプロンプトをVisionAgentに入力するとコードが生成というサービスですね。
VisionAgentを使う利点としては
- ビジョンが使えるアプリケーションを素早く得られる
- Sotaなビジョンモデルを使ってパフォーマンスを改善できる
- チャットによるプロンプトとワンクリックデプロイでビジョンタスクを簡単に解決
プラットフォームの構造

内部には複数のエージェントが存在し、
広範なツールキットにアクセスして特定の画像認識タスクを推論し、実行してくます。
-
Agent
-
VisonAgent (オーケストレーター)
-
Chat Agent LLM Prompt(Anthropic)
-
Planner Agent シングル/マルチプラン
-
Tool Agent ツールの選択、AI/人間の判断
-
Code Agent
-
-
Tools
- オープンソース 画像・動画モデル
- LandigAIカスタムモデル LandingLens
- LandingAI 事前トレーニング済モデル
- ビジュアルAI 関数、スペース、アーティファクト
具体的にどんなツールが利用できるのかはここで確認できます。
ユースケース
動画内で紹介されているユースケース

- ゼッケン番号と対応する顔の検出
- ビリアードのキューボールの軌道の描画
- サメと人の距離をモニター
ゼッケン番号と対応する顔の検出

プロンプトの内容
Here is an image of a race event with runners wering bib numbers.
Can you write code to return the bib numbers of the runners in the
images along with the corresponding cropped faces? Return a python dictionary
with bib_number, cropped_face, and image_path as keys. cropped_face needs to
be PIL image object. The bib numbers are in the format of 4 digits.
Do not include pairings if the bib number is incomplete or the face
is not detected. Use the closest X distance to find the corresponding
face for a bib number.
(これはランナーがゼッケン番号をつけているレースイベントの画像です。
画像内のランナーのゼッケン番号と、対応する切り抜かれた顔を返すコードを書いてもらえますか?
ゼッケン番号、切り抜かれた顔、画像パスをキーとするPythonの辞書を返してください。)
結果

ゼッケンに対応した顔画像も取得されています。

ビリアードのキューボールの軌道の描画
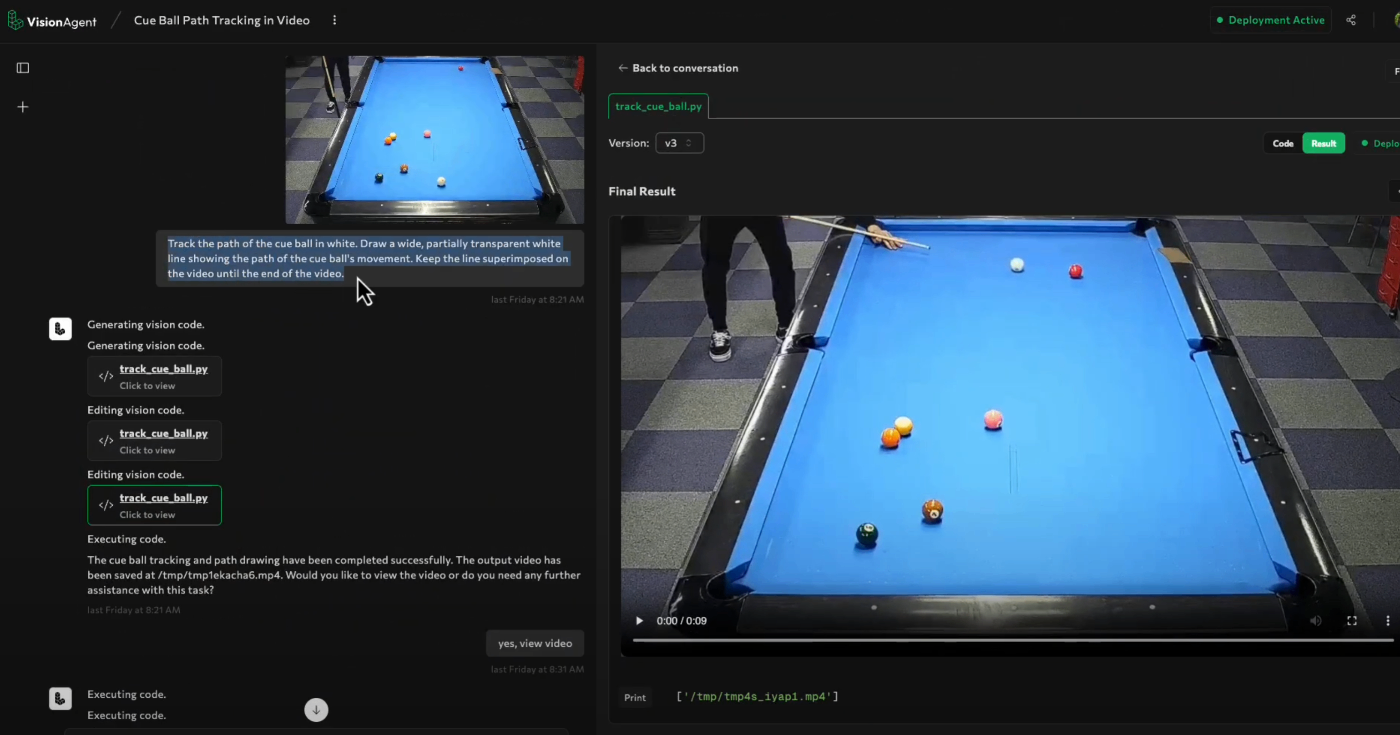
プロンプトの内容
Track the path of the cue ball in white. Draw a wide, partially transparent white
line showing the path of the cue ball's movement. Kepp the line superimposed on
the video until the end of the video.
(白いボール(手玉)の軌跡を追跡してください。手玉の軌道をしめす幅広で半透明の白い線を描いてください。ビデオが終わるまで、その線をビデオに重ねて表示し続けてください。)
結果

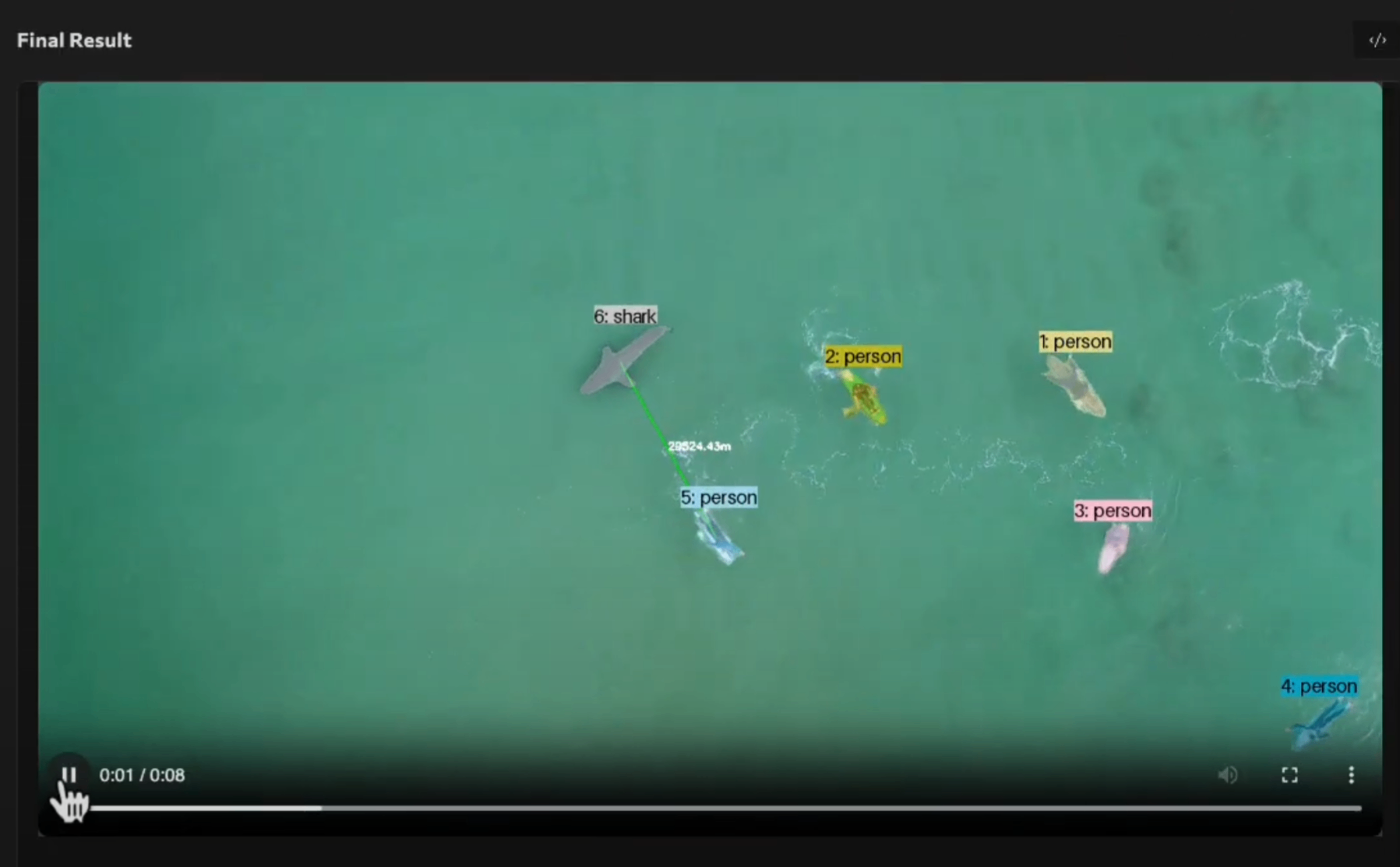
サメと人の距離をモニター
Can you track both people and sharks in this vidio?
Save a video with the tracked masks of both sharks and people and
draw a line between the shark and the closest person with the distance above it.
Use 13pixels = 1m and FPS10.
指示3:「このビデオで、人とサメの両方を追跡できますか?人とサメの追跡されたマスクを含むビデオを保存し、サメと最も近い人の間に線を引き、その上に距離を表示してください。13ピクセルを1メートルとし、フレームレートを1秒あたり10フレームにしてください。」
出力
VisionAgentの意義

VisionAgentを使うことが、同じリクエストをLLM(大規模言語モデル)に直接入力することとどう違うのか疑問に思うかもしれません。これには3つの重要な違いがあります。
まず、VisionAgentは実際には複数の専用エージェントの集合体です。
計画を立てるエージェント、コードを書くエージェント、コードを評価するエージェント、そしてさらにいくつかあります。
次に、VisionAgentは厳選されたツールのライブラリから選択します。これには、オープンソースの画像およびビデオモデル、LandingAIのカスタムモデル、LandingAIの事前トレーニング済みモデル、ビジョンAI関数、厳選されたAPIなどが含まれます。
最後に、VisionAgentは、ワンクリックでWeb APIまたはStreamlitアプリケーションにデプロイできます。LandingAIがインフラストラクチャを管理し、クラウド推論のためにモデルをホストします。
VisionAgentは2つの方法で試すことができます。GitHubリポジトリをクローンしてローカルで作業するか、va.landing.aiにアクセスしてください。
楽しい開発を!
Discussion