OpenAI o3-miniを読んだ
OpenAI o3-miniでたね
ということで
https://openai.com/index/openai-o3-mini/ を読む
We’re releasing OpenAI o3-mini, the newest, most cost-efficient model in our reasoning series, available in both ChatGPT and the API today.
Previewed in December 2024, this powerful and fast model advances the boundaries of what small models can achieve, delivering exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.
私たちは、OpenAI o3-miniをリリースしました。
もっと新しく、私たちの推論モデルシリーズの中でもっともコスト効率が良いモデルです。
ChatGPTでもAPIでも本日から利用可能です。2024年12月にプレビューされるこのパワフルで高速なモデルは、OpenAI o1-miniの低コストと低レイテンシーを維持しながら、科学、数学、コーディングに特に強みを持つ卓越したSTEM分野の機能を提供し、小型モデルが達成できることの限界を広げました。
OpenAI o3-mini is our first small reasoning model that supports highly requested developer features including function calling(opens in a new window), Structured Outputs(opens in a new window), and developer messages(opens in a new window), making it production-ready out of the gate. Like OpenAI o1-mini and OpenAI o1-preview, o3-mini will support streaming(opens in a new window). Also, developers can choose between three reasoning effort(opens in a new window) options—low, medium, and high—to optimize for their specific use cases. This flexibility allows o3-mini to “think harder” when tackling complex challenges or prioritize speed when latency is a concern. o3-mini does not support vision capabilities, so developers should continue using OpenAI o1 for visual reasoning tasks. o3-mini is rolling out in the Chat Completions API, Assistants API, and Batch API starting today to select developers in API usage tiers 3-5(opens in a new window).
OpenAI o3-miniは、関数コーリング、構造化された出力、開発者メッセージを含む、開発者からの要望の高い機能をサポートする最初のスモール推論モデルです。
OpenAI o1-miniやOpenAI o1-previewのように、o3-miniはストリーミングをサポートします。
また、開発者は"reasoning_effort"オプション-"low"、"midium"、"hight"-から選択し、特定のユースケースに最適化することができます。 o3-miniはビジョン機能をサポートしていないので、開発者は視覚的な推論タスクのためにOpenAI o1を使い続ける必要があります。
o3-miniは、API利用ティア3-5の一部の開発者向けに、本日からチャット完了API、アシスタントAPI、バッチAPIで展開されます。
ChatGPT Plus, Team, and Pro users can access OpenAI o3-mini starting today, with Enterprise access coming in February. o3-mini will replace OpenAI o1-mini in the model picker, offering higher rate limits and lower latency, making it a compelling choice for coding, STEM, and logical problem-solving tasks. As part of this upgrade, we’re tripling the rate limit for Plus and Team users from 50 messages per day with o1-mini to 150 messages per day with o3-mini. Additionally, o3-mini now works with search to find up-to-date answers with links to relevant web sources. This is an early prototype as we work to integrate search across our reasoning models.
ChatGPT Plus、Team、Proユーザーは本日よりOpenAI o3-miniにアクセスできるようになり、Enterpriseは2月にアクセスできるようになります。
o3-miniはモデルピッカーにおいてOpenAI o1-miniに代わり、より高いレート制限とより低いレイテンシを提供し、コーディング、STEM、論理的な問題解決のタスクのための魅力的な選択肢となります。
このアップグレードの一環として、PlusおよびTeamユーザーのレート制限をo1-miniの1日あたり50メッセージからo3-miniの1日あたり150メッセージに3倍にします。
さらに、o3-miniは検索と連動し、関連するウェブソースへのリンクから最新の答えを見つけることができるようになりました。 これは、推論モデル全体に検索を統合するための初期のプロトタイプです。
Starting today, free plan users can also try OpenAI o3-mini by selecting ‘Reason’ in the message composer or by regenerating a response. This marks the first time a reasoning model has been made available to free users in ChatGPT.
本日より、無料プランのユーザーも、メッセージコンポーザーで「理由」を選択するか、レスポンスを再生成することで、OpenAI o3-miniを試すことができる。 ChatGPTで推論モデルが無料ユーザーに提供されるのは初めてのことです。
While OpenAI o1 remains our broader general knowledge reasoning model, OpenAI o3-mini provides a specialized alternative for technical domains requiring precision and speed. In ChatGPT, o3-mini uses medium reasoning effort to provide a balanced trade-off between speed and accuracy. All paid users will also have the option of selecting o3-mini-high in the model picker for a higher-intelligence version that takes a little longer to generate responses. Pro users will have unlimited access to both o3-mini and o3-mini-high.
OpenAI o1が私たちの広範な一般知識推論モデルのままである一方、OpenAI o3-miniは、精度とスピードを必要とする技術的なドメインに特化した代替手段を提供します。
ChatGPTでは、o3-miniはスピードと精度のバランスの取れたトレードオフを提供するために、中程度の推論工数を使用しています。
すべての有料ユーザーは、モデルピッカーでo3-mini-highを選択することで、応答を生成するのに少し時間がかかる高知能バージョンを選択することもできます。 プロユーザーは、o3-miniとo3-mini-highの両方に無制限にアクセスできます。
Fast, powerful, and optimized for STEM reasoning
Similar to its OpenAI o1 predecessor, OpenAI o3-mini has been optimized for STEM reasoning. o3-mini with medium reasoning effort matches o1’s performance in math, coding, and science, while delivering faster responses. Evaluations by expert testers showed that o3-mini produces more accurate and clearer answers, with stronger reasoning abilities, than OpenAI o1-mini. Testers preferred o3-mini's responses to o1-mini 56% of the time and observed a 39% reduction in major errors on difficult real-world questions. With medium reasoning effort, o3-mini matches the performance of o1 on some of the most challenging reasoning and intelligence evaluations including AIME and GPQA.
OpenAI o3-miniは、OpenAI o1の前身と同様に、STEM推論に最適化されています。
中程度の推論力を持つo3-miniは、数学、コーディング、科学においてo1の性能に匹敵し、より速い回答を提供します。
専門家であるテスターによる評価では、o3-miniはOpenAI o1-miniよりも、より強力な推論能力を持ち、より正確で明確な回答を生成することが示されました。 テスターは、o1-miniよりもo3-miniの回答を56% の確率で好んでおり、実世界の難しい問題での大きなミスが39%減少していることが確認された。 中程度の推論努力で、o3-miniはAIMEやGPQAを含む最も困難な推論と知能評価のいくつかでo1の性能に匹敵します。
Competition Math (AIME 2024) 数学
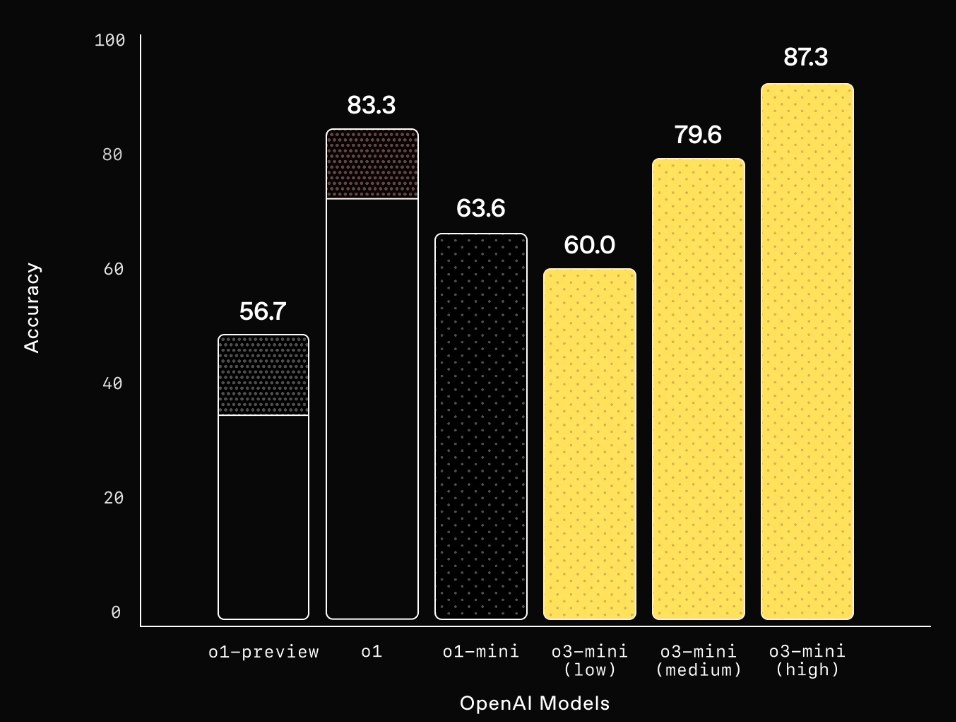
Mathematics: With low reasoning effort, OpenAI o3-mini achieves comparable performance with OpenAI o1-mini, while with medium effort, o3-mini achieves comparable performance with o1. Meanwhile, with high reasoning effort, o3-mini outperforms both OpenAI o1-mini and OpenAI o1, where the gray shaded regions show the performance of majority vote (consensus) with 64 samples.
数学: low 推論努力で、OpenAI o3-miniはOpenAI o1-miniと同等のパフォーマンスを達成し、midiumの努力で、o3-miniはo1と同等のパフォーマンスを達成する。 一方、high推論努力では、o3-miniはOpenAI o1-miniとOpenAI o1の両方を上回り、グレーの網掛け部分は64サンプルでの多数決(コンセンサス)のパフォーマンスを示しています。
PhD-level Science Questions (GPQA Diamond) 博士レベルの科学

PhD-level science: On PhD-level biology, chemistry, and physics questions, with low reasoning effort, OpenAI o3-mini achieves performance above OpenAI o1-mini. With high effort, o3-mini achieves comparable performance with o1.
博士レベルの科学 博士号レベルの生物学、化学、物理学の問題では、推論の労力が少ないにもかかわらず、OpenAI o3-miniはOpenAI o1-miniを上回るパフォーマンスを達成しました。 高い推論努力では、o3-miniはo1と同等のパフォーマンスを達成します。
FrontierMath 研究レベルの数学

Research-level mathematics: OpenAI o3-mini with high reasoning performs better than its predecessor on FrontierMath. On FrontierMath, when prompted to use a Python tool, o3-mini with high reasoning effort solves over 32% of problems on the first attempt, including more than 28% of the challenging (T3) problems. These numbers are provisional, and the chart above shows performance without tools or a calculator.
研究レベルの数学: OpenAI o3-miniの高い推論努力は、FrontierMath上で、前任者よりも優れたパフォーマンスを示した。 FrontierMath上で、Pythonツールを使うよう促されたとき、高い推論努力を持つo3-miniは、難易度の高い(T3)問題の28%以上を含む、32%以上の問題を最初の試みで解く。 これらの数値は暫定的なものであり、上のグラフはツールや電卓を使用しない場合のパフォーマンスを示しています。
Competition Code (Codeforces) 競技コーディング

Competition coding: On Codeforces competitive programming, OpenAI o3-mini achieves progressively higher Elo scores with increased reasoning effort, all outperforming o1-mini. With medium reasoning effort, it matches o1’s performance.
競技コーディング: Codeforcesの競技プログラミングでは、OpenAI o3-miniは推論の努力が増えるにつれて徐々に高いEloスコアを達成し、すべてo1-miniを上回った。 中程度の推論努力では、o1-miniのパフォーマンスに匹敵します。
Software Engineering (SWE-bench Verified) ソフトウェア・エンジニアリング
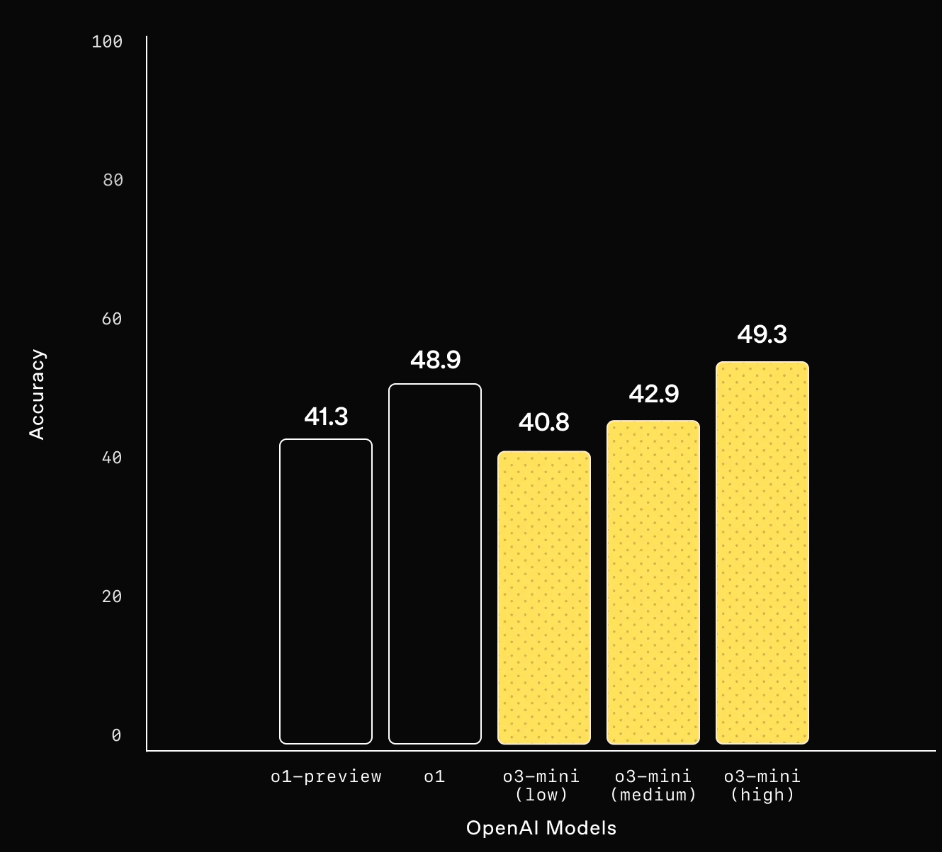
Software engineering: o3-mini is our highest performing released model on SWEbench-verified. For additional datapoints on SWE-bench Verified results with high reasoning effort, including with the open-source Agentless scaffold (39%) and an internal tools scaffold (61%), see our system card.
ソフトウェア・エンジニアリング:o3-miniは、SWEbenchで検証された当社の最高性能のリリースモデルです。 オープンソースのAgentless scaffold (39%)や内部ツールのscaffold (61%)を含む、推論工数の高いSWE-bench Verifiedの結果に関するその他のデータポイントについては、システムカードをご覧ください。
LiveBench Coding

LiveBench coding: OpenAI o3-mini surpasses o1-high even at medium reasoning effort, highlighting its efficiency in coding tasks. At high reasoning effort, o3-mini further extends its lead, achieving significantly stronger performance across key metrics.
LiveBenchコーディング: OpenAI o3-miniは、中程度の推論努力でもo1-highを上回り、コーディングタスクの効率性を強調している。 高い推論努力では、o3-miniはさらにリードを広げ、主要なメトリクスで大幅に強力なパフォーマンスを達成しています。
General knowledge 一般知識

General knowledge: o3-mini outperforms o1-mini in knowledge evaluations across general knowledge domains.
一般知識:o3-miniは、一般知識ドメインにわたる知識評価においてo1-miniを上回る。
Human Preference Evaluation 人間の好みによる評価

Human preference evaluation: Evaluations by external expert testers also show that OpenAI o3-mini produces more accurate and clearer answers, with stronger reasoning abilities than OpenAI o1-mini, especially for STEM. Testers preferred o3-mini's responses to o1-mini 56% of the time and observed a 39% reduction in major errors on difficult real-world questions.
人間の好みによる評価: 外部の専門家テスターによる評価でも、OpenAI o3-miniはOpenAI o1-miniよりも正確で明確な解答を生成し、特にSTEM分野ではより強力な推論能力を持つことが示されています。 テスターは、o1-miniよりもo3-miniの回答を56%の確率で好み、実世界の難しい問題での大きなミスが39%減少したことを確認しました。
Model speed and performance
With intelligence comparable to OpenAI o1, OpenAI o3-mini delivers faster performance and improved efficiency. Beyond the STEM evaluations highlighted above, o3-mini demonstrates superior results in additional math and factuality evaluations with medium reasoning effort. In A/B testing, o3-mini delivered responses 24% faster than o1-mini, with an average response time of 7.7 seconds compared to 10.16 seconds.
OpenAI o1に匹敵する知能を持つOpenAI o3-miniは、より速いパフォーマンスと改善された効率を提供します。 上記のSTEM評価以外にも、o3-miniは中程度の推論努力で数学と事実性の評価において優れた結果を示しています。 A/Bテストでは、o3-miniはo1-miniよりも24%速く回答を提供し、平均回答時間は10.16秒に対して7.7秒でした。
Latency comparison between o1-mini and o3-mini (medium)
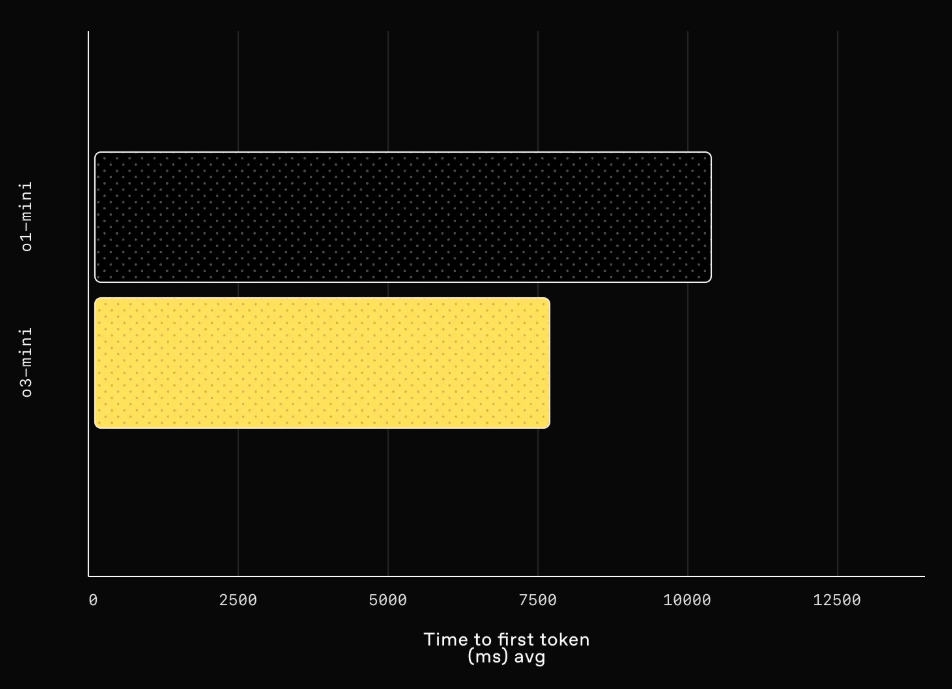
Latency: o3-mini has an avg 2500ms faster time to first token than o1-mini.
レイテンシー:o3-miniはo1-miniよりも最初のトークンまでの時間が平均2500ms速い。
Safety
One of the key techniques we used to teach OpenAI o3-mini to respond safely is deliberative alignment, where we trained the model to reason about human-written safety specifications before answering user prompts. Similar to OpenAI o1, we find that o3-mini significantly surpasses GPT-4o on challenging safety and jailbreak evaluations. Before deployment, we carefully assessed the safety risks of o3-mini using the same approach to preparedness, external red-teaming, and safety evaluations as o1. We thank the safety testers who applied to test o3-mini in early access. Details of the evaluations below, along with a comprehensive explanation of potential risks and the effectiveness of our mitigations, are available in the o3-mini system card.
私たちがOpenAI o3-miniに安全な応答を教えるために使用した重要なテクニックの1つは、熟考型アライメントです。 OpenAI o1と同様に、o3-miniはGPT-4oを安全性と脱獄の評価で大きく上回ることがわかりました。 配備の前に、我々はo1と同じ準備、外部レッドチーム、安全評価のアプローチを用いて、o3-miniの安全リスクを慎重に評価した。 早期アクセスでo3-miniのテストに応募してくれた安全性テスターに感謝する。 以下の評価の詳細、および潜在的なリスクと我々の軽減策の効果に関する包括的な説明は、o3-miniシステムカードに記載されています。
Disallowed content evaluations

Jailbreak Evaluations

What's next
The release of OpenAI o3-mini marks another step in OpenAI’s mission to push the boundaries of cost-effective intelligence. By optimizing reasoning for STEM domains while keeping costs low, we’re making high-quality AI even more accessible. This model continues our track record of driving down the cost of intelligence—reducing per-token pricing by 95% since launching GPT-4—while maintaining top-tier reasoning capabilities. As AI adoption expands, we remain committed to leading at the frontier, building models that balance intelligence, efficiency, and safety at scale.
OpenAI o3-miniのリリースは、費用対効果の高いインテリジェンスの限界を押し広げるというOpenAIのミッションの新たな一歩です。 コストを抑えながらSTEMドメインの推論を最適化することで、高品質のAIをより身近なものにしています。 このモデルは、トップクラスの推論機能を維持しながら、GPT-4の発表以来、トークン単価を95%削減し、インテリジェンスのコストを引き下げてきた実績を継続します。 AIの導入が拡大する中、私たちは、インテリジェンス、効率性、安全性のバランスが取れたモデルを大規模に構築し、フロンティアをリードしていくことをお約束します。
Discussion