JavaScript で人と同じように文字数を数える
🌼 はじめに
人はこのように文字数を数えます
"A" // 1文字
"😆" // 1文字
"👨👩👧👦" // 1文字
しかし、JavaScript に文字数を計算させたらこういう結果になります。
console.log("A".length) // 1
console.log("😆".length) // 2
console.log("👨👩👧👦".length) // 11
なぜこうなるのか、どうやったら JavaScript にも人間と同じ感覚で文字を数えさせるのか、今回はそれについて話します!!!
1. 文字集合とエンコーディング
まず大前提として人とコンピューターが扱う文字は違います。人は日本語とか英語とかの自然言語の文字を扱いますが、コンピューターが直接扱えるのは0/1の数字だけです。
そのため、人が使う文字をコンピューターに処理させるには、文字を0/1に変換しないといけません。
この変換の流れはざっくり 「①文字ごとに番号を振る」 → 「②その番号を 0/1 に変換する」 で行われます。
1-1. 文字集合
「①文字ごとに番号を振る」 ことで作られたものが文字集合です。文字集合にも色々種類がありますが現代だと Unicode が広く使われており、JavaScript も Unicode を採用しています。
| 文字 | Unicode |
|---|---|
| あ | U+3042 |
日本語文字 「あ」 に振られた番号は U+3042 だよ、という約束が Unicode です。
また、U+3042 のように Unicode で振った番号のことは Code Point(符号位置)と言います。
1-2. エンコーディング
では文字ごとに番号が振られたので、「②その番号を 0/1 に変換する」 必要があり、それをエンコーディングと言います。
Unicode 番号のエンコーディング方式には UTF-8、UTF-16、UTF-32 などいくつか種類があります。
UTF は Unicode Transformation Format の略なので共通で、その後につく数字は 1 Code Unit のサイズを表します。
エンコーディング結果を表すときは固定幅のコマを1個以上使いますが、その「固定幅のコマ」を Code Unit と言います。 例えば UTF-16 では 1 Code Unit のサイズが16bitという意味で、1個(または2個)の Code Unit で Code Point を表現します。
エンコーディング方式ごとの例↓
| 文字 | Code Point | エンコーディング方式 | Code Unit 構成 | Code Unit 値(HEX) |
|---|---|---|---|---|
| あ | U+3042 |
UTF-8 | 3 個(各8bit) | 0xE3 0x81 0x82 |
| あ | U+3042 |
UTF-16 | 1 個(16bit) | 0x3042 |
| あ | U+3042 |
UTF-32 | 1 個(32bit) | 0x00003042 |
JavaScript の内部で文字列を扱う際は UTF-16 を採用しているので、これからは UTF-16 エンコーディングを前提に話を進めます。
2. サロゲートペアと JavaScript
Unicode は現代で使われる文字体系ほとんどに対応していて、U+0000 から U+FFFF までの約65,536の Code Point によく使う基本的な文字・記号が含まれています。 この範囲を BMP (Basic Multilingual Plane, 基本多言語面)と言います。
BMP は多くの文字が 1 Code Point を 1 Code Unit で表現できます。
| 文字 | Code Point | UTF-16 Code Unit(HEX) |
|---|---|---|
| A | U+0041 |
0x0041 (1 Code Unit) |
| あ | U+3042 |
0x3042 (1 Code Unit) |
| 가 | U+AC00 |
0xAC00 (1 Code Unit) |
Unicode が作られた当時(1991年ごろ)はこれで充分だったと思いますが、ときが経つにつれて文字はどんどん増えてきました。1990年代の人は絵文字とかが出てくるとは思ってなかったでしょう。
結局 BMP だけでは増えていく文字を全部表現することはできず、BMP を超えた領域まで拡張して新しい文字を対応することになりました。その新しい範囲をSMP(Supplementary Multilingual Plane, 追加多言語面)と言います。
ただ、1 Code Point を 1 Code Unit で表現できるのは BMP までで、その範囲を超えた SMP だと 2 Code Unit 以上が必要になります。
それで誕生したものが2個の Code Unit を組み合わせて1個の Code Point を表現した仕組み、サロゲートペアです。
| 文字 | Code Point | UTF-16 Code Unit(HEX) |
|---|---|---|
| 😆 | U+1F606 |
0xD83D 0xDE06 (2 Code Unit) |
| 𓀀 | U+13000 |
0xD80C 0xDC00 (2 Code Unit) |
| 𠮷 | U+20BB7 |
0xD842 0xDFB7 (2 Code Unit) |
サロゲートペアは英語で Surrogate Pair(Surrogate = 代理、Pair=2人) なので、新しく何かを作る代わりに二人(2 Code Unit)合わせて新しい文字を表現しているという意味かな…と勝手に思ってます。
ここで本題に入ります。JavaScript 文字列の length は Code Unit の数を数えます。
だからこういう現象が起きます。
console.log("A".length) // Code Unit が `0x0041` 1個だから 1
console.log("😆".length) // Code Unit が `0xD83D 0xDE06` 2個だから 2
なるほど、"😆".length が2を出力する理由はわかりました。
ではこれはなんでしょう!
console.log("👨👩👧👦".length) // 11
実は複数の Code Point をくっつけて新しい文字を作ることもできます。
そのとき文字と文字をくっつけるのりみたいな役割をする特殊な制御文字を ZWJ(Zero Width Joiner、ゼロ幅接合子)と言い、ZWJ で複数の文字を結合して作られた文字はZWJシーケンス(ZWJ Sequence)と言います。
👨👩👧👦 はZWJシーケンスの一例で、以下のように構成されています。

では 👨👩👧👦 各構成要素の Code Point、Code Unit を見てみましょう。
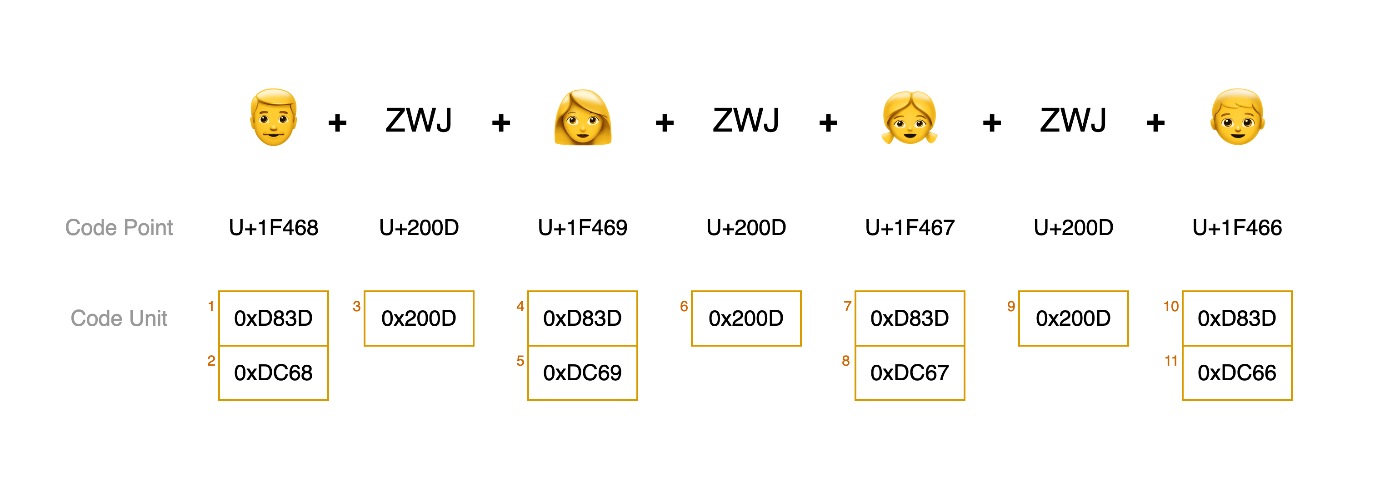
このようにZWJシーケンスを構成している要素の Code Unit を全部足したら11個なので、length は 11 を出力します。
console.log("👨👩👧👦".length) // 11
3. JavaScript に人の認識をもたせる
length の動きは理解できました。でも人は文字数を数えるとき Code Unit じゃなくて見た目の区切り、つまり書記素基準で文字を数えます。
では JavaScript にもその認識をもたせる方法を紹介します。
3-1. スプレッド構文 + Array.length (不完全)
文字列におけるスプレッド構文 (...) は文字列を1文字(1 Code Point)ずつの配列に変換します。なので、[..."😆"] をすると 1 Code Point ごとに区切った配列に変換されます。
そのため、この配列の length を計算するときは数える対象が Code Unit じゃなくて Code Point になります。
console.log("😆".length) // 2 (Code Unit を数える)
console.log([..."😆"].length) // 1 (Code Point を数える)
これでサロゲートペアも Code Point 基準で文字数計算ができました。
ですが、この方法はZWJシーケンスの場合上手くいかないです。
console.log("👨👩👧👦".length) // 11 (Code Unit を数える)
console.log([..."👨👩👧👦"].length) // 7 (Code Point を数える)
[..."👨👩👧👦"] して 1 Code Point ごとに区切った配列を作ると ["👨", "", "👩", "", "👧", "", "👦"] になり、Code Point を数えたら7になります(サロゲートペア4個 + ZWJ3個)。

ZWJシーケンスの場合が考慮されていないので、この方法は不完全です。
3-2. Intl.Segmenter
もっと安全な方法は Intl.Segmenter を使うことです。
Intl.Segmenter オブジェクトを使うと文字列から意味のある項目を取得できます。つまり、文字列を人が認識できる単位に分割できます。
このオブジェクトを利用して、JavaScript に書記素を数えるようにしたら人と同じ感覚で文字を数えられるようになります。
// locale を日本に、粒度(granularity)を書記素(grapheme)に指定
const segmenter = new Intl.Segmenter("ja", { granularity: "grapheme" });
console.log("👨👩👧👦".length) // 11 (Code Unit を数える)
console.log([...segmenter.segment("👨👩👧👦")].length) // 1 (書記素を数える)
これを踏まえて文字を数える関数でも作っといたら再利用できて便利でしょう!
const segmenter = new Intl.Segmenter("ja", { granularity: "grapheme" });
const countChar = (string: string) => {
return [...segmenter.segment(string)].length
}
console.log(countChar("A")) // 1
console.log(countChar("😆")) // 1
console.log(countChar("👨👩👧👦")) // 1
主要ブラウザと最近の Node.js の多くは Intl.Segmenter をサポートしています。ただ Firefox は 2024 年から対応したため、古い環境だと正常に動かない可能性があるので気をつけましょう。
+)書記素以外の基準で分割することもできる
粒度(granularity)を単語や文章に指定して分割することもできます。
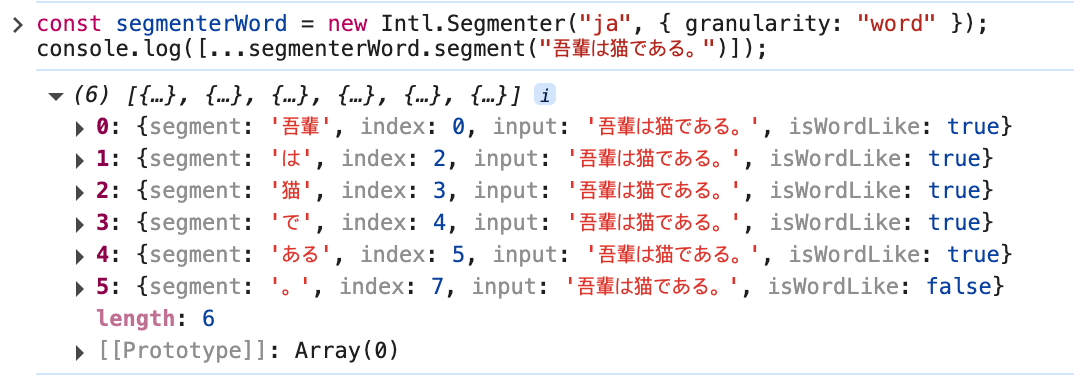
粒度(granularity)を単語(word)に指定

粒度(granularity)を文章(sentence)に指定
なんかめちゃくちゃすごくて韓国語の文章も分割してみたりで遊んでました。
🌷 終わり
ちなみに .split("") は UTF-16 の Code Unit 基準で分割されるため、サロゲートペアや ZWJ シーケンスを分断するリスクがあります。
console.log("A".split("")) // ['A']
console.log("😆".split("")) // ['\uD83D', '\uDE06']
console.log("👨👩👧👦".split("")) // ['\uD83D', '\uDC68', '', '\uD83D', '\uDC69', '', '\uD83D', '\uDC67', '', '\uD83D', '\uDC66']
この場合も Intl.Segmenter を使うと書記素ごとに分割できます。
const segmenter = new Intl.Segmenter("ja", { granularity: "grapheme" });
const splitString = (string: string) => {
return [...segmenter.segment(string)].map(({ segment }) => segment)
}
segmenter.segment(str) はイテラブルを返し、各要素は { segment, index, isWordLike } などを持つオブジェクトです。文字そのものは segment に入っているので、map で segment だけ抽出することで文字ごとの配列が作れます。
console.log(splitString("A")) // ['A']
console.log(splitString("😆")) // ['😆']
console.log(splitString("👨👩👧👦")) // ['👨👩👧👦']
console.log(splitString("A😆👨👩👧👦")) // ['A', '😆', '👨👩👧👦']
Discussion