はじめまして、株式会社Luup SREチームに所属しています、ぐりもお(@gr1m0h)です。
Nobl9社が主催する SLOconf というSLO(サービスレベル目標)にフォーカスしたカンファレンスのローカルなコミュニティーイベント、SLOconf Tokyo 2023 に登壇しました。このイベントは、Googleの渋谷オフィスで 5/16 に開催されました。
発表資料は以下になります。
はじめてのオフライン登壇でした。これについては個人のブログに記載しています。
この記事は登壇内容についての詳細になります。
資料を読めば良いというのはあるのですが、口頭で話した部分は資料から読み取れないのでこのブログで補足していきます。
はじめに
はじめに、何故このテーマで話すに至ったのか簡単に書いてみます。主題ではないのでこの項は読み飛ばしていただいても構いません。
現在LuupのSREチームではSLOを設定し、運用しています。
内容については後述しますが、最近までSLOを設定したまま、あまりアクションが取れていない状態でした。
それを改善するため、「SLOを運用する」とはどういう状態か、「SLOを運用する」にはどんな準備が必要なのかを考え、運用を実際に始めてみました。
この登壇はそれを外に出す良い機会だったため、Google山口さんのSLOconfの登壇募集に手を上げたというのが経緯になります。
なので、当初はどこでも良いからこの話をしたいという思いで、SLOconfでなくても他にSREのイベントがあればそこで話そうと考えていました。ただ、LUUPというIoTデバイスが関わるサービス特有のSLIを設計する際の考え方である CMC: Critical Machine Communicationを紹介できたこと、IoTデバイスが関わるサービス特有のSLOを設定してみての問題を共有できたことは結果的にはSLOconfという場でお話しすることに大変意義があったものになったかなと思っています。LuupとしてSLOを取り巻くコミュニティー(SLOconfやSLOconfの内容を参照するであろうSREのコミュニティーなど)に対して貢献できたと感じています。
登壇内容について
登壇資料にある通りアジェンダとして、大きく以下4つがありました。
- Luup SREチーム
- LUUPにおけるSLO
- LuupにおけるSLO運用
- Luup SREチームの今後
1は本題へ向かうための前提として組織についてお話ししました。4は本題を受けて今後SREチームでどのあたりに挑戦していくかをお話ししています。これらは概ね資料から読み取れると思っているのでここでは記載しません。詳細が気になる方は是非私にDMを送ったり、弊社にカジュアル面談に来ていただければと思います。
ということで、2、3について口頭で話した内容を記載していこうと思います。
LUUPにおけるSLO
ここでは、LUUPにおけるIoTデバイスを踏まえたSLIの考え方、実際に設定しているSLOについて紹介しました。
LUUPにおけるSLIの考え方
SLIの設計については CUJ: Critical User Journey という考え方をよく使用されます。CUJはサイトリライアビリティワークブック[1]に以下のように記載がある通り、「重要な顧客体験、お客様の行動を示したもの」です。
究極的にはSLOの主眼は顧客体験の改善であるべきです。
したがって、SLOはユーザーを中心に置くアクションについて書かれるべきです。
顧客の体験を補足するには、クリティカルユーザージャーニーを利用できます。
クリティカルユーザージャーニーは、あるユーザーの体験の中核部分となるタスクの並びで、サービスのきわめて重要な側面です。
Webやアプリの世界ではこのCUJを重視し、ここからSLI、SLOの設計に落とし込んでいくことになると思います。
IoTでは、「マシンが期待通りに動作できる状態であるか」を計測すべきですが、このようなM2Mの部分はユーザーの行動に含まれないためCUJではカバーできません。そこでLuupでは、CMC: Critical Machine Communication という考え方を導入しています。このCMCは一般用語ではなく、Luup内でCUJと区別するために作成された用語です。

何か一般用語がSRE関連で他に存在すればそちらに統一しようと考えています。(余談ですが、懇親会でこの辺りについていろんな方とお話ししたのですが、同じような考え方は他になさそうでした。私の観測範囲ですが。)
CMCの対象となるものとしては、バッテリーが切れていないか、サーバーと接続されているか等があり、プロトコルとしてはMQTTやLwM2M等があります。
CMCやIoTxSREについてはSRE NEXT 2022で登壇したときのセッションに詳しく記載されていますので、こちらを確認いただくのが良いと思います!
登壇資料
登壇動画
LUUPで設定しているSLO
次に、LUUPで実際に設定しているSLOについて紹介しました。
LUUPを使用してユーザーがライドを行う際の一連のアクティビティとしてはこのようになっております。アプリを立ち上げ、車両に乗るポート、車両を返却するポートを選択肢、ライドを行います。このうち、SLOの対象となっているのは緑の枠で囲っている「ライドの開始」「ライドの一時停止」「ライドの再開」の3つのアクティビティです。

ライド開始のシーケンス図を簡略化したものを例として記載します。この中でSLOの対象となっているのは緑の枠で囲っているCloudFunctionsとAWS IoTの通信の部分です。

SLOとしては、Availability SLOとLatency SLOを設定しており、どちらもPdMやCTO等関係者と合意して99%に設定しています。それぞれの設定については以下ブログを参照いただければと思います。
対象としては、まだCUJ的な対象しか設定できていないのですが、先述した「ライドの開始」「ライドの一時停止」「ライドの再開」に該当するAPIを対象としています。
LuupにおけるSLO運用
ここでは、LuupにおけるSLO運用について実際にどのように行なっているか、行おうとしているかについて紹介しました。
LuupにおけるSLO運用構成

こちらがSLO周りの構成図です。
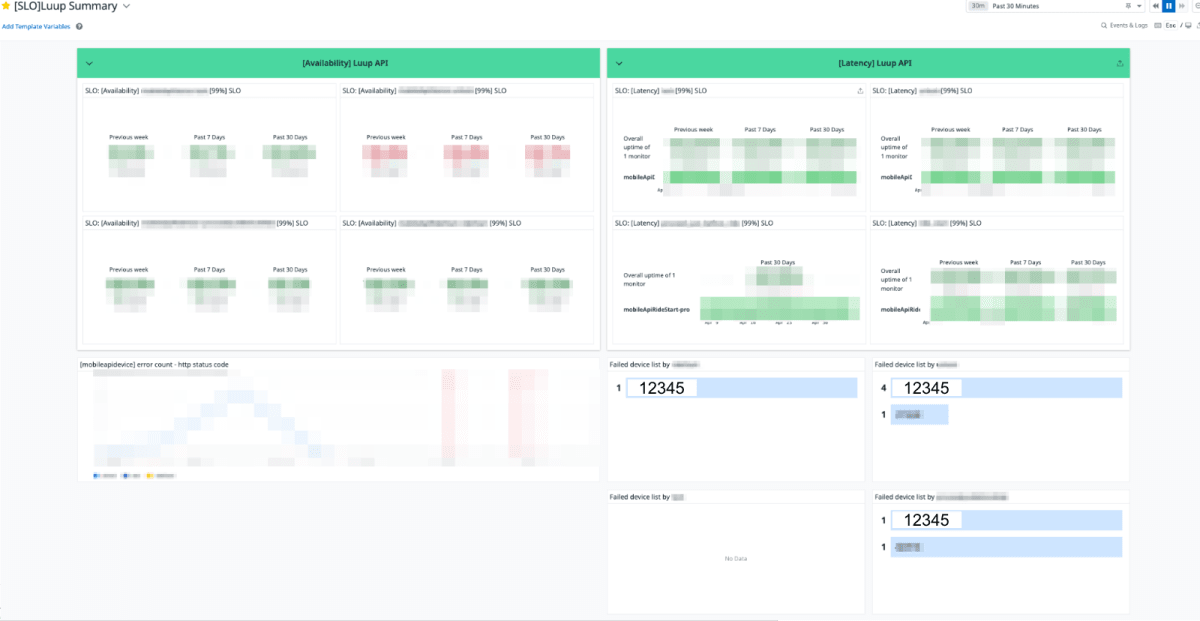
Datadogを使用しているので、このようなSLOのダッシュボードも用意しています。Availability SLO、Latency SLOを表示しています。特徴的なものとしては、Latency SLOの下にある部分でここではAPI別にエラーを検知したデバイスNo.と件数を表示しています。SLO AlertやBurn Rate Alertなどが起きた際ににはまずこのダッシュボードを確認するようにしています。
LuupにおけるSLO運用方法
ここからはLuupにおけるSLOの運用方法についてです。まず、運用方法を考えるにあたって、運用されている状態について認識合わせを行いました。

これらを整理すると、「SLO違反対応、SLO Burn Rate Alert対応、SLO定期見直しの3つのイベントに対する対応」と「Enabling SREという活動」という二つの対応が必要ということがわかります。
まず、SLO定期見直しです。

Luupでは2Q(半期)ごとに定期見直しを実施する予定です。内容としては大きく2つ「定期見直し会」と「SLO、Burn Rate Alert閾値変更対応」を実施します。
定期見直し会では、ファシリテーターはSREチームでSLOに関連するチームメンバーを呼んで実施します。承認者はCUJであればPdM, CMCであればHWチームが担うことになります。
将来的にはGitHub Issueを使用してコミュニケーションを取っていきたいと考えています。ただ、この場合もSREチームありきなので各開発チーム主導にするための施策は別途考えていきたいと思っています。
次にSLO違反対応です。

大きく2つ、「SLO違反対策検討会議」と「SLO違反対応」の実施を行います。基本的にはこの2点を繰り返していき、解決まで進めます。
SLO違反対策検討会議では、定期見直し会同様に該当SLOの関係者を集め対応などを議論します。
最後にBurn Rate Alert対応です。

大きく3つのことを行います。「止血/緩和対応」、止血/緩和できなかった時にはエスカレーションし、「他チームメンバーとコミュニケーションを」行います。そして、「対応の実施」です。途中、インシデントに拡大した場合には、インシデント管理に基づいて対応し、ポストモーテムを作成します。基本的には障害対応と同様に緊急度の高い対応をします。
Luup Case Study: Unlock Availability SLO違反
SLO運用を開始し、現状のSLOを見直して気づいた問題として、UnlockのAvailability SLO違反が常態化しているという問題がありました。これをケーススタディとして紹介しました。
実際にこの問題に対してSLO違反対策検討会議を実施し、原因として考えられるものとして2つ上がっています。

1つ目は、オペレーション用アプリが同じAPIを使用していることです。
これにより、社内外のサービス運用者には影響があるが、LUUPのユーザーには影響ないという状態であってもErrorBudgetが削られるという問題があります。これを改善するためOpsアプリが使用するAPIを別にするというアクションを進めています。また、この新たに作成したAPIに関してもSLOを設定し、社内外のサービス運用者をユーザーとして見た時の信頼性を計測する予定です。
luupのオペレーション用アプリについて詳しくは以下の記事をご覧ください。
2つ目は、同じ車両のリトライによってエラー回数が増えているということです。
これの何が問題かというと、単一の車両のネットワークやファームウェア等車両の問題により一人のユーザーにしか影響がない状態にも関わらず、全体のErrorBudgetを削っているという状態になってしまうためです。単一の車両がダメなら他の車両をサジェストしても良いのですが、複数リトライを実施すれば解決することもあるので、ある程度自動でリトライを行うことは必要です。
また、リトライという行為はサービスを提供できていないということではないためエラーではなくワーニングとして扱うべきものでAvailability SLOに影響が出てはならないものです。サービス提供が遅れたということでLatency SLOに影響が出るのが正しい状態だと思います。
これを改善するため、サーバー側での自動リトライの追加によるリトライの内包を進めています。
Enabling SRE
ここでは、Luupで行なっているEnabling SREについて紹介しました。

Enabling SREとは、開発チームにSREの文化/知識を浸透させて開発者自身がSRE Practiceを実践できるようにする活動を指します。Enabling SREがSREチームのあり方として定義される場合もありますが、ここでは単にSREの普及活動としての意味合いです。
現在の活動としてSLOのIaC化と社内勉強会を進めています。
さいごに
登壇内容が濃かっただけにしっかり書いてしまいました。ハードルを上げるつもりはないので、次回はもっとゆるく書いていこうと思います。
最後に登壇の様子を記載しておきます。
また、文中に記載した通りですが、弊社でのプロダクト開発、SREや使用技術に少しでも興味を持っていただけた方は、以下のリンクからお気軽にご連絡ください!私のTwitterアカウントもDM解放しています。
直近副業や転職を考えている方でなくとも、ただ気軽に話を聞きたいという方でも歓迎です!

Discussion