はじめに
LuupのSREチームに所属している、ぐりもお(@gr1m0h)です。
日本最大のSREカンファレンス SRE NEXT 2024 に登壇しました。このカンファレンスはSRE Loungeの運営メンバーが主体となって運営しており、今回で4回目の開催です。
私の登壇の題は「Enabling Client-side SLO」です。これまでの「Enabling SLO」の活動の一環として、クライアントサイド(iOS・Android)のSLOのを計測し始めた話を共有しました。「Enabling SLO」とは、各開発チームがSREを実践し、SLI/SLOを自律的に設計・実装・運用できるようにする活動です。
登壇では、AndroidやiOSの開発チームとプロダクトマネージャーと共に、クライアントサイドのSLOの運用を始めるまでの意思決定や課題について共有しました。まさに 「信頼性は会話です」[1] という内容になっています。
また、前回のSRE NEXT 2023 では、Luupの開発組織全体とIoT開発チームに対して行ったEnabling SLOの話をしました。今回の発表はその続きとなるので、併せてご覧いただくと、Luup SREチームのSLOに関する活動についてよく理解いただけると思います。
後日、アーカイブ動画が公開されると思いますが、資料だけでは口頭での説明が漏れてしまい、意図が伝わらない可能性があります。そのため、登壇内容をブログとしてまとめます。
LUUPでクライアントのSLOを設定する理由
活動を進めるにあたって、世の中に出ているiOS・Android・Web FrontendのSLOに関する情報が少ないことに気づきました。その理由について考え、LUUPでクライアントサイドのSLOを設定する意義を検討しました。
考えられる理由は以下のとおりです。
- コストの問題
- ユーザー側の都合に左右される問題
- ネットワークの問題や端末の差異、ユーザー側の途中キャンセルなど
- これらの問題があるため、バックエンドやインフラの方がコントロールしやすい
- 2017年のSREconで 「Engineering Reliable Mobile Applications」として話された内容でもこの辺りについて触れられています[2]
- ネットワークの問題や端末の差異、ユーザー側の途中キャンセルなど
- 「SRE」というロールのバックグラウンド・ケイパビリティの問題
- バックエンドやインフラ出身者が多く、クライアントサイドの信頼性に関する経験が少ない
- クライアントサイドでSLOを設定する必要がない場合がある
- サービスがAPIでほぼ完結する場合はAPIのSLOで十分なため
これらの理由を踏まえて、LUUPでクライアントサイドのSLOを設定する動機は以下の通りです。
- よりユーザーに近い部分での計測が望ましい
- クライアント側でAPIを介さずにFirestoreを利用しているケースがある
- APIだけの計測では見逃してしまう部分がある
- Firestoreの直接利用をAPI経由にすることで、クライアントサイドのSLOを一部省略できる可能性がある
- APIを介さない処理も含めて、ユーザー体験を計測したい
- APIだけでなく、BLEでの操作も含みたい
LUUPでクライアントのSLOを設定するために行った取り組み
クライアントのSLOを設定するために。以下の取り組みを行いました。
- CUJの再設定
- SLIの設定
- 文化醸成
- SLOの設定
それぞれについて詳しく説明します。
1. CUJの再設定
まず、なぜ 再 設定する必要があったのかについてです。
IoTに関連するAPIのSLOを設定する際、CUJを基に設定していました。しかし、この時はLUUPにおいて自明である鍵の施錠・解錠を対象とし、サービスのユーザージャーニーを洗い出してCUJを決めるということをしていませんでした。
今回は、1からユーザージャーニーの洗い出しを行いました。
CUJの再設定にあたって、ユーザージャーニー一覧をプロダクトマネージャーに作成してもらい、それを基に議論し、マトリクス形式で結果をまとめました。
ユーザージャーニー一覧は以下の通り、フローチャートでプロダクトマネージャーにまとめてもらいました。このユーザージャーニー一覧を基にプロダクトマネージャー、ソフトウェアエンジニア、SREで議論しました。
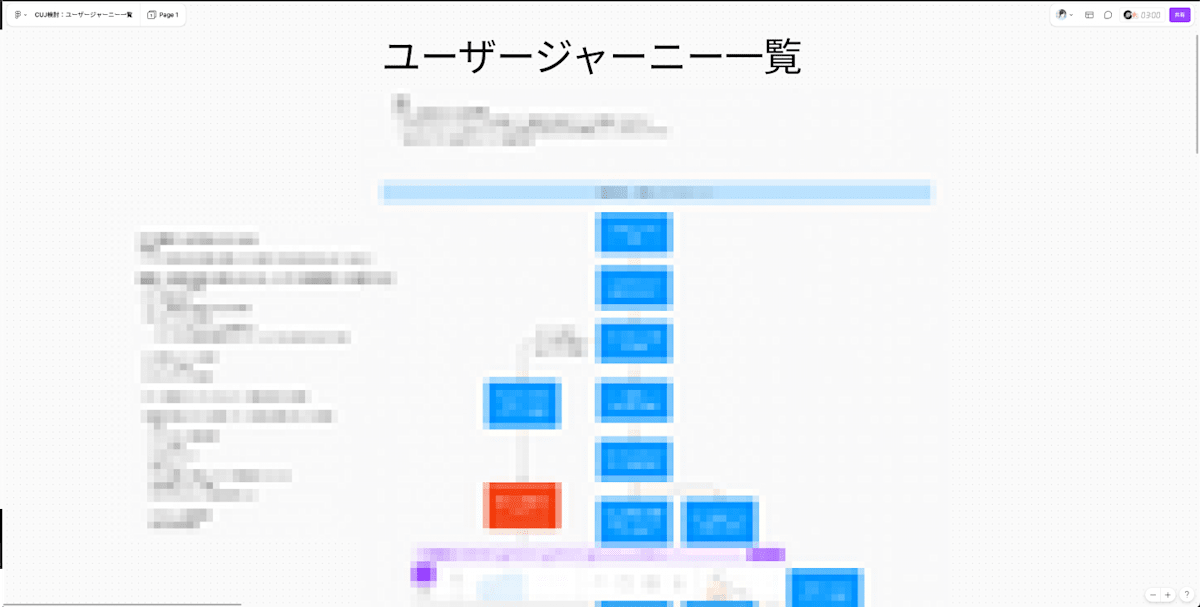
議論のアウトプットとして、以下の通りマトリクス形式でまとめました。
それぞれのユーザージャーニーの関連チームをまとめ、SREで運用しているSLOとの関連、CUJにするかどうかを記載しています。
この活動が進むにつれて、Firebase Performanceのカスタムトレース名やクライアント側で叩いているAPIの一覧を追記しました。

2. SLIの設定
SLOを考える際によく使われるものとして、可用性(Availability)と遅延(Latency)があります。クライアント側でこれらがどのような状態かを現状把握しました。
結果として、既に同様の目的から確認している指標があったので、今回はそれを活用しました。
FirebaseではSLOを設定したり、エラーバジェットの計測ができないため、Datadogにメトリクスをアップロードします。可用性のFirebase ClashlyticsはDatadog RUMで、遅延のFirebase PerformanceはDatadog APMで同様の指標を取得できます。SREでトライアルしたところ、Datadog RUMはコストなどの観点から断念しました。
既存の値を参考にしながら、まずはLatency SLOから始め、クライアントサイドで運用実績を作ることにしました。
Datadog APMの利用については、SREが主導で進め、iOSおよびAndroidチームのサポートのもとでSDKの導入、トレースの設定を行いました。今回は具体的な処理情報が不要だったので、spanは1つだけにしています。

Datadog APMを使って、値を取得できたので、これを基にSLIを設計しました。
クライアントサイドではユーザー側の都合に左右される問題を考慮する必要があります。そのため、パーセンタイル値を設定する際に悩みました。
最終的に、以下のDatadogクエリの通り、75パーセンタイル(75%ile)を設定しました。
p75:trace.<TRACE_NAME>{service:<SERVICE_NAME>, env:production}
ユーザー側の都合に左右される問題については、SLOに関係なくウェブのパフォーマンスを評価する際に考慮すべき問題です。そこで、Googleが提唱するユーザー体験の品質を測定するための指標であるCore Web VitalsのLCPに注目しました。この指標では、良いスコアを「75%ileの2.5秒以下」としています。ここから、ユーザー側の都合に左右される問題を除外するために75%ileの設定が必要と判断しました。
3. 文化醸成
Enabling活動で最も重要なのは、文化醸成や運用を軌道に乗せる部分です。これを進めるために、SLIを確認するためのダッシュボード作成と、WeeklyでもSLI/SLOをWeeklyで確認するという2つを実施しました。
以下の動機から、SLI確認用のダッシュボードを作成しました。
- SLO設定のための情報収集
- SLIというメトリクスをソフトウェアエンジニアに親しみやすいものにする
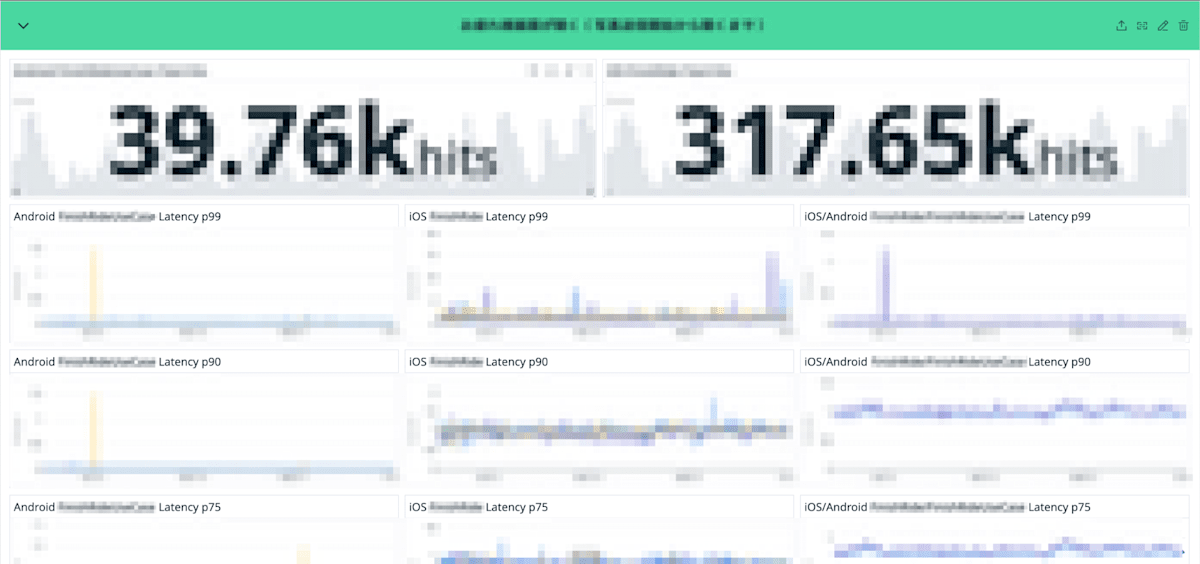
プロダクトマネージャーやソフトウェアエンジニアがイメージしやすいように、CUJごとにグループ分けし、iOSとAndroidのパフォーマンスを比較しやすいようにグラフを並べるなどの工夫をしました。
また、SLI/SLOを意識するために、Weeklyでダッシュボードを確認しています。
SREがファシリテーションを担当し、ダッシュボードを確認して気になる点をサマリーとして共有しています。CUJ、SLI、SLOの妥当性や実際のパフォーマンスについて議論しています。
先ほどのダッシュボードは情報が多いため、議論をしやすくするためにこの会議用のダッシュボードを別途作成しました。
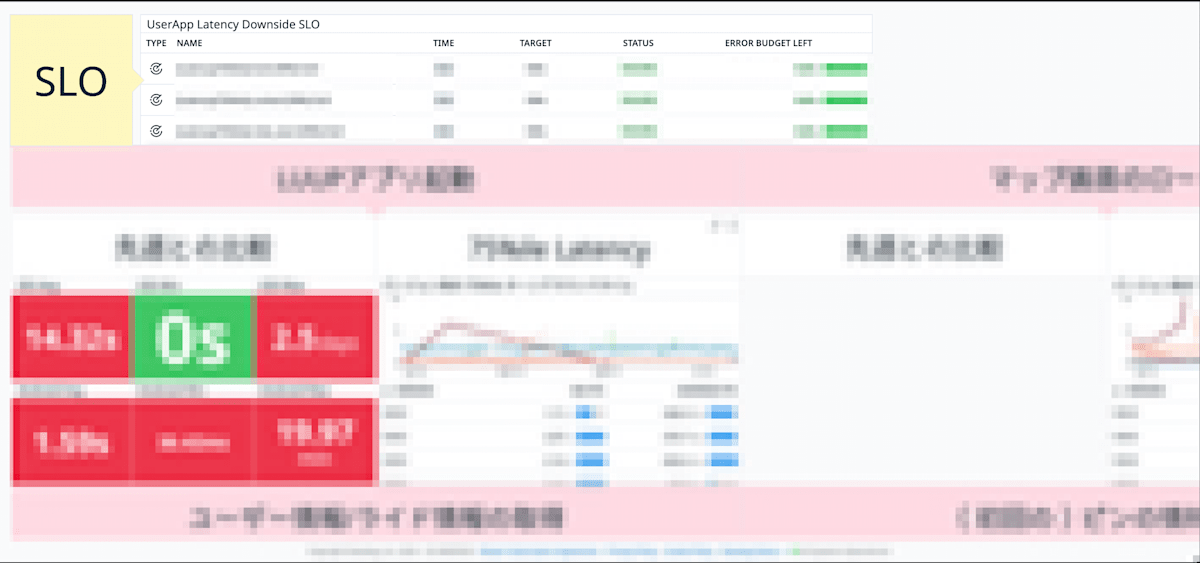
4. SLOの設定
SLOを実際に設定する際、運用を考慮してどの用に作成するかを検討しました。DatadogでのSLO作成と複数のSLOを作成するアプローチを実施しました。
DatadogでのSLO作成
これまでDatadogでLatency SLOを設定する際にはMonitor-based SLOを使用していましたが、今回はTime Slice SLOを検討しました。
Monitor-based SLOを採用した当時、Time Slice SLOは一般利用可能(GA)ではなかったため、どこかで評価したいと考えていました。[3] 今回、新規でSLOを設定する良い機会だったので、Time Slice SLOを調べて採用を検討しました。
Monitor-based SLOとTime Slice SLOの違いについては以下に記載があります。
Monitor-basedは、Datadog Monitorを基にSLOを作成する方法で、SLIはDatadog Monitorのアップタイムを基にしています。Time SliceのSLIは、システムの正常動作時間を合計時間で割ったカスタムアップタイムに基づきます。Datadog Monitorを必要とせず、SLOを設定できます。
Time Slice SLOを採用した理由は以下の通りです。
- Datadog SLOの利用できる機能の多さ
- Time Slice SLOはMonitor-based SLOと違い、Datadog SLOのカレンダービューなど多くの機能を利用できる
- データポイントの評価方法
- Time Slice SLOのほうが詳細にパフォーマンスを評価できる
- Monitor-based SLO; Datadog Monitorに基づく評価
- Time Slice SLO; 最小1分単位の時間スライスの割合で評価
- LUUPのアプリは短期的なパフォーマンス変動が重要ではないため、割合によって値が丸められることを許容できる
- Time Slice SLOのほうが詳細にパフォーマンスを評価できる
Multi-tiered SLOs
SLOの値の意味や基準を決める際に悩むことがあったため、プロダクトマネージャーがイメージしやすいように複数のSLOを作成しました。

将来的に目指す水準である「Upside」、現実的に割りたくない水準である「Downside」、実測値を基に設定する「Actual」の3つを定義しました。基本的には「Downside」を重視して運用します。
このように1つのSLIに対して複数のSLOを作成する考え方は、以下にも記載されています。
上記で紹介したMulti-tiered SLOsを使ったSLOの運用について説明します。
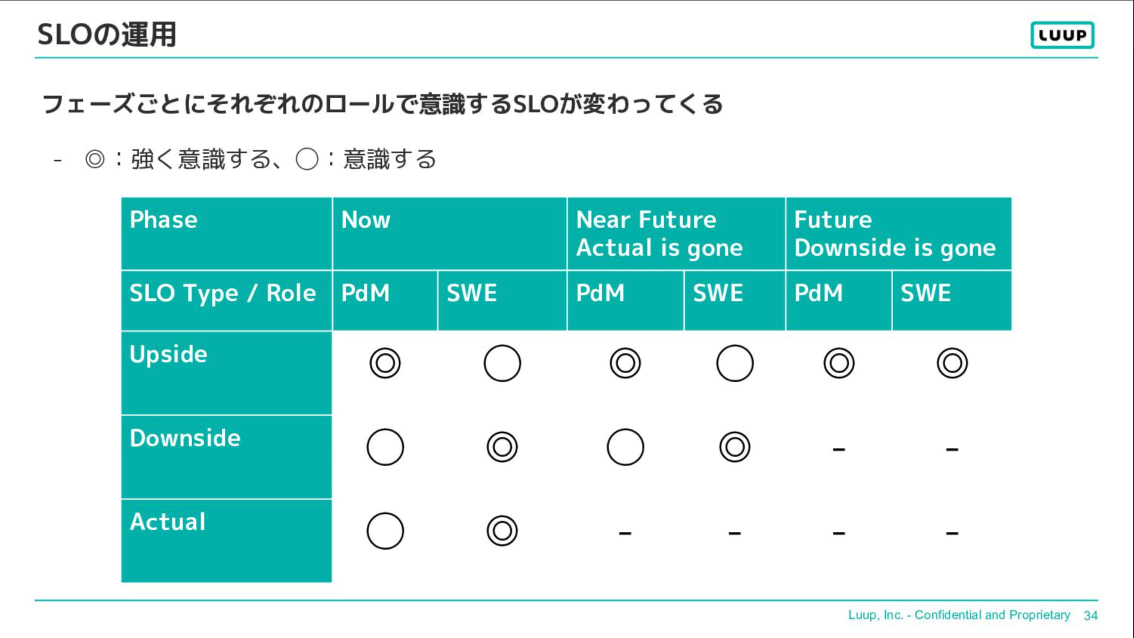
フェーズごとに各ロールで意識するSLOが異なります。プロダクトマネージャーはSLOの達成に注力し、ソフトウェアエンジニアと協力して「Actual」の値を理想的な範囲に近づける活動を行い、将来的にはより高い目標の達成を目指します。ソフトウェアエンジニアはSLOの維持に注力し、「Actual」を監視・改善します。SREも基本的にはプロダクトマネージャーと同様です。また、最終的にはソフトウェアエンジニアがSLOを見ながら活動できるようにサポートします。
今後の展望
現在進行中の活動や今後の展望としては、現場のエンジニアに寄り添ったアラートチューニングを行っています。また、75パーセンタイルを設定し、Tile Slice SLOを設定しているため、補助的なアラートを追加も検討しています。運用面では、「Actual」を廃止し、すべてのSLOで「Downside」を見る体制を整えたいです。また、クライアントサイドだけでなく、APIのSLOも同時に運用し、クライアントとサーバーの関連を見つつ改善を図ります。さらに、クライアントサイドのAvailability SLOの追加も検討中です。
さいごに
クライアントサイドのSLOを導入するときに特に悩んだことや大きな意思決定について紹介しました。LUUPに関して重要なユーザージャーニーを1から考え直し、クライアント特有の問題を考慮しながらSLIを設定しました。また、文化醸成のためにダッシュボードを作成し、Weeklyで確認する場を設け、運用を考慮したSLO設定を行いました。この登壇がクライアントサイドのSLOを検討する際の参考になれば幸いです。
今回の活動を通じて、Enabling活動は相手の立場に立つことが重要だと改めて感じました。
SLOはあくまでツールであり、このツールをプロダクトマネージャーやソフトウェアエンジニアに提供するイメージです。したがって、ユーザー体験の改善や事業フェーズに合った課題解決のためにSLOを活用し、理論に囚われずに挑戦していくことが重要だと思います。
最後に、弊社のプロダクト開発やSRE、使用技術に興味を持っていただけた方は、以下のリンクからお気軽にご連絡ください!私のX(Twitter)アカウントでもDMを受け付けています。
副業や転職をお考えの方だけでなく、気軽に話を聞きたいという方も大歓迎です!

Discussion