こちらの記事は、Luup Advent Calendar 2025 の10日目の記事です。
はじめに
こんにちは、Data Science&Engineering Teamリーダーの小林です。
私は、データ基盤の開発や整備を主な担当業務としており、日々AIを社内でどう活用していくか、どのようなデータ環境であれば活用がしやすいかということを考え実装しています。
最近、BigQueryからVertex AI経由で簡単にLLMを呼び出せる関数が追加され、さまざまな場面で便利に使えるようになってきました。
本記事では、この機能の利用方法と、実際に役立つ具体的なユースケースをご紹介します。
何が嬉しい?
利用方法やユースケースを紹介する前に、BigQueryから直接LLMを呼び出せるメリットを説明します。
- データ移動が不要: BigQuery内のデータを外部へ持ち出さずにLLM処理でき、データのやり取りが簡単
- 既存ワークフローへの組み込みが容易: SQLの中で完結するので、dbtなどのデータ基盤用ワークフローに組み込みやすい
- バッチ処理との親和性: BigQueryの環境で大量データに対するLLM処理を効率的に実行できる
- BIツールとの連携: 生成結果をそのままテーブルに保存してBIツールなどで可視化できる
つまり、AIやLLMアプリの知識やノウハウを持っていない人でも、使い慣れたSQLの延長線上でLLMを扱える ことが大きな強みです。
利用方法
BigQueryからVertex AIのモデルを利用するには、 AI.GENERATE という関数を使うことで簡単に利用できます。
select
AI.GENERATE(
("都市の特徴を1文で簡単に説明してください", city)
).result
from unnest(["東京", "大阪", "京都", "名古屋","福岡"]) as city;
今まであったML.GENERATE_TEXTと比べると、以下のような違いがあります。
- 事前にリモートモデルを準備する必要がない
- 通常の関数になっている(GENERATE_TEXTはテーブルをinput,outputとするテーブル関数)
このように、より使いやすくなっています。
利用にあたって幾つかの準備が必要なので、以下で手順を説明します。
1. Vertex AI APIの有効化
APIの有効化は以下のURLから行えます。
2. Vertex AIを利用する権限を付与する
Vertex AIを利用するには、直接アカウントに権限を付与するか、またはVertex AIへのconnectionを作成して、サービスアカウントに権限を付与する必要があります。
connectionを作成して利用する場合には、関数の中でconnection_idを指定して利用します。
connectionの作成に関しては以下の記事が参考になります。
- コンソールから作成→権限付与する場合:
大量のgeminiの呼び出しは、BigQueryのAI.GENERATEを使う - terraformを利用する場合:
Terraform で Vertex AI 接続を作成し、BigQuery ML から呼び出せるようにする
以上の設定をすることで、BigQueryから直接Vertex AIのモデルを呼び出すことが可能になります。
具体的なユースケース
それでは、実際にどのような使い方ができるのか、具体例を見ていきましょう。
1. 自由入力文章内容の自動ラベリング
サービスに寄せられた声やお問い合わせなどの、自由入力文章を自動分類します。
with comments as (
select
report_id,
comment
from `project.dataset.comments`
where created_at >= timestamp_sub(current_timestamp(), interval 1 day)
)
select
report_id,
comment,
AI.GENERATE((
"内容のpositive/negativeの度合いをpositiveを1でmaxとして[0,1]の範囲で pn_rate に入れてください\n",
"categoryを、[vehicle, service, app, port, other] から選んでください\n",
comment
),
endpoint => "gemini-2.5-flash",
output_schema => "pn_rate float64, category string"
).* except(full_response, status) -- 必要ない項目を除外
from comments;

事前学習なしにしてはそこそこの精度が出ているように見えます。
この結果をdbtのモデルとして保存することで、毎日自動的に更新されるようになります。
2. ダッシュボードの自動サマリー、インサイト生成
ダッシュボードなどで定常的に見ているデータに対して、外部要因(天気、祝日など)を組み合わせて、自動的に数値の変動や傾向のサマリーや、インサイトを生成できます。
with
daily_report as (
select
to_json_string(
array_agg(t)
) as kpi
from `project.dataset.daily_report` as t
where
report_date >= current_date() - 30
),
daily_weather as (
select
to_json_string(
array_agg(t)
) as weather
from `project.dataset.daily_weather` as t
where
date >= current_date() - 30
)
select
AI.GENERATE(
(
"直近30日のサービスの各種KPIデータと、天気のデータをもとに、",
"ここ1週間のトレンドとその要因を要約してください。",
"天候や曜日によって影響を受けるのでそれを加味してください。",
"サービスのデータ:", kpi,
"天気のデータ:", weather
),
connection_id => "project.region.vertex_connection_id",
endpoint => "gemini-2.5-flash"
).result
from daily_report, daily_weather;
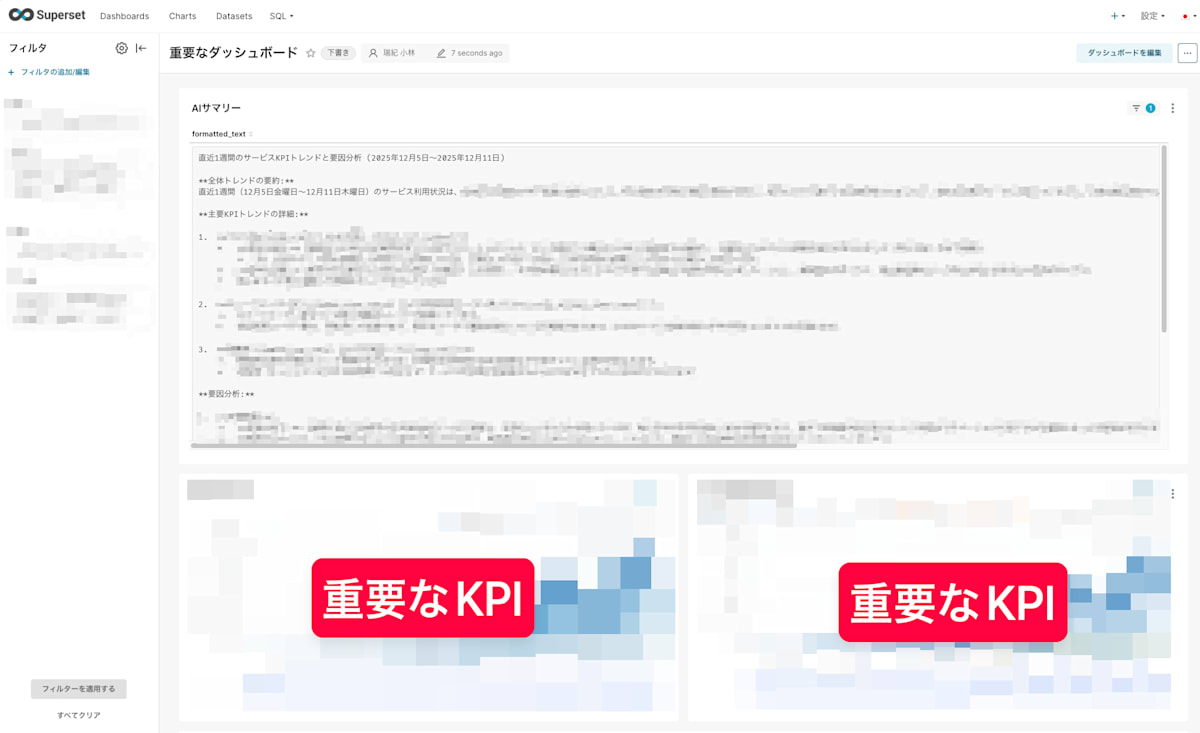
dbtなどで毎日実行させた結果をテーブルとして保存できるので、BIからも簡単に参照できます。
ダッシュボードで表示しているKPIを丸ごとLLMに渡して、それを元にしたインサイトを毎日簡単に表示できます。
3. テーブル・カラムのドキュメント自動生成
実際のデータを見せながら、テーブルの説明やdbt用のカラムドキュメントを生成させます。
WITH target_table AS (
select
TO_JSON_STRING(
ARRAY_AGG(t)
) AS json_data
from
`project.dataset.target_table` AS t
TABLESAMPLE SYSTEM (10 PERCENT)
)
select
AI.GENERATE(
("""
こちらはデータの例です。このデータを元に、dbtの形式で、columnsのyamlを作成してください。
dbtのcolumnsは、例としてはこんな感じです。
重要なカラムであると判断された場合、テストを追加してください。
またデータの範囲が明らかに明確である場合もテストを追加してください。
テストはデフォルトのもの以外に、dbt-utilsも利用可能です。
columns:
- name: カラム名
description: カラムの説明
data_type: データ型
data_tests:
- テスト
""", json_data),
connection_id => 'project.region.vertex_ai_connection_id',
endpoint => 'gemini-2.0-flash-exp',
output_schema => 'yaml string'
).yaml
from target_table;
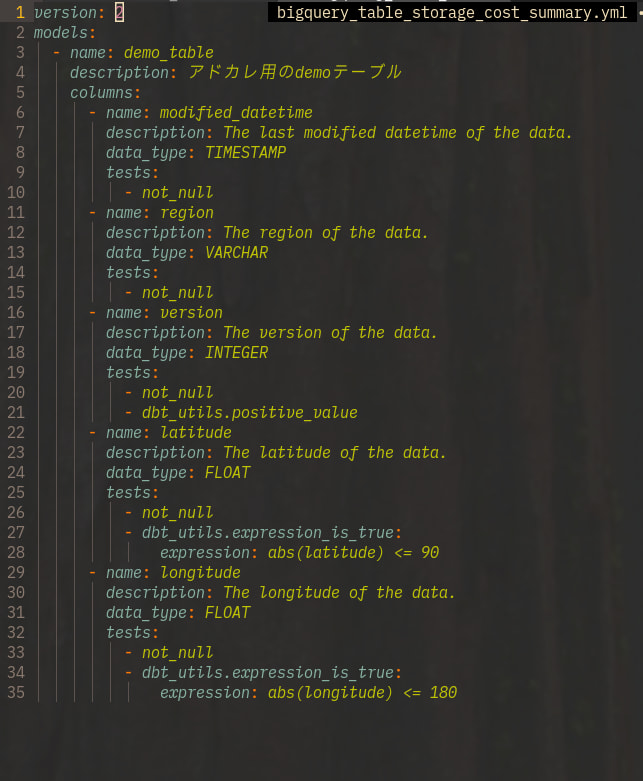
このように、テーブルの説明やカラムの説明だけでなく、テストの設定も自動的に生成できます。
実装時のTips
実際に運用する上で、いくつか注意点があります。
コスト管理
LLMの呼び出しは従量課金なので、開発時は必ず LIMIT や TABLESAMPLE を使って少量のデータで検証しましょう。
-- 開発時は必ずLIMITをつける
WITH source_data AS (
select ... from your_table LIMIT 10 -- 最初は少量で検証
)
select
AI.GENERATE(prompt, ...)
from source_data;
プロンプトの工夫
品質を安定させるために、用語の定義や例を教えてあげることが効果的です。
社内に用語集などがあれば、それをdbtのephemeralモデルやmacroなどで定義して、それを追記させることで、品質の安定が見込めます。
with glossary_model as (
select
glossary_prompt
from {{ ref('glossary') }}
),
daily_report as (
select
to_json_string(
array_agg(t)
) as kpi
from `project.dataset.daily_report` as t
where
report_date >= current_date() - 30
),
select
AI.GENERATE(
(
"直近30日のサービスの各種KPIデータをもとに、",
"ここ1週間のトレンドとその要因を要約してください。",
"用語集を考慮して、適切な表現、定義で説明してください。",
"用語集:", glossary_prompt,"\n",
"サービスのデータ:", kpi,
),
connection_id => "project.region.vertex_connection_id",
endpoint => "gemini-2.5-flash"
).result
from daily_report, glossary_model;
また、output_schema で構造化された出力を指定することで、形式が定まるので後続処理がしやすくなります。
ただ、output_schema を指定すると、日本語での返答や品質の安定性に影響を与える可能性があります。
select
AI.GENERATE(
prompt,
connection_id => 'project.region.vertex_ai',
endpoint => 'gemini-2.0-flash-exp',
output_schema => 'segment_name string, segment_description string'
)
from ...;
まとめ
BigQueryの AI.GENERATE 関数を使うことで、以下のようなユースケースがSQLだけで実現できるようになりました。
- KPIの自動サマリー生成
- データカタログの自動生成
- お問い合わせの自動分類
これらは全て、dbtなど既存のパイプラインに簡単に組み込めるため、新しいインフラを構築する必要がなく、テーブルを作成する知識さえあれば簡単に実装できます。
そのため、データエンジニアなどの専門家が少ない弊チームでも、より効率的にデータ活用を進められるようになりました。
LuupのData Science&Engineering Teamでは、こうした新しい技術を活用しながら、データ活用の効率と品質を高める取り組みを続けています。興味がある方はぜひお話ししましょう!
データ の求人一覧 - 株式会社Luup

Discussion