これは Luup Advent Calendar 2023 の 10 日目の記事です。
こんにちは。Data Engineeringチームの河野(@matako1124) です!
去年の今頃にデータカタログにNotionを選択した理由という記事を書いたのですが、それを今年さらに進化させたよというお話をしたいと思います。
結論から言うと、Notionでの管理からdbt docsに切り替えを行い、Cloud RunでHostingするようにしました。
注意
- 執筆に当たり細心の注意を払っておりますが、不十分な説明や誤りがある可能性もございます。
- 記事内で紹介しているコードは部分的なものであり、参考程度にご参照ください。
目次
- そもそもデータカタログとは
- 今までの課題
- どう解決するか
- まとめ
- 終わりに
そもそもデータカタログとは
データカタログとは何かについて、改めて説明します。
データカタログとは一言でいうと、データについての5W1Hが記されているドキュメントとして捉えるとわかりやすいと思います。
- When(いつ更新されるのか)
- Where(どこに保存されているのか)
- Who(誰が作ったのか)
- What(何のデータが入っているのか)
- Why(なぜ作られたのか)
- How(どのような目的で使われるのか)
Luupでは、BIツールにRedash、DataWarehouseにBigQueryを採用しており、クエリを自分で書いて分析する非エンジニアが多く在籍しております。
そのためデータカタログというドキュメントは、データ活用において非常に重要なツールの一つとして位置付けられています。
今までの課題
前回の記事でご紹介しているとおり、現状データカタログはNotionにまとまっており、Airflowの中でjsonファイルごとにPage化され、自動生成されるようになっています。


約1年間運用していて、以下のような課題が上がってきました。
- データカタログ用のjsonファイルを毎回手動で作るのは意外と面倒
- データカタログが作成されていない場合CIで落ちるようになっているが、CIが落ちて、カタログファイルを作って、またCIを回すという行為自体が意外とストレス
- Notionのページを毎回作り替えるので、NotionPageのURLが毎日変わる(リンクを共有したら次の日には違うリンクになるので使えなくなる)
上記のような課題を解決するために、データカタログが完全自動で生成され、常に最新の情報が担保される仕組みにするにはどうすればいいのか検討しました。
どう解決するか
上記のような課題が上がってきたタイミングで、dbtをパイプラインに導入するフェーズに入っていました。
dbtにはdbt docsというドキュメント機能がついており、CLIで簡単にデータカタログを生成できるので、それを常に最新の状態で全社に展開できれば、現状のNotionデータカタログの代替になると考えました。
それでは具体的にどういうArchitectureで実装したのかについてお話しします。
今回主に求めていた要件は以下二つです。
- Airflowで動かしているdbt coreに追加や修正が加えられた場合、自動でデータカタログも更新する
- Luup社員 or 業務委託 のみが閲覧できるようにアクセスを制御する
これを運用工数少なく実現させるために以下のようなArchitectureで実装しました。
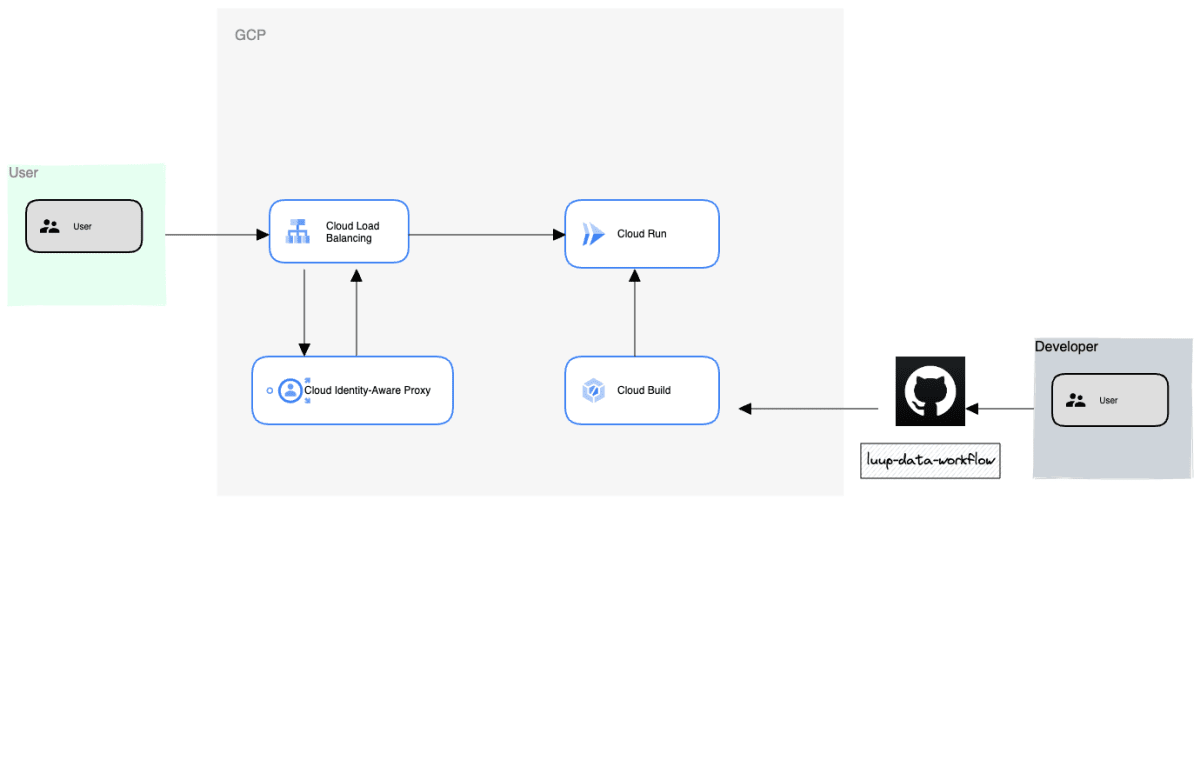
- Cloud Runでdbt docsをHostingする形にしています
- CDには当初よりCloudBuildを使用しているので、CloudBuild上でCDにdbt docs generateを仕込んでいます
- Cloud Load Balancing と Cloud IAPを挟み、社員メーリスのGoogleGroupをIAPに設定することでLuupメンバーのみアクセスできるようにしています
以下Cloud Buildのyaml実装例になります。
# trigger: mainブランチへのmerge
steps:
- id: "Build image"
name: "gcr.io/cloud-builders/docker"
entrypoint: "bash"
args:
- "-c"
- |-
docker build \
-t {image_name} \
-f {docker_file_name} .
- id: "Get credential"
name: "gcr.io/cloud-builders/gcloud"
entrypoint: "bash"
args:
- "-c"
- |
gcloud secrets versions access --secret={secret_name} latest > /credential/dest
volumes:
- name: "credential"
path: "/credential"
- id: "Generate dbt docs"
name: "gcr.io/cloud-builders/docker"
entrypoint: "bash"
volumes:
- name: "credential"
path: "/credential"
args:
- "-c"
- |-
docker run --mount type=volume,src=credential,dst=/credential \
--env GOOGLE_APPLICATION_CREDENTIALS=/credential/dest \
{image_name} \
dbt docs generate --target=$_DBT_TARGET
- id: "Commit & Push image"
name: "gcr.io/cloud-builders/docker"
entrypoint: "bash"
args:
- "-c"
- |-
docker commit $(docker ps -a | grep us-central1-docker.pkg.dev | awk '{print $1}') {image_name}
docker push {image_name}
- id: "Deploy dbt-docs to cloud run"
name: "gcr.io/cloud-builders/gcloud"
entrypoint: "bash"
args:
- "-c"
- |-
gcloud run deploy dbt-data-catalog \
--project=$PROJECT_ID \
--region=us-central1 \
--image={image_name} \
--command=bash \
--args="-c, dbt docs serve --target=$_DBT_TARGET --port 443" \
--port=443 \
--allow-unauthenticated \
--ingress=internal-and-cloud-load-balancing \
--service-account={service_account} \
--update-secrets=/credential/dest=dest:latest \
--update-env-vars GOOGLE_APPLICATION_CREDENTIALS="/credential/dest"
あとはLoad BalancingとIAPでアクセス制御の設定を行います。ドメインはAWSのroute53で設定しています。(細かい設定方法は省略します)


これで設定完了です。
設定したドメインにアクセスします。

無事アクセスに成功しました!
まとめ
データカタログをNotionからdbt docsに切り替え、Cloud RunでHostingするようにしたことで以下の課題が解決されました。
- データカタログ作成工数の削減
- jsonファイルの作成1~2分 → 0分
- 開発のみに集中できるようになった
- データカタログが生成されているかのCIが不要になった
- CIの時間が約3~5分の削減された
- 情報がリッチになった
- テーブル生成のsqlが見れるようになった
- テーブルの依存関係が見れるようになった
実際の削減工数時間は少ないですが、そもそもデータカタログを作る必要がなくなり、脳のキャパシティが空いたことは大きな成果だと思っています。
重要なタスク、チャレンジングなタスクにより多くの時間を投資していけるようにするには、こういうちょっとした仕組み化が重要だったりします。
終わりに
Luupのデータエンジニアリングチームはまだまだメンバーが足りず、最小工数で最大のパフォーマンスを出すため、今回ご紹介したような仕組み化を積極的に採用しています。
Luupでのデータ基盤構築、データ活用に少しでもご興味がある方、ぜひ情報交換という形でもお話しできたら嬉しいです。

Discussion