この記事は、Luup Advent Calendar の 2日目の記事です。
こんにちは、Data Scienceチームの長谷川(@chase0213)です。今回は、同チームインターン生の伊東さん(@RikuIto)と行ったユーザーコメントの分類についてお話します。
普段、Data Scienceチームでは、時系列データや地理空間情報に関する分析や研究開発を主として行っていますが、今回は少し主軸から外れたテーマでお話しします。
はじめに
Luup では、ユーザーの皆様に快適にサービスをご利用いただけるように日々様々な改善に取り組んでいます。改善するためには車両やユーザー体験にどのようなことが起こっているか理解する必要があるため、ご利用いただいた直後に運営にフィードバックできる機能を用意しています。

こちらでいただいたコメントは各部署で目を通しておりますが、ありがたいことにサービスの拡大に伴い、各コメントがどの部署に関連するコメントなのかを把握するだけでも非常に大きなコストがかかってしまっていました。
そこで、自然言語処理技術を用いてコメントを自動で分類し、関連する部署を即座に判別することで、ユーザーやプロダクトに向かう時間を確保しようとしています。
古典的な自然言語処理での試行
コメント分類ということで、まず初めに試したのが、形態素解析と Random Forest によるコメント分類です。形態素解析には、MeCab + IPA辞書を用いており、Random Forest は grid search を使用してハイパーパラメータチューニングを行っています。
仮説として、LUUP のコメントに用いられる語句は特徴的なものが多いので、形態素に分割するだけでそれなりの精度が出るのでは?と考えていましたが、結論として、この方法はあまり精度が出ませんでした。
精度が出なかった要因としては、以下の仮説を挙げています。
- コメントが短文であること
- 言い換えの問題(機体、キックボード、自転車など)
- 否定語(〜しなかった)が含まれること
- 口語体が多いこと
特に短文であることと言い換えの問題は、特徴空間において疎になってしまいやすく、学習に大量のデータが必要になると考えられます。これに対しては、類似語(synonym)の辞書を用意するなどして対処できますが、この問題にかけられる時間的リソースや、より高度な技術が発明されていることからあまり深くは突き詰めませんでした。
Transformerでの試行
形態素解析と Random Forest による試行の後、Transformer での試行に移りました。
Transformer は “Attention Is All You Need” というセンセーショナルなタイトルで Google Brain の研究者らによって 2017年に提案された深層ニューラルネットワークモデルです。それまでは RNN や LSTM をベースにしたモデルが一般的でしたが、Transformer は Attention(注意機構)と呼ばれる構造を導入し、躍進的な精度向上を果たしました。
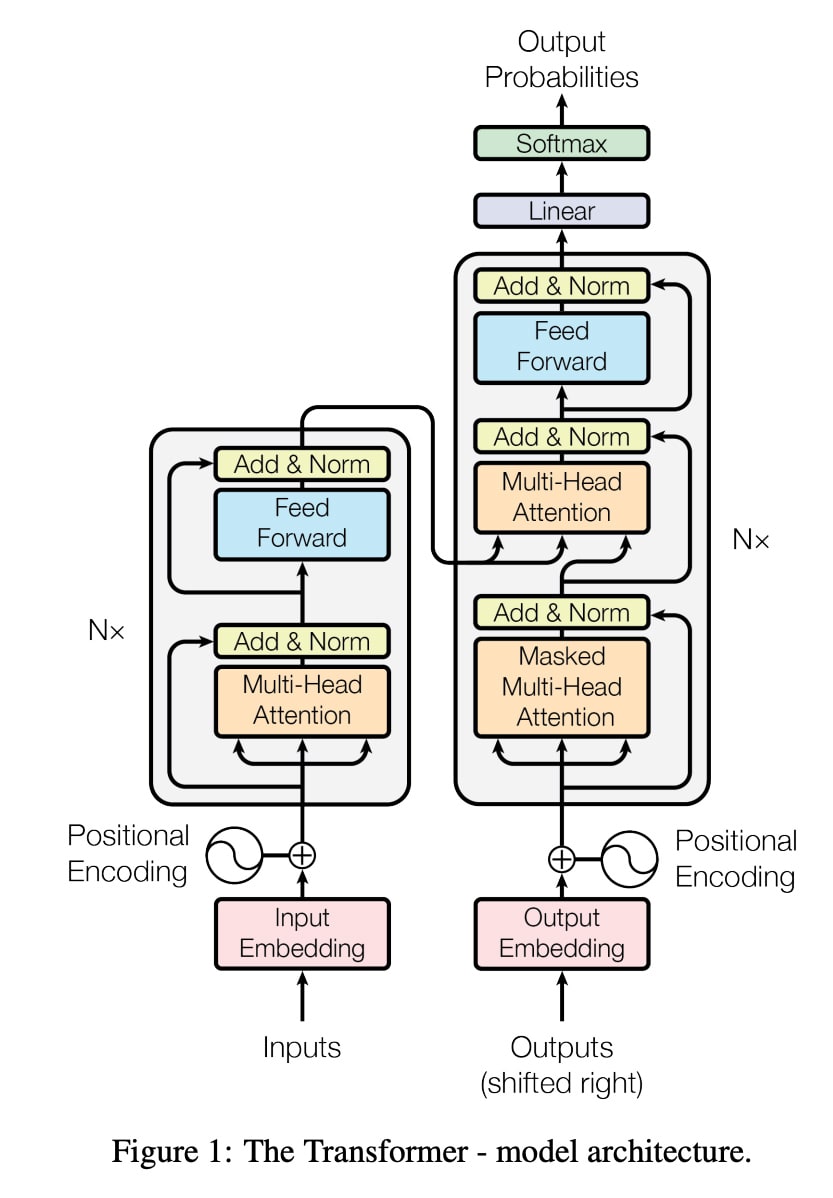
出典:"Attention Is All You Need", Ashish Vaswani, et al., arXiv, https://arxiv.org/pdf/1706.03762.pdf, 2017
その Transformer を内部構造に持ち、モデルの学習アルゴリズム、そして大量のテキスト情報によって学習されたパラメータを含めて開発された自然言語処理モデルが BERT(Bidirectional Encoder Representations from Transformers) と呼ばれるものです。BERT は提案元の Google によってソースコードと学習済みモデルが GitHub上で公開されています。
当初は Tensor Flow でのみ動作するモデルでしたが、その後 PyTorch など他のライブラリやフレームワークでも扱えるものも現れています。特に、学習済みモデルとその学習コードを公開できるコミュニティサービスである Hugging Face(運営主体も同名の企業) は大規模言語モデル(LLM: Large Language Model)の発展に大きく寄与したと言えます。
ALBERT や RoBERTa といった BERT の派生モデルも多く研究開発されており、昨今話題の ChatGPT が使用している GPT(Generative Pre-trained Transformer)というモデルも Transformer がベースとなっています。
RoBERTa を用いたコメント分類
ここでようやく本題ですが、今回は META社(旧Facebook社)が発表した RoBERTa を rinna社が日本語データで事前学習(pretrain)したモデルを使用します。
この学習済みモデルとソースコードは MITライセンスで hugging face にて公開されています。
https://huggingface.co/rinna/japanese-roberta-base
事前学習されたモデルを扱うにあたり、hugging face が提供しているtransformers というライブラリを使用します。
このモデルは wikiペディア等のデータを用いて事前学習されているため、このままでも一定の精度は出ますが、基本的に大規模言語モデルを使用する際には fine tuning という工程を経て、ネットワークの一部のパラメータ(多くは出力層から数層)だけを再学習して使用します。
実際のコードから主要な処理部分を掲載します。
学習データは df_train 、ラベル付けしたいデータは df_test に格納されています。
まずは学習データに付与されているラベルを ID に変換します。ここでは単にリストの先頭から順に番号を振っているだけです。
# 学習データからラベルを取り出す
unique_labels = df_train.label.unique()
# id からラベルへの相互変換辞書を用意する
id2label = dict([(id, label) for id, label in enumerate(unique_labels)])
label2id = dict([(label, id) for id, label in enumerate(unique_labels)])
# 学習データのラベルを id で置き換える
df_train.label = df_train.label.map(label2id.get)
性能評価のために、学習データを学習用と評価用とに分割します。
# ラベル付きデータを学習用のデータと評価用のデータに分ける
from sklearn.model_selection import train_test_split
# 学習データを 8:2 の割合で学習に使用するデータと評価用データに分ける
df_train, df_eval = train_test_split(df_train, test_size=0.2)
print(f"# of train = {df_train.shape[0]}, # of eval = {df_eval.shape[0]}")
その後、pandas.DataFrame型から datasets.Dataset型に変換します。datasets は hugging face から提供されているライブラリです。
# dataframe から dataset型に変換
from datasets import Dataset
train_dataset = Dataset.from_pandas(df_train)
eval_dataset = Dataset.from_pandas(df_eval)
test_dataset = Dataset.from_pandas(df_test)
日本語の文章をモデルへ入力するために、文章を小さな単位に分割(tokenize)して数値に変換する必要があります。モデルの学習時に用いられた tokenizer と同じ tokenizer を使用します。
# roberta の日本語モデルを使って tokenizer を定義する
from transformers import AutoTokenizer, AutoModelForMaskedLM
# 日本語用の tokenizer
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-roberta-base", use_fast=False)
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
def preprocess_function(examples):
# データセットに含まれる text を取り出して tokenizeする
return tokenizer(examples["text"])
# 学習用、評価用、検証用の 3つのデータセットを用意
tokenized_train_dataset = train_dataset.map(preprocess_function, batched=True)
tokenized_eval_dataset = eval_dataset.map(preprocess_function, batched=True)
tokenized_test_dataset = test_dataset.map(preprocess_function, batched=True)
次に、RoBERTa のモデル本体をダウンロードします。今回は、あらかじめ決められたラベルに分類する多クラス分類という問題を解くため、クラス分類用の設定を指定します。
num_labels に推論したいラベルの数を入れるのがポイントです。
# classifier用に num_labels(出力層)を指定してダウンロード
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
"rinna/japanese-roberta-base",
num_labels=len(id2label),
id2label=id2label,
label2id=label2id,
)
モデルを学習します。
ここでは割愛していますが、各パラメータは試行錯誤の末に決定しています。学習データの規模や種類によって異なるので、学習曲線などを見ながら適宜変更が必要です。
# 学習
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="roberta-classification",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=20,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=False,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
学習には GPU を使いましたが、常に GPU を使用しているとクレジットがなくなってしまうので、CPU に結果を移して整形します。同じ様に hugging face が公開している transformers.pipeline というモジュールを使用します。この pipeline を設定して自然言語で書かれたテキストを渡すだけでモデルの出力を返してくれます。
# 出力結果をいい感じに整形する
from transformers import pipeline
# GPU ではなく CPU を使う
model.to('cpu')
# パイプラインの設定
classifier = pipeline("text-classification", tokenizer=tokenizer, model=model)
# ここで実際の推論を実行
result = df_test.text.apply(classifier)
# 結果を表示するために色々変換
labels = [r[0]['label'] for r in result]
scores = [r[0]['score'] for r in result]
df_result = pd.DataFrame({
'label': labels,
'score': scores,
})
df_result
実行結果
モデルの学習は Google Colab上で GPU を使用して行います。CPU でもできなくはないですが、深層ニューラルネットワーク系の学習はテンソル演算が主体のため、GPU を用いた方が圧倒的に高速です。
速度が求められる場面では推論も GPU を用いて行うのが望ましいですが、今回は学習済みモデルを元に定期的に推論するだけなので、CPU で行います。推論部分は、依存パッケージや環境構築の観点から、Docker を用いて実行環境をコンテナ化しています。
GCP で Dockerコンテナを定期実行する方法はいくつか提供されていますが、今回は Cloud Run を使用して、Cloud Composer(airflow)側から定期的にジョブをキックする形で実行します。
実行結果としては、この記事の冒頭で分割した評価用データにおいて精度(precision)が 70%程度出ています。また、実際の出力を関連部署とも実際に目視で確認したところ、実用に耐えるという判断をしています。
実際のユーザーのコメントが入ってしまうためこちらに記載はできませんが、なかなか人間でも判別が難しいものでも分類に成功しています。
逆にうまくいっていないものの多くも、人間でも無理だよねという類のものが多く、それらを取り除いた精度はさらに高いと予想されます。
ただし、どんなに高性能なモデルを使用しても、機械学習である限り一定数の取りこぼしは存在してしまいます。ビジネスに機械学習を適用する上では、そのリスクに応じたバックアッププランを用意しておくことが最も重要だと私は思っています。
おわりに
今回は、RoBERTa という BERT の派生モデルを用いたユーザーのコメント分類についてお話しました。普段は地理空間情報や時系列情報を主として扱っているため、Luup のデータサイエンスの中では少し異色な分野ですが、事業のために必要であれば特定の技術の枠にとらわれることなく取り組んでいます。
Luup でのデータ基盤構築や、データ活用、データドリブンな戦略策定に少しでもご興味がある方は、まずは情報交換という形でも良いのでお話ししてみませんか?
この記事を読んでいただいているあなたとお話できる日を心待ちにしてます。
https://recruit.luup.sc/
参考文献
- Attention Is All You Need
- google-research/bert
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- rinna/japanese-roberta-base
- 日本語RoBERTaをGoogle Colabで試す

Discussion