こんにちは。Luup Developers Blog編集部の堀内 (@shinya_h) です。
この記事では弊社SREチームの役割や達成したいこと (ゴール) を紹介します。本記事を通じて弊社のSREチームの様子を少しでもお伝えできると嬉しいです。
なお、SREとはサイト・リライアビリティ・エンジニアリング (Site Reliability Engineering) の略称です。Google社が提唱、実践しているシステム管理とサービス運用の方法論です。
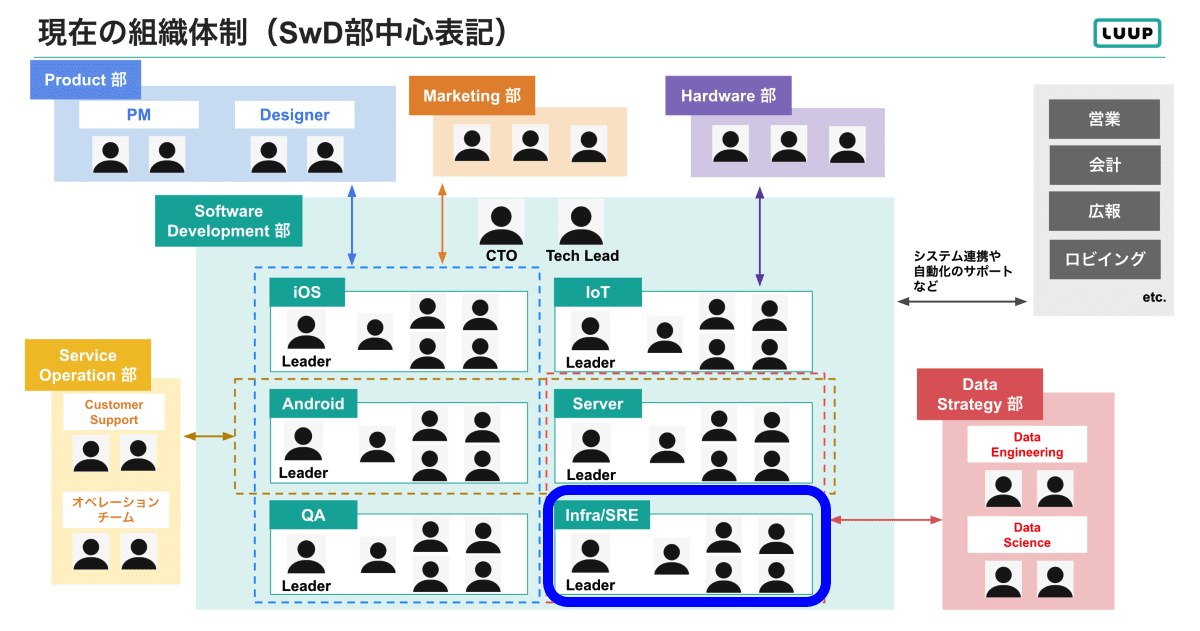
※SwDはSoftware Developmentの略です。
SRE担当範囲
SREの役割は組織や扱うプロダクトなどにより異なりますが、弊社の場合、役割や担当範囲は主に下記と考えています。
- サービスの可用性や信頼性の向上・担保
- 開発や運用の効率性を担保するための自動化
- 変更管理
- モニタリング
- 緊急対応とオンコール体制の構築
- キャパシティプランニング
SREチームの役割
Luupが提供する電動・小型・一人乗りのマイクロモビリティ(以下、車両) シェアリングサービスを提供するためのインフラ品質や信頼性を高めることを主に行っています。
信頼性を高め、Luupプロダクトの進化を Growth Phase や Hyper Growth Phase にするために高度なソフトウェア技術を用いてシステム運用管理全般を担当しています。
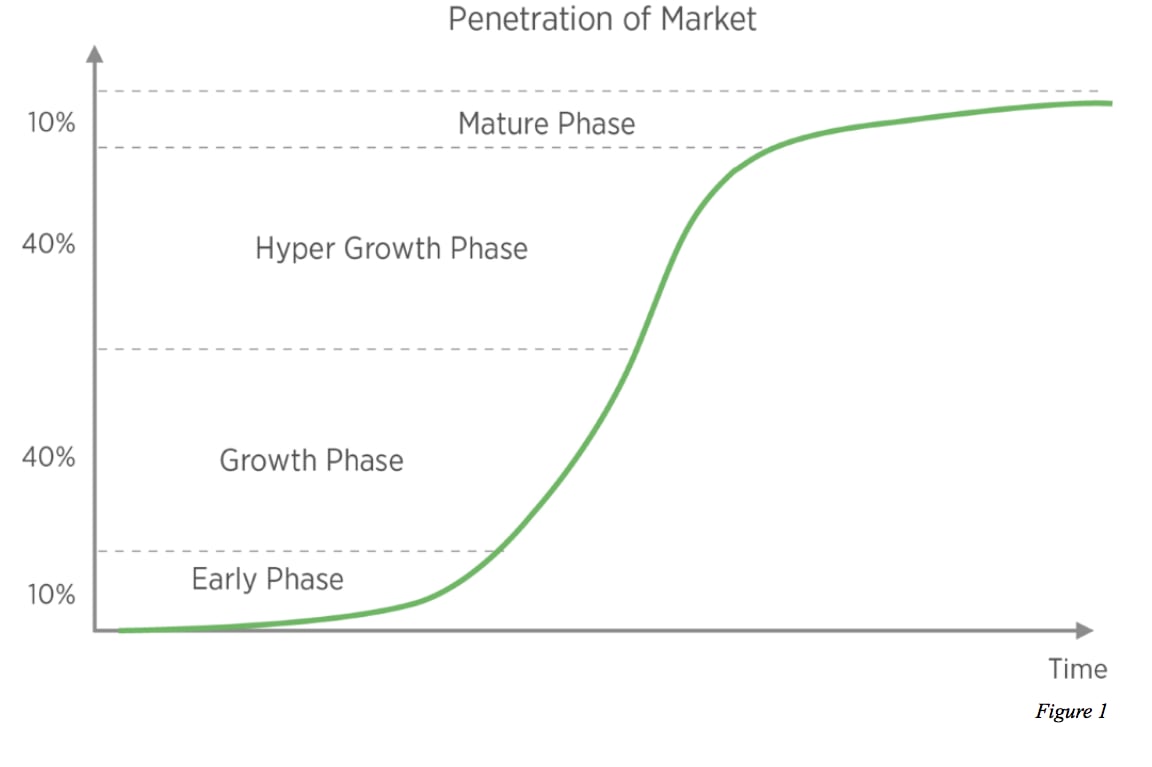
SREチームが達成したいこと
車両をご利用いただいているお客様の乗車回数を ライド数 と社内で呼んでいます。ある時点の総ライド数から10倍スケールさせることができるようにネットワークやインフラの準備を行うため、Project 10x (テン エックス) と名付け、計画的にSREチーム活動を行っています。
Project 10xの ゴール を下記のように定めました。
- 10倍以上のリクエストに耐えられるインフラを用意
- 監視を強化
- SREを専門に実践する仲間を増やす
- 開発組織全体へのSRE導入、実践
また、各フェーズで行うことをそれぞれ明示しました。
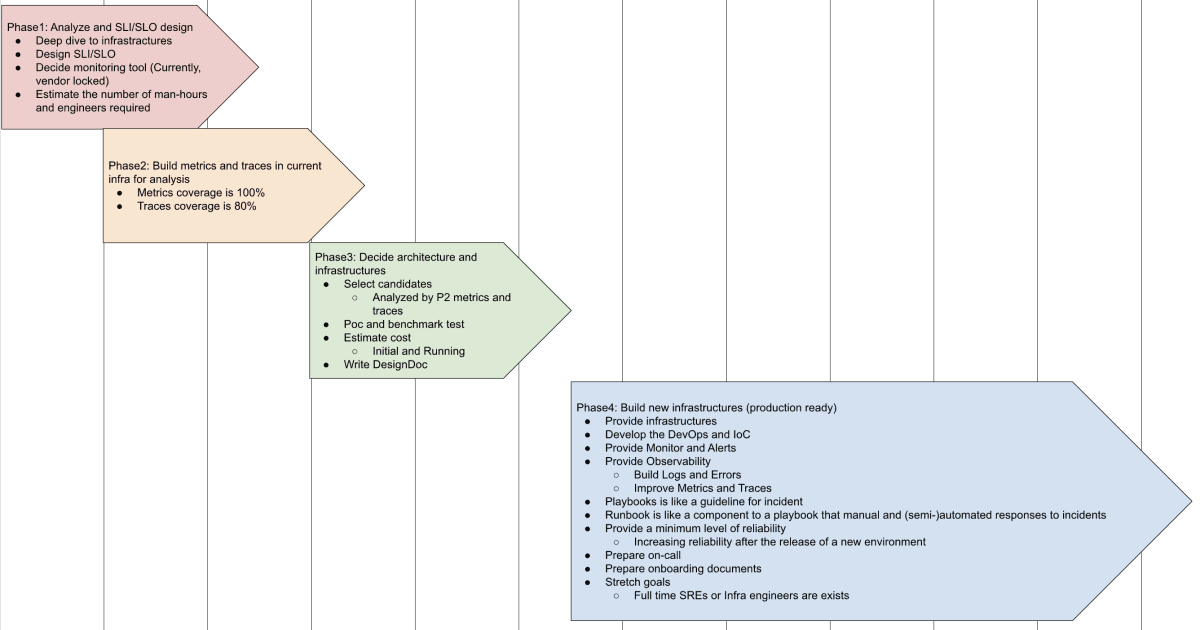
フェーズ1
- スケーラビリティの確保のための準備として分析や見積、設計
- 監視の土台づくり
フェーズ2
- 検知、分析が出来るようにフェーズ1で設計した内容で メトリクス と トレース を仕込む
フェーズ3
- よりスケーラブルなアーキテクチャーを設計、選定
フェーズ4
- スケーラビリティを高めた環境で本番稼働
現在行っている取り組み
-
SLI/SLOの導入
- サービスがお客様の期待に沿うようにサービス信頼性の維持や向上のための指標や合理的な目標を立て、改善ポイントの検知、認知およびコミュニケーションツールとして利用
-
プレイブック作成
- インシデント発生時の運用手順書。オンコール対応時や通常運用時に利用
-
オンコール体制強化
- オンコール指針やチーム内での取り決めを明確にして、インシデント発生時に迅速に対応できるようにすることが重要と捉え整備
※ SLI (Service Level Indicators) はサービスレベルの指標で、SLO (Service Level Objectives) はSLIを元に立てるサービスレベルの目標です。詳しくは下記をご覧ください。
SREチームの魅力
弊社には車両開発を行うHardware部があります。またユーザーの膨大な移動データや利用状況、車両に取り付けたIoT装置から得た車両状態などを含めたビッグデータを扱うData Strategy部も存在します。
SREの関心領域はSoftware Development部の内部に留まらず、Hardwareを含めたサービス開発とDWH基盤、インフラ開発等、多岐にわたります。
車両やIoTを扱っているからこそのSREの難しさがあり、そこにチャレンジできるところが弊社でのSRE仕事の面白さです。
詳しい内容についてはこちらで触れています。ご覧頂けると理解が深まると思います。
ありがたいことにお客様の車両ライド数が右肩上がりになっている状況であり、車両もより一層安全性を考えたものへと日々進化し続けている状況です。
このようなサービスの可用性や信頼性の向上・担保を行うためにSREチームでは日々和気あいあいと楽しく課題に向き合って仕事をしています。
弊社では現在SREの採用やカジュアル面談を積極的に行っていますので、ご興味がございましたらお気軽にお問い合わせください。

Discussion