こんにちは!
2022年2月からLuupにデータエンジニアとしてジョインした河野(@matako1124) です!
元々マイクロモビリティに興味があり、データ基盤もこれからきっちり作っていきたいという0からのフェーズで、お声がけをいただけたことに感謝です。
現在、Luupのデータチームの構成は、Data Strategy部の中にData EngineeringチームとData Scienceチームの2つがある形となっています。

Data Engineeringチームとしては前回の記事執筆者@t-kurimuraと私の二人で取り組んでいます!
ということで、まだ入社数ヶ月の私ですが、Luupでのデータ基盤としてGoogle Cloud Composerを導入し、どのように冪等性を担保した設計にしようとしているかご紹介していきたいと思います。
注意
- 記事執筆から半年ほど経過しており、現在の最新情報と異なる点がある可能性がございます。
- 執筆に当たり細心の注意を払っておりますが、内容に誤りや説明が不十分な箇所がある可能性がございます。
目次
- ワークフロー(Google Cloud Composer)の導入目的
- phase1:ワークフロー環境を整えて、とりあえず動くものを作る
- phase2:dbtを導入し、Validate追加によるデータ整合性向上、ドキュメント化、Lineageを整備。ここまでで「とりあえずデータ基盤」の完成を目指す
- phase2.5:外部ツール取り込みをワークフロー管理下に置き、データ処理の流れの一貫性を作る
- Phase3:データ基盤構造の再設計。SQL処理では対応できない複雑なものや処理が重いものも対応できるデータ基盤を作る
- Google Cloud Composer(Airflow)実装:冪等性を担保しつつ、クエリ容量を抑えるような設計にする
- まとめ
- 終わりに
ワークフロー(Google Cloud Composer)の導入目的
Google Cloud Composerを導入する目的は非常にシンプルで、「BigQueryの処理がスケジューリングクエリで管理できなくなってきたから」 です。
現状のデータ処理フローは、以下の図のようになってます。

どういうことか具体的に説明していきます。
現状は、まだデータ基盤と言える状態のものではなく、FirestoreのデータのCDCがCloudFunctionsを経由してBigQueryにデータが送られます。
その後、分析メンバーはBigQueryの中でSQLを書き、データセット「DWH」もしくはデータセット「Datamart」の中に分析用のテーブルを各々作成し、redash等のBIツールで可視化するという流れで処理が動いている状態です。
分析する際にデータにアクセスしやすくするため、最新のライド情報やユーザー情報などを整理したテーブルなどは、定期的にデータを更新したいので、BigQueryのスケジューリングクエリで設定し、テーブルを作成していました。
ここで挙げられる課題として、
- データ量が多すぎてスケジューリングクエリで設定したものがどれくらいで処理が終わるか考慮できない=依存関係が設定できない
- BigQueryのデータと取り込み元のFirestoreのスキーマが変更されてもエラーに気づかない。
- スケジューリングクエリが多すぎて、管理できない。
- どのテーブルがどこと繋がっているのか可視化されておらず、依存関係がわからないため、無数のスケジューリングクエリを確認しなければならず、修正するときの工数がバカにならない。
- 外部ツールの連携からDataMart作成まで一貫して管理できないことにより、データの整合性担保ができない。
- SQLを書ける人がそれぞれの書き方でデータを取り出しているため、どれが本当に正しいデータなのかわからない。
等まだまだありますが、これではデータの信頼性が担保されておらず、正確な分析がしづらい状態になっています。
これを解決するために導入したのが「Google Cloud Composer」であり、依存関係の処理はもちろんのこと、処理のルール統一化、外部ツールとの連携、SQLの処理、テスト、エラー通知まで一貫して管理できるデータ基盤を作ることで、信頼性の高いデータを渡せるようにしていきます。
ただ、一気に厳密なデータ基盤を作りますというのは無理なので、phaseごとに分けて作成していきます。
phase1:ワークフロー環境を整えて、とりあえず動くものを作る

- スケジューリングクエリでの実行を順にワークフロー環境下での実行に移行していく
- Slackエラー通知の実装
- CI/CDの整備
今回はDAGの設計と実装方法に言及するので、Slackエラー通知の実装方法やCI/CDの整備方法については言及しません。
ちなみに、CI/CDは連携しやすさを重視し、Cloud Buildを採用し、Artifact RegistryにImageを置くような実装方法を取りました。
こちらについてはまた別の機会に取り上げたいと思います。
phase2:dbtを導入し、Validate追加によるデータ整合性向上、ドキュメント化、Lineageを整備。ここまでで「とりあえずデータ基盤」の完成を目指す

- 既存のSQL処理をdbt運用に変更
- メタデータドキュメント化
- Data Lineage
- データ処理テストの実装(Validate)
phase2.5:外部ツール取り込みをワークフロー管理下に置き、データ処理の流れの一貫性を作る
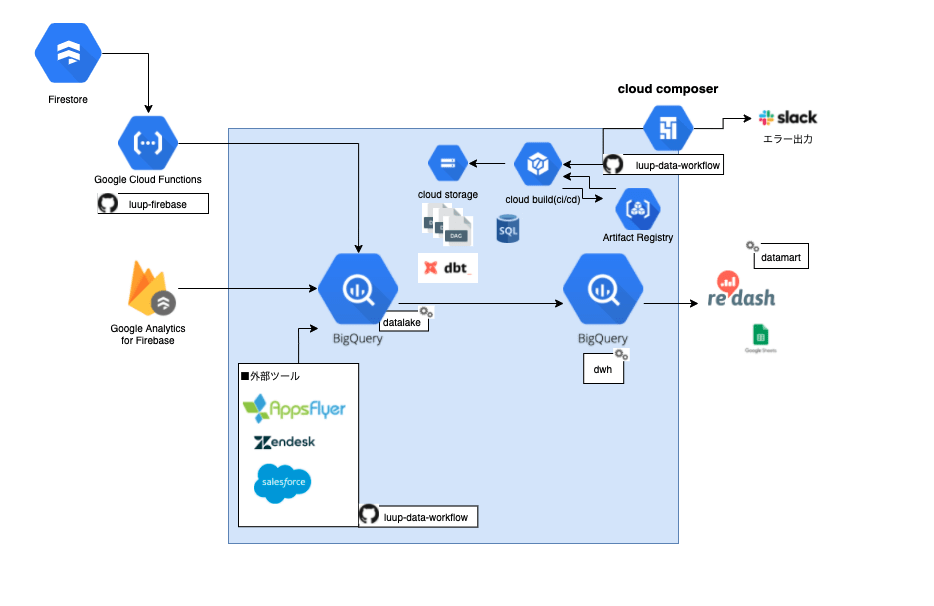
- 外部ツール取り込みをワークフロー管理下に置く
- Appsflyer
- Zendesk
- Salesforce
Phase3:データ基盤構造の再設計。SQL処理では対応できない複雑なものや処理が重いものも対応できるデータ基盤を作る

- データ基盤構造の再設計
- 位置情報データや非構造化データ等の複雑なデータにも対応できるようにする
この流れで進めていこうと考えています。
Google Cloud Composer(Airflow)実装:冪等性を担保しつつ、クエリ容量を抑えるような設計にする
前知識として、Google Cloud Composerとはなにかをさらっとお話します。
Google Cloud Composerとは、OSSであるAirflowというワークフローツールのフルマネージド・サービスであり、Googleがインフラ周りを管理してくれて、ユーザーはDAGの開発に集中できるようなツールです。
Airflowを自前で導入しようとすると、ツールを動かしておくためのサーバーを用意し、どのくらいのスペックでどれくらいの容量を必要とするか等具体的に設計してから動き出す必要がありますが、Google Cloud Composerを利用すればボタンひとつでインフラ周りの環境を構築でき、Google Cloud Composer 2.0からはサーバーのスペックをより詳細に選択できるようになりました。
また、後からスペックの調整もできるので、導入スピードが格段に上がり、最近のデータエンジニアリング界隈では導入する会社が多い印象のツールです。
それでは本題に入っていきたいと思います。
データ処理をする際に結構重要視される「冪等性」についてですが、今回どのように設計したかお話しします。
上記で述べたphase1では、rawデータであるFirestoreのデータを加工して、dwhとなるテーブルを作り、毎日1回実行させてます。
Firestoreの中にはLuupでのライド情報やユーザー情報、機体情報などが入っており、Firestore Extensionという機能を使って、StreamingでBigQueryにデータを送っています。現状ではこのStreamingで送られてきたrawデータを直接SQLから見ているような状況です。
そこで挙げられる課題は、「クエリ容量が大きいものだと一回10TB以上いく」 ことで、それを毎日バッチ処理させるのは結構コストが勿体無い状態でした。
過去何年分かのrawデータを全部なめてテーブルを作るということになるので、今後もデータはどんどん増えていきます。
その際に毎回10TB以上の処理を繰り返すのは現実的ではありません。
またテーブルによっては、1日数億レコードを超えるテーブルもあります。
クエリ容量を減らすには
- 読みとるレコード数を減らす
- 日付でpartitionしてテーブルを内部的に分割する
主にこの二つかなと思います。
partitionテーブルを作るのは設定してあげるだけでいいのですが、レコード数を減らすにはどうすればいいでしょうか。
Firestoreの仕様上、データの追加(CREATE)やデータの更新(UPDATE)、データの削除(DELETE)などデータの操作によってレコード数が増加し、データの格納数ではなくデータの変更回数に比例するので、多くなりやすいです。
なのでここで考えた案は、phase1ではdailyのバッチ処理で済む分析だったため、その日のレコードをdocument_idでgroupingし最新1レコードを取ってきてあげることで、レコード数を削減するという案を採用しました。
document_idの最新レコードを毎日dailyで積み重ねていくことで毎日10TBほどの処理が30MBほどに落ち、大きなクエリ削減となりました。
上記のことを考慮し、以下のようなデータ処理フローにしました。

- データセット「datalake」と「dwh」の2つの層を持つ。
- datalake層は、rawdataから取得したTOP層のデータを用意する。(上で記述した最新レコードのもの)。dailyで上書き追加とする。
- dwh層は、datalakeから取得した分析用のデータを用意する。日付の指定はせず、毎回tableを作り直す。
具体的なソースを見ていきます。
datalake層については、createEmptyTable→InsertJobの二つを順番に実行します。
ポイントは、
- テーブルはpartition化する
- テーブルは上書き追加とし、table名$日付(YYYYMMDD)で繋げてあげる
- schemaUpdateOptionsを設定し、カラム追加をONにする
日付をkeyに毎回上書き追加(データがなければ追加し、あれば上書き)することによって、何回実施しても同じデータになる(冪等性)ようにします。
with TaskGroup(group_id=table_name) as datalake_trans:
create_empty_table = BigQueryCreateEmptyTableOperator(
task_id='create_empty_table',
project_id=project_id,
dataset_id=dataset_id,
table_id=table_name,
gcs_schema_object='gs://{}/dags{}/{}.json'.format(bucket_name, schema_path, table_name),
time_partitioning=
{
'type': 'DAY',
'require_partition_filter': True
}
)
load_daily = BigQueryInsertJobOperator(
task_id='load_daily',
configuration={
'query': {
'query': f"{{% include '{'{}/{}.sql'.format(sql_path, table_name)}' %}}",
'useLegacySql': False,
'writeDisposition': 'WRITE_TRUNCATE',
'schemaUpdateOptions': ['ALLOW_FIELD_ADDITION'],
'destinationTable': {
'projectId': project_id,
'datasetId': dataset_id,
'tableId': '{}${}'.format(table_name, '{{ jst_ts_nodash(ts_nodash) }}')
}
}
}
)
create_empty_table >> load_daily
return datalake_trans
dwh層については、スキーマが修正されることも考慮し、データ処理はdatalake層から全データを取得する設計にしているため、DeleteTable→CreateEmptyTable→InsertJobの順で実行します。
ポイントは、
- スキーマ修正にも対応できる
- partition化する必要がないテーブルにも対応する
- テーブルは空の場合にデータ追加する
dwh層は、特にスキーマ変更やカラムの追加修正が発生するので、簡単に&素早く修正できるようにするためにも、delete→create→loadの順番処理が有効と感じています。
この設計にしておけば、schemaファイルとSQLファイルだけ修正して、backfillするだけで済みます。
with TaskGroup(group_id=table_name) as dwh_trans:
delete_table = BigQueryDeleteTableOperator(
task_id="delete_table",
deletion_dataset_table='{}.{}.{}'.format(project_id, dataset_id, table_name),
ignore_if_missing=True
)
if partition_field != 'None':
time_partitioning = {
'type': 'DAY',
'field': partition_field,
'require_partition_filter': True
}
else:
time_partitioning=None
create_empty_table = BigQueryCreateEmptyTableOperator(
task_id='create_empty_table',
project_id=project_id,
dataset_id=dataset_id,
table_id=table_name,
gcs_schema_object='gs://{}/dags{}/{}.json'.format(bucket_name, schema_path, table_name),
time_partitioning=time_partitioning
)
load_table = BigQueryInsertJobOperator(
task_id='load_table',
configuration={
'query': {
'query': f"{{% include '{'{}/{}.sql'.format(sql_path, table_name)}' %}}",
'useLegacySql': False,
'writeDisposition': 'WRITE_EMPTY',
'destinationTable': {
'projectId': project_id,
'datasetId': dataset_id,
'tableId': table_name
}
}
}
)
delete_table >> create_empty_table >> load_table
return dwh_trans
このように冪等性を担保した設計にすることは、非常に重要なことだと思います。
単純にinsertすればいいという考えでいると、別の人が既にinsertしていて簡単に重複が起こります。
そして分析メンバーに言われるまでデータがおかしいことに気づかないという状態に陥ってしまうでしょう。
データを管理するものとしては、データがおかしいことをいち早く察知する仕組み化は非常に重要なことですよね。
まとめ
Google Cloud Composerでデータ基盤を作る一例として、ぜひ参考にしていただけると幸いです。
データ基盤にはワークフローはほぼ必須だと思います。私はAirflow、DigDag、Luigi、Argoなどいろんなワークフローツールを触ってきましたが、今のところAirflowが一番扱いやすいなと感じています。
情報量も多く、GoogleやAWSでもフルマネージドサービスとしてサービスを提供してくれている唯一のワークフローエンジンです。
これからデータ基盤を構築していきたいと思っている方はぜひ一度触ってみてください。
終わりに
Luupでのデータ基盤の構築はまだまだ走り始めたばかりで、やるべきことは山のようにあります。
マイクロモビリティとしての位置情報データを扱えるという面では、非常に難しいものではあるものの、大量のデータをどう整合性担保して管理していくか、どういう構造にすればデータ活用がより浸透していくか等、面白いことが満載な環境だと私は思っています。
もしLuupでのデータ基盤構築、データ活用に少しでもご興味がある方がいらっしゃればお気軽にご連絡をお待ちしております。

Discussion