重み付きUnionFindに一次関数を乗せてみた
はじめに
Atcoderで競技プログラミングを楽しんでいるluna_moonlightです。この記事では、重み付きUnionFindの上位互換として、一次関数を乗せる方法について解説していきます。
重み付きUnionFindに一次関数を乗せる方法に関して以下の記事があります。 しかし、Pythonで書かれている記事は見当たらなかったので、この記事を書いていきます。
UnionFind
DisjointSetUnion(DSU)とも呼ばれます。UnionFindとは、
| クエリ | 内容 |
|---|---|
unite(x, y) |
頂点 |
is_same(x, y) |
頂点 |
基本的なアイデア
森[1]で管理する
連結か否かが重要なので、下の2つのグラフはUnionFindにおいては同一視できます。もっと言えば、閉路は無駄なので、管理するグラフは森で十分です。言いかえると、unite(x, y)を実行する際にすでに連結な頂点の間に辺を張る必要はありません。

各木を根付き木にする
各木を根付き木にすることで、根が同じか否かで連結性の判定出来ます。
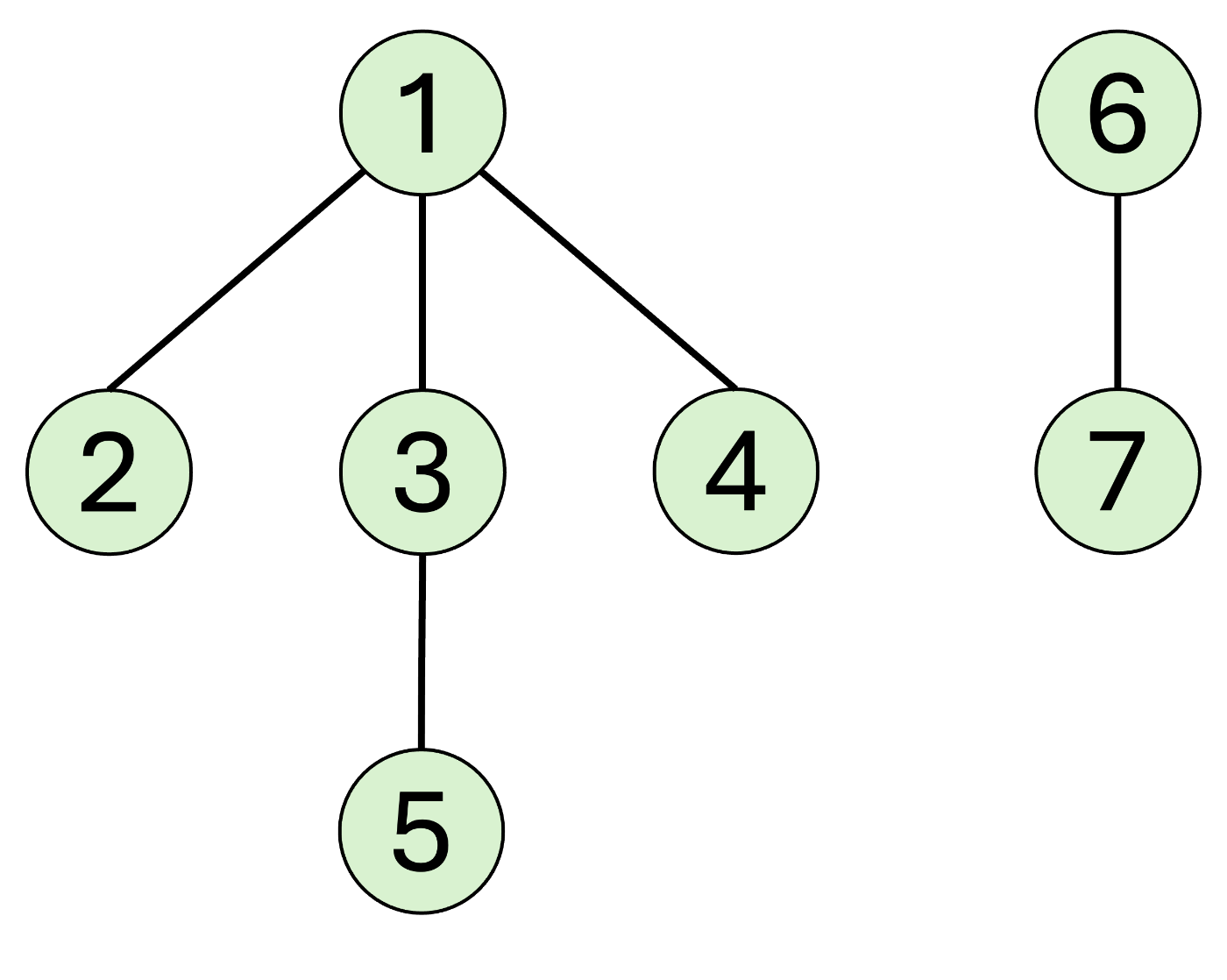
例えば、上のグラフで頂点2の根は頂点1、頂点5の根も頂点1なので連結であると言えます。頂点6の根は頂点6なので、頂点2と頂点6は連結ではないと言えます。
また、unite(x, y)を実行する際は、頂点unite(3, 7)を実行すると下のようなグラフになります。

実装(仮)
ここまでの内容を実装すると以下のようになります。
import sys
sys.setrecursionlimit(10 ** 7)
class UnionFind:
def __init__(self, N):
self.N = N
self.parents = [-1] * N
def root(self, x):
if self.parents[x] == -1:
return x
return self.root(self.parents[x])
def unite(self, x, y):
rx = self.root(x)
ry = self.root(y)
if rx != ry:
self.parents[rx] = ry
def is_same(self, x, y):
return self.root(x) == self.root(y)
計算量削減
下のような最悪なケースでは、木の高さがunite(x, y)とis_same(x, y)ともに最悪計算量が

これを解決するために、UnionFindでは以下の2つの計算量削減が提案されています。これら2つの計算量削減を行うと、計算量が
計算量が
マージテク
直感的に、木の高さが高い方を親にすると、unite(x, y)後の木の高さが高くならなそうです。

その直感は正しいです。unite(x, y)の際に木の高さが高い方を親にすることで、木の高さを
証明の概略
「頂点数
以下では、木
帰納法を使って証明する。
(i)
(ii)
深さuniteして出来上がる。
帰納法の仮定から、
よって、出来上がる木
すなわち、
以上(i),(ii)から、帰納法より、「深さ
経路圧縮
unite(x, y)やis_same(x, y)を実行する際に、毎回頂点

例えば、左のグラフで頂点4から根を探索した場合、頂点3と頂点2を通って根に到達します。そこで、右のグラフのように、頂点2,3,4を頂点1に直接張り替えます。
実装
2つの計算量削減を導入して実装すると以下のようになります。
import sys
sys.setrecursionlimit(10 ** 7)
class UnionFind:
def __init__(self, N):
self.N = N
self.parents = [-1] * N
self.rank = [0] * N
def root(self, x):
if self.parents[x] == -1:
return x
self.parents[x] = self.root(self.parents[x])
return self.parents[x]
def unite(self, x, y):
rx = self.root(x)
ry = self.root(y)
if rx == ry:
return
if self.rank[rx] < self.rank[ry]:
rx, ry = ry, rx
elif self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
self.parents[ry] = rx
def is_same(self, x, y):
return self.root(x) == self.root(y)
重み付きUnionFind
ポテンシャル付きUnionFindとも呼ばれます。重み付きUnionFindとは、長さ
| クエリ | 内容 |
|---|---|
unite(x, y, d) |
|
diff(x, y) |
|
考え方は、普通のUnionFindとほとんど同じです。森で管理して、各辺で端点の差分を管理しています。
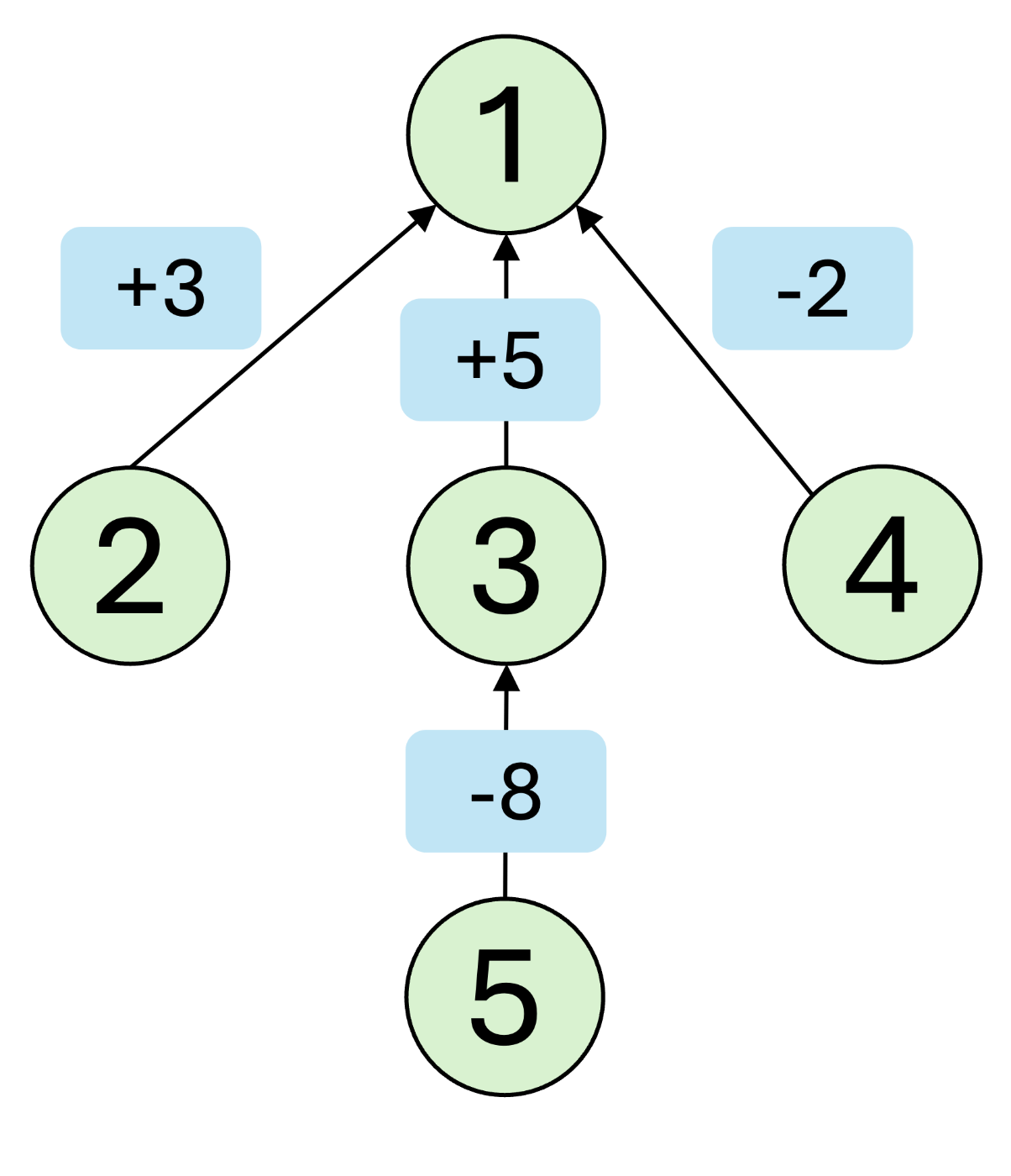
上のグラフでは、
unite(x,y,d)
unite(x,y,d)の処理を下のグラフで考えてみます。

1.rank(x)\geq (y)
例えば、unite(5, 7, -2)というクエリが与えられたとします。普通のUnionFindと同様に頂点5の根を頂点7の根の親にするので、頂点1を頂点6の親とします。そのために、頂点1と頂点6の差分
まず、
次に、
最後に、
よって、
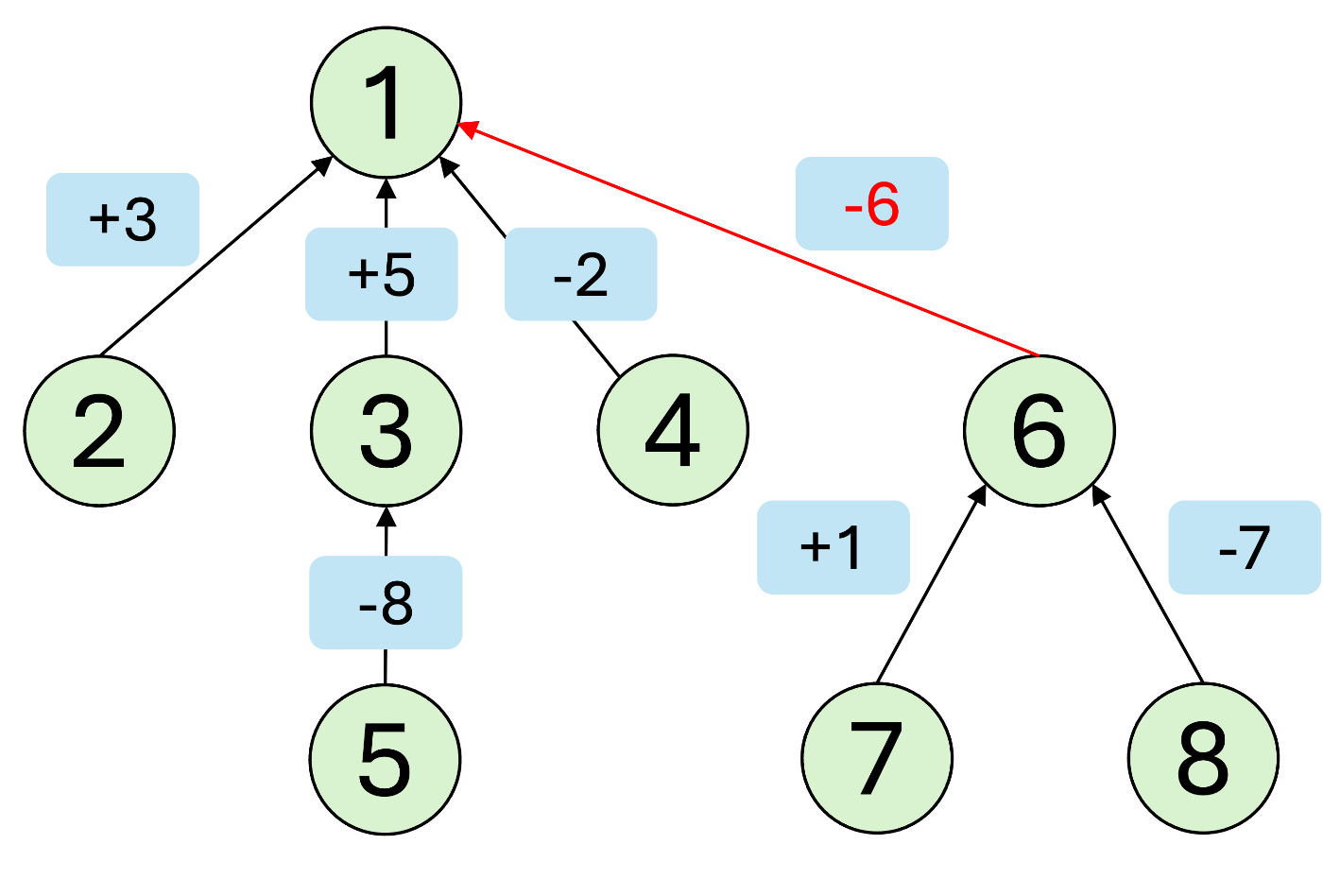
より一般的にunite(x,y,d)について考えます。
頂点
※
すると、
となるので、頂点
2.rank(x)\lt (y)
先ほどと同じグラフで、例えば、unite(8, 4, 2)というクエリが与えられたとします。普通のUnionFindと同様に頂点5の根を頂点7の根の親にするので、頂点1を頂点6の親とします。そのために、頂点1と頂点6の差分
まず、
次に、
最後に、
よって、

より一般的にunite(x,y,d)では、
となるので、頂点
先ほどのrank
diff(x,y)
diff(x,y)の処理を下のグラフで考えてみます。

例えば、diff(3, 8)というクエリが与えられたとします。diff(x,y)でもunite(x,y,d)と同様に、根との差分を考えます。
となるので、-18を返します。
より一般的にdiff(x,y)では、頂点
となるので、
実装
重み付きUnionFindを実装すると以下のようになります。
import sys
sys.setrecursionlimit(10 ** 7)
class WeightedUnionFind:
def __init__(self, N):
self.N = N
self.parents = [-1] * N
self.rank = [0] * N
self.weight = [0] * N
def root(self, x):
if self.parents[x] == -1:
return x
rx = self.root(self.parents[x])
self.weight[x] += self.weight[self.parents[x]]
self.parents[x] = rx
return self.parents[x]
def get_weight(self, x):
self.root(x)
return self.weight[x]
def unite(self, x, y, d):
'''
A[x] - A[y] = d
'''
w = d + self.get_weight(x) - self.get_weight(y)
rx = self.root(x)
ry = self.root(y)
if rx == ry:
_, d_xy = self.diff(x, y)
if d_xy == d:
return True
else:
return False
if self.rank[rx] < self.rank[ry]:
rx, ry = ry, rx
w = -w
if self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
self.parents[ry] = rx
self.weight[ry] = w
return True
def is_same(self, x, y):
return self.root(x) == self.root(y)
def diff(self, x, y):
if self.is_same(x, y):
return True, self.get_weight(y) - self.get_weight(x)
else:
return False, 0
一次関数UnionFind
今回の本題である一次関数UnionFindとは、長さ
| クエリ | 内容 |
|---|---|
unite(x, y, a, b, c) |
|
solve_coef(x, y) |
|
get_val(x) |
|
set_val(x, v) |
|
考え方は、重み付きUnionFindとほとんど同じです。差分の代わりに関数を管理しています。

上のグラフでは、
unite(x,y,a,b,c)
1.頂点x y
頂点unite(x,y,a,b,c)の処理を下のグラフで考えてみます。

1-1.rank(x)\geq (y)
例えば、unite(5,7,2,3,7)というクエリが与えられたとします。普通のUnionFindと同様に頂点5の根を頂点7の根の親にするので、頂点1を頂点6の親とします。そのために、頂点1と頂点6の方程式
まず、
なので、
次に、
なので、
最後に、
よって、
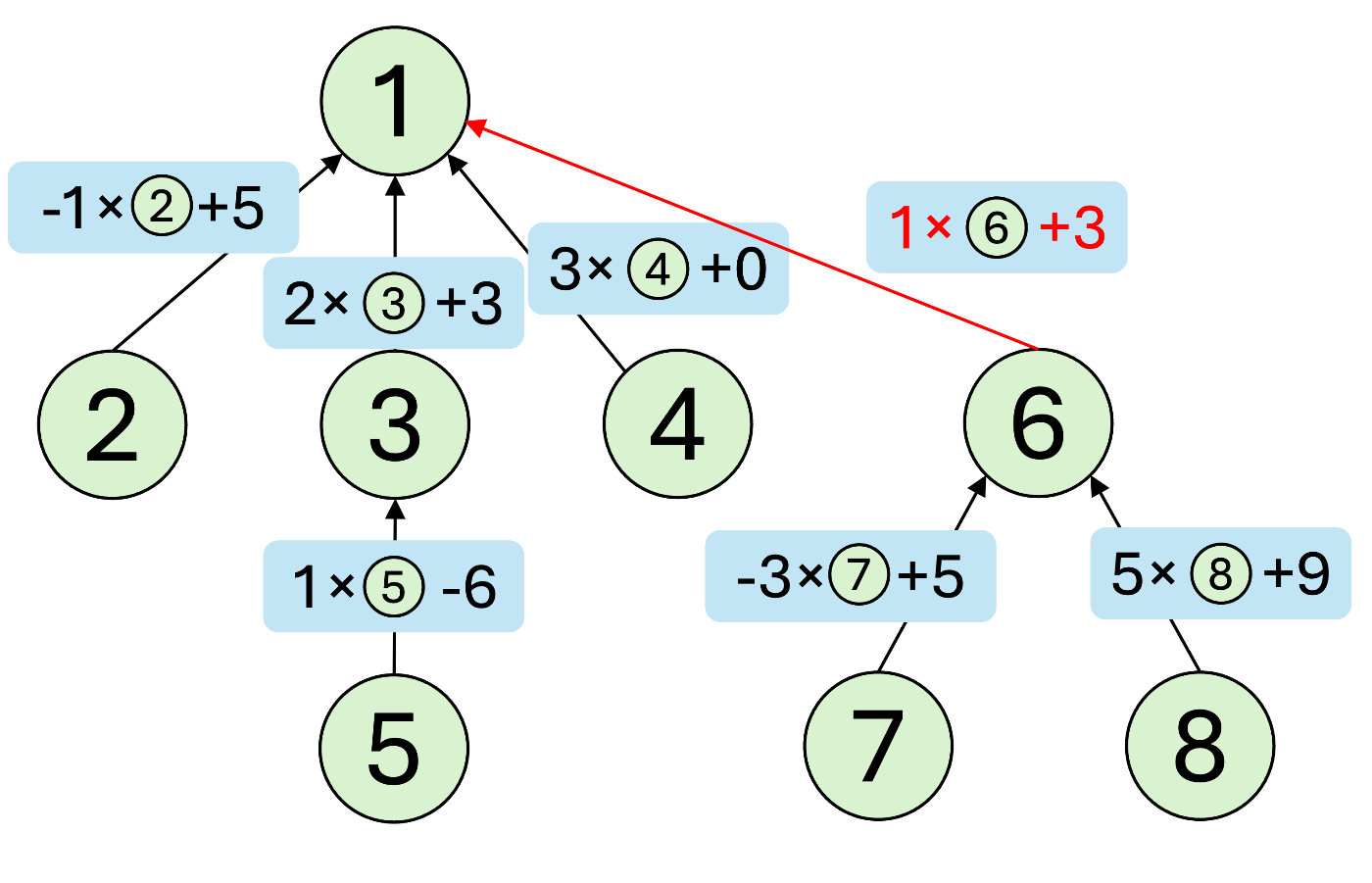
より一般的にunite(x,y,a,b,c)について考えます。
頂点
すると、
よって、
1-2.rank(x)\lt (y)
先ほどと同じグラフで、例えば、unite(8,2,5,1,1)というクエリが与えられたとします。普通のUnionFindと同様に頂点5の根を頂点7の根の親にするので、頂点1を頂点6の親とします。そのために、頂点1と頂点6の方程式
まず、
なので、
次に、
なので、
最後に、
よって、
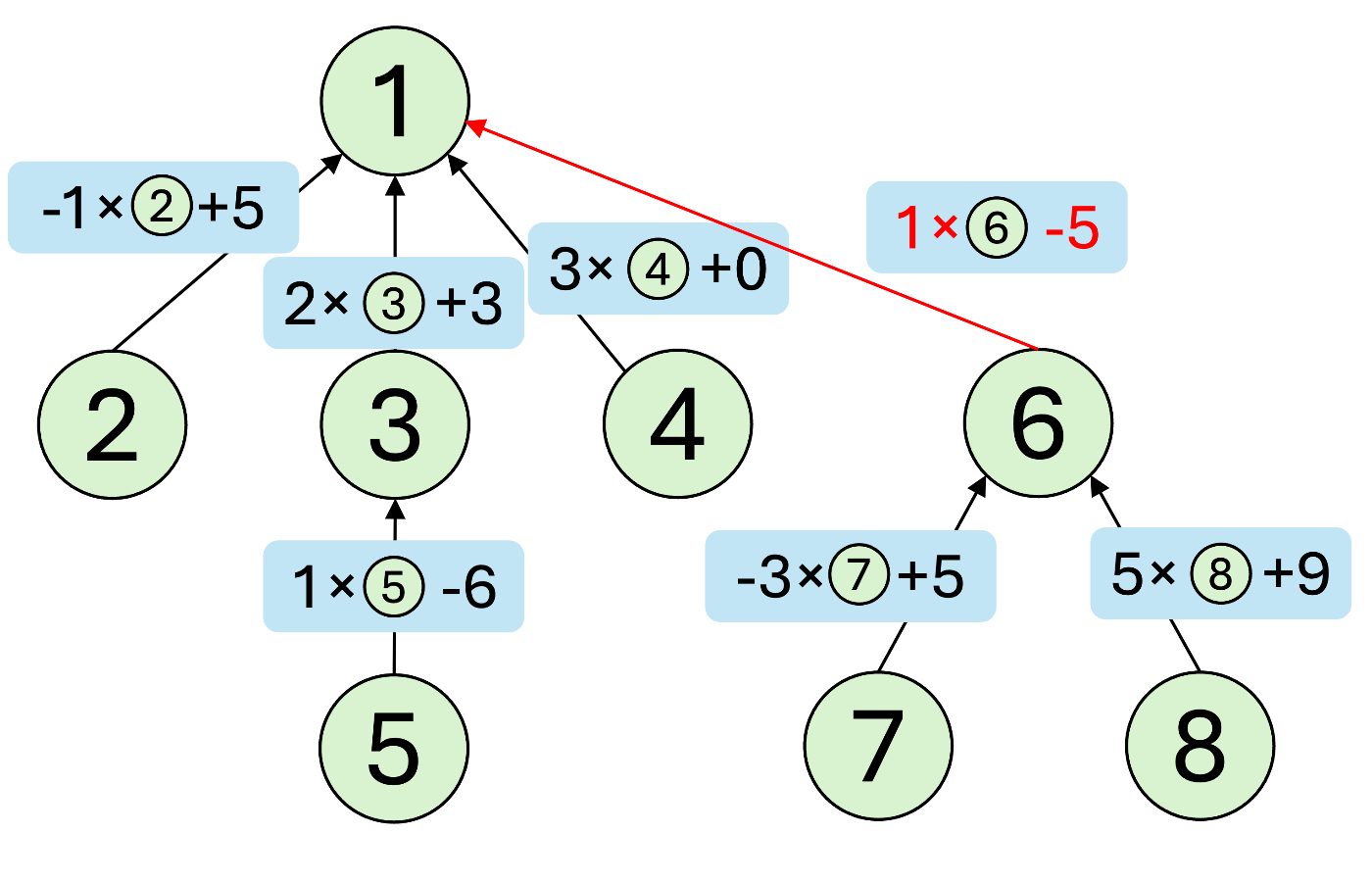
より一般的にunite(x,y,a,b,c)について考えます。
頂点
すると、
よって、
先ほどのrank
2.頂点x y
頂点
頂点unite(x,y,a,b,c)の処理を下のグラフで考えてみます。
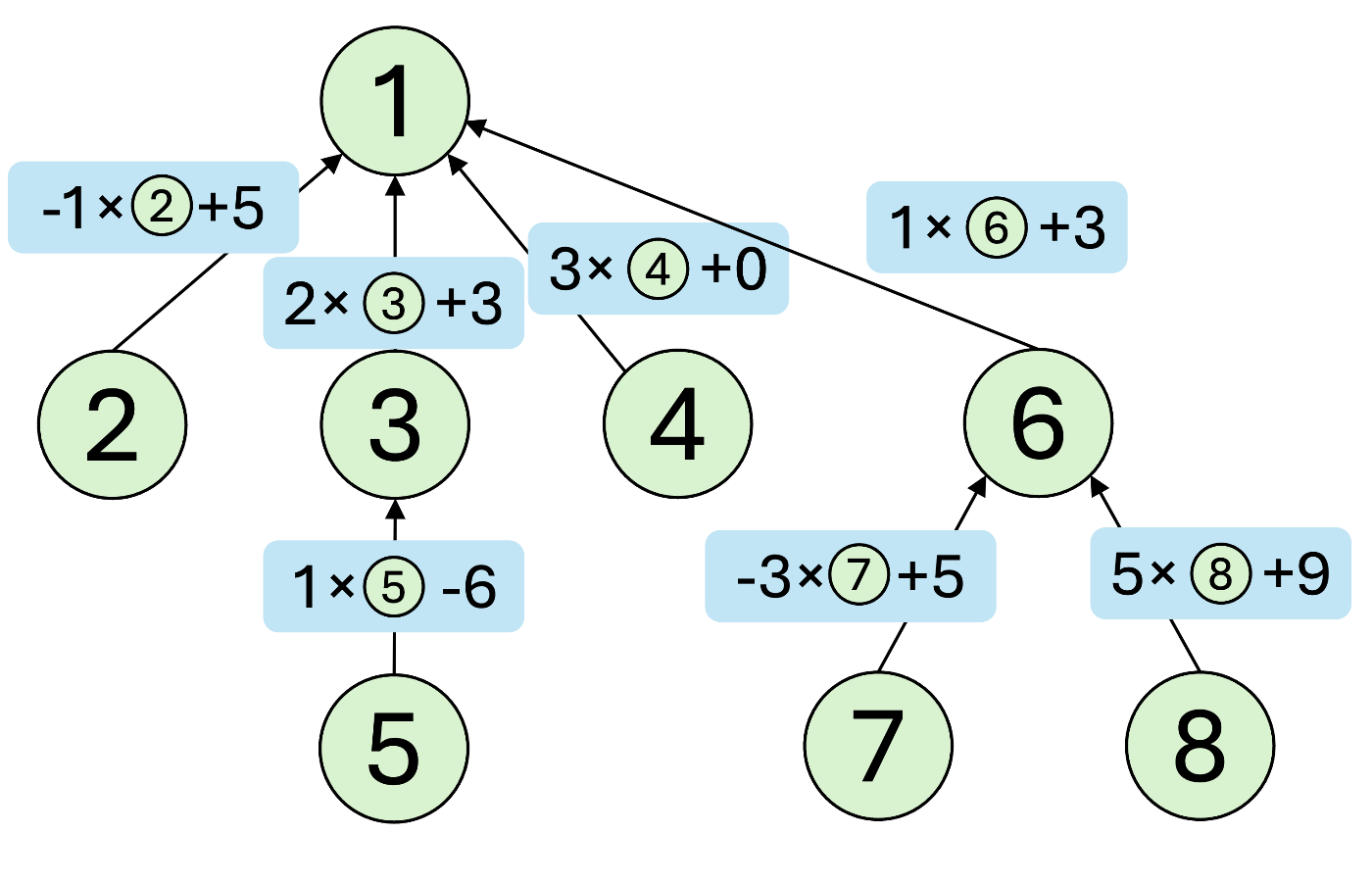
例えば、unite(5,7,4,-3,2)というクエリが与えられたとします。頂点5,7をその根である頂点1で表していきましょう。
まず、
なので、
次に、
なので、
最後に、
よって、
より一般的にunite(x,y,a,b,c)について考えます。
頂点
すると、
よって、
solve_coef(x,y)
solve_coef(x,y)の処理を下のグラフで考えてみます。
例えば、solve_coef(8, 2)というクエリが与えられたとします。頂点2,8をその根である頂点1で表していきましょう。
まず、
なので、
次に、
なので、
最後に、
よって、
より一般的にsolve_coef(x,y)について考えます。
頂点
get_val(x)とset_val(x, v)
get_val(x)とset_val(x, v)については、
実装
一次関数UnionFindを実装すると以下のようになります。
from fractions import Fraction
import sys
sys.setrecursionlimit(10 ** 7)
class UnionFindLinear:
def __init__(self, N):
self.N = N
self.parents = [-1] * N
self.rank = [0] * N
self.coef_p = [1] * N
self.coef_q = [0] * N
self.value = [0] * N
self.specify = [False] * N
def root(self, x):
if self.parents[x] == -1:
return x
px = self.root(self.parents[x])
self.coef_p[x] = self.coef_p[self.parents[x]] * self.coef_p[x]
self.coef_q[x] = self.coef_p[self.parents[x]] * self.coef_q[x] + self.coef_q[self.parents[x]]
self.parents[x] = px
return self.parents[x]
def get_coef(self, x):
self.root(x)
return self.coef_p[x], self.coef_q[x]
def unite(self, x, y, a, b, c):
'''
aA[x] + bA[y] = c
'''
if a == 0 or b == 0:
return False
rx = self.root(x)
px, qx = self.get_coef(x)
ry = self.root(y)
py, qy = self.get_coef(y)
if self.specify[rx] and self.specify[ry]:
return a * Fraction(self.value[rx] - qx, px) + b * Fraction(self.value[ry] - qy, py) == c
if rx == ry:
ca = a * px + b * py
cb = a * py * qx + b * px * qy + c * px * py
if ca == 0:
return cb == 0
self.specify[rx] = True
self.value[rx] = Fraction(cb, ca)
return True
if self.rank[rx] < self.rank[ry]:
rx, ry = ry, rx
a, b = b, a
px, py = py, px
qx, qy = qy, qx
if self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
self.parents[ry] = rx
self.coef_p[ry] = Fraction(-b * px, a * py)
self.coef_q[ry] = qx + Fraction(b * px * qy, a * py) + Fraction(c * px, a)
if self.specify[ry]:
self.specify[rx] = True
self.value[rx] = self.coef_p[ry] * self.value[ry] + self.coef_q[ry]
return True
def is_same(self, x, y):
return self.root(x) == self.root(y)
def solve_coef(self, x, y):
if not self.is_same(x, y):
return False, 0, 0
else:
px, qx = self.get_coef(x)
py, qy = self.get_coef(y)
return True, Fraction(px, py), Fraction(qx - qy, py)
def get_val(self, x):
rx = self.root(x)
px, qx = self.get_coef(x)
if not self.specify[rx]:
return False, 0
else:
return True, Fraction(self.value[rx] - qx, px)
def set_val(self, x, v):
rx = self.root(x)
px, qx = self.get_coef(x)
if self.specify[rx]:
return px * v + qx == self.value[rx]
self.specify[rx] = True
self.val[rx] = px * v + qx
return True
使用例
1. ABC328 F - Good Set Query
解答例
N, Q = map(int, input().split())
uf = UnionFindLinear(N)
S = []
for i in range(Q):
a, b, d = map(int, input().split())
a -= 1
b -= 1
if uf.unite(a, b, 1, -1, d):
S.append(i + 1)
print(*S)
2. 競プロ典型90問 068 - Paired Information
解答例
N = int(input())
Q = int(input())
uf = UnionFindLinear(N)
for _ in range(Q):
T, X, Y, V = map(int, input().split())
X -= 1
Y -= 1
if T == 0:
uf.unite(X, Y, 1, 1, V)
elif T == 1:
f, p, q = uf.solve_coef(X, Y)
if f:
print(p * V + q)
else:
print('Ambiguous')
まとめ
この記事では、重み付きUnionFindに一次関数を乗せる方法について解説しました。実は、重み付きUnionFindは一次関数に限らず、群[3]が乗るそうです。この記事では、そこまでの抽象化はできなかったため、重み付きUnionFindに群を乗せる方法について模索したいと思います。
Discussion