SSG向け日本語対応の全文検索エンジンを作りました(4) - WebGPUで検索したい!
- 第一回 日本語で検索したい!
- 第二回 英語でももちろん検索したい!
- 第三回 打ち間違いしても検索したい!
- 第四回 WebGPUで検索したい!(今回)
- 第五回 使いやすい検索にしたい!
前回のおさらい!そもそも転置インデックスを作る必要すらなく線形探索で十分な性能が出ることがわかりました。やることがなくなってしまった私は、苦し紛れに新しい機能、あいまい検索を導入しました。基本的なアルゴリズムであるbitapの実装を行い、それがちゃんと遅いことを確認(?)したのちに、英語はトライを導入、日本語はbigram一致数の緩和を行うことであいまい検索を1ms以下で実現できました。しかし、偽陰性がかなり多く、実用性には疑問がつくのでした...
以下のサイトで、ぼくが作成した全文検索エンジンのstateicseekを解説しています。みんな、使ってくれよな!
WebGPUで検索、そういうものもあるのか
前回までの検討で、英語に関してはあいまい検索を性能良く実装することができました。しかし、日本語に関しては、一致n-gramの不足を許すbigramという実装の関係で、ものすごく擬陽性が増え、イマイチ使えなさそうな雰囲気です。何か別の手法を検討したいものです。
そんな時、友だちから「検索が重い時はGPUにオフロードする」という話を聞きました。GPUで検索という発想はありませんでしたが、かなり面白そうです。早速実装を検討することにしました。
Chromeでは、WebGPUが利用でき、ブラウザからGPUを直接利用することができます。WebGPUでは3Dグラフィックスで使うシェーダー以外にも、コンピュートシェーダーが利用できます。今回の目的にとてもマッチしているので、WebGPUを使うことにしました。
GPUのアーキテクチャを知ろう
私は昔OpenGL ES2.0を使ったことがあったため、まぁ適当にシェーダーかけば大丈夫っしょwみたいな軽いノリで始めましたが、あまりにも雑な考えだったため、性能が全然出ませんでした。やはり基本から確認せねばならんな、と思い直し、GPUのマイクロアーキテクチャから調べることにしました。
本記事では、AMD RadeonのRDNA 3.5命令セットアーキテクチャのリファレンス(リンク先pdfです)を参照します。ぼくはNVIDIAのGPUを使っているのですが、NVIDIAにGPUのハードウェア構成に関するドキュメントが見当たらなかったため、AMD Radeonのものを参照することにしました。
現代的なGPUは大抵単一命令・複数スレッド(SIMT)という実行モデルに基づいて設計されているようです。これも友だちから教えてもらいました。現代のコンピュータにおけるボトルネックのひとつ、メモリアクセスのレイテンシを隠蔽できる実行モデルです。大量のスレッドを同時に起動しておき、メモリからのデータ読み出しが完了した順にスレッドを切り替えることにより、スレッドから見たレイテンシを小さくできます。
SIMTでは、一つの命令を複数のスレッドで同時に処理します。RDNAでは、スレッドのことをwork-itemと呼び、RDNA3.5では、32 work-items(Wave32)と64 work-items(Wave64)が同時に処理されるようです。Wave32/64を複数束ねたものをWork-groupと呼び、Work-groupの最大サイズは、WebGPUの標準設定では256 work-item、すなわち8個のWave32です。
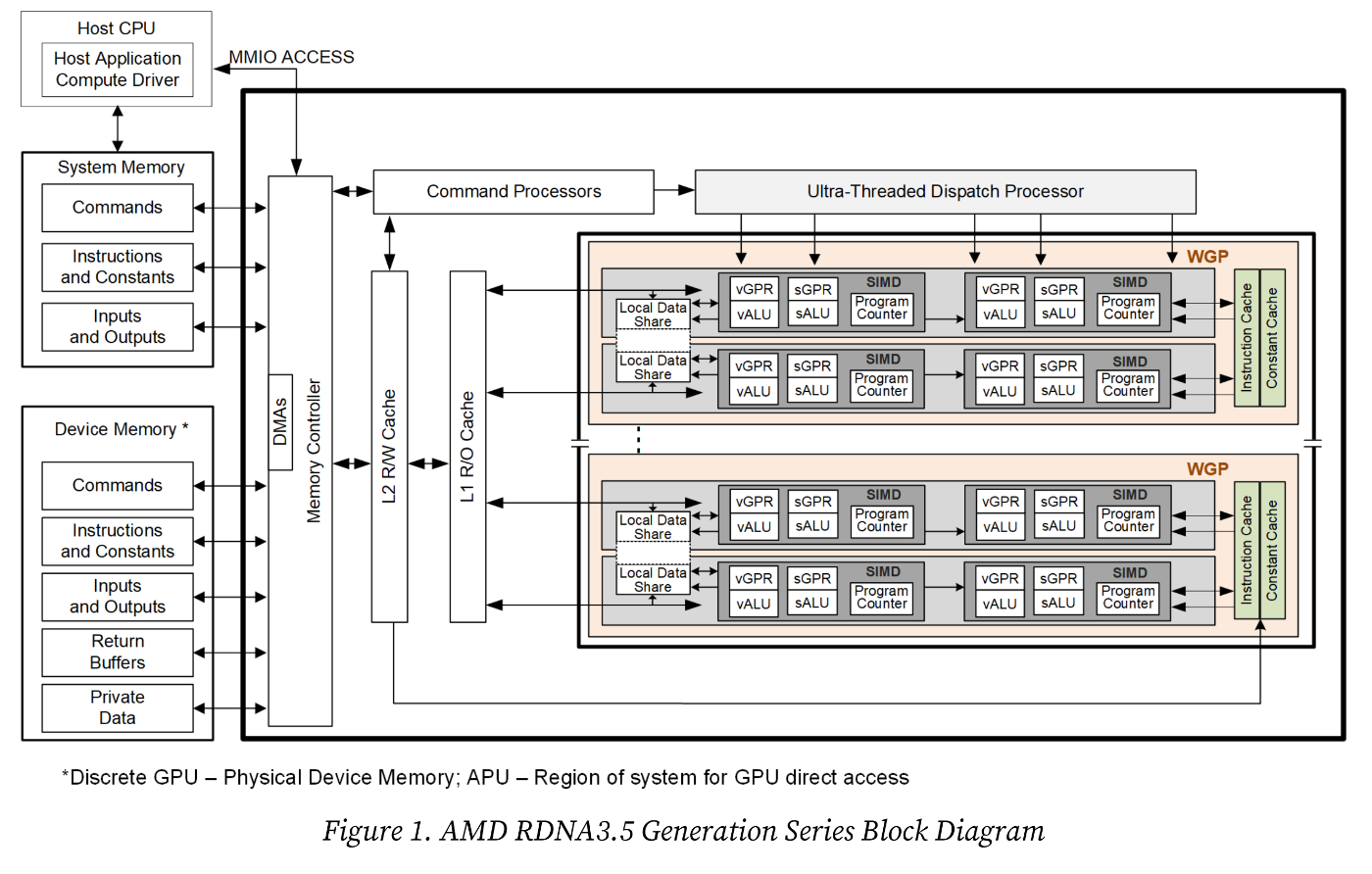

図1, 2は先ほどのドキュメントからRDNA3.5に基づくGPUのハードウェア構成を抜粋したものです。GPUは複数のWork-group Processor(WGP)から成ります。WGPは2個のCompute Unit(CU)から成り、CUは2個のSIMDから成ります。SIMDは1個のScalar ALU(SALU)と32個のVector ALU(VALU)から成り、それぞれScalar General-purpose Register(SGPR)とVector General-purpose Register(VGPR)にアクセスできます。Program Counter(PC)はSIMDごとに1個あります。SALUはRDNAに固有のものらしく、他の会社のGPUにはないと聞きました。
少し言葉の説明をします。PCとは、プログラムの実行を制御するハードウェアで、プログラムのどの部分を実行しているかを指し示すポインタです。具体的には、命令メモリ上にある機械語命令の中で、まさに今実行されている命令位置を指し示しています。一方、ALUとはArithmetic Logic Unitの略で、実際の計算を行う箇所です。また、GPRとはキャッシュよりも速い記憶要素で、誤解を恐れずに言えば、プログラム内で使われる一時変数を表すものです。ALUはGPRの値を使って計算し、計算結果をGPRに書き込みます。GPRはメモリとデータをLoad Store Unit(LSU)を使ってやり取りでき、これらの要素を組み合わせることで、メモリ上のデータを処理してメモリに書き戻すことができます。
RDNA3.5では、おそらくですが、1個のWave32/64が1個のSIMDに割り当てられ、同時に実行されていると思われます。その根拠は、SIMD内ごとに1個のPCがあり、そのPCに32個のVALUが結びついているからです。PCが指し示す命令を32個のVALUで共有しているため、32個のwork-item(スレッド)が並列に動いていそう、と考えています。
ここで注意すべきは、VALUとVGPRに関してです。SIMDのイメージがあると、どうしても、ベクター演算といえば、「1命令でx, y, z, wの4種類の値を計算する」みたいなイメージがつきまといますが、どうもそうではなさそうです。Vectorと書いてありますが、実際はxyzwが1本のレジスタにバンドルされているわけではなく、普通に32bit floating pointのレジスタから構成されているようです。なので、シェーダーは普通のスカラー的なプログラムを書くようにすれば大丈夫で、その代わりスレッド同士は同期して効率よく動くプログラムにする必要があります。
WebGPUを使った計算の手順
WebGPUを使ったコンピュートシェーダーの実行は、以下の手順に従って行います。
- GPU上にバッファをアロケート、データを書き込み
- シェーダーをコンパイル
- シェーダー実行スレッド数を指定して実行
- GPU上のバッファから結果をコピー
コンピュートシェーダーはGPU上のバッファのみにアクセスできます。そのため、JavaScript側からGPUのバッファへ入力データを書き込み、シェーダーはそのバッファを使って計算をし、計算結果をバッファに書き込み、実行が終わったらGPU上のバッファからJavaScript側のバッファへコピーします。
もう少し詳細な手順を以下に示します。専門用語が多いので注意して読んでください。
GPUDeviceをブラウザから取得する- GPU上で使うバッファ
GPUBufferを作成する - シェーダー中で使われるバッファ名に紐づいた番号と、2で作成したバッファの対応を
GPUBindGroupとして作成する - JavaScript文字列として書かれているシェーダーをコンパイルし、
GPUComputePipelineに変換する -
GPUQueueを通じて、GPUBufferへデータを書き込み -
GPUQueueを通じてGPUに実行命令を送る。実行命令はGPUCommandEncoderを使ってGPUCommamdBufferに書き込み、このGPUCommandBufferをGPUQueueを通じてsubmit()する。
6.1GPUCommandEncoderからGPUComputePassEncoderを生成する
6.2 ComputePassに実行するpipelineを指定する
6.3 ComputePassにpipelineで使用するバッファのGPUBindGroupを指定する
6.4 ComputePassに処理するworkgroup数を設定する
6.5GPUCommanBufferに、結果が格納されているGPUBufferからJavaScriptでアクセス可能なバッファへのデータコピー命令を書き込む
6.6GPUQueueに6.5までで作成したGPUCommandBufferをsubmitする。 -
GPUBufferのうち、結果が書き込まれたバッファをmapAsyncして、結果を読み出す
手順がかなり煩雑に見えますが、一度動くプログラムを構成できてしまえば、あとはその修正で済むため、そんなに問題になりません。ぼくの作った前処理と実行手順をご覧ください。もう少し詳細に分けると
GPUDeviceの取得GPUBufferの作成GPUBindGroupの作成GPUPipelineの生成(シェーダーのコンパイル)GPUBufferの書き込みGPUCommandBufferの作成- 実行
- 結果の読み出し
1-4までは前処理として、複数回のGPUへの命令で使いまわせます。また、検索対象のテキストも初期化時に1回だけ書き込み、使いまわします。(5)その他のバッファの書き込みと、(6)GPUCommandBufferの生成はGPU実行ごとに毎回実行する必要があります。
コンピュートシェーダーの書き方
コンピュートシェーダーはWGSLで記述されます。簡単なシェーダーの例を以下に示します。以下のシェーダーは「痔」という一文字を探索するプログラムです。レポジトリにコミットしてあります。また、このWGSLコードを起動するTypeScriptコードもコミットしてあります。ご参照ください。
@group(0) @binding(0) var<storage, read> data: array<u32>;
@group(0) @binding(2) var<storage, read_write> result: array<u32>;
@group(0) @binding(3) var<storage, read_write> pointer: atomic<u32>;
@compute @workgroup_size(256) fn cs(
@builtin(global_invocation_id) id: vec3u
) {
let keyword = 30164u;
let cmp = keyword == data[id.x];
if(cmp) {
let ptr_pos = atomicAdd(&pointer, 1u);
result[ptr_pos] = id.x;
}
}
@で始まる項はAttributeと呼ばれ、変数やバッファなどのオブジェクトを形容するものです。
アトリビュートを除くと、シェーダー関数は以下のように定義されます。
fn cs(id: vec3u) {
...
}
関数名は何でもいいのですが、今回はcsという名前で定義しています。この関数は@computeというアトリビュートを指定することで、コンピュートシェーダーのエントリーポイントとして使われます。また、エントリポイントはcreateComputePipelineにその名前を指定します(関数が1個しかない場合は省略可能)。コンピュートシェーダーの仮引数にはビルトイン入力値を任意個数指定できます。この例では、global_invocation_idというビルトイン入力値をidという名前でアクセスできるようにアトリビュートで指定しています。コンピュートシェーダーには戻り値はなく、結果はGPUバッファに書き込みます。
コンピュートシェーダーにおけるwork-item生成
さて、このシェーダーは「痔」の一文字を検索するプログラムです。しかし、全テキスト領域をループするfor文がありません。これは一体どういうことでしょうか?これは、前章でお話したSIMTのアーキテクチャに関係があります。
SIMTのアーキテクチャでは、できる限り多くのスレッドを生成し、メモリからの読み出しレイテンシを隠蔽するのでした。そのため、一つのスレッドで長くループして複数文字のマッチをするより、できる限りループを短くして、多くのスレッドを作った方がメモリアクセスレイテンシの隠蔽がしやすくなります。そこで、最も短いループとして、1回のループ、すなわちループなしで一文字だけマッチを確認するシェーダーを作り、それをテキスト長だけ起動します。
ループなしでマッチを並列に処理する場合、テキスト中のどの位置の文字をどのスレッドで実行するかを決めなければいけません。それを決めるために使えるビルトイン入力値として、global_invocation_idがあります。雑に説明すると、スレッドそれぞれに割り当てられる固有のidです。これをそのままテキスト中の検索位置として使えます。
global_invocation_idは型がvec3として宣言されます。このidは三次元の値まで使うことができるのですが、今回はテキスト位置だけがわかればいいので、一次元の値のみを使うことにします。fn csのworkgroup sizeを@workgroup_size(256, 1, 1)という三次元の値で指定します。それぞれx, y, zに相当します。xが256なのは、WebGPUの初期設定において最大値が256なのと、後述のハードウェア構成の関係で32の倍数にしたいからです。yとzの値を1とすることで、workgroup内のinvocation_idはx方向にだけインクリメントするようになります。@builtin(global_invocation_id) id: vec3uと宣言した仮引数において、xの値はid.xとして参照でき、これをそのままテキスト位置としてlet cmp = keyword == data[id.x]; で比較します。ちなみに、yとzが両方1の場合は@workgroup_size(256)と省略して指定できます。
このような設定下で、workgroupを1個だけ起動すると、id.xは0-255の範囲で起動されます。workgroupを何個起動するかは、GPUComputePassEncoder.dispatchWorkgroups()の引数に指定します。これも三次元の数字が指定できるのですが、今回はx方向だけを使うため、x方向の値だけ指定します。
x方向に何個workgroupを生成するかは、テキストの長さに依存します。単純にテキストの長さを、workgroup_size(今回は256)で割ります。大抵端数が出て、配列の範囲外にアクセスが生じます。アクセスが生じるとエラーになるので、対処が必要です。が、ぼく対処してませんね...やばい...直します...
ハードウェア構成を考慮したworkgroup_sizeの定め方とメモリアクセス方法
workgroup_sizeにどのくらいの値を設定するかは、前章で説明したアーキテクチャから性能的な制約が出ると考えています。RDNA3.5のSIMDでは、32 work-items(Wave32)が同時に処理されるのでした。そのため、work-itemを束ねたworkgroupは、32の倍数で割り当てるのが良いでしょう。おそらくですが、32の倍数でない場合、利用されないVALUが存在することになり、SIMD内の稼働率が下がり、結果として処理時間がより長くかかるようになるのではないかと思います。
また、Wave32内のLSU(Load Store Unit、メモリとGPR間でデータを転送するユニット)には、VGPRへのLoadアドレスができるだけ近いアドレスを与えるようにした方が性能があがると考えています。今回の例では、Wave32には隣接するglobal_invocation_idが隣接するVALUでの処理に自然に割り当てられているはずです。そのため、このままの構成で問題ないと考えています。
逆に、わざと隣接するVALU間のメモリアクセスアドレスを飛び飛びにしたコードを作り、ベンチマークしてみました。詳細は後ほど説明しますが、処理時間が3倍に伸びました。
GPUBufferの指定
GPUからアクセスできるメモリ領域はGPUBufferとして作成し、それをWGSL内の変数に割り当てます。GPUBufferを作成し、GPUBindGroupLayoutによってGPUBufferにユニークなidを割り当てます。シェーダー内でバッファを表す変数に@binding(id)というようにアトリビュートを指定することで、そのidに割り当てたバッファをGPU内で利用できます。
GPU Bufferの作成
GPUBufferはcreateBufer()によって生成します。createBuffer()には、バッファサイズをバイト単位で指定します。また、バッファの使用用途も同時に指定します。
まず、バッファは大きくわけてSTORAGEとUNIFORMに分けられます。誤解をおそれずに言うと、大きなデータ用のバッファはSTORAGEに、ごく小さい定数はUNIFORMにします。UNIFORMにはいくつか制約があるので(可変長のバッファを指定できない、書き込みができないなど)、単純なスカラ値、ベクタ値ひとつを指定する時に使うとよいでしょう。たぶん、制約がある代わりにUNIFORMへのアクセスは速いんじゃないかな、測定はしてないけれど...一方でSTROAGEは大きなサイズのデータを設定できます。今回の例では、検索対象のテキストや結果書き込みバッファと書き込みバッファ用のポインタはSTORAGEに指定します。
さらに、バッファのJavaScript側からのアクセス方法も同時に指定します。具体的には、JavaScript側のバッファからGPUBufferのコピーをするか(COPY_DST)、GPUBufferからJavaScript側のコピーをするか(COPY_SRC)を指定します。両方する場合は両方指定します。今回の例では、検索対象のテキストは一度JavaScript側のバッファからGPUBufferにコピーし、その後はJavaScript側に書き戻すことはしないためCOPY_DSTを指定します。一方、検索結果を書き込むバッファは特に初期化の必要はなく、GPUBufferからの読み出ししかしないので、COPY_SRCを指定します。結果を書き込むバッファへの書き込みポインタは、起動前に0に初期化し、実行終了後に検索結果の個数を得るために読み出すために、COPY_SRCとCOPY_DSTの両方を指定します。
data: device.createBuffer({
label: `data buffer`,
size: input.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
}),
result: device.createBuffer({
label: `result buffer`,
size: num_result * 4 * 2,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
}),
result_ptr: device.createBuffer({
label: `result pointer buffer`,
size: 4,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST,
}),
GPUBufferとWGSL上の変数を結びつかせる
生成したGPUBufferをWGSLのどの変数名でアクセスできるようにするかは、GPUBufferに固有のidを振ってそのidをJavaScript側とWGSL側で共有することで行います。
GPUBufferにidを振るには、createBingGropu()を利用します。引数のbindingに任意のbinding idを整数で指定します。
const bindGroup = device.createBindGroup({
label: `${name} bindGroup for buffers`,
layout: pipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: buffers.data } },
{ binding: 2, resource: { buffer: buffers.result } },
{ binding: 3, resource: { buffer: buffers.result_ptr } },
],
});
引数のlayoutには、WGSLをコンパイルして得られたGPUPipelineからgetBindGroupLayout()を使って取得できます。なので、先にコンパイルが必要なのですが、コンパイルを後回しにするには手動でレイアウトを作成します。どちらでも大丈夫ですが、WGSL側とJavaScript側でバッファ数や使用用途に相違がある場合はエラーが発生します。
idを振ったGPUBufferの情報を含むGPUBindGroupは、setBindGroup()によりシェーダーに結び付かせます。このとき、indexパラメータを指定してさらにGPUBufferに追加のgroup idを振ります。
WGSL側でバッファの宣言をする
先ほどまでの作業でGPUBufferにidを振ることができました。次はそのidに対応した変数宣言をWGSL側で行います。
変数宣言にはvarを利用します。
@group(0) @binding(0) var<storage, read> data: array<u32>;
@group(0) @binding(2) var<storage, read_write> result: array<u32>;
@group(0) @binding(3) var<storage, read_write> pointer: atomic<u32>;
varで宣言する変数に対して、@binding()アトリビュートを対応するbinding idで指定することで、WGSL側 の変数とGPUBufferを結びつかせます。同時に指定している@group()はsetBindGroup()を呼んだ時に指定したindex(group id)を指定します。
var宣言では、<AS,AM>の中にアドレススペース(AS)とアクセスモード(AM)を指定します。アドレススペースには、ASの箇所をuniformかstrageと指定します。これはGPUBuferに指定した使用用途と同じものを指定します。AMの箇所はread、write、read_writeのいずれかを指定し、WGSL側から見てどのようなアクセスをするかによって指定を変えます。
varで指定するidentifierの後には:の後に変数の型を指定します。いくつかの種類がありますが、このシェーダーではu32とarray<u32>、atomic<u32>を使っています。u32は32bit unsingned intを示し、JavaScript側では要素1個のUint32Arrayとしてマップします。array<u32>は32bit unsigned intの配列で、任意長のUint32Arrayとしてマップします。atomic<u32>はu32と同じく32bit unsigned intなのですが、この変数の演算と読み書きをアトミックに行うことができます。アトミックな演算については後述します。
結果の書き込みとアトミックな演算
これまでの長い設定で、ようやくGPUBufferをWGSLの変数に割り当てることができました。あとはシェーダープログラム内で普通に読み書きすればよいだけです。
let keyword = 30164u;
let cmp = keyword == data[id.x];
if(cmp) {
let ptr_pos = atomicAdd(&pointer, 1u);
result[ptr_pos] = id.x;
}
keywordに指定している30164uは十進数uint32の値を表し、「痔」という文字のunicodeのコードポイントを示します。let cmp = keyword == data[id.x];で、id.xでアクセスできるスレッドidを検索対象テキストの比較位置の32bit uintを取り出し、keywordと比較することで1文字のマッチングを実行します。ちなみに、検索対象テキストは一文字ずつコードポイントをString.prototype.charCodeAt()により取得してUint32Array格納してあることを前提としています。こちらのコードです。
比較結果のcmpがtrueの場合は、resultバッファにマッチ位置であるid.xを書き込みます。書き込み位置はpointerで制御します。pointer値を取得し、その位置にid.xを書き込み、次書き込みのためにpointer値をインクリメントします。
ここでひとつ考慮すべき点があります。SIMTでは大量のスレッドが同時に処理されるのでした。そのため、pointerの読み出しとインクリメントと書き込みが同時に複数のスレッドで行われる可能性があります。これらの処理の順番は保証されないため、pointerには正しくない値が格納される可能性がでます。
この問題を避けるため、前述したアトミック演算を利用します。atomicAdd()により、atomic<>指定された変数の読み出しとインクリメント、書き込みがアトミックに(途中で誰にも邪魔されることなく)実行されます。
ちなみに、スレッドの処理順は定まっていないため、resultバッファへ設定されるマッチ結果は起動ごとに順不同になります。通常はJavaScript側でsort()するなどして使うことが多いと思います。
if文の実行順
もう一つ注意点というか理解しておく必要のある事項があります。SIMTではスレッド間でPCを共有します。そのとき、条件分岐命令(if文)はどのように扱われるのでしょうか?
スレッド単位でif文の比較結果は変わるため、SIMD中でtrue pathとfalse pathが混ざる場合があります。これらが混ざった場合、SIMDは両方のパスを通ります。PCは両方のパスを通るようにインクリメントされていくのですが、VALUごとに実行する/しないを定めるフラグがあり、そのフラグを制御することによりVALUの実行をマスクし必要なVALUだけが実行されます。そのため、両方のパスを通るような条件が多いと、VALUの稼働率が下がり、性能が低下します。SIMD内ではできるだけ条件分岐が一律になるように設定できると性能があがります。とはいえ、条件分岐なので事前に揃えることは難しいとは思います。
GPUBufferの読み出し方法
計算内容はたいしたことないのに、バッファの扱いが面倒くさすぎてこんなに長い説明になってしまいました。しかし、これでようやく計算ができて、あとは結果を読み出すだけ!になりましたが、実はまだバッファの扱いが追加で必要になります。大変ですね。
GPUBufferへの書き込みはGPUQueueに直接命令を下すだけで可能でした。しかし、シェーダーからアクセスできるGPUBufferはJavaScript側から読み出すことができせん。そこで、JavaScriptから読み出すことのできるGPUBufferを作成し、シェーダーの実行終了後にこのGPUBuffer間でデータを全コピーすることでJavaScript側から結果のデータを読み出すことができます。
GPUBufferからの読み出しは具体的には以下の手順を踏む必要があります。
- JavaScriptから読み出せる
GPUBufferを作成する。具体的には、読み出したいGPUBufferと同じサイズのGPUBufferを、MAP_READとCOPY_DST指定で生成する - CommandBufferを作る際、
GPUComputePassを生成したのちにGPUBufferからGPUBufferへのコピー命令(copyBufferToBuffer())を挿入する -
GPUQueue.submit()した後、GPUBufferをREAD指定でmapAsync()して、続いてGPUBufferをgetMappedRange()してその結果をnew Uint32ArrayすることでUint32Arrayに変換する - 作成した
Uint32Arrayからデータを読み出す
多分memmap的な奴だと思います。たぶん。名前からするに。
// Encode commands to do the computation
const encoder = device.createCommandEncoder();
const pass = encoder.beginComputePass();
(中略)
pass.end();
// Encode a command to copy the results to a mappable buffer.
encoder.copyBufferToBuffer(buffers.result, 0, buffers.result_copy, 0, buffers.result.size);
encoder.copyBufferToBuffer(buffers.result_ptr, 0, buffers.result_ptr_copy, 0, buffers.result_ptr.size);
encoder.popDebugGroup();
// Finish encoding and submit the commands
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
// Read the results
await buffers.result_ptr_copy.mapAsync(GPUMapMode.READ);
const resultPtr = new Uint32Array(buffers.result_ptr_copy.getMappedRange());
これで、ようやくWebGPUを使ったプログラムの実行ができるようになりました。お疲れ様です!
GPUリソースの排他利用
...と、したいところでしたが、一つ言い忘れていたことがあります。リソースの共有についてです。
GPUQueue.submit()は同期関数なのですが、結果を読み出すGPUBuffer.mapAsync()は非同期関数です。GPUの実行が終わったあとにPromiseがfulfilledになると思われます。ブラウザ環境では、GPUBuffer.mapAsync()呼び出し直後にコンテキストスイッチが発生し、UIのイベント待ちになるはずです。そうすると、GPUの処理が終わる前に次の検索がトリガされることもあり得ます。次の検索はまた最終的に同じGPUBufferを使った処理をしようとし、その結果ふたつのGPU処理のリソースが競合してエラーになります。具体的には、二回目のGPUBuffer.mapAsync()が失敗します。
この問題を解決する手法を二種類考えました。
- 毎回
GPUBufferなどのオブジェクトを生成し、再利用しない - GPUリソースを排他使用する
これはかなりコーナーケースなため、1)の処理は普段使いするには少し重い気がしています。そこで、2)を採用することにしました。
具体的には、なんちゃってMutexを実装して、GPUを使った検索の直前にaquireし、GPUを使った検索が完全に終了したあとにreleaseするように修正しました。これでいい、はずです。はずです、というのは、このなんちゃってMutexはLLMに生成させたものなので、いまいち正しさに自信がありません...誰か確認してくれ...
プロファイリング方法
WebGPUを使ったプログラムの少し詳細プロファイリングは、PIX on Windowsを使うことで可能です。これも友だちに教えてもらいました。WebGPUが動作しているChrome自体をPIXでプロファイリングすることで、結果としてWebGPUのプロファイリングが可能になります。プロファイルの取り方を説明しているサイトに従うとプロファイルが取れるようになります。ここで、PIXは管理者権限で実行する必要があるかもしれません。
PIXは本来グラフィック用のプロファイラのため、プロファイルを10フレーム分取る、とかそういう設定を行います。しかし、コンピュートシェーダーにはフレームという概念がありません。どうにも取得のタイミングがよくわかりません。わからないので、WebGPUのコードを無限ループさせて、どのタイミングでもプロファイルを取得できるようにしました。
標準のChromeのままだと、デバッグ用のラベルを挿入してもそれが表示されないため、どのタイミングでどのプログラムが動いているのか判然としません。挿入したデバッグ用のラベルをPIX上で表示させるには、先ほどのサイトの「Enabling Debug Markers」の箇所に書かれている作業を実行する必要があります。NuGetのパッケージとってきてdllをChromeの実行ファイルのあるところに仕込むので、セキュリティは気になります。一応このパッケージのオーナーはMicrosoftなので、大丈夫ということにしておきますが、気になる方は避けるのもひとつの方法です。あと、dllはChromeのupdateで消え去るので、Chromeがupdateするたびに置きなおす必要があります。
簡単な文字探索シェーダーのプロファイリング結果
一応、1文字のみの文字探索と、同じく1文字ですが隣接するALUに対して4kbyte離れた位置のデータをロードするようにメモリアロケーションをのプロファイルを取りました。検索対象テキストのサイズは約4MByteです。
図3 1文字のみの文字探索のプロファイル結果
図4 隣接するALUに対して4kbyte離れた位置のデータをロードするようにメモリアロケーションしたコードのプロファイル結果
はい!何も見えないですね!すいません!一応、ざっくりした結果だけ下記に示します。
| 手法 | Dispatch時間 | Copy時間 | Total [ms] |
|---|---|---|---|
| 1文字 | 55[us] | 1.43[ms] | 1.44[ms] |
| 4kbyte | 158[us] | 1.33[ms] | 1.33[ms] |
確かに4kbyte離した方がDispatch時間(おそらく処理時間)が3倍遅いのですが、処理終了後のGPUBufferのコピー時間の方が圧倒的に長く、あまり意味のない結果になりました。また、これらの処理をJavaScript側から時間測定すると、数ms~10ms程度に見えました。GPU内の処理はものすごく速く終わるのに対し、オーバーヘッドが大きすぎる気がしています。図が小さすぎて全く見えませんが、プロファイル中のWave Ocupancy(稼働率だと思われる)は70%くらいで、まだボトルネックはあるようでした。
WGSLで記述したbitap
これまでの作業で、コンピュートシェーダーを用いた検索を実装できる目途がつきましたので、実際に実装しました。WGSLで記述したbitapアルゴリズムと、TypeScriptで記述したbitapアルゴリズムを比較してみてください。大筋は一緒のはずです。ただ、TypeScriptの方ではtextをループしていますが、前述のようにWGSLではループはせず、その代わりにスレッドを起動しています。また、bitap keyで使っているMapはWGSLでは使えないので、配列を線形探索しています。
GPUでのbitapは検索対象のtext全体はループしてはいないのですが、その代わり各文字位置ごとに個別のスレッドが立てられて、そこから始まるテキストをクエリキーワード長分だけループして探索しています。つまり、テキスト長をN、キーワード長をMとすると、GPUのbitapはO(NM)の計算をしています。一方、CPU bitapの計算量はO(N)です。M倍計算量が違うので、無駄が多いのですが、とりあえずはこれで実装してみました。計算量の無駄は多いのですが、その分VALU間のデータの局所性が上がってデータフェッチが速くなりこちらの方が性能がいいかもなぁ、と考えました。GPUでO(N)になるアルゴリズムは実装していないので、実際どのような性能の違いになるかは今のところはわかりません。
bitapのISA
これは余談ですが、ベンチマークをとる前に、RDNA3.5向けにシェーダーをコンパイルした結果をアセンブリ言語で表示させてみました。実際にRadeonのGPUを持っていなくても、Radeon GPU Analyzerをインストールし、rgaコマンドをコマンドラインから使うことでシェーダーをコンパイルした結果をアセンブリ言語で見ることができます。ただ、WGSLからのコンパイルには対応していないので、HLSLに移植したコードをコンパイルしました。
rgaの実行コマンドは以下になります。
rga -s dx12 --offline -c gfx1150 --cs-entry cs --cs-model cs_6_0 --isa isa.txt --cs bitap_dist3.hlsl
こちらが変換結果のISAです。GPU界隈では、アセンブリ言語出力のことをISAと呼ぶようです。普通のISAという言葉の使い方とは違うので戸惑いますが、そういうものなのでしょう。
ISA取ったらなにかわかるかなーと思ったのですが、私の能力が低くてイマイチよくわかりませんでした。勉強が必要ですね。先ほどプロファイルをとった1文字のみの文字検索もHLSLに移植してISAを出力させました。こちらの方が短くて見通しは良いので、じっと眺めると何かがわかるかもしれません。
ベンチマーク・プロファイリング
以前と同じ、3-4MByteのテキストデータに対する検索を実行し、ベンチマークをとりました。今回はGPU bitapが加わっています。ベンチマークを取り直したので、数字は少し違いますが、前回と同じ手法の結果は前回とほぼ似たような数字になっています。
| 手法 | 作成時間 | サイズ | gzipサイズ | 検索時間 | 一致 | 擬陽性 | 偽陰性 |
|---|---|---|---|---|---|---|---|
| 英語(線形) | 334ms | 3,748kbyte | 1,324kbyte | 2.84ms | |||
| 英語(CPU bitap) | 278ms | 3,748kbyte | 1,324kbyte | 73.72ms | 58964 | 17924 | 0 |
| 英語(GPU bitap) | 288ms | 3,748kbyte | 1,324kbyte | 4.47ms | 58964 | 17931 | 0 |
| 英語(Trie) | 921ms | 3,748kbyte | 506kbyte | 0.30ms | 57762 | 10295 | 1202 |
| 手法 | 作成時間 | サイズ | gzipサイズ | 検索時間 | 一致 | 擬陽性 | 偽陰性 |
|---|---|---|---|---|---|---|---|
| 日本語(線形) | 135ms | 3,020kbyte | 1,053kbyte | 0.29ms | |||
| 日本語(CPU bitap) | 128ms | 3,020kbyte | 1,053kbyte | 18.14ms | 15437 | 10062 | 0 |
| 日本語(GPU bitap) | 125ms | 3,020kbyte | 1,053kbyte | 3.92ms | 15437 | 10068 | 0 |
| 日本語(Bigram) | 482ms | 3,020kbyte | 813kbyte | 0.93ms | 13375 | 22148 | 2062 |
GPU bitapは英語・日本語ともに4ms/query程度と、UIのことを考えても許容範囲内になっています。Bigram/Trieよりも一桁遅く、TypeScript上のbitapより1桁速い程度です。また、先におこなった1文字検索のベンチマークでは、実行時間が数ms程度となっており、bitapのようなより複雑なアルゴリズムに変更してもほとんど実行時間が変わりませんでした。なにがしかのオーバーヘッドがあると思いますが、判然としません。
CPU bitapとGPU bitapの一致の数値と擬陽性の数値がほぼ一緒なので、GPU bitapはCPU bitapとほぼ同じものが間違いなく実装されていそうです。ほぼ同じでちょっと違う理由は、GPUでは前述のようにループさせないので、検索位置前後で一致状態のコンテキストが共有されず、すこし誤差が乗るせいだと思っています。

こちらがbitapのプロファイルをとったものです。黄色がコンピュートシェーダーのWave Ocupancyで、おそらく稼働率です。98%くらいで間欠的に動作しています。
| 手法 | Dispatch時間 | Copy時間 | Total [ms] |
|---|---|---|---|
| GPU bitap | 620[us] | 160[us] | 780[us] |
1文字検索よりDispatch時間は伸びましたが、なぜかCopy時間が短縮されたため、Totalでは1msを切っています。ただ、これでもJavaScript側からみると数msの処理時間に見えます。やはりなにがしかのオーバーヘッドが大きい気がしています。
しかし、このプロファイルを見ると、780us程度の処理が隙間なく詰め込まれているんですよね。そうすると、JavaScript側からも、処理時間は1ms以下に見えてないとスループットが合いません。何故遅くなるのでしょうか……わかりません。どこかで長時間ガベージコレクションでも行われているのでしょうか。
最後に
不明な点はかなり多いのですが、とりあえずCPU bitapより一桁高速化できたのでこれで一段落とします。このベンチマークはRTX4070で実行しましたが、intel N100に搭載されているGPUでも高速化が達成できたので、広いプラットフォームで高速化を体感できると思います。
以上で、staticseekで使われている検索アルゴリズムの全てを説明できました。気力があれば、次回、残りの細々した処理、スコアリングやクエリのパースなどについてお話しようと思います。
Discussion