日々の気づきまとめ
tips
-
**/.DS_Storeで全ての階層の.DS_Storeファイルを無視できるよ
-
JSX内でconsole.logがしたい時は、
<>{console.log(~)}</>でできるよ -
クリップボードにコピーする処理
navigator.clipboard
.writeText("コピー内容")
- プログラミングで良く使う英単語(https://qiita.com/Ted-HM/items/7dde25dcffae4cdc7923)
ソフトウェアアーキテクチャ上の区分
1. MVC+Service+Repository
- Model-View-Controller
Webアプリケーションでよく使われる設計パターンで、ユーザーインターフェースとビジネスロジック、データアクセスを分離する。 - Service
業務ロジック(ビジネスロジック)をまとめるための層。MVC でいう M(Model) と C(Controller) の間にビジネスロジック層を挟むようなイメージ。 - Repository
データへの永続化・取得ロジックを一元管理するための層(=データアクセス層)。
2. Symfonyの分け方:Controller+Entity+Repository(+Service)
- Controller
Routing や HTTPリクエスト/レスポンスのやりとりを担当 - Entity
Doctrineのエンティティクラス(=データの構造を表す。テーブルとのマッピング) - Repository
Doctrineのレポジトリクラス(=DBからのデータ取得や検索ロジックを主に担当) - Service
ビジネスロジック。自由にsrc/(サービス名)ディレクトリを作っていく
目的
● 責務を明確にする
コントローラは「リクエストを受け取ってレスポンスを返す」=Webとのやりとりの仲介役
サービスは「ビジネスロジック」を担う
エンティティは「データを表すオブジェクト(モデル)」
レポジトリは「データアクセス」を担当
こうして役割をしっかり分けることで、それぞれの変更が他の部分に与える影響を少なくでき、保守がしやすくなる
● テストしやすくなる
ビジネスロジック(サービス層)を分離することで、コントローラやデータベースへのアクセスから独立した形でユニットテストを行いやすくなる
● 再利用性・拡張性の向上
ビジネスロジックがまとまっていれば、将来的に CLI (コマンドラインツール) やバッチ処理など、Web以外から同じロジックを呼び出したい場合にも再利用が容易
プロキシとリバースプロキシの違い
-
プロキシ
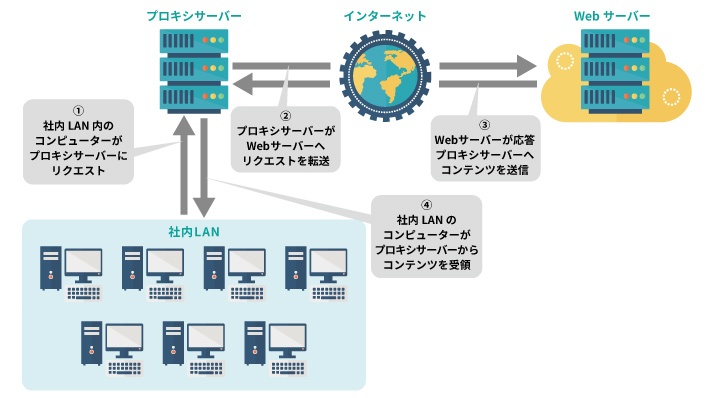
webアクセスする前に代理のコンピュータを噛ます。
メリット- プロキシにキャッシュできる
- 匿名性やセキュリティ、フィルタリング機能を持たせられる
-
リバースプロキシ

webアクセスした後に代理のコンピュータを噛ます。
メリット- リバースプロキシにキャッシュできる
- 一つのURLリクエストを複数のwebサーバーに分散できる
- ユーザーとWebサーバー間でやり取りする内容を暗号化するためにSSL通信が行われるが、通常はWebサーバー上で暗号化・復号の処理が求められる。リバースプロキシで暗号化・復号を行えば、内部のWebサーバーはSSL処理を行う必要がなくなり、負荷を軽減できる
DI
1. DIの定義
DI=オブジェクトの注入。クラスの中で利用する他のクラス(依存オブジェクト)を 自身で生成せずに外部から注入すること。もっと言うと、具体的な実装を new せずに、外部から渡してもらうことで、柔軟に依存関係を管理すること
前提
- phpでは他ファイルに切り出されたClassなどは、TypeScriptのようにimport / exportする代わりに、require / include / require_once / include_once などのインクルード構文を使う
- インターフェイスは型の一種だが、通常の型(クラスやプリミティブ型)とは異なり、メソッドの定義(仕様)だけを決めるもの。だが、LoggerInterface $loggerのように型ヒントとして利用できる
interface LoggerInterface { public function info(string $message); } //LoggerInterfaceを元にFileLoggerを定義 //LoggerInterfaceに定義されているinfoメソッドは最低限必ず実装する必要がある class FileLogger implements LoggerInterface { public function info(string $message) { file_put_contents('log.txt', $message . PHP_EOL, FILE_APPEND); } }
2. 目的・メリット
-
テスト容易性の向上
テスト時にモックやスタブなど、実際のオブジェクトと置き換えやすくなるため、ユニットテストが書きやすくなります。 -
保守性の向上
あるクラスが利用する別のクラス(依存オブジェクト)が明確になるので、依存関係を可視化できます。修正が必要なときは依存オブジェクトを差し替えるだけで済みます。 -
再利用性の向上
クラスが自分で依存オブジェクトを生成しないため、異なる実装のオブジェクトを切り替えて使うことが容易になります。
3. 実例
- DIじゃない
class Sample //クラスを定義
{
//クラス定数。Sample::LOG_FILE_PATH, self::LOG_FILE_PATH として参照可能
const LOG_FILE_PATH = 'sample.log';
//private アクセス修飾子で、同クラス内部からのみアクセス可能。$logger 変数を宣言し、初期値はnull
private $logger = null;
//コンストラクタメソッド。new Sample() としてインスタンスを生成したときに 自動的 に呼び出される
public function __construct()
{
//FileLogger というクラスのオブジェクトを新たに生成して代入
//FileLoggerは別のファイルで定義されている
$this->logger = new FileLogger();
//FileLogger内のsetFilePathメソッドを呼び出す
$this->logger->setFilePath(self::LOG_FILE_PATH);
}
public function doSomething()
{
$this->logger->info('doSomething successed!');
}
}
- DI
class Sample
{
private $logger = null;
//$logger は LoggerInterface型のオブジェクトしか受け取れない
//new Sample(...) の引数として、LoggerInterfaceを元に実装されたクラスのインスタンスを渡す
public function __construct(LoggerInterface $logger)
{
//new演算子に依存していない状態。これがDI
$this->logger = $logger;
}
public function doSomething()
{
// 何か処理
// ログを残す
$this->logger->info('doSomething successed!');
}
}
4. 結局何が嬉しいのか?
DIにするための流れ
1. まず、インターフェイスを用意
インターフェイスを用意することで、どのクラスを渡すかはまだ決まっていないが、「このメソッドは最低限必要」ということだけ決めておく。
interface LoggerInterface {
public function info(string $message);
}
➡ ここでのポイント
- ログを記録する仕組みはまだ決まっていない
- でも
info()メソッドを持つことは確定 - この時点では「どのクラスを使うか」を決めていない
2. Sample クラスを作るが、具体的な実装は決めない
「LoggerInterface を持つものなら何でもOK!」 という状態にしておく。
class Sample {
private $logger;
public function __construct(LoggerInterface $logger) {
$this->logger = $logger;
}
public function doSomething() {
$this->logger->info('doSomething successed!');
}
}
➡ ここでのポイント
-
Sampleクラスは「どんなロガーを使うか」は知らない - でも
LoggerInterfaceに定義されているinfo()は使えることが保証されている - 具体的にどのクラスが渡されるかは
new Sample(...)の時点で決まる(柔軟な設計)
3. 具体的な実装(FileLogger など)を作る
class FileLogger implements LoggerInterface {
public function info(string $message) {
file_put_contents('log.txt', $message . PHP_EOL, FILE_APPEND);
}
}
- この時点で初めて「実際のログの保存方法」が決まる
- このクラスは
LoggerInterfaceを実装しているので、LoggerInterface型の変数として渡せる
4. new Sample() する際に FileLogger を渡す
$logger = new FileLogger();
$sample = new Sample($logger);
$sample->doSomething(); // log.txt にログが記録される
-
Sampleは「渡されたLoggerInterfaceを使うだけ」 - 具体的な
FileLoggerの処理には依存しない - あとから
DatabaseLoggerなどに差し替えてもSampleのコードを一切変更する必要がない!
ちなみに、インターフェイスなしでも DI は可能👇
class Sample {
private $logger;
public function __construct(FileLogger $logger) {
$this->logger = $logger;
}
}
DIコンテナ
1. DIでやっていたこととの違い
インターフェースなどを用いて引数を持たせることで、new演算子に頼る必要がなくなる。しかし、大規模プロジェクトで引数(依存関係)が増えてくると大変
そこで、DIコンテナとして依存関係を諸々定義してやって、使うときは一々引数を持たせるのではなく、DIコンテナを取得して使おうという話
2. 実例
<?php
require_once __DIR__ . '/vendor/autoload.php';
use Pimple\Container; //Pimpleという外部ライブラリ
use FileLogger;
use TwitterManager;
use DatabaseUserAuthenticator;
use Sample;
//Container は 配列のように使えるオブジェクト
$container = new Container();
//'file.logger'を登録。protectでそのまま関数として保持する
$container['file.logger'] = $container->protect(function($logFileName) {
return new FileLogger($logFileName);
});
//$cはコンテナを指す
$container['twitter.manager'] = function ($c) {
$logger = $c['file.logger']('twitter_manager.log');
return new TwitterManager($logger);
};
$container['database.authenticator'] = function ($c) {
return new DatabaseUserAuthenticator();
};
//Sample は FileLogger、TwitterManager、DatabaseUserAuthenticator を必要としている
//これらの依存オブジェクトは全てコンテナから取得するのでDI
$container['sample'] = function ($c) {
return new Sample($c['file.loggger']('sample.log'), $c['twitter.manager'], $c['database.authenticator']);
};
↑のように定義してやると、↓のように呼び出すときに楽
require_once __DIR__ . '/container.php';
// 通常にここでインスタンスを生成する場合
// $logger = new FileLogger('/var/log/sample.log');
// $twitter = new TwitterManager();
// $dbAuthenticator = new DatabaseUserAuthenticator();
// $sample = new Sample($logger, $twitter, $dbAuthenticator);
$sample = $container['sample'];
引数の数や内容が変わったとしても、各呼び出しもとを修正する必要がなく、DIコンテナ(container.php)だけ修正すれば良い
おまけ:protect()の有無
- なし(new FileLoggerの実行結果を直接返す )
$container['file.logger'] = function () {
return new FileLogger('log.txt'); // ログファイル名が固定される
};
$logger = $container['file.logger']; // new FileLogger('log.txt') が実行される
- あり
$container['file.logger'] = $container->protect(function($logFileName) {
return new FileLogger($logFileName);
});
// 呼び出すときに異なるログファイル名を渡せる
$logger1 = $container['file.logger']('sample.log'); // new FileLogger('sample.log')
$logger2 = $container['file.logger']('debug.log'); // new FileLogger('debug.log')
サービス連携を実現するための最初の考え方
Callbackとは
異なるA, Bサービスの連携を行うためには、A側がどこに知らせに行くかという設定と、B側が知らせを受け取ってどう処理するかという設定が必要。
特に、リクエストされる側の設定をコールバック(callback)という。
連携サービス例
「slackにてSymfonyAppで受け取ったコメントの投稿が管理者に受理されたら、コメントをしたユーザーにメールで通知する仕組み」
を実装しようとしたら、まずはSlack, callback(ここでは連携を趣旨とする), SymfonyAppの3フェーズに分ける。
次に、それぞれのフェーズの役割について考えていく。
Slackは受理ボタンを押下した後に、押したことをどうSymfonyAppに通知するか。
callbackはPOSTデータ(payload)をSymfonyAppのどこのコントローラで受け取るか。
SymfonyAppは受け取ったことをどうやってメールで通知するか。
最後に、SymfonyAppに通知する方法、コントローラで受け取る方法、メールで通知する方法を探し、最適なものを選択していく。
スキーマといっても、APIスキーマとDBスキーマの二通りある
DBスキーマはDBの構造に関わるやつ。ER図とかで図示されるやつ
APIスキーマはAPIのリクエスト、レスポンスなどを決めるやつ
APIリクエストはDBスキーマの結合で作った巨大なテーブルから、ORMを用いてデータをAPIスキーマに基づいて引っ張ってくる処理。で、DBスキーマを結合するために必要なのが、PK, FK。巨大なテーブルを作るときは基本、全リクエストに共通するようなスキーマを元に、PK, FKで結合していく。
Slack API用にBotを作る手順
- こちらにアクセス
- 右上のYour Appsをクリック
- Create an Appsをクリック
- 好きなアプリ名を入力して、アプリをインストールするワークスペースを選択(利用したいSlackチャンネルを選択)して作成
- サイドメニューからOAuth & Permissionsを開く
- Scopeメニューで、Select Permission Scopesのプルダウンから何の権限を与えるか選択(channels:writeとか)
- その後、上にスクロールしてInstall to Workspaceをクリック
- インストールが完了すると、User OAuth Tokenと、Bot User OAuth Tokenが表示される。このとき、Bot User OAuth Tokenを使うと、Botが発言とか色々してくれるようにできるのでメモっとくこと
尚、チャネルidはチャネル右クリック→チャネルの詳細を表示する→一番下に書いてある。
その二つから、DSNをslack://<Bot User OAuth Token>@default?channel=<channelId>のように
構成。
セッションストレージとは何か?
1. 「セッション」とは
- Webアプリでは、ユーザーが「ログインした状態」「カートに入れた商品」などを複数リクエスト間で保持する必要があります。
- HTTP はステートレス(1回1回のリクエストが独立)ですが、ユーザーを識別して状態を保ちたい → これを**「セッション(Session)」**と呼び、サーバー側で保存します。
2. セッションストレージの場所
- セッション情報(ユーザーID、ログイン状態、カート内容など)をサーバー側のどこに置くか、いくつかの選択肢があります。
-
ファイル:
/var/sessions/のようにローカルファイルに書き込む -
データベース:
sessionsテーブルなどを用意して、セッションIDと内容を保存 - Redis (または Memcached など)
-
ファイル:
- どのストレージを使うかはアプリの規模・性能要件・インフラ構成などで決めます。
- 他にも
- オブジェクトストレージ(AWS S3 , Azure Blob, MinIO, etc.)
- メッセージキュー(RabbitMQ, Kafka, etc.)
- 分散ファイルシステム (HDFS, etc.)
- その他のNoSQL (ドキュメントDB, Key-Value, GraphDB etc.)
などがある
3. なぜRedisでセッションを保存するの?
- ファイルだと、サーバーが複数台になるとセッションファイルを共有しづらい(NFSなどが必要)。
- DBだと、書き込みが多すぎるとDB負荷が大きくなるし、セッションの高速アクセスはあまりDBに向いていない場合が多い。
- Redisはインメモリで高速かつ、分散クラスタ構成が比較的しやすい → 大規模トラフィックでもスケールしやすい。
- そのため「セッション管理をRedisにする」→ 高速アクセス + 負荷分散に強い、という利点。
phpプロジェクトでもprettier効かせたいとき
例:
.prettierrc
{
"tabWidth": 4,
"semi": false,
"singleQuote": true,
"trailingComma": "all",
"plugins": ["@prettier/plugin-php"]
}
<project名>.code-workspace
{
"folders": [
{
"path": ".",
},
],
"settings": {
"emeraldwalk.runonsave": {
"commands": [
{
"match": "\\.php$",
"cmd": "prettier ${file} --write",
},
],
},
},
}
📝 Googleログイン認証方式の比較表
| 項目 | Implicit Flow | Authorization Code Flow | PKCE(Authorization Code Flow + PKCE) | Implicit Flow + Token Exchange | PKCE + Token Exchange |
|---|---|---|---|---|---|
| フロントエンドでの処理 | Googleの access_token を直接取得 |
認可コード (code) を取得し、バックエンドで access_token に交換 |
認可コード (code) を取得し、code_verifier を使用して交換 |
Googleの access_token を取得し、バックエンドに送信 |
code_verifier を使って認可コードを取得し、バックエンドに送信 |
| バックエンドの関与 | なし(フロントエンドのみ) | 認可コードを access_token に交換 |
認可コードを access_token に交換(PKCEでセキュリティ強化) |
Googleの access_token を受け取り、アプリの access_token に変換 |
認可コードを access_token に交換し、アプリの access_token に変換 |
| アクセストークンの取得方法 | Googleの access_token を直接取得 |
Googleの access_token をサーバーで取得 |
Googleの access_token をサーバーで取得(PKCEで改ざん防止) |
Googleの access_token をサーバーで交換し、アプリ独自の access_token を発行 |
Googleの access_token をサーバーで交換し、アプリ独自の access_token を発行(PKCEでセキュリティ強化) |
| リフレッシュトークンの取得 | ❌ 取得不可 | ✅ 取得可能 | ✅ 取得可能 | ✅ 取得可能(アプリ側で発行) | ✅ 取得可能(アプリ側で発行) |
| セキュリティ | ❌ 低い(access_token がフロントエンドに露出) |
✅ 高い(アクセストークンはサーバー管理) | ✅ 最も高い(PKCEが認可コード横取りを防ぐ) | ⚠️ やや低い(Googleの access_token がフロントエンドに露出するが、アプリの access_token に変換できる) |
✅ 非常に高い(PKCE + Token Exchange で access_token の露出を防ぐ) |
| アクセストークンの露出 | フロントエンドに直接渡る(XSSリスクあり) | フロントエンドには渡らない(安全) | フロントエンドには渡らない(安全) | Googleの access_token がフロントエンドに渡るが、アプリの access_token に変換 |
Googleの access_token はフロントエンドに渡らず、アプリの access_token のみ使用 |
| 認可コード横取り攻撃のリスク | なし(認可コードを使わない) | あり(認可コードが盗まれると access_token を取得可能) |
なし(PKCEにより認可コード横取りを防ぐ) | なし(Googleの access_token を変換するため) |
なし(PKCE + Token Exchange により完全に保護) |
| ユーザーロール管理(RBAC) | ❌ Googleの access_token には含まれない |
✅ アプリの access_token に含められる |
✅ アプリの access_token に含められる |
✅ アプリの access_token に含められる |
✅ アプリの access_token に含められる |
| トークンの有効期限 | 短い(1時間以内で失効) |
refresh_token で長期間維持可能 |
refresh_token で長期間維持可能 |
refresh_token で長期間維持可能 |
refresh_token で長期間維持可能 |
| 適用例 | 簡単なアプリ・テスト環境(セキュリティが不要な場合) | フルスタックアプリ・企業向け(セキュリティが重要な場合) | モバイルアプリ・SPA・API認証が必要なアプリ(最も安全) | 社内システム・Googleログインを活用したいアプリ | 企業向け・セキュリティ重視のモバイルアプリ・SPA |
🔚 結論
- 最低限 → PKCE
- 社内利用 & Googleログインを活かす → Implicit Flow + Token Exchange
- 最もセキュア & APIと統合しやすい → PKCE + Token Exchange
エラー備忘録
1.
API実装にて、一向に解決しないundefinedエラー発生。エラー原因はDBスキーマ上のnotNullカラム×非同期処理。responseが返ってくるまでundefinedになる可能性があったのでif文で括り出す必要があった。非同期処理系は、全てif文でケアすることを心がけるべし
npm create-react-app my-appの代替手段
1. Vite
npm create vite@latest my-react-app --template react
react-serverという最近人気のフレームワークでも同様にviteを統合してテンプレートを作成することができる(参考)
2. Next.js
npx create-next-app@latest my-next-app
おまけ:esbuild, Parcel等
どちらもビルドツール。使う必要はなさそう
クラウドサービスを利用する際、DBと認証を別々にするメリット
1. 認証の独立性とセキュリティの強化
-
認証情報とデータを完全に分離できるため、セキュリティリスクを低減できる。
- もしDBが侵害されても、認証情報は別サービスにあるため影響を受けない。
- より高度なセキュリティ対策が可能(例: AWS CognitoやAuth0はMFA, IP制限, SAML対応)。
- コンプライアンス要件に対応しやすい(個人情報の保存場所を分ける)。
💡 ユースケース:
- ユーザー認証は AWS Cognito / Firebase Auth で管理し、DB にはユーザー情報の一部(UUID, 名前, メール)だけを保存する。
2. ベンダーロックインを防ぐ
-
認証をDBと分離すると、サービスの乗り換えが容易になる。
- 例えば、SupabaseをやめてAWSに移行するとき、DBだけを移行すれば済む。
- 逆に、Supabase Authを使っていると、DBと認証システムをセットで移行する必要があり大変。
💡 ユースケース:
- 最初は Supabase を使い、小規模プロジェクトを素早く開発。
- 将来的にスケールアップする際、DBを AWS RDS に移行し、認証は Auth0 に切り替える。
3. 認証の拡張性が向上
-
Auth.js, Firebase Auth, Cognito, Auth0 などは多機能で、カスタマイズ性が高い。
- ソーシャルログイン(Google, Apple, GitHub)を簡単に追加できる。
- MFA(Multi-Factor Authentication)やパスワードレス認証にも対応しやすい。
💡 ユースケース:
- ユーザー認証は Firebase Auth(Google, Appleログイン)を利用し、
- 社内管理者は AWS Cognito(SAML / OAuth2) を利用するなど、用途に応じて分ける。
4. 柔軟なスケーリング
-
認証とデータベースの負荷を分散できる。
- 例えば、認証システムは負荷が高くなりがち(ログイン・セッション管理・トークン発行)。
- これをDBとは別のサービスに任せることで、DBの負荷を減らせる。
💡 ユースケース:
- 大規模サービスで 認証は Auth0 / Firebase Auth に任せ、DBは AWS RDS に分散することで、
高トラフィックにも耐えられる構成を作る。
5. マイクロサービス化がしやすい
- 認証を 専用の認証サービス(Auth.js / Cognito / Firebase Auth) に分けると、複数のアプリ(Web, モバイル, API)で共通の認証を使いやすい。
- 認証サービスをAPI化することで、DBとは完全に分離して運用できる。
💡 ユースケース:
- フロントエンド(Next.js)・モバイルアプリ(React Native)・バックエンド(NestJS)の全てで 同じAuthサービス を使う。
6. DBの設計がシンプルになる
- 認証情報(パスワード、トークン管理)をDBに持たないので、DBのスキーマがシンプルになる。
- パスワードのハッシュ化、トークンの保存などを自前で管理しなくて済む。
💡 ユースケース:
- ユーザーテーブル(
users)はid, name, emailだけを保存し、
認証情報(パスワード, OAuthトークン)は Auth0 に任せる。
デメリット: 認証とDBを分けるデメリット
| デメリット | 解決策 |
|---|---|
| セットアップが複雑 | Firebase Auth / Auth.js など、設定が簡単な認証サービスを使う |
| コストが増える | 小規模なら Supabase で統合、大規模ならスケールを考えて分離 |
| データの一貫性管理が必要 | 認証サービスのユーザーIDをDBに保存し、外部キーとして管理 |
Firebaseで使えるデータベース一覧
| データベース | タイプ | 特徴 |
|---|---|---|
| Firestore | NoSQL (ドキュメント型) | スケーラブル・リアルタイム・オフライン対応 |
| Realtime Database | NoSQL (ツリー構造) | リアルタイム同期特化・軽量 |
| Cloud SQL | SQL (RDB) | PostgreSQL / MySQL 対応、リレーショナルデータ向き |
| BigQuery | SQL (分析向け) | ビッグデータ解析向け、SQL クエリ対応 |
Supabaseで使えるデータベース一覧
| データベース | タイプ | 特徴 |
|---|---|---|
| PostgreSQL(メインDB) | SQL (RDB) | Supabaseのコア。リレーショナルDBとして機能 |
| Storage(オブジェクトストレージ) | ファイルストレージ | 画像・動画・PDFなどの保存に最適 |
| Vector Search(AI向けDB) | ベクトルDB | 埋め込みベクトル検索(AIアプリ向け) |
npm周り
1. オプションなしnpm install
- project作成時にもしpackage.jsonがなければ、npm initで生成できる。
- package.jsonに従ってnode_modules が生成される。
- installしたパッケージ(コマンド)一覧をpackage-lock.jsonとして出力する
- もしnode_modulesがバグったら、package.jsonだけ残して、node_modules+package-lock.jsonは削除。再度npm installで生成すればいい
2. npm installのオプションについて
2.1 グローバルインストール
グローバルインストールすると自身の PC の環境ならどこでもインストールしたパッケージ(コマンド)が実行できる。
ただし、このオプションでインストールすると、package.json に記述されない。ゆえに、グローバルインストールされたパッケージは環境が異なると使用することができないので、普通はやらない。どうしても階層関係なく実行したいコマンドがあるとかならやっても良い
npm install -g <package>
2.2 ローカルインストール
ローカルインストールすると node_modules と同じディレクトリにある場合にパッケージ(コマンド)が実行できる。
package.json の dependencies(開発環境以外でも使用されるパッケージ) に追加するとき
npm install <package>
package.json の devDependencies(開発環境のみで使用されるパッケージ) に追加するとき
npm install --save-dev <package>
npm install -D <package>
3. おまけ
3.1 devDependenciesとdependenciesの違いが活きる時
npm install --production
このように --production のオプションをつけることによって開発環境でしか使わないパッケージを除外できる。本番環境デプロイ時に参照されることのないパッケージをインストールしなくて済むようになる。
ここがしっかりしていないと「devDependenciesのパッケージが足りない!」とか色々とエラーが出たりする。
3.2 package.json内の~, ^, *などの記号の意味
{
(省略)
"dependencies": {
"a": "3.2.1", //バージョン固定
"b": "~3.2.1", //マイナーバージョン(3.2)までを固定
"c": "^3.2.1", //メジャーバージョン(3)までを固定
"d": "*" //全てのバージョン(*)での挙動を保証
},
(省略)
}
→
| 記述方法 | key | value | 理解しやすい表記 | インストールするバージョン |
|---|---|---|---|---|
| バージョン固定 | a | 3.2.1 | 3.2.1 | 3.2.1 |
| チルダ指定 | b | ~3.2.1 | 3.2.x | 3.2.2 |
| キャレット指定 | c | ^3.2.1 | 3.x.x | 3.3.0 |
| latest | d | * | x.x.x | 4.0.0 |
Git周り
1. 複数のブランチを切る時
1.1 既存のブランチAの変更を前提に新しいブランチBを作りたい場合
普通にmainから切って、Aの変更をBでも作成すると、Aをmergeした時にBがコンフリクトを起こす。
そこで、
git checkout -b <Bの名前> //AからBを切る
作成したBに紐づくPRのマージ先を、B→mainではなくB→Aにする
1.2 既存のブランチの変更が要らない場合
この場合は別にコンフリクトは起きないので、
git checkout main
git checkout -b <Bの名前> //mainからBを切る
で普通にPRを作る
2. PRが大きくなり過ぎた時
git checkout main
git checkout -b hoge //差分のない状態から分割先ブランチを作る
git cherry-pick <分割したいコミットのcommitSHA> //commitSHAはgithubのcommit履歴から確認できる
git push
APIカスタムフック自動生成ライブラリ
最近流行っているもの
1. REST API → Orval
- openapi.ymlからカスタムフックを自動生成できる
- モックAPIを繋ぎ込める
2. GraphQL API → GraphQL
- operations(APIのクライアントスキーマを入れるディレクトリ), schema(APIのサーバースキーマを入れるディレクトリ)からcodegenでカスタムフックを自動生成できる
- REST APIと異なり、必要な情報だけをクエリで引っ張ってくるため、データ効率がいい
TypeScript/JavaScript では、モジュールから値を外部に公開する(他のファイルでインポートする)方法として、大きく 「default export」 と 「named export」 の2種類がある
1. export default と export const の根本的な違い
1.1 export default は “ひとつのモジュールにつき1つだけ設定できる” 特別なエクスポート
- 1つのモジュール内で
default exportは1回しか書けません - インポート時に、モジュール名を自由につけて受け取れる、またはエイリアスで呼び出せる
- 例:
// module.ts export default function doSomething() { ... } // import先 import run from "./module"; // 好きな名前にできる // ↑ doSomething じゃなくてもOK
1.2 export const (named export)は “名前付き” で何度でもエクスポートできる
- 1つのモジュールから複数の named export が可能
- インポート時には、export した名前をそのまま or as でリネームして受け取る
- 例:
// module.ts export const myValue = 42; export const myFunction = () => {...}; // import先 import { myValue, myFunction as func } from "./module";
2. 文法上の相違点
2.1 エクスポートの書き方
2.1.1 default export の書き方
-
宣言と同時
export default function doSomething() { ... } export default class MyClass { ... } -
宣言とは別に export する場合
function doSomething() { ... } export default doSomething;
2.1.2 named export の書き方
-
宣言と同時
export const myValue = 42; export function doSomething() { ... } export class MyClass { ... } -
宣言とは別に export する場合
const myValue = 42; function doSomething() { ... } export { myValue, doSomething };
2.2 インポートの書き方
2.2.1 default export をインポート
-
自由な名前で受け取れる(
runでもexecuteでも何でもOK)。import run from "./module"; - ファイルによっては default export しかない場合、
import anything from "...";の形で直感的に扱いやすいメリットがある。
2.2.2 named export をインポート
-
export 側の名前を指定して受け取る必要がある。
import { myValue, doSomething } from "./module"; - 名前を変えたい場合は
asを使う。import { myValue as value, doSomething as func } from "./module";
2.3 同居(両立)させることは可能か?
可能”
// module.ts
const MY_VALUE = 42;
function doSomething() { ... }
// default export
export default doSomething;
// named export
export { MY_VALUE };
2.4 “default” と “named” のどちらを選ぶべきか?
-
default export
- モジュールのエントリーポイントとなるような1つの機能やクラスを強調したいときに使われることが多い。
- 例:
utils.jsというユーティリティ集ではなく、「メインの機能はこれだよ!」と示すときなど。
-
named export
- 複数の定数、関数、クラスをまとめて公開したいとき。
- 例:
lib.ts内で複数の関数や定数をエクスポートして、それぞれ使いたいものだけインポートできるようにする。
-
両方使うケース
- ライブラリやフレームワークでは、メインの機能は default export、補助的な機能は named export として公開する設計が見られる
- 例:React では、
Reactオブジェクトが default export で、useState,useEffectなどは named export の形で公開されている
3. default, named論争の争点
両者とも「複数の要素を1ファイルに入れることは管理が難しくなり得る」という点では共通認識がある。しかし「そこをどう制御するか」にアプローチの違いがある。
3.1 ファイル設計思想
default派 : 「1ファイル=1モジュール(1つの責務)」が理想。複数要素を出さなくて済むよう、ファイルを積極的に分割する or 本当に関連性の強い要素はdefaultエクスポートにぶら下げる。
named派 : 「複数の要素をまとめたいニーズは多い。名前の衝突や可読性はツールやチームの命名規則で対処しやすい。default exportが自由すぎるのもリスク。」
3.2 エディタ補完/名前の一貫性
default派 : 「anonymous default exportを避ければ、補完や検出性は改善できる。むしろnamed exportを濫用すると、ファイルに何が入っているのか安易に探りにいく悪い習慣になる懸念もある。」
named派 : 「コード補完や自動インポートではnamed exportが直感的。defaultで名前を変える余地があることの方が混乱を生みやすい。」
3.3 タイポ・衝突への対策
default派 : ESLintで「ファイル名とdefault export名を合わせる」「命名規則を徹底する」などすれば問題ない。
named派 : そもそもexport名がインポート名と強制的に一致するnamed exportの方が分かりやすいし、実装漏れやタイポがエラーとして検知できる。
App router時代のCSS戦略について
参考記事:【App Router時代のNext.jsスタイリング戦略】CSS Modules vs Tailwind vs Zero-Runtime
propsの受け取り方
- 子コンポーネントに該当するファイル内で型エイリアス(またはインターフェース)を書くかどうか
- propsの受け取り方を分割代入するかどうか
の2軸ある。
コード例
1. 親コンポーネント
export type Todo = {
id: number;
title: string;
};
const todos: Todo[] = [...]
...
<TodoItem todos={todos}></TodoItem>
2. 子コンポーネント
//型エイリアスを書かない&propsを分割代入しない
export const TodoItem = (props: {todos:Todo[]}) => {
...
//型エイリアスを書かない&propsを分割代入する
export const TodoItem = ({ todos }: { todos: Todo[] }) => {
...
//型エイリアスを書く&propsを分割代入する⇨これが一番シンプルかつわかりやすくて良さそう
type Props = {
todos: Todo[];
};
export const TodoItem = ({ todos }: Props) => {
...
//型エイリアスを書く&propsを分割代入しない
type Props = {
todos: Todo[];
};
export const TodoItem = (props: Props) => {
...
Next.js(React)でSVG画像を扱う時の手段は大まかに3つで、
- インラインスタイル(要はハードコーディング)
- Image(img)タグを使ってsrcにパスを渡す
- svgrなどのライブラリを使ってモジュール化して使う
とあります。
基本2, 3になる。
2で実装するとしたら、
<Image
src="/pencil.svg"
className="hover:bg-[#B8B8B8] rounded-full"
alt="edit"
width={20}
height={20}
/>
こんな感じになります。これがいろんなページで使い回すようなsvgの場合、2の実装は長ったらしくてめんどいので、3を使ってコンポーネント化をするのが吉です。
import Pencil from '../../../../../public/pencil.svg';
<Pencil className='hover:bg-[#B8B8B8]/20 rounded-full' />
ただ、他で使いまわさないアイコンの場合は、ライブラリを追加してindex.d.tsみたいな設定ファイルを作るくらいなら、2でちゃちゃっと書くのが楽。
imgタグとImageタグの棲み分け
Reactのフックについて
フックとは何か
Reactのフック(Hook)は、React 16.8で導入された機能で、関数コンポーネントでステート(状態)やライフサイクルといったReactの機能を「フック」して使えるようにする特殊な関数です。名前は必ず「use」で始まります。
// 基本的なフックの例
const [count, setCount] = useState(0);
useEffect(() => { document.title = `${count}回クリックされました`; });
カスタムフックの作り方
- 「use」で始まる名前の関数を作る
- 必要であれば内部で他のフックを呼び出す
- 必要な値を返す
// カスタムフックの基本形
function useMyCustomHook(initialValue) {
const [value, setValue] = useState(initialValue);
useEffect(() => {
// 何らかの副作用
}, [value]);
const updateValue = (newValue) => {
setValue(newValue);
};
return { value, updateValue };
}
フックと通常の関数の違い
| フック | 通常の関数 |
|---|---|
| 名前が「use」で始まる | 命名に制約なし |
| Reactの状態にアクセス可能 | Reactの状態にアクセス不可 |
| コンポーネントまたは他のフック内でのみ使用可能 | どこでも使用可能 |
| 呼び出し順序が重要 | 呼び出し順序に制約なし |
| 条件付き呼び出し不可 | 条件付き呼び出し可能 |
| リアクティブ(依存データが変化すると再実行) | 非リアクティブ(明示的に呼び出す必要あり) |
フックを使う利点
1. コンポーネントロジックの再利用
異なるコンポーネント間で状態を持つロジックを簡単に再利用できます。
// 複数のコンポーネントで再利用可能
function ComponentA() {
const { value } = useMyCustomHook(0);
return <div>{value}</div>;
}
function ComponentB() {
const { value } = useMyCustomHook(10);
return <button>{value}</button>;
}
2. リアクティブな応答性
依存するデータが変更されると自動的に結果が更新されます。
// データが変化すると自動的に再計算される
function ProductPage() {
const { data } = useProductData(productId);
const isDiscounted = useIsProductDiscounted(data);
return isDiscounted ? <DiscountBadge /> : null;
}
3. コードの整理と関心の分離
関連する状態とロジックをひとつの場所にまとめられます。
// 以前のクラスコンポーネント(ロジックが分散)
class UserProfile extends React.Component {
componentDidMount() { this.fetchUserData(); }
componentDidUpdate(prevProps) { if (prevProps.userId !== this.props.userId) { this.fetchUserData(); } }
fetchUserData() { /* APIから取得 */ }
render() { return <div>{this.state.userData}</div>; }
}
// フックを使用(関心ごとにまとまっている)
function UserProfile({ userId }) {
const userData = useUserData(userId); // データ取得ロジックがカプセル化
return <div>{userData}</div>;
}
4. テストの容易さ
フックを独立してテストできます。またモックも提供しやすくなります。
// フックのテスト
test('useCounter increases count', () => {
const { result } = renderHook(() => useCounter());
act(() => {
result.current.increment();
});
expect(result.current.count).toBe(1);
});
hono勉強したい時はこれをみること
主なテスト
Static Test (静的テスト)
lintやtsなど、タイプミスや型エラーなどに関するチェック
Unit Test (単体テスト)
jestなど、コンポーネント・フック・関数がちゃんと動くかに関するチェック
Integration Test (結合テスト)
画面を実際に動かしてみて、それぞれの画面が要件定義に沿っているか確認するチェック
End to End Test (E2Eテスト)
システム全体が正しく動くかをチェック