ESP32のアセンブリコードを読み解く
はじめに
前回の記事ではESP32を対象に、C/C++からインライン・アセンブラを使用する手順を説明しました。今回はもう少し踏み込んで、アセンブリ言語の練習にお勧めの方法と、調べてもわかりづらい重要なポイントを説明していきます。
前提条件
-
XtensaコアのESP32シリーズ (ESP32/ESP32-S2/ESP32-S3) を使用していること。 -
ArduinoIDEまたはVSCode+PlatformIOでESP32用のプログラムを実行できること。 - C/C++をある程度読書きできること。
※ ESP32-C3などはXtensaコアではないため、本記事の対象から外れます。
アセンブリコードのサンプルを手に入れる
アセンブリ言語を書くためには、どんな命令が用意されているかを把握しておく必要があります。それには 前回の記事 の冒頭で入手をお勧めした Instruction Set Architecture (ISA) のPDFを読む必要がありますが、いきなり予備知識なしで全部読む…というのは現実的ではありません。
実際に動作するアセンブリ言語を使ったの作例を読み解く練習をするが一番だと思いますが、そうそう都合よく練習に適したアセンブリ言語の作例が見つかるものではないと思います。
そこで、C/C++ で書いたコードのコンパイル結果を見て、使用されている命令から調べていく方法を紹介します。
とても便利な Compiler Explorer を利用させて頂く
gccのコマンドラインオプションで-S filename.cのようにするとアセンブリ言語のソースコードが出力される…のですが、頻繁に使用するには少々面倒だと思います。
そこでお勧めしたいのが、 Compiler Explorer というWebサービスです。
早速アクセスして以下の手順を試してみましょう。

- ページ上部のドロップダウンで、
C++を選択する - その右隣のドロップダウンで
Xtensa ESP32 gccの一番新しいものを選択する
(ESP32-S2やESP32-S3の場合はそれぞれ環境にあったものを選択) - その右隣の
Compiler optionsの枠に最適化オプション-O3を入力する - ページ左側のテキスト入力枠に以下のソースコードを入力する
#include <stdint.h>
__attribute__ ((noinline,noclone))
int32_t func(int8_t a, int_fast8_t b)
{
a += 8;
b += 16;
return a * b;
}
int main(void)
{
int32_t x = 16;
int32_t y = 128;
return func(x, y);
}
すると右側のテキスト枠にコンパイル後のアセンブリ言語のソースコードが表示されます。
func(signed char, int):
entry sp, 32
addi.n a2, a2, 8
addi a3, a3, 16
sext a2, a2, 7
mull a2, a3, a2
retw.n
main:
entry sp, 32
movi a11, 0x80
movi.n a10, 0x10
call8 func(signed char, int)
mov.n a2, a10
retw.n
このように、C/C++で目的の処理を記述すれば、アセンブリ言語のソースコードがすぐに手に入ります。ここから処理内容を読み解くことで、必要な命令から効率よく調べられます。
コードを見比べてみる
さて、C/C++のコードと対応するアセンブリ言語のコードが手に入りました。
ふたつのコードを見比べながら読み解くことで、予備知識のない初めての方でも以下の点は推測できることと思います。
- 即値の加算には
addi命令が、変数の乗算にはmull命令が使われている。 - 変数への即値の代入には
movi命令が使われている。 - 関数の呼出しには
call8命令が、関数の終了にはretw.n命令が使われている。
しかし予備知識がない状態では、これ以上を読み解くことは難しいと思います。より深く読み解けるよう、不明点を解消していきましょう。
func(signed char, int): や main: の行は何か?
これはラベルと呼ばれる記述です。C/C++において、使用を避けられがちな gotoステートメントのジャンプ先の記述に用いられるラベル機能と同様のものです。
任意の文字列 + : (コロン)の記述でコード上の任意の位置を示すラベルを記述できます。コンパイル後のコードには関数の先頭部分を示すラベルが付与され、この後に説明するcall8命令などのジャンプ先アドレスの記述に利用されます。
命令名の末尾にある .n は何か?
ざっと全体を眺めると、addiとaddi.n、moviとmovi.nのように、名前の末尾に.nがあるものとないものがあることに気付くと思います。この.nはNarrowの略で、バイナリサイズの小さい命令になります。
-
.n無し = 3Byte 命令 -
.n有り = 2Byte 命令
Xtensaの命令セットは基本的にはどの命令も 3バイトですが、使用頻度の高い一部の命令にのみ 2バイト版が用意されています。どちらも同じ動作をしますが、.n有りの方を使用することで、コンパイル後のバイナリのサイズを削減する効果があります。コードを読み解く上では.nの有無は気にせず、同じ命令と見なして構いません。
関数の引数と戻り値はどうなっているのか?
今回の例には引数を受けて戻り値を返す関数呼出しが含まれています。出力されたソースコードを眺めると、呼出し元でa10とa11に引数を代入しているらしいこと、関数内ではa2とa3で引数を扱っているらしいこと、までは読み解けるかも知れません。しかし、どうしてそうなるのかは見当がつかないことと思いますので、順を追って説明していきます。
C/C++の関数と Xtensa のサブルーチン
C/C++の関数呼出しはXtensaではsubroutine (サブルーチン)と呼称され、以下のような決まりごとがあります。
- C/C++の関数呼出しは
call8命令によるサブルーチン呼出しが使用される - サブルーチンは先頭に必ず
entry命令を配置する - サブルーチンの終了は
retw命令を使用する - 引数は、呼出し側の
a10~a15とサブルーチン側のa2~a7で渡す - 戻り値は、サブルーチン側の
a2と呼出し側のa10で渡す
より深く理解するために、内部の仕組みを少し説明していきます。
前回の記事で、アドレスレジスタはa0~a15の16個ある、と簡単に説明しましたが、実は内部的には64個あるar特殊レジスタ群のうち、選ばれた16個の範囲が a0~a15 として機能しています。そして、call8命令 + entry命令が実行されると、対象範囲が8個分移動します。これにより、それまでa8~a15だったレジスタが、a0~a7へと番号が変わるのです。
以下のような状況を想像すると理解しやすいでしょう。
・64個のar特殊レジスタが並んでいる
・その手前に、レジスタ16個分が見える窓枠が置かれている。
・窓枠にはa0~a15の名札が付けられている。
・サブルーチンを呼出すと窓枠が8個分移動し、終了時に元の位置に戻る。
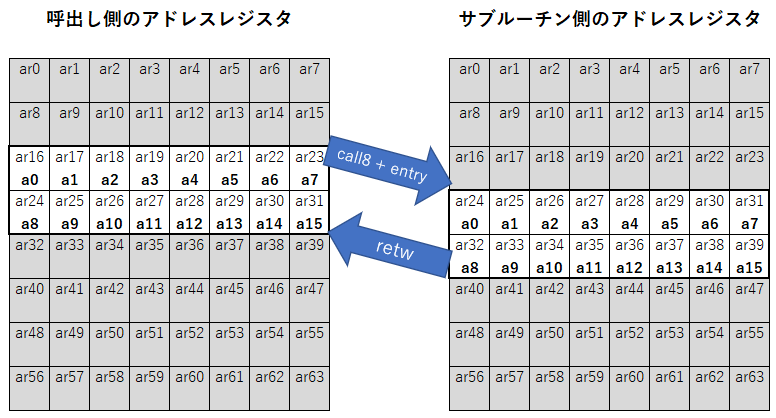
この仕組みは ISA の PDF では Windowed Registerと呼称されて記述されています。
サブルーチン呼出しと連動して窓枠だけが移動します。ar特殊レジスタの中身は特に変化しませんが、a0~a15の番号付けが変化するわけです。この結果、サブルーチン呼出し元のa8~a15の内容は、サブルーチン側ではa0~a7から読み取ることができるのです。
C/C++の関数呼出しはこの仕組みを利用して、引数の先頭から最大6個までをa10~a15に代入してからcall8を使用し、サブルーチン側のa2~a7で受け取ります。
サブルーチンの終了時はこの逆の動作です。retw命令が使用されると、ar特殊レジスタとアドレスレジスタの対応が元の位置に戻ります。C/C++の関数は、サブルーチン側でa2に戻り値を代入してからretwを使用し、呼出し側のa10で戻り値を受け取ります。
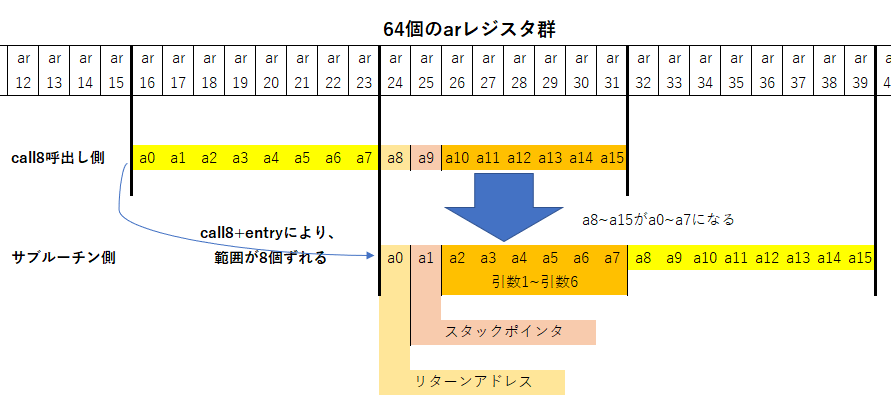
この仕組みにより、サブルーチンはa8~a15の8個のアドレスレジスタを呼出し元に影響を与えずに自由に使うことができます。
前回の記事で、アドレスレジスタを使う場合は「a15側から逆順に使用した方が良い」と簡単にお伝えした理由はこうした背景によります。a0~a7には既に役割が与えられていたり、呼出し元から受け取った引数が格納されている可能性があり、一時変数的に使用するならばa8~a15の方が自由度が高いと言えます。
リターンアドレスの役割 (呼出し側a8 / サブルーチン側a0)
call8命令でサブルーチンにジャンプした後、サブルーチン側のretw命令によって呼出し元へと戻ることができますが、どこに戻れば良いかを示すアドレス情報をreturn address リターンアドレスと呼び、a0レジスタから読み取る仕組みになっています。call8命令は、自身の次の命令を示すアドレスをa8に代入してからサブルーチンにジャンプする仕組みになっており、サブルーチン側はa0でこれを受け取ることができるのです。
スタックポインタの役割 (呼出し側a9 / サブルーチン側a1)
C/C++には、スタックと呼ばれるメモリ領域があり、関数のローカル変数の記録などに使用されている…ということをご存知かも知れません。このスタックメモリの所在を示すレジスタをスタックポインタと呼びます。entry命令を呼び出すと、指定されたバイト数だけスタックポインタの指し示すアドレスが進み、retw命令を呼び出すと元の位置に戻ります。
このスタックポインタを保持するレジスタはspレジスタなのですが、 spレジスタはa1レジスタと実体が同じ になっています。つまり、a1レジスタは常にスタックポインタとして使用されているため、他の用途に使用できません。
スタックメモリについての詳細については説明が長くなりますので、また別の機会としたいと思います。ここでは概要のみを説明します。
関数内で使用される一時変数が多い場合にスタックが使用される
今回のサンプルコードのようなシンプルな関数であれば、変数はすべてアドレスレジスタだけで処理でき、スタックメモリは出番がありませんが、変数の数が多くアドレスレジスタが足りない場合に、変数の内容をスタックメモリに一時保存することがあります。
関数の引数が7個以上ある場合にスタックが使用される
関数の引数は、6個目まではアドレスレジスタ経由で渡すことができますが、7個目から先は呼出し元でスタックメモリに記録しておき、サブルーチン側でスタックメモリから読出すことで受渡しをする仕組みになっています。
アドレスレジスタの一時保存のためにスタックが使用される
サブルーチンを呼び出すと、即座にa0~a3レジスタの内容がスタックメモリに記録されます。
また、a4~a7レジスタの内容も、必要に応じてスタックメモリに記録されます。
このため、特にスタックメモリを利用する予定のない関数であっても、先頭に配置されるentry命令には、少なくとも32バイトを確保するようになっています。
変数の型はどのように扱われているのか
今回の例では、関数func は引数が2つあり、それぞれ int8_t と int_fast8_t となっています。これらの型名に馴染みのない方もいるかと思いますので少々説明します。
-
#include <stdint.h>を記述すると使用できるようになります。 -
int8_t型は、ビット幅が8ビットの符号付き整数型です。
typedefにより、signed charとして扱われます。 -
int_fast8_t型は、ビット幅が少なくとも8ビットの符号付き整数型です。
typedefにより、intとして扱われます。
よって、関数func の引数1は signed char、引数2は int となります。
さて、xtensaのアドレスレジスタはすべて幅32ビットです。つまりC/C++の記述で8ビットや16ビットの変数を使用した場合であっても、コンパイルされた後のコードでは、すべて32ビットで取り扱うことになります。
8ビット符号付き整数型で表現できる値は -128~127 の範囲ですから、例えば 120 + 16 のような計算をすると、答えは 136 ではなく、桁溢れにより -120 になるべきです。
ですが32ビットレジスタで計算した場合は、桁溢れが起きませんから答えは 136 になってしまいます。
このままではC/C++のコードが意図した動作と違う結果になってしまいますから、コンパイラは計算処理の後に符号拡張という処理を追加します。
8ビット型を32ビット型に拡張する場合、ビット7の内容をビット8~ビット31に複製する動作になります。これによって32ビットレジスタでも8ビットの型を再現しているのです。
符号拡張は xtensaでは、sext命令(Sign Extendの略)を使用します。
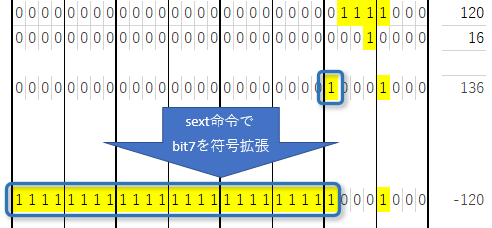
このようにxtensaではC/C++で8ビット型や16ビット型を使用しても、32ビットレジスタを用いて8ビット・16ビット型の演算結果を再現する処理が行われます。つまり32ビット型を使用したときと比べて処理速度が遅くなることがあるのです。
処理速度の低下を抑えつつ、クロスプラットフォーム向けのC/C++コードを記述したい場合には、int_fast8_t型のような処理系によってビット幅が変化する型を利用するのが良いでしょう。
アセンブリ言語のソースコードを解読してみる
ここまでで今回必要な知識は得られたと思いますので、改めてコンパイル元のコードと出力結果とを見比べていきます。まず最初に実行される関数 main から。
int main(void)
{
int32_t x = 16; // 変数 x は関数 func の第1引数として使用される。
int32_t y = 128; // 変数 y は関数 func の第2引数として使用される。
return func(x, y); // 関数 func の戻り値を、そのまま関数 main の戻り値とする。
}
main: // 関数 main のラベル
entry sp, 32 // 関数 の先頭は必ず entry 命令。
movi a11, 0x80 // a11 を変数yとして扱い、128を代入。
movi.n a10, 0x10 // a10 を変数xとして扱い、16を代入。
call8 func(signed char, int) // 関数 func へ サブルーチンジャンプ。
// 引数1は a10 (変数x)、引数2は a11 (変数y)
// 関数 func の戻り値は a10に代入されている。
mov.n a2, a10 // a2 = a10; (関数 func の戻り値を a2 に代入。)
retw.n // retw 命令で関数の呼出し元に戻る。
// このとき、a2 の内容が関数 main の戻り値となる。
C/C++のコードでは変数 xとyにそれぞれ16と128を代入して関数funcの引数として使用し、funcの戻り値をそのままreturnに渡しています。
即値の代入には movi命令 (Move Immediateの略)が使用されます。movi命令には続けて1つのアドレスレジスタと1つの即値の記述が必要で、指定された即値をそのままアドレスレジスタに代入します。
コンパイル後のコードでは、関数の呼出しの際にa10とa11の内容が引数として扱われますから、引数1となる変数 x の内容を a10 に、引数2となる変数 y の内容を a11 に代入するように最適化されています。
そしてcall8命令によってサブルーチンfuncを実行します。その戻り値はa10に入ります。この戻り値を関数mainの戻り値としてそのまま利用するため、mov命令でa10からa2に値を移したのち、retw命令で処理を終えています。
次は関数 func の内容です。
int32_t func(int8_t a, int_fast8_t b)
{
a += 8; // 変数 a に8加算。
b += 16; // 変数 b に16加算。
return a * b; // a * b の結果を返す。
}
func(signed char, int):
entry sp, 32 // 関数の先頭は必ず entry
// a2 は引数1 の変数 a の値が入っている
// a3 は引数2 の変数 b の値が入っている
addi.n a2, a2, 8 // a2 += 8; 変数 a に8加算
addi a3, a3, 16 // a3 += 16; 変数 b に16加算
sext a2, a2, 7 // 7ビット目を符号拡張してint8_t型を再現する。
mull a2, a3, a2 // a2 = a2*a3; 変数 a * b の内容を a2 に代入
retw.n // retw 命令で関数の呼出し元に戻る。
// このとき a2 の内容が関数 func の戻り値となる。
サブルーチン開始時点で a2は引数1、a3は引数2ですから、a2は変数a、a3は変数bと対応しています。
C/C++のコードでは変数 aとbそれぞれに即値 8と16をそれぞれ足しています。コンパイル後のコードではaddi 命令(Add Immediateの略)が使用されています。addi 命令には続けて2つのアドレスレジスタと1つの即値の記述が必要で、2つめのアドレスレジスタの値と即値を合算した値が、1つめのアドレスレジスタに代入されます。
変数aは符号付き8ビット型のため、a2に即値を加算したあとでsext命令で符号拡張処理が行われています。一方、変数bは符号付き32ビット型のため、a3に対してはsext命令は使用されていません。
a*bの乗算には mull命令(Multiply Lowの略)が使用されています。mull 命令には続けて3つのアドレスレジスタの記述が必要で、後ろ2つのアドレスレジスタの値を乗算した値が、1つめのアドレスレジスタに代入されます。今回の例では mull a2, a3, a2 ですから、a3とa2の乗算の結果がa2に代入されます。
最後にretw命令でサブルーチンを終了しますが、このときa2レジスタの内容が戻り値として扱われるため、コンパイラは直前のmull命令の演算結果の代入先としてa2を選ぶよう最適化をしています。
まとめ
以上、 C/C++のコードと、アセンブリ言語のソースコードとを比較して読み解く方法の紹介と、内部処理の仕組みについての説明でした。今回紹介した内容はアセンブリ言語を書く予定がなくとも、例えば少しでも速いC/C++を書きたい場面で、コードの最適化の手掛かりとして役立つと思います。同じ処理内容でも書き方を少し変えるだけでコンパイル結果が変わることは良くありますので、是非 色々と試行錯誤してみてください。
前回も今回も 説明を優先したためにサンプルコードの内容自体には実用性が皆無でしたから、次回は実用的な例をサンプルとして取り上げてみたいと思います。
Discussion