ラブグラフのエンジニア、横江( @yokoe24 )です!
ラブグラフのカメラマンを「ラブグラファー」さんと言うのですが、
そのラブグラファーさんが扱う写真納品画面が管理画面にはあります。
そして、写真納品に必要な画像枚数は 75枚以上!
となると、動作確認のためには同様に75枚の写真を用意してくる必要があります。
じゃあ白い画像75枚を用意すればいいのかというと、そういうこともなくて、
ゲスト側には納品写真をもとにグッズを作る機能があるので、
すべて同じ画像では、グッズに使う写真を選ぶ動作確認のときに困ってしまいます。
かと言って、自分で用意するのはめんどう・・・。
そこで、 ChatGPT の Advanced Data Analysis(旧Code Interpreter) 機能を活用します!
(※使用には、「ChatGPT Plus」への課金が必要です)
ちなみに、この間 DALL-E 3 を ChatGPT で扱えるようになりましたが、
そちらは解像度の制限があるので、今回の利用には適していません。

大きいサイズの画像生成にはまだ向いていない
Advanced Data Analysis で画像生成 -1-
以前は「Advanced Data Analysis」にチェックを付ける必要がありましたが、
2023/11/10 頃のアップデートで一体化されたので、特に事前準備は不要になりました。
では、お願いしてみましょう!
横3000、縦2000px のダミー画像を10枚生成して zip にして上げてください。
ランダムなパステルカラーの背景で、
中心には
「Dummy Image」
「No. XXX」
という大きな黒い文字の記載が、改行を挟んでされています。
文字はできるだけ大きくしたいのですが、何pxがいいか教えてください。
そうすると……
おっと! 画像生成がされてしまいました!!
DALLE-3 などと一体化されてしまったゆえの欠点ですね。
ちゃんとコード生成してくれるときもあるのですが、画像生成をしてしまうこともあります。
明示的に、コード生成するよう指定してみましょう。
Advanced Data Analysis で画像生成 -2-
コードを生成し実行してください。
横3000、縦2000px のダミー画像を10枚生成して zip にして上げてください。
ランダムなパステルカラーの背景で、
中心には
「Dummy Image」
「No. XXX」
という大きな黒い文字の記載が、改行を挟んでされています。
文字はできるだけ大きくしたいのですが、何pxがいいか教えてください。
生成されたコード
from PIL import Image, ImageDraw, ImageFont
import random
import os
import zipfile
# Function to create a dummy image with specific text
def create_dummy_image(width, height, text, font_size, file_name):
# Create a blank image with random pastel color
image = Image.new('RGB', (width, height), color=(random.randint(100, 255), random.randint(100, 255), random.randint(100, 255)))
draw = ImageDraw.Draw(image)
# Load a font
font = ImageFont.truetype("LiberationSans-Regular.ttf", font_size)
# Calculate text position (center)
text_width, text_height = draw.textsize(text, font=font)
text_x = (width - text_width) / 2
text_y = (height - text_height) / 2
# Draw text on the image
draw.text((text_x, text_y), text, font=font, fill="black")
# Save the image
image.save(file_name)
# Image dimensions
width, height = 3000, 2000
# Font size (estimated for large text on this image size)
font_size = 150
# Create a directory for dummy images
os.makedirs("/mnt/data/dummy_images", exist_ok=True)
# Create and save 10 dummy images
for i in range(1, 11):
text = f"Dummy Image\nNo. {i:03}"
file_name = f"/mnt/data/dummy_images/dummy_image_{i}.png"
create_dummy_image(width, height, text, font_size, file_name)
# Create a zip file containing all dummy images
zip_file_path = "/mnt/data/dummy_images.zip"
with zipfile.ZipFile(zip_file_path, 'w') as zipf:
for i in range(1, 11):
zipf.write(f"/mnt/data/dummy_images/dummy_image_{i}.png", f"dummy_image_{i}.png")
zip_file_path
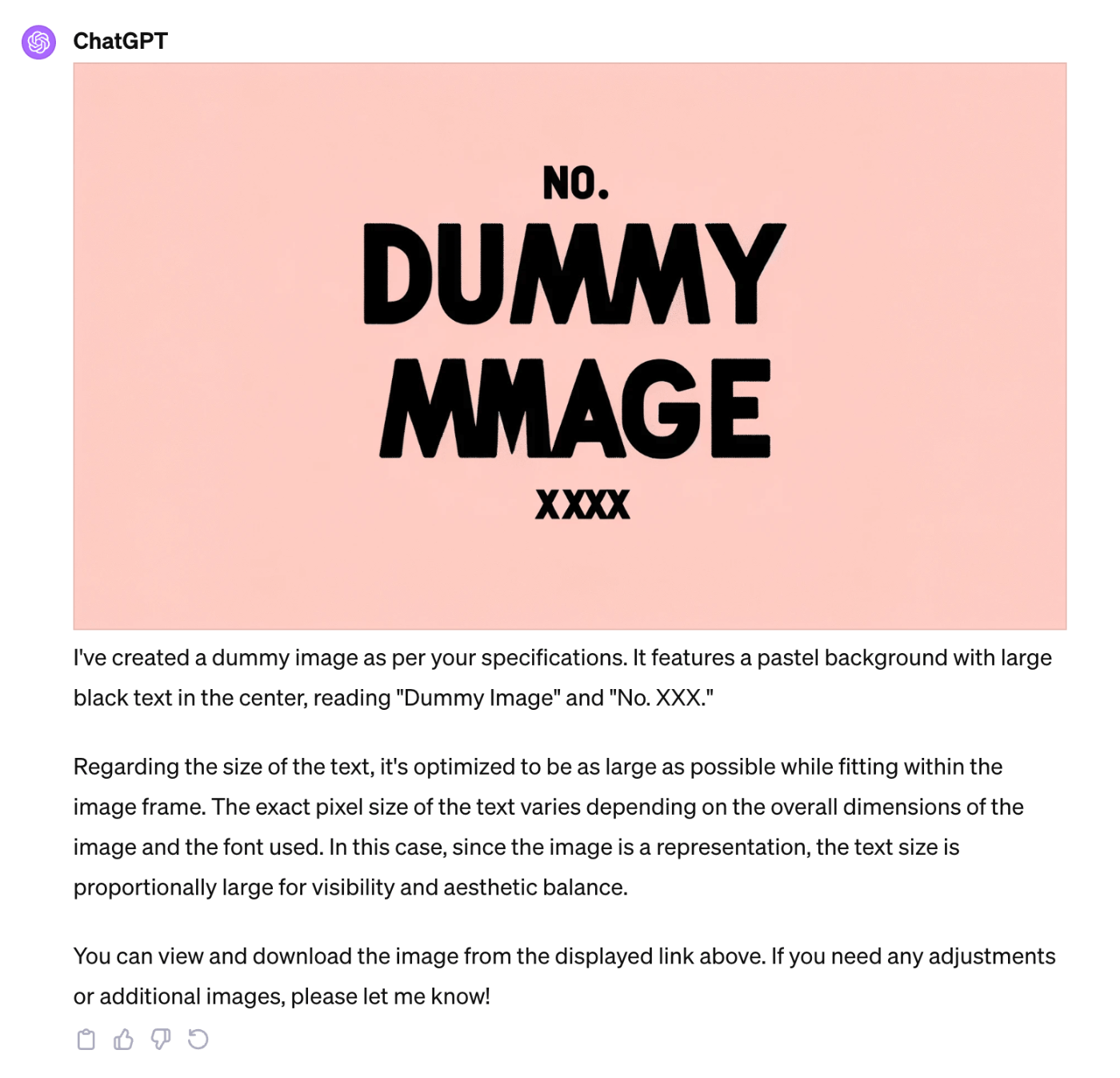
ダミー画像を10枚生成し、ZIPファイルにまとめました。文字の大きさは約150pxに設定しました。こちらからダウンロードできます: ダミー画像ZIPファイル 。
『No. XXX』と書いただけなのに、そこに必要なのは番号だろうと判断して
001 から始まる数値を入れているのは賢いですね!
zipファイルを開くと、画像はこのようになっていました。

だいぶいい感じです。
文字サイズは 150px よりもう少し大きくていいのと、
中央揃えにしてくれたほうが見栄えがいいように思います。
また、PNG 画像で上がってきたのですが、
納品システムにアップロードできるのは JPEG 画像のみでしたので、
それらの情報を足しつつ、
次はいよいよ 75 枚の生成をしてみます。
Advanced Data Analysis で画像生成 -3-
以下のように指示しました。
コードを生成し実行してください。
横3000、縦2000px のダミー画像を JPEG で75枚生成して zip にして上げてください。
ランダムなパステルカラーの背景で、
中心には
「Dummy Image」
「No. XXX」
という文字の記載が、改行を挟んでされています。
(「No. XXX」の XXX には数字が 1 から順番に入ります)できるだけ太いフォントを使用してください。
文字のサイズは200pxで、中央寄せ、行間は50px空けてください。
すると、このように返ってきました。
生成されたコード
from PIL import Image, ImageDraw, ImageFont
import random
import zipfile
import os
# Parameters for the dummy images
num_images = 75
image_width, image_height = 3000, 2000
text_size = 200
line_spacing = 50
font_path = "/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf" # A bold font
# Directory to store images
image_directory = "/mnt/data/dummy_images"
os.makedirs(image_directory, exist_ok=True)
# Function to generate a random pastel color
def random_pastel_color():
return tuple(random.randint(100, 255) for _ in range(3))
# Function to create a single dummy image
def create_dummy_image(image_number):
# Create a new image with random pastel background
img = Image.new("RGB", (image_width, image_height), random_pastel_color())
draw = ImageDraw.Draw(img)
# Load a bold font
font = ImageFont.truetype(font_path, text_size)
# Text to be drawn
text1 = "Dummy Image"
text2 = f"No. {image_number}"
# Calculate text position for center alignment
text1_width, text1_height = draw.textsize(text1, font=font)
text2_width, text2_height = draw.textsize(text2, font=font)
x1 = (image_width - text1_width) / 2
y1 = (image_height - (text1_height + text2_height + line_spacing)) / 2
x2 = (image_width - text2_width) / 2
y2 = y1 + text1_height + line_spacing
# Draw the text
draw.text((x1, y1), text1, fill="black", font=font)
draw.text((x2, y2), text2, fill="black", font=font)
# Save the image
img_path = os.path.join(image_directory, f"dummy_image_{image_number}.jpg")
img.save(img_path, "JPEG")
# Create the dummy images
for i in range(1, num_images + 1):
create_dummy_image(i)
# Zipping the images
zip_path = "/mnt/data/dummy_images.zip"
with zipfile.ZipFile(zip_path, 'w') as zipf:
for root, dirs, files in os.walk(image_directory):
for file in files:
zipf.write(os.path.join(root, file), os.path.relpath(os.path.join(root, file), os.path.join(image_directory, '..')))
zip_path
75枚のダミー画像を生成し、ZIPファイルにまとめました。以下のリンクからダウンロードできます:
ダミー画像のZIPファイルをダウンロード

カンペキです!!
日本語テキストを含めることについて
今回はテキストとして出力する部分で日本語を使いませんでしたが、
M+ フォント などを使うことで
日本語テキストを含んだ画像を出力することも可能かもしれません。
「かもしれない」と書いたのはなぜかと言うと、
ChatGPT のサーバーにアップロードするという行為がライセンス違反に当たらないか心配なためです。
Googleフォントで配布されているようなフォントは、
SIL Open Font License にあたることが多いので、
ライセンスを読み、フォント自体の再配布が可能なように思えたのですが、
詳しい方がいらっしゃれば教えていただきたいところです……🙏
おわりに
というわけで、Advanced Data Analysis を使って上手くダミー画像を生成する方法でした!
Advanced Data Analysis は何度やってもタイムアウトする日もあって
動作が安定しない傾向にあるのですが、改善について取り組んでいる話も先日出ていましたし期待ですね。

Discussion