📊
データ分析 python 基本のグラフ -ヒストグラム-
データ分析で使用するグラフを簡単にまとめていきます
python + google colaboratory で 実行しています
ヒストグラムとは
連続する数値データの分布を視覚化します。
例)
20人の年齢データがあるとします。
ビンの個数を5個に設定(=データを5コの範囲に分割する)し、データがどこに分布しているかをグラフで表示します。
import pandas as pd
data = {'Age': [15, 25, 29, 31, 33, 35, 38, 40, 42, 45, 47, 50, 52, 55, 60, 65, 70]}
df = pd.DataFrame(data)
df['Age'].plot.hist(bins=5)

いろいろな方法でヒストグラムを表示してみる
使用したデータ
使用したデータ
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/webshop_review_data.csv')
df
データの項目名
- お客様の性別
- お客様の年齢
- 購入タイプ
- 購入目的
- サイトの使いやすさ評価
- 配送の利便性評価
- 注文のしやすさ評価
- サイトのナビゲーション評価
- 商品の品質評価
- ショッピング体験の快適さ評価
- カスタマーサポートの評価
- サービス全般の評価
- 商品の梱包状態評価
- 総合満足度
pandas を使ってヒスとグラムを表示する
pandasのデータフレームのメソッド hist を使って、ヒストグラムを作成します。
pandas が 内部で matplotlib を使用しているため、明示的に matplotlib を import する必要がありません。
df['総合満足度'].hist(bins=10)

Matplotlib を使ってヒストグラムを表示する
グラフに日本語ラベルを表示できるようにするため japanize_matplotlib をインストールします
!pip install -q japanize_matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
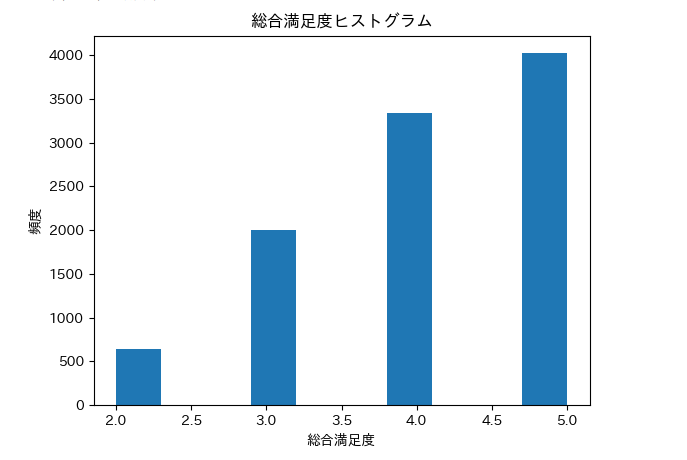
plt.hist(df['総合満足度'], bins = 10)
plt.title('総合満足度ヒストグラム')
plt.xlabel('総合満足度')
plt.ylabel('頻度')
seaborn を使ってヒストグラムを表示する
import seaborn as sns
sns.histplot(df['総合満足度'], bins=10)

ちなみに Seaborn 0.11.0 以降では sns.distplot() は非推奨となっているため、代わりに sns.histplot() の使用が推奨されています。
seaborn を使ってヒストグラムと分布図を同時に表示する
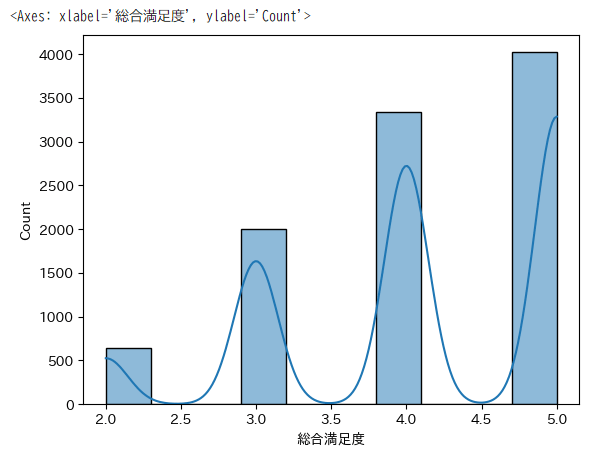
histplot の引数 kde に Trueを指定すると、カーネル密度推定(Kernel Density Estimate, KDE) が追加されます。
KDEはデータの分布を滑らかな曲線で表し、ヒストグラムの各ビンがどのようにデータ全体の分布に対応するかを視覚的に表示します。
import seaborn as sns
sns.histplot(df['総合満足度'], bins=10, kde=True)
Discussion