データ分析 python 基本のグラフ -棒グラフ-
データ分析で使用するグラフを簡単にまとめていきます
python + google colaboratory で 実行しています
棒グラフとは
カテゴリデータの値や頻度を視覚化します。
例)
こんな売上CSVがあったとします。
| Product | Sales |
|---|---|
| Product A | 500 |
| Product B | 300 |
| Product C | 800 |
| Product D | 150 |
| Product E | 600 |
import pandas as pd
data = {
'Product': ['Product A', 'Product B', 'Product C', 'Product D', 'Product E'],
'Sales': [500, 300, 800, 150, 600]
}
df = pd.DataFrame(data)
df.plot.bar(x='Product', y='Sales')
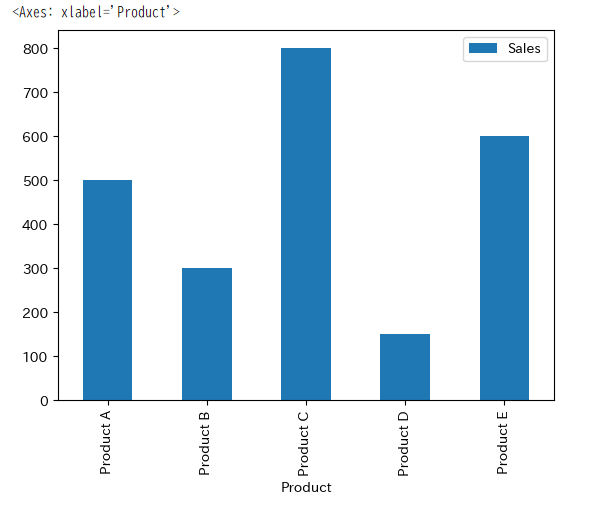
縦軸が売上、横軸は商品。
カテゴリ(商品)の値(売上)を棒で表現したグラフです。
いろいろな方法で棒グラフを表示してみる
まずはデータ読み込む
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/webshop_review_data.csv')
df
データの項目名
- お客様の性別
- お客様の年齢
- 購入タイプ
- 購入目的
- サイトの使いやすさ評価
- 配送の利便性評価
- 注文のしやすさ評価
- サイトのナビゲーション評価
- 商品の品質評価
- ショッピング体験の快適さ評価
- カスタマーサポートの評価
- サービス全般の評価
- 商品の梱包状態評価
- 総合満足度
Matplotlibの日本語対応
グラフに日本語ラベルを表示できるようにするため japanize_matplotlib をインストールします
# Matplotlib のグラフに日本語のタイトルやラベルを表示させるため
!pip install -q japanize_matplotlib
Matplotlibで1項目だけを棒グラフにする
総合満足度だけを棒グラフにしてみます
import matplotlib.pyplot as plt
import japanize_matplotlib
x= df['総合満足度'].value_counts().index
y= df['総合満足度'].value_counts().values
plt.bar(x, y)

Seabornで1項目だけを棒グラフにする
seaborn の barplot で表示してみます
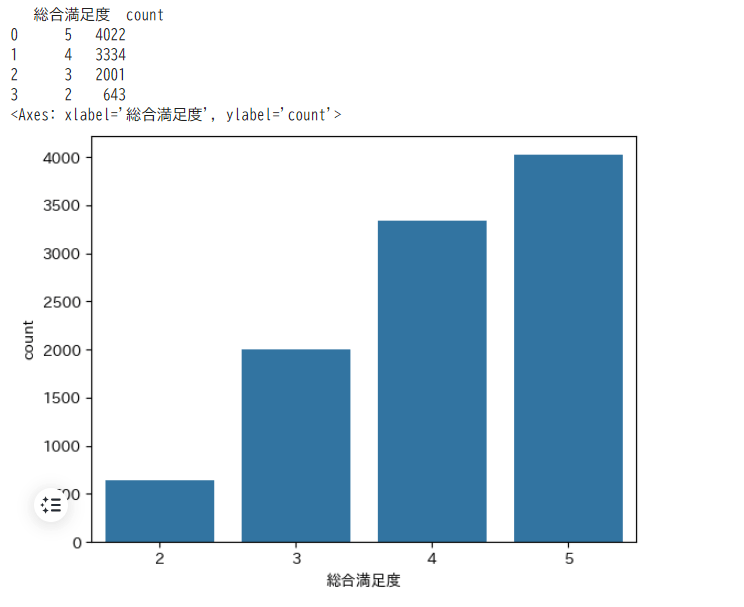
count_data = df['総合満足度'].value_counts().reset_index()
print(count_data)
sns.barplot(x='総合満足度', y='count', data=count_data)
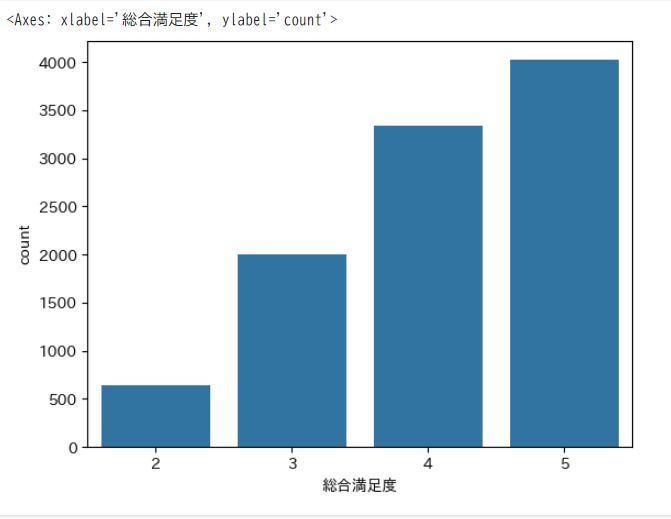
seaborn の countplot を使用すると、カテゴリごとの集計を自動で行ってくれます
import seaborn as sns
sns.countplot(x='総合満足度', data=df)
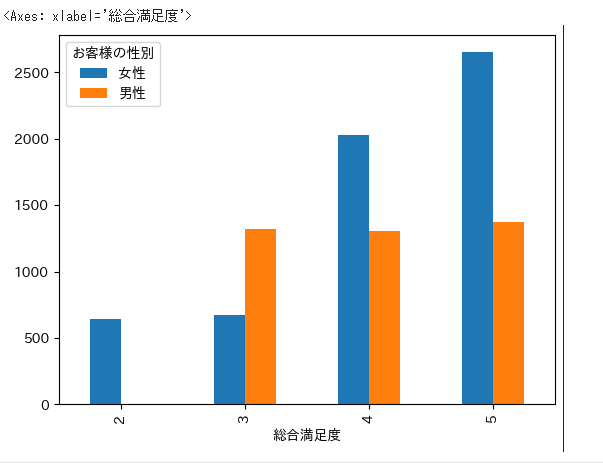
pandasでクロス集計した結果を棒グラフにする
総合満足度 と お客様の性別 で、クロス集計表を作成します。
crosstab = pd.crosstab(df['総合満足度'], df['お客様の性別'])
crosstab
| 総合満足度 | 女性 | 男性 |
|---|---|---|
| 2 | 643 | 0 |
| 3 | 677 | 1324 |
| 4 | 2030 | 1304 |
| 5 | 2650 | 1372 |
クロス集計表を棒グラフで表示してみます。
crosstab.plot.bar()
seabornを使用して棒グラフを作成する
seabornを使用して棒グラフを表示するとクロス集計する手間が省けます
import seaborn as sns
sns.countplot(x='満足度', hue='性別', data=df)

棒グラフのBinを調整する
棒グラフが細かすぎてわからない場合の対処法です。
スキル評価と睡眠時間を seaborn の countplot で棒グラフにしてみました。
ちょっと細かすぎてわかりづらいです・・・
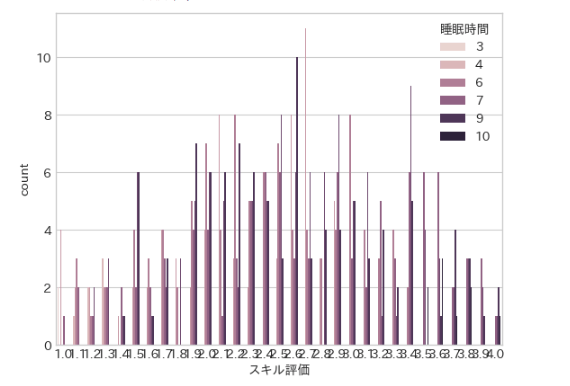
まずはデータを確認してみます
!pip install -q japanize_matplotlib
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
plt.style.use('seaborn-whitegrid')
plt.rcParams['font.family'] = 'IPAexGothic'
df = pd.read_csv('/content/drive/MyDrive/Skill_Evaluation_and_Related_Data.csv')
df.head(3)

スキル評価の重複しない値を確認してみます
df['スキル評価'].unique()

df['睡眠時間'].unique()

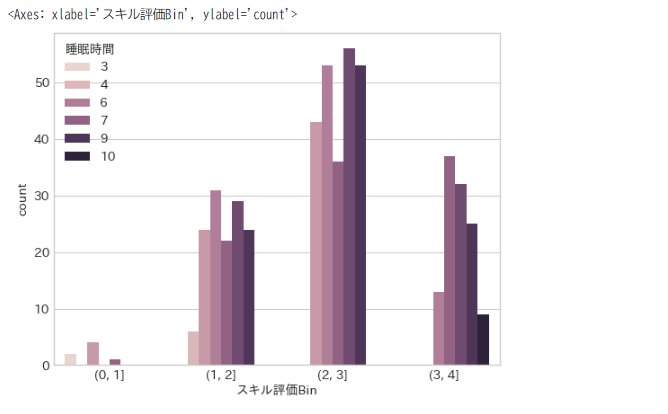
スキル評価で棒グラフを作成すると細かすぎるので、スキル評価の値をカテゴライズして見やすい棒グラフにしたいと思います。
pandas の cut メソッドを使用して、連続する数値データ区間(ビン)に分割してカテゴライズします。
cut メソッドを使用すると、データを指定された範囲に分けて、それぞれのデータがどの区間に属するかを判定します。
カテゴライズした値は「スキル評価Bin」列にセットします。
-
rangeメソッドは range(start, stop, step) 指定した範囲の値を生成します
start: 範囲の開始値(この値は含まれます)。省略するとデフォルトで 0 になります。
stop: 範囲の終了値(この値は含まれません)。必須です。
step: 値の増分(何ステップごとに値を増やすか)。省略するとデフォルトで 1 になります。 -
right=True
境界の右端を含む場合は True を指定します
# スキル評価を整数ごとのビンに分割する
# --0から4までの範囲を1単位ごとに区切る
# --right=Trueで境界の右端を含める
df['スキル評価Bin'] = pd.cut(df['スキル評価'], bins=range(0, 5, 1), right=True)
df.head()
スキル評価Bin列にカテゴリ値が追加されています。
(1,2]は 1は含まず 2は含む という意味になります。
| index | スキル評価 | キャリア年数 | 性別 | スキルアップ時間 | 睡眠時間 | 健康管理時間 | 人脈構築活動時間 | 週末スキルアップ時間 | 検収参加頻度 | カフェイン摂取量 | スキル評価Bin |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.3 | 18 | Female | 30 | 5 | 14 | 14 | 6 | 3 | 3 | (1, 2] |
| 1 | 2.6 | 23 | Female | 24 | 9 | 29 | 30 | 10 | 3 | 8 | (2, 3] |
| 2 | 3.6 | 23 | Female | 48 | 10 | 6 | 16 | 18 | 0 | 3 | (3, 4] |
| 3 | 1.9 | 22 | Male | 25 | 8 | 15 | 28 | 3 | 2 | 10 | (1, 2] |
| 4 | 2.9 | 24 | Male | 28 | 7 | 22 | 18 | 3 | 7 | 10 | (2, 3] |
x軸をスキル評価Binにして、棒グラフを表示します
sns.countplot(x='スキル評価Bin', hue='睡眠時間', data=df)
Discussion