
初めまして。
株式会社ログラスでAI基盤開発(と、野球)を担当しているエンジニアの神﨑( @kanfab1 )です。
今年の8月からログラスに参画して、現在はAI Agentの開発における技術課題の解消というミッションに日々挑戦しています。
今日は14日目ということで、1年を振り返りつつ本題に入ります。
2025年のハイライト
記憶に新しいとは思いますが、今年のMLBワールドシリーズは凄かったですね。激戦でした。
そんな中でも山本由伸投手の連投については、胸を打つものがありましたね。
ですが、そんなに球数投げて大丈夫か??と心配になった方も多かったはず。
MLBではオープナーなど、投手の中でも分業化が進む中で先発完投型として3年連続の沢村賞を思い出させるピッチングを見せてくれました。
※沢村栄治さんの背番号は14なので、ちょうど今日です。
そんな中、LLMに携わる人なら思ったはずです。
「そんな球数(トークン)投げたら、肩(コンテキスト)壊しちゃうよ!」
大切なことは全て野球が教えてくれます。
コンテキストエンジニアリングとしてのトークン圧縮の重要性
LLMをプロダクトに組み込む際、トークン消費量はコストとレイテンシーに直結する重要な課題です。
執筆時点[1]の最新版であるGPT-5.1の場合、入力トークンは100万トークンあたり$1.25、出力は$10です[2]。複雑なAgentシステムでは、1リクエストあたり数千〜数万トークンを消費することも珍しくありません。また、コンテキストウィンドウが大きくなるほど、推論速度も低下しUXを損ないます。
このような背景から、コンテキストエンジニアリングの一環として、いかにトークンを圧縮してLLMに情報を渡すかが重要になってきています。
圧縮アプローチの3つのレイヤー
トークン圧縮には、大きく分けて3つのアプローチがあります。

Gemini Canvasを使って作成
- フォーマットレベルの圧縮: データ構造の表現方法を変更(例: JSON → TOON)
- プロンプトレベルの圧縮: 重要でないトークンを削除(例: LLMLingua)
- 多次元レベルの圧縮: ベクトル埋め込みとして直接渡す(例: CompLLM)
例えば、2.プロンプトレベルの圧縮 では、Microsoftが発表したLLMLingua (Jiang et al., 2023)[3]という手法があります。
最大20倍の圧縮率が報告されており、条件が揃えば性能を維持したままトークン数を削減(最大1/4程度)できるとされています。
さらに、3.多次元レベルの圧縮では、CompLLM (Berton et al., 2025)[4]と呼ばれる手法で、長いコンテキストなどの特定条件下でベクトル空間で直接圧縮を行い、Time To First Token (TTFT) を4倍高速化できるとされています。
今回は、これらの中でもフォーマットレベルでの最適化に注目し、話題になっているTOON(Token-Oriented Object Notation)[5]を実際に検証していきます。
TOONとは何か
TOON (Token-Oriented Object Notation) の概要
TOONはLLM向けに最適化されたJSONの代替フォーマットです。
最大の特徴は、JSONとロスレス互換性を保ちながら、トークン数を30-60%削減できる可能性がある点にあります。
公式のベンチマーク結果[6]では以下のような効果が報告されています。
- 平均39.6%のトークン削減
- 正答率の向上: JSONの69.7%に対し、TOONは73.9%
- コスト削減: GPT-4価格で100万リクエストあたり$2,147の削減
- 人間可読性: YAMLのインデント構造とCSVのテーブル形式を組み合わせた設計
なぜトークンを削減できるのか
TOONの圧縮効果は、配列内のオブジェクト構造の冗長性に着目した設計から生まれます。
例えば、ユーザー情報の配列をJSONで表現すると、
{
"users": [
{"id": 1, "name": "Alice", "role": "admin"},
{"id": 2, "name": "Bob", "role": "user"},
{"id": 3, "name": "Charlie", "role": "user"}
]
}
同じデータをTOONで表現すると、
users[3]{id,name,role}:
1,Alice,admin
2,Bob,user
3,Charlie,user
といったように、キー名が繰り返し出現するJSONに対し、TOONは [3] で配列要素数を宣言し、{id,name,role} といった形で1行にまとめます。
実際のデータ行はカンマ区切りで並べるテーブル形式を採用しています。これにより、配列のサイズが大きいほど圧縮効果が高まります。
JSONとのロスレス互換性がもたらすメリット
次に重要なのは、TOONとJSONはロスレスで相互変換可能という点です。
つまり既存のAPIレスポンスがJSON形式で定義されている場合でも、下記の流れのように中間層を用いる事で透過的な適用が可能です。
- 既存APIからJSON形式でレスポンスを取得
- JSON形式からTOON形式へ変換してLLMのプロンプトに含める
- LLMの出力をTOONで受け取る
- 必要に応じてJSONに戻して既存システムのリクエストに含める
更にTypeScript、Python、Go、RustなどLLMアプリケーションの主要言語での実装が公開されており、既存コードへの組み込みも容易です。
import toon
# JSON → Toon変換
json_data = {"users": [...]}
toon_string = toon.dumps(json_data)
# Toon → JSON変換
parsed_data = toon.loads(toon_string)
TOONの透過的な導入戦略としてのMCP
ここまででTOONの技術的なメリットは理解できました。
では、実際にプロダクトへ導入する際の障壁について考えていきます。
LLMアプリケーション開発における周辺システムとの疎結合設計
従来のアプリケーション開発では、データフォーマットの変更は既存システム全体に影響を及ぼすため、大きな改修コストが伴いました。
しかし、LLMアプリケーション開発では設計思想が根本的に異なります。
現在のLLMアプリケーション開発では、Model Context Protocol (MCP) を介してツールを提供する設計が提唱されています。
既存APIを直接LLMに接続するのではなく、MCPサーバーが中間層として機能し、以下を実現します。
- 既存APIの仕様をLLMが理解できる形式でTool(ツール)として連携
- APIやプログラムなどの実行結果をLLMに返却
- 既存システムとLLMの疎結合を維持
この設計により、AIの自立性を一定担保したまま、決定論的なロジックを使い分けさせることが可能になっています。
その副次的効果ではありますが、既存APIは一切変更せず、MCPサーバー内でフォーマット変換などの最適化を透過的に実施することが可能なのです。
フォーマットレベルの圧縮導入の障壁が低い理由
MCPという変換層が前提のアーキテクチャだからこそ、TOONのようなフォーマットレベルの最適化を導入する障壁は極めて低くなります。
- 既存システムは無変更: PostgreSQLやREST APIなど、既存のデータソースはそのまま
-
MCPサーバー内で変換:
json.dumps()をtoon.dumps()に変更するだけ - LLMには最適化された形式: トークン効率を最大化した状態で情報を提供
むしろ、MCPサーバーを構築する際に、TOONのようなフォーマットレベルの最適化を行わない方が、トークン効率の改善機会を逃していると言えるでしょう。
つまり、フォーマットレベルの導入は「既存システムを大きく改修する必要がある特別な施策」ではなく、「LLMアプリケーションのベストプラクティスに沿った自然な最適化」なのです。
では、このアプローチが実際にどの程度の効果をもたらすのか、次のセクションで実証検証を通じて確認していきます。
実証検証:LangChain AgentでのTOON効果測定
理論上の効果は分かりました。
では、実際のAgentシステムでどの程度の効果があるのか検証してみます。
検証設計
今回は以下のような構成で検証を行いました。
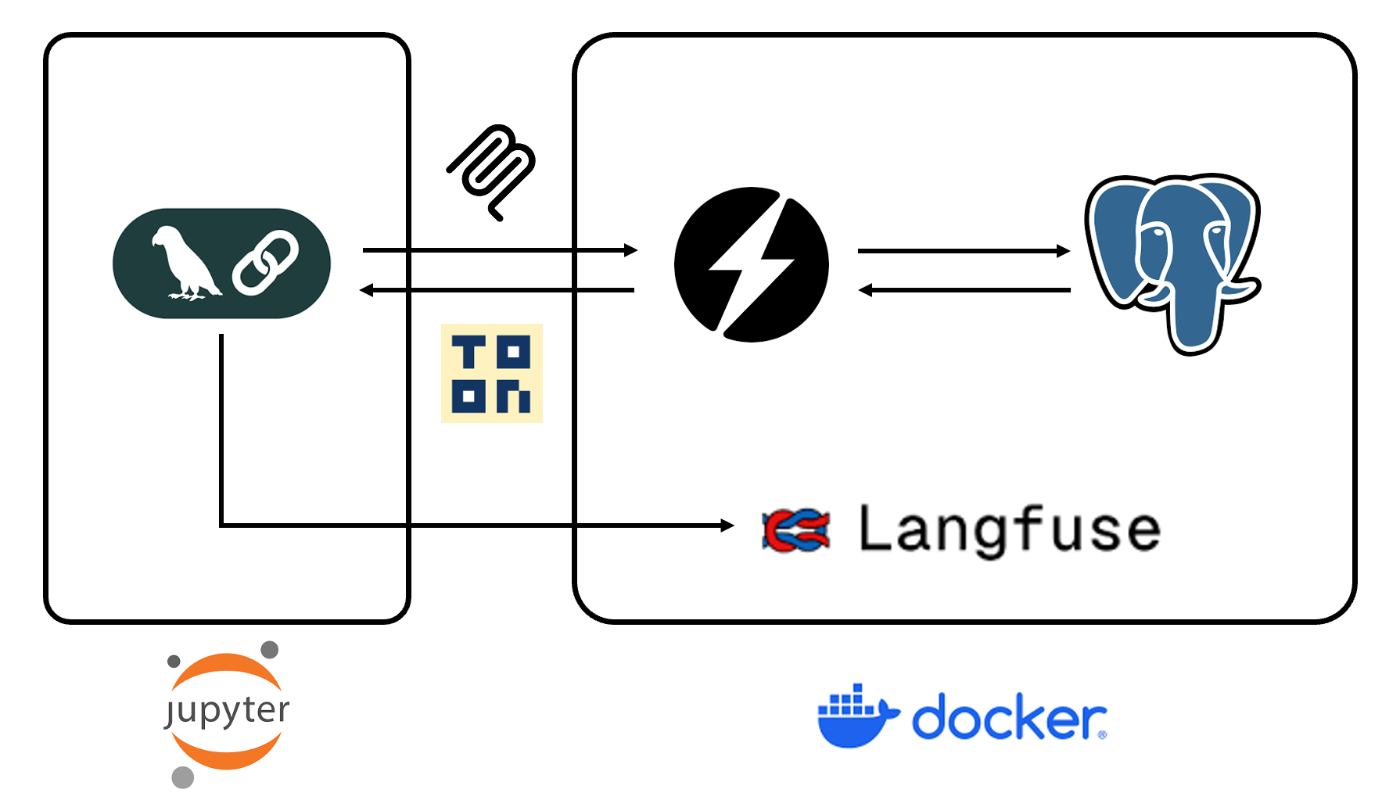
LangChain Agent (Jupyter Notebookで稼働)
↓ MCPクライアントとして接続
MCP Server (FastMCP)
↓ ツール提供
- list_tables (DB内に存在するテーブルの一覧を返す)
- get_table_metadata (テーブルの構造を返す)
- execute_query (SQLを実行してその結果を返す)
↓ クエリ実行
PostgreSQL Database
全体の実行をLangfuseで計測
前述した通り、MCPサーバーを経由することで、PostgreSQLへのアクセス層とは別で、フォーマット変換層を透過的に提供します。
※そして検証のための開発も最小限で済みます。
検証環境
- Agent: LangChain + Anthropic Claude Sonnet 4.5
- MCP Server: PostgreSQL接続、テーブルスキーマ取得機能を提供
- データソース: PostgreSQL ※検証用のダミーデータ
- 計測ツール: Langfuse(トークン使用量、レイテンシー、コスト、トレースを記録)
- 比較対象: 同一テーブルのスキーマをJSON形式とTOON形式で取得
実施ケース(サンプルタスク)
検証用に作成したPostgreSQLのダミーテーブルを使い、スキーマ情報を取得して自律的にテーブルデータを取得するというタスクを想定しました。
※下記のようなデータ構造を用いてます。
カラム名、データ型、制約など、テーブルの構造を表す情報は配列形式で返却されるため、TOONによる圧縮効果が期待できるケースであり、実際のプロダクトでも発生しやすいユースケースかと思います。
また、実際にデータの量によって圧縮効率が変わることや、データの理解能力に差が出ないことを確かめるために3種類のケースを想定しました。
A. 1件のレコードを取得するケース(少)
B. 10件程度のレコードを取得するケース(普)
C. 1000件程度のレコードを取得するケース(多)
検証結果
ケース毎に3回実行し、Langfuseで計測した平均値を用いて比較します。
圧縮効率はトークン量の削減率で確認し、効率化についてはツールの呼び出し回数で比較します。
そして処理能力はレイテンシーで確認するという簡易的なチェックで検証しました。
分析対象: 18トレース(各ケース3回実行)
組み合わせ: クエリ(A/B/C) × MCP(json/toon) × 試行(test03/04/05)
JSON形式とTOON形式でのトークン使用量、コスト、レイテンシーを比較しました。
JSON vs TOON 比較(平均値)
クエリA:1件のレコード取得
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 12,521 | 11,736 | 6.3%削減 |
| 出力トークン数 | 479 | 404 | 15.6%削減 |
| 合計コスト(推定) | $0.0447 | $0.0413 | 7.8%削減 |
| ツール呼び出し回数 | 2.7 | 2.7 | 変化なし |
| 平均レイテンシー | 34.73s | 36.67s | 5.6%悪化 |
クエリB:10件のレコード取得
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 23,346 | 26,138 | 12.0%増加 |
| 出力トークン数 | 1,115 | 1,082 | 3.0%削減 |
| 合計コスト(推定) | $0.0868 | $0.0946 | 9.1%増加 |
| ツール呼び出し回数 | 4.7 | 4.3 | 8.5%削減 |
| 平均レイテンシー | 53.31s | 52.45s | 1.6%改善 |
クエリC:1000件のレコード取得
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 130,588 | 105,929 | 18.9%削減 |
| 出力トークン数 | 1,158 | 1,373 | 18.5%増加 |
| 合計コスト(推定) | $0.4091 | $0.3384 | 17.3%削減 |
| ツール呼び出し回数 | 4.0 | 5.0 | 25.0%増加 |
| 平均レイテンシー | 64.27s | 61.94s | 3.6%改善 |
JSON vs TOON 比較(最大効果のケース)
試行間でばらつきがあったため、JSONで最もトークンを使った試行とTOONで最も使わなかった試行を比較し、最大効果を追加で検証しました。
クエリA:1件のレコード取得
JSON: test05(最大トークン) vs TOON: test03(最小トークン)
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 12,566 | 10,305 | 18.0%削減 |
| 出力トークン数 | 534 | 372 | 30.3%削減 |
| 合計コスト(推定) | $0.0457 | $0.0365 | 20.2%削減 |
| ツール呼び出し回数 | 3 | 2 | 33.3%削減 |
| レイテンシー | 71.01s | 17.69s | 75.1%改善 |
クエリB:10件のレコード取得
JSON: test04(最大トークン) vs TOON: test03(最小トークン)
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 24,342 | 16,636 | 31.7%削減 |
| 出力トークン数 | 946 | 806 | 14.8%削減 |
| 合計コスト(推定) | $0.0872 | $0.0620 | 28.9%削減 |
| ツール呼び出し回数 | 5 | 2 | 60.0%削減 |
| レイテンシー | 27.45s | 25.83s | 5.9%改善 |
クエリC:1000件のレコード取得
JSON: test04(最大トークン) vs TOON: test03(最小トークン)
| 指標 | JSON | TOON | 削減率 |
|---|---|---|---|
| 入力トークン数 | 135,003 | 75,579 | 44.0%削減 |
| 出力トークン数 | 1,149 | 920 | 19.9%削減 |
| 合計コスト(推定) | $0.4222 | $0.2405 | 43.0%削減 |
| ツール呼び出し回数 | 3 | 2 | 33.3%削減 |
| レイテンシー | 34.94s | 31.35s | 10.3%改善 |
検証結果の考察
1. データ量と圧縮効果の相関
今回の検証では、データ量によってTOONの効果が大きく異なるという結果になりました。
- クエリA(1件): 平均6.3%削減 → 効果は限定的
- クエリB(10件): 平均12.0%増加 → 逆効果
- クエリC(1000件): 平均18.9%削減、最大44.0%削減 → 明確な効果
特に注目すべきは、中規模データ(10件)で逆効果が出た点です。
これは実務での導入判断において極めて重要な知見です。
2. 中規模データで逆効果となったケースの分析
クエリB(10件)でTOONが悪化した主な原因を分析しました。
トークン増加の要因:
- 入力トークンが12.0%増加(23,346 → 26,138)
- コストも9.1%増加($0.0868 → $0.0946)
原因の特定:
個別のトレースを確認したところ、TOON使用時にツール呼び出しが増える試行がありました。(test04: 6回 vs JSON平均: 4.7回)。
検証に使用したテーブル(検証用ダミーデータ)は循環参照する構造で、LLMが「テーブル名だけでは判断できない」と判断し、個別テーブルの情報を追加収集する動きを見せました。
この追加のツール呼び出しがトークン増加の主因でした。
LLMの非決定性:
temperature=0に設定しても、試行ごとに推論パスが変わる非決定性が確認されました。これにより、同じ入力でもツール選択が異なり、結果に大きなばらつきが生じます。
3. 大規模データでの安定した効果
一方、クエリC(1000件)では、公式ベンチマークを上回る効果が確認されました。
- 平均18.9%削減(入力トークン: 130,588 → 105,929)
- 最大44.0%削減(最適ケース: 135,003 → 75,579)
- コスト17.3%削減(平均)、43.0%削減(最大)
公式ベンチマーク(平均39.6%)と平均値に乖離がある理由は、
- 測定範囲: 公式は入力データのみ、今回はAgent全体のトークン消費
- タスクの性質: 公式は純粋なフォーマット変換、今回はツール呼び出しを含むAgent実行
実務では後者のような環境が一般的であり、実際の削減効果は公式値より控えめに見積もるべきです。ただし、最適条件下では公式値を超える効果も十分に期待できます。
4. 実務への示唆
- 大規模データで効果が出やすい: 100件以上のレコードを返すエンドポイントから優先導入
- 中小規模データでは慎重に: 10〜100件では効果が不安定、必ず計測して判断
- MCPツール設計が重要: ツールの粒度や説明文がLLMの選択に影響し、結果を左右する
- A/Bテスト必須: 試行ごとのばらつきが大きいため、複数回の計測が不可欠
まとめ:トークン圧縮は投球フォームの最適化
話は冒頭に戻りますが、山本由伸投手の連投を支えたのは、無駄のない投球フォームでした。
同様に、コンテキストを破壊しないためには、無駄のないトークン利用が不可欠です。
検証の結果、TOONは、実用的なフォーマットレベルの圧縮手法であると言えます。
- 最大44%のトークン削減を実測で確認(1000件データ、最適ケース)
- 平均でも大規模データ(1000件)で18.9%の削減を達成
- JSON互換性により、段階的な導入が可能
- 配列データが多いユースケース(100件以上)で特に効果的
- Langfuseなどの計測ツールと組み合わせて効果を可視化
ただし、万能ではありません。小規模データ(10件以下)では効果が不安定で、逆にトークンが増えるケースも確認されました。
いつだって山本由伸投手が投げれば良いというわけではないのです。
重要なのは、ベンチ(運用監視者) が 選手(LLMアプリ) の状態を可視化して、パフォーマンスを最大にするよう適材適所の ブルペンマネジメント(LLM Ops) をしていく事なのです。
実践に向けて
今回の検証を通じて、TOON(フォーマットレベルの圧縮)を実際のプロダクトに導入する際は、以下のステップが良いと考えました。
- 計測から始める: Langfuseなどで現状のトークン消費を可視化し、ボトルネックを特定
- 小さく始める: 配列データを多く返す高頻度エンドポイントから試験導入
- 効果を検証: A/Bテストでトークン削減率、精度、レイテンシーを確認
- 段階的に展開: 効果が確認できたツールから順次Toon化を進める
MCPサーバーでの透過的な実装であれば、Tool毎に対応も可能です。
ですが、本当に大切なのはLLM Opsを実現する基盤(Langfuse)が整っていることです。
LLMをプロダクトに組み込む私たちは、常に非決定論による挙動の変化を把握しておく必要があります。
その挙動の変化こそが決定論と非決定論の境界であり、そこの設計こそがLLMアプリを設計するという事に他ならないと思います。
その境界で無駄なトークンを消費しないよう、フォーマットレベルの圧縮アプローチを試す価値は十分にあるでしょう。
来シーズンも日本人選手の活躍を楽しみにしつつ、私たちも効率的なLLMシステムの運用開発を目指していきましょう。
参考文献
TOONフォーマット
コンテキストエンジニアリング・プロンプト圧縮
- Microsoft LLMLingua
- LLMLingua公式サイト
- CompLLM: Compression for Long Context Q&A
- A Survey of Context Engineering for LLMs
- Anthropic: Effective Context Engineering
LangChain + Langfuse
-
2025年12月時点 ↩︎
-
OpenAI Pricing :(https://platform.openai.com/docs/pricing) ↩︎
-
Jiang et al., "LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models", arXiv:2310.05736 (2023). https://arxiv.org/abs/2310.05736 ↩︎
-
Berton et al., "CompLLM: Compression for Long Context Q&A", arXiv:2509.19228 (2025). https://arxiv.org/abs/2509.19228 ↩︎
-
TOON公式リポジトリ: https://github.com/toon-format/toon ↩︎
-
TOON ベンチマーク :https://github.com/toon-format/toon?tab=readme-ov-file#benchmarks) ↩︎
-
Introducing the Model Context Protocol : https://www.anthropic.com/news/model-context-protocol ↩︎

Discussion