はじめに
はじめまして、2024 年 4 月にログラスにジョインしたエンジニアの石畑です。
まだまだドメインやシステムについて学んでいる最中なのですが、その中でアラート監視・運用周りをより良くできそうだったので、試行錯誤したことをまとめたいと思います。
どんな課題があったのか?
ログラスではフロントエンドからバックエンド、インフラに至る全てのログ・メトリクスが Datadog に集約され、横断的に分析・監視できる仕組みが整っています。アラートも Datadog でモニタリングを作成し、「Slack に通知 → ローテションのオンコール担当が対応」という体制が作れています。
しかし、歴史的に積み重なったモニタリングが過剰にアラート通知を行い、「(対応不要なため)一部反応されず、無視されている」状況でした。
現時点では大きな問題ではありませんが、プロダクトも組織も急成長しており、今後運用の負荷も増加していくと思うので、「オオカミ少年になっているアラート通知」を削除するために動き出しました。
不要なアラートとは
そもそも不要なアラートとは何なんでしょうか?入門 監視でアラートについて以下のような説明がされています。
アラートについて話す時、コンテキストによって 2 つの意味を使い分けている人が多いことに気が付きました。
誰かを叩き起こすためのアラート
緊急の対応が求められ、でなければシステムがダウンしてしまうものです。電話、テキストメッセージ、アラームなどの方法で送られます。例えば、全 Web サーバーがダウンした、メインサイトの疎通が取れないなどのケースです。
参考情報としてのアラート
すぐに対応する必要はありませんが、アラートが来たことは誰かが確認すべきものです。例えば、夜間バックアップジョブが失敗したというケースです。
私たちの定義では、後者のアラートは事実上アラートではなく、単なるメッセージです。
アラートは、アラートを受け取った人に緊急性があり、すぐに対応する必要があることを認識させるためのものです。
引用 : 『入門 監視―モダンなモニタリングのためのデザインパターン』(Mike Julian 著, O’Reilly Japan, 2019, p36)
私もこの定義に則り、「緊急性があり、直ちに調査・対応が必要な通知」以外は不要なアラートとして、削除していきます。
不要なアラートを特定する
さて、このように定義しても現実「緊急性の高い通知」を特定するのは簡単ではありません。明らかなノイズを除くと、通知・対応コストと取りこぼしリスクがトレードオフになり、「念のため通知しておこう」となりがちです。また、まだ自分の機能の知識は浅く、さらに通知は月に数百件ほどあったので、特定は困難でした。
そこで、以下の手順を踏んで改善策を決定していきました。
- 直近 2 ヶ月のアラートの分析
- Datadog の Event 分類と件数出し
- Slack でのリプライ・リアクションの有無を取得
- (アラート通知される)エラーのパターン分類・緊急度の有無を分析
- 改善案の作成
- 各開発チームの有識者と議論・対応の決定
直近 2 ヶ月のアラートの分析
アラート分析で行ったことを簡単に見ていきます。
Datadog の Event 分類と件数出し
Datadog のアラートは全て Event として記録され、Event Management で確認することができます。これで過去に発生したアラートの種別や件数が確認できます。
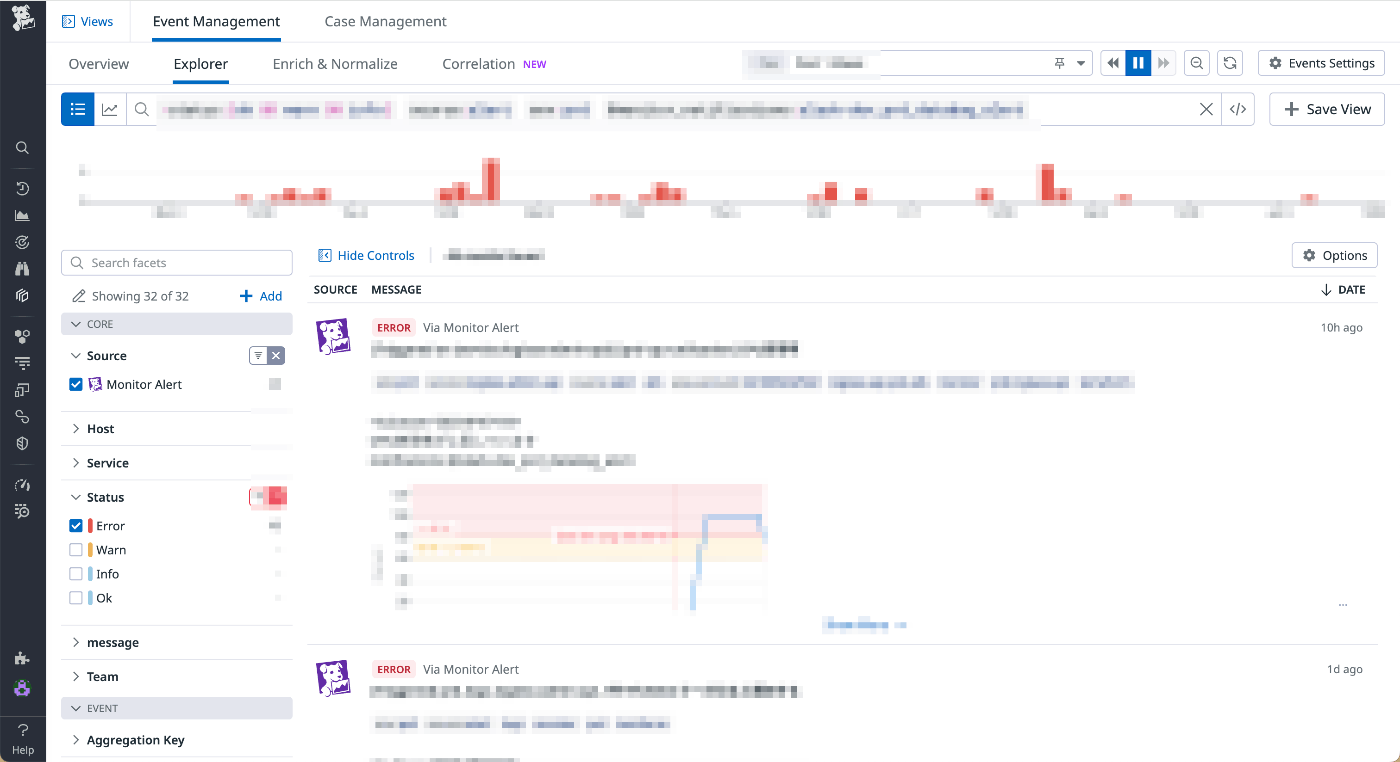
ここからサービスやアラート内容などで分類したダッシュボードを作成し、通知件数が多いアラートを特定しました。
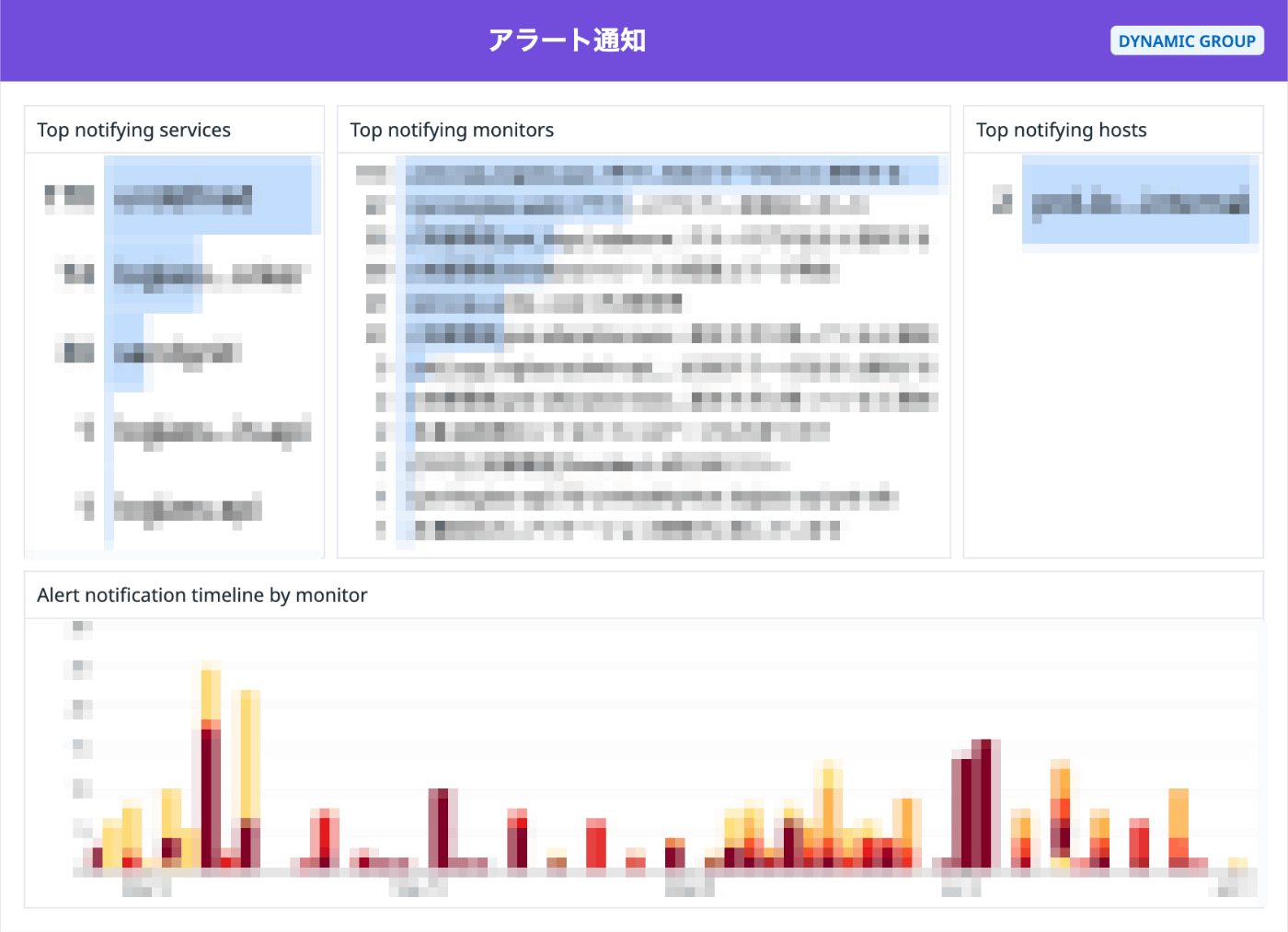
Slack でのリプライ・リアクションの有無を取得
アラートは Slack にポストされ、原則として「そのスレッドで担当者が対応を開始し、コミュニケーションを取る」という運用を行っているため、対応されたアラートには Slack でリプライがあります。
そこで、Slack API で直近 2 ヶ月の全てのアラート内容、リプライ数、リアクション有無を取得しました。これらは conversations.history で全て取得出来ます。この API で特定チャンネルの全てのポストを取得できるんですが、一部メンバーの会話や Datadog 以外からのアラート通知、メッセージ形式が違うものもあったので、アラート内容を取得するのはやや手間でした。API レスポンスの subtype や user で目的のポストを絞り込みました。
エラーのパターン分類・緊急度の有無を分析
エラーログをアラート通知しているケースも存在し、これが通知数を増加させている一番の要因となっていました。この通知は、対応不要なエラーから重要なエラーまで、玉石混淆なアラートとなっていたため、0, 1 で不要なアラートとは判断できず、エラーパターン毎に分析が必要でした。
その時に便利だったのが Datadog Logs の Pattern ビューです。マッチするログをサンプリングして、エラーメッセージに基づいて適度な粒度でグルーピングしてくれます。
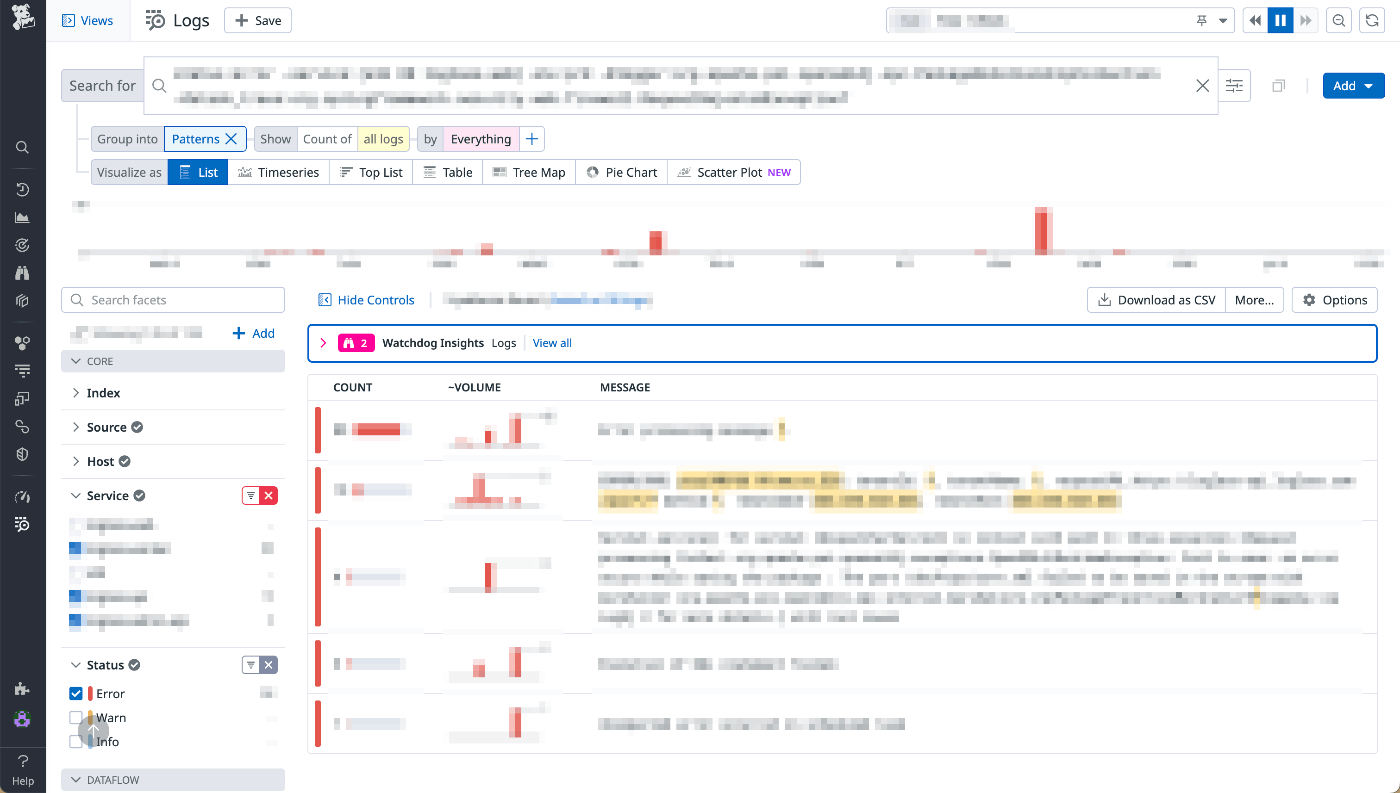
ここから通知数の多いエラーを特定し、本当に必要なエラーログか? 緊急度はどうか? など、分析を行いました。
以上のことを行い、ノイズの多い通知の特定や緊急度、適切な通知方法(即時・日次、個別・グルーピングなど)を検討し、改善案を作成しました。
各開発チームの有識者と議論・対応の決定
そして、改善案を作成したら、最後に最も大切な工程である、有識者との議論を行います。
ここまで行うと「あーこれはよく出る対応しなくていいやつね」と、だいぶアラートについて詳しくなっていました。コードも読んで問題ないことを確認していたりもします。
しかし、それでも一人で勝手に決める事はできません。アラートが追加された重要な歴史的なできごとがあるかも知れないですし、緊急ではなくともここから知見を得ている人もいるかも知れません。通知は人のためにするものであり、運用しているメンバーが重要だと考えているならば重要な通知です。
本当は全員と議論したいところですが、以下のように組織も大きくなり難しいので、
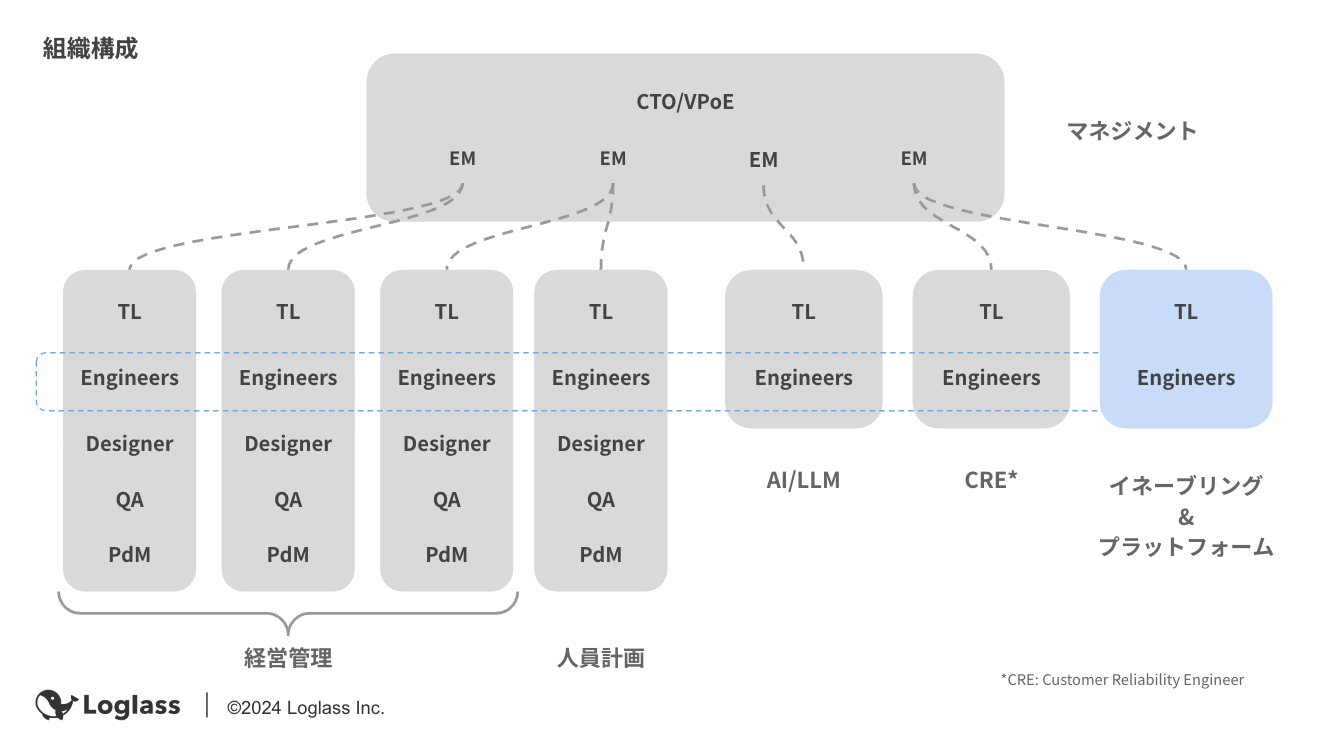
各チームの代表者と議論を行い、事前の分析結果を基に以下のような問いに答えていきました。
- ◯◯ は消せる通知か?
- 消す場合
- モニター自体を止めるか?
- 自動化などの根本対応を行うか?
- モニター方法を変えるか?
- 消さない場合
- どのように反応できていない状況を改善するか?
合意したものを対応策として実施していきます。
対応例
アラートを消す取り組みの一つとして、ダッシュボードの作成を行いました。
即時対応は必要ないけど、ウォッチしておきたいモニターやエラーログなどを、アラート通知から消す代わりにダッシュボードで見ていきます。
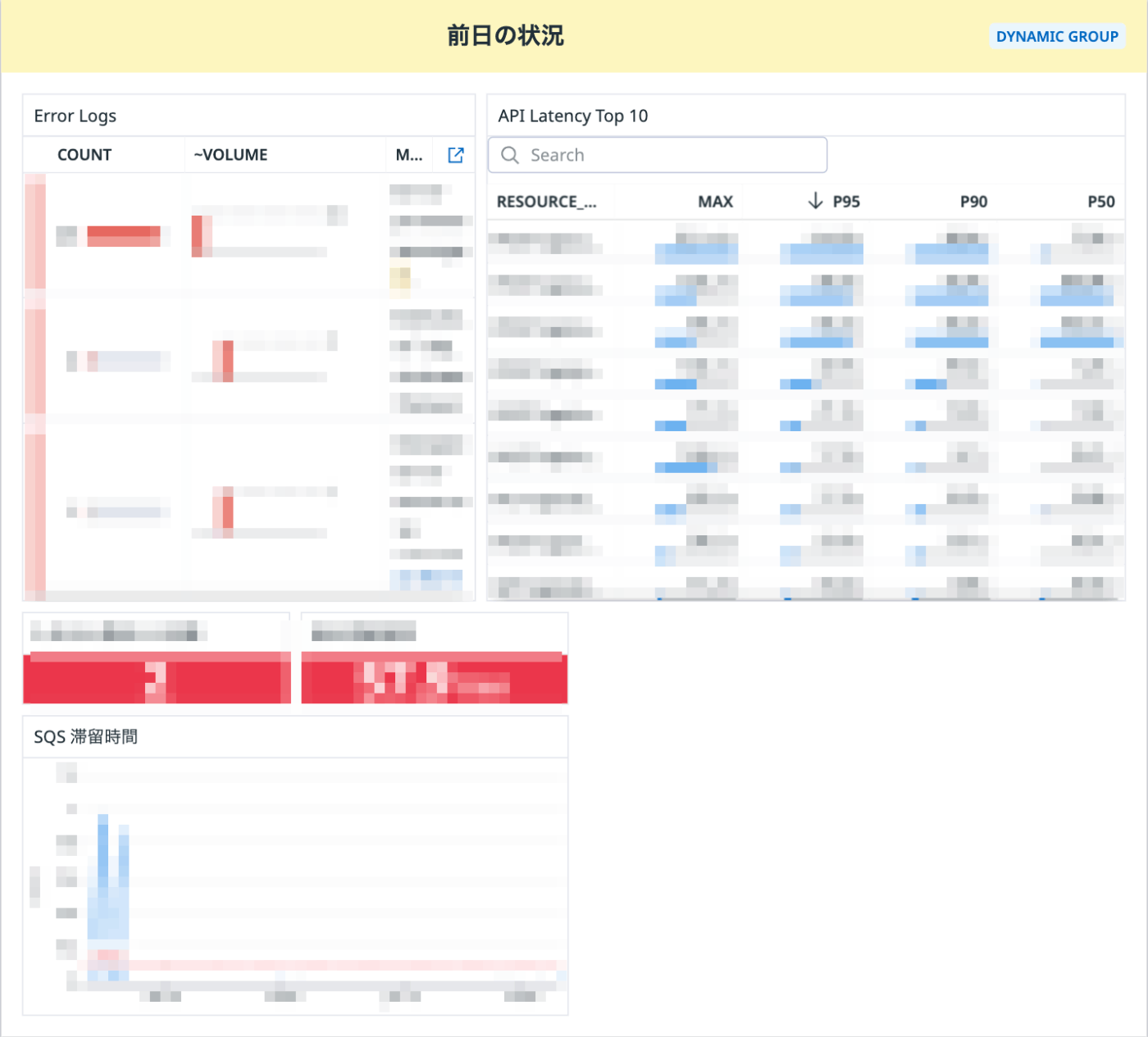
ただ、ダッシュボードを作るだけでは見なくなるので、これを Slack Workflow で日次で通知し、運用担当が確認します。

対応が必要なものは Backlog に積んで対応していきます。
さいごに
ここまで読んでいただきありがとうございます! 今回は、システムやドメインの知識が少ない自分がどのように工夫してアラート通知を改善して行ったか、の取り組みを紹介しました。
まだまだ改善は始まったばかりで、引き続き分析に使ったダッシュボードを定期的に確認し、改善や効果検証をしていきたいと思います!

Discussion