はじめに
2025年6月に、株式会社ログラスへクラウド基盤エンジニアとして入社しましたひろむです。
クラウド基盤チームは、インフラの構築や運用を担っています。最近はSRE領域にも手を伸ばしており、マルチプロダクトに対応するためのKubernetesでの共通基盤の構築、プロダクトセキュリティの強化などを推し進めています。
その一環として、ログラスでは各サービスのセキュリティを横断的に見ることのできるSysdig Secure(以下Sysdigと記載)を導入しています。この記事では、ログラスがSysdigを利用する上で、実際の業務内容や今後のSysdig運用で目指すべき姿などを記載したいと思います。
以下、クラウド基盤メンバーの見形さんや中井さんが、ログラスでSREをする面白さや今後の展望などを綴った記事があるので是非そちらもご覧いただければと思います。
Sysdigとは
クラウドネイティブ環境に特化した、統合セキュリティプラットフォームです。
従来のセキュリティ対策が境界防御中心であったのに対し、SysdigはCNAPP(Cloud Native Application Protection Platform)/ CWPP(Cloud Workload Protection Platform)として、クラウド上で動くアプリケーションやワークロードを包括的に保護する機能を提供します。
内部ではFalcoとOpen Policy AgentのOSSがベースで構成されており、主に以下のような機能を提供しています。
クラウド検知と対応(CNAPP/CWPP)
- リアルタイムでの脅威検知
- コンテナランタイムセキュリティ
- 侵入者の活動痕跡検出
脆弱性管理とポスチャー管理(CSPM/CIEM)
- コンテナイメージの脆弱性スキャン
- クラウド設定の継続的監視
- 権限の過剰付与検出
権限とエンタイトルメントの管理
- IAM権限の可視化
- 最小権限の原則に基づく推奨事項
ログラスでのSysdig運用
Sysdig導入後、主な業務として「検知したアラートへの対応」「ノイジーアラートのexception設定」「クラウドプロバイダーのintegration更新」「Sysdig policyの棚卸し」の4つを主とした運用を行っています。いずれもプロダクトセキュリティを守っていく上でとても重要な項目となるので、以降ではそれぞれの運用業務で具体的にどのようなことを実施しているのかを記載していきます。
検知したアラートへの対応
Sysdigにおけるポリシーとルールの関係は「ポリシー」の中に、より具体的な条件である「ルール」が含まれるといった階層的な関係になっています。ポリシーではManaged PolicyとCustom Policyがあり、ログラスではここで定義されているポリシーのSeverityがHighのものに対して、特定のSlackチャンネルへ通知を飛ばしています。Slackチャンネルに通知されると、クラウド基盤チームのメンバーがアラートの通知から検知に至ったプロセスなどを調べます。
詳細なアラート内容までは公開できませんが、当該アラートでは、AWS SSM Session Managerで接続したユーザーが脅威検知ルールにマッチするコマンドを実行したことで発生していました。
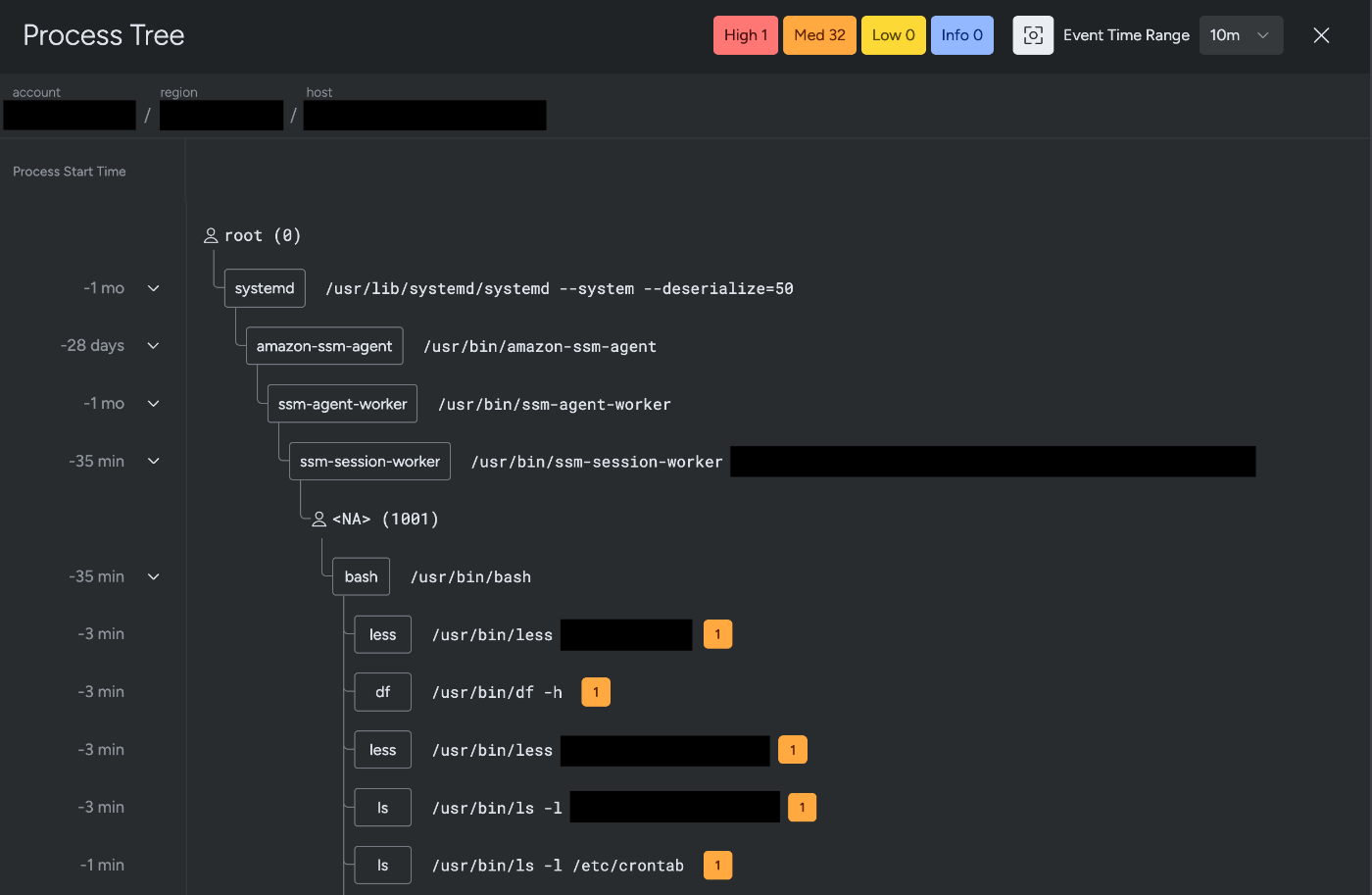
このように、ランタイム脅威検知のアラートではシステムコール単位で誰が何を実行したのかという点などを見ています。想定されないような挙動があったユーザには直接、その操作が必要になった理由や背景などを確認し問題がないことを確認しています。また、同様の操作を以前からしていて、急にアラートとして出力されるようになった場合などは、脅威検知ルールの変更があったのかなどを確認します。必要に応じて、Sysdigの方にサポートを受けながら不明点をなくした上でクローズするようにしています。

ノイジーアラートのexception設定
上記のようにアラート内容を確認していく中で、誤検知ではないが頻繁に出力され、かつ
クラウド基盤チームで特定の条件でアラート出力を止めたい場合、exceptionを追加しています。ノイジーアラートはアラート疲れ(運用チームが重要なアラートを見逃すこと)防止や、通知コストの削減、監視品質の信頼性向上といった面で非常に重要だと思っています。
exceptionを適用する上で以下2点を意識しています。
1. ゼロトラスト観点でexception適用する
2. 複数のフィールドや演算子を利用する
1. ゼロトラスト観点でexception適用する
exception適用する上で、適用範囲を「いい塩梅で決める」ことが最も難しいと感じています。exceptionの範囲が広すぎること、狭すぎること、それぞれで以下のような弊害が生じるので、ここはクラウド基盤メンバーでレビューしてもらった上で決めています。
- exception範囲が広すぎることの弊害
本当に悪意のあるイベントを見逃す可能性がある: 例えば、あるアラートが繰り返し発生した際、「これはクラウド基盤メンバーの操作だから」と広範囲に例外を適用してしまうと、内部のユーザーが意図的に悪意のある操作をした場合に検知ができず、対応が遅れることにつながる可能性があります。
これは、ゼロトラストの観点から見ても適切ではありません。ゼロトラストでは、「内部のユーザーも信頼しない」という前提があるので、特定のユーザーやグループの操作を安易に例外とすることで、その前提が崩れてしまいます。
- exception範囲が狭すぎることの弊害
運用負荷の増大: 一つのルールに合致する別のパターンでアラートが頻繁に出力され、その都度exceptionを精査し、追加するといった作業が発生します。これにより、アラートチューニングが継続的な運用負荷となり、チームの生産性を低下させてしまいます。
2. 複数のフィールドや演算子を利用する
上記の課題を解決するために、汎用的だが、広すぎない例外を実現するために、Sysdigの公式ドキュメントで推奨されているベストプラクティスを参考にしています。
特に重要なのは、複数のフィールドと適切な演算子を組み合わせることです。これにより、単一の条件で広範なイベントを除外するのではなく、より正確な条件で例外を設定できます。ログラスではcomps, fields, name, values の4つのフィールドを組み合わせて使うようにしています。
公式ドキュメントに記載の以下の例は、複数の類似したプロセス(nginx, nginx-runner, nginx-server)が/etc/nginxディレクトリにアクセスする際のノイズを、効率的に除外する方法を示しています。修正前コードでは、イベント発生後に3つの独立したルールを順次評価しますが、修正後コードではイベント発生後に1つのルール評価で済むため、条件のチェックを最適化し、かつ新しいnginx関連プロセス(例:nginx-workerなど)を追加したい場合、配列に要素を1つ追加するだけで済みます。
修正前
name: proc_name_folder
fields: [proc.name, fd.name]
comps: [“=”, startswith]
values:
- [“nginx”, “/etc/nginx”]
- [“nginx-runner”, “/etc/nginx”]
- [“nginx-server”, “/etc/nginx”]
修正後
name: proc_name_folder
fields: [proc.name, fd.name]
comps: [in, startswith]
values:
- [[“nginx”, “nginx-runner”, “nginx-server”], “/etc/nginx”]
クラウドプロバイダーのintegration更新
ログラスではSysdigをAmazon Web ServiceやGoogle Cloudと連携させています。この連携設定(integration)は一度設定して終わりではなく、定期的な更新作業が必要です。この作業は単にバージョンを上げるだけでなく、システムのセキュリティと機能性を継続的に向上させるための重要なプロセスです。
なぜインテグレーション更新が必要か?
プロバイダーの脆弱性対応: プロバイダーのコード自体にセキュリティ上の問題(入力値の検証不備など)が発見されることがあります。インテグレーションを更新することで、これらの脆弱性に対応し、システムの安全性を保つことができます。
新規機能の利用: Sysdig側で新しいセキュリティ機能やモニタリング機能が追加された場合、プロバイダーを更新することでこれらの新機能が利用できるようになります。
適用方法の変更へ追従するため: プロバイダーのバージョンアップだけでなく、Terraformを使ったインテグレーションの適用方法自体が変更されることがあるため、周辺のterraformコードごと更新が必要になります。
実際の更新時に直面した課題
ログラスでは、AWS Organizationsの管理アカウントからCloudFormation StackSetを使って、各AWSアカウントにSysdigのintegration設定を一括で配布しています。
integrationを行うための最新のTerraformコードを取得した後、既存のSysdig関連リソースを一度削除し、terraform applyを実行したところ、「CloudFormationのStackインスタンスが残っているため削除できない」旨のエラーが発生しました。このエラーはSysdig起因ではなく、AWS Organizationsの仕様によるものとなっており、aws cloudformation delete-stack-instancesコマンドを使い、残存していたStackインスタンスを全て削除しました。この作業により、StackSetに紐づく全てのStackがクリーンに削除され、無事、新しいバージョンのインテグレーションを適用することができました。
Sysdig policyの棚卸し
Sysdigが提供するマネージドポリシーは、最新の脅威動向に合わせて日々更新され、新しいポリシーやルールが追加されます。これらの更新を放置すると、新しい脅威検知機能を見逃してしまう可能性があります。そこでログラスでは、四半期に一度、Sysdigのポリシーを棚卸しする作業を行っています。
棚卸しの目的
この作業の主な目的は、Sysdigが新しく追加したポリシーの中から、MediumやInfoレベルであっても、ログラスの環境ではHighレベルで通知すべきと判断すべきルールがないかをチェックすることです。
-
Sysdig APIからJSONデータを取得:
AWS CloudTrail、Syscall、GitHubなどの各ポリシータイプごとに、最新のポリシー情報をJSON形式で取得します。 -
jqでデータの整形:
取得したJSONデータを、後工程で扱いやすいようにjqコマンドで簡略化します。 -
PythonスクリプトでCSVに変換:
nameとruleNameを抽出し、スプレッドシートに貼り付けられるようPythonスクリプトでCSVデータに変換します。
棚卸し作業のポイント
こうしてスプレッドシートに抽出されたデータと、前回棚卸ししたデータとの差分を比較し、新しいルールや変更点がないかを確認します。この作業を通じて、新しく追加されたルールを精査し、既存の環境に適用すべきかを判断します。通知すべきと判断したルールは、直接SysdigのGUIで設定するのではなく、Terraform管理されたカスタムポリシー用のファイルに追加します。これにより、変更履歴が残り、チーム内でのレビューも容易になります。この棚卸し作業によって、Sysdigの持つ最新のセキュリティ機能を最大限に活用し、自律的にセキュリティレベルを向上させるために不可欠な運用プロセスとなっています。
現在の課題と今後の取り組み
Sysdigの運用を進める中で、いくつかの課題が出てきています。これらの課題を解決することで、より効果的で持続可能なセキュリティ運用の実現につながると考えています。
現在の課題
-
運用の属人化
現状、Sysdigのintegration更新手順などがチーム内で属人化しており、特定のメンバーに依存する運用となっています。これにより、知見の共有不足やチーム全体のスキル向上の阻害要因となっています。 -
アラート対応が特定チームのみになっている
現在、全てのアラートをクラウド基盤チームで対応していますが、特にランタイム脅威検知などはアプリケーション側起因で発生することが多いため、責務の分散が課題となっています。一次対応をアプリケーション開発者に移管することで、クラウド基盤チームの運用負荷軽減とアプリケーション側のセキュリティ意識向上の両立を目指したいと考えています。
今後の展望
-
運用の標準化とドキュメント化
Sysdigに関するあらゆる作業や運用手順をドキュメント化し、クラウド基盤チーム内での属人化を解消します。これにより、チーム全体でのノウハウ共有とスキルレベルの底上げをしたいと考えています。 -
責務の明確化とチーム間連携の強化
現在はクラウド基盤チームが中心となってSysdigの運用を行っていますが、特に脆弱性管理やランタイム脅威検知の部分については、アプリケーション開発者にも定期的に確認・対応してもらい、責務を明確化することを計画しています。
この取り組みにより以下の効果を期待しています:
- アプリケーション開発者側での能動的なセキュリティ意識向上
- クラウド基盤チームの運用負荷軽減
- プロダクトセキュリティ全体の底上げ
実際に、毎週行っているセキュリティ定例にアプリケーション開発者も参加し始めており、今後本格的な責務の明確化を進めていく予定です。
まとめ
Sysdigの導入により、ログラスでは効率的で実効性の高いセキュリティ運用を実現できています。
実際に、Sysdig導入後すぐに複数のAWSアカウントやGoogle Cloudアカウントを横断的に分析し、他部署から要求されながらも本番運用には至らなかったアカウントや、過剰に権限が付与されていたアカウントを発見・整理することができました。これにより、セキュリティリスクの可視化と具体的な改善につなげることができています。
今後の課題である運用の標準化や責務の明確化を通じて、Sysdigを単なる監視ツールとしてではなく、開発チームとのコミュニケーションハブとして活用していきたいと考えています。
最後までお読みいただきありがとうございました!

Discussion