
この記事の全体地図
ポンだしスライドバージョン
(まず1分程度これを眺めていただき、ご興味持ってもらえたら本文に入っていただくのもいいかもしれないです)
動機・目的
Eval (「良い出力とは何か」を定義し測定可能にする、LLM出力の品質の測定)の重要性がよく語られています。 例えばこの動画だと 40:33あたりで言及
- ユーザの使用データ集積(特に失敗例)-> そこからEvalSetを抽出・結晶化 -> EvalSetが通るようにプロンプト改善(既存のEvalに対してデグレも検知、両立するように)
というデータフライホイールを回していく中で、「EvalSet」自体が moatである、とまで言えるほどです。
今回は、開発の中で使うようなプロンプトに対する eval を書いてみることで、それに親しみ、直感を育んでみたいと思います。
その結果として:
- prompt の eval を書き始めると、従来的コードと同様に eval 容易性が高くなるように書こう、分割しよう、という動機が働く
- In -> Out の型が構造的になっていないとアサーションが難しい
- 長い散文のモノリスを解体、I/Oが明確なプロンプトに分割しないと、因子やrubric(評価観点)の組合せ爆発により評価困難
- もしかしたら、従来型コードと同じように eval 容易性の高いプロンプトがおよそ良いプロンプトなのかもしれない
という自分なりの示唆・直感を得たので、その過程を共有したいと思います。
また、チームで使うプロンプトに対する eval を書くということも、「お気持ち」以外のものでプロンプトの良し悪しを語れる、他の人が書いたプロンプトに改善PRを出しやすくなる、という作用もあるかと思います。
使用ツール・サンプルリポジトリ
-
promptfoo
- LLM-Product/機能に対する、監視・evalではなく、普段使いのプロンプトを評価してみよう、というモチベーションのため
- ベンダーフリーのため
-
https://github.com/yodakeisuke/BDD-prompts-with-eval
- BDDのプラクティスをプロンプト群に落とす、というシチュエーションを例とします
リポジトリの解説
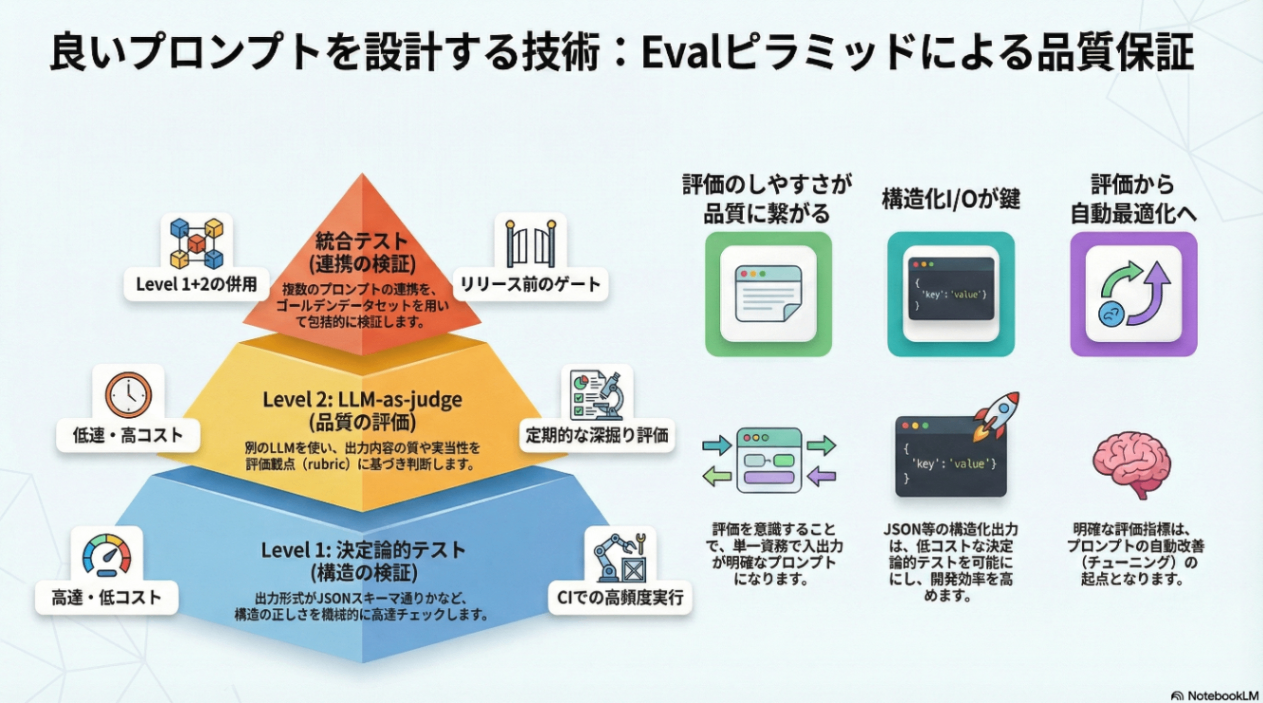
全体像:Evalピラミッドとリポジトリ構成
プロンプトの評価には複数のレベルがあります。AI評価ピラミッドでは3層構造が提唱されています:

このリポジトリでは、Level 1〜2を promptfoo で実装しています:
dev-prompt-eval/
├── eval/
│ ├── test-deterministic/ ← Level 1: 構造検証(高速・低コスト)
│ ├── test-qualitative/ ← Level 2: LLM-as-judge(深い品質評価)
│ └── test-integration/ ← Level 1+2 の統合テスト
├── eval-set/ ← ゴールデンデータセット
└── tuning/ ← 評価を活用した最適化(GEPA)
※ この階層定義は何かの推奨に従った、などではなく自分はこうした、だけのものです
| レイヤー | 目的 | 方法 | 速度 | 用途 |
|---|---|---|---|---|
| test-deterministic | 構造検証 | 決定論的アサーション | 高速 | CI、高頻度実行 |
| test-qualitative | 品質評価 | LLM-as-judge | 遅い | 定期的な深掘り |
| test-integration | 統合テスト | 両者併用、prompt結合テスト | 中 | リリース前ゲート |
評価対象プロンプトの概説
評価対象は BDDのプラクティスのうちの1つ、 「Example Mapping」 を行うプロンプト(SKILL.md)です。
プロンプトに写すのは、なんらかの「プロセス」ですので、In->Process->Out とその連鎖、と捉えるのが現実に即しています。(決定論的コードでも同じですが)
今回は、Example Mappingというプロセス(写しとるドメイン)を、
入力: ユーザーストーリー(フリーフォーマット、自然言語)
↓ プロセス(Example Mapping)
出力: ストーリー、発見したrule(実例をいくつか含む)、曖昧な点
と型で構造定義(モデリング)しました。
要は↓ということになります

出力スキーマ:
{
"story": { "as_a": "...", "i_want_to": "...", "so_that": "..." },
"rules": [{ "id": "rule_1", "name": "...", "examples": [...] }],
"questions": { "blocker": [], "clarification": [], "future": [] },
}
余談ですが、spec-driven系のツールで受入基準を書いていくのは、BDDプラクティスの簡易版のように思えます。
Level 1:output構造の決定論的アサーション
最も基本的な単位の eval です。
構造が正しいかを機械的に検証します。必須フィールドがあるか、値の型は正しいか、意図した「構造」が守られているか、決定論的にアサーションをかけます。
入力テストデータである、「ユーザストーリー」を定義しています
# test-deterministic/promptfooconfig.yaml
tests:
- description: "予実差異レポートの表示改善"
vars:
story_input: "予実差異レポートで、マイナス値を赤字で表示したい。"
assert:
# 構造検証:story, rules, questions が存在するか
- type: javascript
value: |
const out = JSON.parse(output);
const hasStory = out.story &&
out.story.as_a.length > 0 &&
out.story.i_want_to.length > 0;
const hasRules = Array.isArray(out.rules) && out.rules.length >= 1;
const hasQuestions = out.questions &&
Array.isArray(out.questions.blocker);
return hasStory && hasRules && hasQuestions;
LLMを呼び出している箇所:
# promptfooconfig.yaml
providers:
- id: anthropic:claude-agent-sdk // プロパイダーに claude-agent-sdk を指定できるのが、Claude Code用のプロンプト評価したい場合に嬉しい
config:
model: sonnet
working_dir: ./test-deterministic/sandbox
setting_sources:
- project
prompts:
- file://../../.claude/skills/bdd/example-mapping/SKILL.md
providers でLLMを指定し、prompts で評価対象のプロンプトファイルを指定します。tests の各ケースに対して、promptfooがLLMを呼び出し、その出力に対してアサーションを実行します。
決定論的テストの特徴:
- 高速: 評価フェーズでのLLM呼び出し無し(出力生成には必要)
- 低コスト: アサーション自体は無料
- CI向き: コード変更のたびに実行可能
従来的なテスティングピラミッドのように、コストが低いこの層でできるevalを増やしたいです。
というときに、「そもそも出力が構造化されていないと機械的アサーションができない」ですね。
なので、I/Oの型を明確にすることが eval 容易性・コスト節約にも繋がります。
Level 2:LLM-as-judge評価
「構造は正しいが、中身は良いのか?」を検証します。Example Mappingの例では、質問の深さ、ドメイン適合性、重複の有無などはLLM(または人間)の判断が必要です。
テストデータに加え、 rubric(評価観点)を定義します。(テスト定義は yamlで書きます)
# test-qualitative/promptfooconfig.yaml
tests:
- description: "曖昧な要求からの質問生成能力"
vars:
story_input: "予算入力画面をもっと使いやすくしたい"
assert:
- type: llm-rubric
value: |
以下の観点で評価してください(5段階):
1. 質問の深さと洞察力(3 Amigos視点)
- Developer: 技術的複雑性、既存機能との整合性
- Tester: エッジケース、エラーハンドリング
- PO: ビジネス価値、優先度
評価観点: 3つの視点から最低1つずつ質問を含む = 5
2. FP&A SaaS特化性
- 既存機能との整合性
- 権限・承認フローへの影響
- Excel出力への影響
評価観点: 5つの考慮事項のうち3つ以上言及 = 5
総合評価: 平均4.0以上でpass
お手本データを用意して、出力の類似度を評価する、という手段もあります。
テストデータ(CSV)の例:
source_type,category,complexity,story_input,expected_rules_min,expected_questions_min
job,権限承認,complex,承認済み予算は部門長も編集不可にしたい。CFOのみ編集可能。,4,6
persona,シミュレーション,complex,複数の予算シナリオを比較したい。楽観・標準・悲観の3パターン。,5,7
complexity に応じて expected_rules_min / expected_questions_min を設定し、出力の妥当性を検証します。
テストケースについては
- ユーザーストーリの複雑性
- 新規か保守か
- ユーザ指示の明確さ
のような 因子・水準 を掛け合わせてケース設計しています。
LLM-as-judgeの特徴:
- 深い評価: 人間の判断基準を符号化できる
- 説明付き: なぜpassしたか・failしたかの理由が得られる(annotation)
- 高コスト: 出力生成 + 判定で2回のLLM呼び出し
ここで、1つの巨大なモノリシックプロンプトを評価しようとすると、「rubricが爆発する」ということが起きるかと思います。
1つのことをうまくやろうとしているプロンプトに対しては、 eval が非常にやりやすいです。
この例では、
/commands/bdd-discover-spec.md のカスタムコマンドをエントリポイント/オーケストレーターとし(usecase層みたいです)
/skills/bdd/配下に、階層的に実際の知識を書いています(domain層みたいです)
ある skill のOutが他の skill のInになっていたり、合成可能な単一責務のレゴブロックとして定義しています。(決定論的プログラミングと同じです)
統合テスト:ゴールデンデータセットによる検証
Level 1 + Level 2 を組み合わせ、更に、単体レベルのプロンプトではなく複数のプロンプトが合成されたプロンプトに対して書くこともできます。
promptfooなどのツールでは、データセットを生成できるのでそれを使用したりもできます。
(実際のプロダクト開発では、このゴールデンデータセット、EvalSetを育てていくことが重要なことの1つになりそうです。)
# test-integration/promptfooconfig.yaml
tests: file://../../eval-set/samples/integration-test.csv # 9ケース
defaultTest:
assert:
# Level 1: 構造検証(7つの決定論的アサーション)
- type: is-json
- type: javascript
value: |
const parsed = JSON.parse(output);
return ['story', 'rules', 'questions', 'next_actions']
.every(key => key in parsed);
# ... 省略 ...
# Level 2: ドメイン適合性(LLM-as-judge)
- type: llm-rubric
value: |
FP&A SaaS brownfield開発の制約を考慮しているか評価:
- 既存機能との整合性
- 権限・承認フローへの影響
- Excel出力への影響
2-3個以上の観点に言及していればpass
統合テストのデータセット(9ケース):
- Job-based: 5ケース(手作業削減、精度向上、可視化、統制、協働)
- Persona-based: 4ケース(部門長、経理、CFO、IT管理者)
自分なりの示唆・得られた直感
プロンプトのevalを書き始めたら「eval容易性の高い、単一責務でI/Oの型が明確な自然言語関数とその合成を書こう」という気持ちになりました。
In -> Out の型が構造的になっていないと、決定論的アサーションが難しく、コスパの良いevalを回し難くなると感じました。
長い散文のモノリスを解体、I/Oが明確なプロンプトに分割しないと、rubric(評価観点)の組合せ爆発によりテスト困難になると実感しました。
そしてもしかしたら、従来型コードと同じように eval 容易性の高いプロンプトがおよそ良いプロンプトなのかもしれない...
In -> Out の型を構造化することは、structure outputや、成果物のtemplate、exampleの提示などのプラクティスと同じになるかと思います。
関心事が明確な部品は、再利用性に優れます。
またより日常的な例として、何か「仕事」をするとき、
- 成果物イメージを固める。使えるinput、前提は?
- サブタスク(段取り)とそのI/Oに分割する
のようなワークプラン設計をすると思います。(I/Oの明確化、サブプロセス分割)
また、何かの「業務」をコーディングするときも、I -> O の型とその合成/連鎖を考えると思います。
これはプロンプティングの場合は、自然言語 -> 自然言語 この矢印であるLLM関数 の合成/連鎖の設計が相当するかと思います。
更に... 評価から最適化へ
自然言語 -> 自然言語の LLM関数、という表現は、DSPyにおいてはより顕著です。
const assistant = new AxAgent({
name: 'Personal Assistant',
description: 'Helps manage tasks and remember important information',
// ↓このagentは、`メッセージ、userID -> 応答` という関数
signature: 'message:string, userId:string -> response:string, actionsTaken:string[]',
functions: tools,
memory
});
また、agentにtoolを登録するのは
自然言語 -> 自然言語 のLLM関数に(大抵は)副作用がある関数を渡すようなものだという感覚にもなってきます。
話をやや戻して...
評価観点が明確になると、自動最適化が可能になります。
このリポジトリの tuning/ では、DSPyを使ってプロンプトを最適化も試しています。評価メトリクスがあるからこそ、「どのプロンプトが良いか」を機械的に判定し、改善ループを回せます。
SKILL.md(初期プロンプト)
↓ GEPA最適化(tuning/)
最適化済みSKILL.md
↓ promptfoo評価(eval/)
品質スコア → 改善ループへ
Evalは単なる品質保証ではなく、改善フライホイールの起点です。
自然言語関数を「エンジニアリング」していくにあたり、より重要になっていくと考えられます。
読んでいただきありがとうございました!!

Discussion