ログラスの龍島(@hryushm)です。寒くなってきましたね。最近は鴨肉を焼くのがマイブームです。ということで今日はPolarsとDuckDBの話です。
PolarsとDuckDBは、近年注目を集めているデータ処理のための高速なクエリエンジンです。それぞれ異なる強みを持っていますが、どちらもシングルノードでOLAPの分析処理を非常に高速に実行できるという共通点があります。この記事では、データソースにPostgreSQLを用いた場合において、PolarsとDuckDBのパフォーマンスにどのような違いが現れるのかについて比較します。
Polarsとは
Polarsは、Rustで実装されたデータフレームライブラリで、特にパフォーマンスに優れたクエリエンジンです。Pandasの代替を目指しており、大規模なデータを効率的に処理できる設計がされています。マルチスレッドを活用して並列処理を行い、Pythonとのバインディングも提供しているため、Pandasに慣れ親しんだユーザであれば扱いやすいツールです。
CSVファイルからデータを読み取り、簡単な分析を行うサンプルコードは以下です。
import polars as pl
# CSVファイルからデータを読み込む
csv_file = "data.csv"
df = pl.read_csv(csv_file)
# 年齢が30歳以上のデータをフィルタし、部署ごとの平均給与を計算する
result = df.filter(pl.col("age") > 30).groupby("department").agg(
[
pl.col("salary").mean().alias("average_salary"),
pl.col("salary").sum().alias("total_salary")
]
)
print(result)
DuckDBとは
DuckDBは、データ分析に特化した高速に動作するインプロセスDBです。SQLiteのような軽量さを持ちながらも、列指向のデータストレージを採用しており、高度な分析クエリを効率的に実行できます。
CSVファイルからデータを読み取り、簡単な分析を行うサンプルコードは以下です。
DuckDB自体データを永続化するモードとインメモリにのみ保持してプロセスが終了すると読み込んだデータが破棄されるモードがあり、今回はインメモリモードの例です。
import duckdb
# DuckDBでCSVファイルを直接クエリする
csv_file = "data.csv"
conn = duckdb.connect()
# 年齢が30歳以上のデータをフィルタし、部署ごとの平均給与と合計給与を計算するクエリ
query = f"""
SELECT
department,
AVG(salary) AS average_salary,
SUM(salary) AS total_salary
FROM read_csv_auto('{csv_file}')
WHERE age > 30
GROUP BY department
"""
conn.sql(query).show()
PolarsとDuckDBの比較
簡単に2つを比較すると下記のようになります。
| 特徴 | Polars | DuckDB |
|---|---|---|
| 実装言語 | Rust | C++ |
| APIサポート | Python、Rust | Python, Java, Go, ...他多数 |
| データ操作スタイル | DataFrame(、SQL※) | SQL |
※Polarsはデータ操作としてSQLをサポートしているものの、公式にも As the DataFrame interface is primary, new features are typically added to the expression API first. とあり、DataFrameの利用が推奨されています。
性能比較
PolarsとDuckDBのベンチマーク比較は多く行われていますが、対象データの性質やクエリの内容によるというのが正直なところのようです。参考までにPolarsが速いというPolarsのベンチマークとDuckDBが速いというベンチマークを掲載しておきます。 どのベンチマークにも共通するのはよく比較対象となるPandasよりは圧倒的に速いということです。
データソースにPostgreSQLを用いた場合の比較
今回はデータソースにPostgreSQLを用いた場合の比較をします。背景としてはPolarsやDuckDBなどを調査していた際に、これだけ速ければPostgreSQLなどのRDBMSのクエリエンジン部分にPolars, DuckDBを利用することでそのままPostgreSQLを利用するより速いことがあり得るのでは?と思ったためです。更新処理やトランザクションなどOLTPの処理に強いPostgreSQLを通常は使い、重たいクエリ処理はPostgreSQLはデータを返すのみに留め、集計処理はPolars, DuckDBに任せるという構成が実現可能かもしれないと考えました。
単純に考えるとPostgreSQLのみで完結したほうがオーバーヘッドもなく高速だと考えられますが、実は既にDuckDBでPostgreSQLをデータソースとしたベンチマークを実施したブログがあり、特定のパターンではPostgreSQL単体より高速になったというのです。
it also was faster than stock Postgres on roughly half of them, which is astonishing given that DuckDB has to read its input data from Postgres through the client/server protocol as described above.
(日本語訳) また、そのうちの約半分では、純正のPostgresよりも高速だった.DuckDBは上記のようにクライアント/サーバープロトコルを通じてPostgresから入力データを読み込む必要があることを考えると、これは驚くべきことである。
検証のスクリプトが公開されているので、手元でも動かしてみつつ、Polarsでも実行した上で性能比較してみます。
ベンチマーク
上記ブログのパターンに追加して、Polars+PostgreSQL、Polars+Parquetで行います。
| パターン | データソース | 集計処理 |
|---|---|---|
| duckdb | DuckDBの永続化ストレージ | DuckDB |
| duckdb/postgres | PostgreSQL | DuckDB |
| polars | ローカルのParquetファイル | Polars |
| polars/postgres | PostgreSQL | Polars |
| postgres | PostgreSQL | PostgreSQL |
DuckDBにTPC-Hの拡張機能があるため、データセットやクエリ生成に用いることとします。TPC-Hはデータウェアハウスの性能検証を目的としたベンチマークです。
また、ソフトウェアの利用したバージョンは下記です。
| Software | Version |
|---|---|
| PostgreSQL | 16.4 |
| DuckDB | 1.1.2 |
| Polars | 1.9.0 |
| (ConnectorX) | 0.3.3 |
結果

まず前述のブログにもあったDuckDB+PostgreSQLでPostgreSQL単体より半分以上が速いという部分の検証ですが、今回は7/22パターンでDuckDB+PostgreSQLが高速ということになりました。他のパターンでも肉薄しているものはあるので、半分以上が高速という結果になってもおかしくは無いかもしれません。

そして肝心のPolars+PostgreSQLですが、圧倒的に遅いという結果となってしまいました。他が1秒以下でしのぎを削る中、4,5秒程度かかってしまっています。
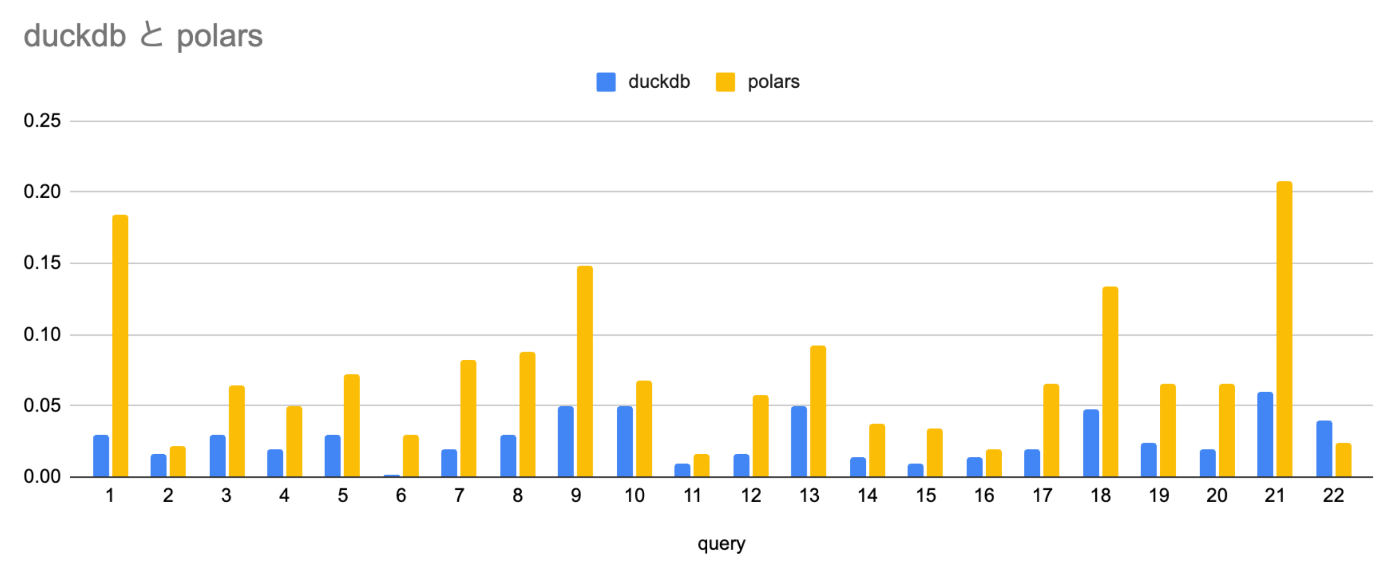
一方Polars+Parquetは最も高速なDuckDB+DuckDBストレージよりは遅いですが、ほぼ全て200ms以下で返せています。Polarsはクエリ部分は遜色ないものの、DBからのデータ取得が遅いと予想されます。
以上から、更に疑問が生まれます。なぜDuckDBはPostgreSQLからのデータ取得が速く、Polarsは遅いのでしょうか?
DuckDBのデータ取得
前述のブログからDuckDBのPostgreSQL接続について、高速な要因をまとめると下記のようになります。
- binary転送モードの利用: PostgreSQLのbinary転送モードを使用し、文字列変換のオーバーヘッドを回避
- 並列化: 複数のクエリで、テーブルの一部を並列にスキャンする。PostgreSQLのTIDスキャン機能を利用して効率的にテーブルをパーティショニングして取得
- ProjectionとSelectionのPushdown※: 必要な列、必要な行のみをPostgreSQLから取得することでデータ転送量を削減
- DuckDBの最適化されたクエリ処理エンジン: ベクトル化されたクエリ処理エンジンを使用して、取得したデータを効率的に処理
2,3については具体的なクエリを見ると理解が深まりそうです。
ベンチマーク時に実行されていたクエリの一部分を取得すると下記のようになっていました。2,3の内容に対応する箇所にコメントを入れています
COPY (
SELECT
"l_quantity",
"l_extendedprice",
"l_discount",
"l_tax",
"l_returnflag",
"l_linestatus",
"l_shipdate"
-- [3:ProjectionのPushdown] lineitemは全部で16列あるが、利用する列のみselect
FROM
"public"."lineitem"
WHERE
ctid BETWEEN '(9000,0)' :: tid
AND '(10000,0)' :: tid -- [2:並列化]Tupple IDでパーティショニングされている
AND (
"l_shipdate" <= '1998-09-02'
AND "l_shipdate" IS NOT NULL
) -- [3:SelectionのPushdown] 必要な行のみにフィルタ
) TO STDOUT (FORMAT "binary");
-- ...以下ctidの絞り込みを変えたクエリが連続
DuckDBでのPythonコードは下記のようなイメージです。
import duckdb
con = duckdb.connect()
con.execute('INSTALL postgres_scanner')
con.execute('LOAD postgres_scanner')
con.execute("CALL postgres_attach('dbname=tpch', filter_pushdown=true)")
result = con.execute("""
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01'
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus
""")
CALL postgres_attach するとDuckDB内で扱えるようになり、QueryPlan時にPushdownなども含めてPostgreSQLからデータロードするSQLを組み立ていると考えられます。これはDuckDBがデータベースからのデータ取得処理も含めてQueryPlanを最適化できているということであり、後述するPolarsとは異なる点で強みであると考えられます。
Polarsのデータ取得
PolarsはPythonコードから見ていきます
import polars as pl
lf = pl.read_database_uri(
query="SELECT * FROM lineitem", # select文である必要があり、テーブルは指定できない
uri="postgresql://postgres:postgres@localhost:5432/tpch",
partition_on="l_orderkey", # パーティションキーは明示的に指定する
partition_num=10,
).lazy()
result = (
lf.filter(pl.col("l_shipdate") <= var1)
.group_by("l_returnflag", "l_linestatus")
.agg(
pl.sum("l_quantity").alias("sum_qty"),
pl.sum("l_extendedprice").alias("sum_base_price"),
(pl.col("l_extendedprice") * (1.0 - pl.col("l_discount")))
.sum()
.alias("sum_disc_price"),
(
pl.col("l_extendedprice")
* (1.0 - pl.col("l_discount"))
* (1.0 + pl.col("l_tax"))
)
.sum()
.alias("sum_charge"),
pl.mean("l_quantity").alias("avg_qty"),
pl.mean("l_extendedprice").alias("avg_price"),
pl.mean("l_discount").alias("avg_disc"),
pl.len().alias("count_order"),
)
.sort("l_returnflag", "l_linestatus")
).collect()
DuckDBと同様にデータ取得時のクエリを見てみます。
COPY (
SELECT
*
FROM
(SELECT * FROM lineitem) AS CXTMPTAB_PART
WHERE
4200001 <= CXTMPTAB_PART.l_orderkey
AND CXTMPTAB_PART.l_orderkey < 4800001
) TO STDOUT WITH BINARY
明示的に指定した l_orderkeyによるパーティショニングは行えていますが、利用されるカラムやフィルタを指定できていない(Projection, SelectionのPushdownができていない)部分がDuckDBとは異なっています。
Pushdownができていない背景として、Polarsはデータベースからのデータ取得にConnectorXというライブラリを用いており、Polarsから切り離されていることがあると考えられます。
ConntectorX側にどのようなクエリをしてほしいかは read_database_uri のqueryに渡しているselect文しか無いため、Pushdownしたい場合はこのselect文を自力で調整していくしかなさそうです。
Polarsも今後データベース接続をPolars内部で行うようになった場合、より最適化されることが期待されますが、Issuesを見てもそのような方向性で考えられてはいなそうでした。
まとめ
PolarsとDuckDBをデータベース接続してのデータ取得という観点で比較しました。接続処理をライブラリ内で行い最適化できているかどうかが大きな性能差につながることがわかりました。
この観点ではDuckDBが優勢でしたが、Polarsも十分高性能ですし、SQLインターフェースではないためテストがしやすいという利点もあります。ユースケースによってどちらが(もしくは他の製品が)最適であるかは変わるので、導入検討の際はユースケースに基づいた検証を行うのが良さそうです。

Discussion