はじめに
こんにちは、ログラスでエンジニアをしてる福土(@ryoya_cre8or)です!
SQLの結合アルゴリズムである
- Nested Loop
- Hash
- Sort Merge
についてご存知でしょうか?
かくいう私はこの辺りのアルゴリズムを特に意識せずにこれまで開発をしてきており、この機会にそれぞれの結合アルゴリズムへの理解とそのパフォーマンスの差異について手を動かしながら理解したいと考え、今日に至ります。
結合アルゴリズムによってSQLクエリのパフォーマンスが大きく変わることは、エンジニアが理解しておくべき非常に重要なポイントです。
クエリが遅くなることで、アプリケーション全体のレスポンスが低下し、ユーザー体験に直接影響を与えることがあります。そのため、最適な結合アルゴリズムを理解し、適切に選択することは、エンジニアとしての腕の見せ所です。
なお、今回はPostgreSQLを使って検証を進めていきます。
3つの結合アルゴリズムについて
冒頭で紹介した3つのアルゴリズムを説明する前に、代表的なDBMSでサポートされているアルゴリズムをご紹介します。以下の表にまとめました。
| DBMS | Nested Loop | Hash | Sort Merge |
|---|---|---|---|
| PosgreSQL | YES | YES | YES |
| Oracle | YES | YES | YES |
| MySQL | YES | YES(MySQL 8.0.20 以降) | No |
これを見ると、ほとんどの主要なDBMSはこれら3つの結合アルゴリズムをサポートしており、それぞれの特徴や使用ケースに応じて選択されます。それでは、それぞれの結合アルゴリズムについて詳しく見ていきましょう。
Nested Loop
Nested Loop(入れ子ループ)結合は、2つのテーブル間の結合を二重ループを使って行う結合方法です。具体的には、外側のループで一つのテーブルを走査し、内側のループでその各行に対応するもう一つのテーブルを走査します。
そのため、最悪の計算量としてはO(M * N)となります。インデックスを貼ることで計算効率が良くなりますがそちらは後ほど紹介します。
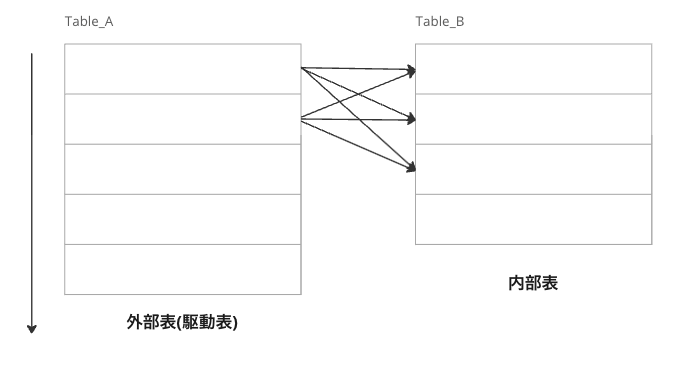
この結合方法の特徴は、テーブルのどちらを外側(駆動表)に、どちらを内側(内部表)にするかによってパフォーマンスが大きく変わる点です。外側のテーブルのサイズが小さく、内側のテーブルの結合キーにインデックスをつけることでパフォーマンスを高めることができます。
例えば、以下のようなSQLクエリを考えてみましょう。
-- tableAの作成
CREATE TABLE tableA (
id SERIAL PRIMARY KEY,
value INT
);
-- tableBの作成
CREATE TABLE tableB (
id SERIAL PRIMARY KEY,
value INT
);
-- tableCの作成
CREATE TABLE tableC (
id SERIAL PRIMARY KEY,
value INT
);
-- tableCのvalueにインデックス作成
CREATE INDEX idx_tableC_tableA_id ON tableC(value);
-- データの挿入
INSERT INTO tableA (value)
SELECT generate_series(1, 10000);
INSERT INTO tableB (value)
SELECT generate_series(1, 10000);
INSERT INTO tableC (value)
SELECT generate_series(1, 10000);
このクエリでは、tableA を外部表とし、tableBとtableCの2つの内部表を用意しました。
tableBにはvalueにインデックスがありませんが、tableCのvalueにはインデックスを作成しています。
まず、tableAとtableBを結合した時の実行計画は以下になります。
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tB.value
FROM tableA tA
JOIN tableB tB ON tA.value = tB.value;
--------------------------------------------------------------------------------------------------
Nested Loop (cost=0.00..1500315.00 rows=10000 width=12) (actual time=50.867..4329.928 rows=10000 loops=1)
Join Filter: (ta.value = tb.value)
Rows Removed by Join Filter: 99990000
-> Seq Scan on tablea ta (cost=0.00..145.00 rows=10000 width=8) (actual time=0.042..2.153 rows=10000 loops=1)
-> Materialize (cost=0.00..195.00 rows=10000 width=4) (actual time=0.005..0.218 rows=10000 loops=10000)
-> Seq Scan on tableb tb (cost=0.00..145.00 rows=10000 width=4) (actual time=50.793..52.124 rows=10000 loops=1)
Planning Time: 1.134 ms
Execution Time: 4332.365 ms
実行時間が4332.365 msとなっており、外部表と内部表ともにSeq Scanが選択されているためテーブルの行全てを走査していることがわかります。
続いてtableAとtableCを結合した実行計画がこちらです。
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Nested Loop (cost=0.29..3570.00 rows=10000 width=12) (actual time=0.106..15.856 rows=10000 loops=1)
-> Seq Scan on tablea ta (cost=0.00..145.00 rows=10000 width=8) (actual time=0.012..0.886 rows=10000 loops=1)
-> Index Only Scan using idx_tablec_tablea_id on tablec tc (cost=0.29..0.33 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=10000)
Index Cond: (value = ta.value)
Heap Fetches: 10000
Planning Time: 0.773 ms
Execution Time: 16.299 ms
こちらは実行時間が16.299 msで、先ほどのインデックスなしと比べると圧倒的に早いことがわかります。
tableCのvalueに貼られたIndexを見るとB-Treeであることがわかります。
-- インデックスの確認
SELECT
indexname,
indexdef
FROM
pg_indexes
WHERE
tablename = 'tablec';
--------------------------------------------------------------------------------------------------
indexname | indexof
tablec_pkey | CREATE UNIQUE INDEX tablec_pkey ON public.tablec USING btree (id)
idx_tablec_tablea_id | CREATE INDEX idx_tablec_tablea_id ON public.tablec USING btree (value)
よってtableAとtableCを結合した場合の計算量はO(A * log(C)) となり、tableCのレコードが今後増えてもパフォーマンスはそれほど悪化しないことがわかります。
また少し踏み込むと内部表の取得にはIndex Only Scanが使われておりますが、ヒープアクセスが発生しています。本来であれば、Indexに含まれる値をそのまま使うことで、ヒープアクセスを省略してディスクI/Oを最小限に抑えることができますが、可視性マップが最新ではない可能性があることでヒープアクセスが発生していることが考えられます。そのため可視性マップを最新に更新する必要があります。
可視性マップはテーブルの行が格納されているヒープ領域のうち、削除フラグのついた不要な領域を管理しているメタデータを保持しています。これはPosgreSQLが追記型アーキテクチャを採用しているために生じており詳細の説明はこちらの記事を参照ください。(参考)
つまり言い換えると、どのページ(行のデータを格納している基本的なデータ構造)が実行中トランザクションから見えるかを追跡するデータを保持しており、可視性マップによって対象のページが全てのトランザクションから可視であることを確認できるとヒープアクセスを省略しIndexに含まれている情報だけでデータ取得ができることを意味します。
そのためここでは可視性マップを更新するために、VACUUMを行ってから実行計画を確認します。
-- 可視性マップを更新する
VACUUM;
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Nested Loop (cost=0.29..3390.00 rows=10000 width=12) (actual time=0.042..12.611 rows=10000 loops=1)
-> Seq Scan on tablea ta (cost=0.00..145.00 rows=10000 width=8) (actual time=0.013..0.962 rows=10000 loops=1)
-> Index Only Scan using idx_tablec_tablea_id on tablec tc (cost=0.29..0.31 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=10000)
Index Cond: (value = ta.value)
Heap Fetches: 0
Planning Time: 0.120 ms
Execution Time: 13.006 ms
わずかにパフォーマンスの改善が見られますが、そこまで差分は見られないようです。
Hash
Hash結合は、一方のテーブルに対してハッシュテーブルを作成し、もう一方のテーブルの結合キーをもとにハッシュ関数で演算を行い、一致するレコードを探し出す方法です。このため、計算量はO(M + N)となります。これは、両方のテーブルを1回ずつ走査するだけで済むためです。(ただしハッシュ衝突やメモリ不足になる場合を除く)
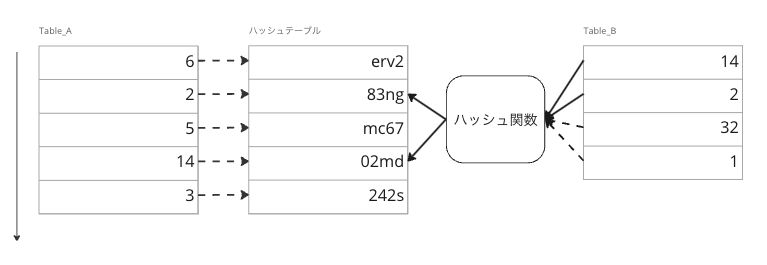
Hash結合の主な特徴は、ハッシュテーブルを作成するためにメモリを多く消費することです。PostgreSQLでは、この目的のためにwork_memというメモリ領域が使われます。この領域はソートやハッシュなど特定の処理でのみ利用される作業領域です。
この結合はNested Loopにて内部表にインデックスが存在しない場合、もしくは大規模なデータを扱う場合に利用を検討するのが適切です。Hash結合はNested Loopに比べて消費するメモリ量が大きいため、OLTP(Online Transaction Processing)処理に不向きである特徴があります。一方で大規模なクエリ同士の結合や、バッチ処理などOLAPのようなクエリ環境では、特にパフォーマンスを発揮しやすい結合となっています。
Hash結合の欠点としては、先にアクセスしてハッシュテーブルを作成する等の必要な準備を行うビルドフェーズ(Build Phase)と、後でアクセスしながら結合を実行する検証フェーズ(Probe Phase)という2つのフェーズが分かれており、ビルドフェーズが終わるまでレスポンスが返せないため、レイテンシー(応答時間)が高く、リアルタイム性が求められるクエリにはあまり適していません。
Hash結合を使用する際に注意すべき点は、work_memが十分でない場合です。メモリが不足すると、PostgreSQLは一時的にディスク領域を使用してスワップを行うため、パフォーマンスが大幅に低下する可能性があります。適切なwork_memの設定は、Hash結合のパフォーマンスに直接影響を与えます。
以下の例を確認してみましょう。
-- メモリ設定の変更
ALTER SYSTEM SET work_mem = '10MB';
SELECT pg_reload_conf();
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Hash Join (cost=259.02..529.93 rows=9512 width=12) (actual time=3.311..5.187 rows=10000 loops=1)
Hash Cond: (ta.value = tc.value)
-> Seq Scan on tablea ta (cost=0.00..140.12 rows=9512 width=8) (actual time=0.013..0.433 rows=10000 loops=1)
-> Hash (cost=140.12..140.12 rows=9512 width=4) (actual time=2.982..2.983 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
-> Seq Scan on tablec tc (cost=0.00..140.12 rows=9512 width=4) (actual time=0.007..0.928 rows=10000 loops=1)
Planning Time: 0.117 ms
Execution Time: 5.572 ms
tableAとtableCに10000件ずつデータを挿入し、実行計画を確認するために何度か検証しましたが平均6msほどでした。
続いてwork_memを0.1MB設定して検証してみます。
-- メモリ設定の変更
ALTER SYSTEM SET work_mem = '0.1MB';
SELECT pg_reload_conf();
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tB.value
FROM tableA tA
JOIN tableB tB ON tA.value = tB.value;
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Hash Join (cost=297.02..681.93 rows=9512 width=12) (actual time=3.963..12.743 rows=10000 loops=1)
Hash Cond: (ta.value = tc.value)
-> Seq Scan on tablea ta (cost=0.00..140.12 rows=9512 width=8) (actual time=0.012..1.119 rows=10000 loops=1)
-> Hash (cost=140.12..140.12 rows=9512 width=4) (actual time=3.621..3.623 rows=10000 loops=1)
Buckets: 4096 Batches: 8 Memory Usage: 75kB
-> Seq Scan on tablec tc (cost=0.00..140.12 rows=9512 width=4) (actual time=0.013..1.335 rows=10000 loops=1)
Planning Time: 0.329 ms
Execution Time: 13.181 ms
上記は数値が13.181 msとなっています。
実行計画にBatchesがありますが、このBatchはハッシュテーブルがメモリに収まりきらない場合にデータを分割するための単位です。work_memには1つのBatchのみが割り当てられていますが、これが1を超えると一時ファイルとして書き込まれます。これがTEMP落ちです。
TEMP落ちとはメモリが足りなくなったときにストレージのTEMP領域にスワップすることで生じ、これが先ほど言及したパフォーマンス低下に影響します。
work_memを10MB である時に比べBatchは8となっており明らかに実行時間が長くなっています。効率的に動作する場合は O(M + N)の計算量ですが、メモリ不足等が起こると期待したパフォーマンスにならない場合が起こり得ます。
ちなみに、Nested Loopで同じデータ量の結合を検証してみましたがTEMP落ちが起きているHash結合と比べてそこまでパフォーマンスが良いとは言えませんでした。100万件、1000万件のレコードを入れて検証してみましたが結果は一緒で、この辺は別の記事でNested Loop結合のパフォーマンスがHash結合に結合に劣後している点について調べて、まとめてみたいと思います。
-- ハッシュ結合とマージ結合をOFFにする
SET enable_hashjoin = OFF;
SET enable_mergejoin = OFF;
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Nested Loop (cost=0.29..3232.62 rows=9512 width=12) (actual time=0.194..15.787 rows=10000 loops=1)
-> Seq Scan on tablea ta (cost=0.00..140.12 rows=9512 width=8) (actual time=0.113..2.573 rows=10000 loops=1)
-> Index Only Scan using idx_tablec_tablea_id on tablec tc (cost=0.29..0.32 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=10000)
Index Cond: (value = ta.value)
Heap Fetches: 0
Planning Time: 2.392 ms
Execution Time: 16.436 ms
Sort Merge
最後に紹介するのはSort Merge結合です。Merge Joinとも呼ばれます。この結合は結合対象のテーブルをそれぞれ結合キーでソートし、一致する結合キーを走査するというものです。
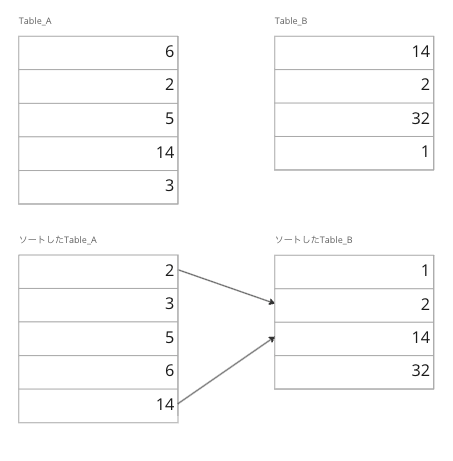
Sort Merge結合の場合、事前にデータを事前にソートするためにHash結合で扱ったようにwork_mem が十分なサイズでない場合、TEMP落ちを起こしてしまいパフォーマンスが著しく低下してしまいます。逆にいうとテーブルのデータが事前にソート済みの場合ソートステップが不要となり、よりパフォーマンスが良くなります。そのため、インデックスを貼ることができればデータのソートが不要になり、Sort Merge結合において理想的な状態を作り出すことができます。
tableBのvalueにインデックスを貼っていない場合は以下の通りです。
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tB.value
FROM tableA tA
JOIN tableB tB ON tA.value = tB.value;
---------------------------------------------------------------------------------------------------- 実行計画
Merge Join (cost=1618.77..1818.77 rows=10000 width=12) (actual time=7.768..12.168 rows=10000 loops=1)
Merge Cond: (ta.value = tb.value)
-> Sort (cost=809.39..834.39 rows=10000 width=8) (actual time=3.286..3.724 rows=10000 loops=1)
Sort Key: ta.value
Sort Method: quicksort Memory: 853kB
-> Seq Scan on tablea ta (cost=0.00..145.00 rows=10000 width=8) (actual time=0.057..1.987 rows=10000 loops=1)
-> Sort (cost=809.39..834.39 rows=10000 width=4) (actual time=4.443..5.771 rows=10000 loops=1)
Sort Key: tb.value
Sort Method: quicksort Memory: 853kB
-> Seq Scan on tableb tb (cost=0.00..145.00 rows=10000 width=4) (actual time=0.030..2.006 rows=10000 loops=1)
Planning Time: 0.866 ms
Execution Time: 12.895 ms
上記を見てわかる通りtableAとtableBともにソート処理が走ってから、マッチングが行われています。この場合tableAの行数がA、tableBの行数がBだとするとそれぞれの計算量は実行計画からわかるように、クイックソートなのでO(A * log(A)) 、O(B * log(B)) になります。その後各テーブルの全行を1回ずつ見ることからO(A + B) の計算量が加わり合計で、O(A * log(A) + B * log(B) + A + B)となります。オーダー記法では最も影響する項に着目するため、全体としてはO(A * log(A) + B * log(B))の計算量となります。
続いてインデックスを貼っているtableCとの結合ケースを見てみましょう。
-- 実行計画
EXPLAIN ANALYZE
SELECT tA.id, tA.value, tC.value
FROM tableA tA
JOIN tableC tC ON tA.value = tC.value;
--------------------------------------------------------------------------------------------------
Merge Join (cost=809.68..1290.67 rows=10000 width=12) (actual time=2.995..6.978 rows=10000 loops=1)
Merge Cond: (tc.value = ta.value)
-> Index Only Scan using idx_tablec_tablea_id on tablec tc (cost=0.29..306.29 rows=10000 width=4) (actual time=0.013..1.004 rows=10000 loops=1)
Heap Fetches: 0
-> Sort (cost=809.39..834.39 rows=10000 width=8) (actual time=2.973..3.485 rows=10000 loops=1)
Sort Key: ta.value
Sort Method: quicksort Memory: 853kB
-> Seq Scan on tablea ta (cost=0.00..145.00 rows=10000 width=8) (actual time=0.011..1.111 rows=10000 loops=1)
Planning Time: 0.238 ms
Execution Time: 7.613 ms
いくらか実行時間が短くなっていることがわかるかと思います。また、tableBの時ではソートしている処理がtableCとの結合ではIndex Only Scanだけで済んでいます。今回のケースではテーブルの一方のみIndexを貼っている検証でしたが双方ともIndexを貼っている場合には、さらにソート処理をスキップすることができ更なるパフォーマンス改善が期待できます。
この場合ソート処理が行われないため、先ほどソートされていないSort Merge結合で表現していた計算量がO(A + C) にまで減少します。
3つの結合アルゴリズムを比較した場合
3つのアルゴリズムのパフォーマンスを比較すると以下のようになるようです。(以下のケースは特定の状況を示すものであり、常に以下のパフォーマンスとなるわけではありません)
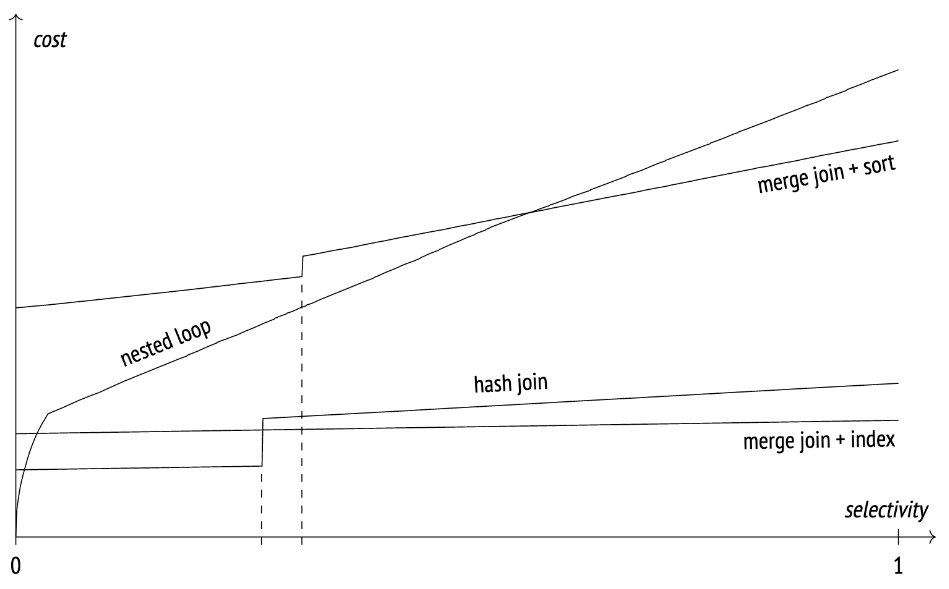
引用: Queries in PostgreSQL: 7. Sort and merge
横軸のselectivityとは選択率を意味し、これは特定の列の値を指定してテーブル全体からどれくらい絞り込むことができるかという割合です。これが1の場合100件のデータからある値を走査した場合、100件全てがマッチしてしまうことを意味します。一般に選択率が低いほどインデックスを貼った時のパフォーマンスが良くなります。
選択率の観点だと、低ければ低いほどNested Loop結合のパフォーマンスがよいことがわかります。途中階段状になっている箇所はTEMP落ちが生じたところを示しています。選択率が多いと結合する結果セットが大きくなったり、ソート対象の行がメモリを圧迫することでメモリ不足を引き起こしやすくなってしまうことが理由です。
選択率が高くなるにつれてHash結合やSort Merge結合のコストがNested Loopと比べて低くなるため、1つの結合アルゴリズムを選ぶ基準として知っておくと良いでしょう。
またデータ量によってはメモリ量が不足し、ディスクへのI/Oが発生することでパフォーマンスが著しく低下することも否めません。そうなった場合にはNested Loopを改めて利用することを検討すると良いと思います。
まとめと今後の意気込み
今回3つの結合アルゴリズムを調べてみて、それぞれのメリットデメリットやインデックスがパフォーマンスに多大な影響を与えることを改めて認識しました。一方で、インデックスやアルゴリズムに対する理解をより深めていく必要があるなと感じ、次に書きたい記事のトピックも見つかりました。(こちらは後日また投稿しようと思います)
今回の記事が他のエンジニアの方の学びのきっかけになれば幸いです。
参考文献
- Egor Rogov. “Queries in PostgreSQL: 7. Sort and merge”. Postgres Pro. 2022.10.06. https://postgrespro.com/blog/pgsql/5969770. (参照 2024.06.24)
- 村上 直広. “PostgreSQL Index Only Scan 奮闘記 その1”. TECHSCORE BLOG. 2013.5.27. https://www.techscore.com/blog/2013/05/27/postgresql-index-only-scan-奮闘記-その1/. (参照 2024.06.25)
- 布目 綾子. “基礎から理解するデータベースのしくみ(4)”. 日経クロステック. 2006.01.20. https://xtech.nikkei.com/it/article/COLUMN/20060111/227102/. (参照 2024.06.24)
- ぱと (id:pato_taityo). “PostgreSQL実行計画のハッシュノードに出力されるバケット数とバッチ数の解説”. ぱと隊長日誌. 2017-05-29. https://taityo-diary.hatenablog.jp/entry/2017/05/29/055949. (参照 2024.06.24)
- Fujitsu. “チューニング ~ SQLチューニングを実施する ~”. PostgreSQLインサイド - ソフトウェア : 富士通. 2021.01.22. https://www.fujitsu.com/jp/products/software/resources/feature-stories/postgres/article-index/implement-sqltuning/. (参照 2024.06.24)
- MySQL. “8.2.1.4 ハッシュ結合の最適化”. MySQL. 更新日不明. https://dev.mysql.com/doc/refman/8.0/ja/hash-joins.html#:~:text=MySQL 8.0.20 以降では、ブロックネストループのサポートが削除され、以前にブロックネステッドループが使用されていた場所では、サーバーはハッシュ結合を採用します。. (参照 2024.06.24)
- ミック. “第6章 結合”. SQL実践入門. 池田大樹著. 東京. 技術評論社. 2021. p.177-198, p.300-302.

Discussion