はじめに
みなさん、DBをバージョンアップして酷い目にあったことありますよね?
先日ログラスの本番データベースのバージョンアップをしたのですが、Site Reliability Engineeringの観点で非常に良いトライが出来たので共有します。
PostgreSQLのロジカルレプリケーションを使って、データを最新に保った新旧のインスタンスを用意した。結果的に安心安全にバージョンアップ作業ができました。
データベースのバージョンアップはサービス運用やっていくと絶対にやらないといけない作業ですが、影響範囲は甚大です。この記事では工夫することで、何か問題が起こってもすぐに切り戻すことが出来るという話をします。
このメンテを通じて、ログラスで利用していたAurora PostgreSQLをエンジンバージョン11.19(PG11)から15.2(PG15)にバージョンアップしました。
バージョンアップ作業の何が難しいのか?
誤解を恐れずに言うと、作業自体はそんなに難しくはありません。ただ事前に「何も起こらないこと」を保証するのが難しいのです。
難しいポイントはいくつかあると思いますが、中でも「挙動が変わっていないことを保証しづらいこと」「与える影響を把握しづらいこと」「問題が発覚するタイミングによっては切り戻しがしにくいこと」があると思います。
挙動が変わっていないことを保証しづらいこと
書くのは簡単ですが、挙動が変わらないことを担保することは難しいです。
「挙動が変わっていないこと」の定義は色々ありますが、今回は各開発チームにバグバッシュ的に触ってもらうことで挙動が変わっていないことを担保するという方針にしました。
事前の検証作業でバージョンアップによってソートの並び順が変わりうることが分かっていたので、「並び順」と「極端にレスポンスが遅くなるクエリがないか」というレビュー観点を伝えて取り組んでもらいました。
もしE2Eテストがプロダクト全体にあるプロダクトであれば、それらを通して問題がなければOKとすることができると思います。しかし、パフォーマンス劣化が起こらないことをE2Eなどで保証することは難しいので、触って動かして確認してもらうという工程は省きにくいと感じています。
与える影響を把握しづらいこと
影響を把握しづらいことは、結構厄介です。サービスが小さいうちはよいですが、サービスが大きくなってくると、思わぬところから参照されていたり、同じクエリでもバージョンによってはクエリの結果が変わったり(時にはエラーになったり)、パフォーマンスへの影響があったりと、影響を完璧に予測するのは困難です。またバージョンアップで性能が良くなれば良いですが、性能が良くならないこともあります。
今回はパフォーマンスへの影響は、過去に本番環境に流れていたクエリを新しいバージョンのインスタンスに投げて確認しました。

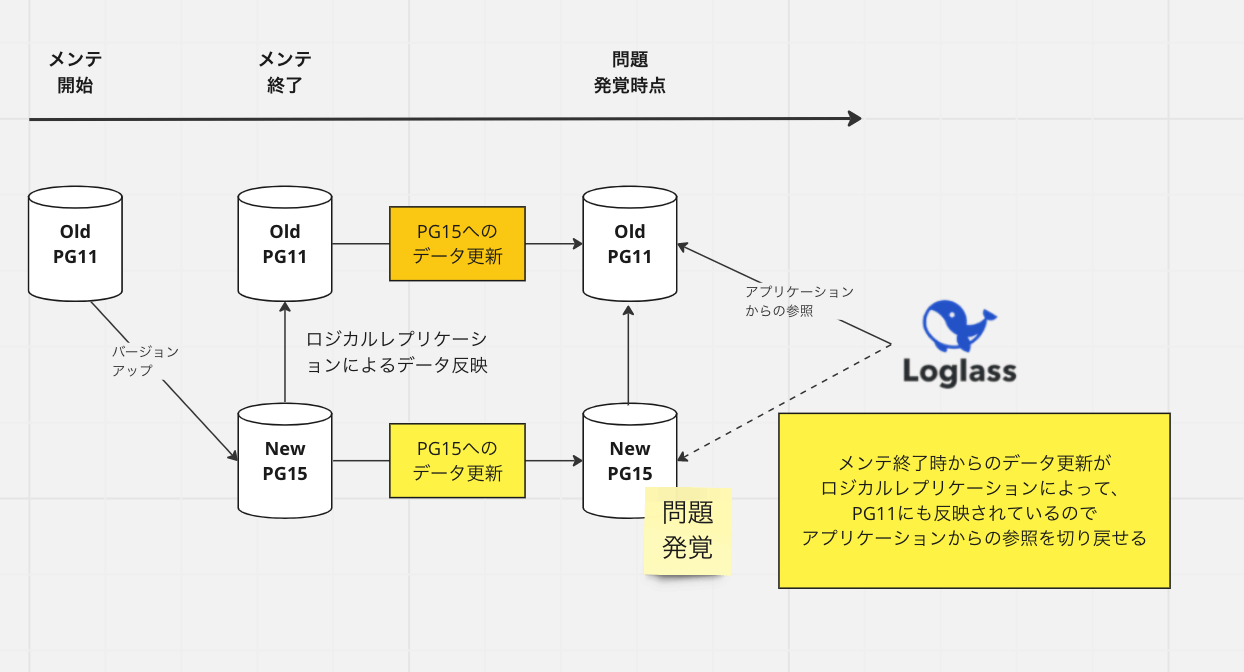
問題が発覚するタイミングによっては切り戻しができないこと
リリース後しばらくしてから問題が発見されるというケースがあります。そのときに切り戻しを行いたくても、データが更新されていて、切り戻しは困難になります。
そういう場合は、前に進める形で問題解決をすることになりますが、データが汚染されているケースなど、考えるだけでも「うっ」となる経験をしたことがある人もいるのではないでしょうか?(もちろん自分もやったことがあります)
この問題を図示するとこんな感じになります。

以上から、緻密に準備をしても、最終的に不確実性を無くせないこと、そして仮説検証に時間をかけ過ぎるのはコスパが合わないことがあるという話をしました。
最終的に残る不確実性にどう取り組んだのか?
常にサクッと切り戻しができれば実行してよいのではないか?と考え、新旧のインスタンスが常にデータ同期されていればいいと考えました。その手法として、今回はロジカルレプリケーションという手法を利用しました。
図示をするとこんな感じになります。先程の図との違いは、旧バージョンインスタンス(PG11)にもPG15のデータ更新が入っていることになります。この仕組みによって、常に同期が保たれ続けます。
ロジカルレプリケーションとは?
いわゆるリードレプリカを作るようなレプリケーション(ストリーミングレプリケーション)との違いは、レプリケーション元となるインスタンスとレプリケーション先のインスタンスの環境が、異なるバージョンでもレプリケーションが出来ることです。
今回はここに注目して、PG15に入る変更をPG11に反映して常に同期したバージョン違いのDBがあれば切り戻せると考えました。

ちなみにPostgreSQLについては富士通さんの以下の記事が非常に詳しいです。このメンテで非常にお世話になりました。そしてPostgreSQLを運用しているチームはこのサイトをすべて読みましょう。絶対に得るものがあります。
なぜロジカルレプリケーションを使おうと思ったのか
それはアプリケーションを修正するのではなく、インフラレイヤーで変更を吸収したかったからです。
新旧の両方のデータベースにWriteするように、アプリケーションを修正することもできました。ですが、その手法はアプリケーションに手を入れねばならず、開発チームの機能開発の時間を奪ってしまいかねません。なのでできればインフラレイヤーだけで安全にバージョンアップが出来る環境を作れないか?と思い、この手法を選択しました。
実際の作業
実際には深夜にメンテナンスの時間を確保して、作業を行いました。以下が作業手順になります。
- メンテナンスモードへ移行
- PG11のスナップショットを取得
(PG11をPG15にバージョンアップするので、PG11はスナップショットから作り直しました) - PG11(旧バージョン)をPG15(新バージョン)へバージョンアップ
- PG11のスナップショットからDBを復元
- レプリケーション元のインスタンス(PG15)に、ロジカルレプリケーションのpublicationを設定
psql -h ${PG_15_HOST} -c "CREATE PUBLICATION engine_upgrade FOR ALL TABLES";
- レプリケーション先のインスタンス(PG11)に、ロジカルレプリケーションのsubscriptionを設定
psql -h ${PGHOST_11_BAK} -c "CREATE SUBSCRIPTION engine_upgrade CONNECTION 'host=${PG_15_HOST} port=${PGPORT} dbname=${PGDATABASE} user=${PGUSER} password=${PGPASSWORD}' PUBLICATION engine_upgrade with (copy_data = false)"
- 動作確認(PG15への書き込みがPG11に反映されていることを確認)
- メンテモードを解除してサービスイン
この構成で得たもの
まずは作業者の安心感が違います。何か問題が起こっても、DNSの切りかえだけで切り戻せるという安心感は何事にも代えがたく、当日も安心感たっぷりで作業することができました。
また将来的にもこうすればできるよねという実績をチームで得ることが出来ました。この経験を手順書として、将来のSRE組織に活かしていきます。
その他
ここがこの記事のメインかもしれません。
ここまでロジカルレプリケーションの話を書いてきましたが、本番に至るまでに様々な挑戦をしてきました。記事の分量の関係で言いたいことがボヤけてしまうので、書ききれない事項をトピックだけ書いておきます。
書ききれなかったトピックとしては、以下のようなものがあります。
DDLはレプリケーションできないこと
DDLはロジカルレプリケーションの対象ではないので、PG15へのDDL反映はPG11へ反映することができません。
リリース日程を調整して、新バージョン(PG15)に問題がないことを判断した上で、旧バージョン(PG11)の削除を行いました。都度開発チームと連携しつつ、運用しています。
バグバッシュを行ったこと
上記の 挙動が変わっていないことを保証すること にも書きましたが、新バージョン(PG15)になっても挙動が変わらないよね?ということを、SREチームが担保することは難しいです。(仕様をすべて知っているわけではないため)今回は各開発チームにお願いしてバグバッシュを行ってもらいました。
手法としては検証環境を前もって新バージョン(PG15)に切り替えておいて、QAチームに手伝ってもらいながら行いました。
ロジカルレプリケーションの設定でお金を少し使ってしまったこと
ロジカルレプリケーションを利用し始めるときに、レプリケーション元と先でデータが一致しているときは、オプションに copy_data = false をつけることが出来ます。このオプションを指定すると、差分レプリケーションですみます。レプリケーション完了までの時間を短縮することができて、データ転送量も抑えることができるという知見を得ました。
Aurora Postgresではメジャーバージョンのジャンプアップはマイナーバージョンによってはできないこと
AuroraはPG11→PG15というようなジャンプアップした、メジャーバージョンアップが可能ですが、更新元のPG11の最新バージョンに予めバージョンアップしていないと、メジャーバージョンを超えるジャンプアップができませんでした。
【参考】
Amazon Auroraでメジャーバージョンアップグレードで中間メジャーバージョンをスキップ出来るようになりました
- この記事に載っている変更はterraformで行ったこと
実際にやってみて得た知識は人に紐付きます。コード化やドキュメント化してみても、チームへのインストールが完了したとはならないところが難しいところです。こういった生きた知識をチームのものとし、更には会社のものにしていくことが運用業務の難しさと醍醐味だと感じています。
これらの1つずつの積み重ねが弊社のSite Reliabilityを支えていると感じています。
その後の話
特に切り戻しが発生することなく、無事に旧インスタンスを削除することができました。事前の準備はしましたが、使われなくてホッとしています。この何もなくてよかった瞬間を味わうことができるのもSREの醍醐味ですね。
個人的な感想
ログラスはB2Bサービスで、膨大なトラフィックを捌くtoC向けサービスとはちょっと毛色が違うかもしれません。
しかし、サービスの成長に伴い、お客様からの要求が高くなっていくのを肌で感じています。また、これから経営管理loglassだけではなく、複数のプロダクトのリリースが控えています。そうなった時にプロダクトを超えて高い品質水準を保っていくことは非常にチャレンジングだと思いますし、チームとして知見を貯めていける環境を作っていかないとビジネスが大きくコケてしまうことに繋がると思っています。
今回のメンテのように、問題が起こったときにサクッと切りもどせる態勢をとっておくことは、Site Reliabilityを高めるEngineeringであると考えています。B2Bサービスでも、「Site ReliabilityをEngineeringを通して高めて行く」 を、これからも楽しく追求していきたいと思っています。
We Are Hiring
最後にお約束のやつです。一緒にこういう作業を通してプロダクトづくりをしてくれる仲間を募集しています。
Twitter(@shin1988)をやっていますので、カジュアルにお声がけください。
このバージョンアップ作業をリードしてくれた原はRustの本も出版しており、一緒に強いチームを作っていきたいと思っています。

Discussion