はじめに
サービスが突然ダウンして障害が発生した経験はありますか?
最近、ログラスでは、アプリケーションが大量のメモリを使用し、「java.lang.OutOfMemoryError」エラーが発生し、サービスがダウンする障害が発生しました。
問題を解決するには、シンプルに 「原因を特定する」 -> 「解消する」 というサイクルを積み重ねていくことが重要であると今回の対応で学びました。
しかし、シンプルであるがゆえに、自身の調査方法のミスや知識不足による不十分な調査が、根本的な原因ではない箇所の修正につながり、なぜか改善しない現象が発生しました。
この記事では、試行錯誤の末に失敗した対応と、その後に問題を解決するために採用した対応策について説明しています。
弊社には、JVMに詳しいメンバーがいたため、誤りに気付くことができました。同じミスをする人が減るように、この経験が参考になれば幸いです。
前提
ログラスで使っている技術
- 言語
- Kotlin
- フレームワーク
- Spring Boot
- インフラストラクチャ
- AWS
- ECS on Fargate
- AWS
※ 今回の記事内容に関係のある技術のみ記載
どんな障害だったか?
- アプリケーションでメモリを大量に使用する処理が実行
- この結果、Full GC(ガベージコレクション)が実行
- 「java.lang.OutOfMemoryError: Java heap space」エラーが発生
- このエラーにより、アプリケーションは異常終了
- ヘルスチェックが通過しなくなり、結果としてサービスがダウン
失敗編
原因調査と修正を行う
まず、ローカル環境で問題を再現し、調査を開始しました。
Intellj IDEA プロファイリングツールを活用し、メモリの割り当てを詳細にみていきました。
今回の原因としては、DBから値を取得後、データを加工する処理をする処理の一部で、メモリが特に多く割り当てられておりメモリリークを起こしていることがわかりました。
そのため、修正方法としては、その加工処理直前に不必要なデータを間引く対応をいれました。
修正完了し、解決!と思い、リリース前のQAテストを実施。 事象が再発、リリースの取り止めました。
なぜ、原因調査に失敗していたのか?
原因は2点ありました。
- 実際にサービスダウンした事象を再現せず、原因調査を行ったこと
- Intellj IDEA プロファイリングの使い方を間違えていたこと
Intellj IDEAとても便利で、ローカル環境で気軽にアプリケーションのCPUやメモリ使用量を分析可能です。しかし、利用するほうがしっかり理解した上で使わないと、適切な原因が見つからない可能性があります。
公式のドキュメントにも記載がありますが、「多くの割り当てが必ずしも問題を示しているわけではないということ」ということを理解していませんでした。
ここで注意すべき重要なことは、多くの割り当てが必ずしも問題を示しているわけではないということです。メモリリークは、割り当てられたオブジェクトが実行中のアプリケーションのどこかから参照されているためにガベージコレクションできない場合にのみ発生します。割り当てプロファイリングはガベージコレクションについて何も教えてくれませんが、それでもさらに調査するためのヒントを得ることができます。
出典: https://pleiades.io/help/idea/tutorial-find-a-memory-leak.html#allocation-profiling
正しい原因を突き止められないと、改善したつもりだけど、何故か解決しないという状況に陥る可能性が高くなります。
解決に向けてやったこと
テスト見直しと拡充
問題解決の最初のステップとして、テストの見直しと拡充を実施しました。
機能追加によって漏れがないか、変更が必要なテストがないかを確認し、必要な修正を加えました。
テストのお陰でデグレしてないことやユーザの振る舞いが変わっていないことを担保でき、安心してリリースできました。
特に今回お世話になったのがスナップショットテストでした。
スナップショットテストの詳しい記事については、弊社のメンバーが書いた以下の記事がおすすめです!
本番のHeapSizeを確認する
本番環境で実際に利用されているアプリケーションのHeapサイズがどの程度割り当てられているかを確認しました。具体的な設定例は以下の通りです。
-XX:MaxHeapSize=6150m
-XX:+ExitOnOutOfMemoryError
この設定では、Heapサイズが約6GBに割り当てられています。
割り当てられているHeapサイズを超えてしまう可能性のある原因を実際に見ていきます。
事象を再現し、HeapDumpを取得する
HeapDumpとは、特定の瞬間のメモリスナップショットのことで、問題の特定に役立ちます。
ローカル環境では、IntelliJ IDEAを使用してHeapDumpを確認することができます。
また、デバックモードで起動しブレークポイントを利用するとその時のHeapの状態が見れるので原因調査するのに便利でした。
検証環境では、Spring Bootのactuatorを利用してHeapDumpを取得することができます。
詳しい取得方法については、以下の公式ドキュメントをご参照ください。
原因を特定する
検証環境で、取得したHeapDumpは、Intellj IDEAでも見ることができます。
Profiler > "Open Snapshot" からファイルを選択するだけです。
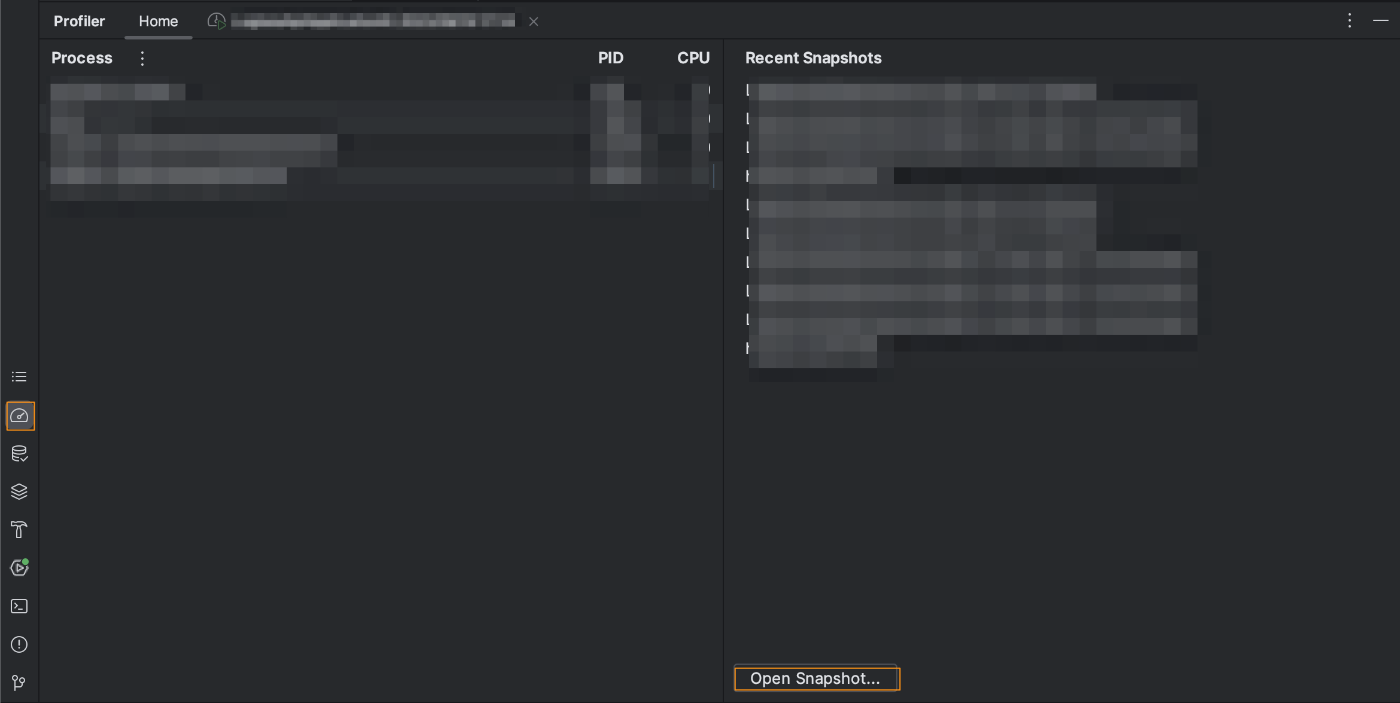
インスタンス数が一番多いものから順に並んでいます。
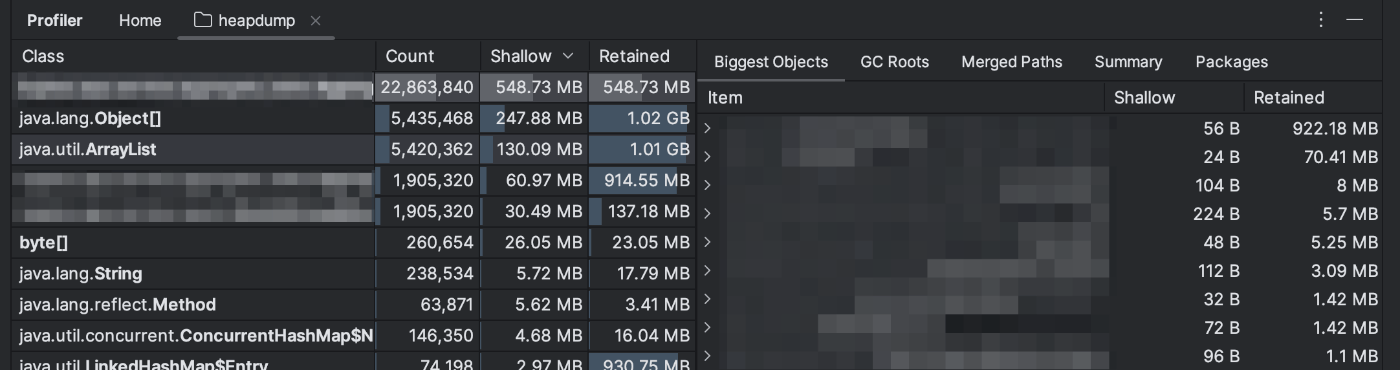
Shallow Size
オブジェクト自体を格納するために割り当てられたメモリの量。このオブジェクトによって参照されるオブジェクトのサイズは含まれません。
Retained Size
オブジェクトの浅いサイズと保持されているオブジェクトの浅いサイズの合計(オブジェクトはこのオブジェクトからのみ参照されます)。つまり、保持されるサイズは、このオブジェクトをガベージコレクションすることで再利用できるメモリの量です。
出典: https://pleiades.io/help/idea/read-the-memory-snapshot.html
検証環境で取得したHeapDumpを分析すると、Object数が多く、合計で2286万のObjectが使用されており、その結果、約548MBのメモリが消費されていることがわかります。
2286万のObjectを詳細に分析することで、具体的にどの種類のObjectが作成されているかを確認しました。
以下はその詳細です。
これを見た私の感想

何事も積み重なると膨大なメモリ消費を引き起こすこと をこの経験から学びました。
解消する
上記の通り、大量のObjectを生成してしまっていることが原因でした。そのため、メモリにのる前に不要なObjectを生成しないようにする対策を実施しました。
アプリケーションの特性上、大量のObjectを生成してしまう可能性のある機能だったので、それを意識せず実装してしまうと今回のような影響が出てしまいます。
この問題に対する本質的な変更は、filter処理を追加するだけでした。
.filter { it.hasId },
最初の修正では、DBから値を取得してきた時点ですでにメモリにデータがロードされ、加工する前に大量の不必要なObjectが生成されてしまっていました。なので、加工処理にすらたどり着くことができず、結果意味のない対応となっていました。
改善策として、データ取得後に不必要なObjectを生成しないように変更を加えることが成功の要因でした。
そしてボトルネックは移りゆく
あとは、改善したアプリケーションで、 「事象を再現し、HeapDumpを取得する」-> 「原因を特定する」 -> 「解消する」 というサイクルを着実に繰り返すことで、問題を1つ1つ解決していきました。
1つ解消すると、またそのあとのボトルネックが出てきて、「1日1改善」で進めていきました。
小話
ログラスでは、ULIDを利用していますが、ULIDは、メモリ使用量が「12B」です。
たかが12Bだと思っていましたが、膨大な量を取り扱うとなると、それだけでもMBやGBに至ってしまう場合もあるということに今回始めて気づかされました。
当たり前だけど、それすらもメモリを食いつぶす原因になることがあります。
| ULID数 | B | KB | MB |
|---|---|---|---|
| 1 | 12B | 0.012KB | |
| 10 | 120B | 0.12KB | |
| 100 | 1,200B | 1.2KB | |
| 1,000 | 12,000B | 12KB | |
| : | |||
| 1,000,000 | 12,000,000B | 12,000KB | 12MB |
最後に
今回のJVMのメモリ改善とはいっても、 リファクタリングですよね? とメンバーが言っていて、まさにそうだなと実感したので、メモリ改善こわくないよ!!と思えたのがとてもよかったです。
今回修正は、不必要なオブジェクトを作らないように変更していった話でしたが、今後は必要なオブジェクトをより軽量化していく対応をする必要があったりと、まだまだ課題は沢山ありとても身が引き締まります!
最後まで読んでいただき、ありがとうございました。
ログラスに是非興味を持った方はこちら
▽採用ポジション一覧
- Webアプリケーションエンジニア
- QA
- SRE

Discussion