初めまして、ログラスのKagaya(@ry0_kaga)です。
ここ1年弱の間はAIプロダクトの新規立ち上げに勤しんでいました。
アイディア・営業スライドだけから始まり、MVPリリース、更新まで回すことができましたが、その過程で色々な反省や学びがあります。
今回はその中でも評価・Evalにフォーカスして、体験・失敗談についてセルフ振り返りをしてみます。
LangChain Interrupt 2025でAndrew Ng氏は下記のような指摘をしています。
「Evalsについて人々は話しますが、なぜか実行しません。…ほとんどのチームは、体系的な評価を導入するのが遅すぎるように感じますね。」
Evalや評価駆動開発(Evaluation-Driven Development)[1]の重要性は当然知っていたつもりでしたが、私も御多分に洩れず、新規プロダクト開発でバタバタすると、どうしても体系的な評価の導入が遅れてしまうという体験をしました。
リリース前
| 項目 | 概要 | 効果 |
|---|---|---|
| 初期評価システム | Slack + スプレッドシート + N1エキスパート | ミニマムに検証 |
| ドメイン理解 | 理解→共感→憑依の3段階アプローチ | エンジニアでも評価者に |
| 各ステップのトレース | Agentic Workflowの各ステップを独立評価 | 問題箇所の特定が容易 |
| チーム巻き込み | Langfuse活用、営業メンバーも直接調整 | MVPまでのスピードアップ |
| 自動化 | LLM-as-judge早期導入、リスクで使い分け | 初期から品質チェック自動化 |
| スキルギャップ | AIワークフロー設計の経験不足 | リソース配分の失敗 |
Slack・スプシ・N1フォーカスの初期評価
まず最初に行ったのは社内検証でした。AIレビューの体験がどれだけ意味があるのか、また現実的にどの程度の精度が出るかをミニマムに検証することが目的です。
とにかくシンプルに始めました。
やったこと:
- Slackボットで即座に実行する環境
- スプレッドシートで結果を記録・比較
- 社内のN1メンバーにフォーカスして一緒に評価
ドメインエキスパートではないエンジニアでは気づけない観点も多々あるため、社内のN1のドメインエキスパートと密に連携しつつも、自分自身で実際にアノテーションを行いながら、観点の抽出や獲得に努めました。
ツールは原始的でしたが、ミニマムな工数で、スピーディに改善点の発見と磨き込みを行うことができました。
雑なEvalsから始めるEval Driven Development
「最初はほとんど役に立たないような雑なEvalsを作り、それがどう機能するかを見て、『このEvalsはダメだな。こうすれば修正できる』と考えて改善を重ね、より良いものにしていくのです。」
20分で作れる簡易的なEval、人間の目視評価を補完する程度から開始して、反復的に改善していくアプローチです。
- 完璧な評価システムを待つより、80%の精度でも今すぐ始める
- エラーの影響が小さい部分から自動化を始める
- 人間の判断を完全に置き換えるのではなく、補完する
AIジャッジによる見逃しが許容できない点は、後述しますが、人間による評価も駆使しました。
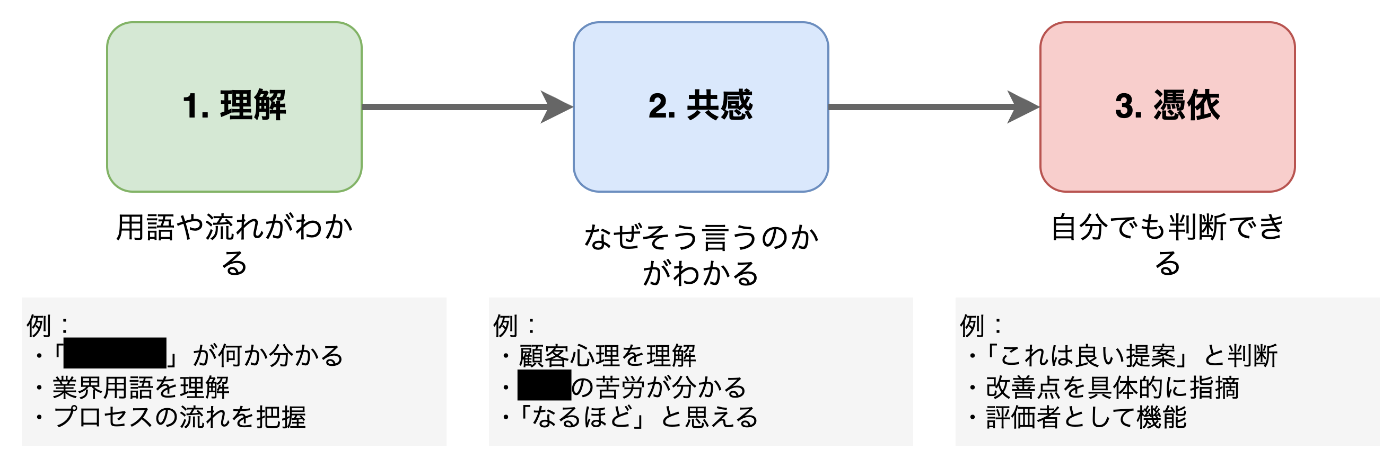
理解・共感・憑依の三段階を目指して自らアノテーション
特に初期は対象ドメイン・世界を理解するために、テストデータでの評価やデータセット作成を自らの手で集中的に行い続けました。
- 理解:用語や流れがわかる
- 共感:なぜそう言うのかがわかる
- 憑依:自分でも判断できる
憑依レベルまで達すれば、エンジニアでも評価者になれます。
(とはいえ、そこまでの道のりは長く、実際に今も自信を持って判断できるレベルではないです)
プロンプトの細分化とエンドツーエンドでのトレース
私たちのシステムは複数のステップで動作していました。いわゆるAgentic Workflowと呼ばれるような形です。
コストやリソースの関係でエンドツーエンドの評価を重視してはいましたが、各コンポーネントを独立して追跡・評価も可能にしていたため、どこで問題が起きているかを特定しやすかったのは嬉しいポイントでした。
- どの部分が効いているか追跡可能
- 変更の影響範囲が明確
- 各ステップでA/Bテストが容易
チーム全体での取り組み
プロンプト管理・トレーシング基盤としてLangfuseを検証目的で採用し、何なら一部のビジネスメンバーには直接Langfuseを触ってもらっていました。
(エンジニアの都合で、負荷をかけた点ではあるので、申し訳ない気持ちはあります。特にLangfuseのキャッチアップ)
またプロダクトの性質上、メタプロンプトとも呼ぶべき、一定の範囲内でプロダクト上からプロンプトを変動させる仕組みを取っていたため、AIに詳しい営業メンバーが直接プロンプトをチューニングしてもらうことができました。
- ビジネスサイドのメンバーがUIから直接プロンプトの振る舞いを調整
- エンジニアはコンテキストエンジニアリングに集中
誰でも簡単にAIの挙動と関連コンテキストを確認できるシンプルなツールの重要性を実感しました。
また、チーム全体でLLM/プロンプト周りのQCD(Quality, Cost, Delivery)を分担することにも繋がり、特にMVPリリースまでのスピードアップと品質担保には大きく貢献したと感じています。
早期からのLLM-as-judge活用
初期からLLM-as-judgeは活用を行なっていたおかげで、単純なキーワード一致では評価できないニュアンスのある側面も、一定は自動化できており、特に初期はそれなりにワークしていました。
LLM-as-a-Judgeは影響度で導入にグラデーションをつけながら始めています。
| リスクレベル | 例 | 失敗時の影響 | 評価手法 |
|---|---|---|---|
| 低リスク | サマリーの品質 | ・要約が不完全になる程度 ・担当が補完可能 |
AIジャッジを積極活用 |
| 高リスク | ・顧客の信頼を失う ・商談が破談 ・法的責任問題に発展 |
ヒューマンレビュー必須 (ビジネスメンバーと協働) |
また、初期フェーズは合成データ、データ生成にLLMを活用して評価プロセスを早々に開始。そこから実際のアノテーションや人の目を通したケースに差し替えていきました。
エージェントビルダーのスキルギャップ
Andrew Ng氏が指摘する通り、既存プロセスをAIワークフローに落とし込む点で試行錯誤を繰り返しました。
「タスクをどの程度の粒度でマイクロタスクに分解すべきか?そして、最初のプロトタイプを構築した後、それが十分に機能しない場合、どのステップの改善に注力すべきか?こうした一連のスキルセットを持つ人材は、まだ非常に少ないと思います。」
一方でアプリケーション自体の開発は止められません。シビアな期限やスコープが存在する中、AIワークフローの部分に工数やリソースを投下しきれなかったのは反省が残ります。
ここで想像以上にアプリケーション自体の開発に工数が取られ、評価システムへの投資ができなかったことが、リリース後に効いてきました。
リリース後
| 問題 | 原因 |
|---|---|
| 継続的評価の不在 | 初期システムから移行できず |
| スケールの壁 | 初期フォーカス以外のケースへの対応 |
| 更新の停滞 | 90%達成で満足してしまった |
継続的評価の不在によるリリース後の四苦八苦
初期の評価システム(Slack、スプシ、Langfuse)は悪くありませんでした。
しかし、プロダクション運用を見据えた評価システムへの移行が遅れました。
AIプロダクトは「何もせずとも壊れる」のです。
- モデルは変化する(ナーフ、アップデート)
- ユースケースは進化する
- 顧客の期待値は上昇する
スケールの壁と「良い」の定義は何か?
私たちの課題の一つは、評価基準(evaluation criteria)の定義が曖昧・認識が揃っていなかったことです。
例えば「初回採用面談のスコア」を判定するには、「良い初回採用面談とは?」についての徹底的な言語化や抽象化が欠かせません。
ドメインの深い理解なしに、品質や評価を語ることはできません。
また、初期は割り切ってN1~2にフォーカスし、結果として類似ケースでもそこそこの点数が取れていましたが、顧客や利用シーンが増えるにつれて追いつかないシーンが増えていきました。
- 製造業では機能するが、IT業界では精度が50%に低下
- 初回面談はOKだが、クロージングフェーズで問題続出
- 「良い提案」の定義が顧客ごとに異なる
O'Reilly『AI Engineering』で提唱されているような分類で自分たちのプロダクト・ドメインに合わせた評価の体系化と基準化がもう少し必要でした。
-
ドメイン固有の能力(Domain-Specific Capability)
- 業界用語の正確な使用
-
生成能力(Generation Capability)
- 事実との整合性(ローカル/グローバル)
- 提案の具体性と実行可能性
- 安全性(不適切な約束をしない)
-
指示追従能力(Instruction-Following Capability)
- 要求された形式での出力
- 文字数制限の遵守
- トーンの一貫性
「良い」の定義、最後に更新したのはいつですか?
一定満足した精度(例えば90%)に達しても、以降どうアップデートするか? に向き合う必要があります。
つまりもっと良い出力・観点を探し続けるということです。
LLM Judgeでスコアを出しても:
- そのスコアが本当に正しいのか?
- 顧客はそれで満足しているのか?
- もっと良い出力があるのではないか?
初期フェーズでOKとなった性能に満足し、継続的な改善が遅れてしまいました。
教訓
振り返ると、私たちは3つの溝に落ちていました。
| 名 | 状態 | 課題 |
|---|---|---|
| 理解の溝 | 「なんとなく動いている」で満足 | 何が失敗しているか見えない |
| 仕様の溝 | 「顧客に寄り添う」という曖昧な目標 | プロンプトで表現できない |
| 汎化の溝 | N1で成功すれば大丈夫 | 精度がバラバラ |
Day 1(いや、Hour 1)からの評価インフラ構築
簡易版から始めつつも、もう少し早く評価インフラをリッチに構築することです。
ゴールデンデータセットを作り、ドメイン固有の要件、品質、指示追従能力を測定する独自指標・基準を定義し、自動で評価を実行する。品質が閾値を下回ったら即座にアラートを飛ばす。
私たちがスプレッドシートでやっていたことを、もう少し早く、リッチに自動化すべきだったかもしれません、Eval Driven Development。
評価データのスライシング
全体の平均値だけでなく、データを細かく分けて評価する仕組みを初期から整備しておくと楽ができたなと感じます。
例えば商談・面談のケースで考えると、ブレイクダウンすると様々な属性や切り口が存在しています。
- 業界別:製造業 vs IT業 vs 小売業
- 面談フェーズ別:初回接触 vs 提案 vs クロージング
- 顧客規模別:エンタープライズ vs SMB
「全体では80%の精度だが、XX業の初回面談では50%」という問題を可視化・発見することができるかもしれません。

評価システムへの信頼維持
評価システムは作って終わりではありません。常に信頼性を保つ必要があります。
- 評価基準のドリフト対策
- 評価基準を見直し、ビジネス要件との乖離をチェック
- 「良いXXX」の定義が変わっていないか確認
- 新しいユースケースに対応する基準の追加
- 詳細な記録の重要性
- バイナリ判定(合格/不合格)+その理由を必ず記録
- 例:「不合格 - 競合他社名を間違えて記載」
- この記録が次の改善サイクルの貴重なインプットに
- 定期的なキャリブレーション
- 定期的にドメインエキスパートと評価基準の認識合わせ
- 同じサンプルを複数人で評価し、判定のブレを確認
- 評価者間の合意率(Cohen's Kappa)を測定
AIプロダクトにおいては、評価システムへの投資は、プロダクトへの投資と同じくらい重要です。
言語化力と傾聴力
もはやMoreというかやっていきの話です。
真面目に良い評価のためにも言語化力と傾聴力の必要性を実感しています。
言語化力とは、「なんとなく良い」を「なぜ良いのか」に変換する能力です。例えば、「この提案はちょっと違う」と言ったとき、「どこがどう違うのか」「理想的にはどうあるべきか」を評価基準として定義できる力。
傾聴力とは、ドメインエキスパートの本音を引き出す能力です。彼らは忙しい中で協力してくれています。短い時間で本質的なフィードバックを得るには、適切な質問を投げかけ、言葉の裏にある意図を読み取る必要があります。
まとめ
改めて、振り返って見ると、辿ってきた道が明確になります。[2]
| 種類 | 事象 | 具体例 |
|---|---|---|
| 理解の溝 | 何が起きているか把握できない | 「なんとなく動いている」 → 何が失敗しているのか、どう改善すべきか見えない |
| 仕様の溝 | 意図を指示に変換できない | 「顧客に寄り添う」 → どうプロンプトで表現する?顧客に寄り添うとは? |
| 汎化の溝 | 様々なケースに対応できない | 製造業OK → IT業界NG 初回OK → クロージングNG |
適切な仕組みがあれば、理解の溝では「何を見るべきか」が明確になり、仕様の溝では「何が良い出力か」が定義でき、汎化の溝では「どこで失敗しているか」が可視化されます。
評価は終わらない旅
当たり前ですがプロダクトは「作って終わり」ではありません。AIプロダクトはモデルの変化や進化にも対応する必要があります。
- 評価への投資に「早すぎる」ことはない
- 評価は「Nice to Have」ではなく「Must Have」
- 「後で改善」は「永遠に改善しない」と同義
- 評価への投資は、技術的負債の返済ではなく、資産形成
Andrew Ng氏の「20分でEvalsを作る」という言葉の通り、短い時間でもやれることはあります。
「木を切るのに忙しくて、斧を研ぐ時間がない」状態を避けるためにも、継続的に仕組みをアップデートする時間を怠ってはいけません。
あなたのチームでも、こんなことありませんか?「良さげに動いているのでOK」としていませんか?
今回は以上です!

Discussion