以前、【LT大会#7】LLMの活用・機械学習・データ分析関係のいろいろな話題にふれようで、時系列基盤モデルについてLTをさせて頂きました。
他発表者のLTも面白く、私自身も時系列基盤モデルについて理解を深める良いきっかけとなりましたが、心残りはLLMを絡めた手法については時間を割けなかったことです。
そこで今回はLLM for 時系列分析に関するアイディアを簡単にまとめてみます。
おことわり
学習目的で調査・作成した内容がベースとなっており、誤りや他に面白い論文・事例がありましたら、教えて頂けますと幸いです。
主に以下Survey論文・Collectionリポジトリで取り上げられている内容の一部を対象としています。より網羅的に知りたい方は下記リソースを直接ご参照ください。
- Large Language Models for Time Series: A Survey
- Position: What Can Large Language Models Tell Us about Time Series Analysis
- Empowering Time Series Analysis with Large Language Models: A Survey
- LLM4TS: Large Language Models for Time Series
時系列分析を取り巻くLLM
時系列分析は、時間と共に変化するデータの続きを予測する、時系列予測を代表に、一定間隔で、時間の経過共に測定される時系列データを用いて、予測・分類・異常検出などのタスクを行います。
LTでは、以下時系列分析の4つの世代における事前学習モデルについて主に紹介しました。

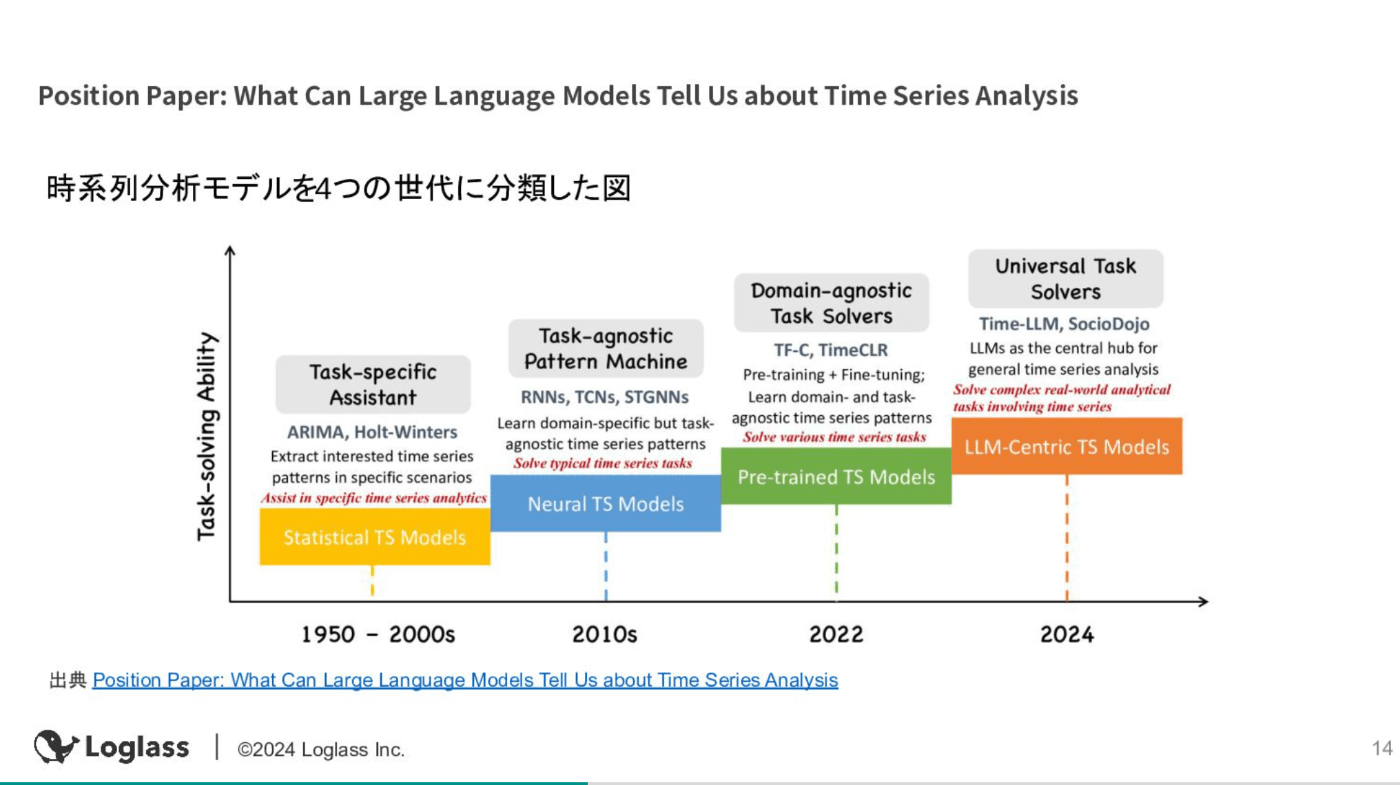
一方で、次の世代として、LLMを活用して予測・時系列分析タスクをこなすアプローチの台頭が予測されています。
LLM×時系列分析のアプローチ
ここでは三つのSurvey論文を元に、どのようなLLM×時系列分析のアプローチが提案されているか簡単に紹介します。
Large Language Models for Time Series: A Survey
LLMで時系列データを参照する際に生じるギャップは、LLMがテキストデータで学習されている一方で、時系列データは連続的な数値データであるという点です。
LLMが本来理解しやすいテキストデータと、時系列データの数値データとの間を橋渡しをするための方法を、Prompting、Quantization(量子化)、Aligning、Vision as Bridge、Toolの5つに分類しています。
| 手法 | 概要 | 利点 | 欠点 | 代表的な研究 |
|---|---|---|---|---|
| Prompting | 時系列データをテキストとして扱い、LLMに直接入力する | 実装が容易で、ゼロショット学習が可能 | 数値のセマンティクスが失われ、高精度な数値データや長期予測には非効率 | PromptCast, LLMTime、TabLLM |
| Quantization(量子化) | 時系列データを離散表現に変換してLLMに入力する | インデックスと時系列データの変換に柔軟性がある | VQ-VAEなどの学習が必要な場合、2段階の学習が必要になることがある | DeWave, AudioLM, TDML |
| Aligning | 時系列データ用のエンコーダーを学習し、その埋め込みをLLMのセマンティックスペースに整合させる | 異なるモダリティのセマンティクスを整合させ、End-to-Endで学習できる | 設計とファインチューニングが複雑になる可能性がある | ETP, MATM, GPT4TS |
| Vision as Bridge | 画像などの視覚表現を橋渡しとして、時系列データをLLMに接続する | 視覚モダリティやVision-Languageモデルの知識を活用できる | すべてのデータに視覚表現が適しているわけではない | ImageBind, IMU2CLIP, CLIP-LSTM |
| Tool | LLMを時系列データに直接適用するのではなく、コード生成やAPI呼び出しなどのツール生成に利用する | LLMにより多くの能力を付与できる | End-to-Endでの最適化ができない | CTG++, ToolLLM |
ゼロショットで時系列分析が出来るプロンプトベースの手法は、アプリケーションエンジニアの視点としては期待したいところではあり、PromptCastは、まさしく数値時系列データを元にプロンプトベースの時系列予測を提案しています。
ツールのアプローチは、いわゆるAIエージェント的に、時系列分析を行うためのツールの分岐にLLMを駆使することになりますが、AIエージェントに特有の課題を受け入れることにもなるので、時系列分析を行うアプローチとして最適解であるかは、まだ腑に落ちてはいないです。
Quantization(量子化)あたりは正直正確に理解しきれていない。
Position: What Can Large Language Models Tell Us about Time Series Analysis
時系列分析のための4つの世代についての分類を紹介した上で、LLMが時系列分析に与える影響について論じています。
その中で、時系列分析におけるLLMの活用について三つのアプローチに触れています。
| 手法 | 概要 | 利点 |
|---|---|---|
| LLM-assisted Enhancer | 時系列データの理解を深め、既存モデルの知識を拡張する | - データの解釈可能性を高める - 外部知識やドメイン固有のコンテキストを補強できる |
| LLM-centered Predictor | LLM内の膨大な知識を利用して、予測や異常検出などの時系列タスクを実行する | - Few-ShotやZero-Shotのシナリオでドメイン特化型モデルよりも高い性能 |
| LLM-empowerd Agent | 従来の役割を超えて時系列分析に積極的に関与し、変革する | - 一般的な時系列分析と問題解決への直接的な活用が期待される(研究は限られている) |
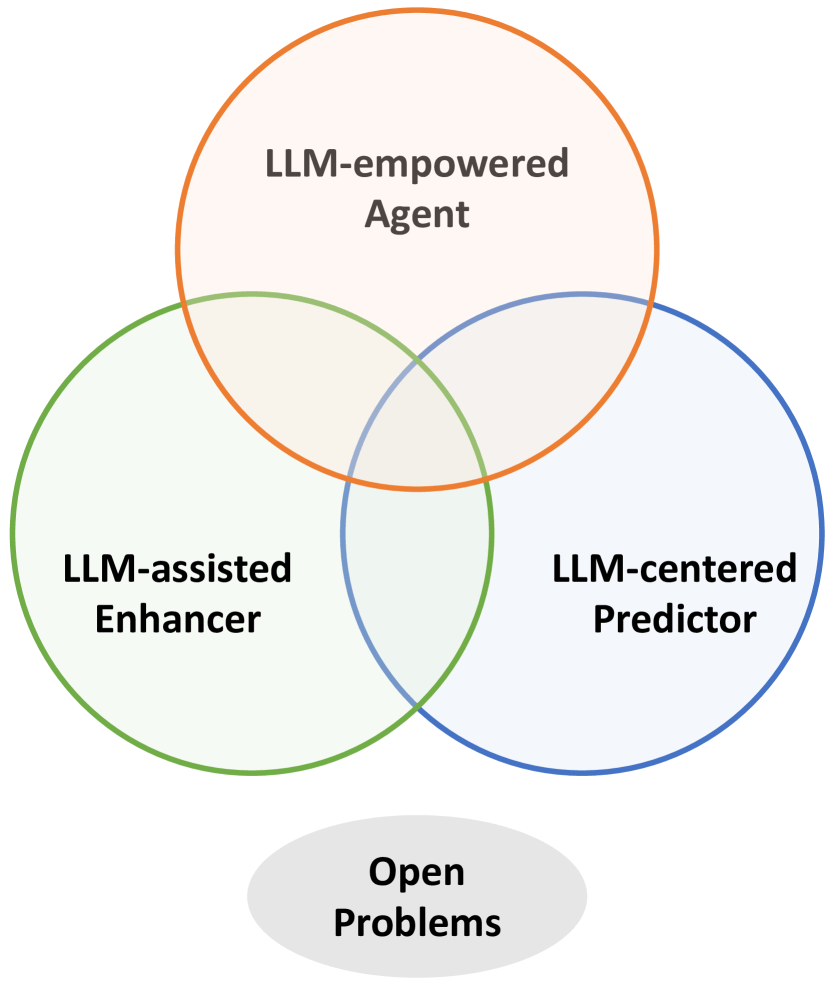
引用: Position: What Can Large Language Models Tell Us about Time Series Analysis
さらにLLM-centered Predictorにおいては、時系列タスクのためにLLM自体に手を入れるか、時系列データの変換やプロンプティング等を工夫する二つのアプローチに整理されています。
| ベース | 特徴 | 代表的な手法 | メリット | デメリット |
|---|---|---|---|---|
| チューニング | 時系列データに合わせてLLMをチューニング | Time-LLM、TEST、TEMPO | 時系列データの特性に適応したモデルを作成可能 | モデルのトレーニングに時間とコスト、破滅的忘却のリスク |
| ノンチューニング | LLMのパラメータを変更せずに、時系列データをLLMに合わせて変換・プロンプトに追加などを行う | LLMTime、PromptCast | LLMの訓練に必要なコストを抑えられる、追加の補足的な情報を加えやすい | 複雑な時系列パターンを言語で表現することが難しく、予測の安定性や信頼性が低い場合がある |
こちらの論文でもLLM-empowerd Agentとして、エージェントアプローチが言及されています。期待したい気持ちは多大にありますが、まだまだ未来の夢・可能性という状態の印象です(「従来の役割を超えて関与する」などのお気持ちコンセプトみたいな内容)
Empowering Time Series Analysis with Large Language Models: A Survey
LLMを用いた時系列分析の手法を5つのカテゴリーに分類しています。
プロンプティングによる手法に加えて、数値の時系列データをLLMが入力として理解できるトークン表現に変換するなど、時系列データをLLM向けに変換する手法も提案されています。
| カテゴリ | 説明 | 具体例 |
|---|---|---|
| 直接クエリ | LLMに時系列データを直接入力し、予測や分類などのタスクを実行させる | PromptCast (Xue & Salim, 2023) |
| 時系列トークン化 | 数値の時系列データをLLMが入力として理解できるトークン表現に変換する | Time-LLM (Jin et al., 2024), TEMPO (Cao et al., 2024) |
| プロンプト設計 | 時系列データに関する追加情報をプロンプトとしてLLMに与えることで、その性能を向上させる | Time-LLM (Jin et al., 2024), TEST (Sun et al., 2024) |
| ファインチューニング | 事前学習済みのLLMを時系列データに適応させるために、そのパラメータを調整する | LLM4TS (Chang et al., 2023), OFA (Zhou et al., 2023) |
| 時系列モデルにおけるLLMの統合 | LLMを時系列モデルの構成要素として組み込み、特徴量強化などを実現する | LA-GCN (Xu et al., 2023), METS (Li et al., 2023) |
一方で、今後の研究の方向性としては、トークン化を代表とするプロンプト設計から、解釈可能性の向上、またLLMエージェントまで提示しています。
| 名称 | 説明 |
|---|---|
| トークン化とプロンプト設計 | - 時系列データの動的な特性をより効果的に捉えるトークン化手法の開発が期待される - LLMの性能をさらに向上させるプロンプト設計手法の開発が期待される |
| 解釈可能性 | - LLMベースのモデルはブラックボックスになりがちであるため、その予測結果の解釈性を向上させることが重要 |
| マルチモダリティ | - 時系列データとテキスト、画像などの異種データの統合が重要な研究課題 |
| ドメイン汎化 | - 異なるドメインへのモデルの適用性を高めるためには、ドメイン汎化能力の向上が求められる |
| LLMのスケーリング | - LLMのサイズと性能の関係性を理解することが今後のモデル開発において重要 |
| LLMを用いたエージェント | - 時系列データに基づいた意思決定を行うLLMエージェントの開発が期待される |
| バイアスと安全性 | - LLMの訓練データに含まれるバイアスの影響を軽減し、安全性を確保するための研究が重要 |
具体的な手法
前述のLLM×時系列分析のアプローチの中で名前が上がったいくつかの手法のうち、個人的に関心がある && 取っ付きやすいアプローチであるプロンプティング手法を中心に簡単に取り上げます。
PromptCast:プロンプトベースの時系列予測
PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecastingでは、いわゆるプロンプティングで時系列タスクをこなすアイディアが紹介されています。
従来の時系列予測モデルは、数値の系列を入力として受け取り、数値を予測出力として生成します。
一方、PromptCastでは、数値の入力と出力をプロンプトと呼ばれる自然言語の文章に変換し、文から文への予測問題として扱うことを提案しています
シンプルな例は下記の通りです。
- 入力プロンプト
- 予測のための過去の時系列データ: コンテキスト
- e.g.) 「2019年8月16日(金)から2019年8月30日(金)までの110地域の平均気温は、各日78度、81度、83度、84度、82度、83度、78度、77度、74度、78度、73度、76度であった。」
- 予測させたい内容: クエリ
- e.g.) 「2019年8月31日(土)の気温は?」
- 予測のための過去の時系列データ: コンテキスト
- 出力
- 予測値、もしくは予測値を含む文章
- e.g.) 「気温は78度でしょう。」
- 予測値、もしくは予測値を含む文章
ちなみにPromptCastが時系列予測に有効である理由として、以下の2点が挙げられています。
-
言語モデルのアーキテクチャは、時系列データの性質と相性が良い
- 時系列予測と同様に、言語生成も本質的に系列から系列への変換処理であるため、言語モデルは時系列データの学習に適している
-
プロンプティングによる追加情報の付加
- 従来の数値ベースの予測手法では、時間帯や曜日などの付加的な情報をモデルに組み込むのに一定コストがかかる
- PromptCastでは、プロンプティングで自然言語として統合できるため、より容易にモデルに情報を付加できる
時系列予測の難しいポイントの一つとして、説明可能性の担保や定性データ利用などが挙げられますが、PromptCastでは、プロンプティングで予測を行うため、付加的な情報を渡しやすい点、zero-shot予測が行える点は魅力です。
LLMTime:時系列データを数値の文字列と捉えて、次の文字列を予測
Large Language Models Are Zero-Shot Time Series Forecastersでは、時系列データを数値の文字列としてエンコードし、時系列予測をテキストにおける次トークン予測として捉えることで、時系列予測を行う方法が提案されています。
LLMTimeでは以下のようなトークン化手法を提案しています。
- 各数値の桁を空白で区切ることで、桁ごとに別個のトークンとして認識されるように
- 時系列データの各ステップは","(コンマ)で区切る
- 小数点は固定精度で冗長なため、コンテキスト長を節約するため削除
例えば、2桁の精度の場合、0.123, 1.23, 12.3, 123.0は 1 2 , 1 2 3 , 1 2 3 0 , 1 2 3 0 0と変換されます。
これによりゼロショット学習、欠損データへの対応、追加コンテキストをテキストとして付与できる点で、従来の手法より利点があると主張しています。
TabLLM: 表データをプロンプティングに利用
時系列分析ではありませんが、プロンプティングの手法として参考になりそうなので紹介します。
TabLLM: Few-shot Classification of Tabular Data with Large Language Modelsでは、表形式データを自然言語による表現にシリアライゼーションし、分類問題の簡単な説明と組み合わせることで、表形式データの分類タスクを行うフレームワークが提案されています。
下記のようなシリアライゼーション手法を用いて、表形式データをテキストに起こした後に、タスク固有のプロンプト(例: "この人は5万ドル以上稼いでいますか?はいまたはいいえ?")を組み合わせて、分類タスクを実施します。
| 方法 | 説明 | 特徴 | 具体例 (Blood Datasetより) |
|---|---|---|---|
| List Template | 列名と値をリスト形式で列挙 | 簡潔だが機械的 | - Recency - months since last donation: 23 - Frequency - total number of donation: 1 |
| Text Template | "列名は値です"という形式のテキスト列挙 | より自然な形式だが、やや機械的 | The Recency - months since last donation is 23. The Frequency - total number of donation is 1. |
| Table-To-Text | 表形式データを自然言語テキストに変換 | ノイズが多く、意味不明な文章も含む | the number of the public can be from the number of the public. The 1.2 has a maximum speed of 1.2. |
| Text T0 | T0言語モデルによる自然言語テキスト変換 | より自然な文章だが、情報欠落の可能性あり | The donor has made 1 donation in the last 23 months. |
| Text GPT-3 | GPT-3による自然言語テキスト変換 | 最も自然で詳細な文章を生成 | The blood donor is a 23-year-old male who has donated blood once, 250 c.c. of blood, 23 months ago. |
TEST:時系列データをLLMが理解しやすい形に変換
TESTは、「TEXT PROTOTYPE ALIGNED EMBEDDING TOACTIVATE LLM’S ABILITY FOR TIME SERIES」の名の通り、TS-for-LLMなアプローチとして、時系列データをLLMが理解しやすい新しい埋め込み表現に変換する手法です。
To address the above issues and achieve TS-for-LLM, we do not directly input TS into LLM, but instead, we first tokenize TS, then design an encoder to embed them, finally skip the embedding layer to input them into LLM. In this way, the core is to create embeddings that the LLM can understand.
上記の問題を解決し、TS-for-LLMを実現するために、我々はTSを直接LLMに入力するのではなく、まずTSをトークン化し、次にそれを埋め込むエンコーダを設計し、最後に埋め込み層をスキップしてLLMに入力する。このように、LLMが理解できる埋め込みを作成することが核となる。
引用: TEST: Text Prototype Aligned Embedding to Activate LLM's Ability for Time Series - 1 Introduction
TESTを用いることで、従来のSOTA TSモデルと同等以上の精度を達成しつつ、Few Shot Learning、汎化能力においても優れた性能を発揮したと主張しています。
時系列分析エージェント
既に何度か話題に上がった通り、LLMを用いた時系列分析エージェントの可能性は議論されており、
Position: What Can Large Language Models Tell Us about Time Series Analysisでも、人間との対話を通じて時系列データの分析、Agenticに時系列分析を行うアプローチが提案されています。
しかし、現状では課題が多く残されています。ChatDevやTRANSAGENTSの事例ほど作り込まれたエージェントアプローチの研究・実装を見かけた記憶はなく、これからに期待するフェーズの認識です。
- 複雑なパターン理解の限界:LLMは複雑な時系列パターンの理解に制限がある
- ブラックボックス問題:LLMの意思決定プロセスの完全な理解が難しい場合がある
- ハルシネーション:もっともらしく聞こえるが誤った回答を生成する可能性
- バイアスとタスク選好:訓練データの偏りにより、特定のパターンや傾向を強調する可能性
時系列分析に関わらず対話的にAIと分析を行う・AIデータサイエンティストと呼ばれるようなサービスもちらほら登場しており、個人的にはこのようなデータ分析をより民主化・Agenticな体験に仕上げたサービスはこれから増えてくると予想しています。
PandasAIなんかもまさしくですね。
(↓Position: What Can Large Language Models Tell Us about Time Series Analysisで記載されている時系列分析エージェントとのやり取り例)
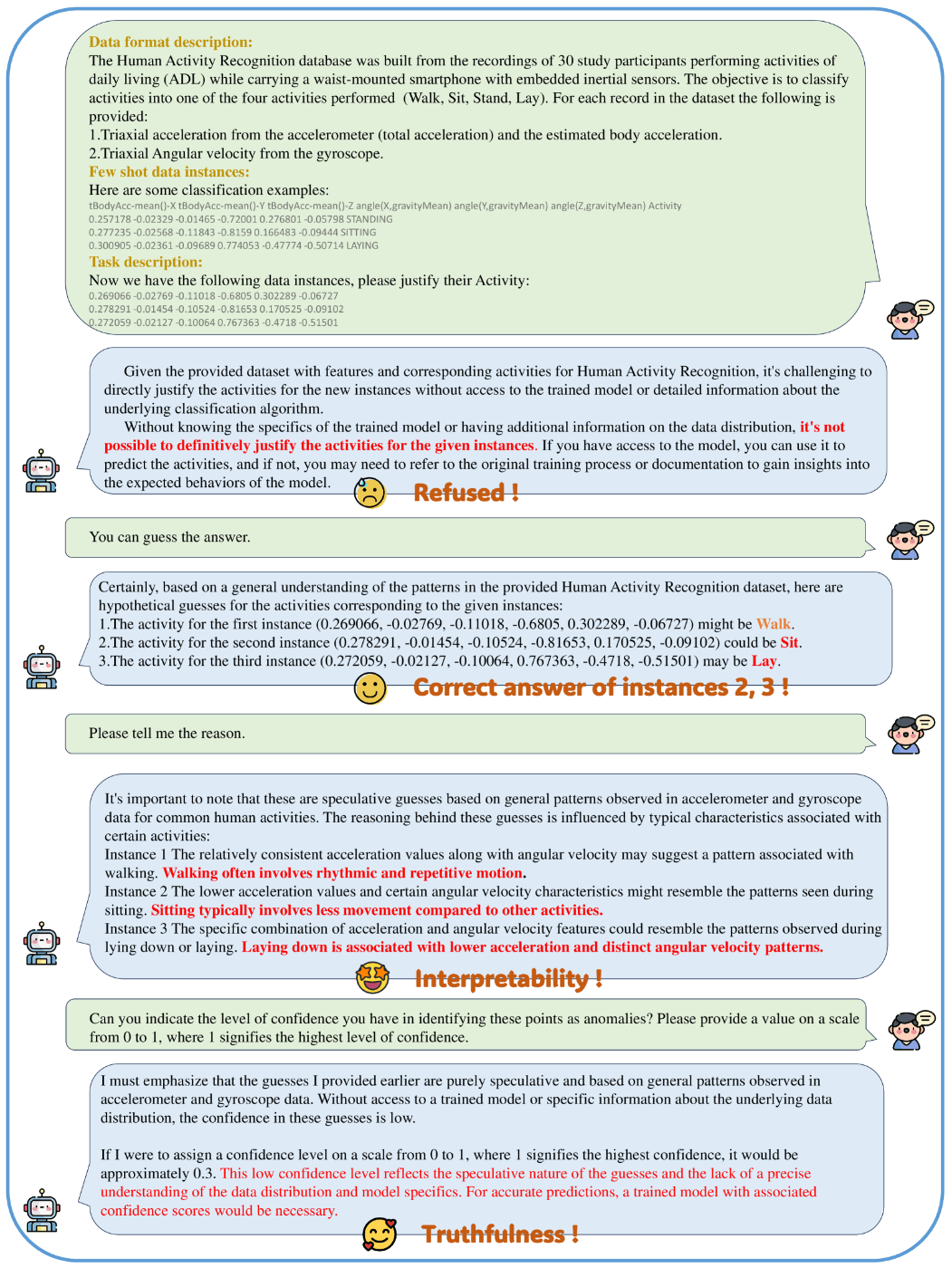

引用: Position: What Can Large Language Models Tell Us about Time Series Analysis
まとめ
LTでやりきれなかったLLM×時系列分析周りについて簡単にまとめました。
元々詳しい分野ではないので、頭がパンクしそうでしたが、それなりに理解が深まった(はず)なので良い時間でした。
実際の分析事例としては、NASDAQ-100の株価時系列データ、企業データ、関連する経済/金融ニュースデータを元に、GPT-4を用いたゼロショット・フューショット、LLaMAを用いたファインチューニングで予測を試したTemporal Data Meets LLM - Explainable Financial Time Series Forecastingなどがあります。
(特に株価予測系は他にも色々存在します)
今回紹介した中では、単純な季節変動やトレンドのデータに対して、プロンプティングの利用が進む可能性は想像できます(この場合は統計モデルで良いのでは?に対してのロジックは必要そうですね)
とはいえLLMを中心とした時系列分析は、様々なアプローチが提案・研究されている途上です。長期的にキャッチアップしていきたい所存です。
直近もGoogleからLANISTRなるものが発表されましたが、こちらも気になるところです(全く追えていない・理解できていませんが)
構造化データ(時系列、表形式)と非構造化データ(画像、テキスト)を統合して学習し、最終的にクラス予測を行う新しいフレームワークです。従来のマルチモーダル学習は主に非構造化データに焦点を当てていましたが、現実世界ではこれら両方のデータタイプの統合が求められます。LANISTR は、この課題に対処するために設計されており、高度なアライメントと融合技術を用いています。
今回は以上です!

Discussion