はじめに
アドベントカレンダーで書いた認可のベストプラクティスの記事が結構反応を頂けたのですが、最終的な結論が ユースケースによる という投げやりなまとめになってしまっていたのが少し気になっていました。
そこで、ユースケース別の実装パターンをより詳しく解説しようと思い、Kotlin Fest 2024にプロポーザルを出しました。
が、力及ばずお見送りとなってしまいました。
そんな中、Kotlin Festのスポンサーとしてログラスがブースを出展することになり、採択されなかったプロポーザルを紹介する 「ボツポーザル」 が企画されました。
ブースにお越しいただいた方々にスムーズに説明できるようにプロポーザルの内容を詳しく書き起こしています。
特に、前回の記事で詳しく触れられなかったユースケース別のKotlinでの実装方法や、DDDにおける認可の扱いについて調査したので、それらについて解説していきます。
DDDにおける認可の扱い
前回の記事ではレイヤードアーキテクチャやオニオンアーキテクチャなどの戦術的DDDを実践している際に認可処理をどのように書くべきか?というトピックを取り上げました。
今回の記事では 「DDDにおいて認可はどのように取り扱われるべきか?」 というトピックについて取り上げてみようと思います。
このトピックについて調べるために、DDDに関する有名な本や記事を読み漁りましたが、認可について触れているものは多くはありませんでした。
その中で実践ドメイン駆動設計[1](以下IDDD本)だけは詳しく解説していました。

第2章の「ドメイン、サブドメイン、境界づけられたコンテキスト」の中にこのような一節があります。
しかし彼らはモデルには明確な制限があって、それ以上に広げすぎては行けないということを理解していなかった。その結果、セキュリティや権限の情報をコラボレーションモデルに組み込んでしまうという、間違いを犯してしまった。
(中略)
つまりそれは、二つのモデルをひとつに混ぜ込んでしまうということだ。程なく彼らも気がついた。この混乱する状況は、セキュリティについての関心事をコアドメインに混ぜ込んだことに起因するものである。まさにコアビジネスロジックのど真ん中で、開発者がクライアントの権限をチェックしてからリクエストを処理していたのだ。
https://amzn.asia/d/25RBJdH
IDDD本では、SaaSOvastionというコンパウンドスタートアップがやるような複数のSaaSプロダクトを展開する架空の企業がDDDを導入するエピソードが書かれています。
その中のコラボレーションのためのプロダクトの実装を軽量DDDでしていたときにこの文が出てきます。
コラボレーションモデルに権限の情報を組み込んでしまうことを「 間違いを犯してしまった。 」と言っていますね。
そこで出てくる悪い例のサンプルコードが以下になります。
public class Forum extends Entity {
...
public Discussion startDiscussion(String aUsername, String aSubject) {
if (this.isClosed()) {
throw new IllegalStateException("Forum is closed.");
}
User user = userRepository.userFor(this.tenantId(), aUsername);
if (!user.hasPermissionTo(Permission.Forum.StartDiscussion)) {
throw new IllegalStateException("User may not start forum discusstion.");
}
String authorUser = user.username();
String authorName = user.person().name().asFormattedName();
String authorEmailAddress = user.person().emailAddress();
Discussion discussion = new Discussion(
this.tenant(), this.forumId(),
Domainregistry.discussionRepository().nextIdentity(),
authorUser, authorName, authorEmailAddress,
aSubject);
}
}
Entityの中でRepository経由でUserを取得しているなど、色々とツッコミどころはありますが、ここでの悪いポイントは、「フォーラムでディスカッションを始めるためには、ユーザーが Permission.Forum.StartDiscussion という Permission を持つこと」という認可ロジックがビジネスロジックに組み込まれてしまっているところです。
結局このコードは以下の様にリファクタリングされます。
public class Forum extends Entity {
...
public Discussion startDiscussionFor(
ForrumNavigationService aForumNavigationService,
Author anAuthor,
String aSubject) {
if (this.isClosed) {
throw new IllegalStateExeption("Forum is closed.");
}
Discussion discussion = new Discusssion(
this.tenant(), this.forumId(),
aForumNavigationService.nextDiscussionId(),
anAuthor, aSubject);
// 以下略
}
}
権限にまつわるロジックがまるっとなくなっていますね。
Usernameを渡すその代わりに、 Author というオブジェクトが渡されるようになりました。
Author とは一体何者なのでしょうか?
ApplicationServiceではこのように書かれています。
public class ForumApplicationService ... {
...
@Transactional
public Discussion startDiscussion(
String aTenantId, String aUsername,
String aForumId, String aSubject) {
Tenant tenant = new Tenant(aTenantId);
ForumId forumId = new ForumId(aForumId);
Forum forum = this.forum(tenant, forumId);
if (forum == null) {
throw new IllegalStateException("Forum does not exists.");
}
Author author = this.collaborationService.authorFrom(tenant, anAuthorId);
Discussion newDiscussion = forum.startDiscussion(
this.forumNavigationService(),
author,
aSubject)
this.discussionRepository.add(newDiscussion);
return newDiscussion;
}
}
アプリケーションサービス内にも権限にまつわるロジックは書かれていません。
権限にまつわるロジックはどこにいったのでしょうか?
正解はここです。
Author author = this.collaborationService.authorFrom(tenant, anAuthorId);
コラボレーションコンテキストでは「ユーザー」をそのまま扱わずに、投稿者・作成者・モデレーター・所有者・参加者というコラボレーションコンテキスト内のロールに変換して利用しています。
CollaborationService は腐敗防止層としてユーザーをコラボレーションコンテキストにロールに変換するためのインターフェースが定義されています。
(第11章 「ファクトリ」 で出てきます。結構離れているので見つけるのが大変でした。)
package com.saasovation.collaboration.domain.model.collaborator;
import com.saasovation.collaboration.domain.model.tenant.Tenant;
public interface CollaboratorService {
public Author authorFrom(Tenant aTenant, String anIdentity);
public Creator creatorFrom(Tenant aTenant, String anIdentity);
public Moderator moderatorFrom(Tenant aTenant, String anIdentity);
public Owner ownerFrom(Tenant aTenant, String anIdentity);
public participant participantFrom(Tenant aTenant, String anIdentity);
}
この CollaborationService はインフラ層で実装されています。
package com.saasovation.collaboration.infrastructure.services;
public class UserRoleToCollaboratorService implements CollaboratorService {
public UserRoleToCollaborationService() {
super();
}
@Override
public Author authorFrom(Tenant aTenant, String anIdentity) {
return (Author) UserInRoleAdaptor
.newInstance()
.toCollaborator(aTenant, anIdentity, "Author", Author.class);
}
}
実装の内部では UserInRoleAdaptor というものを呼んでいます。
権限周りの関心事は認証・アクセスコンテキストという汎用サブドメインに切り出されており、アダプター経由で変換するようになっています。
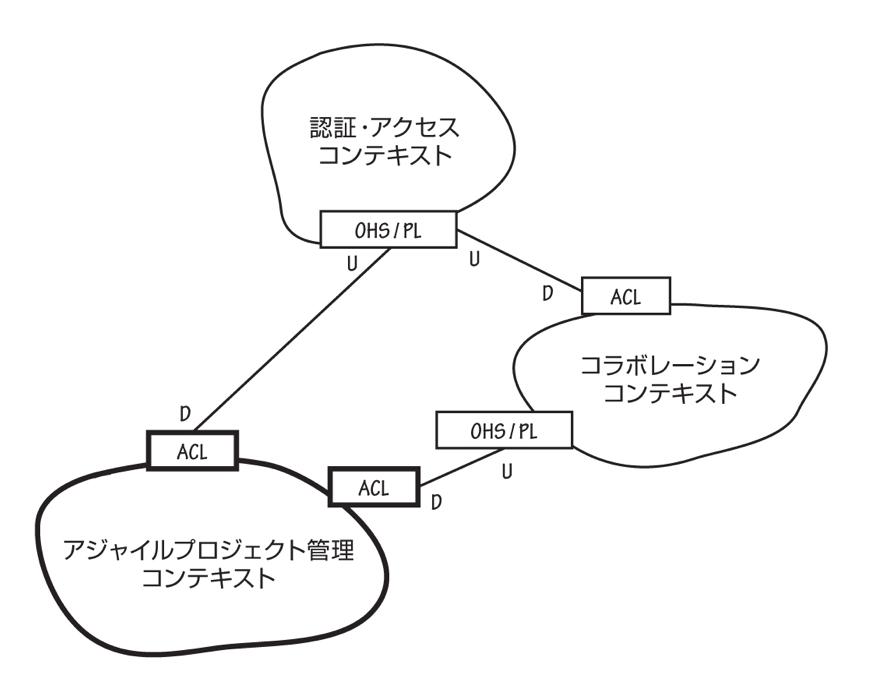
コラボレーションコンテキストと認証・アクセスコンテキストはRESTful API経由でデータをやり取りするため、Adaptorの実装は認証・アクセスコンテキストへのAPIリクエストが書かれています。
今回は内部実装まで詳しく書きませんが、APIリクエストで認証・アクセスコンテキストに対して Author ロールに変換可能か?という問い合わせをUserInRoleAdaptorでは行っています。
認証・アクセスコンテキストではユーザーが投稿者になる権限を持つか?というチェックをしてレスポンスを返します。
このように認証・アクセスコンテキストを汎用サブドメインとして切り出すことで、コアドメインからセキュリティや権限についての関心事を取り除いています。
まとめると、IDDD本においては認可に関する関心事はコアドメインから分離すべきものだと考えて良いでしょう。
認可のベストプラクティスでは?
認可のベストプラクティスをまとめたOso Authorization Academy[2]でもIDDD本と同じようなことが書かれていました。
Authorization Academyの2章「What is Authorization」の最初に 「認可は重要だが通常コア機能やビジネスロジックとは無関係」 とあります。
Authorization is a critical element of every application, but it's nearly invisible to users. It's also usually unrelated to the core features or business logic that you're working on.
https://www.osohq.com/academy/what-is-authorization
また、2章の最後にも承認ロジックをアプリケーションコードから分離することを勧めています。
(日本語翻訳済み)
上記にはさまざまな順列や組み合わせがありますが、ほとんどのアプリケーションでは通常、次の設定をお勧めします。
- 認証を処理するには、ID プロバイダーを使用します。
- アプリケーション自体で認証を強制します。
- 承認インターフェースを追加して、承認ロジックをアプリケーションコードから分離します。
また、こちらの記事ではかの有名なボブおじさんが 「セキュリティはアプリケーション特有の関心事であり、ビジネスオブジェクトはこのことについて意識しない」 と言っていると書いています。
これらのことを踏まえると、認可のベストプラクティスでも、認可ロジックはビジネスロジックとは分離するのが良いとなりそうです。
認可ロジックをどのように分離するのか
認可ロジックをビジネスロジックと分離することはわかりましたが、認可ロジックを分離する方法はいくつか考えられます。
認可ロジックを分離するパターンについても、Authorization Academy[2:1]の第2章で紹介されています。
それぞれのパターンについて詳しく見ていきます。
Centeralized authorization
IDDD本でやっていたように 認証・アクセスコンテキスト という汎用サブドメインを定義し、認可にまつわるロジックを集約するパターンを考えてみましょう。
このパターンは認可ロジックが一元管理され、認可処理は必ず認証・アクセスコンテキストのモジュール内で実行されます。
Authorization Academyではこのようなパターンを Centralized authorization として紹介しています。
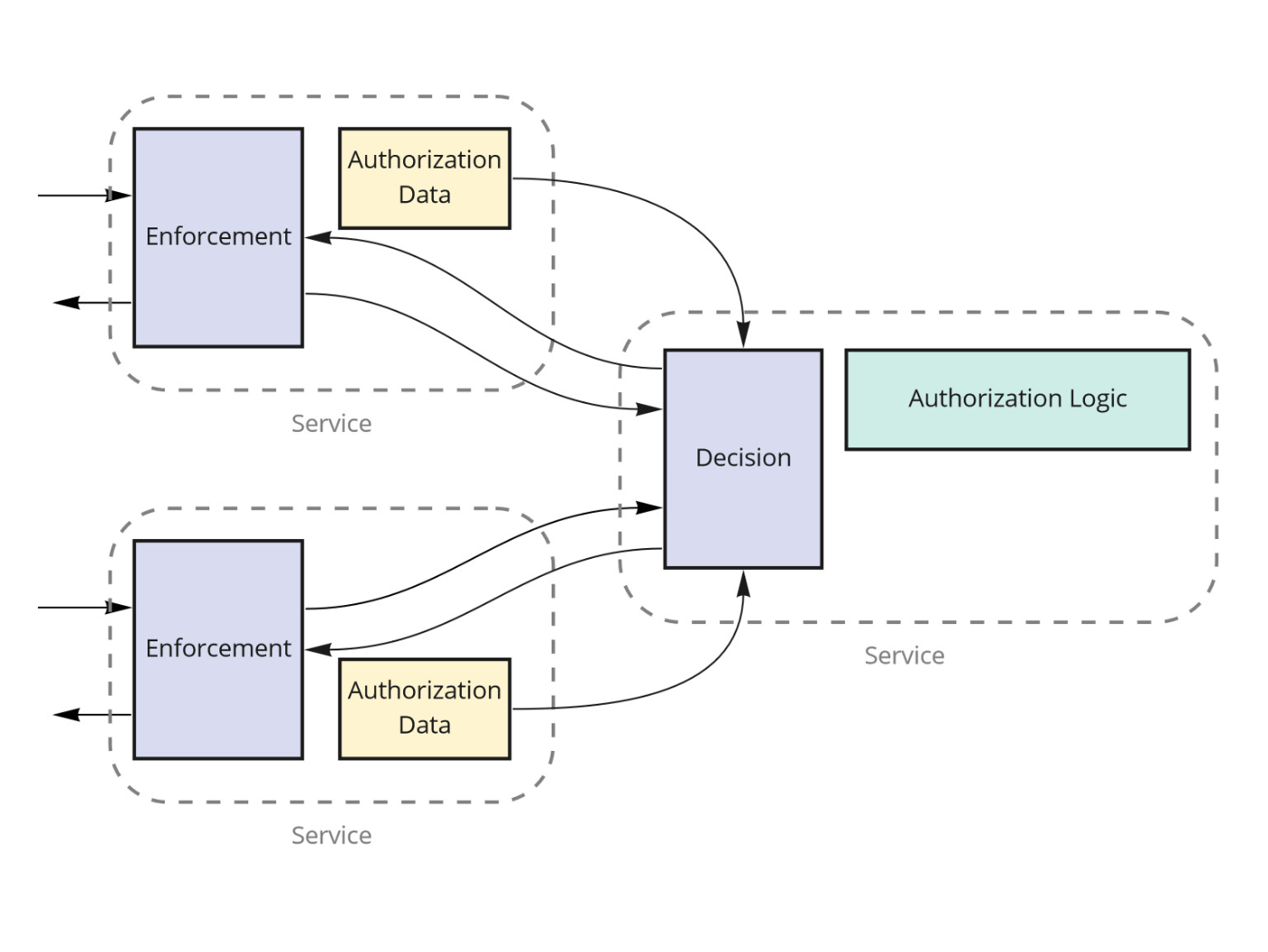
しかし、Authorization Academyの中ではこのパターンには欠点があるとあります。
(日本語翻訳済み)
一元化されたサービスは、複数のアプリケーション間で決定ロジックの一貫性を保ち、ポリシーの変更を分離するのに役立ちます。ただし、この方法の欠点は、決定を下すために多くの承認データを一元化する必要があることです。
https://www.osohq.com/academy/what-is-authorization#addingauthzapp
認可の決定を下すために必要なデータを各サービスから取得する必要があり、認可ロジックはサービスレベルで分離されているが、全てのサービスに依存する状態になるでしょう。
Decentralized authorization
Authorization Academyでは認可ロジックをサービス内で持つことで、認可の判断に必要なデータをサービス内で取得できるパターンも紹介しています。
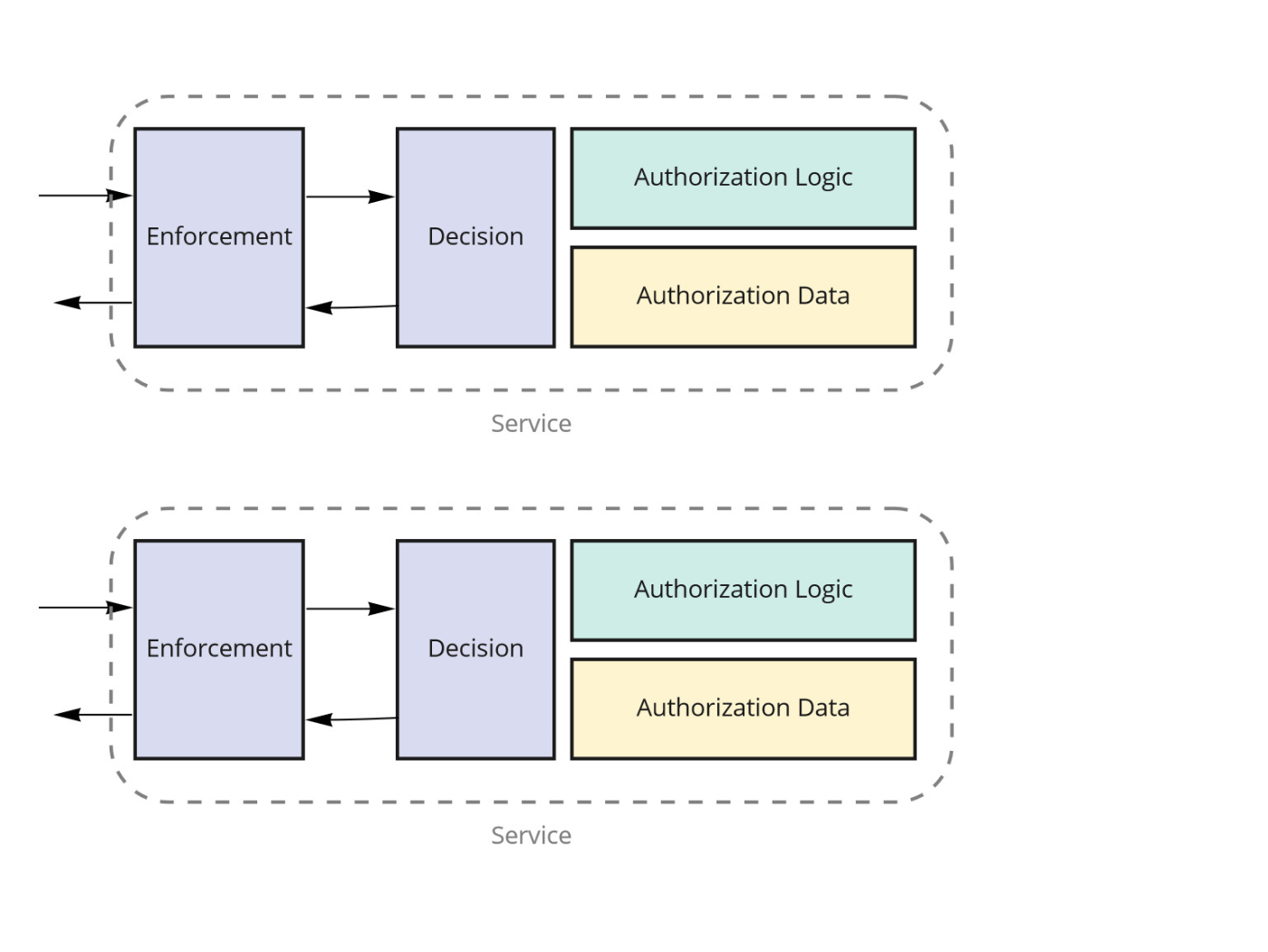
このパターンでは認可処理の実行はサービス内で完結するので単純なサービスにおいてはかなりシンプルになるはずです。
Hybrid approach
一方でプロダクトが拡大し、サービス単体のデータだけでは認可処理を実行できないケースが生まれたときには Decentralized authorization では対応できなくなります。
そのような場合には Decentralized authorization と Centeralized authorization の良いところを混ぜた Hybrid approach が推奨されています。

各サービスは認可処理のインターフェースを公開しておきます。
サービス内で認可をする際に別サービスのリソースの認可情報が必要な場合は、対象サービスの認可エンドポイントを実行するようなイメージです。
(詳しくはAuthorization Academyを御覧ください)
Kotlinにおける認可ロジックを分離する実装方法
認可ロジックを分離のパターンについてはある程度わかりましたが、どのように実装すればよいのでしょうか?
Kotlinで認可ロジックを分離する実装方法をユースケース別に考えてみます。
ブログ管理サービス
前回の記事でも利用したブログ管理サービスを例にします。
ブログ管理サービスの認可ロジックは以下の通りです。
- チーム内にブログを投稿できるのはチームのメンバーのみ
- 記事を編集できるのは投稿者のみ
- 記事を削除できるのは投稿者とチームの管理者のみ
- プライベートな記事はチームのメンバーだけが閲覧可能
Postの作成
ブログポストの作成時の認可処理をどのように実装するか考えてみます。
前回の記事でも出てきた共通interfaceを使って認可処理を分離するパターンを考えてみます。
fun <T> isAllowed(actor: Actor, action: String, resource: T): Boolean
まず、Actorを定義します。
data class Actor(
val userId: UserId,
val teamRoles: Map<TeamId, Role>,
)
今回は記事(POST)に対する認可処理がメインになるので、以下のようになると思います。
fun isAllowed(actor: Actor, action: String, resource: Post): Boolean {
return when (action) {
"CREATE" -> resource.publishedTeamId in actor.teamRoles.keys.toHashSet()
else -> false
}
}
ではこのインターフェースを利用するUseCaseを考えてみましょう。
package com.example.blog.usecase.post
@Service
class CreatePostUseCase(
private val actorFetcher: ActorFetcher,
private val postRepository: PostRepository,
) {
fun execute(userId: UserId, authorId: UserId, title: String, body: String, publishedTeamId: TeamId, isPublic: Boolean) {
val post = Post.create(authorId, title, body, publishedTeamId, isPublic)
val author = actorFetcher.fetch(userId)
if (!isAllow(author, "CREATE", post)) {
throw PermissionDeniedException()
}
postRepository.save(post)
}
}
認可ロジックを呼び出す責務はUseCaesが担っています。
IDD本でも同様にApplicationServiceに認可処理を呼び出す責務を持たせていました。
このようにすることで、Postの作成メソッドには認可に関するロジックが一切含まれていない状態になります。
package com.example.blog.domain.post
data class Post private constructor(val id: PostId, val title: String, val body: String, val authorId: UserId, val publishedTeamId: TeamId, val isPublic: Boolean) {
companion object {
fun create(authorId: UserId, title: String, body: String, publishedTeamId: TeamId, isPublic: Boolean) {
if (title.isEmpty()) throw IllegalArgumentException("title is empty")
if (body.isEmpty()) throw IllegalArgumentException("body is empty")
return Post(PostId.gen(), title, body, authorId, publishedTeamId, isPublic)
}
}
小規模なシステムで、認可処理を分離するだけであれば、この手法はとても手軽で簡単に取り入れることができると思います。
発展: Authorizedモナドを利用するパターン
先ほどの手法では、UseCaseで認可処理を呼び出すことを責務としていましたが、責務としては強制力が少し弱いのが気になります。
例えば、認可処理を呼び出している箇所を丸っと削除してもエラーになることはありません。
"UseCaseで認可処理の呼び出しをする"というルールを知らない実装者がウッカリ「認可処理を呼び忘れてしまっていた!」ということが起こったとしても不思議ではありません。
(もちろんテストがしっかり書かれていて、毎回実行されるようになっていれば気がつけるはずです!ですが、ルールの存在すら知らない場合はどうしようもありません。)
package org.example.blog.usecase.post
@Service
class CreatePostUseCase(
private val actorFetcher: ActorFetcher,
private val postRepository: PostRepository,
) {
fun execute(userId: UserId, authorId: UserId, title: String, body: String, publishedTeamId: TeamId, isPublic: Boolean) {
val post = Post.create(authorId, title, body, publishedTeamId, isPublic)
// 認可処理の呼び出しをなくてしても、エラーにならない!
// val author = actorFetcher.fetch(userId)
// if (!isAllow(author, "CREATE", post)) {
// throw PermissionDeniedException()
// }
postRepository.save(post)
}
}
こういったときに役立つのが、コンテキストを持った値を表現するモナドです。
認証済みというコンテキストを持った Authorizedモナドを作ることで、UseCase内で認可処理の呼び出しを強制する方法を考えてみます。
Authorizedモナドを以下のようにとして定義します。
package com.example.authorization
sealed interface Authorized<out T> : Monad<T>
sealed interface Allowed<out T> : Authorized<T> {
val value: T
}
sealed interface Denied<out T> : Authorized<T> {
val value: T
}
認証済みには Allowed と Denied の2つの状態を用意しています。
これらを sealed interface で定義することで、このパッケージ内以外で実装できないようにしています。
この Authorized なオブジェクトを作成する抽象クラスを定義しましょう。
認証済みという文脈を持った値 Authorized<T> は特定のクラス経由でしか作成できないようにします。
package com.example.authorization
abstract class Authorizer<T> {
abstruct fun authorize(actor: Actor, action: String, resource: T): Authorized<T>
protected fun allow(resource: T): Allowed<T> = AllowedData(resource)
protected fun deny(resource: T): Denied<T> = DeniedData(resource)
}
private data class AllowData<T>(override val value: T): Allowed<T> {
// モナドの実装
}
private data class DenyData<T>(override val value: T): Denied<T> {
// モナドの実装
}
これらの実態のデータを作る allow と deny という関数を抽象クラス内で protected として限定公開しておくことで、 Authorizer を実装したクラスを経由しないと、 Authorized<T> を作成できないようにしています。
Authorized を実装したPostに対する認可ロジックはこのように定義されます。
package com.example.blog.domain.post
object PostAuthorizer : Authorizer<Post> {
fun authorize(actor: Actor, action: String, resource: Post): Authorized<Post> {
val isAllowed = when (action) {
"CREATE" -> resource.publishedTeamId in actor.teamRoles.keys.toHashSet()
else -> false
}
return if (isAllowed) allow(resource) else deny(resource)
}
}
抽象クラスで定義したお陰で、blogのモジュールの中で Authorizer の実装が可能になります。
こうすることで、各モジュールに認可ロジックを保持させつつ、認可ロジックは隔離できます。
更にRepositoryの引数を Allowed<Post> に置き換えてあげます。
package com.example.blog.domain.post
interface PostRepository {
fun save(post: Allowed<Post>)
}
こうすることで、 save メソッドを呼び出すためには、 Authorized<Post> を作成する必要があり、 Authorized<Post> を作成するためには、 Authorizer を経由して認可ロジックを実行しなければなりません。
Repositoryを防いでおけば、認可されていないデータが保存される心配もありませんし、認可ロジックの実行を強制することができます。
Authorizer を利用するUseCaseは以下のようになります。
package com.example.blog.usecase.post
import ...
@Service
class CreatePostUseCase(
private val actorFetcher: ActorFetcher,
private val postRepository: PostRepository,
) {
fun execute(userId: UserId, authorId: UserId, title: String, body: String, publishedTeamId: TeamId, isPublic: Boolean) {
val post = Post.create(authorId, title, body, publishedTeamId, isPublic)
val author = actorFetcher.fetch(userId)
val authorizedPost = PostAuthorizer.authorize(actor, "CREATE", post)
when (authorizedPost) {
is Allowed<Post> -> postRepository.save(authorizedPost)
is Denied<Post> -> throw PermissionDeniedException()
}
}
}
Authorizer を利用すると、基本的なリソースの作成、更新、削除、単一のデータ取得についてはほとんど同じように書くことができます。
(冗長になるので、ここでは省略します。)
Postの一覧取得
考えることが多いのは更新系よりも取得系のほうが多いと思います。
特定のユーザーが投稿したPostの一覧を取得するケースを考えてみましょう。
一覧は更新日順に降順ソートされ、20ページごとにページングされるとします。
ユーザーは閲覧できるPostは公開されているものと、自分が所属するチームに投稿されたものでしたね。
このとき考慮すべきはページングされるデータに対してどのように認可を適応するか?になります。
DBからデータを全件取得してアプリケーション内でフィルターをかけるのであれば、 Authorizer を使った方法で良いですが、ページングが必要なケースではレコード数が多く、アプリケーション内でフィルターをかけるのはパフォーマンスやCPUやメモリなどのリソース的に困難な場合が多いでしょう。
前回の記事ではそれに対応する方法としてQueryServiceの内部で認可処理を実行するパターンを紹介しました。
package com.example.blog.infra.post
class PostQuerySerivceImpl(val query: DSLContext): PostQuerySerivce {
override fun listByAuthor(actor: Actor, authorId: UserId): List<PostListItemDto> {
val authorizedPostTable =
authorizedQuery(query, actor, "read", Post::class)
return authorizedPostTable
.join(USER).on(USER.ID.eq(POST.AUTHOR))
.leftJoin(TEAM).on(TEAM.ID.eq(POST.PUBLISHED_TEAM_ID))
.and(POST.AUTHOR_ID.eq(authorId))
.map { /* PostListItemDtoに変換する処理 */ }
}
}
認可ロジックはこのように分離されます。
package com.example.blog.infra.post
fun authorizedQuery(
query: DSLContext,
actor: Actor,
action: String,
resource: KClass<Post>,
): Table<PostRecord> {
return when (action) {
// 読み取り可能なPOSTに絞り込んだテーブルを返す
"read" -> query.selectFrom(POST)
.where(POST.PUBLISHED_AT.`in`(actor.teamRoles.keys))
.or(POST.PUBLISHED_AT.isNull)
.asTable()
else -> query.selectFrom(POST).where(falseCondition())
}
}
この方法の欠点としては認可ロジックがQueryBuilderに依存してしまうため、QueryBuilderに合わせたロジックを書く必要があります。
同じリソースに対する認可ロジックをアプリケーションで書いている場合に、2重で認可ロジックを管理する必要もあるでしょう。
その対応策として、取得可能なリソースの条件をQueryServiceの引数として指定する方法を考えてみましょう。
class PagePostQuerySerivceImpl(val query: DSLContext): PagePostQuerySerivce {
override fun listByUser(
userId: UserId,
// 取得可能なリソース条件を引数に追加
teamIdsFilter: Set<TeamId>,
offset: Int,
limit: Int,
): Authorized<Page<PostListItemDto>> {
return query.select().from(POST)
.join(USER).on(USER.ID.eq(POST.AUTHOR_ID))
.where(POST.AUTHOR_ID.eq(userId.toString()))
.and(
POST.PUBLISH_TEAM_ID.`in`(allowedTeamIdsFilter.map {
it.value.toString()
}).or(POST.IS_PUBLIC.eq(true))
)
.orderBy(POST.UPDATEDAT.desc())
.limit(limit)
.offset(offset)
.fetch()
.map { /* PostListItemDtoに変換 */ }
.let { Page(it, offset + it.size) }
}
}
こうするとQueryService内で認可ロジックを実行する必要はなくなり、QueryServiceと認可ロジックを分離することができます。
引数のデータを使ったクエリを自由に組み立てることができるようになるため、ページングのためにソートした上でオフセットを指定することもQueryService内で可能になります。
QueryServiceを呼び出すUseCaseはこのようになります。
@Service
class PagePostsByUserUseCase(
private val actorFetcher: ActorFetcher,
private val pagePostQueryService: PagePostQuerySerivce,
private val teamRepository: TeamRepository,
) {
fun execute(
userId: UserId,
authorId: UserId,
): Allowed<Page<PostListItemDto>> {
// ユーザーが所属するチーム一覧を取得する
val teams = teamRepository.listByUser(userId)
val author = actorFetcher.fetch(userId)
val authorizedTeams = teams.map { team ->
TeamAuthorizer.authorize(actor, "READ", team)
}
// List<Authorized<T>> -> Pair<Allowed<List<T>>, Denied<List<T>>>
val (allowedTeams, deniedTeams) = authorizedTeams.partition()
return allowedTeams.map { teams: List<Team> ->
val teamIdsFilter = teams.map { it.id }.toSet()
pagePostQueryService.listByUser(authorId, teamIdsFilter)
}
}
}
ユーザーが所属する Team を取得して、そのTeamに対して閲覧権限があるかをチェックします。
ユーザーが所属するチームをわざわざ取得しているのは、 「Teamの閲覧権限がある = ユーザーが所属するTeam」という認可ロジックを漏らさないためです。
この認可ロジックは TeamAuthorizer に書かれているので、UseCaseで勝手に判断することは許されません。
object TeamAuthorizer : Authorizer<Team> {
fun authorize(actor: Actor, action: String, resource: Team): Authorized<Post> {
val isAllowed = when (action) {
"READ" -> resource.id in actor.teamRoles.keys.toHashSet()
else -> false
}
return if (isAllowed) allow(resource) else deny(resource)
}
}
認可された List<Allowed<Team>> を変換して、IDだけ抽出して、QueryServiceに渡しています。
また、UseCaseの返り値を Authorized<Page<PostListItemDto>> とすることで、認可処理の実行を強制しています。
一方で、この方法のデメリットとしては、結局認可ロジックのためにQueryServiceを拡張する必要があることです。
例えば、TeamIdでの絞り込みの他にも、Post別に閲覧可能なユーザーを設定できるような機能を追加開発するとします。
その場合はQueryServiceに閲覧可能なUserIdでのフィルターをするための引数を追加する必要があるでしょう。
理想的には、認可ロジック(Authorizer)に変更を加えるだけでその変更が適応されると良いのですが、この方法ではそれは難しいでしょう。
一つ前に紹介したQueryService内で認可ロジックを実行する方法ですと、変更する箇所は認可ロジックだけになります。
やはり認可処理については、ユースケースやプロダクトの状況に合わせて適切な方法を選択する必要がありそうです。
まとめ
DDDでの認可の取り扱いについては、多くの本でははっきり触れられてはいませんでしたが、ビジネスロジックと認可ロジックを分離するというのはIDDD本[1:1]でもOso Authorization Academy[2:2]でも同様でした。
また認可ロジックを分離するパターンを紹介しました。
- Centralized authorization
- Decentralized authorization
- Hybrid approach
Centralized authorizationは認可ロジックの分離度が最も高いですが、認可の判断をするために必要なデータを取得するために全てのサービスに依存することになります。
小さなサービスでは分散パターンを利用し、スケールが必要なタイミングでHybrid approachに移行するのがおすすめされていました。
さらに認可ロジックを分離しつつ、認可のユースケース別にKotlinでの実装方法を解説しました。
Authorizedモナドは認可ロジックを分離しつつ、認可処理を強制することができる点が個人的には気に入っています。
今回は説明のためにフレームワークに依存しない形で認可ロジックを分離する方法について取り上げましたが、フレームワーク側で認可ロジックとビジネスロジックをうまく分離できるものは多く存在します。
(それこそOsoやSpring Securityなどです)
最終的には、ユースケースやプロダクトの状況に合わせて適切な実装方法を選択する必要は依然としてありそうという結論に至りました。
さいごに
ここまで読んでくださった皆様のお気に入りの実装パターンについてもぜひコメント欄で教えていただけると嬉しいです 👇👇👇
「こういうやり方もあるぞ!」という意見をお待ちしております 😄

Discussion