はじめに
ルミナイR&Dチームの栗原です。
これまでの記事では、レビュー論文 “Retrieval-Augmented Generation for Large Language Models: A Survey” (Gao et al., 2024) を手がかりに、
- Fig.2 / Fig.3:RAG の基本フローと
Naive / Advanced / Modular RAG の違い - Fig.4:Prompt / Fine-tuning / RAG の「守備範囲」と使い分け方
をざっくり整理してきました。
ここまでは、どれも 「1回検索してから1回生成」 という、直列のフローを前提にしています。しかし実務で RAG を使っていると、こんな場面にぶつかります。
- 最初の回答を読んで「やっぱり◯◯も知りたい」と条件が増える
- マルチホップQA(「A と B の違いは?」系)で、1回の検索では足りない
- 回答の途中で「この部分だけはちゃんと原文を読みたい」と感じる
このようなケースでは、「1回だけの検索」では足りない ことが多いです。
そこで本記事では、Gao et al. の Fig.5 を手がかりに、
- Iterative Retrieval(反復検索)
- Recursive Retrieval(再帰的検索)
- Adaptive Retrieval(適応的検索)
という、エージェント寄りの RAG パターンを整理します。
参照:“Retrieval-Augmented Generation for Large Language Models: A Survey” — Gao et al., 2024
この記事で学べること
- RAG が「1回検索して終わり」だと困る典型パターン
- Iterative / Recursive / Adaptive Retrieval の違いと、向いているタスクのイメージ
- 既存の Advanced RAG を「ちょっとだけエージェント寄り」にする最小パターン
1. なぜ「1回だけの検索」では足りなくなるのか
まず、前回までに見た 標準的な RAG をざっくり思い出します。
- ユーザーの質問(クエリ)を受け取る
- 質問を埋め込みに変換して、ベクタDBなどから 一度だけ検索 する
- 取得したチャンクをまとめて LLM に渡し、一度だけ回答生成 する
FAQ ボットやシンプルな検索タスクなら、これで十分なことも多いです。
しかし、次のような場面では破綻しがちです。
-
マルチホップQA
例:「論文 A と論文 B の主な違いを、手法・データセット・結果の3点で教えて」
→ A と B をそれぞれ読んでから、差分をまとめる必要がある。 -
あいまいな質問から始まるリサーチ
例:「最近の◯◯の動向をざっくり教えて」→「じゃあ、その中で〜について詳しく」
→ 会話の中で、検索ターゲットが少しずつ変わっていく。 -
回答途中で前提が変わるタスク
例:「この仕様書を読んでテスト観点を列挙 → やっぱり API 部分だけに絞って」
→ 途中でフィルタ条件が変わるので、再検索したい。
つまり、現実のタスクでは、
「検索と生成を1往復だけで終わらせない」ための仕組み
が欲しくなります。
Gao et al. の Fig.5 は、その代表的な 3 パターンを Iterative / Recursive / Adaptive Retrieval としてまとめています。
2. Iterative Retrieval:必要になったら何度も取りに行く
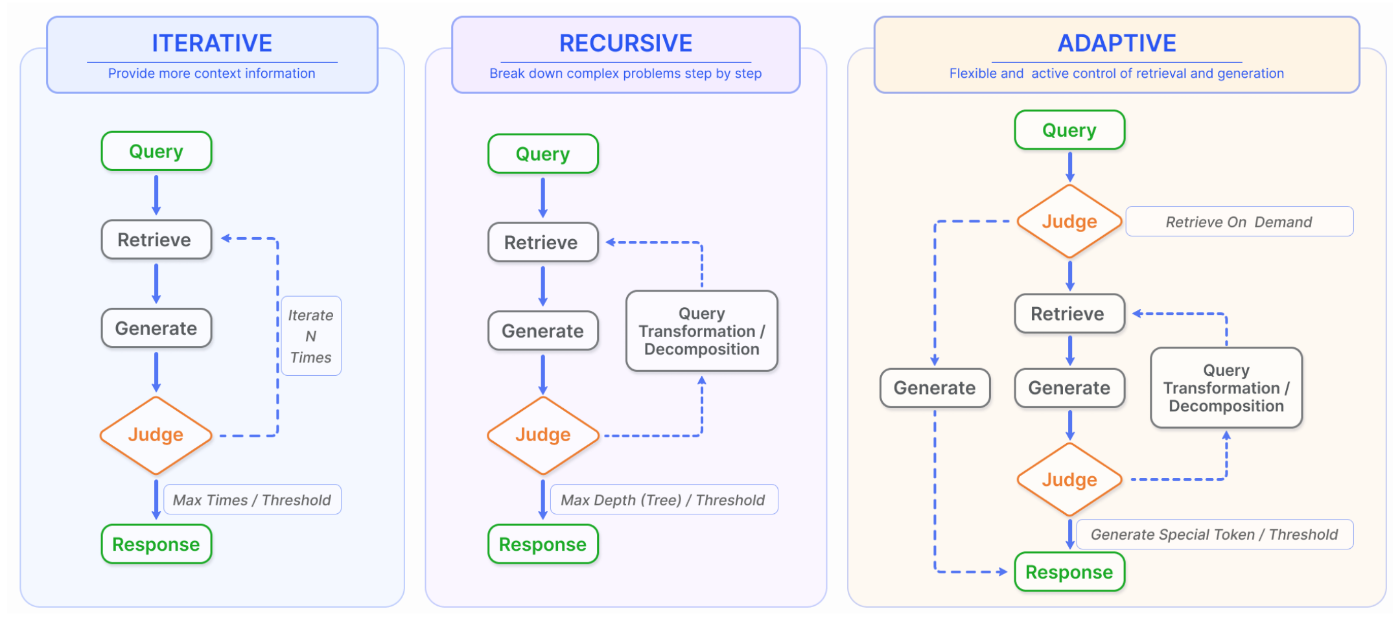
図1. RAGにおける検索-生成の3パターン(Gao et al., 2024 Fig.5 より)
2.1 コンセプト
Iterative Retrieval(反復検索) は、その名のとおり
「必要になったタイミングで、何度でも検索し直す」
というパターンです。
典型的には、次のようなループ構造を取ります。
- 最初のクエリで検索&回答
- LLM(あるいは人間)が回答を読んで、「追加で知りたい点」や「足りない情報」を洗い出す
- それを 新しいサブクエリ として再度 Retrieval を行う
- 2–3 を、満足するまで繰り返す
ReAct などの「Thought → Action(Search) → Observation」を繰り返すスタイルが、まさに Iterative Retrieval の代表です。
2.2 どんなタスクで効くか
- 段階的なリサーチタスク
例:「◯◯の歴史をざっくり → 特定の時代だけ深掘り → 関連人物をさらに深掘り」 -
対話型の問い合わせ対応
例:「料金体系を教えて → 年払いプランに絞って → 学割はある?」など、ユーザー側の条件が途中で増える場合 - 「最初は全体像、あとで詳細」というワークフロー全般
2.3 既存RAGをちょっとIterativeにする最小パターン
前回のような answer(query, mode="rag") があるとします。
それを「やや Iterative にする」としたら、まずは次のようなラッパー関数から始められます。
def iterative_answer(initial_query: str, max_rounds: int = 3) -> str:
query = initial_query
history = []
for round_id in range(1, max_rounds + 1):
# いつもの RAG で回答
ans = answer(query, mode="rag")
history.append({"query": query, "answer": ans})
# 追加で調べるべきことがあるか、LLMに聞く(簡易版)
follow_up = call_llm(
f"""これまでのQ&Aは以下です。
[履歴]
{history}
このあと、質問者がさらに知りたくなりそうなポイントがあれば、
「追加で調べるべき質問」を日本語で1つだけ出してください。
もう十分なら「なし」とだけ答えてください。"""
)
if "なし" in follow_up:
break
# 次のループでは、フォローアップを新しいクエリとして扱う
query = follow_up
# シンプルに、最後の回答だけ返す(実運用なら連結など)
return history[-1]["answer"]
ここでは、制御フローだけ を見てください。
- 中身の
answer()は前回の Advanced RAG のまま - その周りを
forループと「フォローアップ生成」で包むだけで、
「1回検索 → 2〜3回検索」といった Iterative Retrieval の形に近づきます。
3. Recursive Retrieval:問題を分解しながら深掘りする
図1(再). RAGにおける検索-生成の3パターン(Gao et al., 2024 Fig.5 より)
3.1 コンセプト
Recursive Retrieval(再帰的検索) は、
「元の質問を小さなサブクエリに分解し、それぞれで検索 → 結果を統合する」
というパターンです。
イメージとしては、木構造(ツリー)で問題を分割していく感じです。
- 元のクエリから、「論点」や「サブタスク」を LLM で抽出
- 各サブクエリごとに RAG を実行
- 最後に、サブ結果をまとめる回答フェーズをもう一度 LLM で回す
3.2 どんなタスクで効くか
-
マルチホップQA
例:「論文 A と論文 B の違いを、手法 / データセット / 結果の3観点で整理して」
→["Aの手法", "Bの手法", "Aの結果", "Bの結果", "AとBの違い"]のように分割して扱いたい。 - 大きな仕様書を章ごとに分解して比較するタスク
例:「旧バージョン仕様書と新バージョン仕様書の差分を、API / セキュリティ / 料金で一覧にして」
3.3 ざっくりした流れの疑似コード
実際のコードは少し長くなるので、流れだけ擬似コードで書くとこんな感じです。
def decompose_query(query: str) -> list[str]:
# LLMに「論点を3〜5個に分解して」と頼む
text = call_llm(
f"次の質問を、必要なサブ質問に分解してください。箇条書きで3〜5個:\n\n{query}"
)
# 箇条書きテキスト → リスト にパースする処理を書く
return parse_bullets(text)
def recursive_rag(query: str) -> str:
# 1. 分解フェーズ
subqueries = decompose_query(query)
# 2. 各サブクエリについて、普段の RAG を回す
sub_answers = []
for sq in subqueries:
ans = answer(sq, mode="rag") # 前回実装の RAG 関数を再利用
sub_answers.append({"question": sq, "answer": ans})
# 3. 最後に統合フェーズ
final = call_llm(
f"""元の質問: {query}
以下は、サブ質問ごとの回答です。これらを踏まえて、
元の質問への最終的な回答を、日本語でコンパクトにまとめてください。
{sub_answers}
"""
)
return final
ポイントは、
- 分解 → 各サブタスクで RAG → 統合 の 3段階をはっきり分けること
- 個々の RAG の実装は前回の Advanced RAG のままでよく、
フローの組み方だけ で Recursive Retrieval に近づけられること
です。
4. Adaptive Retrieval:モデルが「いつ検索するか」を決める
図1(再). RAGにおける検索-生成の3パターン(Gao et al., 2024 Fig.5 より)
4.1 コンセプト
最後の Adaptive Retrieval(適応的検索) は、
「検索するかどうか、いつ検索するかを モデル自身が判断する」
というパターンです。
代表的な研究としては、
-
Self-RAG:テキスト生成中に、
retrieve/criticなどの専用トークンを使いながら、自分で検索タイミングや自己チェックを行う - FLARE:生成中のトークン確率が低くなる(=自信が下がる)箇所で追加検索を挟む
といったものがあります。
実装としてはかなり複雑ですが、コンセプトとしてはシンプルで、
モデルの「自信がないところ」だけ外部知識で補強する
という考え方です。
4.2 どんなタスクで効くか
- 回答の 一部だけ 外部知識が必要なタスク
例:- 前半は一般的な概念説明(モデルの知識でOK)
- 後半だけ社内規定や固有名詞を参照する必要がある
- コストを抑えたい場合
→ 毎回フル RAG ではなく、「怪しいときだけ検索したい」
4.3 擬似 Adaptive Retrieval の最小パターン
本物の Self-RAG を実装するのは重いので、
まずは 「検索した方がよさそうか?」を LLM に先に聞いてみる という、疑似的なパターンから始められます。
def need_retrieval(query: str) -> bool:
"""この質問は外部ドキュメントを見ないと危なそうか?をLLMに聞く簡易版"""
judgment = call_llm(
f"""次の質問に答えるには、社内ドキュメントなど
外部の知識ベースを参照した方が安全だと思いますか?
「はい」か「いいえ」だけで答えてください。
質問: {query}
"""
)
return "はい" in judgment
def adaptive_answer(query: str) -> str:
if need_retrieval(query):
# RAGを使うルート
return answer(query, mode="rag")
else:
# 素のLLMだけで答えるルート
return answer(query, mode="prompt")
これでもう、かなり簡略化された Adaptive Retrieval もどき になります。
- まだ「生成途中で検索する」までは行っていない
- しかし、「検索するかどうかの判断」を LLM に任せている
という意味で、Fig.5 の Adaptive Retrieval の考え方を かなり低コストで試せる 形です。
この記事では、Fig.5 を手がかりに
- Iterative Retrieval:必要なら何度も検索する
- Recursive Retrieval:問題をサブクエリに分解して、それぞれ検索する
- Adaptive Retrieval:そもそも検索するかどうかをモデルが決める
という 3 つのパターンを、既存の Advanced RAG を少し拡張する形で眺めてみました。
すべてを一気に実装する必要はなく、
- まずは「Iterative っぽく」1〜2 回の追い検索を入れてみる
- マルチホップっぽいタスクが見えたら Recursive パターンを検討する
- コストや精度のバランスを見ながら、簡易 Adaptive を足していく
くらいのスタンスで、既存の RAG を 少しずつエージェント寄り にしていくのが現実的だと思います。
【現在採用強化中です!】
- AIエンジニア
- PM/PdM
- 戦略投資コンサルタント
▼代表とのカジュアル面談URL

Discussion