🐼
[RAPIDS]GPUを使ってPandasを爆速にしよう
RAPIDS
RAPIDSとは、NVIDIA社が提供するオープンソースライブラリ群(と呼べばいいのか)で、極々簡単にいうならばPandasやScikit-learn、networkxなど日頃データサイエンスでよく使うPythonライブラリのGPU版です。元となっているライブラリの使用感をほぼそのままに、かつGPUの力を使って高速に処理できるようになります。
要はGPUの恩恵をもっと幅広く受けられるようにしようぜ、というものですね。今回、少しRAPIDSに触れる機会がありその凄さを感じ取ることができたのでその実装を含めて紹介します。
参考
取り組んだこと
- GoogleColabでの実装を行います
- ひとまず、PandasとそのGPU版であるcudfの処理速度差まで確認します
GoogleColabでの実装
実装方法
何の芸もないですが、こちらのページにあるGoogleColabのリンクを開き、notebookを上から順に実行するだけです。
いくつか補足します。
- 使用中のGPUを確認しましょう。
GoogleColabではGPUを自動で割り当てられるのですが、注意書きにある通りTesla T4, P4, or P100どれかになっていることを下記のコマンドで確認しましょう。
!nvidia-smi
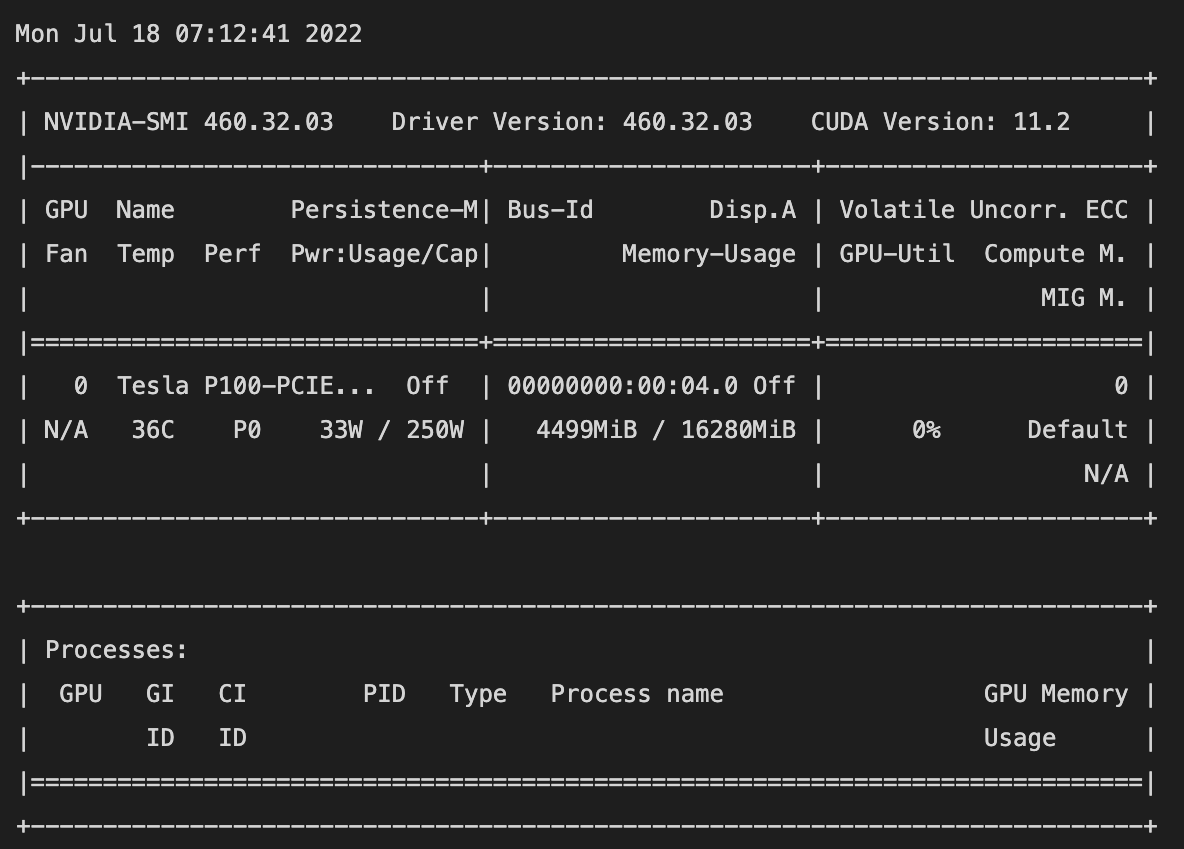
左側中段 Tesla P100が割り当てられています
- notebookを実行すると何度かGoogleColabがクラッシュ→再起動しますが焦らないでください。
- 一つ一つのセルを順番に実行してください。
- Restarting kernel...というメッセージが、処理が続いている雰囲気で表示されるのですがそこで終わりなので次にいきましょう。
- ひとまず下記の箇所までの実行で大丈夫です
# Installing RAPIDS is now 'python rapidsai-csp-utils/colab/install_rapids.py <release> <packages>'
# The <release> options are 'stable' and 'nightly'. Leaving it blank or adding any other words will default to stable.
!python rapidsai-csp-utils/colab/install_rapids.py stable
import os
os.environ['NUMBAPRO_NVVM'] = '/usr/local/cuda/nvvm/lib64/libnvvm.so'
os.environ['NUMBAPRO_LIBDEVICE'] = '/usr/local/cuda/nvvm/libdevice/'
os.environ['CONDA_PREFIX'] = '/usr/local'
PandasのGPU版 cudfの速さを試してみる
簡単な操作でPandasとcudfの速さを比較します。notebookの続きで下記を実行してください。
- ライブラリの読み込み
import pandas as pd
import cudf
#テスト用のデータセットを用いるために使用
from sklearn.datasets import make_spd_matrix
- ランダムな大きめのデータを作り、Pandas,cudfのデータフレームとする
#10000×10000のランダムな対称正定値行列を作る
random_10000 = make_spd_matrix(10000, random_state=None)
#Pandasでデータフレームを作成
df_random = pd.DataFrame(random_10000)
#Pandasデータフレームをcudf形式にする(GPUに載せる)
cudf_random = cudf.from_pandas(df_random)
これから先、df_random(Pandas) VS cudf_random(cudf)の比較をします。
10000×10000のデータフレームを保存するのにかかる時間を計測
#Pandas
%%time
file_name = "df_random.csv"
df_random.to_csv(file_name, index=False)

Pandasだと2分33秒くらい
#cudf
%%time
file_name = "cudf_random.csv"
cudf_random.to_csv(file_name, index=False)

cudfだと7秒くらい
10000×10000のデータフレームを読み込むのにかかる時間を計測
#Pandas
%%time
df_random = pd.read_csv("df_random.csv")

Pandasだと40秒くらい
#cudf
%%time
cudf_random = cudf.read_csv("cudf_random.csv")

cudfだと2秒くらい
整理
| タスク | Pandas | cudf |
|---|---|---|
| 保存 | 2分33秒 | 7秒 |
| 読み込み | 40秒 | 2秒 |
まとめ
今回はデータセットの読み込みと保存だけでしたが、両者の処理速度に大きな差が出ました。例えばヘルスケア業界ではリアルワールドデータといった大規模なデータセットを扱うことがあるのですが、その処理を高速化できるのであればかなりの恩恵を受けられそうに思います。
RAPIDSの真価はデータフレームだけでなく機械学習やネットワーク図なども含めて感じられるものですので、また改めて記事にしようと思います。
あとがき
GoogleColabで毎回環境作るのはさすがに面倒ですね。
Discussion