[streamlit]Pythonで機械学習アプリを作ってみよう.vol01
はじめに
本格的な機械学習作業の前におおよその状態を掴んでおきたい時であったり、Pythonが分からない方とコミュニケーションを取りながら作業を進めたいケースではWEBアプリの活用が役に立ちます。
Pythonを用いてアプリ作成する方法はいくつかありますが、中でもstreamlitというライブラリはHTML、CSS、PHP、Javascriptの記述を必要としないという特徴から、多くのデータサイエンティストにとって比較的扱いやすいと言えるでしょう。
この記事では、streamlitに関するPythonコードの記述とその挙動を確かめながら簡単な機械学習アプリを実装してみます。
完成イメージ
- csvファイルで読み込んだデータセットから特徴量を選んで散布図を描画します
- 説明変数、目的変数を選択して重回帰分析またはロジスティック回帰分析にてモデリングを行います
対象となる方
- 機械学習アプリの作成と実装に取り組んで見たい方
- Pythonの基本的な記述が理解できる方
- Anaconda、Dockerなどを用い自身のPython環境が構築できている方
- 機械学習タスクを経験したことがある方(サンプルコードの写経程度でもOK)
ご期待に添えないケース
- 解析環境をGoogleColabのみとされている場合は、おそらくこの記事では手順が不足しています
- streamlitヘビーユーザー向けではありません
- 機械学習プログラミング、及び理論自体を深掘りしていく記事ではありません
- 企業で優れたBIツールを導入している場合は、そこまで恩恵を感じられないかもしれません
全体のながれ
- 環境の準備
- Pythonコードの準備
- 実装
- 各パートの記述について解説
環境の準備
使用するPython環境に必要なライブラリをインストールします。
pip install streamlit
ただし、Anaconda環境の方は下記のインストールが推奨されているようです。
conda install -c conda-forge streamlit
その他、pandas、scikit-learn、matplotlib、seabornも今回のアプリでは必要になりますので、まだの場合は同様にインストールしてください。
Pythonコードの準備
VS Codeなどのテキストエディタを用いて下記のPythonコードをapp.pyというファイル名で保存します。
#ライブラリの読み込み
import time
import streamlit as st
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#タイトル
st.title("機械学習アプリ")
st.write("streamlitで実装")
# 以下をサイドバーに表示
st.sidebar.markdown("### 機械学習に用いるcsvファイルを入力してください")
#ファイルアップロード
uploaded_files = st.sidebar.file_uploader("Choose a CSV file", accept_multiple_files= False)
#ファイルがアップロードされたら以下が実行される
if uploaded_files:
df = pd.read_csv(uploaded_files)
df_columns = df.columns
#データフレームを表示
st.markdown("### 入力データ")
st.dataframe(df.style.highlight_max(axis=0))
#matplotlibで可視化。X軸,Y軸を選択できる
st.markdown("### 可視化 単変量")
#データフレームのカラムを選択オプションに設定する
x = st.selectbox("X軸", df_columns)
y = st.selectbox("Y軸", df_columns)
#選択した変数を用いてmtplotlibで可視化
fig = plt.figure(figsize= (12,8))
plt.scatter(df[x],df[y])
plt.xlabel(x,fontsize=18)
plt.ylabel(y,fontsize=18)
st.pyplot(fig)
#seabornのペアプロットで可視化。複数の変数を選択できる。
st.markdown("### 可視化 ペアプロット")
#データフレームのカラムを選択肢にする。複数選択
item = st.multiselect("可視化するカラム", df_columns)
#散布図の色分け基準を1つ選択する。カテゴリ変数を想定
hue = st.selectbox("色の基準", df_columns)
#実行ボタン(なくてもよいが、その場合、処理を進めるまでエラー画面が表示されてしまう)
execute_pairplot = st.button("ペアプロット描画")
#実行ボタンを押したら下記を表示
if execute_pairplot:
df_sns = df[item]
df_sns["hue"] = df[hue]
#streamlit上でseabornのペアプロットを表示させる
fig = sns.pairplot(df_sns, hue="hue")
st.pyplot(fig)
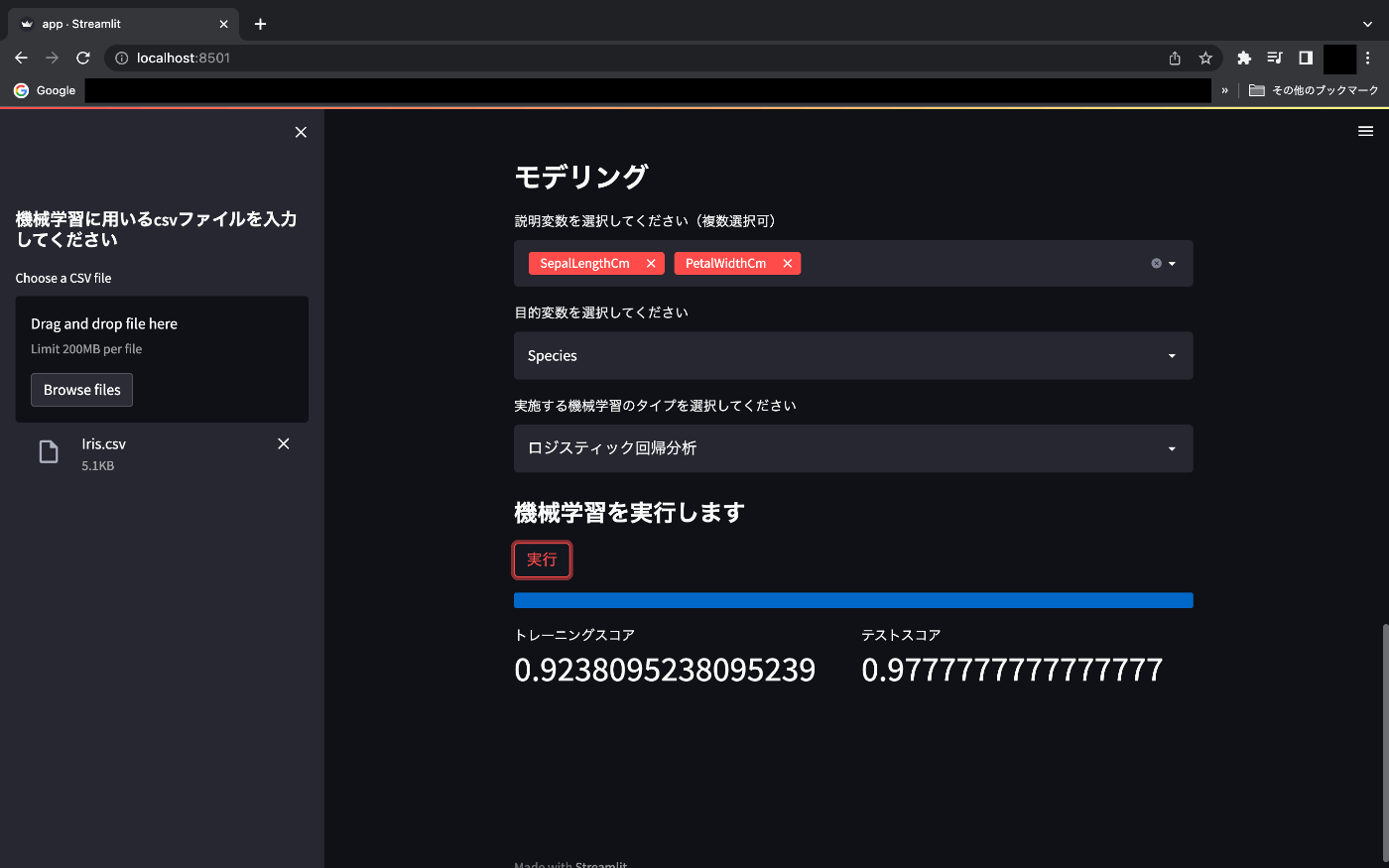
st.markdown("### モデリング")
#説明変数は複数選択式
ex = st.multiselect("説明変数を選択してください(複数選択可)", df_columns)
#目的変数は一つ
ob = st.selectbox("目的変数を選択してください", df_columns)
#機械学習のタイプを選択する。
ml_menu = st.selectbox("実施する機械学習のタイプを選択してください", ["重回帰分析","ロジスティック回帰分析"])
#機械学習のタイプにより以下の処理が分岐
if ml_menu == "重回帰分析":
st.markdown("#### 機械学習を実行します")
execute = st.button("実行")
lr = linear_model.LinearRegression()
#実行ボタンを押したら下記が進む
if execute:
df_ex = df[ex]
df_ob = df[ob]
X_train, X_test, y_train, y_test = train_test_split(df_ex.values, df_ob.values, test_size = 0.3)
lr.fit(X_train, y_train)
#プログレスバー(ここでは、やってる感だけ)
my_bar = st.progress(0)
for percent_complete in range(100):
time.sleep(0.02)
my_bar.progress(percent_complete + 1)
#metricsで指標を強調表示させる
col1, col2 = st.columns(2)
col1.metric(label="トレーニングスコア", value=lr.score(X_train, y_train))
col2.metric(label="テストスコア", value=lr.score(X_test, y_test))
#ロジスティック回帰分析を選択した場合
elif ml_menu == "ロジスティック回帰分析":
st.markdown("#### 機械学習を実行します")
execute = st.button("実行")
lr = LogisticRegression()
#実行ボタンを押したら下記が進む
if execute:
df_ex = df[ex]
df_ob = df[ob]
X_train, X_test, y_train, y_test = train_test_split(df_ex.values, df_ob.values, test_size = 0.3)
lr.fit(X_train, y_train)
#プログレスバー(ここでは、やってる感だけ)
my_bar = st.progress(0)
for percent_complete in range(100):
time.sleep(0.02)
my_bar.progress(percent_complete + 1)
col1, col2 = st.columns(2)
col1.metric(label="トレーニングスコア", value=lr.score(X_train, y_train))
col2.metric(label="テストスコア", value=lr.score(X_test, y_test))
実装
使用するPython環境でターミナル(Winの場合コマンドプロンプト)を開きます。私の場合、VS Codeのメニューから新しいターミナルを開きます(画面下部にターミナルが表示されます)
ターミナルで、先ほど保存したapp.pyファイルを格納しているフォルダまで移動します。cd 移動先フォルダ名と入力してreturnです。私の場合、User直下のstreamlitフォルダに保存したので下記のようになります。
cd streamlit
app.pyを含むフォルダまで移動できたら、いよいよアプリを起動します。ターミナルで下記を実行してください。
streamlit run app.py
正常に起動できたらターミナル上にメッセージが表示されます。数字の部分は異なっているかもしれません。
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
経験上、自動的にブラウザが立ち上がるのですがそうでない場合はブラウザで下記のURLを入力してください。8501と書いている部分は上記のメッセージに合わせます。
http://localhost:8501
各パートの記述について解説
streamlitの操作方法は全て公式Documentに掲載されていますので、そちらをご覧いただくことが一番よいと思います。
とはいえ折角ですので、今回のサンプルアプリapp.pyについてパートごとに解説します。
ライブラリのインポート
通常のPythonと同じです。streamlitはstという名称で読み込むことが慣例のようです。
#ライブラリの読み込み
import time
import streamlit as st
以下略
テキストの記法
テキストの表示は下記のように記載します。マークダウンについては#の数を増やすごとに文字が小さくなります。
st.title("機械学習アプリ")
st.write("streamlitで実装")
st.markdown("### モデリング")
サイドバーの活用とファイルの送信
最初にcsvファイルを入力するところからこのアプリがスタートするのですが、全て縦に連なるページというのも味気ないのでその部分だけサイドバーに出力しています。
# 以下をサイドバーに表示
st.sidebar.markdown("### 機械学習に用いるcsvファイルを入力してください")
#ファイルアップロード
uploaded_files = st.sidebar.file_uploader("Choose a CSV file", accept_multiple_files= False)
if uploaded_files:
以下略
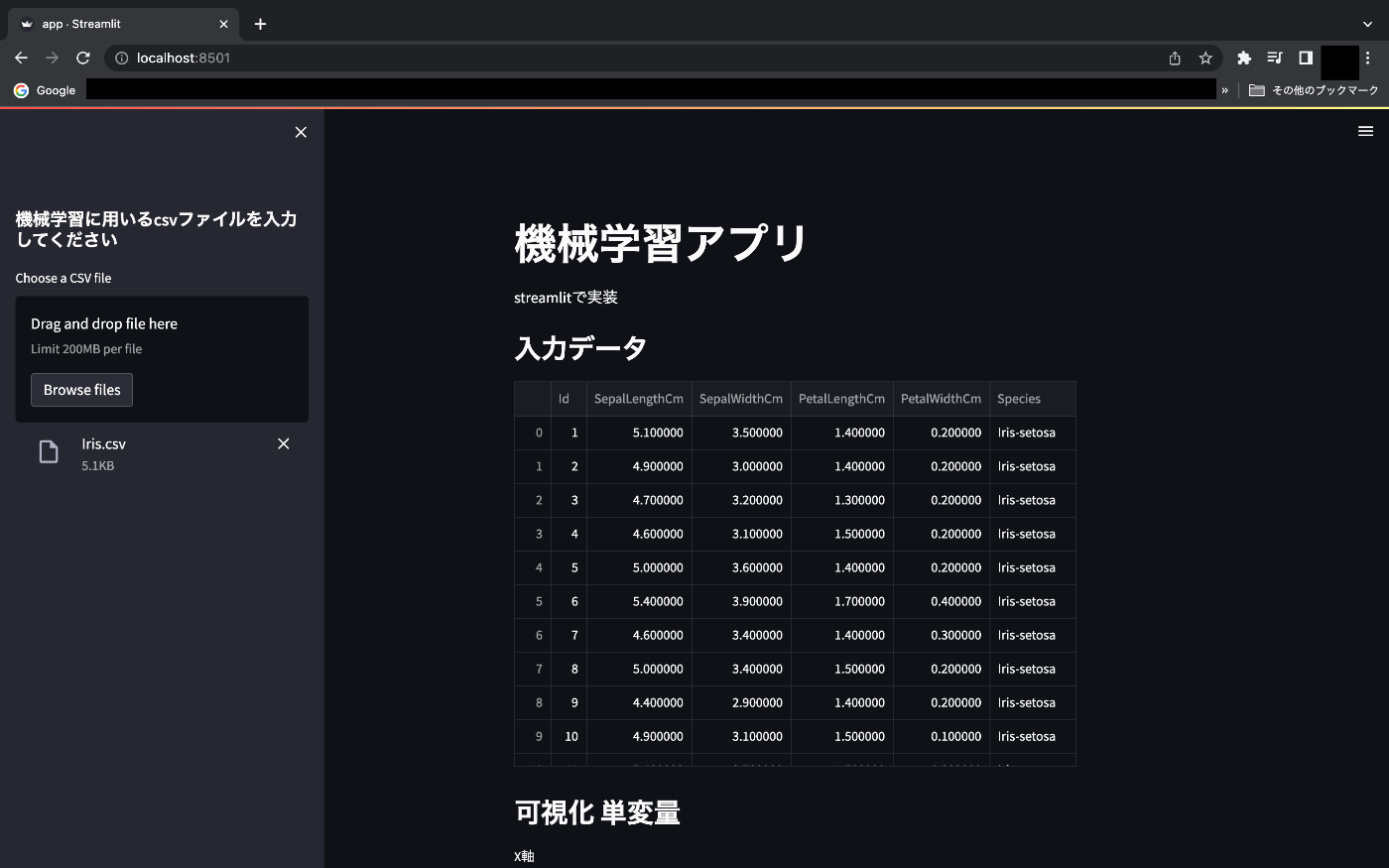
データフレームの表示
csvファイルが入力されると自動的にpandasデータフレームを表示します。
通常のPython使用時のようにpandasだけでも表示はできるのですがst.dataframe(df.style.highlight_max(axis=0))といった記述を用いることにより、ハイライトが利いていてより見易い表を出力できます。
なお、データフレームの列情報df.columnsをここで取得しているのは、後に可視化や機械学習の特徴量選択時に用いるためです。
df = pd.read_csv(uploaded_files)
df_columns = df.columns
#データフレームを表示
st.markdown("### 入力データ")
st.dataframe(df.style.highlight_max(axis=0))
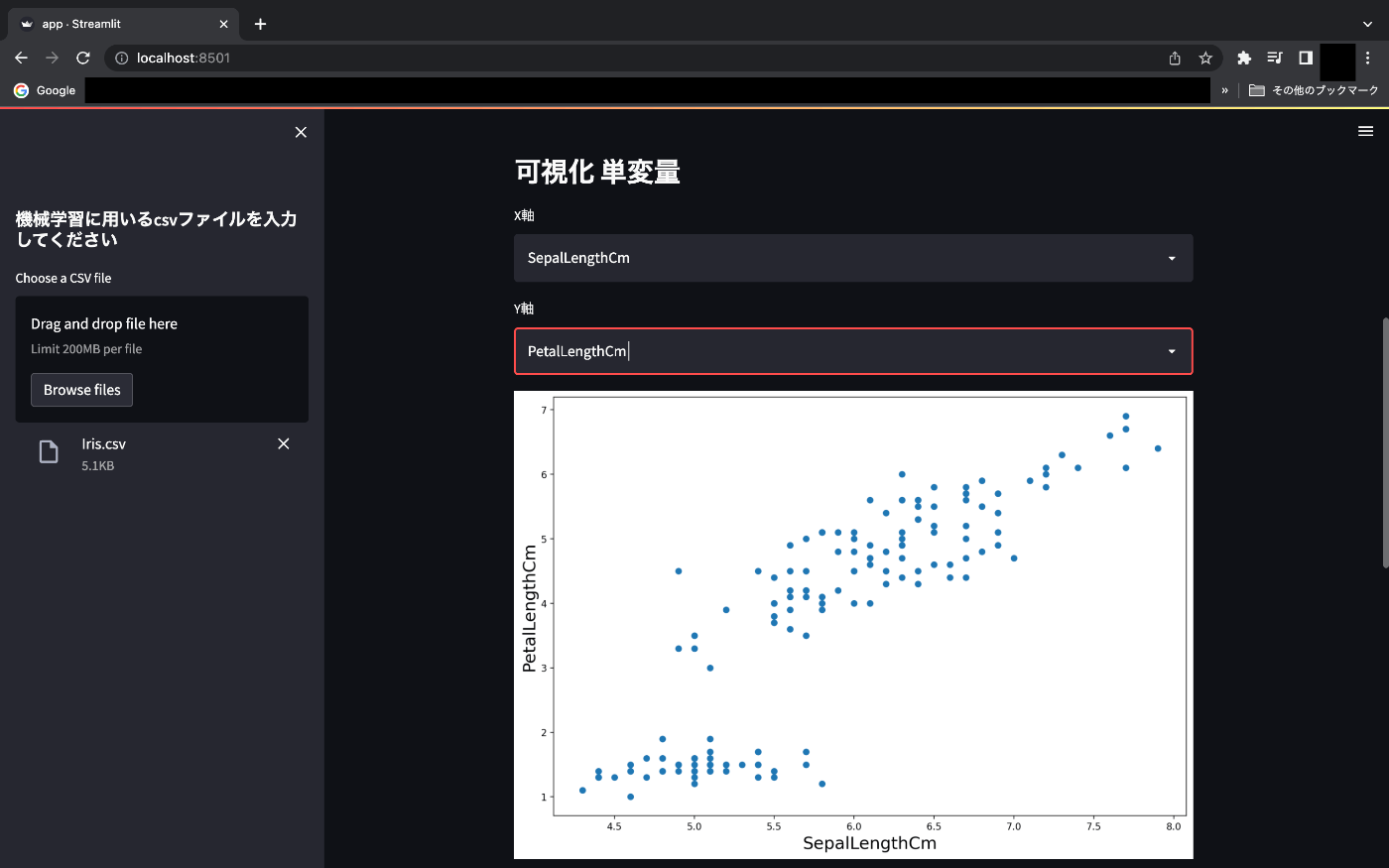
シンプルな可視化(単変量)
matplotlibでの可視化です。st.selectboxを用いてX軸とY軸に何を設定するかを選び、それをx,yの変数に代入しています。描画時はst.pyplot()と記述します。
#データフレームのカラムを選択オプションに設定する
x = st.selectbox("X軸", df_columns)
y = st.selectbox("Y軸", df_columns)
#選択した変数を用いてmtplotlibで可視化
fig = plt.figure(figsize = (12,8))
plt.scatter(df[x],df[y])
plt.xlabel(x,fontsize = 18)
plt.ylabel(y,fontsize = 18)
st.pyplot(fig)
ペアプロットでの可視化(多変量)
seabornを用いて複数の変量を一括で眺めることも当然可能です。ここで重要なのはst.multiselect()。先ほどのグラフと異なり複数の特徴量を選択することができるメソッドになります。st.multiselect()で選択された特徴量はリスト形式となりますので、後続において非常に使い勝手が良いです。
オマケ要素としてst.button("ペアプロット描画")というボタンも設定しています。ifと組み合わせることでボタンを押して初めて処理が実行されるようになるので、特徴量を選択する前にエラーが勝手に表示されてしまうのを防いでいます。
#データフレームのカラムを選択肢にする。複数選択
item = st.multiselect("可視化するカラム", df_columns)
#散布図の色分け基準を1つ選択する。カテゴリ変数を想定
hue = st.selectbox("色の基準", df_columns)
#実行ボタン(なくてもよいが、その場合、処理を進めるまでエラー画面が表示されてしまう)
execute_pairplot = st.button("ペアプロット描画")
#実行ボタンを押したら下記を表示
if execute_pairplot:
df_sns = df[item]
df_sns["hue"] = df[hue]
#streamlit上でseabornのペアプロットを表示させる
fig = sns.pairplot(df_sns, hue="hue")
st.pyplot(fig)

モデリング
細かく設定しようと思えばキリがないので、今回は重回帰分析(目的変数が連続値)とロジスティック回帰分析(目的変数はカテゴリ)を用いたシンプルな内容に止めています。streamlit特有の操作というのは少ないので、通常のPythonを用いた機械学習タスクの流れをご存じであれば理解できることかと思います。
- 説明変数の選択(複数)
多変量解析なので、複数の特徴量を選択できます。数値データでないと後続がエラーになります。
#説明変数は複数選択式
ex = st.multiselect("説明変数を選択してください(複数選択可)", df_columns)
- 目的変数の選択
目的変数は1種類を選択します。ロジスティック回帰分析はカテゴリデータでも構いません。
#目的変数は一つ
ob = st.selectbox("目的変数を選択してください", df_columns)
- 機械学習のタイプ(重回帰分析かロジスティック回帰分析か)を選択し、以降を分岐させる
#機械学習のタイプを選択する。
ml_menu = st.selectbox("実施する機械学習のタイプを選択してください", ["重回帰分析","ロジスティック回帰分析"])
if ml_menu == "重回帰分析":
以下略
- データを訓練データ、テストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(df_ex, df_ob, test_size = 0.3)
- 機械学習でフィッティングする
lr = LogisticRegression()
中略
lr.fit(X_train, y_train)
- 訓練、テストスコアを出力する
st.write()などで普通に書いてもいいのですが、他にst.metric()というメソッドもあり、スコアのような指標を表示させる場合はこちらの方が「それっぽい」ので今回採用しています。二つ並べるときは一旦st.columns(2)でその旨を指定し、col1.metric(ラベル、値)と記述します。
col1, col2 = st.columns(2)
col1.metric(label="トレーニングスコア", value=lr.score(X_train, y_train))
col2.metric(label="テストスコア", value=lr.score(X_test, y_test))

- プログレスバー
余談ですが下記の記述によりプログレスバーを表示させています。ただしモデリングの進捗を正確に反映しているものではなく、「なんとなく格好いい、やってる感」に過ぎません...
この記事をご覧の方には是非上手に活用していただければと思います。

my_bar = st.progress(0)
for percent_complete in range(100):
time.sleep(0.02)
my_bar.progress(percent_complete + 1)
おわりに
以上、streamlitを用いた簡単な機械学習アプリの作成でした。重要なのはデプロイ(要はブラウザへの表示)の方法とstreamlit独特の記述くらいなもので、あとは普段通りにPythonでやりたいことを書けばいいだけです。場当たり的に開発すると「なんだかよく分からないものが出来上がる」のはアプリ・システム開発あるあるなので、「何が求められているか、何がしたいのか」要件定義を明確にしてから取り掛かるのが良いかもしれませんね。
Discussion