自分でECS/Fargateやその周辺リソースのインフラ構築・整備をしたり、まわりのインフラ強くないチームメンバーがデバッグに苦戦する様子を見ながら、やっぱりECSは登場するリソースがちと多かったり役割分担がとっつきにくかったりするよなぁと思っていました。
漠然とそんなことを思っていた頃、社内で自分の属するグループに勉強会が爆誕し「これはECSの話するしかないのでは」と思い立ち...そのまま2ヶ月ほど経過してしまいました。というわけで社内アドベントカレンダーに登録し、締切駆動執筆することにしました。というわけで
この記事は LITALICO Engineers Advent Calendar 2023 の18日目の記事です。
はじめに
この記事では、ECS、特にFargateを使ったWebサーバの構築を、基礎からハンズオン的に組み上げていく内容になっています。ECSタスクやタスク定義、サービス、デプロイの動きやALBとの連携、エラー確認がスコープです。
また経緯として、社内のインフラ(というよりECS/Fargate)を使っているがあまり詳しくないメンバーたちに対し、取っ掛かり程度に登場人物たちを知ってもらう勉強会ネタを想定して書かれています。
そのため想定読者は
- 業務でECS/Fargateなアプリケーションを書いておりある程度の保守を行っているエンジニア
- 一応普段の開発をやるのに支障はない程度の理解はあるが、インフラ変更のレビューでイマイチ良くわからない・トラブル時にどこの何を見て調査すればいいのか自信がない
のようになっています。すでに自分で構築ができるほどの方や逆にECSを触ったことないような方は対象外になっています。
下準備:AWSの周辺リソース一式を用意する
本記事ではFargateによるタスクやサービスをじっくり作っていきますが、あくまで運用者を対象としていることもあり、Fargateコンテナを動かすために必要となる周辺リソースの話はほとんどしません。
しかしながら必要な周辺リソースは地味に多いため、ここでは拙作の周辺リソース一式構築セット[1]を使います。
READMEの使い方セクションにある3要素のうち「AWSインフラ」のみを使います(appコンテナとecspressoの成分は記事内で作ります)。READMEに従いAWSインフラ部分をterraform applyすれば、3分クッキングよろしくリソースセットが出来上がります。この時点ではALBは不要です(あとで作ります)。
なお、terraform applyすると下記のようにOutputsが出力されますが、それぞれ後で利用するため、どこかに記録しておきます。
...
Apply complete! Resources: 14 added, 0 changed, 0 destroyed.
Outputs:
log_group_name = "/ecs/fargate-skeleton_jikkuri-main"
repository_url = "xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/fargate-skeleton_jikkuri"
security_group_id = "sg-03039ee76fdf43249"
subnet1_id = "subnet-0e0ffebc344d9c9cd"
subnet2_id = "subnet-015290279b708b989"
target_group_arn = "arn:aws:elasticloadbalancing:ap-northeast-1:xxxxxxxxxxxx:targetgroup/fargate-skeleton-jikkuri-main/745c0b38f0caab9a"
task_execution_role_arn = "arn:aws:iam::xxxxxxxxxxxx:role/fargate-skeleton_jikkuri_task_execution_role"
※ここではTF_VAR_nameをjikkuriにしています。
単純なコマンドを実行する
じっくり動かしていくということで、まずはコンテナで単純なコマンドを実行してみます。
docker composeでやってみる
実際にFargateを使う前に、動かす予定の同等のものをdocker composeで起動します。Rubyでhello worldということで、下記のように定義ファイル[2]を用意します。
services:
app:
image: ruby:3.2-slim
command: ruby -e "puts 'じっくり!Fargate'"
用意したら、よくある開発のようにdocker compose upしてみます。

dockerイメージのpullが行われ、compose用のネットワークとコンテナを作成し、コンテナでputs "じっくり!Fargate"が実行されていそうなことがわかります。
サーバコマンドなどではなく出力して終了なコマンドを指定しているので、実行後はすぐ終了しています。
タスク定義を用意する
次に、これと同等のものをFargateで実行してみます。Fargat(ECS)では、docker-compose.yamlに近い設定を「タスク定義」と呼ばれるリソースで指定します。ちなみに、AWSのドキュメントによると、タスク定義は
タスク定義はアプリケーションのブループリントです。これは、アプリケーションを形成するパラメータと 1 つ以上のコンテナを記述する JSON 形式のテキストファイルです。
となっています。
というわけで、Fargateで起動可能な、できるだけシンプルにしたタスク定義のjsonがこちら。
// 説明のためコメントを入れていますが、実際にはコメント付きJSONは扱えないので、コメントは消してください
{
"family": "fargate-jikkuri", // タスク定義の名前。適当に命名する
"cpu": "256",
"memory": "512",
// terraform outputsのtask_execution_role_arnの値
"executionRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/fargate-skeleton_jikkuri_task_execution_role",
"networkMode": "awsvpc",
"containerDefinitions": [
{
"name": "app",
"image": "ruby:3.2-slim",
"command": ["ruby", "-e", "puts 'じっくり!Fargate'"],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/fargate-skeleton_jikkuri-main", // terraform outputsのlog_group_nameの値
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "logs"
}
}
}
]
}
これを適当な名前(ここではhello-taskdef.json)で作成し、下記のコマンドでタスク定義の登録ができます。
aws ecs register-task-definition --cli-input-json fileb://hello-taskdef.json
登録が成功すると、AWSコンソールのECSのタスク定義の画面に表示されるはずです。登録したタスク定義を押すと下記のように見えます。
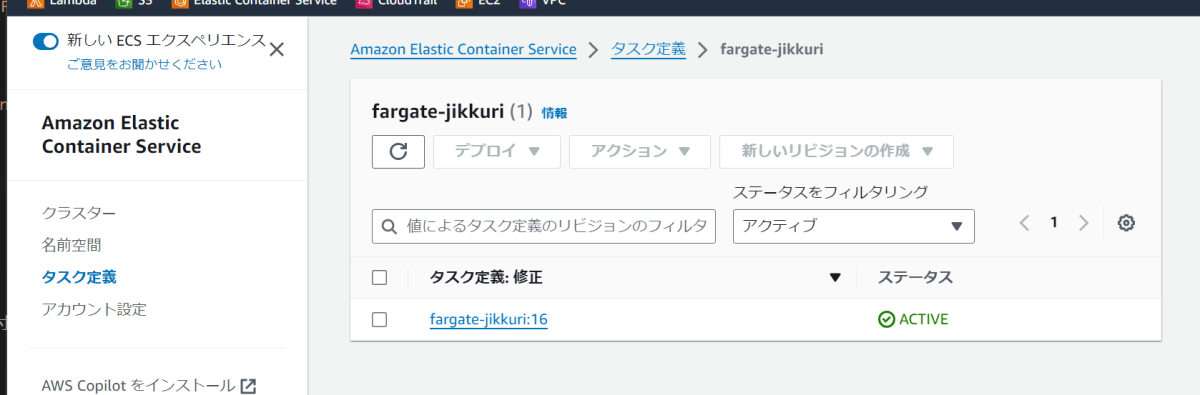
選択されているものがいま登録したもので、筆者の環境ではそこそこ試行錯誤したこともありリビジョン16となっています。新しいバージョンを登録するごとに、1から順に増えていきます。このように、タスク定義は構造としてはリビジョンが積み上がるjsonリストになっています。
ECSでは、この定義をもとに「タスク」を起動します。タスク定義が設定なのに対し、タスクは実際に動くコンテナ(群)の実体です。設定であるdocker-compose.yamlに対し、docker compose upで実際に起動するコンテナが実体、という関係に近いです。
タスクを起動してみる
それではタスクを起動してみます。さきほどのタスク定義が表示されている画面よりタスク定義のリビジョンを一つ選択し、デプロイ > タスクの実行 を選びます。
下記のような画面になりますが、「既存のクラスター」の欄で最初にterraformで作っておいたもの(fargate-skeleton-{指定した名前}になる)を選択すると、勝手にいくつかの選択肢が埋まります。

そのまま画面下にいき「作成」を押すとタスクが作成(起動)されます。クラスターのタスク一覧の画面に遷移するので表示されているタスクのIDを押すと、下記のようにタスクの詳細が確認できます。

色々と情報が見えていますが、画像中央から少し左下にタスク定義とリビジョンが表記されています。タスクには元になったタスク定義リビジョンが必ず存在しここから確認できるため、問題の調査などを行う際にはここから起動イメージのタグやスペックなどを辿ることができます。
さて、タスク作成からしばらくする※と、ログのタブより下記のように出力が確認できます。

※Fargateタスクの起動は数十秒~1,2分程度かかるので、タスクが終了するまで待つ必要があります
ここまでで、docker composeと同様のシンプルなコンテナ(コマンド)実行をFargateで再現することができました。
Webサーバを起動する
最低限Hello World的なコマンド実行はできたので、より一般的なWebサーバを起動してみます。
docker composeでやってみる
前回同様、まずはdocker composeで同等のものを動かします。最低限httpの応答さえできれば何でも良いので、ここでは下記のように変更します。
services:
app:
image: ruby:3.2-slim
- command: ruby -e "puts 'じっくり!Fargate'"
+ command: bash -c 'gem install webrick && ruby -run -e httpd /home -p 3000'
+ ports: [3000:3000]
カスタムイメージを作ると手数と解説が増えてしまうので、少々強引にwebrickをインストールしてhttpサーバを起動しています。その他オプションとして、ルートディレクトリが見えると精神衛生上よろしくないので/homeを指定し、後続のステップの都合上でポート3000を指定しています。
これでdocker compose upした上でhttp://localhost:3000にアクセスすると、下記のようにレスポンスが見えるはずです。
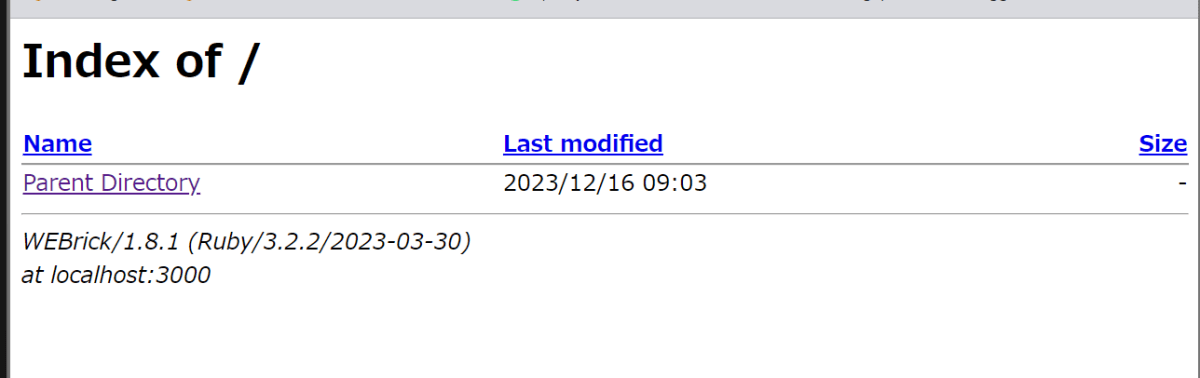
サーバーコマンドをFargateタスクで動かす
普通、FargateでWebサーバを動かすのであればECSサービスを用意してALBを作って...とすることがほとんどですが、ここではまずじっくりと単純なタスクのみでやってみます。つまり、前ステップと同じように、docker composeのものをそのまま再現します。
{
"containerDefinitions": [
{
"name": "app",
"image": "ruby:3.2-slim",
- "command": ["ruby", "-e", "puts 'じっくり!Fargate'"],
+ "command": [
+ "bash",
+ "-c",
+ "gem install webrick && ruby -run -e httpd /home -p 3000"
+ ],
+ "portMappings": [{ "containerPort": 3000 }],
"logConfiguration": {
これを前回同様にregister-task-definitionのコマンドでタスク定義として登録し、登録されたリビジョンからタスクを起動するのですが、インターネットからコンテナに疎通できるように追加設定が必要です。
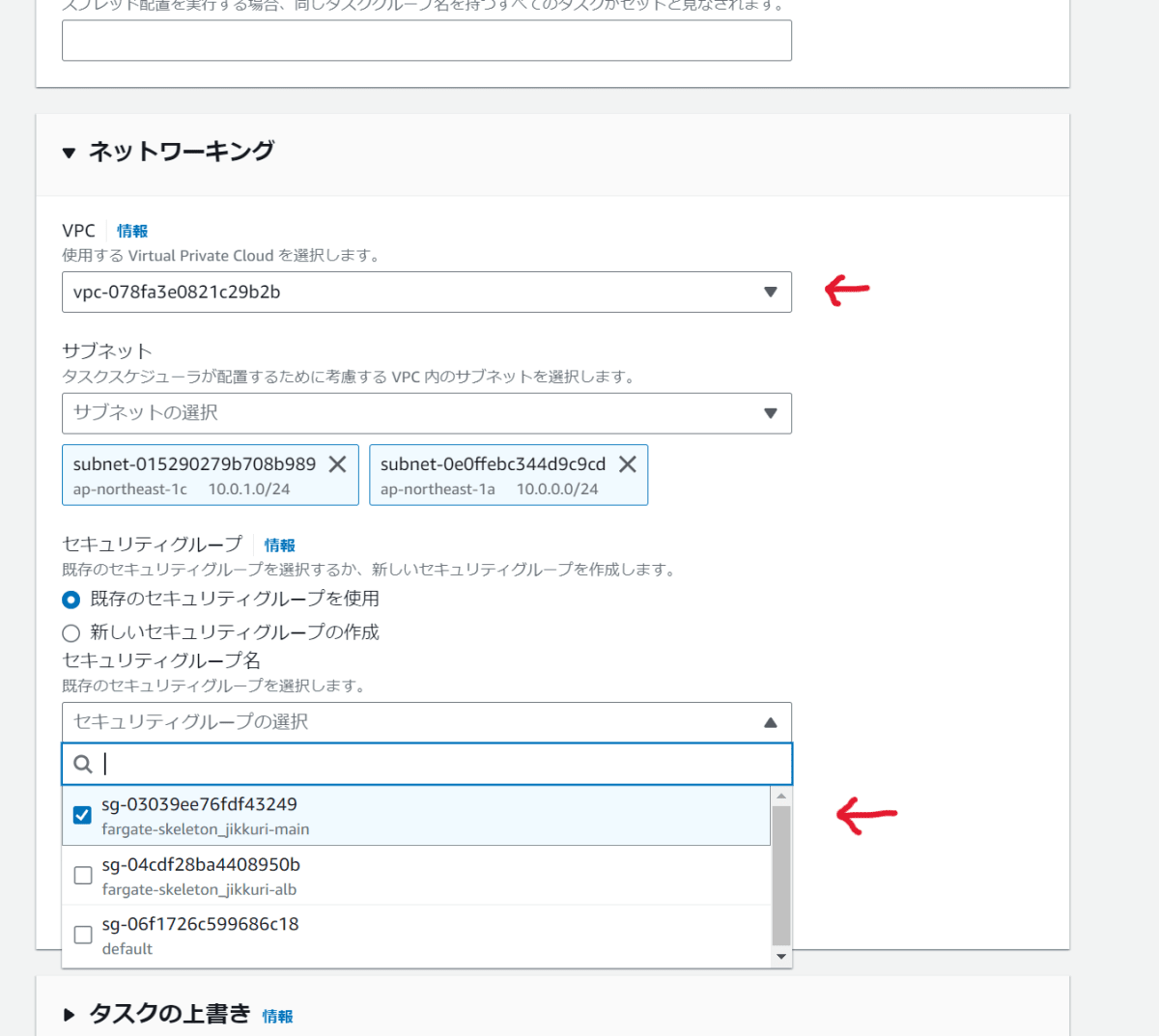
リビジョンを選択し デプロイ > タスクの実行 を選び、クラスタを選ぶところまでは前回と同様。その後タスクを作成する前に、同じ画面の少し下のネットワーキング設定を開き、下記2点を設定します。
- VPCを事前のterraformで準備したものにする(名前を見ても何もわかりませんが、雰囲気で選びましょう。間違っていれば下記セキュリティグループが一覧に出ません)
- セキュリティグループを
fargate-skeleton_xxx-mainにする(インターネット全体からTCP3000ポートへの接続を許可[3])
上記設定ができたらタスクを作成します。タスク詳細画面にいきしばらくすると、下記のような状態になります。

画面下のコンテナステータスがRunningになったことを確認後(ときどき右上の更新ボタンを押しましょう)、中央右に見えるパブリックIPをコピーし、httpで3000ポートにアクセスしてみます。この場合は http://13.231.220.13:3000 になり、これをブラウザで開きます。するとdocker composeのときと同様の画面が見えるはずです。
FargateタスクはこのようにIPアドレス[4]が割り当てられており、接続を受け付けるコマンドを実行しつつセキュリティグループで通信許可すれば、このようにブラウザからもページ閲覧可能になります。
継続稼働させる
単にWebサーバを起動して接続するだけならタスク単体でも動くことがわかったので、更にECSサービスを使っていきます。
ECSサービスとは
ECSサービスとは、公式ドキュメントによると
Amazon ECS サービスを使用すると、Amazon ECS クラスター内で、タスク定義の指定した数のインスタンスを同時に実行して維持できます。タスクの 1 つが失敗または停止した場合、Amazon ECS サービススケジューラはタスク定義の別のインスタンスを起動してそれを置き換えます。これは、サービスで必要な数のタスクを維持するのに役立ちます。
オプションで、ロードバランサーの背後でサービスを実行することもできます。ロードバランサーは、サービスに関連付けられたタスク間でトラフィックを分散させます。
となっています。ざーっくり要約すると、以下のようになります。
- タスクがN個起動している状態を維持する。減ることがあれば新規タスクを起動して補充する
- ロードバランサとの連携をいい感じにする
ECSサービスを使う
それでは、先程起動したWebサーバのタスクをECSサービス経由で起動します。
サービスもタスク定義と同様にjsonで設定を定義します。サービスはタスクを起動するもののため、設定内容には先程タスクを起動する際に指定したものと同じような属性が多くなっています。
// 例によってコメントは除去してから適用してください
{
// fargate-jikkuriの部分はタスク定義のfamilyに合わせる。リビジョンは各々の環境で最新になっているものにする
"taskDefinition": "fargate-jikkuri:20",
"desiredCount": 1,
"networkConfiguration": {
"awsvpcConfiguration": {
"assignPublicIp": "ENABLED",
// securityGroupsとsubnetsは下準備セクションでのterraformの出力から持ってくる
// もしくは、前回タスク起動したときの設定から持ってくる
"securityGroups": ["sg-03039ee76fdf43249"],
"subnets": [
"subnet-015290279b708b989",
"subnet-0e0ffebc344d9c9cd"
]
}
}
}
fargate-jikkuriタスク定義のリビジョン20をタスク数1で起動。また指定したネットワーク設定(パブリックIPあり・セキュリティグループとサブネットを指定)にする、というような内容です。
これでサービスを作成するには、下記のようにコマンド実行します[5]。
aws ecs create-service --cluster fargate-skeleton_jikkuri --service-name web --launch-type FARGATE --cli-input-json file://service-def.json
コマンドが成功したら、AWSコンソールでfargate-skeleton_jikkuriのクラスタのページを見ると、下記のようにサービスが作成されているはずです。1件のタスクが実行されていると表示されています。

※例によってタスク起動には時間がかかるので、更新ボタンを押しながら待ちます
タスクが起動すれば、前ステップと同様に、タスク詳細画面からIPアドレスを取得すれば3000ポートからwebrickの画面が見えるはずです。
タスク数を調整してみる
サービスはタスクの数を維持するものなので、設定上のタスク数を変更すれば勝手に増えるし、止めれば復活します。ここでは、タスク数を2にして増えるまで待ち、その後片方のタスクを手動で停止してみます。
サービス一覧(クラスタ詳細)ページよりサービスを選び更新ボタンを押すと変更画面が見えるので、「必要なタスク」を2にじて更新します。するとサービスのデプロイ画面になり、下記のような表示が見えます。

1件が実行中、2個が必要、とあります。実態のタスク数と設定のタスク数に差が生じたので、サービスはタスクを増やすことで解消しようとします。また、2件が実行中になった後にタスク一覧画面よりタスクを停止すると、そのうち復活してきます。
オートスケーリングで要求タスク数が増えた場合や、なんらかのエラーや負荷などでタスクが落ちてしまった場合などは、このような動きでタスク数が維持されています。
更新・公開する
ECSサービスも登場してかなり現実的になってきましたが、最後に運用を見据えてデプロイとALB設置までやってみます。
デプロイしてみる
まずデプロイですが、これは特に新しい要素はなく、新しいバージョン用のタスク定義リビジョンを作成し、サービスに設定するリビジョンを新しいものに設定するだけです。
一般的には、更新を含むアプリケーションコードをDockerイメージに詰めてビルド・何かしらのリポジトリにpushし、そのイメージを使うようにタスク定義を作ることになります。しかし本記事ではrubyのイメージをそのまま使っているので、rubyのバージョンを更新してみることにします。
ということで、まず新しいバージョンのタスク定義リビジョンを作成します。前までに使っているものから下記のように変更します。
{
"name": "app",
- "image": "ruby:3.2-slim",
+ "image": "ruby:3.3-rc-slim",
"command": [
"bash",
あと一週間でRuby 3.3がリリースされると思われる(執筆時点)ので、先んじてRC版を試しておくというシナリオにしました。この状態でAWS CLIにてregister-task-definitionしておきます。筆者の環境ではリビジョン21が登録されました。
次に、このリビジョンをサービスで使うようにします。今回はjsonからCLIで更新してみるので、サービス定義にあるタスク定義のリビジョン部分を更新します。
{
- "taskDefinition": "fargate-jikkuri:20",
+ "taskDefinition": "fargate-jikkuri:21",
"desiredCount": 1,
"networkConfiguration": {
更新コマンドは下記のようになります。create-serviceとの差分はサブコマンド名 (create-service -> update-service) と、--launch-type FARGATEがなくなったこと、サービス名指定のオプション名がservice-nameからserviceに変わったことです。オプション名は違う理由は謎。
aws ecs update-service --cluster fargate-skeleton_jikkuri --service web --cli-input-json file://service-def.json
成功すると、次第にサービス内でタスクの追加・削除が起こっていきます。タスク一覧より途中経過はこのようになっています。

新しいリビジョンのタスクを起動 → 古いリビジョンのタスクを削除、という流れになる※のですが、途中経過ではこのように新旧タスクが起動している状態も発生します※。
新リビジョンのタスク起動完了後、そのIPアドレスから3000ポートにブラウザでアクセスすると、Ruby3.3がデプロイされたことが確認できます。

ここではイメージビルドはやりませんでしたが、デプロイの流れを実施しました。現実的にはecspressoなどのツールを使って実施すると思いますが、何にせよここで実施したのと同じように(イメージビルドした後)新タスク定義を登録しサービス更新する、という手順でデプロイが実現されます。
ALBにつなぐ
最後に、ロードバランサと連携します。
ALBとその周辺リソースの構築については本筋ではないので、下準備で使ったterraformで3分クッキングします。最初にterraform applyしたときと同様で、今回はTF_VAR_use_alb環境変数をセットしてapplyすると、3分程[6]でALBとALBリスナーが出来上がります。
ECSサービスとALBの連携は、サービス側にALB(のターゲットグループ[7])を指定するかたちです。ということでサービス定義は下記のようになります。
"taskDefinition": "fargate-jikkuri:21",
"desiredCount": 1,
// containerNameは、タスク定義のcontainerDefinitionsの中にあるコンテナ定義のname。この記事のとおりであればappでよい
// targetGroupArnはterraform outputのtarget_group_arnの値
+ "loadBalancers": [
+ {
+ "containerName": "app",
+ "containerPort": 3000,
+ "targetGroupArn": "arn:aws:elasticloadbalancing:ap-northeast-1:xxxxxxxxxxxx:targetgroup/fargate-skeleton-jikkuri-main/745c0b38f0caab9a"
+ }
+ ],
"networkConfiguration": {
"awsvpcConfiguration": {
これでupdate-serviceすると、前ステップでのデプロイの流れを踏襲しつつ、新タスクのIPが指定したALBターゲットグループに登録されます。デプロイ完了後にAWSコンソールでターゲットグループを見ると、新しく作成されたタスクのローカルIPがサービスで指定したIPで登録されていることが確認できます。
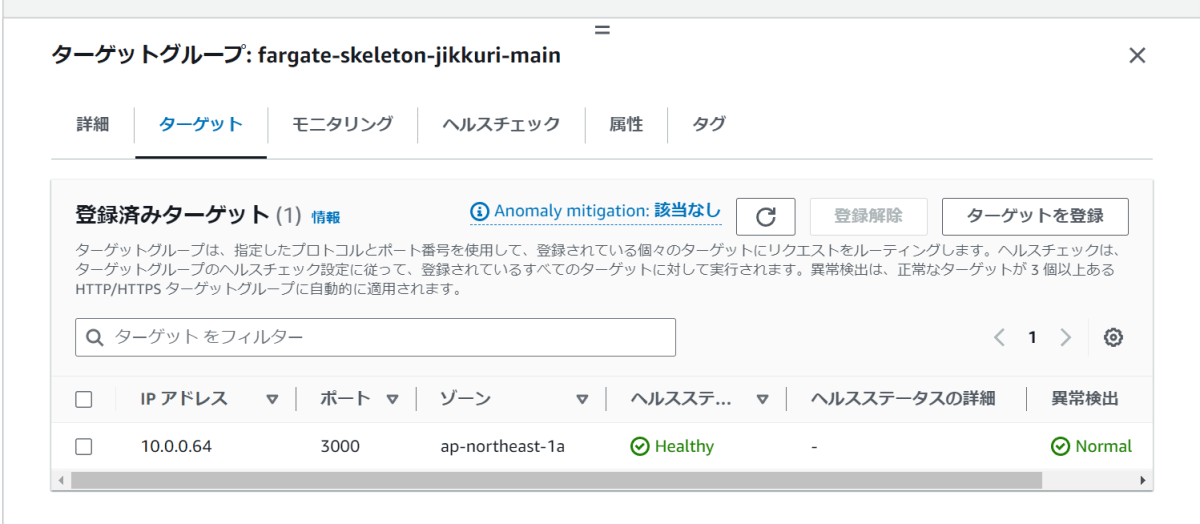
ここから更にサービス更新をすると、ヘルスチェックの検査がありつつもサービスのタスク増減と似たようなかたちで登録IPが差し替わることになります。
また、ターゲットグループに登録されているので、当然[8]ALBのドメインで閲覧できます。

最下部にALBのドメインが見えており、ALB経由になっていることが確認できます。
エラーを発生させてみる
ここで、少し実運用に近いケースとして、いくつかの異常系の挙動を見てみます。
ヘルスチェックに失敗させてみる
まずはヘルスチェックが失敗するパターンをやってみます。
用意しているターゲットグループではヘルスチェックは/へのHTTPリクエストがステータス200で返ることを検証しています。ここでは、Webサーバを起動させないようにすることで失敗させます。
"name": "app",
"image": "ruby:3.3-rc-slim",
- "command": [
- "bash",
- "-c",
- "gem install webrick && ruby -run -e httpd /home -p 3000"
- ],
+ "command": ["sleep", "infinity"],
"portMappings": [{ "containerPort": 3000 }],
"logConfiguration": {
sleep infinityすると、ただずっと終わらないコマンドを実行することができます[9]。何もしないので、当然ヘルスチェックは失敗します。
この状態でresigter-task-definitionとupdate-serviceししばらくすると、タスク一覧は下記のようになります。新しいタスクであるリビジョン22の方が停止しようとしています。
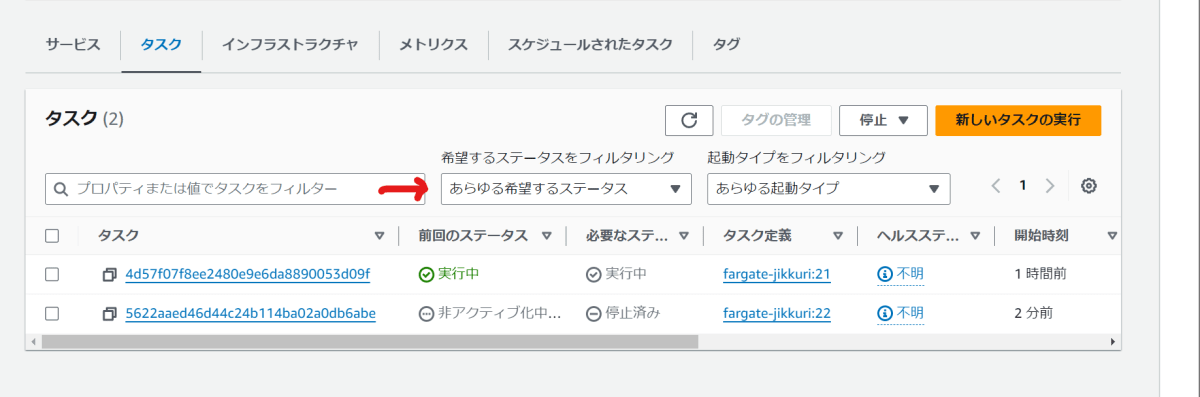
※矢印部分のフィルタリングを変更する必要があります。デフォルトでは実行中のものしか見えないので注意
ここで停止されたタスクの詳細を見ると、"Task failed ELB health checks"と終了理由が表示されます。また、ターゲットグループのターゲット一覧や、ECSサービスのイベントページにも同様にヘルスチェックが失敗した旨が表示されているはずです。失敗の種類によっては、ここから何故失敗したのかの情報が得られる場合があります。
コマンド内エラーする
次に実行コマンドがエラーで終了する場合を試してみます。想定ケースとしては、Webサーバの初期化コードがバグで動かない場合・Railsであればdb:migrateを行っていない場合などです。
"bash",
"-c",
- "gem install webrick && ruby -run -e httpd /home -p 3000"
+ "gem install webrick && ruby -run -e http /home -p 3000"
],
"portMappings": [{ "containerPort": 3000 }],
こちらも同様にデプロイしてしばらくすると、新しく起動したタスクが終了状態になっているはずです。今回の場合、タスク詳細ページより、必要なコンテナが何らか終了した(ためにタスクが終了した)こと・コンテナのログよりコマンドがNameErrorで終了していることがわかります。
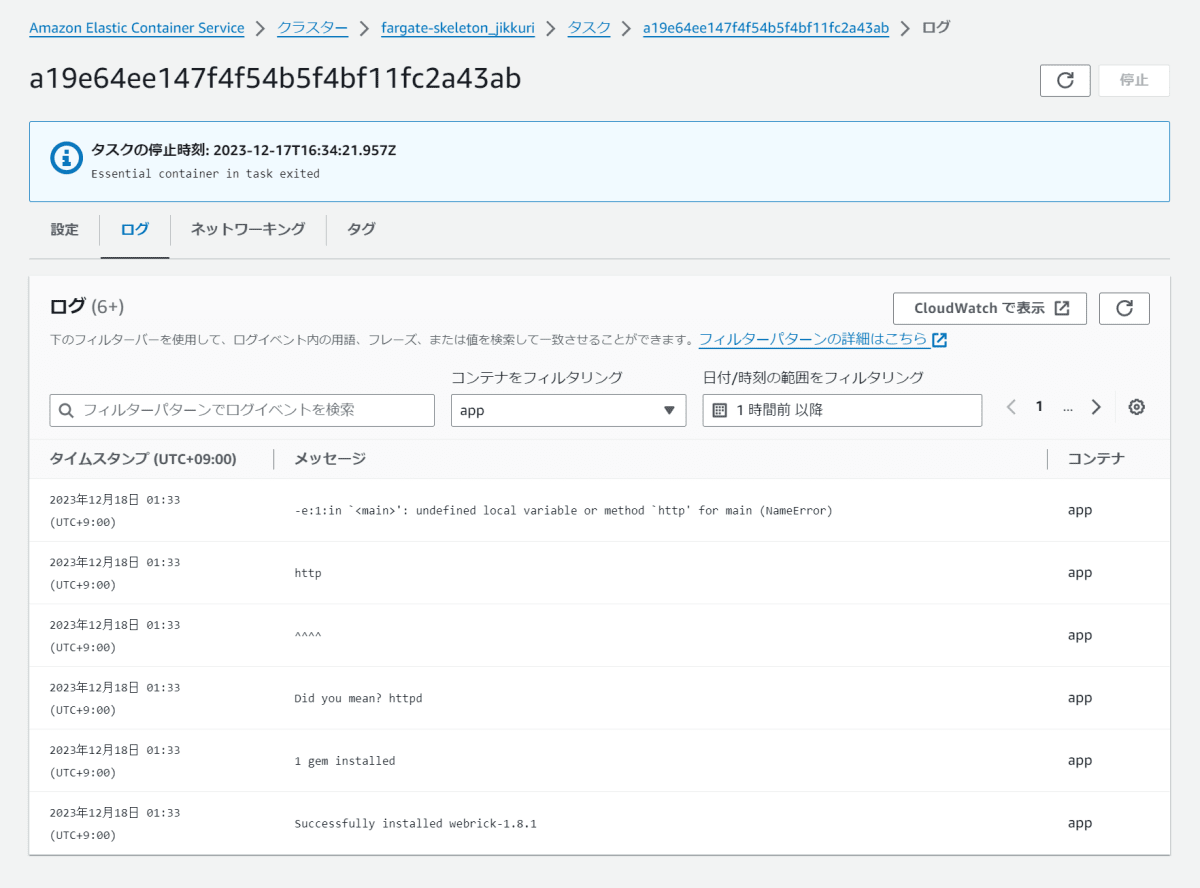
このような場合は、コンテナのログを見ることで問題は解決できることが多いでしょう。CloudWatchLogsなどにもログは出ているはずなので、そこから確認することもできるはずです。
タスク起動を失敗させる
またそれとも別のケースとして、タスク起動自体ができないケースを試します。ここではイメージタグ指定をtypoしてみます。
{
"name": "app",
- "image": "ruby:3.3-rc-slim",
+ "image": "ruby:3.3-rc-srim",
"command": [
"bash",
こちらもコマンドエラーと同様に起動しないのですが、実際に起こったエラーが確認できるのは下記のタスク詳細になります。タスクは起動していないので、ログを見ても何もわかりません(というより、ログは存在しません)。
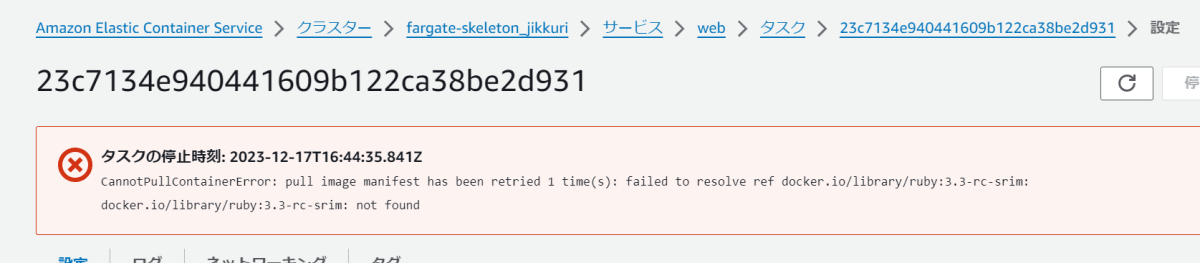
現実的にイメージタグ指定がおかしいケースは少ないと思いますが、タスク起動ができないパターンとしては、IAM関連や通信経路の問題がある・パラメータストアへのアクセスができないなど案外発生することがあります。
異常系として3ケースほど例を挙げましたが、事象によってエラーになる箇所が違ったりします。アプリケーションログだけを見ても解決できないことも多いため、確認すべき箇所がいくつかあるということを覚えておく必要があります。
まとめ
ただタスクを動かすところからWebサーバを運用に近いところに持っていくところまで、じっくりと動かしました。
見ての通り登場人物や関連が結構多くなっており、不慣れな間は覚えきることができないかもしれませんが、時折「あのへんにxxな役割のリソースがあった気がする」とか「xxとyyは別の役割だったかも」などと思い出せる程度になればと思います。
最後に改めて、継続料金が発生するリソース(ALB, タスク, サービスのタスク数)は3分クッキングのREADMEも参考にしつつしっかり片付けておきましょう。
-
これ自体はこの記事用というよりはサンドボックス用途一般です ↩︎
-
最近では
compose.yamlが標準らしいのですが、慣れの都合でdocker-compose.yamlにしています ↩︎ -
実験用途のため、実運用には適さないザル設定になっています ↩︎
-
パブリックIPが割り当てられるかはサブネットやタスク起動時の設定によりますが、本記事ではそのあたりは割愛します ↩︎
-
cluster,service-name,launch-typeはjson内でも指定できるが、後半でupdate-serviceする際の使いまわしのためコマンド側で指定しています ↩︎ -
3分クッキングは冗談なのですが、本当に2分52秒で生成されました ↩︎
-
ALBとALBリスナーとターゲットグループと...あたりも本記事では割愛します。ECS登場人物多いのよ... ↩︎
-
ALB自体のセキュリティグループは3分クッキングで作成済です ↩︎
-
この手の検証では結構便利です ↩︎
LITALICOは「障害のない社会をつくる」というビジョンを掲げ、教育・障害福祉・介護福祉などの領域で、情報メディア、HRサービス、SaaS型業務支援システム、学校向けの支援サポートのソフトウェアなど複数のビジネスモデル・サービスモデルをtoB/toC/toG向けに展開しています。
Discussion