サーバーのアクセスログを見て、「生成AIのクローラーからのアクセスが増えてる」と思ったことはないでしょうか?
以下の記事によれば、OpenAIのGPTBotは「2024年5月→2025年5月」でリクエスト数が約+305%、全クローリングに占めるシェアが2.2%→7.7%に増加しているとのことです。
クローラー全体のアクセス数も増加傾向にあり、クローラー(AI+検索エンジン)の総トラフィックは年間18%増加したというデータも出ています。
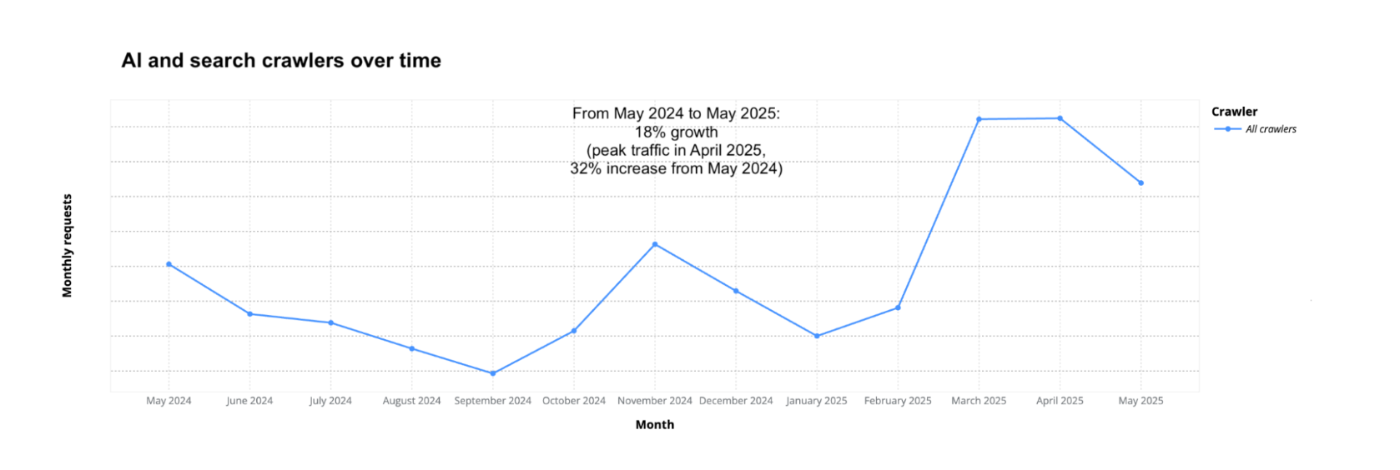
※グラフは上記記事から引用
今後もクローラーからのアクセスは増えると考えられ、場合によってはサーバー負荷にも影響します。
クローラーからのアクセス遮断を検討する場合、その役割や影響を把握したうえで判断する必要があります。クローラーからのアクセスかどうかや、クローラーの種類はUser-Agentで判定するのが一般的です。
本記事では、主要なクローラーをカテゴリ別に整理し、その機能やUser-Agentをまとめました。なお、User-Agentは偽装される可能性があるため、クローラーの正確な判定方法についても併せて解説します。
クローラー(Bot)一覧
次の5カテゴリに分けて紹介します。
- 生成AI系
- 検索エンジン系
- SNS系
- SEOツール系
- 保存・研究データ収集系
また、クローラーとBotの違いは以下で、厳密にはクローラーはBotの一種という位置付けです。
- クローラー: 主にWebを巡回して取得・インデックスする自動プログラム
- Bot: 自動プログラムの総称
🤖 生成AI系
| Bot名 | 運営組織 | User-Agent例 |
|---|---|---|
| GPTBot | OpenAI | GPTBot/1.0 (+https://openai.com/gptbot) |
| ClaudeBot | Anthropic | ClaudeBot/1.0 (+https://anthropic.com/claudebot) |
| Google-Extended | Google-Extended |
|
| Applebot (AI用途) | Apple | Applebot/0.1 (+http://www.apple.com/go/applebot) |
| PerplexityBot | Perplexity AI | PerplexityBot (+https://www.perplexity.ai/bot) |
| OAI-SearchBot | OpenAI | OAI-SearchBot |
| ChatGPT-User | OpenAI | ChatGPT-User |
| Meta-ExternalAgent | Meta | Meta-ExternalAgent |
GPTBot
- OpenAIの大規模言語モデル(GPT)に利用されるデータ収集ボット(公式)
ClaudeBot
- AnthropicのClaudeモデル向けクローラー(公式)
Google-Extended
- GoogleがGemini向けに提供するクローラー拡張設定。検索用Googlebotとは別扱い。
Applebot
- 従来の検索・プレビュー用Applebotだが、Apple IntelligenceのAI学習にも利用されている
- 参照: Applebot 公式
PerplexityBot
- 回答生成のためWebクロールを行っている。アクセス頻度が高い傾向がある
- 目的: 回答生成・検索体験のためのクロール
OAI-SearchBot
- OpenAIの検索特化型クローラーとされるUA
- リアルタイムなWeb情報取得
ChatGPT-User
- ChatGPT経由のユーザーフェッチを示すUAとされる
- ブラウジングやプラグイン/ツール使用時の取得と関連付けられることがある
Meta-ExternalAgent
- Metaによる外部取得用UAとされ、LLM向けのデータ収集用途が指摘されている
🔍 検索エンジン系
| Bot名 | 運営組織 | User-Agent例 |
|---|---|---|
| Googlebot | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
|
| bingbot | Microsoft | Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Baiduspider | Baidu | Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) |
| YandexBot | Yandex | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
| DuckDuckBot | DuckDuckGo | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
| Sogou Spider | Sogou | Sogou web spider/4.0 (+http://www.sogou.com/docs/help/webmasters.htm#07) |
| AdsBot-Google | AdsBot-Google (+http://www.google.com/adsbot.html) |
|
| Mediapartners-Google | Mediapartners-Google |
Googlebot
- Google検索のインデックス作成に必須のクローラー
- クロール頻度はサイト評価や更新頻度に応じて自動調整される
- User-Agent偽装が頻繁に発生するため、確認には公式手順によるIP逆引きチェックが推奨
- Googleのクローラー一覧
-
Googlebotを対象に制御可能(robots.txt ガイド) - 参照サイト
- ブロックすると、Google 検索での表示・トラフィックに影響がある
AdsBot-Google
- Google 広告のランディングページ品質評価(特殊なケース用クローラー(Google公式)、AdsBot 公式ページ)
- ブロックすると、広告審査や品質評価に影響する(Google公式、AdsBot 公式ページ)
Mediapartners-Google
- AdSense のコンテンツターゲティング用クロール(Google公式)
- ブロックすると、広告配信・最適化に影響する可能性がある
bingbot
- Microsoftの検索エンジンBingのクローラー
- Bingの検索結果だけでなく、CopilotやEdgeブラウザのAI機能にも利用される可能性がある
- Googlebot同様に正規性確認のためIPアドレスレンジを公開している
- Bingbotの検証手順。
Baiduspider
- 中国最大手検索エンジンBaiduのクローラー
- ブロックすると、Baidu 検索での表示・トラフィックに影響する
YandexBot
- ロシアの検索エンジンYandexのクローラー
- ニュース・画像・動画など複数種類のボットが存在し、アクセス元はロシアIPが多い
- 参照: YandexBot 公式
DuckDuckBot
- DuckDuckGoの検索結果に使用される
- 参照: DuckDuckBot 公式ヘルプ
- ブロックすると、DuckDuckGo 検索での表示に影響する
Sogou Spider
- 中国のSogou検索エンジンのボット。日本語サイトにもアクセスしてくる
📱 SNS系
SNSのボットは、基本的には、必要になったタイミングでアクセスします(検索エンジンのように定期クロールではない)。ユーザーがSNSにURLを貼ったときや、プラットフォーム側のキャッシュ更新時にアクセスします。
| Bot名 | 運営組織 | User-Agent例 |
|---|---|---|
| facebookexternalhit | Meta | facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
| Facebot | Meta | facebot |
| Twitterbot | X (旧Twitter) | Twitterbot/1.0 |
| Pinterestbot | Pinterestbot/1.0 |
|
| Bytespider | ByteDance/TikTok | Bytespider |
facebookexternalhit
- FacebookやInstagramで共有されたURLをプレビュー生成する際に使用する
- 画像の取得に失敗すると、複数回アクセスされる
- ブロックするとリンクカード(遷移先のプレビュー)が表示されない
- (公式ドキュメント)
Facebot
- MetaのFacebookクローラーが使う別UA
- 基本的な役割は
facebookexternalhitと同じで、貼られたURLの情報取得に使われる
Twitterbot
- XでURLをプレビュー生成する際に使われるクローラー
- ブロックするとリンクカード(遷移先のプレビュー)が表示されない
- (公式ヘルプ/ドキュメント)
Pinterestbot
- Pinterest でピン作成に利用。画像の取得やメタデータの確認を行う
Bytespider
- ByteDance(TikTok等)によるクローラー
- TikTok等向けのコンテンツ取得を行う(公式サイト)
📊 SEOツール系
| Bot名 | 運営組織 | User-Agent例 |
|---|---|---|
| AhrefsBot | Ahrefs | AhrefsBot/7.0 (+http://ahrefs.com/robot/) |
| SemrushBot | Semrush | SemrushBot (+http://www.semrush.com/bot.html) |
| DotBot | Moz | DotBot/1.2 (+https://moz.com/help/moz-api/mozscape/mozscape-overview/technical-details) |
| MJ12bot | Majestic | MJ12bot/v1.4.8 (+http://mj12bot.com/) |
| Screaming Frog SEO Spider | Screaming Frog | Screaming Frog SEO Spider/17.1 |
| SeznamBot | Seznam.cz | SeznamBot/3.2 (+https://napoveda.seznam.cz/en/seznambot-intro/) |
AhrefsBot
- SEO分析ツール「Ahrefs」のクローラー
- 競合分析やキーワード調査に利用される
- クロール頻度が高く、サーバー負荷が大きいため拒否するサイトも多い
- サイト監査データの収集を行う(Ahrefs 公式 UA ページ)
SemrushBot
- SEO分析ツール「Semrush」のクローラー
- こちらもアクセス頻度は高い
- SemrushBot 公式
DotBot
- Mozのデータ収集用ボット。SEOツール「Moz Pro」に利用される
- (Moz 公式 UA 情報)
MJ12bot
- Majesticのデータ収集用ボット。分散型クローラーで、アクセス元が多様
- MJ12bot 公式
- robots.txt:
MJ12botで制御(公式)
Screaming Frog SEO Spider
- SEO解析ツール(公式ガイド)
🗄️ 保存・研究データ収集系
ウェブの記録や検証、研究・教育、データセット公開などに役立てる目的で、広範にページを収集・保存するタイプのボットです。
| Bot名 | 運営組織 | User-Agent例 |
|---|---|---|
| CCBot | Common Crawl | CCBot/2.0 (+https://commoncrawl.org/faq/) |
| archive.org_bot | Internet Archive | archive.org_bot (+http://archive.org/details/archive.org_bot) |
CCBot
- Common Crawlプロジェクトのクローラー
- 公開Webを大規模に収集し、研究やAI学習データに利用しており、アクセス量は膨大。
- Common Crawl 公式
archive.org_bot
- Internet ArchiveのWayback Machine用ボット
- Webページを保存し、履歴閲覧を可能にする
- ブロックするとWaybackに保存されなくなる
- Internet Archive 公式
User-Agent偽装について
User-Agentだけでは判定できない理由
User-Agentヘッダーは簡単に偽装できてしまいます。悪意のあるスクレイピングツールやボットが「Googlebot」や「facebookexternalhit」を名乗ってアクセスすることは日常的に起こっています。
以下のような「-A」オプションを付けてコマンドを実行すると、User-Agentを偽装できます。
curl -A "Googlebot/2.1 (+http://www.google.com/bot.html)" https://example.com
curl -A "facebookexternalhit/1.1" https://example.com
偽装される理由
1. アクセス制限を回避したい
- robots.txtやUser-Agentフィルターをすり抜ける
- 正規クローラーの許可リストに紛れ込む
2. 正規クローラー向けのデータを取得したい
- 一部のサイトでは正規クローラー向けに最適化されたコンテンツを提供しているため、これが狙われます
- SNSプレビュー用の画像や要約を取得
- 検索エンジン向けの構造化データにアクセス
- JavaScript不要の静的HTMLを取得
正規クローラーの判定方法
User-Agentは簡単に偽装できますが、IPアドレスは偽装できないため、これを確認することで本物かどうかを判定できます。確認方法は以下2つのアプローチがあります。
①DNS逆引き
IPアドレスには「このIPは○○のものです」という情報(逆引きDNSレコード)が設定されているため、これを確認します。
手順(Googlebotの場合):
- アクセス元IPを逆引き → 「googlebot.com」かチェック
- そのホスト名を正引き → 元のIPと一致するかチェック
※もし悪意のある第三者の場合、自分のIPに偽のホスト名は設定できるが、googlebot.comゾーンはGoogleしか管理できないため、ステップ2(正引き)では失敗する
$ host 66.249.66.1
1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com.
$ host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
②公式IPリストと照合
一部のクローラーは「私たちはこれらのIPアドレスを使います」というリストを公開しているため、アクセス元IPがそのリストに含まれるか、によって確認できます。
| クローラー | 対応方法 |
|---|---|
| Bingbot | 公式IPリストを公開 |
| Yandex | 公式IPリストを公開 |
まとめ
本記事では、Botを「生成AI / 検索 / SNS / SEOツール / 研究・保存(アーカイブ)」の5系統に整理し、代表的なUser-Agentと役割を示しました。
情報はAIに使われるが、サイトには誰も来ない、という状況が加速するなか、AIクローラーに対して課金ルールを設定できる新しい仕組みも登場しています。
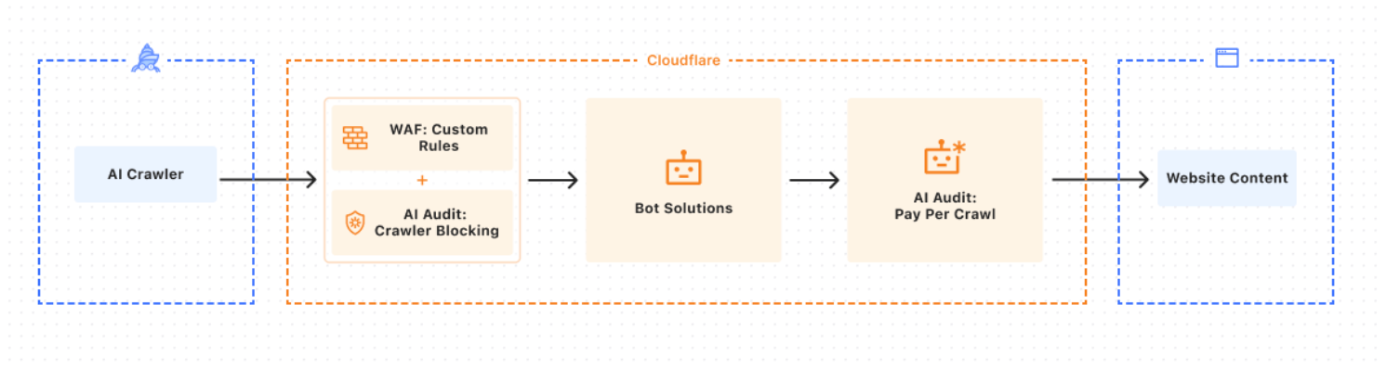
引用:The Cloudflare Blog - Introducing pay per crawl
こういった収益モデルの変化の動向は、しっかり追っていきたいと思います。
最後までご覧いただき、ありがとうございました。

Discussion