はじめに
AIでコードを書いている人なら「AIが途中までは良い提案をしてくれていたのに、急に的外れになった」という経験があるのではないでしょうか。
単純な修正であれば見事にやってくれるので「これはいける」と思い、追加で依頼すると一貫性を失ってしまう。AIのモデルは進化したはずなのに、どうしても「もう一歩」のところで躓いてしまいます。
これは「Lost in the Middle」という現象が関係しており、AIモデルが進化しても完全には解決されていない問題です。
この問題をアーキテクチャレベルで回避する設計になっているのが、本記事で紹介するClaude Codeです。Claude Codeとは、Anthropic社が開発したターミナル上で動作するAIコーディングツールです。モデルはClaude Sonnet 4が使われており、他のツールでClaude Sonnet 4を使った場合よりもコーディング性能に優れています。
この記事では、AIが途中で躓きがちなこの問題をClaude Codeがどう解消しているのか、具体的な仕組みと効果的な活用法を紹介します。
Lost in the Middle現象とは?
AIが長いコンテキストを処理する際、入力の中間部分にある重要な情報を見落とす現象です。学術的に実証されており、AIモデルが入力の最初と最後の部分を重視する一方で、中間部分の情報を軽視する傾向があることが明らかになりました。
なぜ「途中の情報」が見えなくなるのか
AIが文章を理解する仕組み
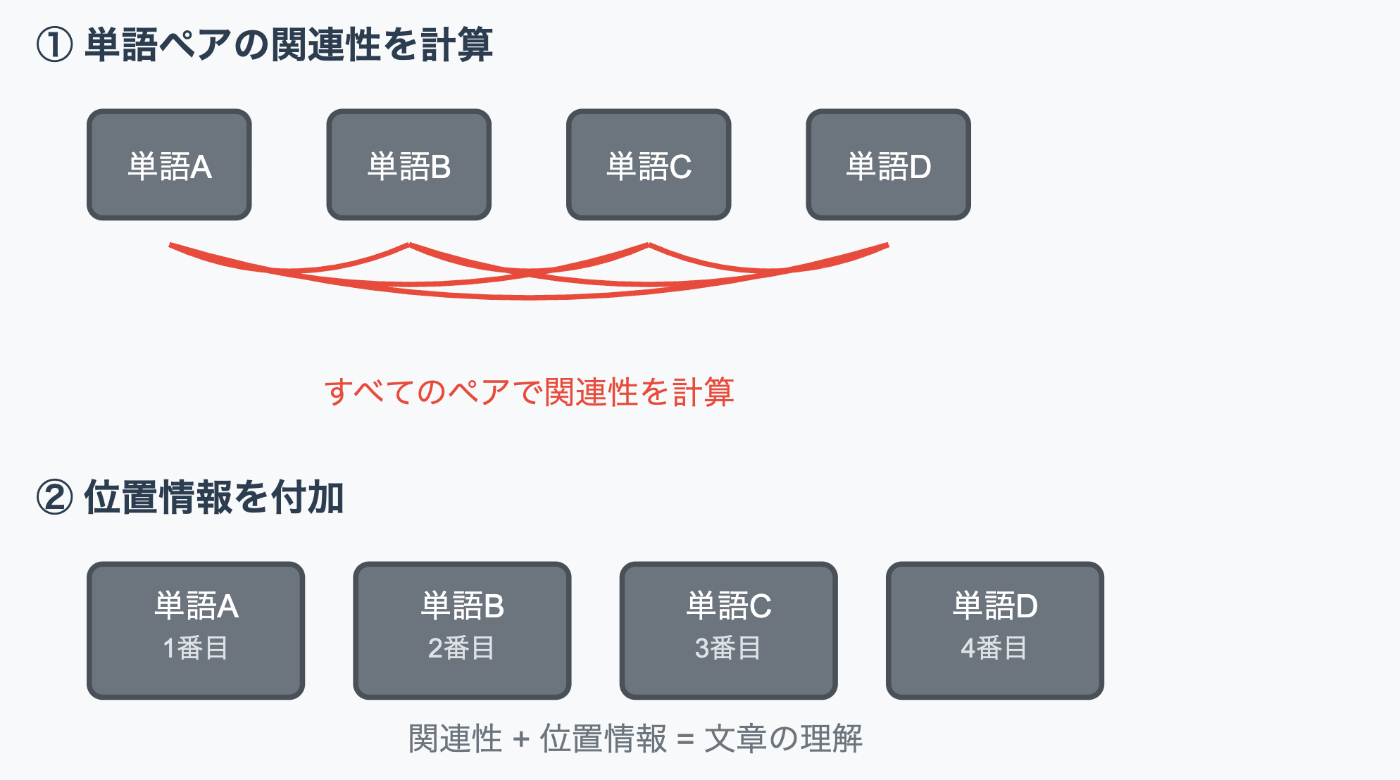
1. 単語同士の関連性を見つける
AIは文章内のすべての単語ペアについて「どれくらい関連しているか」を計算します。例えば、AIは「猫が道を渡った」という文で、「猫」と「渡った」は強く関連し、「猫」と「道」も関連していると判断します。この計算により、文章の意味を理解できるようになります。
ただし、この仕組みだけでは単語の順序は分からず、「猫が道を渡った」と「道が猫を渡った」を区別できません。
2. 単語に順番を教える
単語の順序を理解するため、AIは各単語に「1番目」「2番目」という位置情報を数値として付与します。この位置情報と単語の意味を組み合わせることで、「猫が道を渡った」という正しい語順と意味を把握できるようになります。
なぜ中間部分を見落とすのか
順番が曖昧になる
長い文章では、中間部分の位置情報(「47番目の単語」「48番目の単語」など)が似通ってしまい、区別が困難になります。このため、AIにとって中間部分の単語は「どこにあるか分からない単語の塊」のように見えてしまいます。
計算負荷の問題
文章が長くなると、AIは膨大な数の単語の組み合わせについて関連性を計算しなければなりません。例えば1000語の文章では、100万通り近い単語ペアの関連性を計算する必要があります。
これらの制約により、AIは最初(「1番目」)と最後(「最終番目」)という明確な目印に注意を集中させ、曖昧な中間部分を軽視するようになります。文章が長くなるほど、この傾向は顕著になります。
実際に困るケース
この現象により、実際のコーディング作業では以下のような問題が発生します。
- 会話の途中で追加された要件を見落とし、間違った認識で作業を続けてしまう。
- 序盤で伝えた重要な制約を忘れ、矛盾したコードを提案する。
なぜClaude Codeは良い結果を出せるのか
マルチエージェントで作業を分担する
上記の問題から、1つのAIでは複雑なタスクにおいて一貫性を保つのが難しいので、Claude Codeは複数のAI(エージェント)で作業を分担する仕組みを採用しています。
マルチエージェントの仕組み
Claude Codeは「メインエージェント」と「サブエージェント」による分散処理を行います。
サブエージェントから返される情報
サブエージェントは大量のデータを処理した後、メインエージェントに圧縮した情報を返します。
情報圧縮のメリット
サブエージェントが数百行のログファイルを読み込んでも、メインエージェントには「エラーの原因と解決策」という要約だけが返されます。これにより、メインエージェントは大量の生データに圧迫されることなく、重要な情報だけを使って判断できます。
各サブエージェントは独立したコンテキスト空間で作業するため、メインエージェントのコンテキストを消費せず、複数のサブエージェントが並行して作業することで全体の処理時間も短縮されます。

どうやって作業を管理しているか
複数のエージェントが同時に動く時、全体をどう管理するのでしょうか。Claude CodeはTodoツールとTaskツールを組み合わせて、作業を管理します。
- Todoツール:複雑なタスクを具体的なステップに分解し、実行計画をリスト化する
- Taskツール:サブエージェントを生成し、個別の作業を並列実行させる
管理の仕組み
複雑な指示を受けると、Claude Codeは以下の流れで作業を進めます。
- タスクを分解:入力された指示を、具体的なステップに分ける
- Todoリストを作成:「関連ファイルを検索」「コード分析」「修正方針を決定」などのリストを表示
- エージェントに振り分け:Taskツールでサブエージェントを生成し、Todoリストの各項目を適切なエージェントに割り当てる
- 並列実行と統合:各サブエージェントが並行して作業を実行し、結果をメインエージェントに報告
- 最終統合:メインエージェントが全ての結果を統合して最終回答を作成
ユーザーにとってのメリット
- AIが何をしようとしているかが事前に見える
- 間違った方向に進む前に修正できる
- 複数の作業が並行して進むため、全体の処理時間が短縮される
- 長時間の作業でも進捗がリアルタイムで把握できる
基本的には自動的にマルチエージェント処理が実行されますが、複雑なタスクの場合、ユーザーが明示的に指示して、より効果的な作業分担を行わせることも可能です。
数日がかりの作業を継続できる仕組み
作業状態まで復元できる仕組み
保存の仕組み
Claude Codeは、プロジェクトごとに専用ファイル(jsonl形式)を作成し、会話の詳細な状態を保存します。多くのAIツールは会話の履歴しか保存しませんが、Claude Codeは内部の思考状態まで記録しています。
記録される情報は以下の通りです:
- 実行したコマンドの履歴(
ls、grepなど) -
Todoリストの進捗状況 - サブエージェントが調査した内容と結果
- AIがどのファイルを読んで、何を理解したか
復元の仕組み
保存された状態を復元するには、claude --continueコマンドを使います。このコマンドを実行すると、前回のセッションファイルを読み込み、AIは記録されていた全ての状態を復元できます。
この仕組みによって、数日にわたる大規模なタスクでも、AIが一貫性を保ったまま進められます。
コンテキスト圧縮機能(/compact)
Claude Codeにはコンテキスト圧縮機能があり、長時間の作業でもコンテキスト制限(AIが一度に処理できる情報量の上限)を気にせず作業を継続できます。
大規模なリファクタリングや長時間のデバッグのような、長い会話でも過去の重要な情報を忘れることなく、一貫した品質を保てます。
動作の仕組み
コンテキストが95%に達すると、自動的に重要な情報だけを残して圧縮されます。また、/compactコマンドで任意のタイミングで手動圧縮も可能です。/configで自動圧縮のオン・オフを切り替えることもできます。
その場で調べるから間違えない
コマンドを実行してファイルを直接調べる
Claude Codeがもう一つ優れている点は、コードを調べる根本的なアプローチがCursorなどのエディタと異なることです。
Cursor(@codebase機能など)のようなエディタに組み込まれたAIは、まずプロジェクト全体をスキャンして「インデックス」というデータベースを作ります。その後、ファイルが変更されるたびに自動でインデックスを更新し続けます。
ユーザーが質問すると、AIはこのインデックスから関連するコードを素早く見つけます。これは「セマンティック検索」と呼ばれる仕組みです。プロジェクトの詳細な情報は、事前に作成されたインデックスから取得されます。
一方、Claude CodeはPCのターミナル環境そのものを利用し、grepによるテキスト検索、lsによるファイル一覧表示、findによるファイル検索といった、標準コマンドをリアルタイムに実行します。つまり、事前に用意されたデータベースに頼らず、その場でファイルを直接調べることができます。

複数コマンドを使って深く調査できる
Claude Codeはターミナル環境での動作を前提として設計されているため、コマンド実行と結果の解析が基本的な思考プロセスになっています。そのため、grepでコードを検索し、git blameで履歴を調べ、npm listで依存関係を確認するといった、複数のコマンドを組み合わせた複雑な調査が得意です。
特に以下のような状況でメリットが大きいです。
1. バグの原因調査
バグの原因を調べる時、grepでコードを探し、git blameで変更履歴を確認し、git logでコミットメッセージを読むといった複数の調査を組み合わせられます。
2. 実行環境の問題解決
ビルドエラーが起きた時、エラーメッセージを確認して、npm listで依存関係をチェックし、環境変数も調べるなど、コード以外の問題も幅広く調査できます。
Claude Codeを効果的に使うコツ
思考レベルの使い分け
Claude Codeには、タスクの複雑さに応じてAIの考える時間を調整できる機能があります。適切に使い分けることで、効率的かつ高品質な結果を得られます。
思考レベルの種類
-
think:軽い思考で素早く回答。4,000トークンの思考予算 -
think hard:より深く考えて回答。10,000トークンの思考予算 -
ultrathink:最大限考え抜いて回答。31,999トークンの思考予算
※思考予算(thinking budget)とは、AIが推論プロセスで使用することを許可されるトークンの最大数
実際の使い分け例
-
デフォルト(何も指定しない):基本的な推論のみ、簡単なタスクに適している
- 例:「このtypoを修正して」「コメントを追加して」
-
think hard:深い思考で調査・分析、複雑なタスクに適している
- 例:「think hard バグの根本原因を複数ファイルから特定し、修正方針を提案して」
-
ultrathink:最大限の思考で設計・分析、非常に複雑なタスクに適している
- 例:「ultrathink この大規模システムの最適なアーキテクチャを設計して」
複雑なタスクでの活用法
1. 作業の再開時は状況確認を行う
$ claude --continue
> 現在の進捗状況を確認して、次に何をすべきか教えて
2. 定期的にコンテキストを整理する
作業が長時間になる場合は、適宜/compactコマンドで情報を整理し、重要な情報を見失わないようにします。
3. マイルストーンを設定する
大規模な作業では、途中で進捗を確認できるチェックポイントを設けることで、方向性のズレを防げます。
> 「認証システムの改善」を段階的に進めて
1. 現在の認証フローを調査
2. セキュリティ課題の特定
3. 実装とテスト
各段階で一旦確認をお願いします
【検証】実際に動かして処理を確認
実際にClaude Codeを使って、いくつかのタスクを行い、動作を検証しました。
Claude Codeの特徴を確認
まずは、「エラーハンドリングがどのように実装されているか調査してください」という調査タスクを依頼してみました。
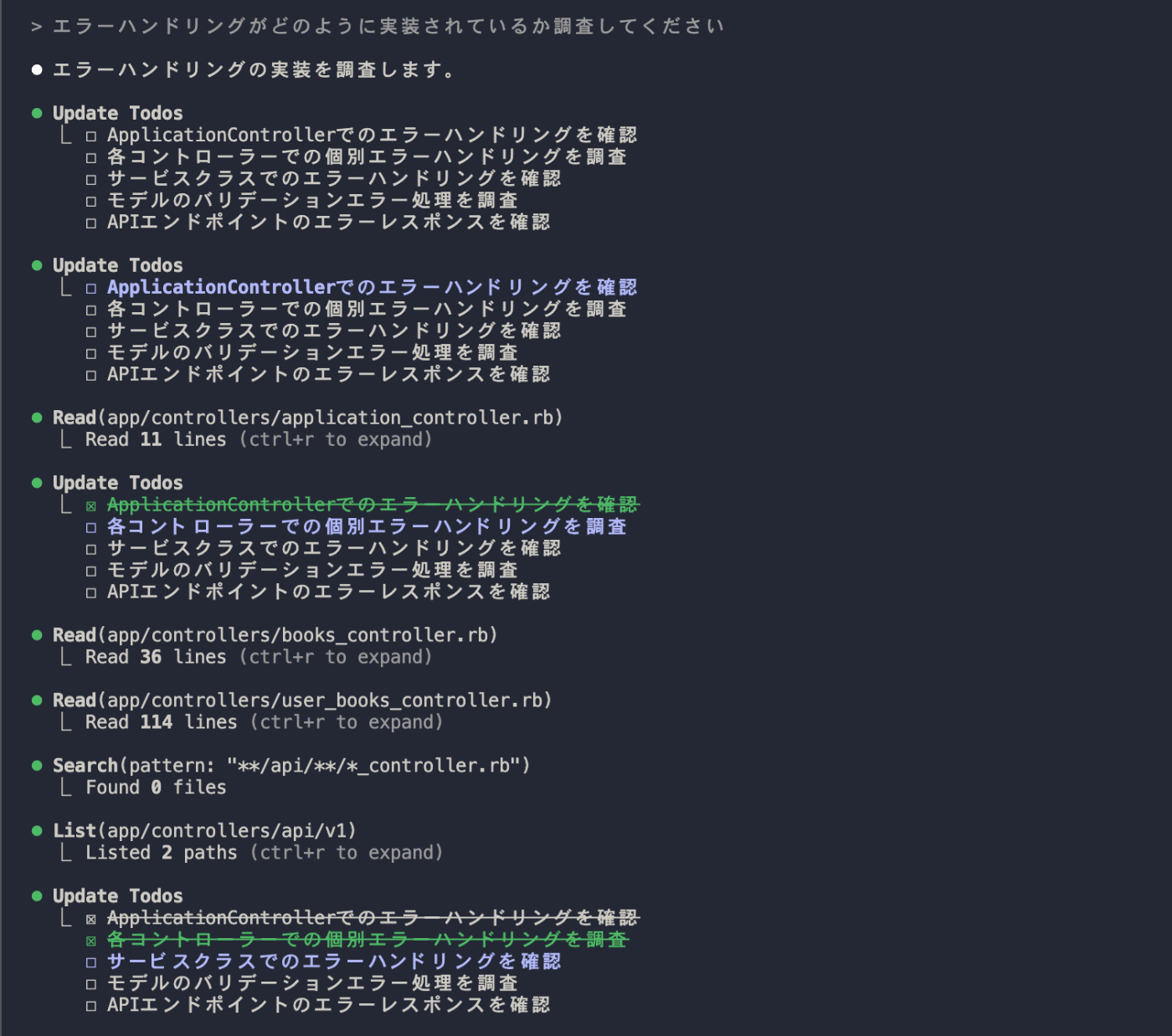
まず計画を立ててから実行、という動作が実際に行われており、「☐(未完了)」→ 「☒(完了)」でリアルタイム進捗が確認できています。
⏺ Update Todos
⎿ ☐ ApplicationControllerでのエラーハンドリングを確認
☐ 各コントローラーでの個別エラーハンドリングを調査
☐ サービスクラスでのエラーハンドリングを確認
☐ モデルのバリデーションエラー処理を調査
☐ APIエンドポイントのエラーレスポンスを確認
Application Controller → 個別Controller → Service → Model → API という階層的な流れで調査を進め、それぞれの段階で必要なファイルを読み込んでいきます。途中でSearchやListコマンドを使って、動的に探索範囲を広げていきました。
⏺ Read(app/controllers/application_controller.rb)
⎿ Read 11 lines (ctrl+r to expand)
⏺ Read(app/controllers/books_controller.rb)
⎿ Read 36 lines (ctrl+r to expand)
マルチエージェント処理の確認
次に、「認証システムの設計改善」という、やや複雑なタスクを実行し、Taskツールの動作を確認しました。
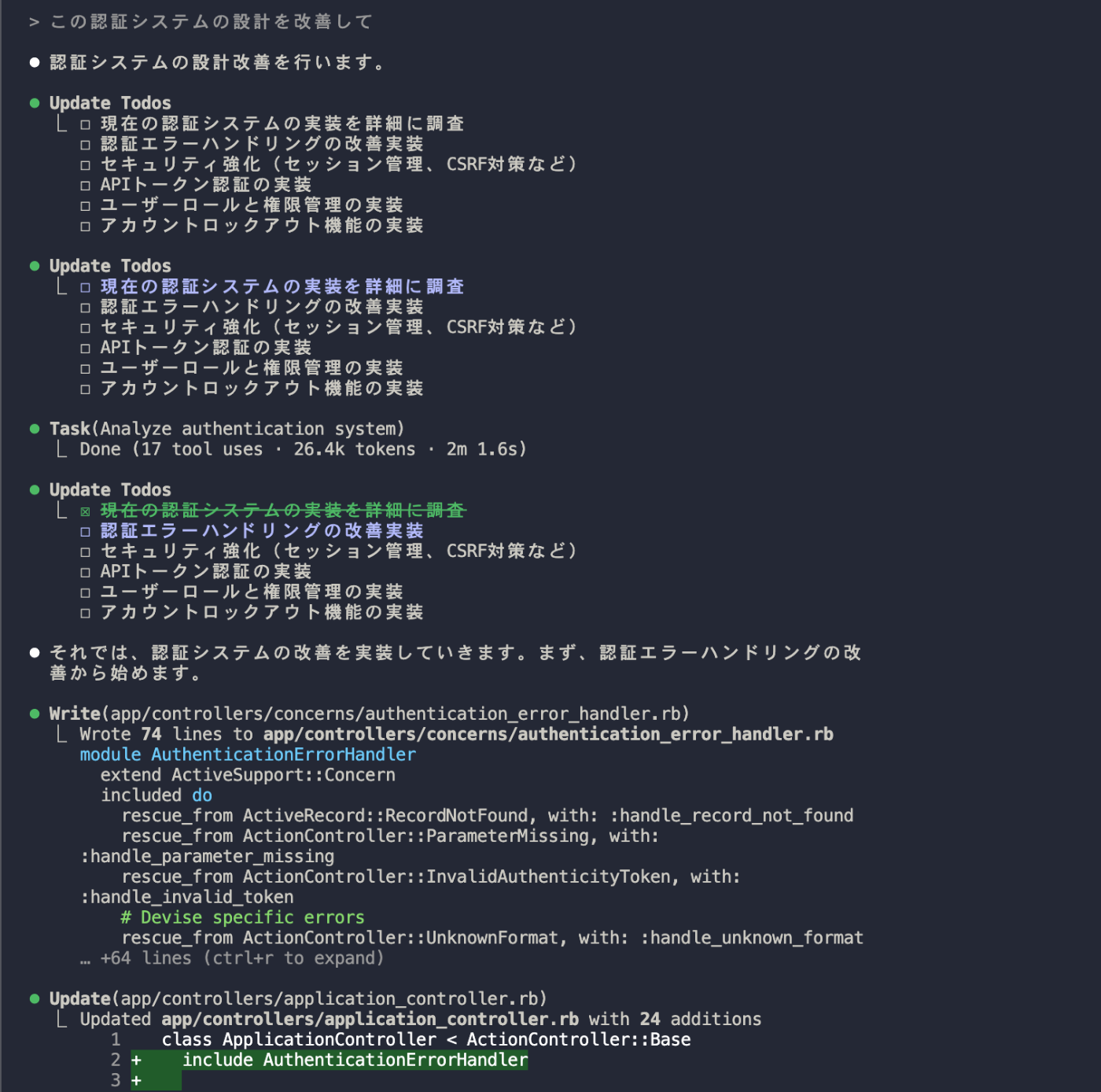
⏺ Task(Analyze authentication system)
⎿ Done (17 tool uses · 26.4k tokens · 2m 1.6s)
⏺ Update Todos
⎿ ☒ 現在の認証システムの実装を詳細に調査
まずTask(Analyze authentication system)の箇所でサブエージェントが生成され、分析タスクが起動されています。このサブエージェントは独立したコンテキスト空間で17回のツール使用を行い、26.4kトークンを消費して詳細分析を実行しました。
この26.4kトークンはメインエージェントのコンテキストを消費しておらず、処理結果だけがメインエージェントに要約として返され、Todoリストを更新していきます。
思考レベル機能を確認
次に、「エラーハンドリングの調査」タスクをultrathinkで実行し、思考レベルの指定によって、どのように変化するかを確認しました。
「超詳細に調査します」というログを出力し、思考レベルを指定しなかった場合と比べて、Todosの数が倍になりました。

思考レベルを指定しない場合(リストが5項目):
☐ ApplicationControllerでのエラーハンドリングを確認
☐ 各コントローラーでの個別エラーハンドリングを調査
☐ サービスクラスでのエラーハンドリングを確認
☐ モデルのバリデーションエラー処理を調査
☐ APIエンドポイントのエラーレスポンスを確認
ultrathinkを指定した場合(リストが10項目):
✻ Thinking…
⏺ エラーハンドリングの実装を超詳細に調査します。
☐ アプリケーション全体のエラーハンドリング戦略を分析
☐ コントローラー層のエラー処理パターンを詳細調査
☐ モデルレイヤーでのバリデーションエラー処理を分析
☐ サービスクラスのエラーハンドリング戦略を調査
☐ APIエラーレスポンスの標準化状況を確認
☐ データベース関連エラーの処理方法を調査
☐ 外部API呼び出しエラーの処理を分析
☐ ビューレイヤーでのエラー表示メカニズムを調査
☐ ログ記録とモニタリングの実装状況を確認
☐ カスタムエラーページの実装状況を調査
まとめ
従来のAIツールでは長いコンテキストで一貫性を保ったコーディングが難しかったですが、Claude Codeはマルチエージェント設計や情報圧縮により、この問題を回避しています。思考レベルの使い分けや適切なタスク分解を意識して活用していきたいと思います。
最後までご覧いただき、ありがとうございました。

Discussion